 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Interactive Motion Prediction and Planning: Playing Games with Motion Prediction Models
Apr 05, 2022
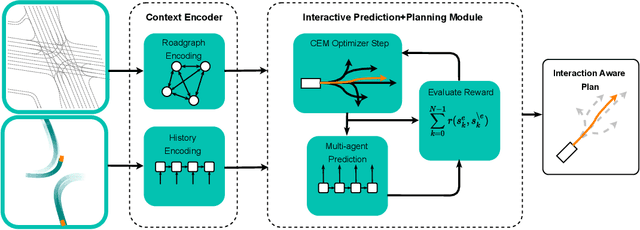
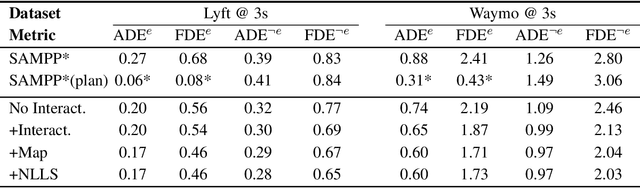

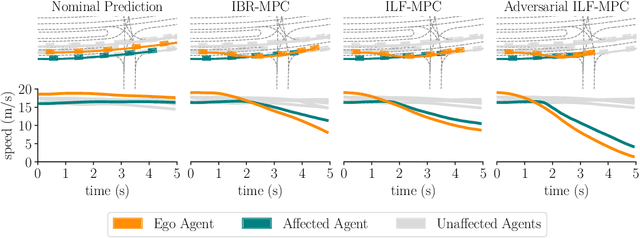
In most classical Autonomous Vehicle (AV) stacks, the prediction and planning layers are separated, limiting the planner to react to predictions that are not informed by the planned trajectory of the AV. This work presents a module that tightly couples these layers via a game-theoretic Model Predictive Controller (MPC) that uses a novel interactive multi-agent neural network policy as part of its predictive model. In our setting, the MPC planner considers all the surrounding agents by informing the multi-agent policy with the planned state sequence. Fundamental to the success of our method is the design of a novel multi-agent policy network that can steer a vehicle given the state of the surrounding agents and the map information. The policy network is trained implicitly with ground-truth observation data using backpropagation through time and a differentiable dynamics model to roll out the trajectory forward in time. Finally, we show that our multi-agent policy network learns to drive while interacting with the environment, and, when combined with the game-theoretic MPC planner, can successfully generate interactive behaviors.
Research on the correlation between text emotion mining and stock market based on deep learning
May 09, 2022This paper discusses how to crawl the data of financial forums such as stock bar, and conduct emotional analysis combined with the in-depth learning model. This paper will use the Bert model to train the financial corpus and predict the Shenzhen stock index. Through the comparative study of the maximal information coefficient (MIC), it is found that the emotional characteristics obtained by applying the BERT model to the financial corpus can be reflected in the fluctuation of the stock market, which is conducive to effectively improve the prediction accuracy. At the same time, this paper combines in-depth learning with financial texts to further explore the impact mechanism of investor sentiment on the stock market through in-depth learning, which will help the national regulatory authorities and policy departments to formulate more reasonable policies and guidelines for maintaining the stability of the stock market.
LEAD1.0: A Large-scale Annotated Dataset for Energy Anomaly Detection in Commercial Buildings
Mar 30, 2022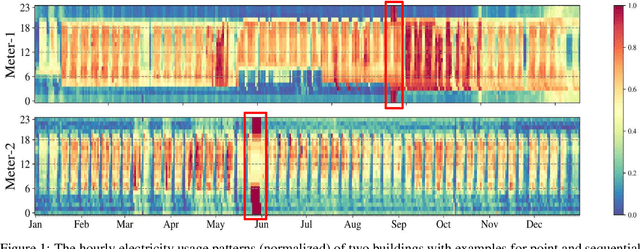
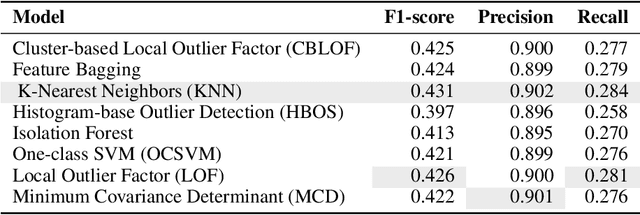
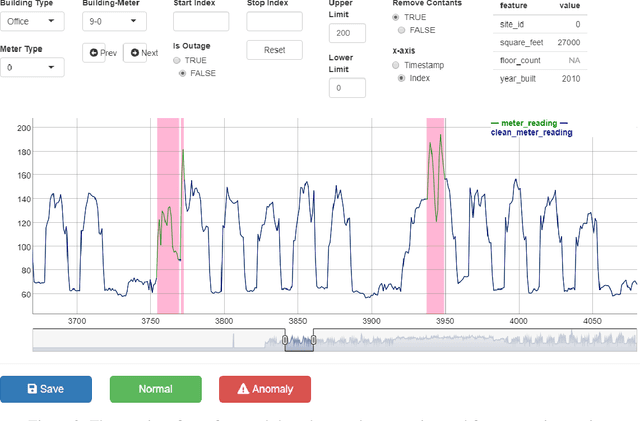
Modern buildings are densely equipped with smart energy meters, which periodically generate a massive amount of time-series data yielding few million data points every day. This data can be leveraged to discover the underlying loads, infer their energy consumption patterns, inter-dependencies on environmental factors, and the building's operational properties. Furthermore, it allows us to simultaneously identify anomalies present in the electricity consumption profiles, which is a big step towards saving energy and achieving global sustainability. However, to date, the lack of large-scale annotated energy consumption datasets hinders the ongoing research in anomaly detection. We contribute to this effort by releasing a well-annotated version of a publicly available ASHRAE Great Energy Predictor III data set containing 1,413 smart electricity meter time series spanning over one year. In addition, we benchmark the performance of eight state-of-the-art anomaly detection methods on our dataset and compare their performance.
Self-Consistent Dynamical Field Theory of Kernel Evolution in Wide Neural Networks
May 19, 2022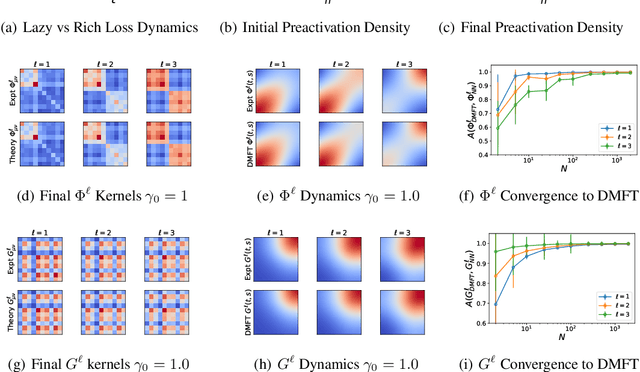

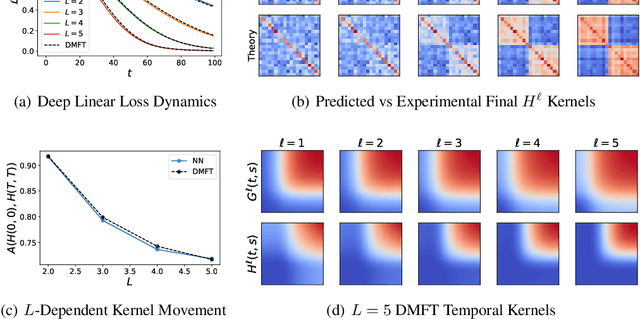
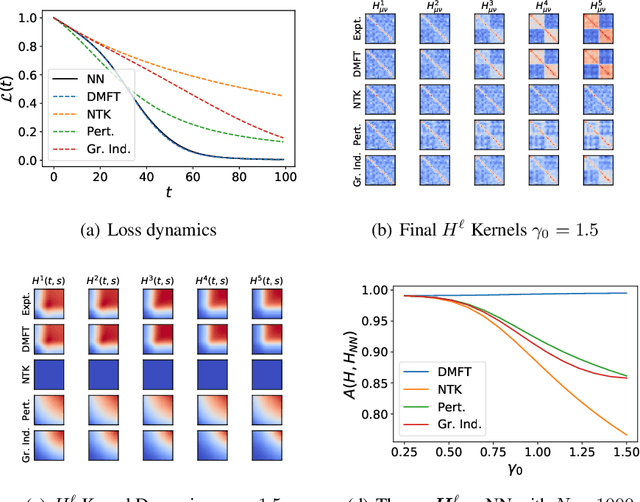
We analyze feature learning in infinite width neural networks trained with gradient flow through a self-consistent dynamical field theory. We construct a collection of deterministic dynamical order parameters which are inner-product kernels for hidden unit activations and gradients in each layer at pairs of time points, providing a reduced description of network activity through training. These kernel order parameters collectively define the hidden layer activation distribution, the evolution of the neural tangent kernel, and consequently output predictions. For deep linear networks, these kernels satisfy a set of algebraic matrix equations. For nonlinear networks, we provide an alternating sampling procedure to self-consistently solve for the kernel order parameters. We provide comparisons of the self-consistent solution to various approximation schemes including the static NTK approximation, gradient independence assumption, and leading order perturbation theory, showing that each of these approximations can break down in regimes where general self-consistent solutions still provide an accurate description. Lastly, we provide experiments in more realistic settings which demonstrate that the loss and kernel dynamics of CNNs at fixed feature learning strength is preserved across different widths on a CIFAR classification task.
Comparison of Traditional and Hybrid Time Series Models for Forecasting COVID-19 Cases
May 05, 2021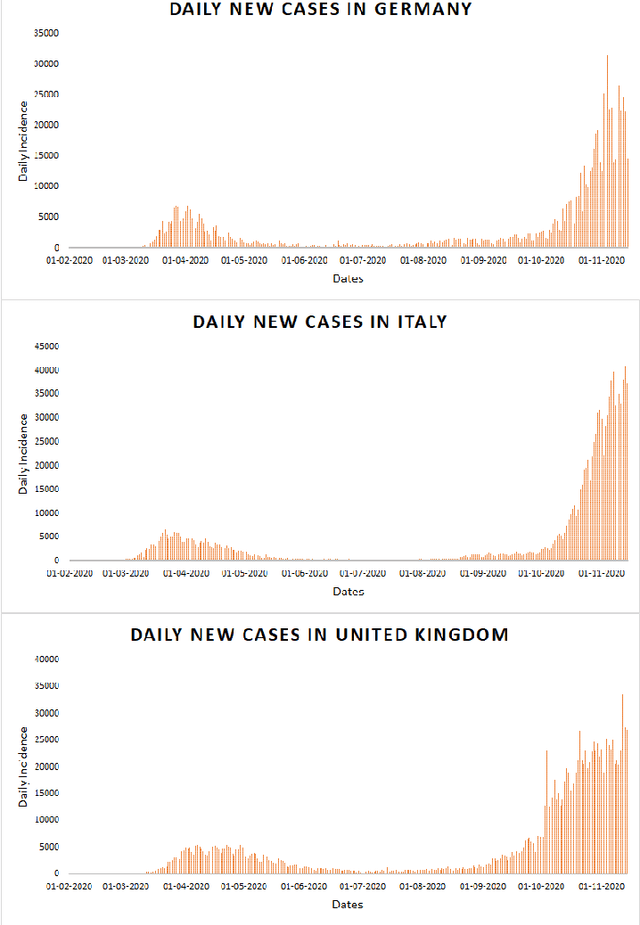
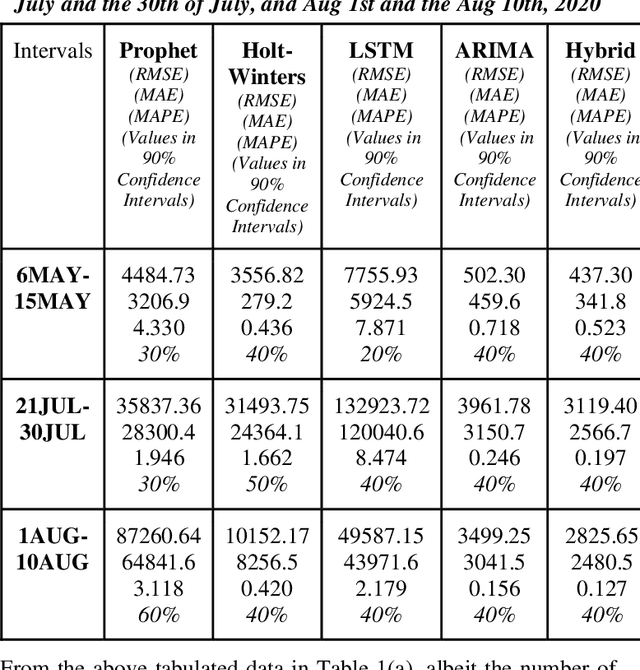
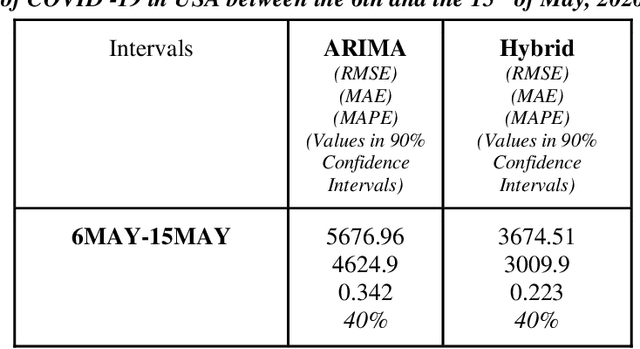
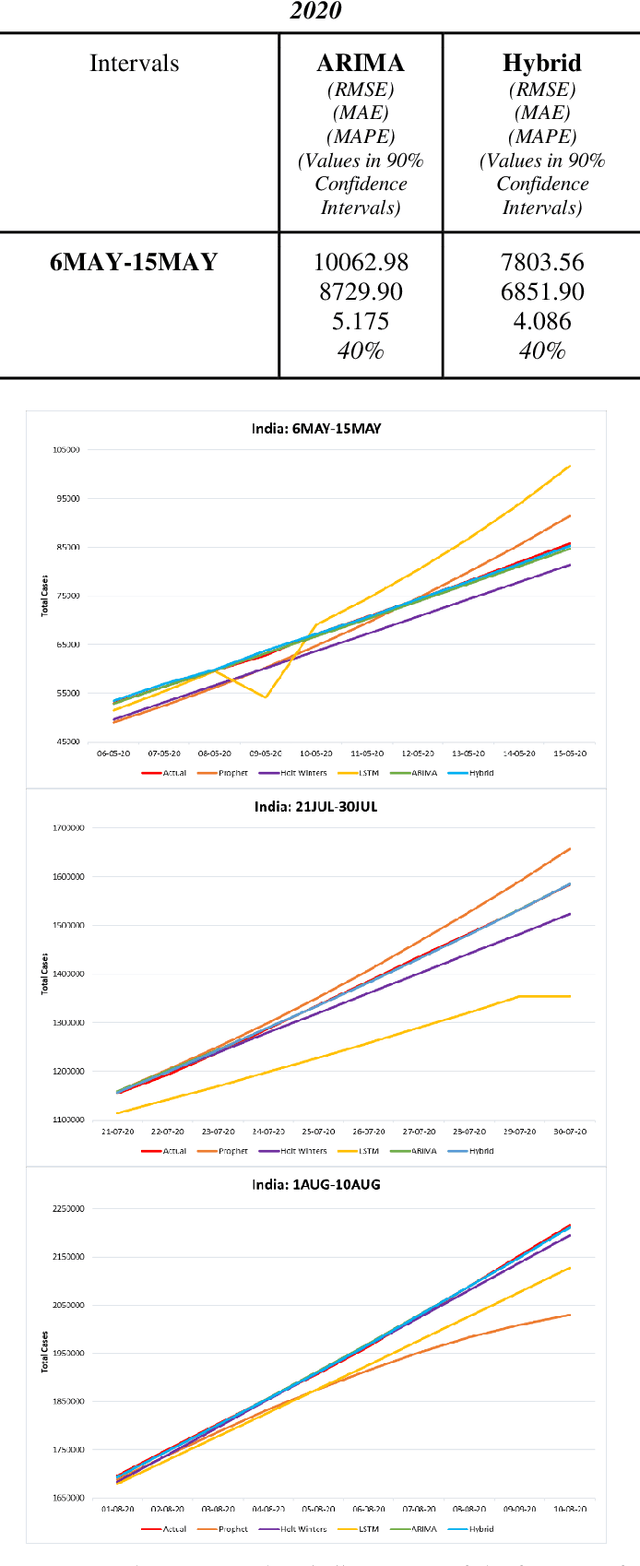
Time series forecasting methods play critical role in estimating the spread of an epidemic. The coronavirus outbreak of December 2019 has already infected millions all over the world and continues to spread on. Just when the curve of the outbreak had started to flatten, many countries have again started to witness a rise in cases which is now being referred as the 2nd wave of the pandemic. A thorough analysis of time-series forecasting models is therefore required to equip state authorities and health officials with immediate strategies for future times. This aims of the study are three-fold: (a) To model the overall trend of the spread; (b) To generate a short-term forecast of 10 days in countries with the highest incidence of confirmed cases (USA, India and Brazil); (c) To quantitatively determine the algorithm that is best suited for precise modelling of the linear and non-linear features of the time series. The comparison of forecasting models for the total cumulative cases of each country is carried out by comparing the reported data and the predicted value, and then ranking the algorithms (Prophet, Holt-Winters, LSTM, ARIMA, and ARIMA-NARNN) based on their RMSE, MAE and MAPE values. The hybrid combination of ARIMA and NARNN (Nonlinear Auto-Regression Neural Network) gave the best result among the selected models with a reduced RMSE, which proved to be almost 35.3% better than one of the most prevalent method of time-series prediction (ARIMA). The results demonstrated the efficacy of the hybrid implementation of the ARIMA-NARNN model over other forecasting methods such as Prophet, Holt Winters, LSTM, and the ARIMA model in encapsulating the linear as well as non-linear patterns of the epidemical datasets.
Rapid model transfer for medical image segmentation via iterative human-in-the-loop update: from labelled public to unlabelled clinical datasets for multi-organ segmentation in CT
Apr 13, 2022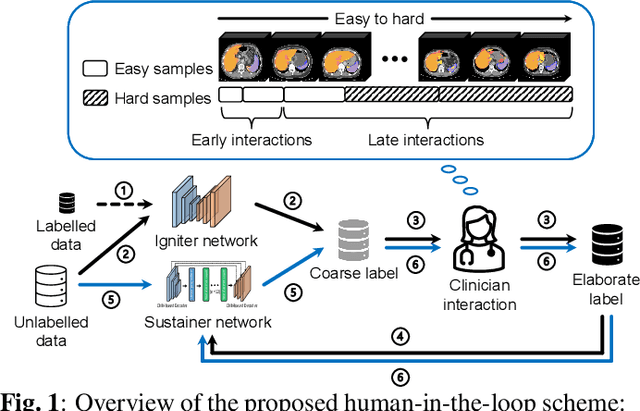
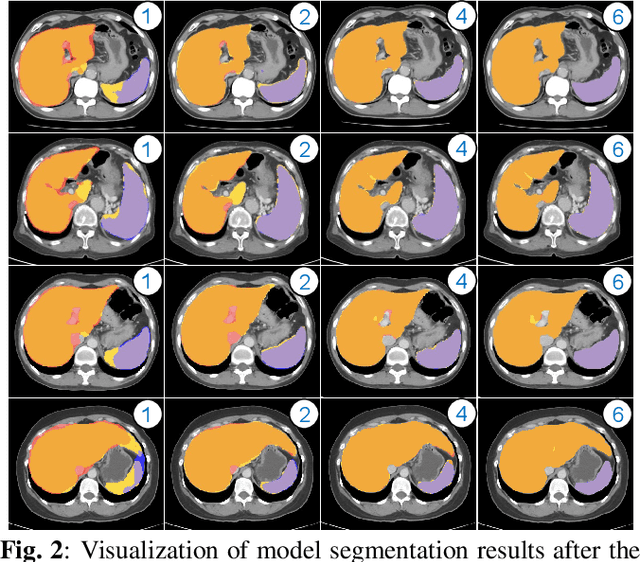
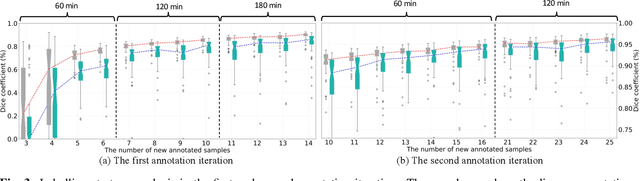
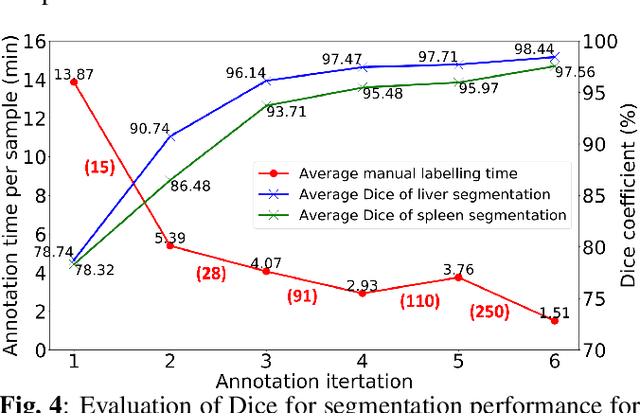
Despite the remarkable success on medical image analysis with deep learning, it is still under exploration regarding how to rapidly transfer AI models from one dataset to another for clinical applications. This paper presents a novel and generic human-in-the-loop scheme for efficiently transferring a segmentation model from a small-scale labelled dataset to a larger-scale unlabelled dataset for multi-organ segmentation in CT. To achieve this, we propose to use an igniter network which can learn from a small-scale labelled dataset and generate coarse annotations to start the process of human-machine interaction. Then, we use a sustainer network for our larger-scale dataset, and iteratively updated it on the new annotated data. Moreover, we propose a flexible labelling strategy for the annotator to reduce the initial annotation workload. The model performance and the time cost of annotation in each subject evaluated on our private dataset are reported and analysed. The results show that our scheme can not only improve the performance by 19.7% on Dice, but also expedite the cost time of manual labelling from 13.87 min to 1.51 min per CT volume during the model transfer, demonstrating the clinical usefulness with promising potentials.
Long-term Control for Dialogue Generation: Methods and Evaluation
May 15, 2022
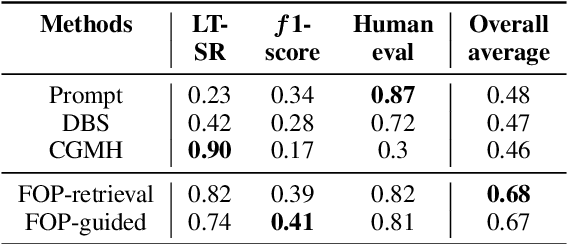
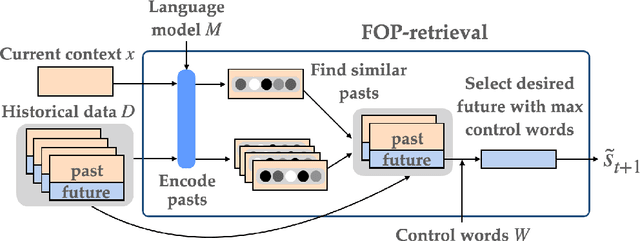
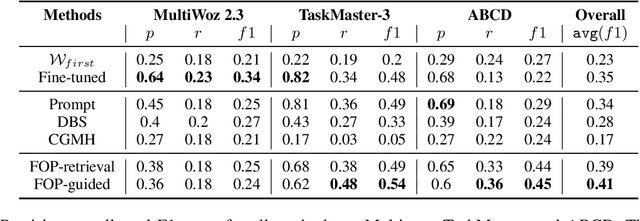
Current approaches for controlling dialogue response generation are primarily focused on high-level attributes like style, sentiment, or topic. In this work, we focus on constrained long-term dialogue generation, which involves more fine-grained control and requires a given set of control words to appear in generated responses. This setting requires a model to not only consider the generation of these control words in the immediate context, but also produce utterances that will encourage the generation of the words at some time in the (possibly distant) future. We define the problem of constrained long-term control for dialogue generation, identify gaps in current methods for evaluation, and propose new metrics that better measure long-term control. We also propose a retrieval-augmented method that improves performance of long-term controlled generation via logit modification techniques. We show through experiments on three task-oriented dialogue datasets that our metrics better assess dialogue control relative to current alternatives and that our method outperforms state-of-the-art constrained generation baselines.
Continuously-Tempered PDMP Samplers
May 19, 2022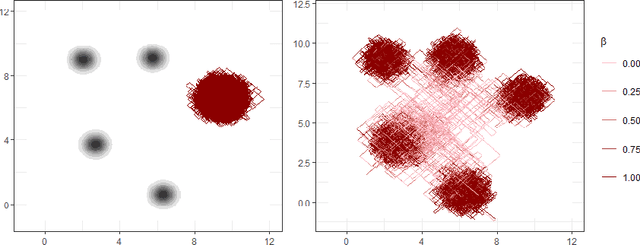
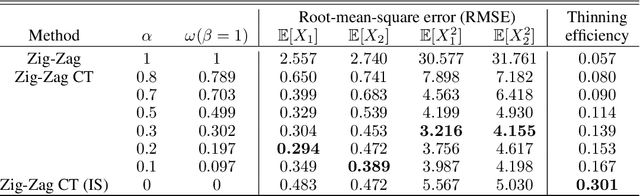
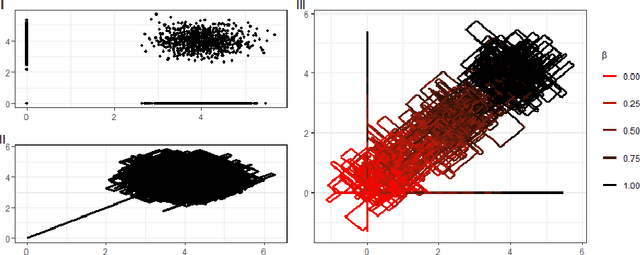
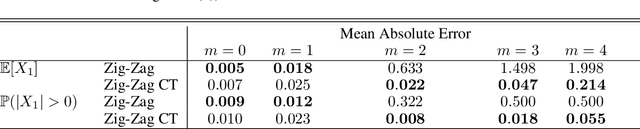
New sampling algorithms based on simulating continuous-time stochastic processes called piece-wise deterministic Markov processes (PDMPs) have shown considerable promise. However, these methods can struggle to sample from multi-modal or heavy-tailed distributions. We show how tempering ideas can improve the mixing of PDMPs in such cases. We introduce an extended distribution defined over the state of the posterior distribution and an inverse temperature, which interpolates between a tractable distribution when the inverse temperature is 0 and the posterior when the inverse temperature is 1. The marginal distribution of the inverse temperature is a mixture of a continuous distribution on [0,1) and a point mass at 1: which means that we obtain samples when the inverse temperature is 1, and these are draws from the posterior, but sampling algorithms will also explore distributions at lower temperatures which will improve mixing. We show how PDMPs, and particularly the Zig-Zag sampler, can be implemented to sample from such an extended distribution. The resulting algorithm is easy to implement and we show empirically that it can outperform existing PDMP-based samplers on challenging multimodal posteriors.
Learning Car Speed Using Inertial Sensors
May 15, 2022

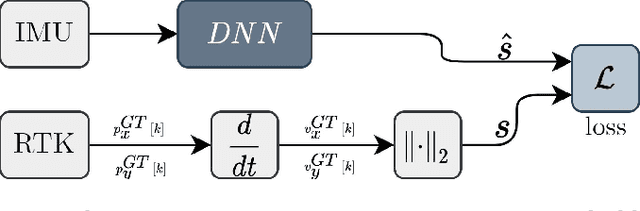
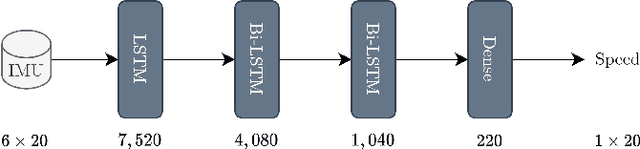
A deep neural network (DNN) is trained to estimate the speed of a car driving in an urban area using as input a stream of measurements from a low-cost six-axis inertial measurement unit (IMU). Three hours of data was collected by driving through the city of Ashdod, Israel in a car equipped with a global navigation satellite system (GNSS) real time kinematic (RTK) positioning device and a synchronized IMU. Ground truth labels for the car speed were calculated using the position measurements obtained at the high rate of 50 [Hz]. A DNN architecture with long short-term memory layers is proposed to enable high-frequency speed estimation that accounts for previous inputs history and the nonlinear relation between speed, acceleration, and angular velocity. A simplified aided dead reckoning localization scheme is formulated to assess the trained model which provides the speed pseudo-measurement. The trained model is shown to substantially improve the position accuracy during a 4 minutes drive without the use of GNSS position updates.
ResAct: Reinforcing Long-term Engagement in Sequential Recommendation with Residual Actor
Jun 01, 2022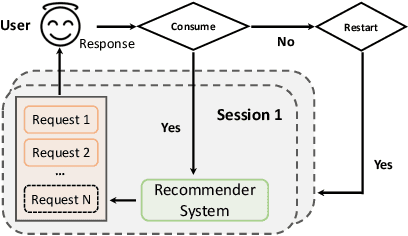
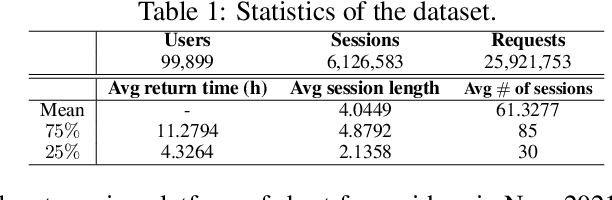
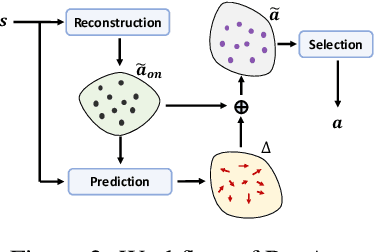
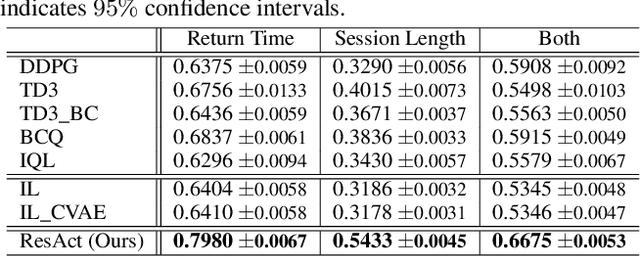
Long-term engagement is preferred over immediate engagement in sequential recommendation as it directly affects product operational metrics such as daily active users (DAUs) and dwell time. Meanwhile, reinforcement learning (RL) is widely regarded as a promising framework for optimizing long-term engagement in sequential recommendation. However, due to expensive online interactions, it is very difficult for RL algorithms to perform state-action value estimation, exploration and feature extraction when optimizing long-term engagement. In this paper, we propose ResAct which seeks a policy that is close to, but better than, the online-serving policy. In this way, we can collect sufficient data near the learned policy so that state-action values can be properly estimated, and there is no need to perform online exploration. Directly optimizing this policy is difficult due to the huge policy space. ResAct instead solves it by first reconstructing the online behaviors and then improving it. Our main contributions are fourfold. First, we design a generative model which reconstructs behaviors of the online-serving policy by sampling multiple action estimators. Second, we design an effective learning paradigm to train the residual actor which can output the residual for action improvement. Third, we facilitate the extraction of features with two information theoretical regularizers to confirm the expressiveness and conciseness of features. Fourth, we conduct extensive experiments on a real world dataset consisting of millions of sessions, and our method significantly outperforms the state-of-the-art baselines in various of long term engagement optimization tasks.