 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Less is More: Proxy Datasets in NAS approaches
Mar 14, 2022
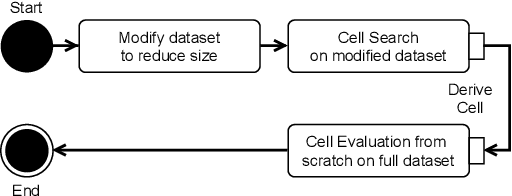
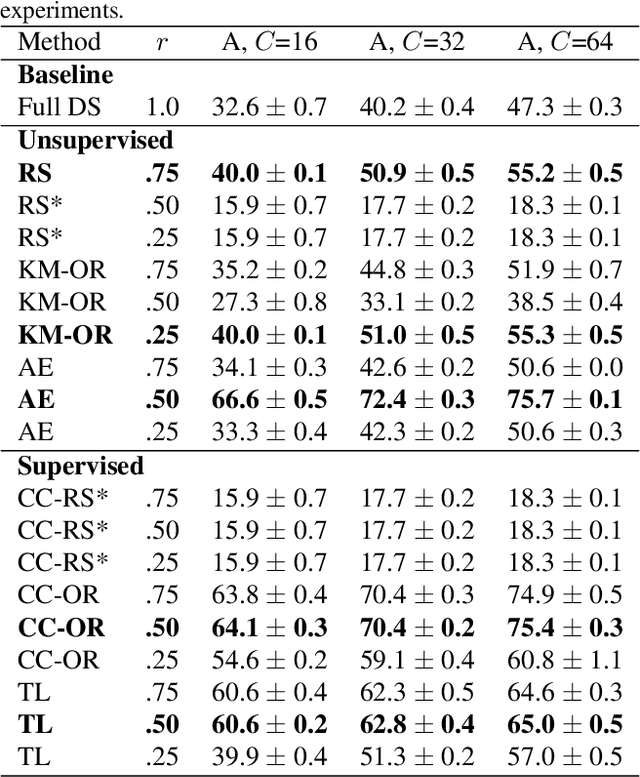
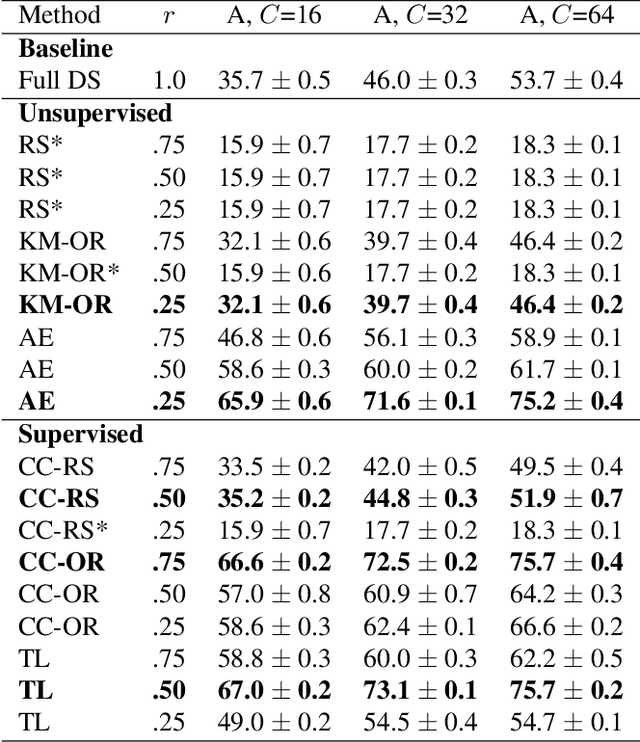
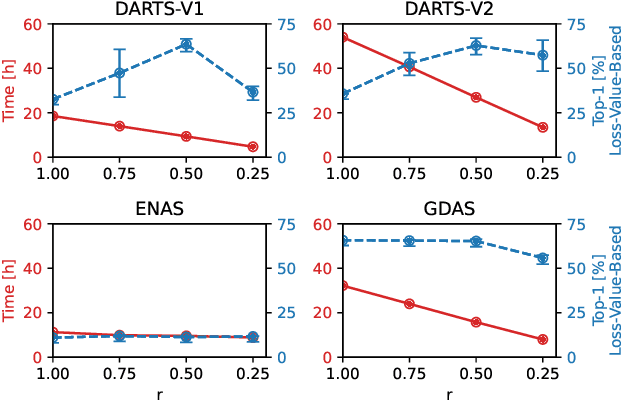
Neural Architecture Search (NAS) defines the design of Neural Networks as a search problem. Unfortunately, NAS is computationally intensive because of various possibilities depending on the number of elements in the design and the possible connections between them. In this work, we extensively analyze the role of the dataset size based on several sampling approaches for reducing the dataset size (unsupervised and supervised cases) as an agnostic approach to reduce search time. We compared these techniques with four common NAS approaches in NAS-Bench-201 in roughly 1,400 experiments on CIFAR-100. One of our surprising findings is that in most cases we can reduce the amount of training data to 25\%, consequently reducing search time to 25\%, while at the same time maintaining the same accuracy as if training on the full dataset. Additionally, some designs derived from subsets out-perform designs derived from the full dataset by up to 22 p.p. accuracy.
Neural Generalised AutoRegressive Conditional Heteroskedasticity
Feb 23, 2022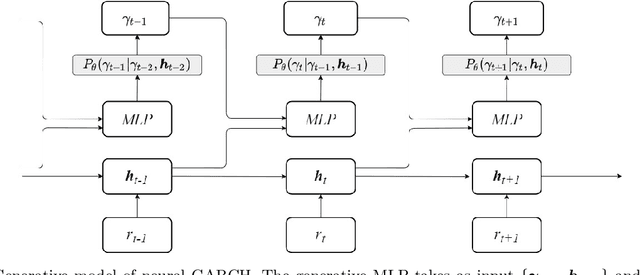

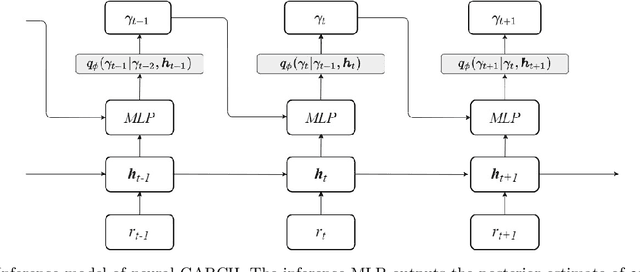
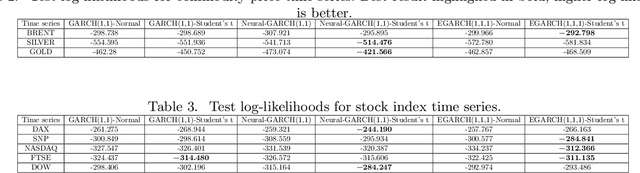
We propose Neural GARCH, a class of methods to model conditional heteroskedasticity in financial time series. Neural GARCH is a neural network adaptation of the GARCH 1,1 model in the univariate case, and the diagonal BEKK 1,1 model in the multivariate case. We allow the coefficients of a GARCH model to be time varying in order to reflect the constantly changing dynamics of financial markets. The time varying coefficients are parameterised by a recurrent neural network that is trained with stochastic gradient variational Bayes. We propose two variants of our model, one with normal innovations and the other with Students t innovations. We test our models on a wide range of univariate and multivariate financial time series, and we find that the Neural Students t model consistently outperforms the others.
Prediction-Based Reachability Analysis for Collision Risk Assessment on Highways
May 03, 2022
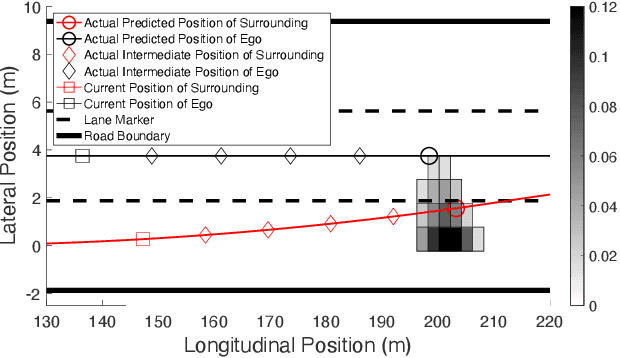
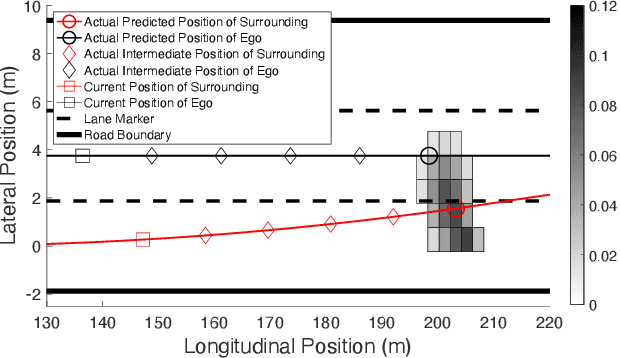
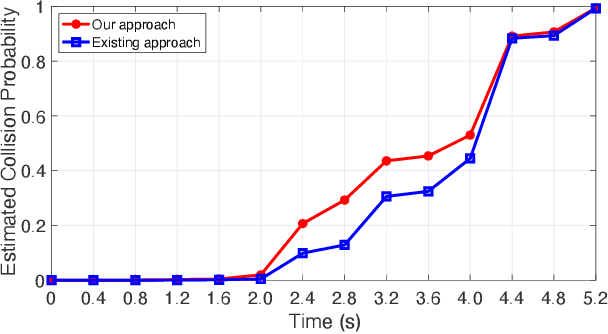
Real-time safety systems are crucial components of intelligent vehicles. This paper introduces a prediction-based collision risk assessment approach on highways. Given a point mass vehicle dynamics system, a stochastic forward reachable set considering two-dimensional motion with vehicle state probability distributions is firstly established. We then develop an acceleration prediction model, which provides multi-modal probabilistic acceleration distributions to propagate vehicle states. The collision probability is calculated by summing up the probabilities of the states where two vehicles spatially overlap. Simulation results show that the prediction model has superior performance in terms of vehicle motion position errors, and the proposed collision detection approach is agile and effective to identify the collision in cut-in crash events.
Great Power, Great Responsibility: Recommendations for Reducing Energy for Training Language Models
May 19, 2022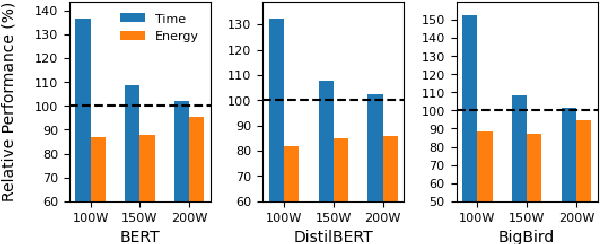

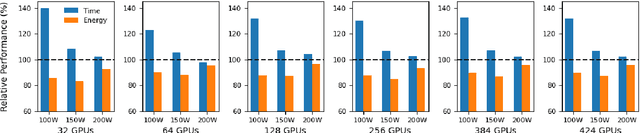
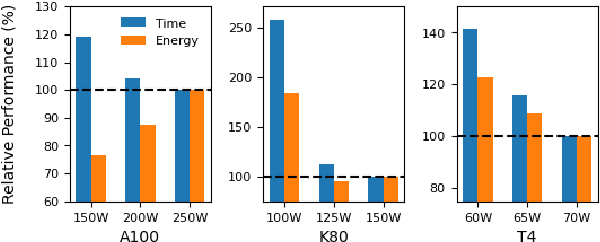
The energy requirements of current natural language processing models continue to grow at a rapid, unsustainable pace. Recent works highlighting this problem conclude there is an urgent need for methods that reduce the energy needs of NLP and machine learning more broadly. In this article, we investigate techniques that can be used to reduce the energy consumption of common NLP applications. In particular, we focus on techniques to measure energy usage and different hardware and datacenter-oriented settings that can be tuned to reduce energy consumption for training and inference for language models. We characterize the impact of these settings on metrics such as computational performance and energy consumption through experiments conducted on a high performance computing system as well as popular cloud computing platforms. These techniques can lead to significant reduction in energy consumption when training language models or their use for inference. For example, power-capping, which limits the maximum power a GPU can consume, can enable a 15\% decrease in energy usage with marginal increase in overall computation time when training a transformer-based language model.
Recognising Known Configurations of Garments For Dual-Arm Robotic Flattening
Apr 30, 2022
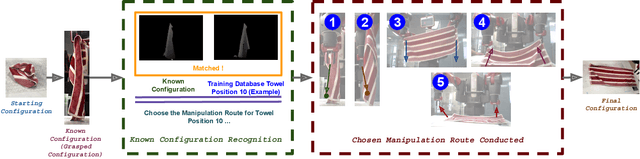


Robotic deformable-object manipulation is a challenge in the robotic industry because deformable objects have complicated and various object states. Predicting those object states and updating manipulation planning are time-consuming and computationally expensive. In this paper, we propose an effective robotic manipulation approach for recognising 'known configurations' of garments with a 'Known Configuration neural Network' (KCNet) and choosing pre-designed manipulation plans based on the recognised known configurations. Our robotic manipulation plan features a four-action strategy: finding two critical grasping points, stretching the garments, and lifting down the garments. We demonstrate that our approach only needs 98 seconds on average to flatten garments of five categories.
Autonomous Vehicle Calibration via Linear Optimization
Apr 27, 2022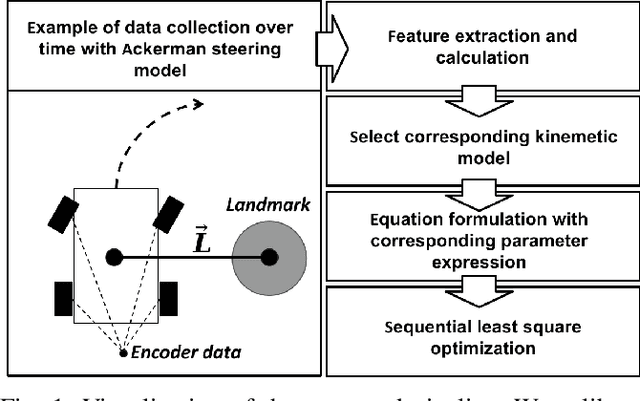
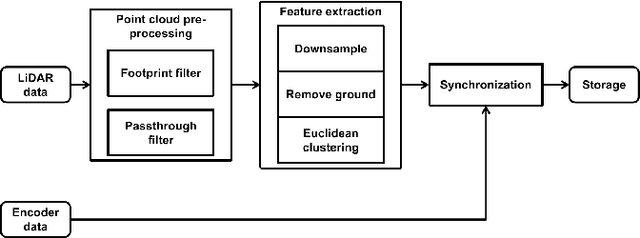
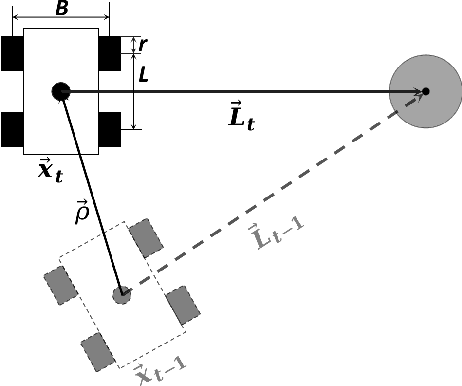
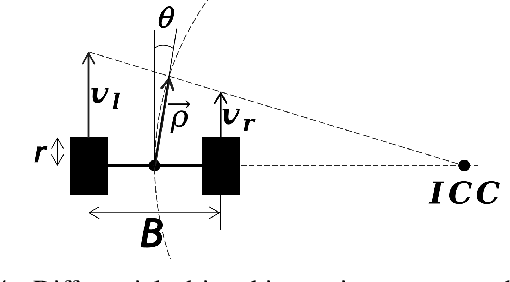
In navigation activities, kinematic parameters of a mobile vehicle play a significant role. Odometry is most commonly used for dead reckoning. However, the unrestricted accumulation of errors is a disadvantage using this method. As a result, it is necessary to calibrate odometry parameters to minimize the error accumulation. This paper presents a pipeline based on sequential least square programming to minimize the relative position displacement of an arbitrary landmark in consecutive time steps of a kinematic vehicle model by calibrating the parameters of applied model. Results showed that the developed pipeline produced accurate results with small datasets.
Greedy-GQ with Variance Reduction: Finite-time Analysis and Improved Complexity
Mar 30, 2021



Greedy-GQ is a value-based reinforcement learning (RL) algorithm for optimal control. Recently, the finite-time analysis of Greedy-GQ has been developed under linear function approximation and Markovian sampling, and the algorithm is shown to achieve an $\epsilon$-stationary point with a sample complexity in the order of $\mathcal{O}(\epsilon^{-3})$. Such a high sample complexity is due to the large variance induced by the Markovian samples. In this paper, we propose a variance-reduced Greedy-GQ (VR-Greedy-GQ) algorithm for off-policy optimal control. In particular, the algorithm applies the SVRG-based variance reduction scheme to reduce the stochastic variance of the two time-scale updates. We study the finite-time convergence of VR-Greedy-GQ under linear function approximation and Markovian sampling and show that the algorithm achieves a much smaller bias and variance error than the original Greedy-GQ. In particular, we prove that VR-Greedy-GQ achieves an improved sample complexity that is in the order of $\mathcal{O}(\epsilon^{-2})$. We further compare the performance of VR-Greedy-GQ with that of Greedy-GQ in various RL experiments to corroborate our theoretical findings.
Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
May 06, 2021
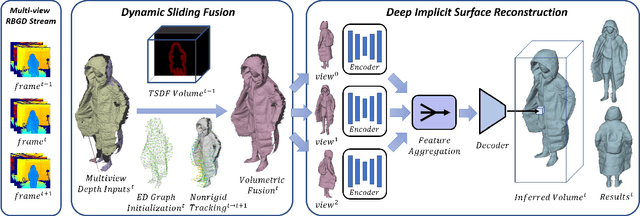

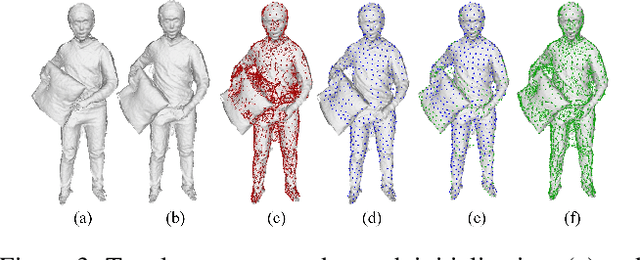
Human volumetric capture is a long-standing topic in computer vision and computer graphics. Although high-quality results can be achieved using sophisticated off-line systems, real-time human volumetric capture of complex scenarios, especially using light-weight setups, remains challenging. In this paper, we propose a human volumetric capture method that combines temporal volumetric fusion and deep implicit functions. To achieve high-quality and temporal-continuous reconstruction, we propose dynamic sliding fusion to fuse neighboring depth observations together with topology consistency. Moreover, for detailed and complete surface generation, we propose detail-preserving deep implicit functions for RGBD input which can not only preserve the geometric details on the depth inputs but also generate more plausible texturing results. Results and experiments show that our method outperforms existing methods in terms of view sparsity, generalization capacity, reconstruction quality, and run-time efficiency.
Channel Estimation in RIS-assisted Downlink Massive MIMO: A Learning-Based Approach
May 15, 2022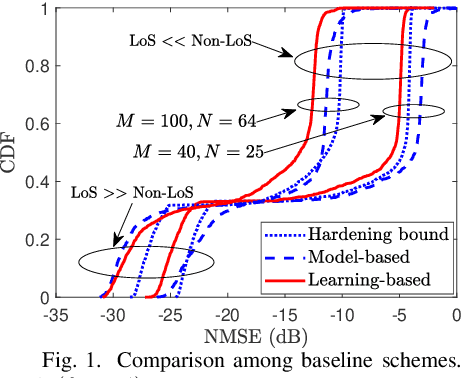
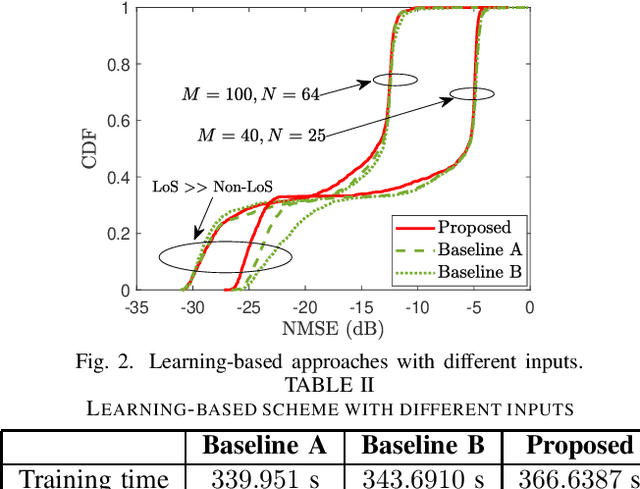
For downlink massive multiple-input multiple-output (MIMO) operating in time-division duplex protocol, users can decode the signals effectively by only utilizing the channel statistics as long as channel hardening holds. However, in a reconfigurable intelligent surface (RIS)-assisted massive MIMO system, the propagation channels may be less hardened due to the extra random fluctuations of the effective channel gains. To address this issue, we propose a learning-based method that trains a neural network to learn a mapping between the received downlink signal and the effective channel gains. The proposed method does not require any downlink pilots and statistical information of interfering users. Numerical results show that, in terms of mean-square error of the channel estimation, our proposed learning-based method outperforms the state-of-the-art methods, especially when the light-of-sight (LoS) paths are dominated by non-LoS paths with a low level of channel hardening, e.g., in the cases of small numbers of RIS elements and/or base station antennas.
Reconstructing common latent input from time series with the mapper-coach network and error backpropagation
May 05, 2021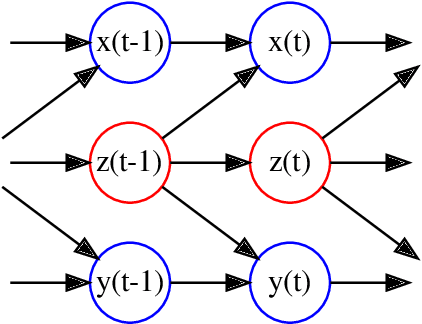
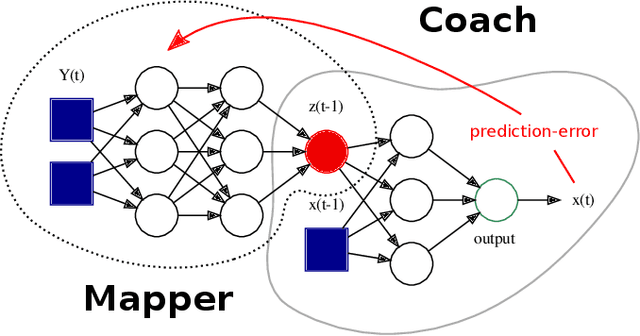
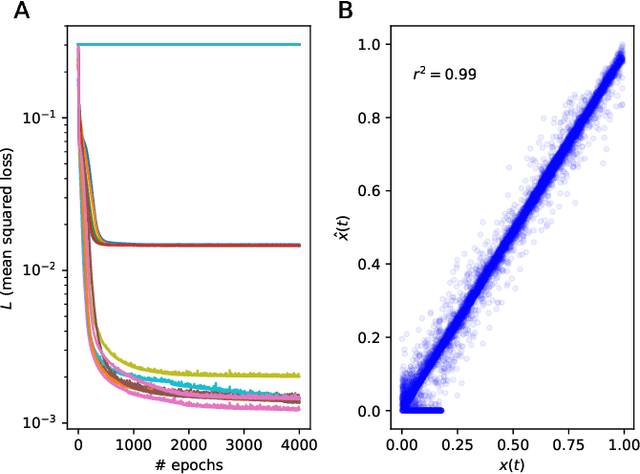
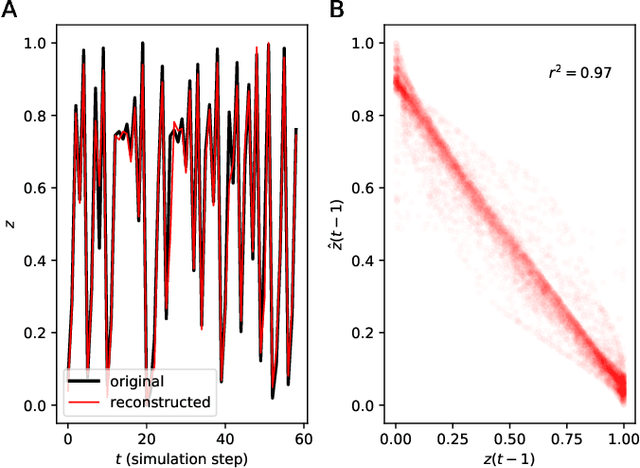
A two-module, feedforward neural network architecture called mapper-coach network has been introduced to reconstruct an unobserved, continuous latent variable input, driving two observed dynamical systems. The method has been demonstrated on time series generated by two chaotic logistic maps driven by a hidden third one. The network has been trained to predict one of the observed time series based on its own past and on the other observed time series by error-back propagation. It was shown, that after this prediction have been learned successfully, the activity of the bottleneck neuron, connecting the mapper and the coach module, correlates strongly with the latent common input variable. The method has the potential to reveal hidden components of dynamical systems, where experimental intervention is not possible.