 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time High-Resolution Background Matting
Dec 14, 2020
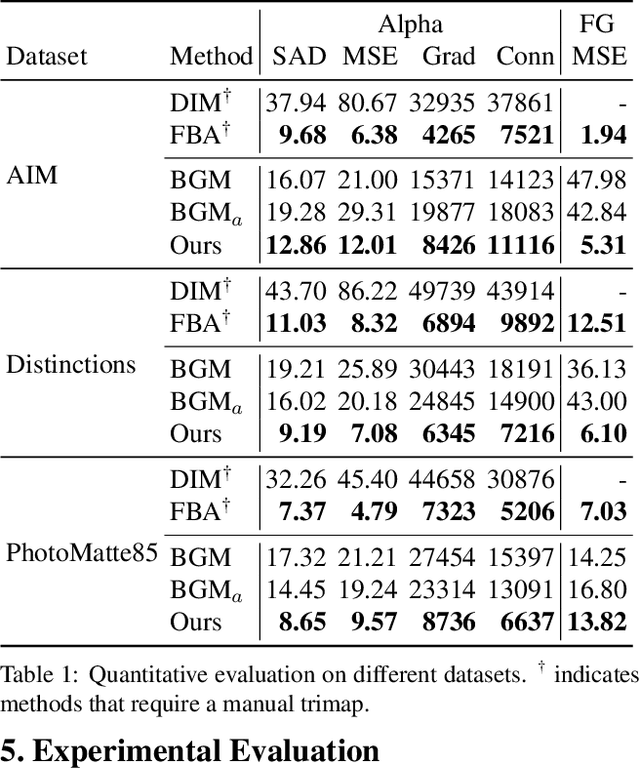

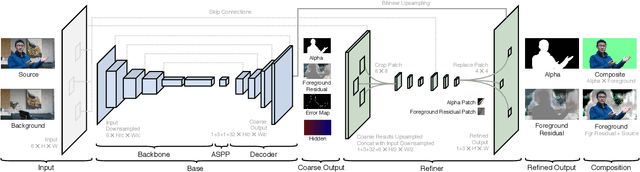
We introduce a real-time, high-resolution background replacement technique which operates at 30fps in 4K resolution, and 60fps for HD on a modern GPU. Our technique is based on background matting, where an additional frame of the background is captured and used in recovering the alpha matte and the foreground layer. The main challenge is to compute a high-quality alpha matte, preserving strand-level hair details, while processing high-resolution images in real-time. To achieve this goal, we employ two neural networks; a base network computes a low-resolution result which is refined by a second network operating at high-resolution on selective patches. We introduce two largescale video and image matting datasets: VideoMatte240K and PhotoMatte13K/85. Our approach yields higher quality results compared to the previous state-of-the-art in background matting, while simultaneously yielding a dramatic boost in both speed and resolution.
HIRL: A General Framework for Hierarchical Image Representation Learning
May 26, 2022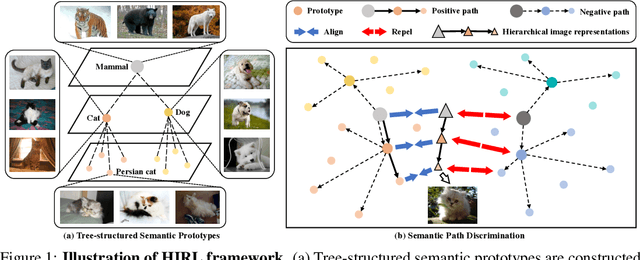
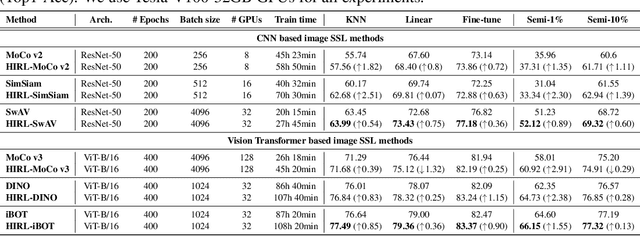


Learning self-supervised image representations has been broadly studied to boost various visual understanding tasks. Existing methods typically learn a single level of image semantics like pairwise semantic similarity or image clustering patterns. However, these methods can hardly capture multiple levels of semantic information that naturally exists in an image dataset, e.g., the semantic hierarchy of "Persian cat to cat to mammal" encoded in an image database for species. It is thus unknown whether an arbitrary image self-supervised learning (SSL) approach can benefit from learning such hierarchical semantics. To answer this question, we propose a general framework for Hierarchical Image Representation Learning (HIRL). This framework aims to learn multiple semantic representations for each image, and these representations are structured to encode image semantics from fine-grained to coarse-grained. Based on a probabilistic factorization, HIRL learns the most fine-grained semantics by an off-the-shelf image SSL approach and learns multiple coarse-grained semantics by a novel semantic path discrimination scheme. We adopt six representative image SSL methods as baselines and study how they perform under HIRL. By rigorous fair comparison, performance gain is observed on all the six methods for diverse downstream tasks, which, for the first time, verifies the general effectiveness of learning hierarchical image semantics. All source code and model weights are available at https://github.com/hirl-team/HIRL
Aligning Robot Representations with Humans
May 15, 2022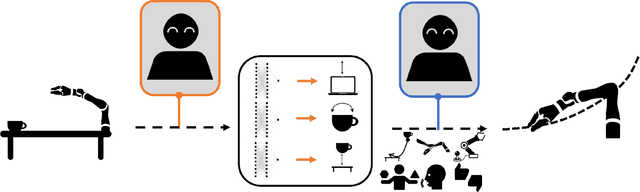
As robots are increasingly deployed in real-world scenarios, a key question is how to best transfer knowledge learned in one environment to another, where shifting constraints and human preferences render adaptation challenging. A central challenge remains that often, it is difficult (perhaps even impossible) to capture the full complexity of the deployment environment, and therefore the desired tasks, at training time. Consequently, the representation, or abstraction, of the tasks the human hopes for the robot to perform in one environment may be misaligned with the representation of the tasks that the robot has learned in another. We postulate that because humans will be the ultimate evaluator of system success in the world, they are best suited to communicating the aspects of the tasks that matter to the robot. Our key insight is that effective learning from human input requires first explicitly learning good intermediate representations and then using those representations for solving downstream tasks. We highlight three areas where we can use this approach to build interactive systems and offer future directions of work to better create advanced collaborative robots.
Leaner and Faster: Two-Stage Model Compression for Lightweight Text-Image Retrieval
Apr 29, 2022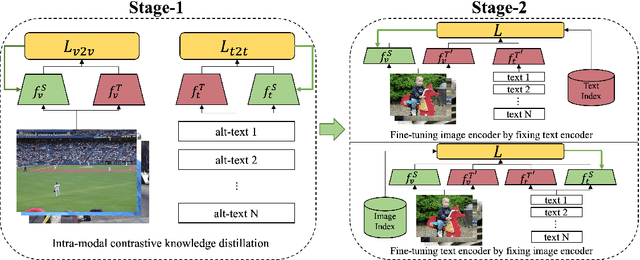
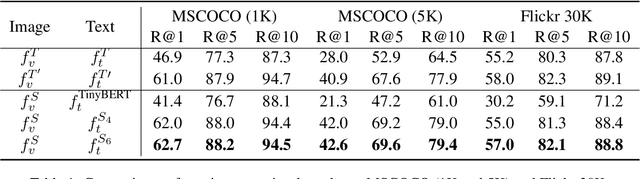
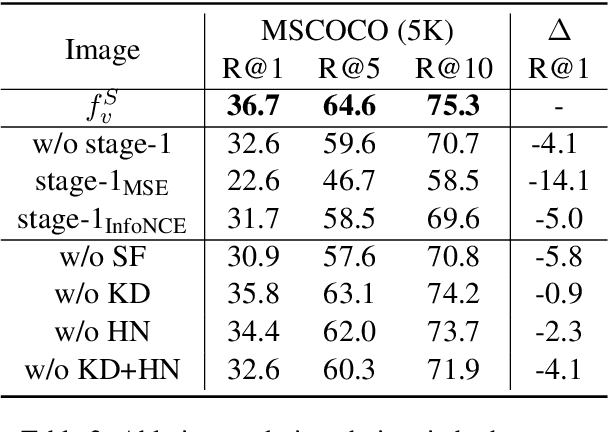
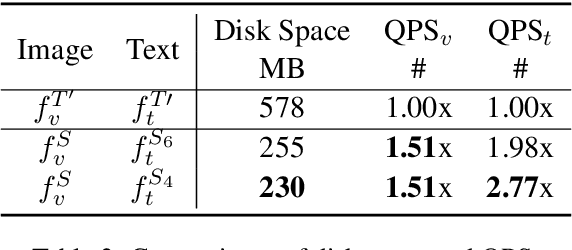
Current text-image approaches (e.g., CLIP) typically adopt dual-encoder architecture us- ing pre-trained vision-language representation. However, these models still pose non-trivial memory requirements and substantial incre- mental indexing time, which makes them less practical on mobile devices. In this paper, we present an effective two-stage framework to compress large pre-trained dual-encoder for lightweight text-image retrieval. The result- ing model is smaller (39% of the original), faster (1.6x/2.9x for processing image/text re- spectively), yet performs on par with or bet- ter than the original full model on Flickr30K and MSCOCO benchmarks. We also open- source an accompanying realistic mobile im- age search application.
muNet: Evolving Pretrained Deep Neural Networks into Scalable Auto-tuning Multitask Systems
May 22, 2022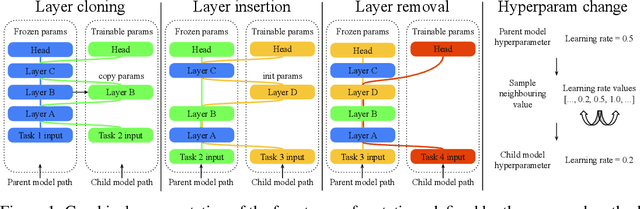
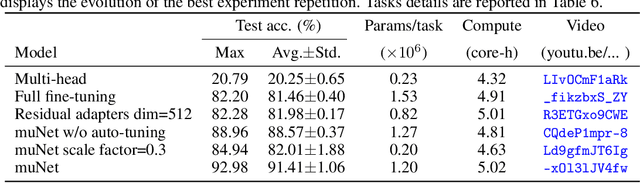
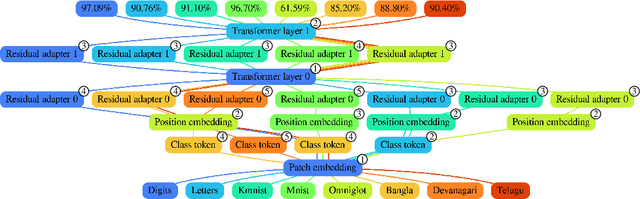
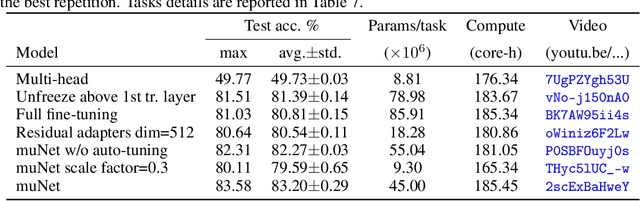
Most uses of machine learning today involve training a model from scratch for a particular task, or sometimes starting with a model pretrained on a related task and then fine-tuning on a downstream task. Both approaches offer limited knowledge transfer between different tasks, time-consuming human-driven customization to individual tasks and high computational costs especially when starting from randomly initialized models. We propose a method that uses the layers of a pretrained deep neural network as building blocks to construct an ML system that can jointly solve an arbitrary number of tasks. The resulting system can leverage cross tasks knowledge transfer, while being immune from common drawbacks of multitask approaches such as catastrophic forgetting, gradients interference and negative transfer. We define an evolutionary approach designed to jointly select the prior knowledge relevant for each task, choose the subset of the model parameters to train and dynamically auto-tune its hyperparameters. Furthermore, a novel scale control method is employed to achieve quality/size trade-offs that outperform common fine-tuning techniques. Compared with standard fine-tuning on a benchmark of 10 diverse image classification tasks, the proposed model improves the average accuracy by 2.39% while using 47% less parameters per task.
Class-Incremental Learning for Action Recognition in Videos
Mar 25, 2022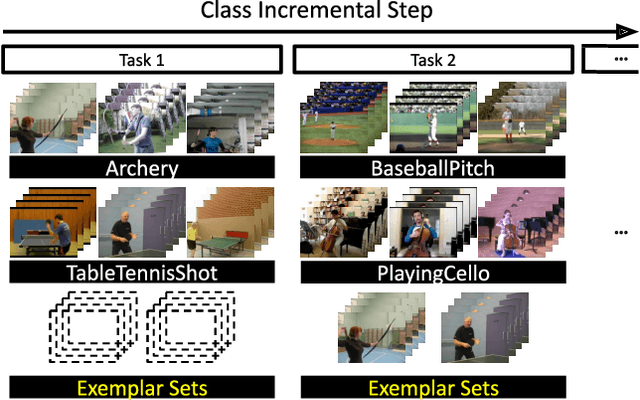
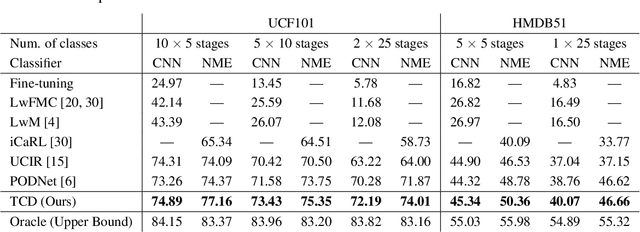

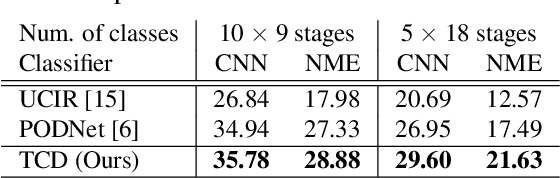
We tackle catastrophic forgetting problem in the context of class-incremental learning for video recognition, which has not been explored actively despite the popularity of continual learning. Our framework addresses this challenging task by introducing time-channel importance maps and exploiting the importance maps for learning the representations of incoming examples via knowledge distillation. We also incorporate a regularization scheme in our objective function, which encourages individual features obtained from different time steps in a video to be uncorrelated and eventually improves accuracy by alleviating catastrophic forgetting. We evaluate the proposed approach on brand-new splits of class-incremental action recognition benchmarks constructed upon the UCF101, HMDB51, and Something-Something V2 datasets, and demonstrate the effectiveness of our algorithm in comparison to the existing continual learning methods that are originally designed for image data.
Trainable Weight Averaging for Fast Convergence and Better Generalization
May 26, 2022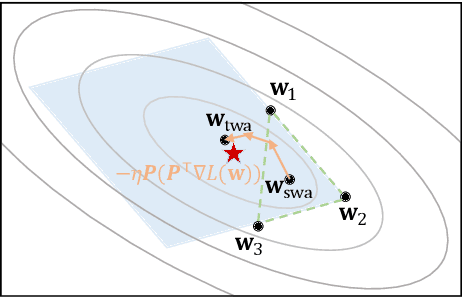
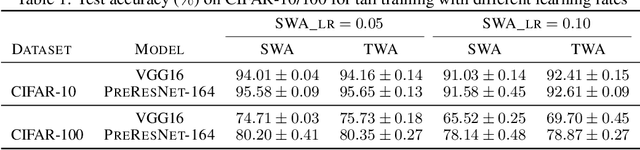
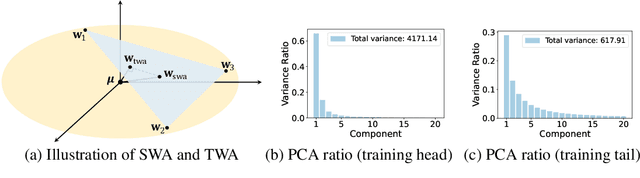
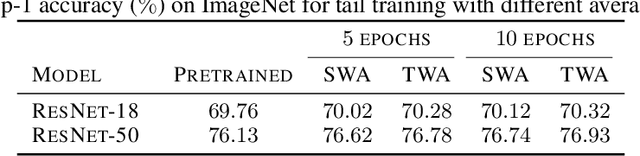
Stochastic gradient descent (SGD) and its variants are commonly considered as the de-facto methods to train deep neural networks (DNNs). While recent improvements to SGD mainly focus on the descent algorithm itself, few works pay attention to utilizing the historical solutions -- as an iterative method, SGD has actually gone through substantial explorations before its final convergence. Recently, an interesting attempt is stochastic weight averaging (SWA), which significantly improves the generalization by simply averaging the solutions at the tail stage of training. In this paper, we propose to optimize the averaging coefficients, leading to our Trainable Weight Averaging (TWA), essentially a novel training method in a reduced subspace spanned by historical solutions. TWA is quite efficient and has good generalization capability as the degree of freedom for training is small. It largely reduces the estimation error from SWA, making it not only further improve the SWA solutions but also take full advantage of the solutions generated in the head of training where SWA fails. In the extensive numerical experiments, (i) TWA achieves consistent improvements over SWA with less sensitivity to learning rate; (ii) applying TWA in the head stage of training largely speeds up the convergence, resulting in over 40% time saving on CIFAR and 30% on ImageNet with improved generalization compared with regular training. The code is released at https://github.com/nblt/TWA.
Discrete models of continuous behavior of collective adaptive systems
Apr 26, 2022
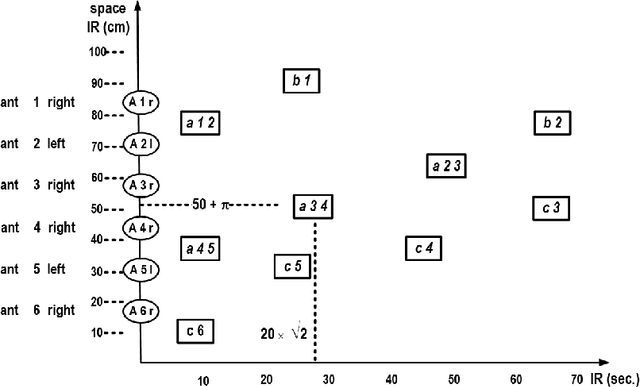
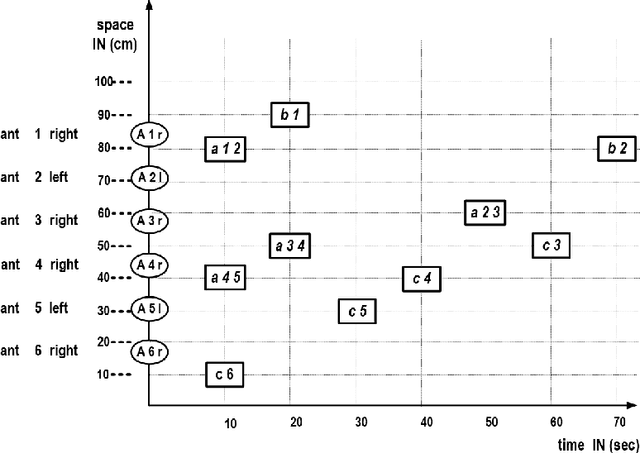
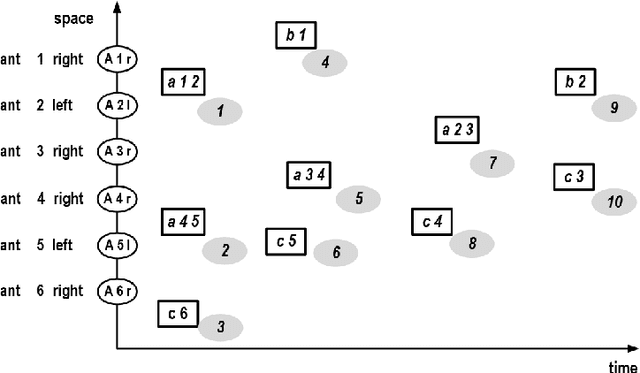
Artificial ants are "small" units, moving autonomously around on a shared, dynamically changing "space", directly or indirectly exchanging some kind of information. Artificial ants are frequently conceived as a paradigm for collective adaptive systems. In this paper, we discuss means to represent continuous moves of "ants" in discrete models. More generally, we challenge the role of the notion of "time" in artificial ant systems and models. We suggest a modeling framework that structures behavior along causal dependencies, and not along temporal relations. We present all arguments by help of a simple example. As a modeling framework we employ Heraklit; an emerging framework that already has proven its worth in many contexts.
Stable Online Control of Linear Time-Varying Systems
Apr 30, 2021
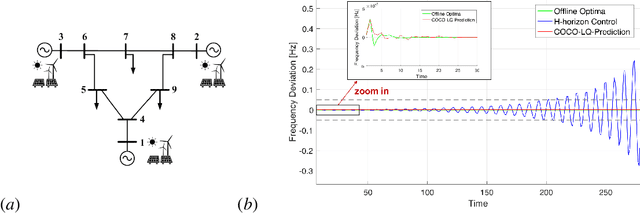

Linear time-varying (LTV) systems are widely used for modeling real-world dynamical systems due to their generality and simplicity. Providing stability guarantees for LTV systems is one of the central problems in control theory. However, existing approaches that guarantee stability typically lead to significantly sub-optimal cumulative control cost in online settings where only current or short-term system information is available. In this work, we propose an efficient online control algorithm, COvariance Constrained Online Linear Quadratic (COCO-LQ) control, that guarantees input-to-state stability for a large class of LTV systems while also minimizing the control cost. The proposed method incorporates a state covariance constraint into the semi-definite programming (SDP) formulation of the LQ optimal controller. We empirically demonstrate the performance of COCO-LQ in both synthetic experiments and a power system frequency control example.
Mitigating Toxic Degeneration with Empathetic Data: Exploring the Relationship Between Toxicity and Empathy
May 15, 2022
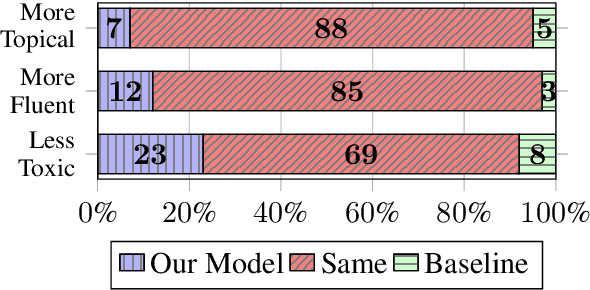
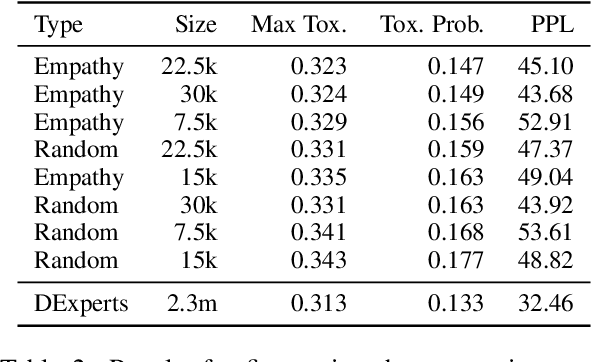
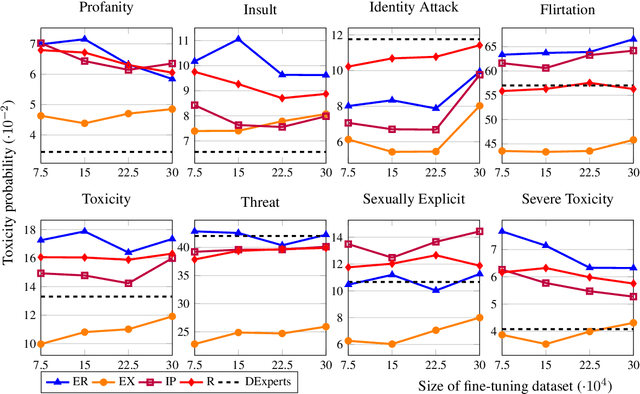
Large pre-trained neural language models have supported the effectiveness of many NLP tasks, yet are still prone to generating toxic language hindering the safety of their use. Using empathetic data, we improve over recent work on controllable text generation that aims to reduce the toxicity of generated text. We find we are able to dramatically reduce the size of fine-tuning data to 7.5-30k samples while at the same time making significant improvements over state-of-the-art toxicity mitigation of up to 3.4% absolute reduction (26% relative) from the original work on 2.3m samples, by strategically sampling data based on empathy scores. We observe that the degree of improvement is subject to specific communication components of empathy. In particular, the cognitive components of empathy significantly beat the original dataset in almost all experiments, while emotional empathy was tied to less improvement and even underperforming random samples of the original data. This is a particularly implicative insight for NLP work concerning empathy as until recently the research and resources built for it have exclusively considered empathy as an emotional concept.