 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Anytime Learning of Markov Decision Processes
May 31, 2022
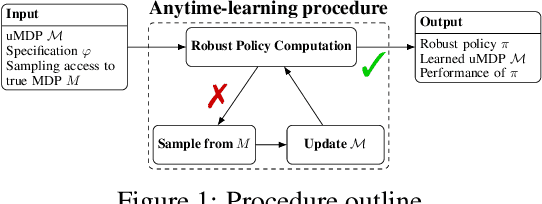
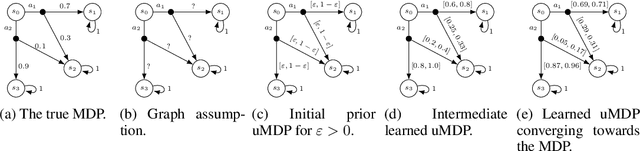
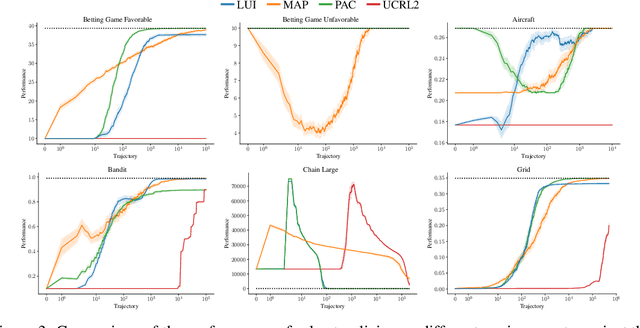
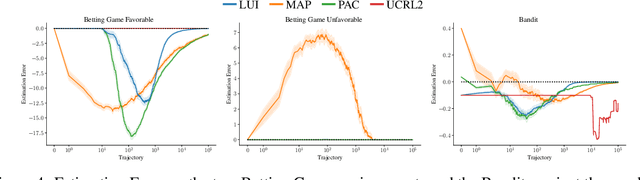
Markov decision processes (MDPs) are formal models commonly used in sequential decision-making. MDPs capture the stochasticity that may arise, for instance, from imprecise actuators via probabilities in the transition function. However, in data-driven applications, deriving precise probabilities from (limited) data introduces statistical errors that may lead to unexpected or undesirable outcomes. Uncertain MDPs (uMDPs) do not require precise probabilities but instead use so-called uncertainty sets in the transitions, accounting for such limited data. Tools from the formal verification community efficiently compute robust policies that provably adhere to formal specifications, like safety constraints, under the worst-case instance in the uncertainty set. We continuously learn the transition probabilities of an MDP in a robust anytime-learning approach that combines a dedicated Bayesian inference scheme with the computation of robust policies. In particular, our method (1) approximates probabilities as intervals, (2) adapts to new data that may be inconsistent with an intermediate model, and (3) may be stopped at any time to compute a robust policy on the uMDP that faithfully captures the data so far. We show the effectiveness of our approach and compare it to robust policies computed on uMDPs learned by the UCRL2 reinforcement learning algorithm in an experimental evaluation on several benchmarks.
Deep-learning-enabled Brain Hemodynamic Mapping Using Resting-state fMRI
Apr 25, 2022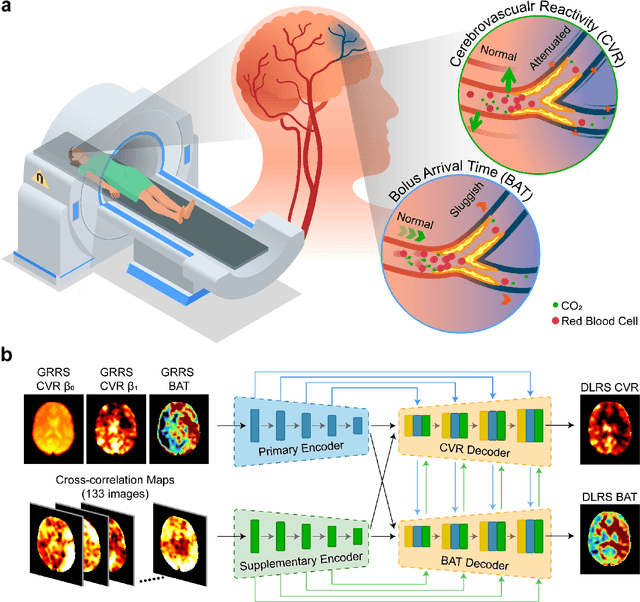
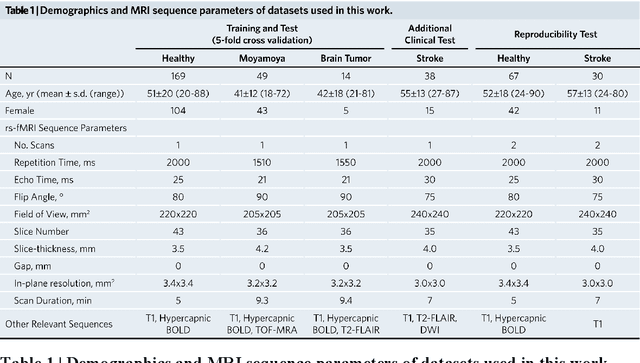
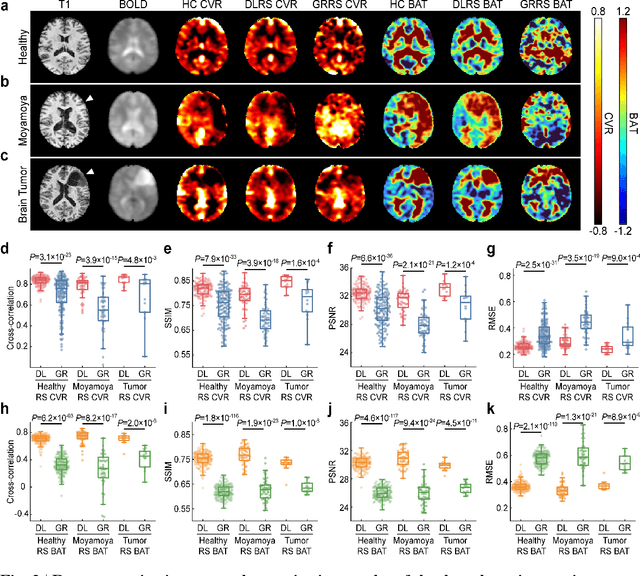
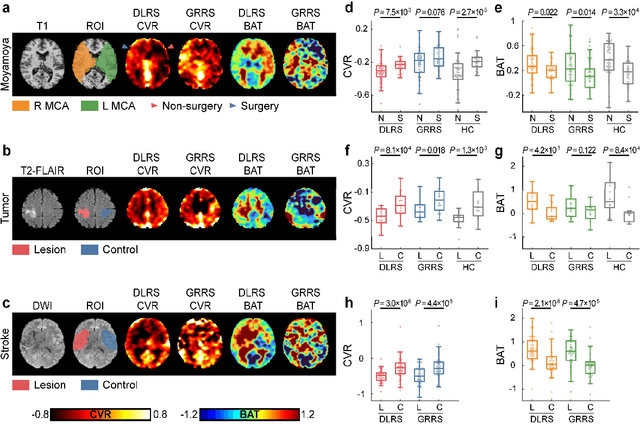
Cerebrovascular disease is a leading cause of death globally. Prevention and early intervention are known to be the most effective forms of its management. Non-invasive imaging methods hold great promises for early stratification, but at present lack the sensitivity for personalized prognosis. Resting-state functional magnetic resonance imaging (rs-fMRI), a powerful tool previously used for mapping neural activity, is available in most hospitals. Here we show that rs-fMRI can be used to map cerebral hemodynamic function and delineate impairment. By exploiting time variations in breathing pattern during rs-fMRI, deep learning enables reproducible mapping of cerebrovascular reactivity (CVR) and bolus arrive time (BAT) of the human brain using resting-state CO2 fluctuations as a natural 'contrast media'. The deep-learning network was trained with CVR and BAT maps obtained with a reference method of CO2-inhalation MRI, which included data from young and older healthy subjects and patients with Moyamoya disease and brain tumors. We demonstrate the performance of deep-learning cerebrovascular mapping in the detection of vascular abnormalities, evaluation of revascularization effects, and vascular alterations in normal aging. In addition, cerebrovascular maps obtained with the proposed method exhibited excellent reproducibility in both healthy volunteers and stroke patients. Deep-learning resting-state vascular imaging has the potential to become a useful tool in clinical cerebrovascular imaging.
Deep Reinforcement Learning for Radio Resource Allocation in NOMA-based Remote State Estimation
May 24, 2022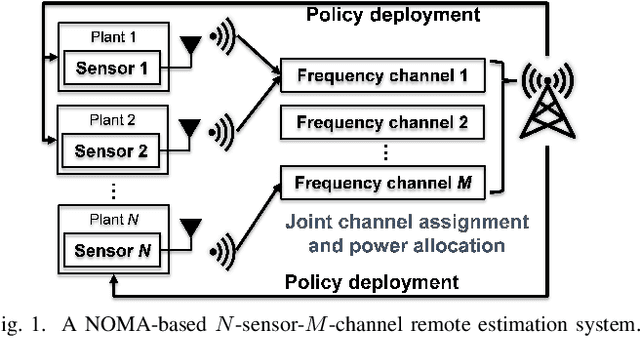
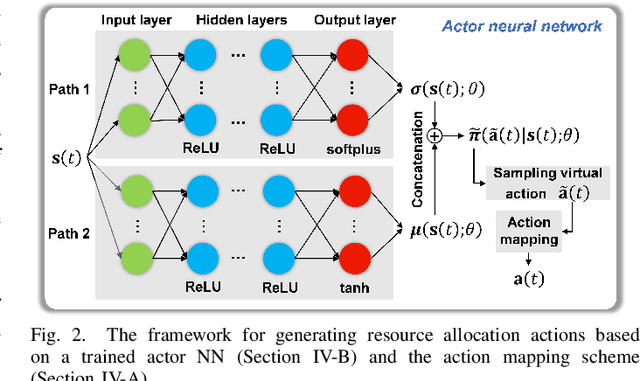
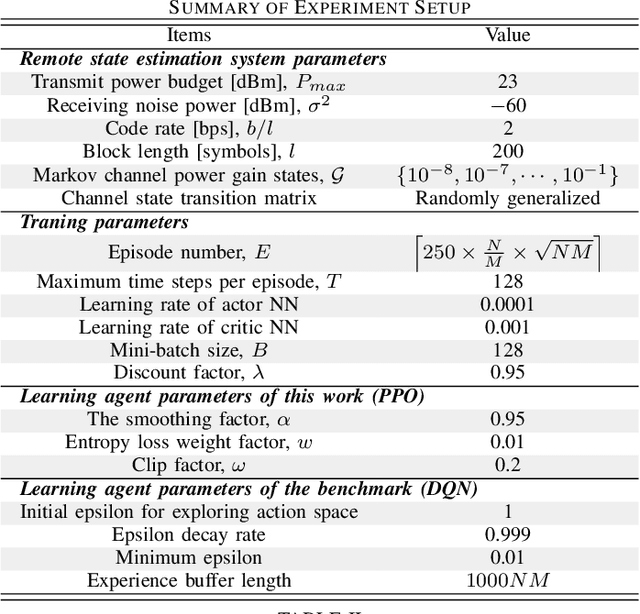
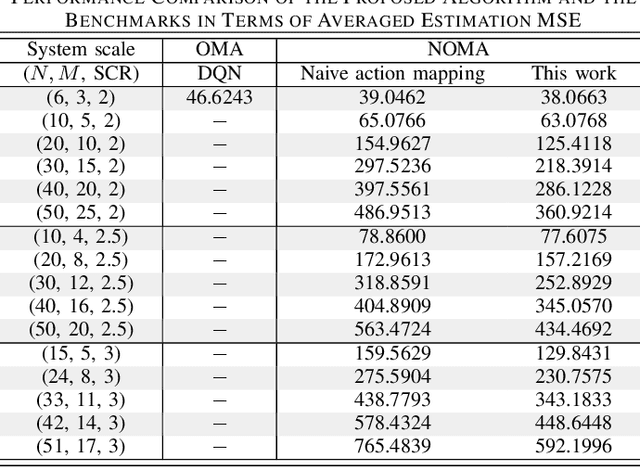
Remote state estimation, where many sensors send their measurements of distributed dynamic plants to a remote estimator over shared wireless resources, is essential for mission-critical applications of Industry 4.0. Most of the existing works on remote state estimation assumed orthogonal multiple access and the proposed dynamic radio resource allocation algorithms can only work for very small-scale settings. In this work, we consider a remote estimation system with non-orthogonal multiple access. We formulate a novel dynamic resource allocation problem for achieving the minimum overall long-term average estimation mean-square error. Both the estimation quality state and the channel quality state are taken into account for decision making at each time. The problem has a large hybrid discrete and continuous action space for joint channel assignment and power allocation. We propose a novel action-space compression method and develop an advanced deep reinforcement learning algorithm to solve the problem. Numerical results show that our algorithm solves the resource allocation problem effectively, presents much better scalability than the literature, and provides significant performance gain compared to some benchmarks.
A Meta Reinforcement Learning Approach for Predictive Autoscaling in the Cloud
May 31, 2022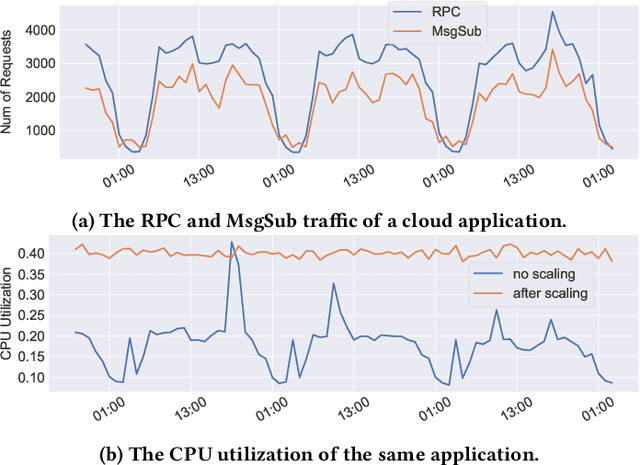

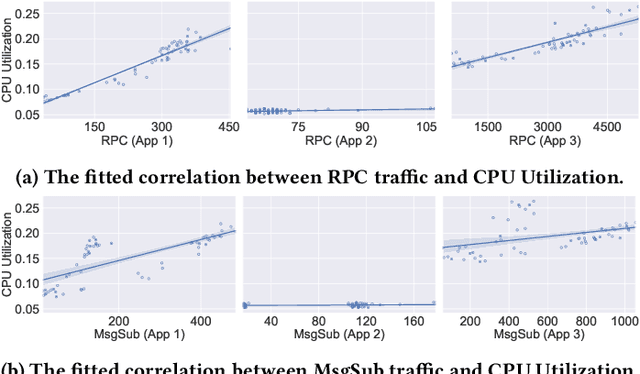

Predictive autoscaling (autoscaling with workload forecasting) is an important mechanism that supports autonomous adjustment of computing resources in accordance with fluctuating workload demands in the Cloud. In recent works, Reinforcement Learning (RL) has been introduced as a promising approach to learn the resource management policies to guide the scaling actions under the dynamic and uncertain cloud environment. However, RL methods face the following challenges in steering predictive autoscaling, such as lack of accuracy in decision-making, inefficient sampling and significant variability in workload patterns that may cause policies to fail at test time. To this end, we propose an end-to-end predictive meta model-based RL algorithm, aiming to optimally allocate resource to maintain a stable CPU utilization level, which incorporates a specially-designed deep periodic workload prediction model as the input and embeds the Neural Process to guide the learning of the optimal scaling actions over numerous application services in the Cloud. Our algorithm not only ensures the predictability and accuracy of the scaling strategy, but also enables the scaling decisions to adapt to the changing workloads with high sample efficiency. Our method has achieved significant performance improvement compared to the existing algorithms and has been deployed online at Alipay, supporting the autoscaling of applications for the world-leading payment platform.
A Data-Efficient Model-Based Learning Framework for the Closed-Loop Control of Continuum Robots
Apr 22, 2022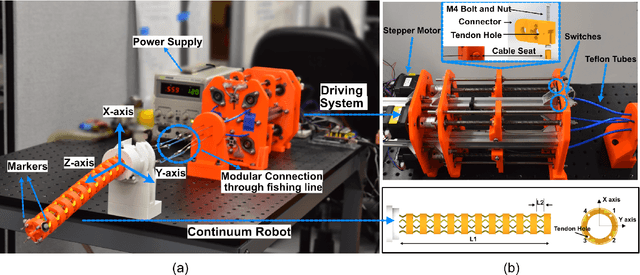
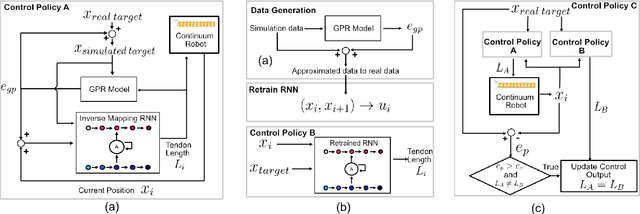
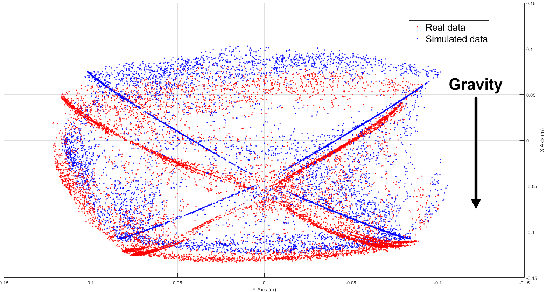
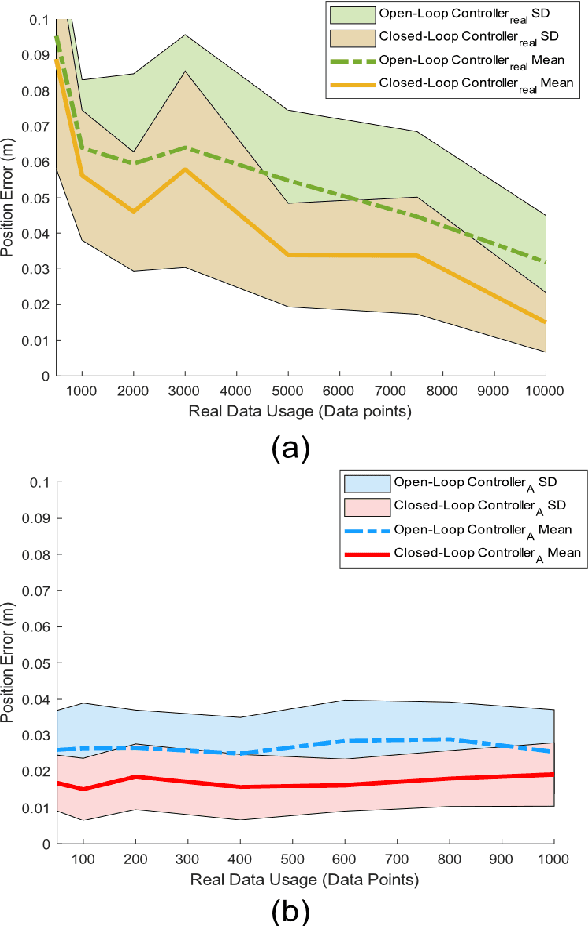
Traditional dynamic models of continuum robots are in general computationally expensive and not suitable for real-time control. Recent approaches using learning-based methods to approximate the dynamic model of continuum robots for control have been promising, although real data hungry -- which may cause potential damage to robots and be time consuming -- and getting poorer performance when trained with simulation data only. This paper presents a model-based learning framework for continuum robot closed-loop control that, by combining simulation and real data, shows to require only 100 real data to outperform a real-data-only controller trained using up to 10000 points. The introduced data-efficient framework with three control policies has utilized a Gaussian process regression (GPR) and a recurrent neural network (RNN). Control policy A uses a GPR model and a RNN trained in simulation to optimize control outputs for simulated targets; control policy B retrains the RNN in policy A with data generated from the GPR model to adapt to real robot physics; control policy C utilizes policy A and B to form a hybrid policy. Using a continuum robot with soft spines, we show that our approach provides an efficient framework to bridge the sim-to-real gap in model-based learning for continuum robots.
Benchmarking Domain Generalization on EEG-based Emotion Recognition
Apr 18, 2022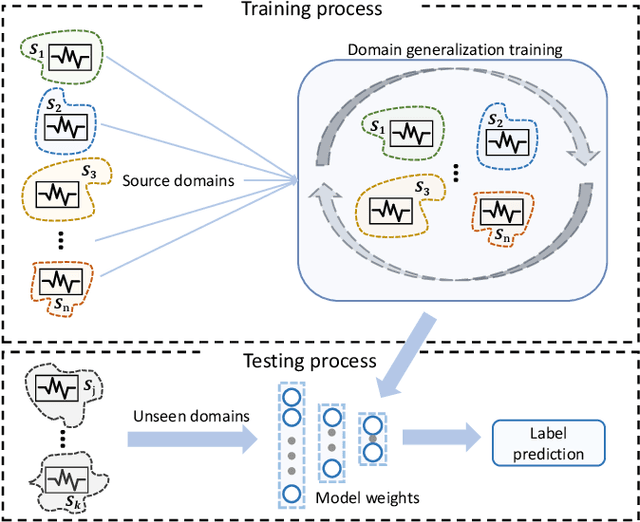
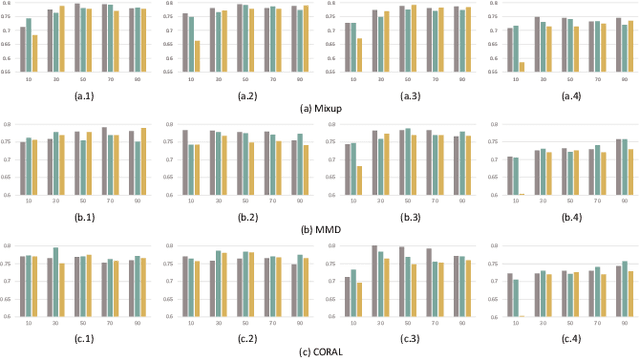
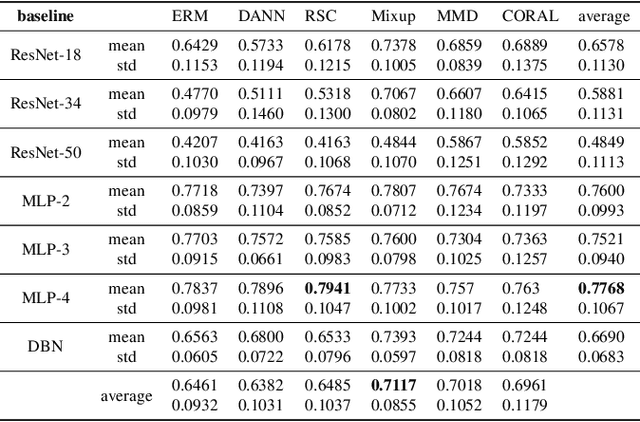
Electroencephalography (EEG) based emotion recognition has demonstrated tremendous improvement in recent years. Specifically, numerous domain adaptation (DA) algorithms have been exploited in the past five years to enhance the generalization of emotion recognition models across subjects. The DA methods assume that calibration data (although unlabeled) exists in the target domain (new user). However, this assumption conflicts with the application scenario that the model should be deployed without the time-consuming calibration experiments. We argue that domain generalization (DG) is more reasonable than DA in these applications. DG learns how to generalize to unseen target domains by leveraging knowledge from multiple source domains, which provides a new possibility to train general models. In this paper, we for the first time benchmark state-of-the-art DG algorithms on EEG-based emotion recognition. Since convolutional neural network (CNN), deep brief network (DBN) and multilayer perceptron (MLP) have been proved to be effective emotion recognition models, we use these three models as solid baselines. Experimental results show that DG achieves an accuracy of up to 79.41\% on the SEED dataset for recognizing three emotions, indicting the potential of DG in zero-training emotion recognition when multiple sources are available.
GSA-Forecaster: Forecasting Graph-Based Time-Dependent Data with Graph Sequence Attention
Apr 13, 2021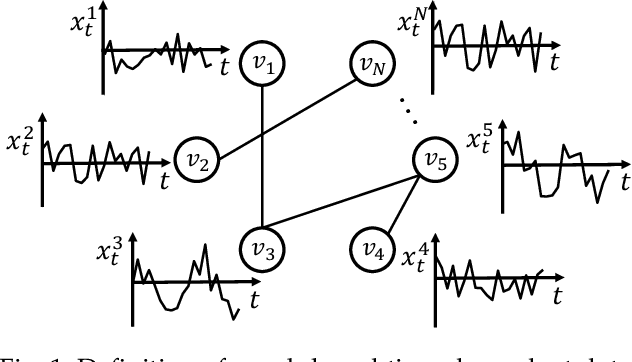

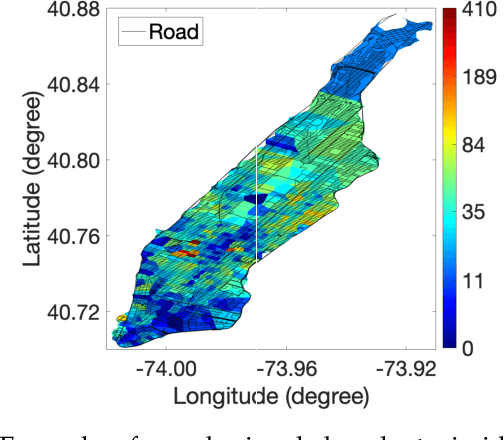

Forecasting graph-based time-dependent data has many practical applications. This task is challenging as models need not only to capture spatial dependency and temporal dependency within the data, but also to leverage useful auxiliary information for accurate predictions. In this paper, we analyze limitations of state-of-the-art models on dealing with temporal dependency. To address this limitation, we propose GSA-Forecaster, a new deep learning model for forecasting graph-based time-dependent data. GSA-Forecaster leverages graph sequence attention (GSA), a new attention mechanism proposed in this paper, for effectively capturing temporal dependency. GSA-Forecaster embeds the graph structure of the data into its architecture to address spatial dependency. GSA-Forecaster also accounts for auxiliary information to further improve predictions. We evaluate GSA-Forecaster with large-scale real-world graph-based time-dependent data and demonstrate its effectiveness over state-of-the-art models with 6.7% RMSE and 5.8% MAPE reduction.
Day-to-Night Image Synthesis for Training Nighttime Neural ISPs
Jun 06, 2022
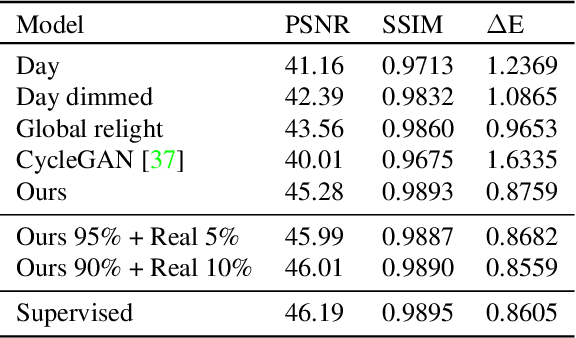

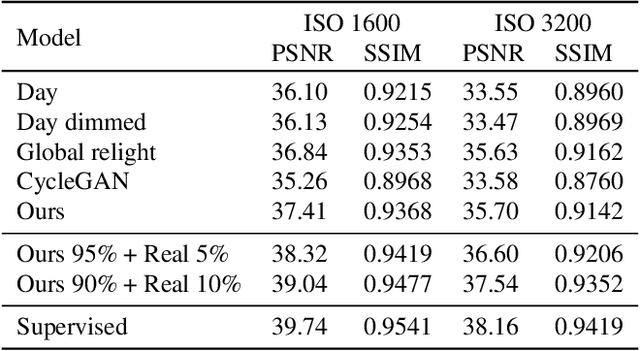
Many flagship smartphone cameras now use a dedicated neural image signal processor (ISP) to render noisy raw sensor images to the final processed output. Training nightmode ISP networks relies on large-scale datasets of image pairs with: (1) a noisy raw image captured with a short exposure and a high ISO gain; and (2) a ground truth low-noise raw image captured with a long exposure and low ISO that has been rendered through the ISP. Capturing such image pairs is tedious and time-consuming, requiring careful setup to ensure alignment between the image pairs. In addition, ground truth images are often prone to motion blur due to the long exposure. To address this problem, we propose a method that synthesizes nighttime images from daytime images. Daytime images are easy to capture, exhibit low-noise (even on smartphone cameras) and rarely suffer from motion blur. We outline a processing framework to convert daytime raw images to have the appearance of realistic nighttime raw images with different levels of noise. Our procedure allows us to easily produce aligned noisy and clean nighttime image pairs. We show the effectiveness of our synthesis framework by training neural ISPs for nightmode rendering. Furthermore, we demonstrate that using our synthetic nighttime images together with small amounts of real data (e.g., 5% to 10%) yields performance almost on par with training exclusively on real nighttime images. Our dataset and code are available at https://github.com/SamsungLabs/day-to-night.
Streaming Solutions for Time-Varying Optimization Problems
Nov 03, 2021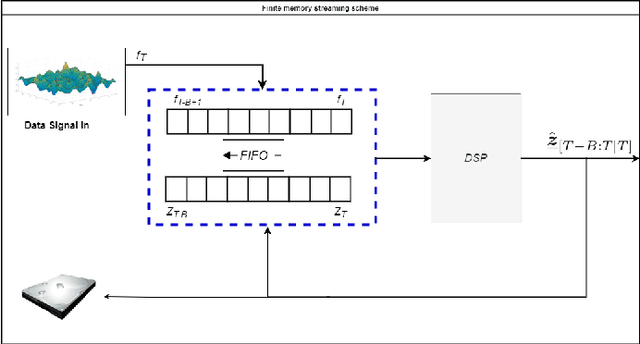
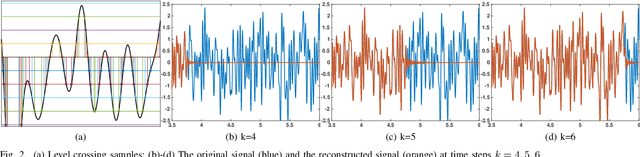
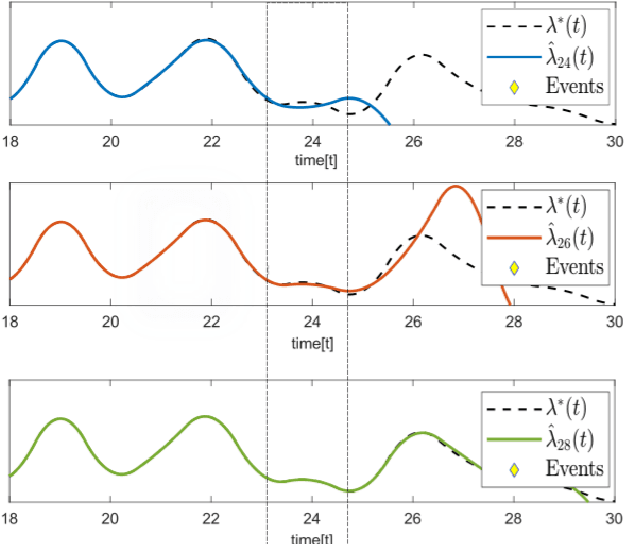
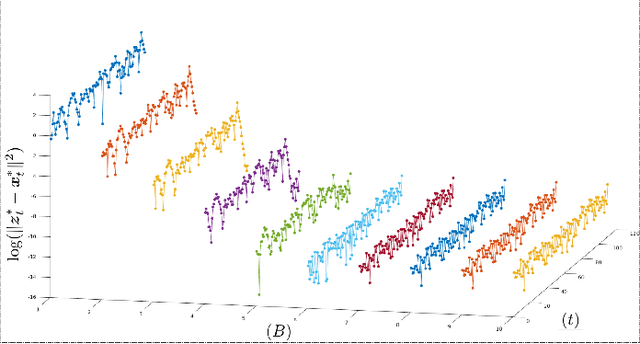
This paper studies streaming optimization problems that have objectives of the form $ \sum_{t=1}^Tf(\mathbf{x}_{t-1},\mathbf{x}_t)$. In particular, we are interested in how the solution $\hat{\mathbf{x} }_{t|T}$ for the $t$th frame of variables changes as $T$ increases. While incrementing $T$ and adding a new functional and a new set of variables does in general change the solution everywhere, we give conditions under which $\hat{\mathbf{x} }_{t|T}$ converges to a limit point $\mathbf{x}^*_t$ at a linear rate as $T\rightarrow\infty$. As a consequence, we are able to derive theoretical guarantees for algorithms with limited memory, showing that limiting the solution updates to only a small number of frames in the past sacrifices almost nothing in accuracy. We also present a new efficient Newton online algorithm (NOA), inspired by these results, that updates the solution with fixed complexity of $ \mathcal{O}( {3Bn^3})$, independent of $T$, where $B$ corresponds to how far in the past the variables are updated, and $n$ is the size of a single block-vector. Two streaming optimization examples, online reconstruction from non-uniform samples and non-homogeneous Poisson intensity estimation, support the theoretical results and show how the algorithm can be used in practice.
Minimal Explanations for Neural Network Predictions
May 19, 2022

Explaining neural network predictions is known to be a challenging problem. In this paper, we propose a novel approach which can be effectively exploited, either in isolation or in combination with other methods, to enhance the interpretability of neural model predictions. For a given input to a trained neural model, our aim is to compute a smallest set of input features so that the model prediction changes when these features are disregarded by setting them to an uninformative baseline value. While computing such minimal explanations is computationally intractable in general for fully-connected neural networks, we show that the problem becomes solvable in polynomial time by a greedy algorithm under mild assumptions on the network's activation functions. We then show that our tractability result extends seamlessly to more advanced neural architectures such as convolutional and graph neural networks. We conduct experiments to showcase the capability of our method for identifying the input features that are essential to the model's prediction.