 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards a Real-time Measure of the Perception of Anthropomorphism in Human-robot Interaction
Jan 24, 2022

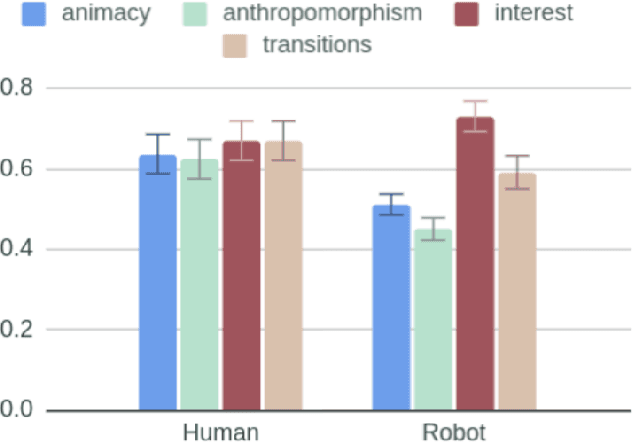
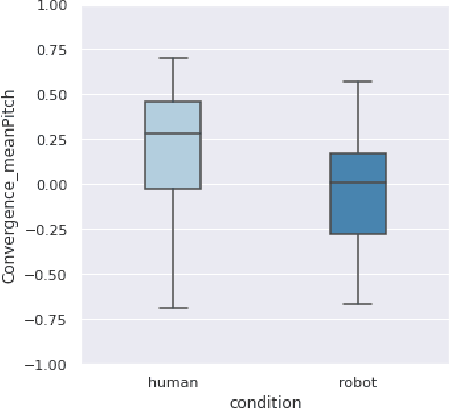
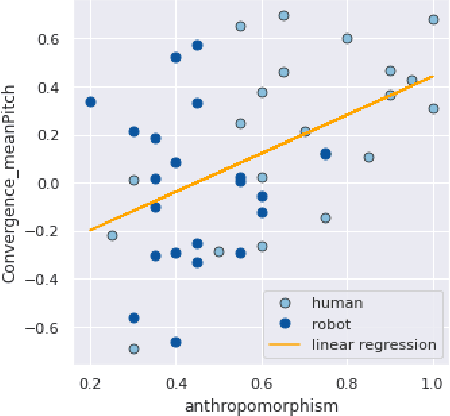
How human-like do conversational robots need to look to enable long-term human-robot conversation? One essential aspect of long-term interaction is a human's ability to adapt to the varying degrees of a conversational partner's engagement and emotions. Prosodically, this can be achieved through (dis)entrainment. While speech-synthesis has been a limiting factor for many years, restrictions in this regard are increasingly mitigated. These advancements now emphasise the importance of studying the effect of robot embodiment on human entrainment. In this study, we conducted a between-subjects online human-robot interaction experiment in an educational use-case scenario where a tutor was either embodied through a human or a robot face. 43 English-speaking participants took part in the study for whom we analysed the degree of acoustic-prosodic entrainment to the human or robot face, respectively. We found that the degree of subjective and objective perception of anthropomorphism positively correlates with acoustic-prosodic entrainment.
Causal discovery under a confounder blanket
May 11, 2022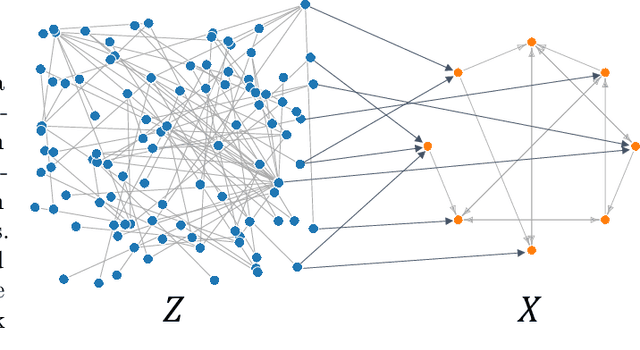
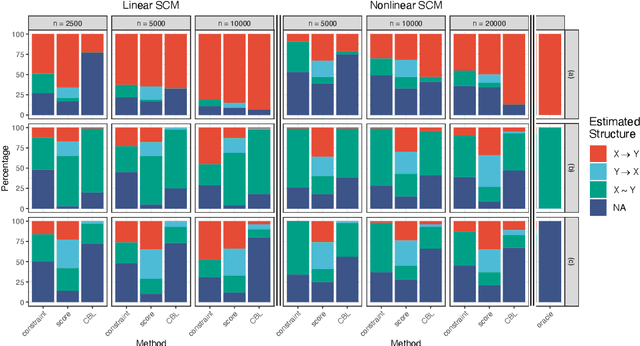
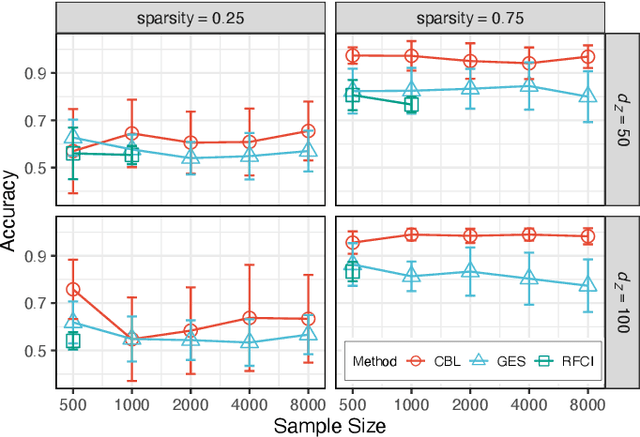
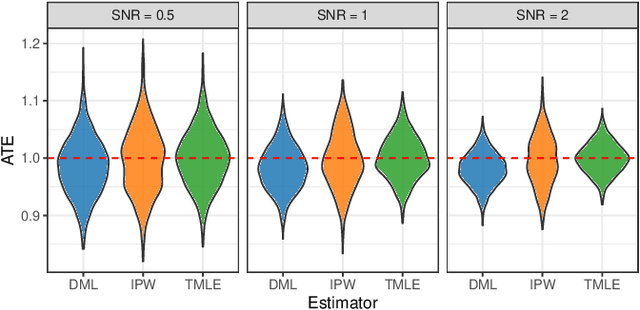
Inferring causal relationships from observational data is rarely straightforward, but the problem is especially difficult in high dimensions. For these applications, causal discovery algorithms typically require parametric restrictions or extreme sparsity constraints. We relax these assumptions and focus on an important but more specialized problem, namely recovering a directed acyclic subgraph of variables known to be causally descended from some (possibly large) set of confounding covariates, i.e. a $\textit{confounder blanket}$. This is useful in many settings, for example when studying a dynamic biomolecular subsystem with genetic data providing causally relevant background information. Under a structural assumption that, we argue, must be satisfied in practice if informative answers are to be found, our method accommodates graphs of low or high sparsity while maintaining polynomial time complexity. We derive a sound and complete algorithm for identifying causal relationships under these conditions and implement testing procedures with provable error control for linear and nonlinear systems. We demonstrate our approach on a range of simulation settings.
Research on the correlation between text emotion mining and stock market based on deep learning
May 09, 2022This paper discusses how to crawl the data of financial forums such as stock bar, and conduct emotional analysis combined with the in-depth learning model. This paper will use the Bert model to train the financial corpus and predict the Shenzhen stock index. Through the comparative study of the maximal information coefficient (MIC), it is found that the emotional characteristics obtained by applying the BERT model to the financial corpus can be reflected in the fluctuation of the stock market, which is conducive to effectively improve the prediction accuracy. At the same time, this paper combines in-depth learning with financial texts to further explore the impact mechanism of investor sentiment on the stock market through in-depth learning, which will help the national regulatory authorities and policy departments to formulate more reasonable policies and guidelines for maintaining the stability of the stock market.
Self-Consistent Dynamical Field Theory of Kernel Evolution in Wide Neural Networks
May 19, 2022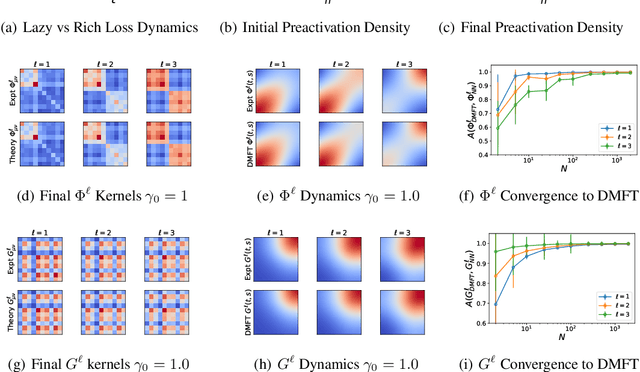

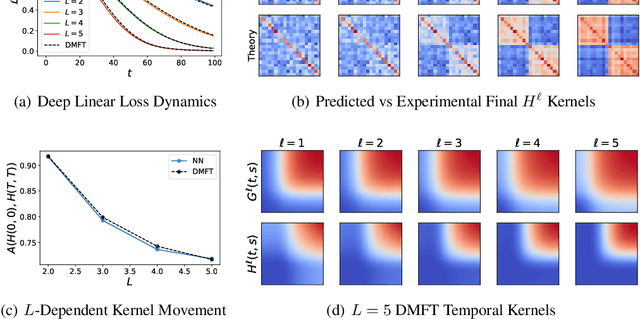
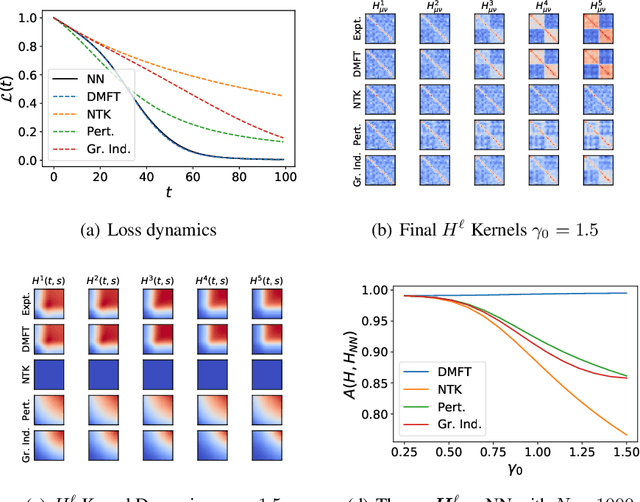
We analyze feature learning in infinite width neural networks trained with gradient flow through a self-consistent dynamical field theory. We construct a collection of deterministic dynamical order parameters which are inner-product kernels for hidden unit activations and gradients in each layer at pairs of time points, providing a reduced description of network activity through training. These kernel order parameters collectively define the hidden layer activation distribution, the evolution of the neural tangent kernel, and consequently output predictions. For deep linear networks, these kernels satisfy a set of algebraic matrix equations. For nonlinear networks, we provide an alternating sampling procedure to self-consistently solve for the kernel order parameters. We provide comparisons of the self-consistent solution to various approximation schemes including the static NTK approximation, gradient independence assumption, and leading order perturbation theory, showing that each of these approximations can break down in regimes where general self-consistent solutions still provide an accurate description. Lastly, we provide experiments in more realistic settings which demonstrate that the loss and kernel dynamics of CNNs at fixed feature learning strength is preserved across different widths on a CIFAR classification task.
TO-FLOW: Efficient Continuous Normalizing Flows with Temporal Optimization adjoint with Moving Speed
Mar 28, 2022
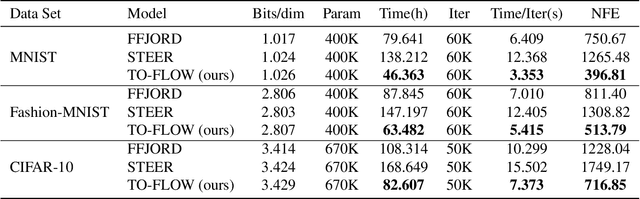
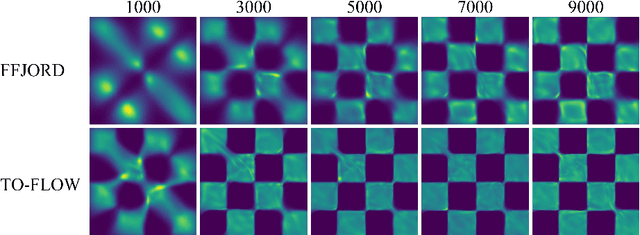

Continuous normalizing flows (CNFs) construct invertible mappings between an arbitrary complex distribution and an isotropic Gaussian distribution using Neural Ordinary Differential Equations (neural ODEs). It has not been tractable on large datasets due to the incremental complexity of the neural ODE training. Optimal Transport theory has been applied to regularize the dynamics of the ODE to speed up training in recent works. In this paper, a temporal optimization is proposed by optimizing the evolutionary time for forward propagation of the neural ODE training. In this appoach, we optimize the network weights of the CNF alternately with evolutionary time by coordinate descent. Further with temporal regularization, stability of the evolution is ensured. This approach can be used in conjunction with the original regularization approach. We have experimentally demonstrated that the proposed approach can significantly accelerate training without sacrifying performance over baseline models.
Deep Recurrent Modelling of Granger Causality with Latent Confounding
Feb 23, 2022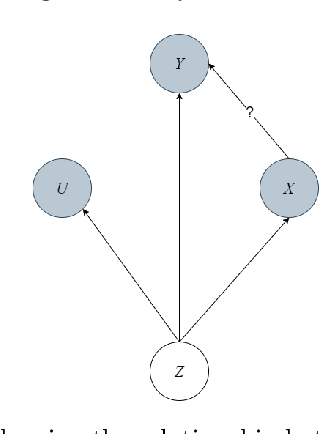

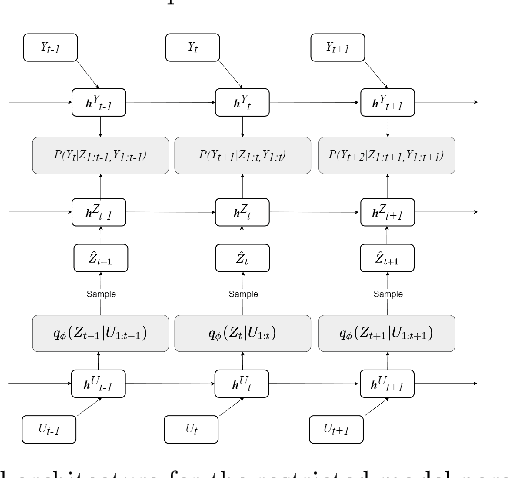
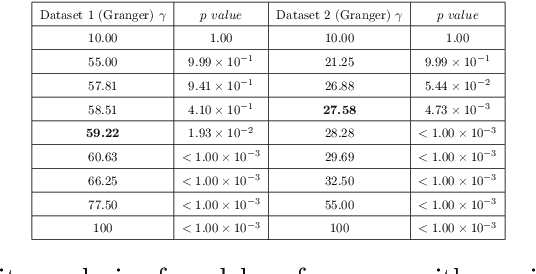
Inferring causal relationships in observational time series data is an important task when interventions cannot be performed. Granger causality is a popular framework to infer potential causal mechanisms between different time series. The original definition of Granger causality is restricted to linear processes and leads to spurious conclusions in the presence of a latent confounder. In this work, we harness the expressive power of recurrent neural networks and propose a deep learning-based approach to model non-linear Granger causality by directly accounting for latent confounders. Our approach leverages multiple recurrent neural networks to parameterise predictive distributions and we propose the novel use of a dual-decoder setup to conduct the Granger tests. We demonstrate the model performance on non-linear stochastic time series for which the latent confounder influences the cause and effect with different time lags; results show the effectiveness of our model compared to existing benchmarks.
Value Iteration in Continuous Actions, States and Time
May 10, 2021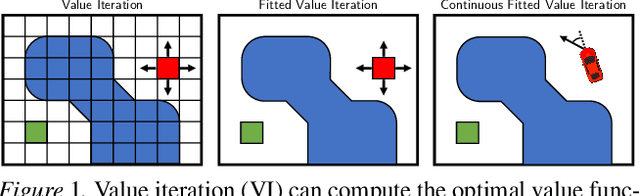
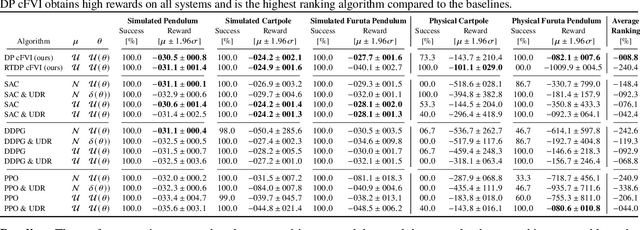
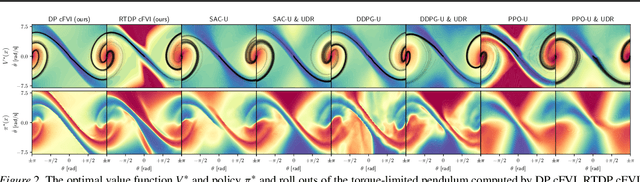
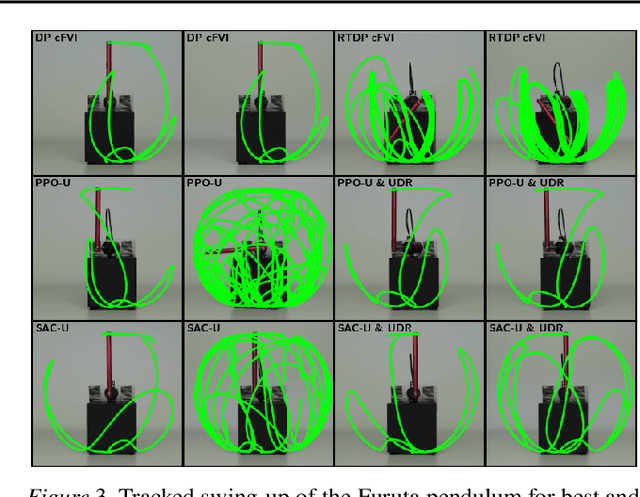
Classical value iteration approaches are not applicable to environments with continuous states and actions. For such environments, the states and actions are usually discretized, which leads to an exponential increase in computational complexity. In this paper, we propose continuous fitted value iteration (cFVI). This algorithm enables dynamic programming for continuous states and actions with a known dynamics model. Leveraging the continuous-time formulation, the optimal policy can be derived for non-linear control-affine dynamics. This closed-form solution enables the efficient extension of value iteration to continuous environments. We show in non-linear control experiments that the dynamic programming solution obtains the same quantitative performance as deep reinforcement learning methods in simulation but excels when transferred to the physical system. The policy obtained by cFVI is more robust to changes in the dynamics despite using only a deterministic model and without explicitly incorporating robustness in the optimization. Videos of the physical system are available at \url{https://sites.google.com/view/value-iteration}.
Real-Time Video Super-Resolution by Joint Local Inference and Global Parameter Estimation
May 06, 2021
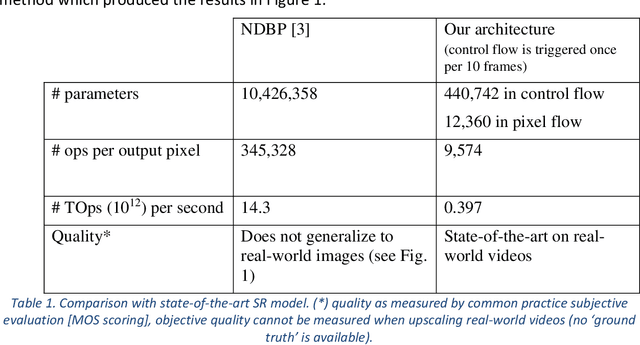
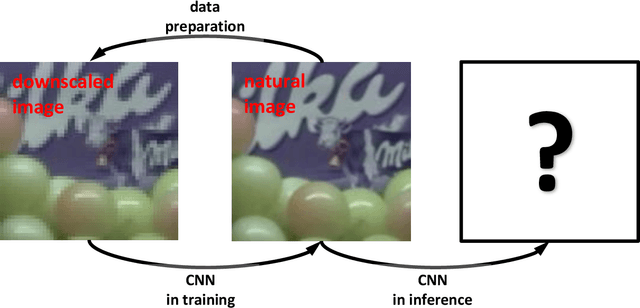
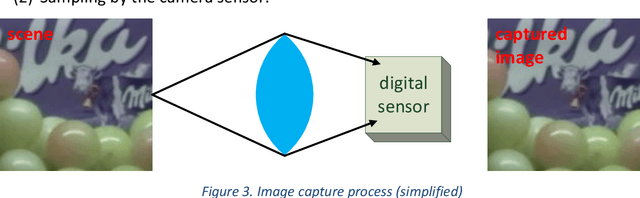
The state of the art in video super-resolution (SR) are techniques based on deep learning, but they perform poorly on real-world videos (see Figure 1). The reason is that training image-pairs are commonly created by downscaling a high-resolution image to produce a low-resolution counterpart. Deep models are therefore trained to undo downscaling and do not generalize to super-resolving real-world images. Several recent publications present techniques for improving the generalization of learning-based SR, but are all ill-suited for real-time application. We present a novel approach to synthesizing training data by simulating two digital-camera image-capture processes at different scales. Our method produces image-pairs in which both images have properties of natural images. Training an SR model using this data leads to far better generalization to real-world images and videos. In addition, deep video-SR models are characterized by a high operations-per-pixel count, which prohibits their application in real-time. We present an efficient CNN architecture, which enables real-time application of video SR on low-power edge-devices. We split the SR task into two sub-tasks: a control-flow which estimates global properties of the input video and adapts the weights and biases of a processing-CNN that performs the actual processing. Since the process-CNN is tailored to the statistics of the input, its capacity kept low, while retaining effectivity. Also, since video-statistics evolve slowly, the control-flow operates at a much lower rate than the video frame-rate. This reduces the overall computational load by as much as two orders of magnitude. This framework of decoupling the adaptivity of the algorithm from the pixel processing, can be applied in a large family of real-time video enhancement applications, e.g., video denoising, local tone-mapping, stabilization, etc.
* Technical report; accompanying a poster appearing in ICCP 2021
Deep Interactive Motion Prediction and Planning: Playing Games with Motion Prediction Models
Apr 05, 2022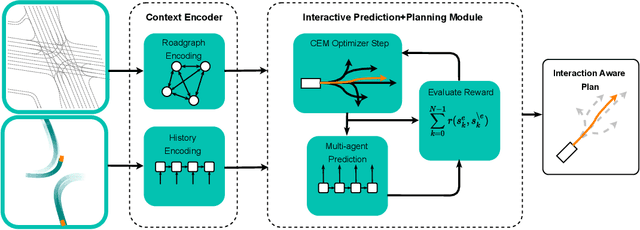

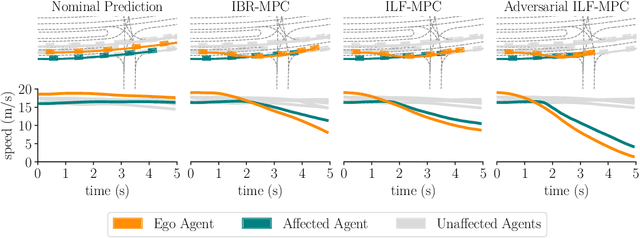
In most classical Autonomous Vehicle (AV) stacks, the prediction and planning layers are separated, limiting the planner to react to predictions that are not informed by the planned trajectory of the AV. This work presents a module that tightly couples these layers via a game-theoretic Model Predictive Controller (MPC) that uses a novel interactive multi-agent neural network policy as part of its predictive model. In our setting, the MPC planner considers all the surrounding agents by informing the multi-agent policy with the planned state sequence. Fundamental to the success of our method is the design of a novel multi-agent policy network that can steer a vehicle given the state of the surrounding agents and the map information. The policy network is trained implicitly with ground-truth observation data using backpropagation through time and a differentiable dynamics model to roll out the trajectory forward in time. Finally, we show that our multi-agent policy network learns to drive while interacting with the environment, and, when combined with the game-theoretic MPC planner, can successfully generate interactive behaviors.
Long-term Control for Dialogue Generation: Methods and Evaluation
May 15, 2022
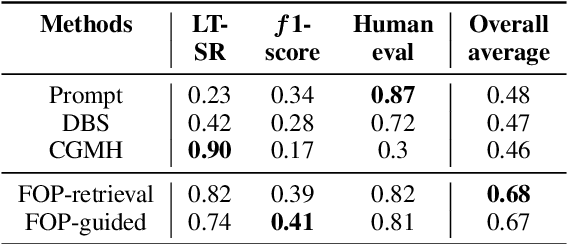
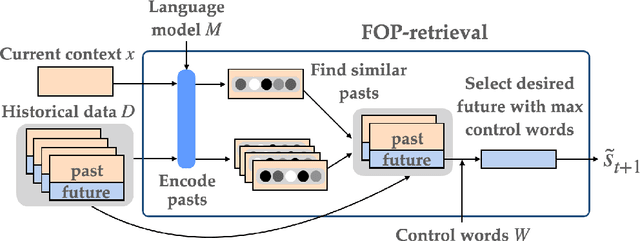
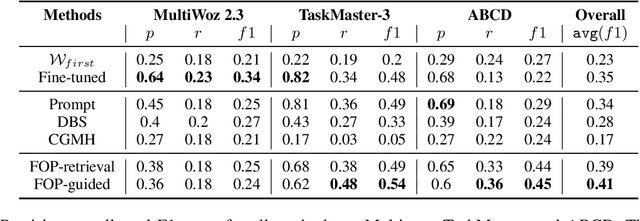
Current approaches for controlling dialogue response generation are primarily focused on high-level attributes like style, sentiment, or topic. In this work, we focus on constrained long-term dialogue generation, which involves more fine-grained control and requires a given set of control words to appear in generated responses. This setting requires a model to not only consider the generation of these control words in the immediate context, but also produce utterances that will encourage the generation of the words at some time in the (possibly distant) future. We define the problem of constrained long-term control for dialogue generation, identify gaps in current methods for evaluation, and propose new metrics that better measure long-term control. We also propose a retrieval-augmented method that improves performance of long-term controlled generation via logit modification techniques. We show through experiments on three task-oriented dialogue datasets that our metrics better assess dialogue control relative to current alternatives and that our method outperforms state-of-the-art constrained generation baselines.