 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Dual Dense Connection Network for Video Super-resolution
Mar 05, 2022
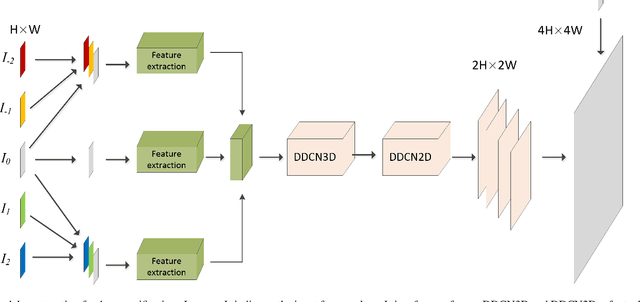
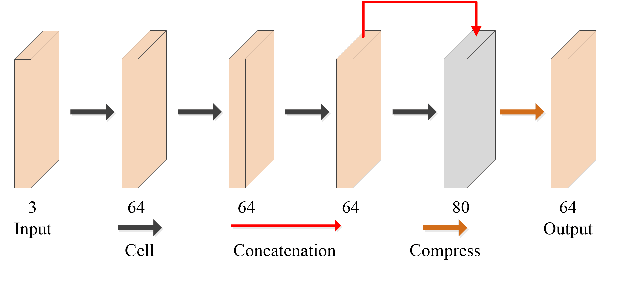
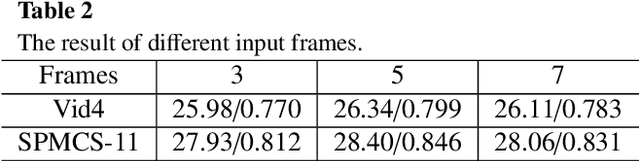
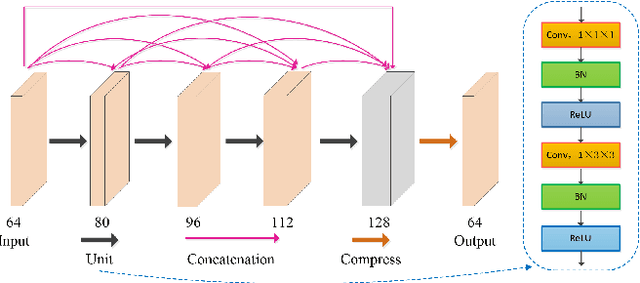
Video super-resolution (VSR) refers to the reconstruction of high-resolution (HR) video from the corresponding low-resolution (LR) video. Recently, VSR has received increasing attention. In this paper, we propose a novel dual dense connection network that can generate high-quality super-resolution (SR) results. The input frames are creatively divided into reference frame, pre-temporal group and post-temporal group, representing information in different time periods. This grouping method provides accurate information of different time periods without causing time information disorder. Meanwhile, we produce a new loss function, which is beneficial to enhance the convergence ability of the model. Experiments show that our model is superior to other advanced models in Vid4 datasets and SPMCS-11 datasets.
Real Time Egocentric Object Segmentation: THU-READ Labeling and Benchmarking Results
Jun 09, 2021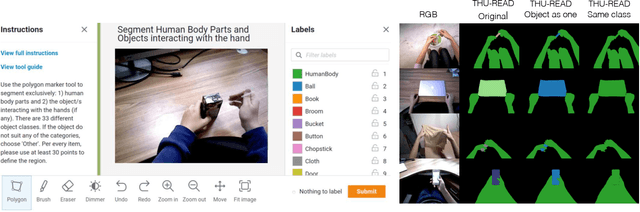
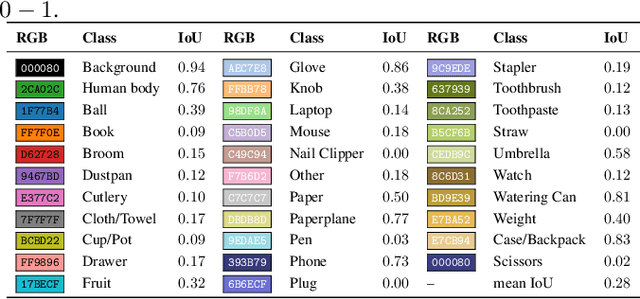

Egocentric segmentation has attracted recent interest in the computer vision community due to their potential in Mixed Reality (MR) applications. While most previous works have been focused on segmenting egocentric human body parts (mainly hands), little attention has been given to egocentric objects. Due to the lack of datasets of pixel-wise annotations of egocentric objects, in this paper we contribute with a semantic-wise labeling of a subset of 2124 images from the RGB-D THU-READ Dataset. We also report benchmarking results using Thundernet, a real-time semantic segmentation network, that could allow future integration with end-to-end MR applications.
Enhancement of Healthcare Data Transmission using the Levenberg-Marquardt Algorithm
Jun 09, 2022
In the healthcare system, patients are required to use wearable devices for the remote data collection and real-time monitoring of health data and the status of health conditions. This adoption of wearables results in a significant increase in the volume of data that is collected and transmitted. As the devices are run by small battery power, they can be quickly diminished due to the high processing requirements of the device for data collection and transmission. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data and the frequency of transmission will improve the device battery life via using inference algorithm. There is an issue of improving transmission metrics with accuracy and efficiency, which trade-off each other such as increasing accuracy reduces the efficiency. This paper demonstrates that machine learning can be used to analyze complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem using the Levenberg-Marquardt algorithm to enhance both metrics by taking fewer samples to transmit whilst maintaining the accuracy. The algorithm is tested with a standard heart rate dataset to compare the metrics. The result shows that the LMA has best performed with an efficiency of 3.33 times for reduced sample data size and accuracy of 79.17%, which has the similar accuracies in 7 different sampling cases adopted for testing but demonstrates improved efficiency. These proposed methods significantly improved both metrics using machine learning without sacrificing a metric over the other compared to the existing methods with high efficiency.
Robotic and Generative Adversarial Attacks in Offline Writer-independent Signature Verification
Apr 14, 2022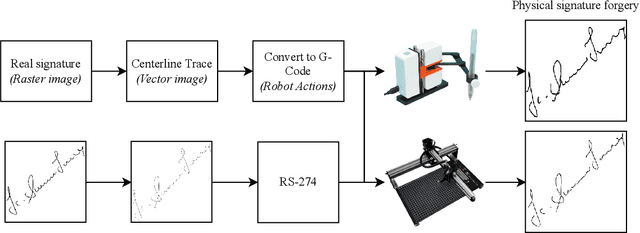
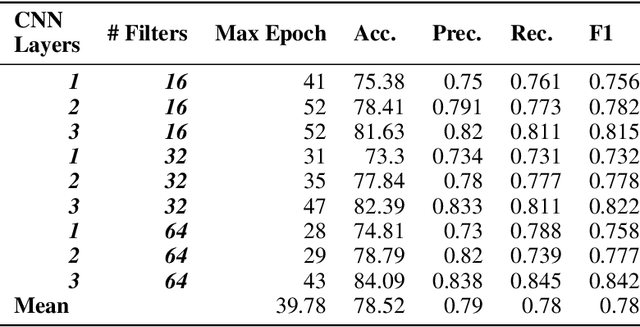

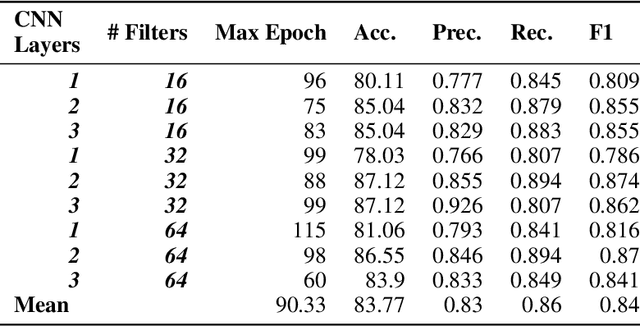
This study explores how robots and generative approaches can be used to mount successful false-acceptance adversarial attacks on signature verification systems. Initially, a convolutional neural network topology and data augmentation strategy are explored and tuned, producing an 87.12% accurate model for the verification of 2,640 human signatures. Two robots are then tasked with forging 50 signatures, where 25 are used for the verification attack, and the remaining 25 are used for tuning of the model to defend against them. Adversarial attacks on the system show that there exists an information security risk; the Line-us robotic arm can fool the system 24% of the time and the iDraw 2.0 robot 32% of the time. A conditional GAN finds similar success, with around 30% forged signatures misclassified as genuine. Following fine-tune transfer learning of robotic and generative data, adversarial attacks are reduced below the model threshold by both robots and the GAN. It is observed that tuning the model reduces the risk of attack by robots to 8% and 12%, and that conditional generative adversarial attacks can be reduced to 4% when 25 images are presented and 5% when 1000 images are presented.
Real-Time Optimized N-gram For Mobile Devices
Jan 07, 2021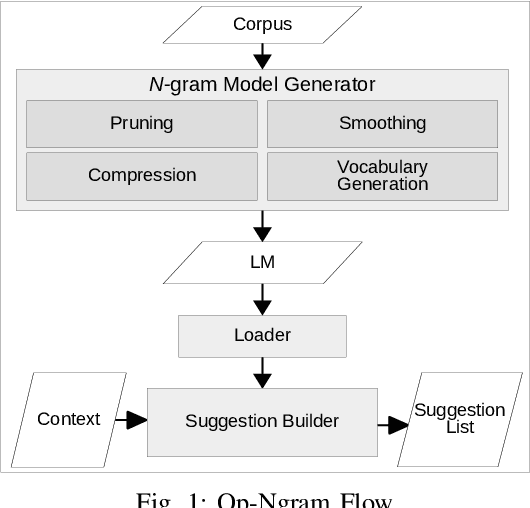
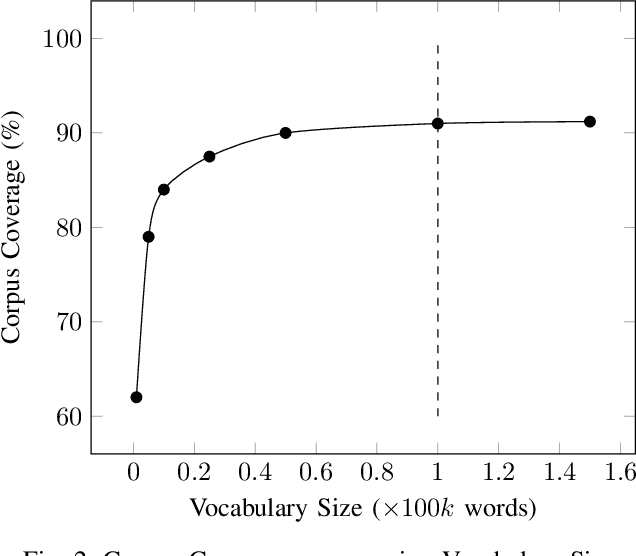
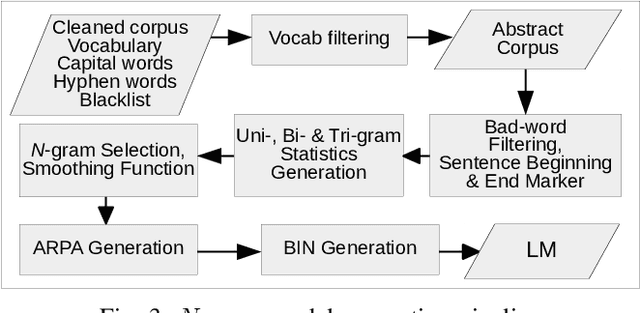

With the increasing number of mobile devices, there has been continuous research on generating optimized Language Models (LMs) for soft keyboard. In spite of advances in this domain, building a single LM for low-end feature phones as well as high-end smartphones is still a pressing need. Hence, we propose a novel technique, Optimized N-gram (Op-Ngram), an end-to-end N-gram pipeline that utilises mobile resources efficiently for faster Word Completion (WC) and Next Word Prediction (NWP). Op-Ngram applies Stupid Backoff and pruning strategies to generate a light-weight model. The LM loading time on mobile is linear with respect to model size. We observed that Op-Ngram gives 37% improvement in Language Model (LM)-ROM size, 76% in LM-RAM size, 88% in loading time and 89% in average suggestion time as compared to SORTED array variant of BerkeleyLM. Moreover, our method shows significant performance improvement over KenLM as well.
* 2019 IEEE 13th International Conference on Semantic Computing (ICSC). Accessible at https://ieeexplore.ieee.org/document/8665639
Cyber Mobility Mirror: A Deep Learning-based Real-World Object Perception Platform Using Roadside LiDAR
Apr 07, 2022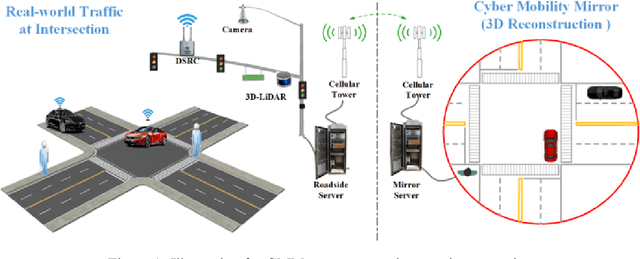
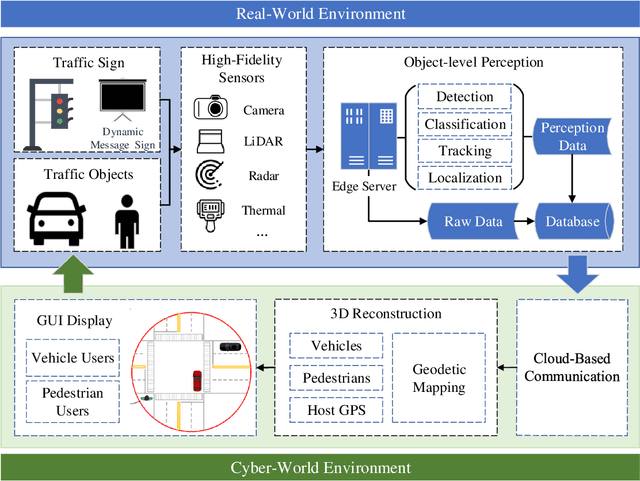
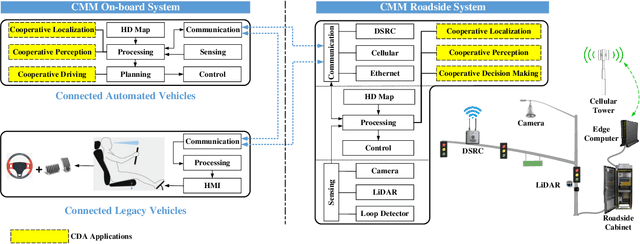
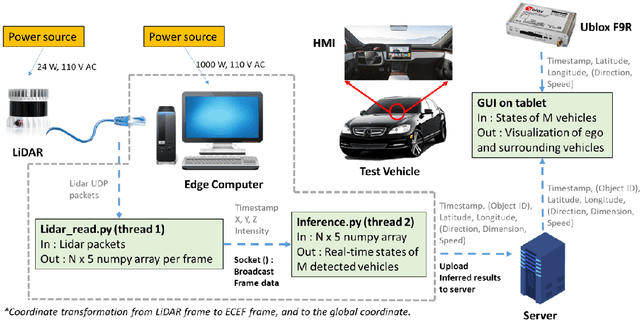
Object perception plays a fundamental role in Cooperative Driving Automation (CDA) which is regarded as a revolutionary promoter for the next-generation transportation systems. However, the vehicle-based perception may suffer from the limited sensing range and occlusion as well as low penetration rates in connectivity. In this paper, we propose Cyber Mobility Mirror (CMM), a next-generation real-time traffic surveillance system for 3D object perception and reconstruction, to explore the potential of roadside sensors for enabling CDA in the real world. The CMM system consists of six main components: 1) the data pre-processor to retrieve and preprocess the raw data; 2) the roadside 3D object detector to generate 3D detection results; 3) the multi-object tracker to identify detected objects; 4) the global locator to map positioning information from the LiDAR coordinate to geographic coordinate using coordinate transformation; 5) the cloud-based communicator to transmit perception information from roadside sensors to equipped vehicles, and 6) the onboard advisor to reconstruct and display the real-time traffic conditions via Graphical User Interface (GUI). In this study, a field-operational system is deployed at a real-world intersection, University Avenue and Iowa Avenue in Riverside, California to assess the feasibility and performance of our CMM system. Results from field tests demonstrate that our CMM prototype system can provide satisfactory perception performance with 96.99% precision and 83.62% recall. High-fidelity real-time traffic conditions (at the object level) can be geo-localized with an average error of 0.14m and displayed on the GUI of the equipped vehicle with a frequency of 3-4 Hz.
Video Prediction at Multiple Scales with Hierarchical Recurrent Networks
Mar 17, 2022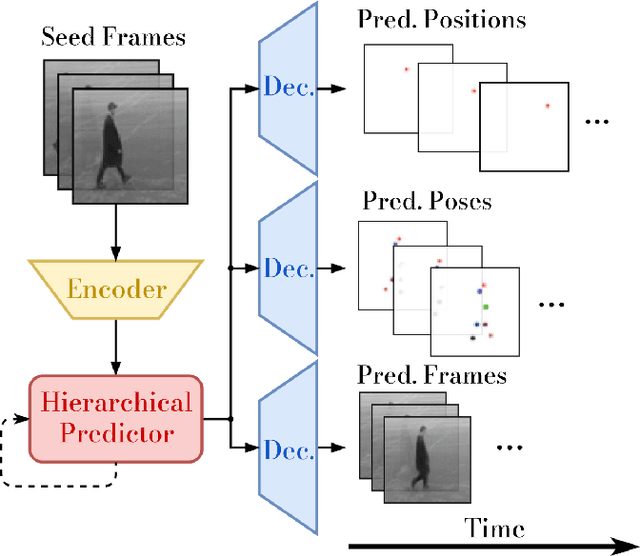
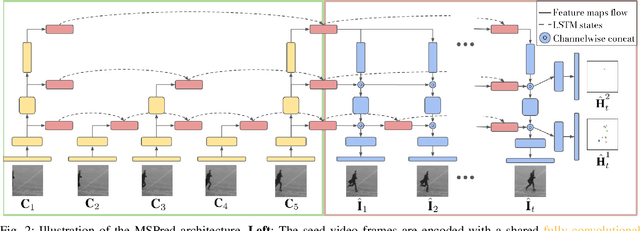


Autonomous systems not only need to understand their current environment, but should also be able to predict future actions conditioned on past states, for instance based on captured camera frames. For certain tasks, detailed predictions such as future video frames are required in the near future, whereas for others it is beneficial to also predict more abstract representations for longer time horizons. However, existing video prediction models mainly focus on forecasting detailed possible outcomes for short time-horizons, hence being of limited use for robot perception and spatial reasoning. We propose Multi-Scale Hierarchical Prediction (MSPred), a novel video prediction model able to forecast future possible outcomes of different levels of granularity at different time-scales simultaneously. By combining spatial and temporal downsampling, MSPred is able to efficiently predict abstract representations such as human poses or object locations over long time horizons, while still maintaining a competitive performance for video frame prediction. In our experiments, we demonstrate that our proposed model accurately predicts future video frames as well as other representations (e.g. keypoints or positions) on various scenarios, including bin-picking scenes or action recognition datasets, consistently outperforming popular approaches for video frame prediction. Furthermore, we conduct an ablation study to investigate the importance of the different modules and design choices in MSPred. In the spirit of reproducible research, we open-source VP-Suite, a general framework for deep-learning-based video prediction, as well as pretrained models to reproduce our results.
Who will stay? Using Deep Learning to predict engagement of citizen scientists
Apr 28, 2022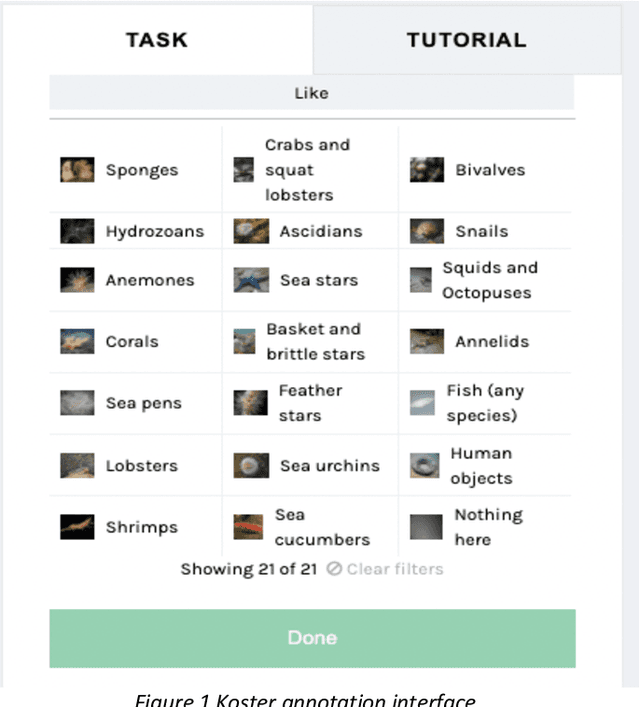
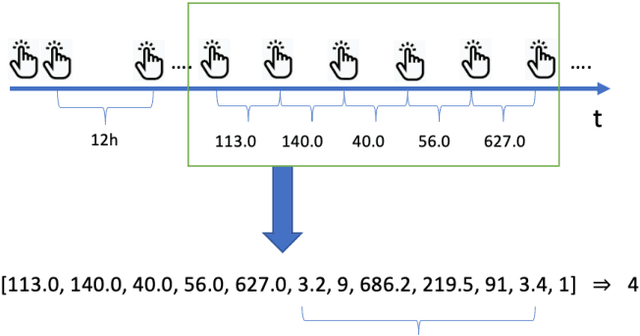
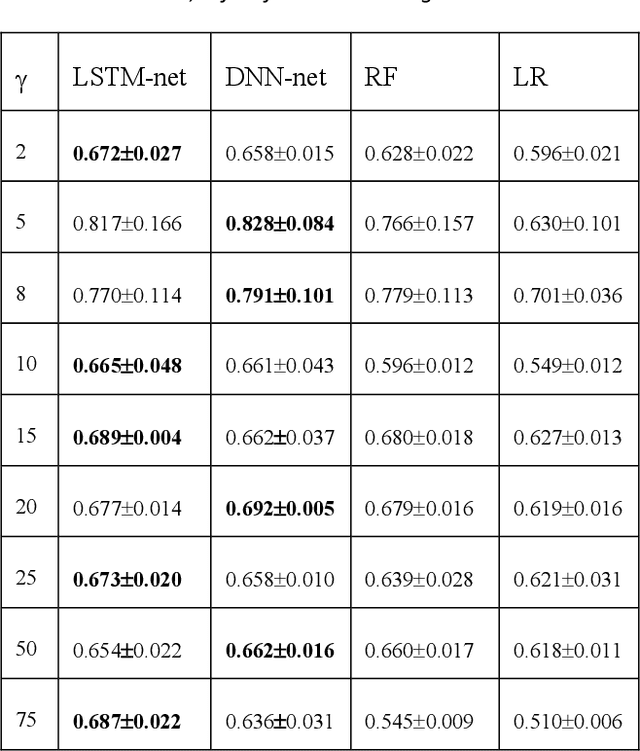
Citizen science and machine learning should be considered for monitoring the coastal and ocean environment due to the scale of threats posed by climate change and the limited resources to fill knowledge gaps. Using data from the annotation activity of citizen scientists in a Swedish marine project, we constructed Deep Neural Network models to predict forthcoming engagement. We tested the models to identify patterns in annotation engagement. Based on the results, it is possible to predict whether an annotator will remain active in future sessions. Depending on the goals of individual citizen science projects, it may also be necessary to identify either those volunteers who will leave or those who will continue annotating. This can be predicted by varying the threshold for the prediction. The engagement metrics used to construct the models are based on time and activity and can be used to infer latent characteristics of volunteers and predict their task interest based on their activity patterns. They can estimate if volunteers can accomplish a given number of tasks in a certain amount of time, identify early on who is likely to become a top contributor or identify who is likely to quit and provide them with targeted interventions. The novelty of our predictive models lies in the use of Deep Neural Networks and the sequence of volunteer annotations. A limitation of our models is that they do not use embeddings constructed from user profiles as input data, as many recommender systems do. We expect that including user profiles would improve prediction performance.
Making SGD Parameter-Free
May 04, 2022We develop an algorithm for parameter-free stochastic convex optimization (SCO) whose rate of convergence is only a double-logarithmic factor larger than the optimal rate for the corresponding known-parameter setting. In contrast, the best previously known rates for parameter-free SCO are based on online parameter-free regret bounds, which contain unavoidable excess logarithmic terms compared to their known-parameter counterparts. Our algorithm is conceptually simple, has high-probability guarantees, and is also partially adaptive to unknown gradient norms, smoothness, and strong convexity. At the heart of our results is a novel parameter-free certificate for SGD step size choice, and a time-uniform concentration result that assumes no a-priori bounds on SGD iterates.
Small Object Detection for Near Real-Time Egocentric Perception in a Manual Assembly Scenario
Jun 11, 2021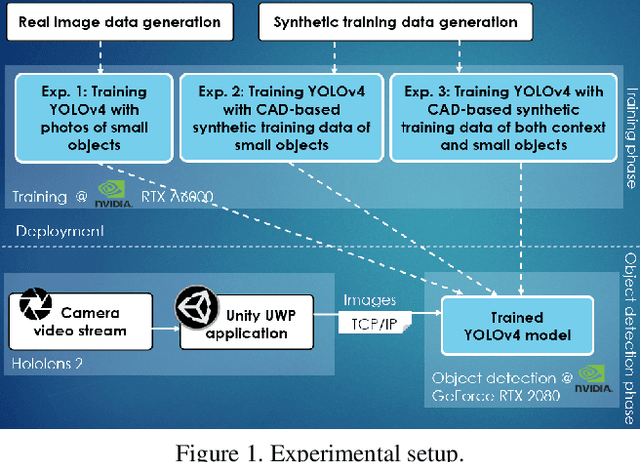
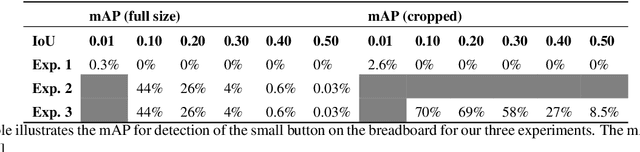
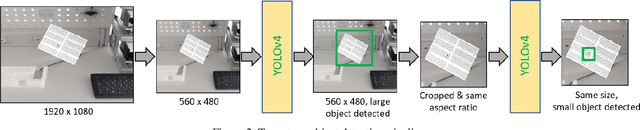

Detecting small objects in video streams of head-worn augmented reality devices in near real-time is a huge challenge: training data is typically scarce, the input video stream can be of limited quality, and small objects are notoriously hard to detect. In industrial scenarios, however, it is often possible to leverage contextual knowledge for the detection of small objects. Furthermore, CAD data of objects are typically available and can be used to generate synthetic training data. We describe a near real-time small object detection pipeline for egocentric perception in a manual assembly scenario: We generate a training data set based on CAD data and realistic backgrounds in Unity. We then train a YOLOv4 model for a two-stage detection process: First, the context is recognized, then the small object of interest is detected. We evaluate our pipeline on the augmented reality device Microsoft Hololens 2.