 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Spatial-Temporal Attention Multi-Graph Convolution Network for Ride-Hailing Demand Prediction Based on Periodicity with Offset
Apr 08, 2022
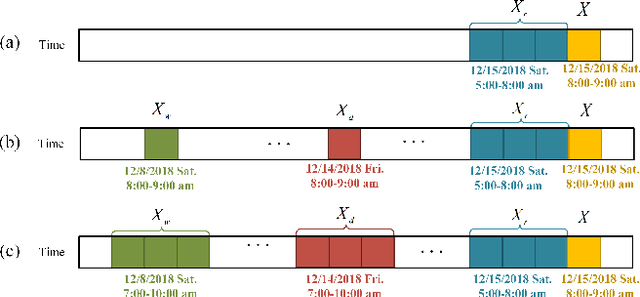
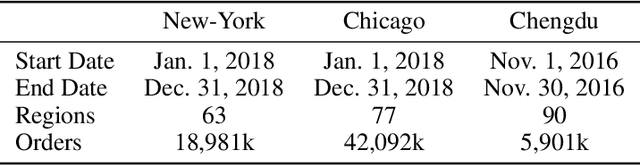
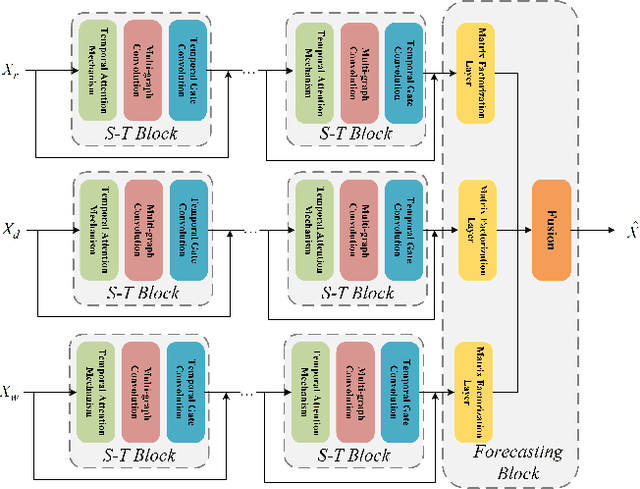
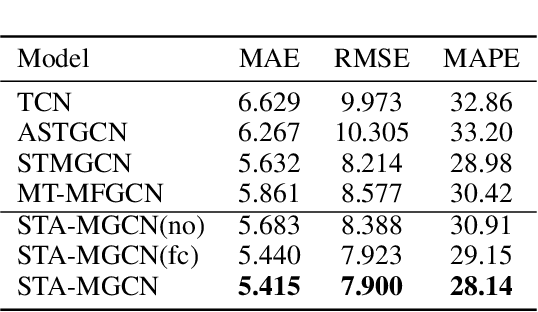
Ride-hailing service is becoming a leading part in urban transportation. To improve the efficiency of ride-hailing service, accurate prediction of transportation demand is a fundamental challenge. In this paper, we tackle this problem from both aspects of network structure and data-set formulation. For network design, we propose a spatial-temporal attention multi-graph convolution network (STA-MGCN). A spatial-temporal layer in STA-MGCN is developed to capture the temporal correlations by temporal attention mechanism and temporal gate convolution, and the spatial correlations by multigraph convolution. A feature cluster layer is introduced to learn latent regional functions and to reduce the computation burden. For the data-set formulation, we develop a novel approach which considers the transportation feature of periodicity with offset. Instead of only using history data during the same time period, the history order demand in forward and backward neighboring time periods from yesterday and last week are also included. Extensive experiments on the three real-world datasets of New-York, Chicago and Chengdu show that the proposed algorithm achieves the state-of-the-art performance for ride-hailing demand prediction.
Efficient Architecture Search for Diverse Tasks
Apr 15, 2022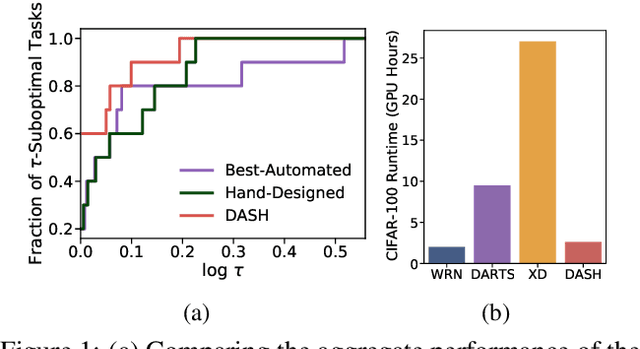

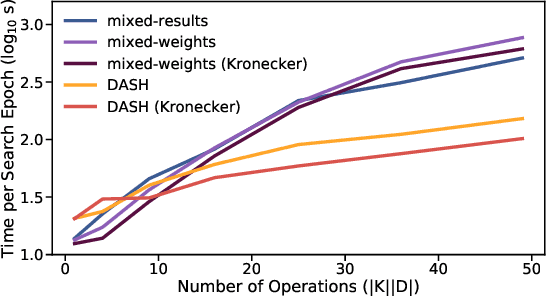
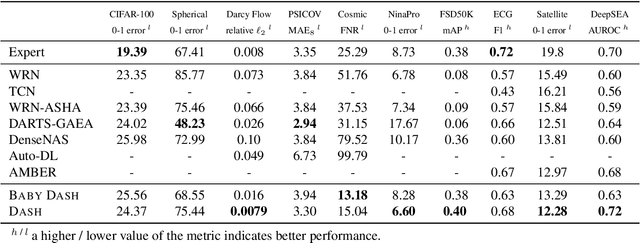
While neural architecture search (NAS) has enabled automated machine learning (AutoML) for well-researched areas, its application to tasks beyond computer vision is still under-explored. As less-studied domains are precisely those where we expect AutoML to have the greatest impact, in this work we study NAS for efficiently solving diverse problems. Seeking an approach that is fast, simple, and broadly applicable, we fix a standard convolutional network (CNN) topology and propose to search for the right kernel sizes and dilations its operations should take on. This dramatically expands the model's capacity to extract features at multiple resolutions for different types of data while only requiring search over the operation space. To overcome the efficiency challenges of naive weight-sharing in this search space, we introduce DASH, a differentiable NAS algorithm that computes the mixture-of-operations using the Fourier diagonalization of convolution, achieving both a better asymptotic complexity and an up-to-10x search time speedup in practice. We evaluate DASH on NAS-Bench-360, a suite of ten tasks designed for benchmarking NAS in diverse domains. DASH outperforms state-of-the-art methods in aggregate, attaining the best-known automated performance on seven tasks. Meanwhile, on six of the ten tasks, the combined search and retraining time is less than 2x slower than simply training a CNN backbone that is far less accurate.
Extrinsic Calibration and Verification of Multiple Non-overlapping Field of View Lidar Sensors
May 14, 2022



We demonstrate a multi-lidar calibration framework for large mobile platforms that jointly calibrate the extrinsic parameters of non-overlapping Field-of-View (FoV) lidar sensors, without the need for any external calibration aid. The method starts by estimating the pose of each lidar in its corresponding sensor frame in between subsequent timestamps. Since the pose estimates from the lidars are not necessarily synchronous, we first align the poses using a Dual Quaternion (DQ) based Screw Linear Interpolation. Afterward, a Hand-Eye based calibration problem is solved using the DQ-based formulation to recover the extrinsics. Furthermore, we verify the extrinsics by matching chosen lidar semantic features, obtained by projecting the lidar data into the camera perspective after time alignment using vehicle kinematics. Experimental results on the data collected from a Scania vehicle [$\sim$ 1 Km sequence] demonstrate the ability of our approach to obtain better calibration parameters than the provided vehicle CAD model calibration parameters. This setup can also be scaled to any combination of multiple lidars.
Lifelong Personal Context Recognition
May 10, 2022
We focus on the development of AIs which live in lifelong symbiosis with a human. The key prerequisite for this task is that the AI understands - at any moment in time - the personal situational context that the human is in. We outline the key challenges that this task brings forth, namely (i) handling the human-like and ego-centric nature of the the user's context, necessary for understanding and providing useful suggestions, (ii) performing lifelong context recognition using machine learning in a way that is robust to change, and (iii) maintaining alignment between the AI's and human's representations of the world through continual bidirectional interaction. In this short paper, we summarize our recent attempts at tackling these challenges, discuss the lessons learned, and highlight directions of future research. The main take-away message is that pursuing this project requires research which lies at the intersection of knowledge representation and machine learning. Neither technology can achieve this goal without the other.
Transformer based multiple instance learning for weakly supervised histopathology image segmentation
May 18, 2022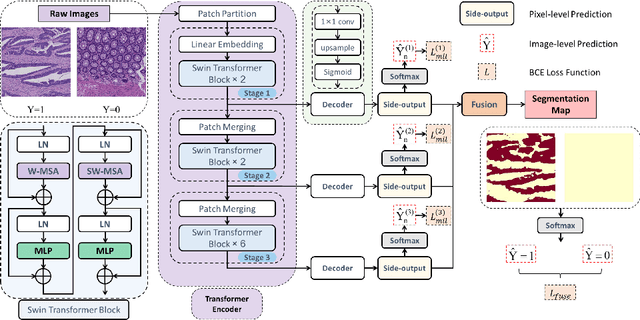
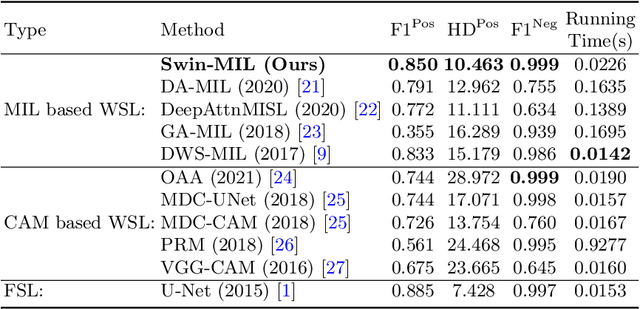
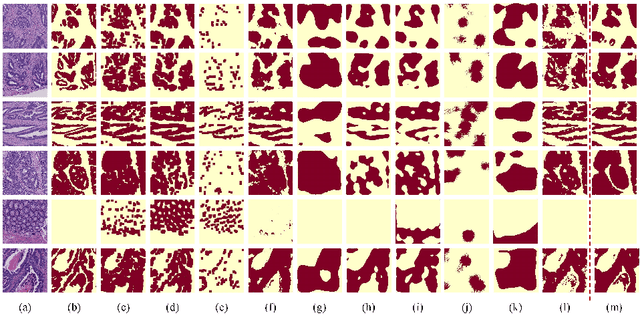
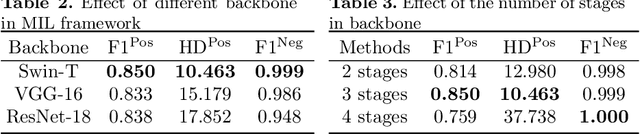
Hispathological image segmentation algorithms play a critical role in computer aided diagnosis technology. The development of weakly supervised segmentation algorithm alleviates the problem of medical image annotation that it is time-consuming and labor-intensive. As a subset of weakly supervised learning, Multiple Instance Learning (MIL) has been proven to be effective in segmentation. However, there is a lack of related information between instances in MIL, which limits the further improvement of segmentation performance. In this paper, we propose a novel weakly supervised method for pixel-level segmentation in histopathology images, which introduces Transformer into the MIL framework to capture global or long-range dependencies. The multi-head self-attention in the Transformer establishes the relationship between instances, which solves the shortcoming that instances are independent of each other in MIL. In addition, deep supervision is introduced to overcome the limitation of annotations in weakly supervised methods and make the better utilization of hierarchical information. The state-of-the-art results on the colon cancer dataset demonstrate the superiority of the proposed method compared with other weakly supervised methods. It is worth believing that there is a potential of our approach for various applications in medical images.
Dynamic Network-Code Design for Satellite Networks
Apr 04, 2022
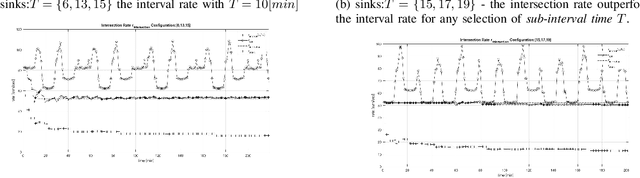

Internet access from space enjoys renaissance as satellites in Mega-Constellations is no longer fictitious. Network capacity, subject to power and computational complexity constraints among other challenges, is a major goal in this type of networks. This work studies Network Coding in the presence of dynamically changing network conditions. The notion of generalized acyclic network is introduced and employed for promoting the generation of linear-multicast network code for what is considered to be a cyclic network. The performance of several network coding schemes, among these is the known static network code, is evaluated by a STK simulation for a swarm of communicating satellites, conceptually based on the Iridium system. Exploiting the prior knowledge of the networks topology over time, new network coding approaches are described, whose aim is to better cope with the time-varying, dynamic behavior of the network. It is demonstrated that in all cases, pertaining to our example network, static network codes under-perform compared to the presented approach. In addition, an efficient test for identifying the most appropriate coding approach is presented.
The Complexity of Markov Equilibrium in Stochastic Games
Apr 08, 2022
We show that computing approximate stationary Markov coarse correlated equilibria (CCE) in general-sum stochastic games is computationally intractable, even when there are two players, the game is turn-based, the discount factor is an absolute constant, and the approximation is an absolute constant. Our intractability results stand in sharp contrast to normal-form games where exact CCEs are efficiently computable. A fortiori, our results imply that there are no efficient algorithms for learning stationary Markov CCE policies in multi-agent reinforcement learning (MARL), even when the interaction is two-player and turn-based, and both the discount factor and the desired approximation of the learned policies is an absolute constant. In turn, these results stand in sharp contrast to single-agent reinforcement learning (RL) where near-optimal stationary Markov policies can be efficiently learned. Complementing our intractability results for stationary Markov CCEs, we provide a decentralized algorithm (assuming shared randomness among players) for learning a nonstationary Markov CCE policy with polynomial time and sample complexity in all problem parameters. Previous work for learning Markov CCE policies all required exponential time and sample complexity in the number of players.
Reinforcement Learning for Branch-and-Bound Optimisation using Retrospective Trajectories
May 28, 2022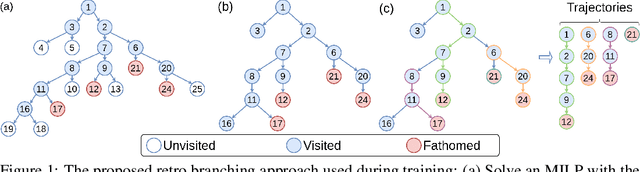
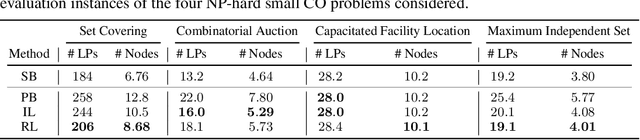
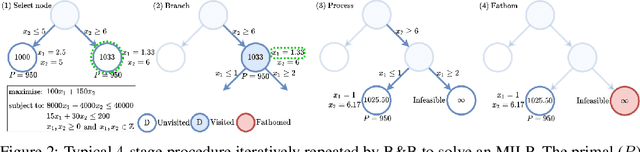
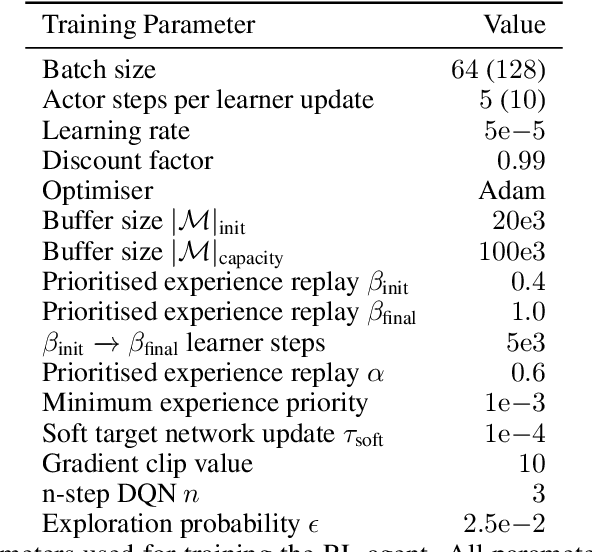
Combinatorial optimisation problems framed as mixed integer linear programmes (MILPs) are ubiquitous across a range of real-world applications. The canonical branch-and-bound (B&B) algorithm seeks to exactly solve MILPs by constructing a search tree of increasingly constrained sub-problems. In practice, its solving time performance is dependent on heuristics, such as the choice of the next variable to constrain ('branching'). Recently, machine learning (ML) has emerged as a promising paradigm for branching. However, prior works have struggled to apply reinforcement learning (RL), citing sparse rewards, difficult exploration, and partial observability as significant challenges. Instead, leading ML methodologies resort to approximating high quality handcrafted heuristics with imitation learning (IL), which precludes the discovery of novel policies and requires expensive data labelling. In this work, we propose retro branching; a simple yet effective approach to RL for branching. By retrospectively deconstructing the search tree into multiple paths each contained within a sub-tree, we enable the agent to learn from shorter trajectories with more predictable next states. In experiments on four combinatorial tasks, our approach enables learning-to-branch without any expert guidance or pre-training. We outperform the current state-of-the-art RL branching algorithm by 3-5x and come within 20% of the best IL method's performance on MILPs with 500 constraints and 1000 variables, with ablations verifying that our retrospectively constructed trajectories are essential to achieving these results.
Statistical-Computational Trade-offs in Tensor PCA and Related Problems via Communication Complexity
Apr 15, 2022
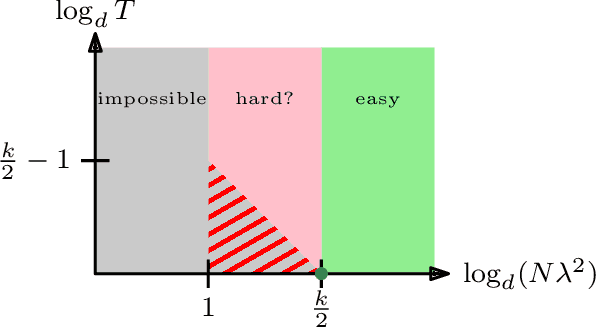
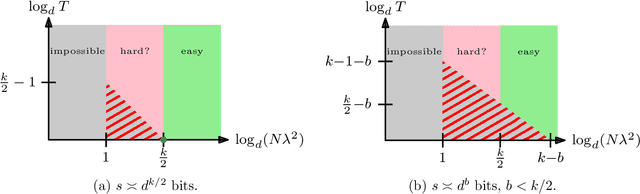

Tensor PCA is a stylized statistical inference problem introduced by Montanari and Richard to study the computational difficulty of estimating an unknown parameter from higher-order moment tensors. Unlike its matrix counterpart, Tensor PCA exhibits a statistical-computational gap, i.e., a sample size regime where the problem is information-theoretically solvable but conjectured to be computationally hard. This paper derives computational lower bounds on the run-time of memory bounded algorithms for Tensor PCA using communication complexity. These lower bounds specify a trade-off among the number of passes through the data sample, the sample size, and the memory required by any algorithm that successfully solves Tensor PCA. While the lower bounds do not rule out polynomial-time algorithms, they do imply that many commonly-used algorithms, such as gradient descent and power method, must have a higher iteration count when the sample size is not large enough. Similar lower bounds are obtained for Non-Gaussian Component Analysis, a family of statistical estimation problems in which low-order moment tensors carry no information about the unknown parameter. Finally, stronger lower bounds are obtained for an asymmetric variant of Tensor PCA and related statistical estimation problems. These results explain why many estimators for these problems use a memory state that is significantly larger than the effective dimensionality of the parameter of interest.
An optimized hybrid solution for IoT based lifestyle disease classification using stress data
Apr 04, 2022



Stress, anxiety, and nervousness are all high-risk health states in everyday life. Previously, stress levels were determined by speaking with people and gaining insight into what they had experienced recently or in the past. Typically, stress is caused by an incidence that occurred a long time ago, but sometimes it is triggered by unknown factors. This is a challenging and complex task, but recent research advances have provided numerous opportunities to automate it. The fundamental features of most of these techniques are electro dermal activity (EDA) and heart rate values (HRV). We utilized an accelerometer to measure body motions to solve this challenge. The proposed novel method employs a test that measures a subject's electrocardiogram (ECG), galvanic skin values (GSV), HRV values, and body movements in order to provide a low-cost and time-saving solution for detecting stress lifestyle disease in modern times using cyber physical systems. This study provides a new hybrid model for lifestyle disease classification that decreases execution time while picking the best collection of characteristics and increases classification accuracy. The developed approach is capable of dealing with the class imbalance problem by using WESAD (wearable stress and affect dataset) dataset. The new model uses the Grid search (GS) method to select an optimized set of hyper parameters, and it uses a combination of the Correlation coefficient based Recursive feature elimination (CoC-RFE) method for optimal feature selection and gradient boosting as an estimator to classify the dataset, which achieves high accuracy and helps to provide smart, accurate, and high-quality healthcare systems. To demonstrate the validity and utility of the proposed methodology, its performance is compared to those of other well-established machine learning models.