 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stable Online Control of Linear Time-Varying Systems
Apr 30, 2021

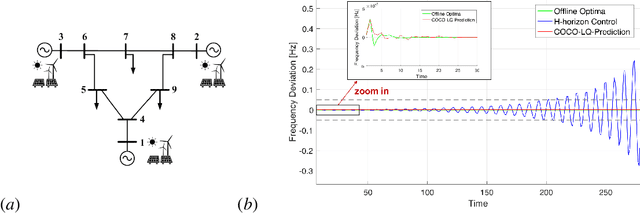

Linear time-varying (LTV) systems are widely used for modeling real-world dynamical systems due to their generality and simplicity. Providing stability guarantees for LTV systems is one of the central problems in control theory. However, existing approaches that guarantee stability typically lead to significantly sub-optimal cumulative control cost in online settings where only current or short-term system information is available. In this work, we propose an efficient online control algorithm, COvariance Constrained Online Linear Quadratic (COCO-LQ) control, that guarantees input-to-state stability for a large class of LTV systems while also minimizing the control cost. The proposed method incorporates a state covariance constraint into the semi-definite programming (SDP) formulation of the LQ optimal controller. We empirically demonstrate the performance of COCO-LQ in both synthetic experiments and a power system frequency control example.
TreEnhance: An Automatic Tree-Search Based Method for Low-Light Image Enhancement
May 25, 2022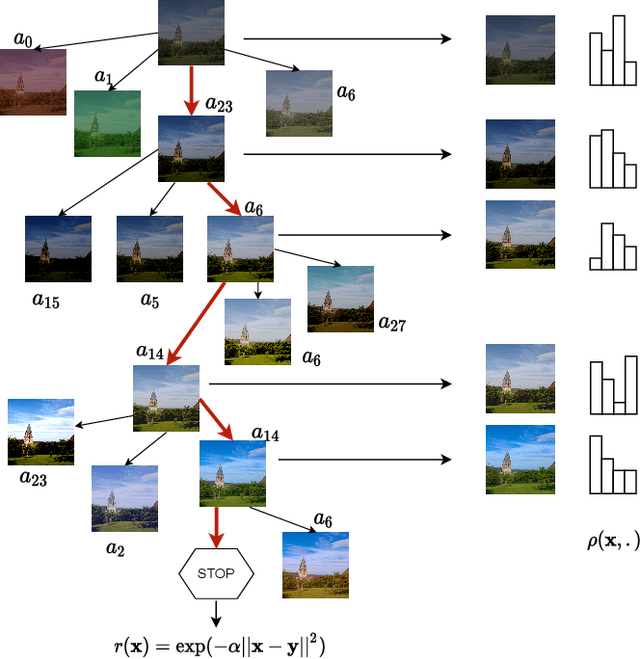
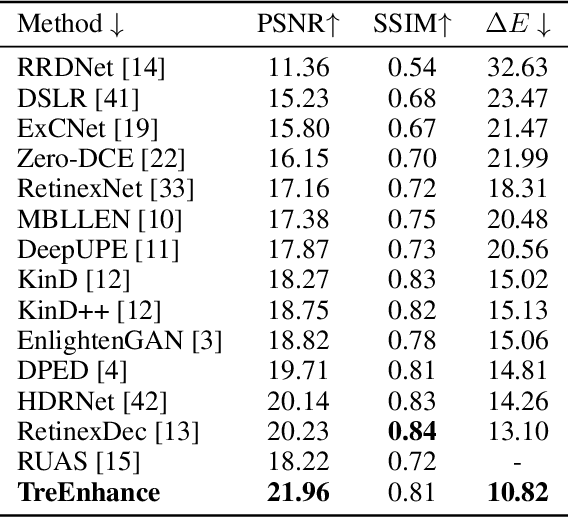
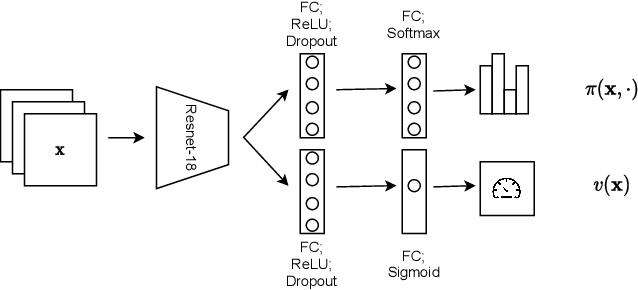
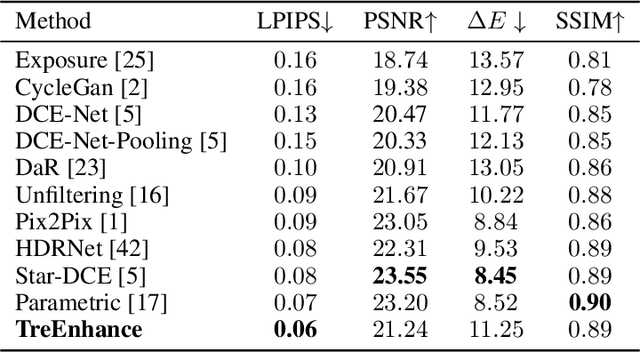
In this paper we present TreEnhance, an automatic method for low-light image enhancement capable of improving the quality of digital images. The method combines tree search theory, and in particular the Monte Carlo Tree Search (MCTS) algorithm, with deep reinforcement learning. Given as input a low-light image, TreEnhance produces as output its enhanced version together with the sequence of image editing operations used to obtain it. The method repeatedly alternates two main phases. In the generation phase a modified version of MCTS explores the space of image editing operations and selects the most promising sequence. In the optimization phase the parameters of a neural network, implementing the enhancement policy, are updated. After training, two different inference solutions are proposed for the enhancement of new images: one is based on MCTS and is more accurate but more time and memory consuming; the other directly applies the learned policy and is faster but slightly less precise. Unlike other methods from the state of the art, TreEnhance does not pose any constraint on the image resolution and can be used in a variety of scenarios with minimal tuning. We tested the method on two datasets: the Low-Light dataset and the Adobe Five-K dataset obtaining good results from both a qualitative and a quantitative point of view.
Neural Implicit Flow: a mesh-agnostic dimensionality reduction paradigm of spatio-temporal data
Apr 08, 2022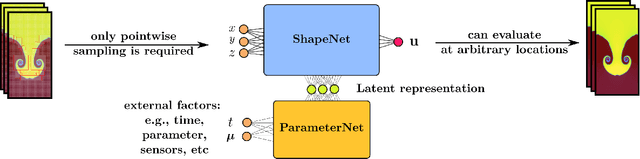

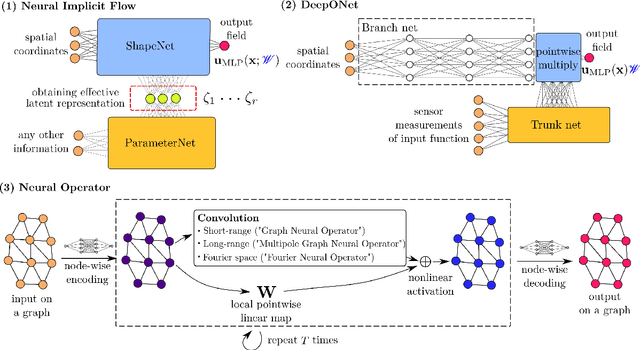
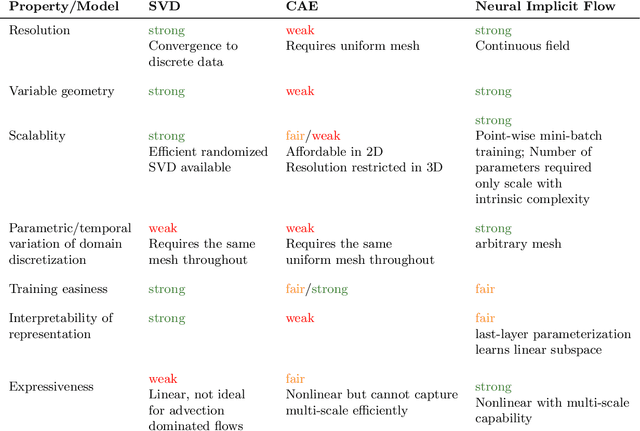
High-dimensional spatio-temporal dynamics can often be encoded in a low-dimensional subspace. Engineering applications for modeling, characterization, design, and control of such large-scale systems often rely on dimensionality reduction to make solutions computationally tractable in real-time. Common existing paradigms for dimensionality reduction include linear methods, such as the singular value decomposition (SVD), and nonlinear methods, such as variants of convolutional autoencoders (CAE). However, these encoding techniques lack the ability to efficiently represent the complexity associated with spatio-temporal data, which often requires variable geometry, non-uniform grid resolution, adaptive meshing, and/or parametric dependencies. To resolve these practical engineering challenges, we propose a general framework called Neural Implicit Flow (NIF) that enables a mesh-agnostic, low-rank representation of large-scale, parametric, spatial-temporal data. NIF consists of two modified multilayer perceptrons (MLPs): (i) ShapeNet, which isolates and represents the spatial complexity, and (ii) ParameterNet, which accounts for any other input complexity, including parametric dependencies, time, and sensor measurements. We demonstrate the utility of NIF for parametric surrogate modeling, enabling the interpretable representation and compression of complex spatio-temporal dynamics, efficient many-spatial-query tasks, and improved generalization performance for sparse reconstruction.
Primitive3D: 3D Object Dataset Synthesis from Randomly Assembled Primitives
May 25, 2022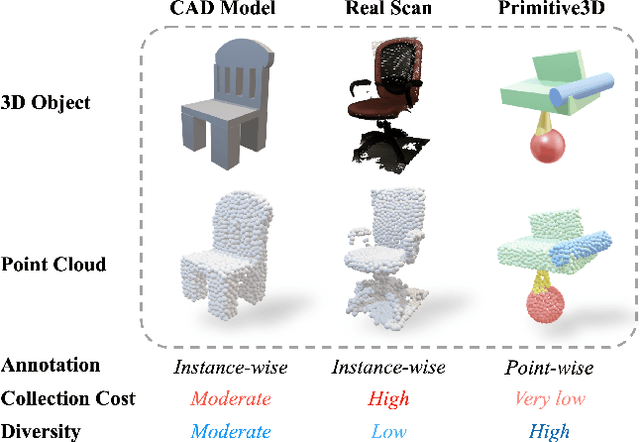

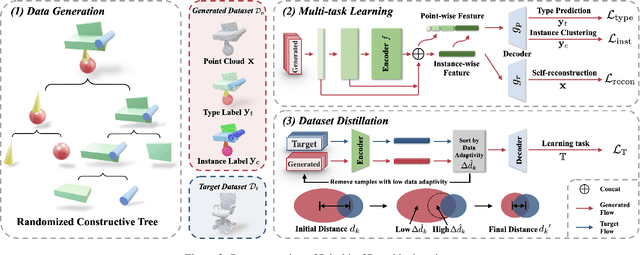
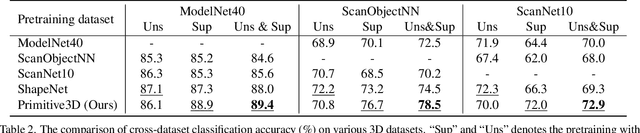
Numerous advancements in deep learning can be attributed to the access to large-scale and well-annotated datasets. However, such a dataset is prohibitively expensive in 3D computer vision due to the substantial collection cost. To alleviate this issue, we propose a cost-effective method for automatically generating a large amount of 3D objects with annotations. In particular, we synthesize objects simply by assembling multiple random primitives. These objects are thus auto-annotated with part labels originating from primitives. This allows us to perform multi-task learning by combining the supervised segmentation with unsupervised reconstruction. Considering the large overhead of learning on the generated dataset, we further propose a dataset distillation strategy to remove redundant samples regarding a target dataset. We conduct extensive experiments for the downstream tasks of 3D object classification. The results indicate that our dataset, together with multi-task pretraining on its annotations, achieves the best performance compared to other commonly used datasets. Further study suggests that our strategy can improve the model performance by pretraining and fine-tuning scheme, especially for the dataset with a small scale. In addition, pretraining with the proposed dataset distillation method can save 86\% of the pretraining time with negligible performance degradation. We expect that our attempt provides a new data-centric perspective for training 3D deep models.
Secure and Private Source Coding with Private Key and Decoder Side Information
May 10, 2022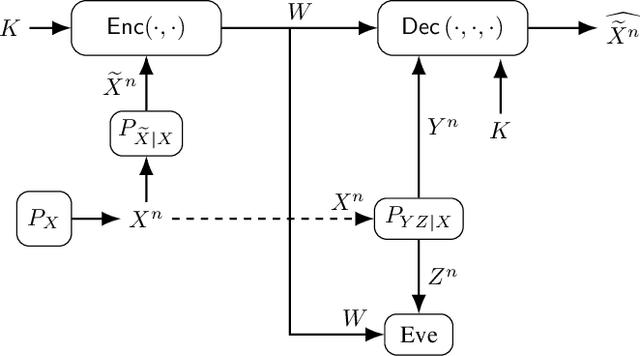
The problem of secure source coding with multiple terminals is extended by considering a remote source whose noisy measurements are the correlated random variables used for secure source reconstruction. The main additions to the problem include 1) all terminals noncausally observe a noisy measurement of the remote source; 2) a private key is available to all legitimate terminals; 3) the public communication link between the encoder and decoder is rate-limited; 4) the secrecy leakage to the eavesdropper is measured with respect to the encoder input, whereas the privacy leakage is measured with respect to the remote source. Exact rate regions are characterized for a lossy source coding problem with a private key, remote source, and decoder side information under security, privacy, communication, and distortion constraints. By replacing the distortion constraint with a reliability constraint, we obtain the exact rate region also for the lossless case. Furthermore, the lossy rate region for scalar discrete-time Gaussian sources and measurement channels is established.
Location-free Human Pose Estimation
May 25, 2022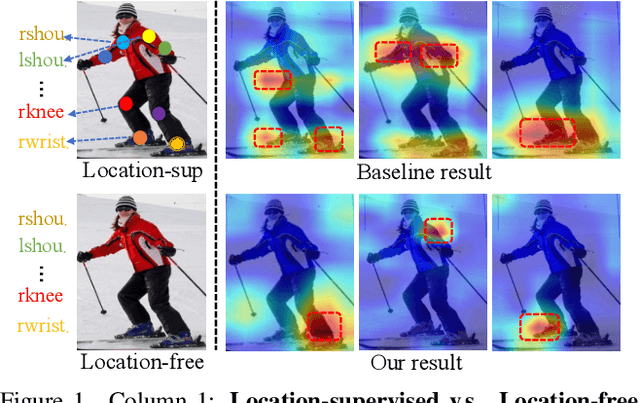
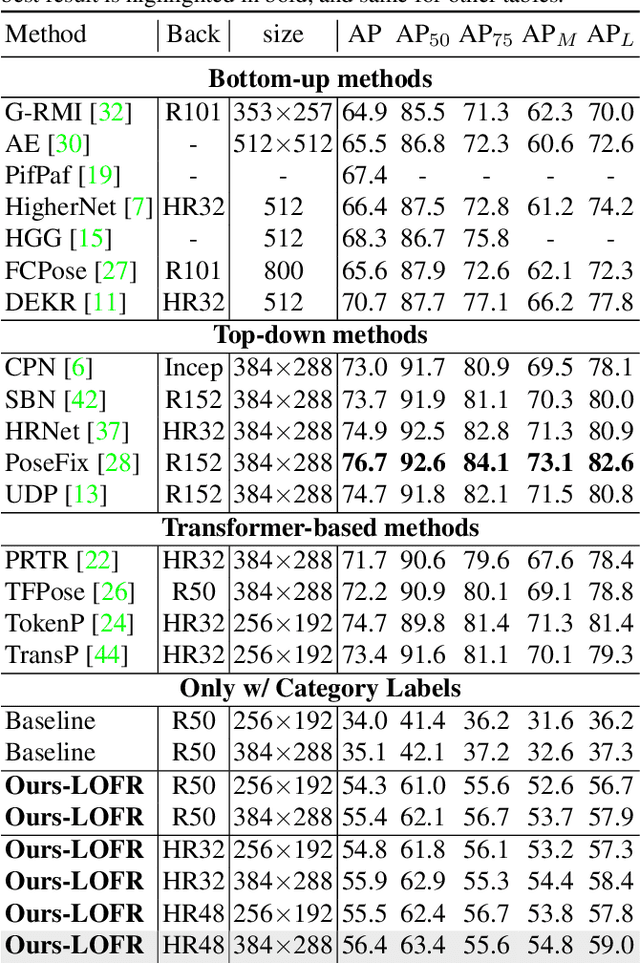
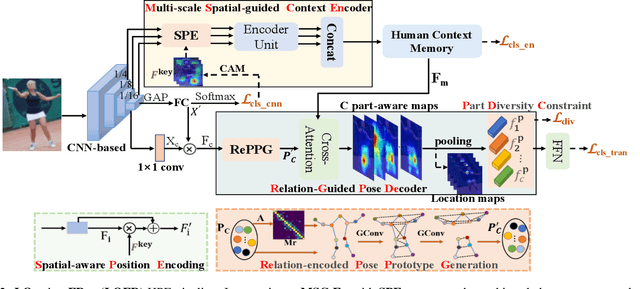
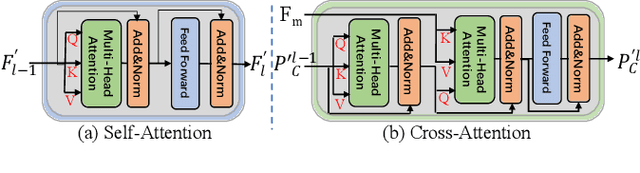
Human pose estimation (HPE) usually requires large-scale training data to reach high performance. However, it is rather time-consuming to collect high-quality and fine-grained annotations for human body. To alleviate this issue, we revisit HPE and propose a location-free framework without supervision of keypoint locations. We reformulate the regression-based HPE from the perspective of classification. Inspired by the CAM-based weakly-supervised object localization, we observe that the coarse keypoint locations can be acquired through the part-aware CAMs but unsatisfactory due to the gap between the fine-grained HPE and the object-level localization. To this end, we propose a customized transformer framework to mine the fine-grained representation of human context, equipped with the structural relation to capture subtle differences among keypoints. Concretely, we design a Multi-scale Spatial-guided Context Encoder to fully capture the global human context while focusing on the part-aware regions and a Relation-encoded Pose Prototype Generation module to encode the structural relations. All these works together for strengthening the weak supervision from image-level category labels on locations. Our model achieves competitive performance on three datasets when only supervised at a category-level and importantly, it can achieve comparable results with fully-supervised methods with only 25\% location labels on MS-COCO and MPII.
On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
Jun 02, 2021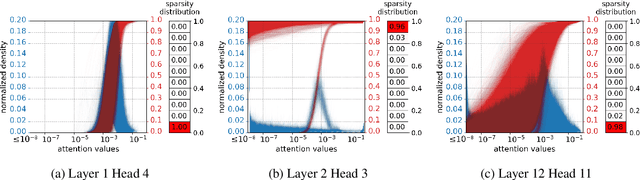
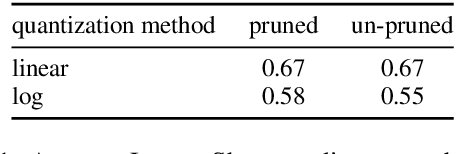
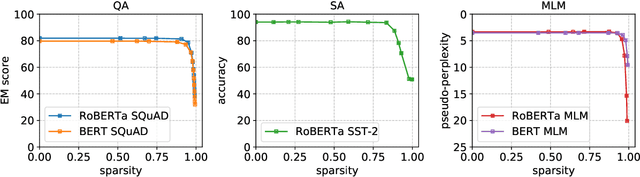
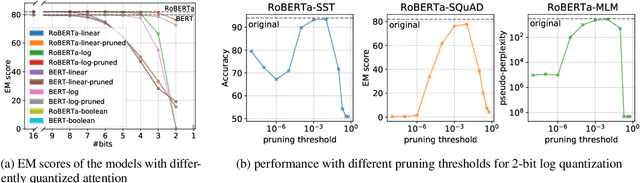
How much information do NLP tasks really need from a transformer's attention mechanism at application-time (inference)? From recent work, we know that there is sparsity in transformers and that the floating-points within its computation can be discretized to fewer values with minimal loss to task accuracies. However, this requires retraining or even creating entirely new models, both of which can be expensive and carbon-emitting. Focused on optimizations that do not require training, we systematically study the full range of typical attention values necessary. This informs the design of an inference-time quantization technique using both pruning and log-scaled mapping which produces only a few (e.g. $2^3$) unique values. Over the tasks of question answering and sentiment analysis, we find nearly 80% of attention values can be pruned to zeros with minimal ($< 1.0\%$) relative loss in accuracy. We use this pruning technique in conjunction with quantizing the attention values to only a 3-bit format, without retraining, resulting in only a 0.8% accuracy reduction on question answering with fine-tuned RoBERTa.
GWA: A Large High-Quality Acoustic Dataset for Audio Processing
Apr 04, 2022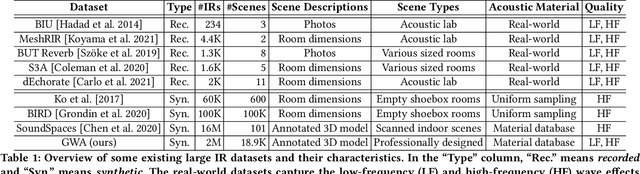
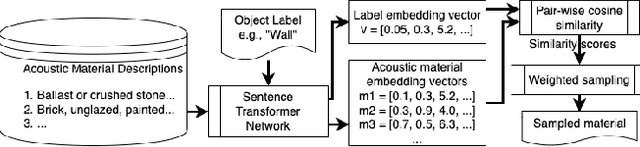

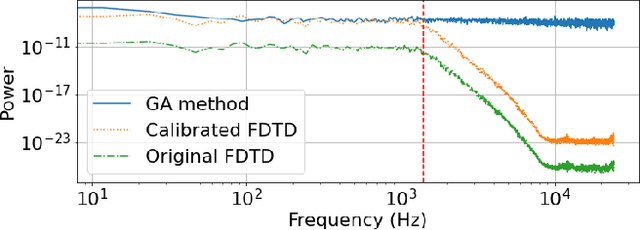
We present the Geometric-Wave Acoustic (GWA) dataset, a large-scale audio dataset of over 2 million synthetic room impulse responses (IRs) and their corresponding detailed geometric and simulation configurations. Our dataset samples acoustic environments from over 6.8K high-quality diverse and professionally designed houses represented as semantically labeled 3D meshes. We also present a novel real-world acoustic materials assignment scheme based on semantic matching that uses a sentence transformer model. We compute high-quality impulse responses corresponding to accurate low-frequency and high-frequency wave effects by automatically calibrating geometric acoustic ray-tracing with a finite-difference time-domain wave solver. We demonstrate the higher accuracy of our IRs by comparing with recorded IRs from complex real-world environments. The code and the full dataset will be released at the time of publication. Moreover, we highlight the benefits of GWA on audio deep learning tasks such as automated speech recognition, speech enhancement, and speech separation. We observe significant improvement over prior synthetic IR datasets in all tasks due to using our dataset.
Learning Latent Causal Dynamics
Feb 23, 2022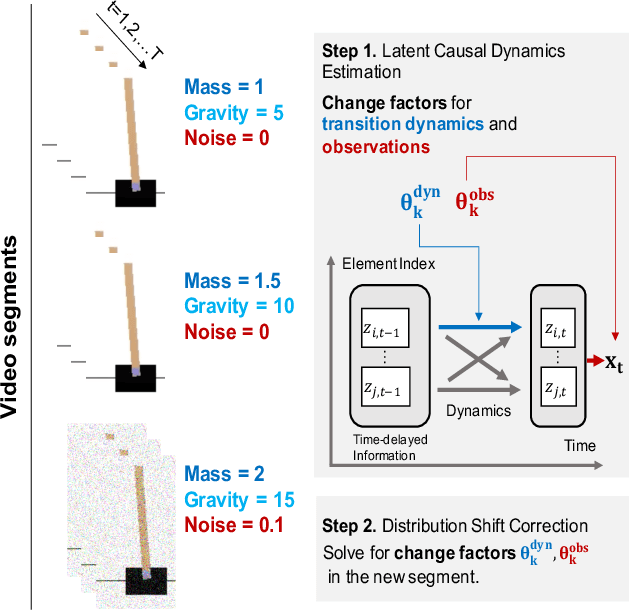
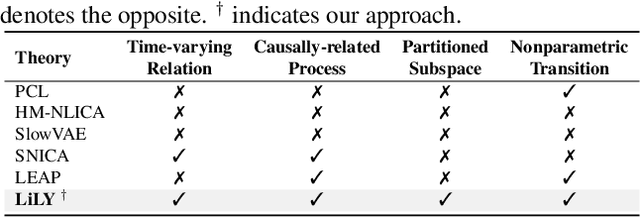
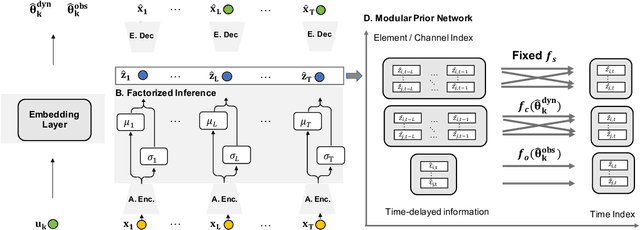
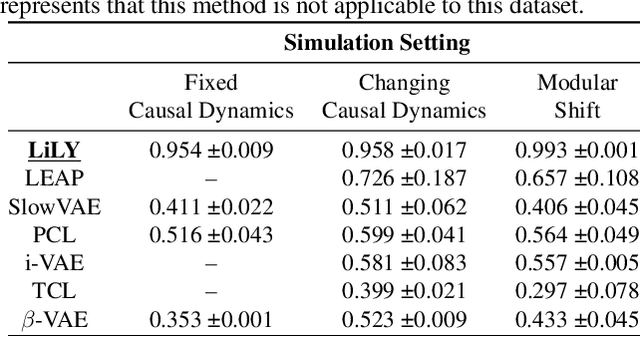
One critical challenge of time-series modeling is how to learn and quickly correct the model under unknown distribution shifts. In this work, we propose a principled framework, called LiLY, to first recover time-delayed latent causal variables and identify their relations from measured temporal data under different distribution shifts. The correction step is then formulated as learning the low-dimensional change factors with a few samples from the new environment, leveraging the identified causal structure. Specifically, the framework factorizes unknown distribution shifts into transition distribution changes caused by fixed dynamics and time-varying latent causal relations, and by global changes in observation. We establish the identifiability theories of nonparametric latent causal dynamics from their nonlinear mixtures under fixed dynamics and under changes. Through experiments, we show that time-delayed latent causal influences are reliably identified from observed variables under different distribution changes. By exploiting this modular representation of changes, we can efficiently learn to correct the model under unknown distribution shifts with only a few samples.
Fault-Resilient PCIe Bus with Real-time Error Detection and Correction
May 12, 2021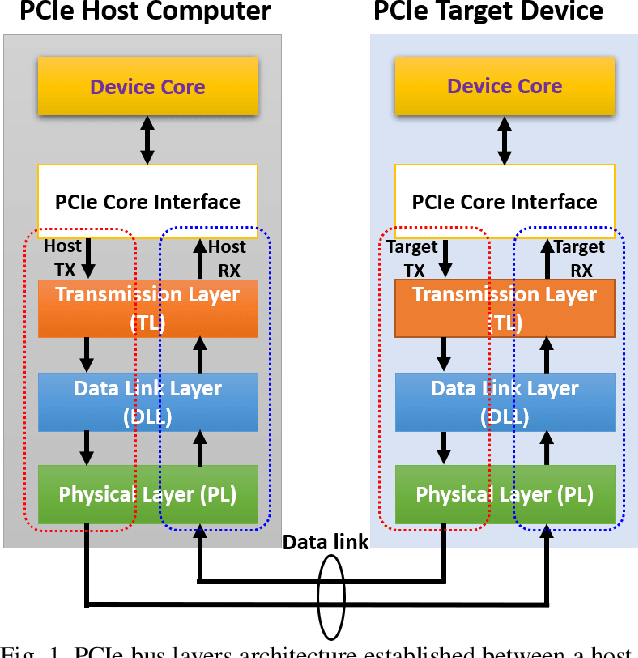

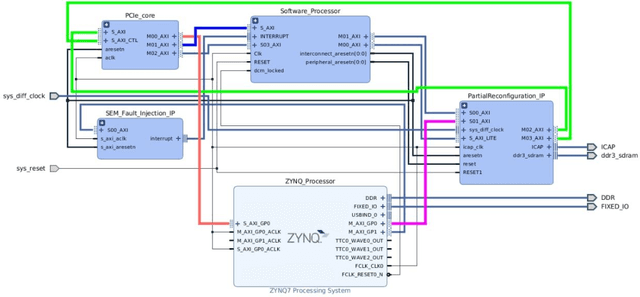
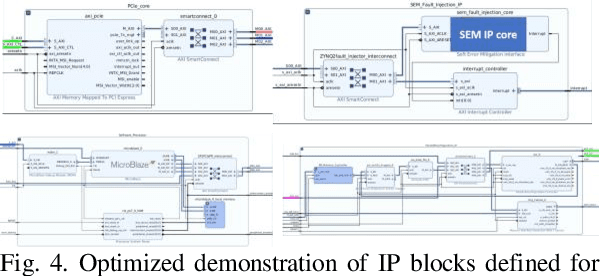
This paper presents a novel IP design for real-time fault/error detection and recovery on a peripheral component interconnect express (PCIe) which interfaces a host system (here a PC) to a slave design including processing system and memory transaction implemented on a Zynq Ultrascale Xilinx Kintex FPGA board (KCU105). The proposed IP design is capable of detection and correction of different types of PCIe errors on-the-fly