 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revitalize Region Feature for Democratizing Video-Language Pre-training
Mar 19, 2022
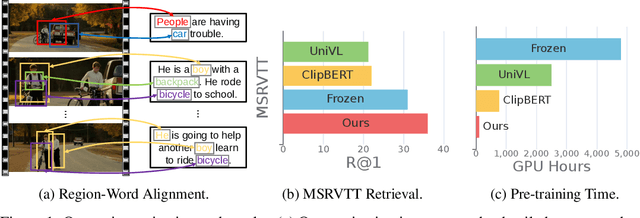
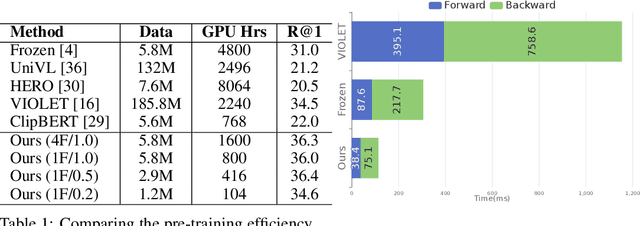
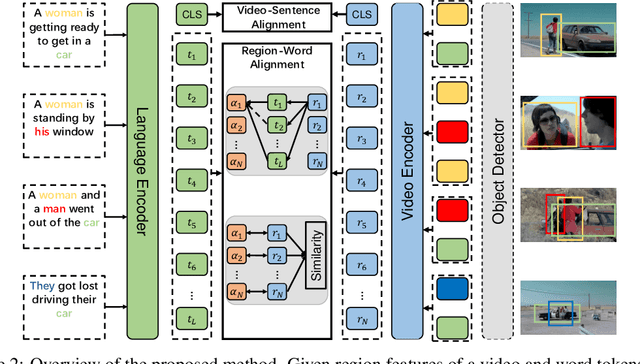

Recent dominant methods for video-language pre-training (VLP) learn transferable representations from the raw pixels in an end-to-end manner to achieve advanced performance on downstream video-language tasks. Despite the impressive results, VLP research becomes extremely expensive with the need for massive data and a long training time, preventing further explorations. In this work, we revitalize region features of sparsely sampled video clips to significantly reduce both spatial and temporal visual redundancy towards democratizing VLP research at the same time achieving state-of-the-art results. Specifically, to fully explore the potential of region features, we introduce a novel bidirectional region-word alignment regularization that properly optimizes the fine-grained relations between regions and certain words in sentences, eliminating the domain/modality disconnections between pre-extracted region features and text. Extensive results of downstream text-to-video retrieval and video question answering tasks on seven datasets demonstrate the superiority of our method on both effectiveness and efficiency, e.g., our method achieves competing results with 80\% fewer data and 85\% less pre-training time compared to the most efficient VLP method so far. The code will be available at \url{https://github.com/showlab/DemoVLP}.
Fine-tuning Language Models over Slow Networks using Activation Compression with Guarantees
Jun 02, 2022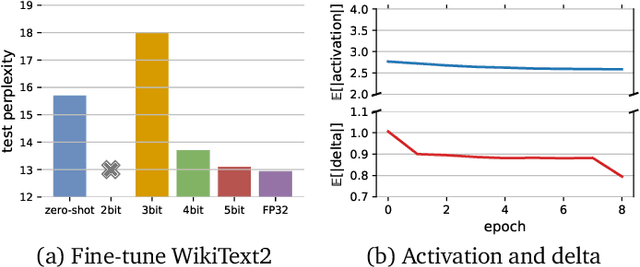
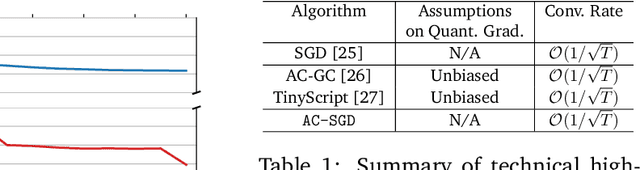
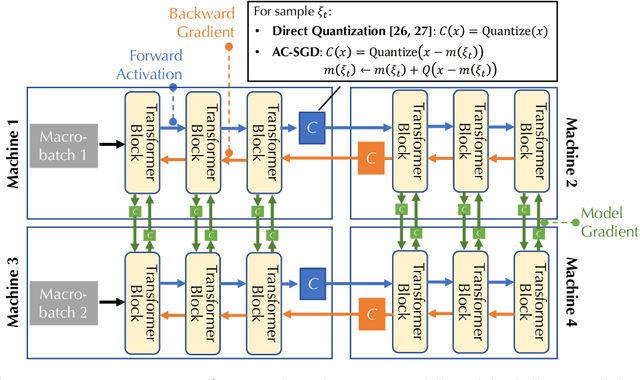

Communication compression is a crucial technique for modern distributed learning systems to alleviate their communication bottlenecks over slower networks. Despite recent intensive studies of gradient compression for data parallel-style training, compressing the activations for models trained with pipeline parallelism is still an open problem. In this paper, we propose AC-SGD, a novel activation compression algorithm for communication-efficient pipeline parallelism training over slow networks. Different from previous efforts in activation compression, instead of compressing activation values directly, AC-SGD compresses the changes of the activations. This allows us to show, to the best of our knowledge for the first time, that one can still achieve $O(1/\sqrt{T})$ convergence rate for non-convex objectives under activation compression, without making assumptions on gradient unbiasedness that do not hold for deep learning models with non-linear activation functions.We then show that AC-SGD can be optimized and implemented efficiently, without additional end-to-end runtime overhead.We evaluated AC-SGD to fine-tune language models with up to 1.5 billion parameters, compressing activations to 2-4 bits.AC-SGD provides up to 4.3X end-to-end speed-up in slower networks, without sacrificing model quality. Moreover, we also show that AC-SGD can be combined with state-of-the-art gradient compression algorithms to enable "end-to-end communication compression: All communications between machines, including model gradients, forward activations, and backward gradients are compressed into lower precision.This provides up to 4.9X end-to-end speed-up, without sacrificing model quality.
Simple and Effective Relation-based Embedding Propagation for Knowledge Representation Learning
May 13, 2022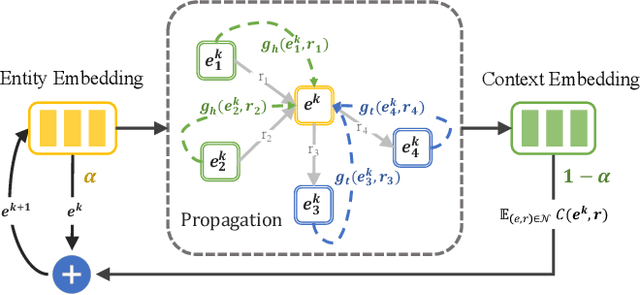

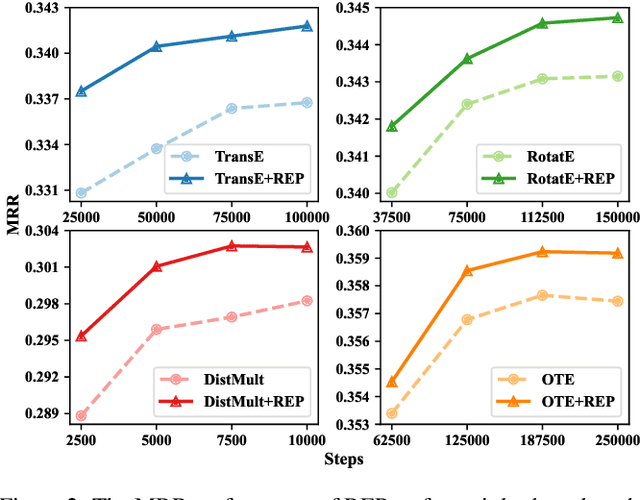
Relational graph neural networks have garnered particular attention to encode graph context in knowledge graphs (KGs). Although they achieved competitive performance on small KGs, how to efficiently and effectively utilize graph context for large KGs remains an open problem. To this end, we propose the Relation-based Embedding Propagation (REP) method. It is a post-processing technique to adapt pre-trained KG embeddings with graph context. As relations in KGs are directional, we model the incoming head context and the outgoing tail context separately. Accordingly, we design relational context functions with no external parameters. Besides, we use averaging to aggregate context information, making REP more computation-efficient. We theoretically prove that such designs can avoid information distortion during propagation. Extensive experiments also demonstrate that REP has significant scalability while improving or maintaining prediction quality. Notably, it averagely brings about 10% relative improvement to triplet-based embedding methods on OGBL-WikiKG2 and takes 5%-83% time to achieve comparable results as the state-of-the-art GC-OTE.
Arrhythmia Classifier using Binarized Convolutional Neural Network for Resource-Constrained Devices
May 13, 2022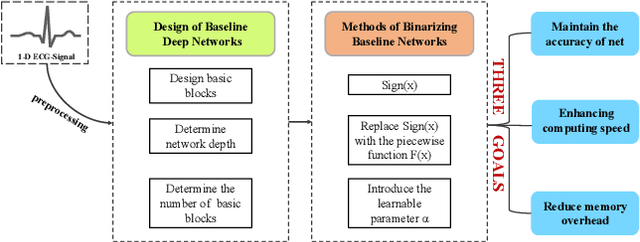
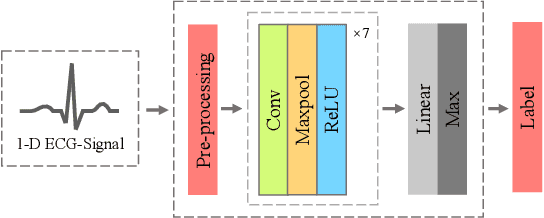
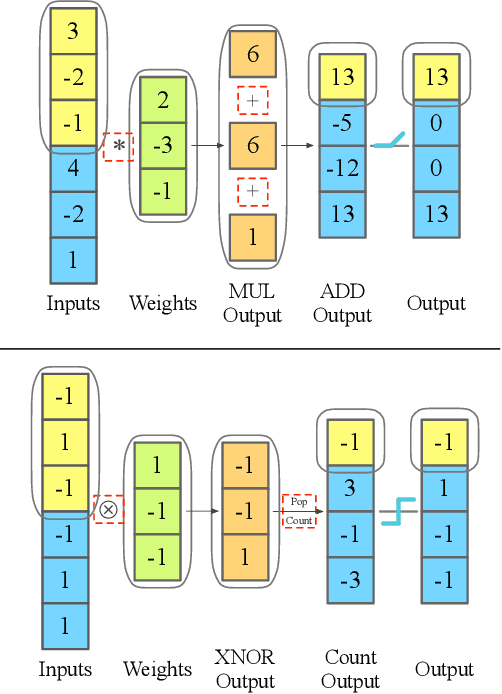
Monitoring electrocardiogram signals is of great significance for the diagnosis of arrhythmias. In recent years, deep learning and convolutional neural networks have been widely used in the classification of cardiac arrhythmias. However, the existing neural network applied to ECG signal detection usually requires a lot of computing resources, which is not friendlyF to resource-constrained equipment, and it is difficult to realize real-time monitoring. In this paper, a binarized convolutional neural network suitable for ECG monitoring is proposed, which is hardware-friendly and more suitable for use in resource-constrained wearable devices. Targeting the MIT-BIH arrhythmia database, the classifier based on this network reached an accuracy of 95.67% in the five-class test. Compared with the proposed baseline full-precision network with an accuracy of 96.45%, it is only 0.78% lower. Importantly, it achieves 12.65 times the computing speedup, 24.8 times the storage compression ratio, and only requires a quarter of the memory overhead.
Fully Adaptive Composition in Differential Privacy
Mar 10, 2022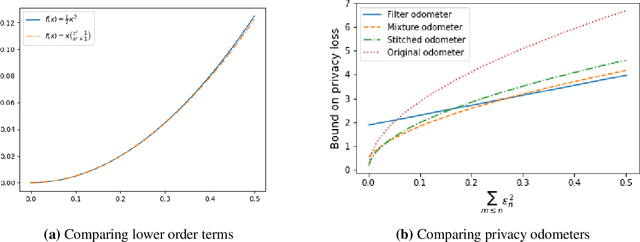
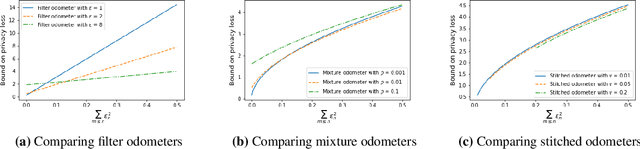
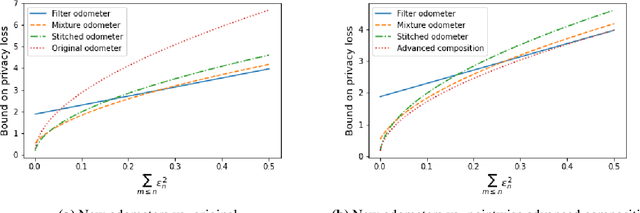
Composition is a key feature of differential privacy. Well-known advanced composition theorems allow one to query a private database quadratically more times than basic privacy composition would permit. However, these results require that the privacy parameters of all algorithms be fixed before interacting with the data. To address this, Rogers et al. introduced fully adaptive composition, wherein both algorithms and their privacy parameters can be selected adaptively. The authors introduce two probabilistic objects to measure privacy in adaptive composition: privacy filters, which provide differential privacy guarantees for composed interactions, and privacy odometers, time-uniform bounds on privacy loss. There are substantial gaps between advanced composition and existing filters and odometers. First, existing filters place stronger assumptions on the algorithms being composed. Second, these odometers and filters suffer from large constants, making them impractical. We construct filters that match the tightness of advanced composition, including constants, despite allowing for adaptively chosen privacy parameters. We also construct several general families of odometers. These odometers can match the tightness of advanced composition at an arbitrary, preselected point in time, or at all points in time simultaneously, up to a doubly-logarithmic factor. We obtain our results by leveraging recent advances in time-uniform martingale concentration. In sum, we show that fully adaptive privacy is obtainable at almost no loss, and conjecture that our results are essentially unimprovable (even in constants) in general.
Accelerated Policy Learning with Parallel Differentiable Simulation
Apr 14, 2022
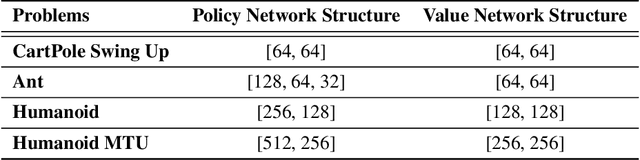
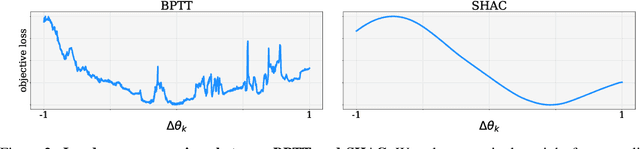
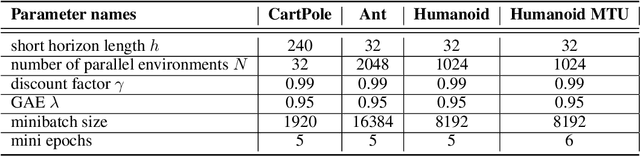
Deep reinforcement learning can generate complex control policies, but requires large amounts of training data to work effectively. Recent work has attempted to address this issue by leveraging differentiable simulators. However, inherent problems such as local minima and exploding/vanishing numerical gradients prevent these methods from being generally applied to control tasks with complex contact-rich dynamics, such as humanoid locomotion in classical RL benchmarks. In this work we present a high-performance differentiable simulator and a new policy learning algorithm (SHAC) that can effectively leverage simulation gradients, even in the presence of non-smoothness. Our learning algorithm alleviates problems with local minima through a smooth critic function, avoids vanishing/exploding gradients through a truncated learning window, and allows many physical environments to be run in parallel. We evaluate our method on classical RL control tasks, and show substantial improvements in sample efficiency and wall-clock time over state-of-the-art RL and differentiable simulation-based algorithms. In addition, we demonstrate the scalability of our method by applying it to the challenging high-dimensional problem of muscle-actuated locomotion with a large action space, achieving a greater than 17x reduction in training time over the best-performing established RL algorithm.
Ordinal-ResLogit: Interpretable Deep Residual Neural Networks for Ordered Choices
Apr 24, 2022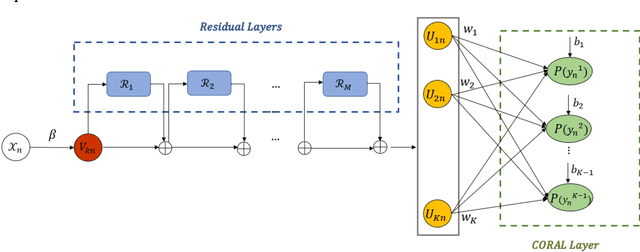
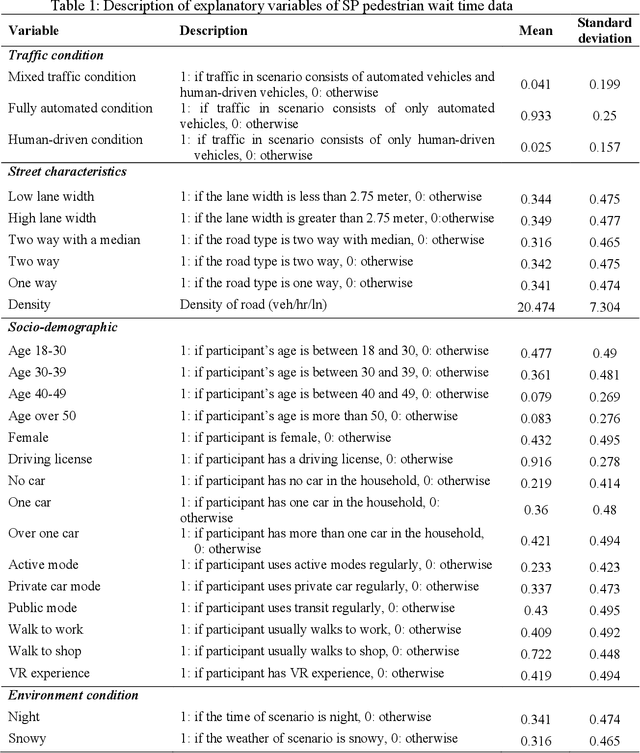
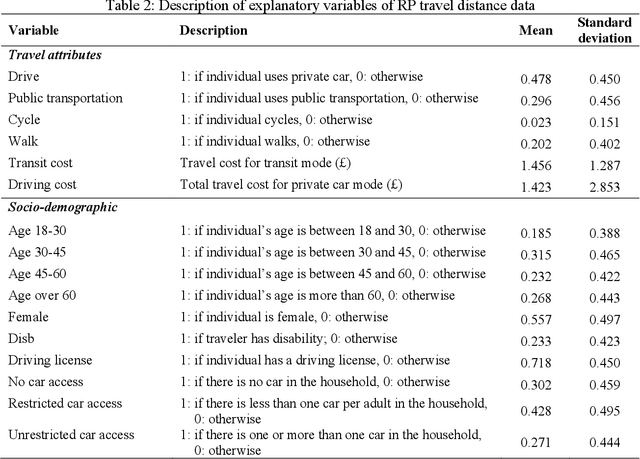
This study presents an Ordinal version of Residual Logit (Ordinal-ResLogit) model to investigate the ordinal responses. We integrate the standard ResLogit model into COnsistent RAnk Logits (CORAL) framework, classified as a binary classification algorithm, to develop a fully interpretable deep learning-based ordinal regression model. As the formulation of the Ordinal-ResLogit model enjoys the Residual Neural Networks concept, our proposed model addresses the main constraint of machine learning algorithms, known as black-box. Moreover, the Ordinal-ResLogit model, as a binary classification framework for ordinal data, guarantees consistency among binary classifiers. We showed that the resulting formulation is able to capture underlying unobserved heterogeneity from the data as well as being an interpretable deep learning-based model. Formulations for market share, substitution patterns, and elasticities are derived. We compare the performance of the Ordinal-ResLogit model with an Ordered Logit Model using a stated preference (SP) dataset on pedestrian wait time and a revealed preference (RP) dataset on travel distance. Our results show that Ordinal-ResLogit outperforms the traditional ordinal regression model for both datasets. Furthermore, the results obtained from the Ordinal-ResLogit RP model show that travel attributes such as driving and transit cost have significant effects on choosing the location of non-mandatory trips. In terms of the Ordinal-ResLogit SP model, our results highlight that the road-related variables and traffic condition are contributing factors in the prediction of pedestrian waiting time such that the mixed traffic condition significantly increases the probability of choosing longer waiting times.
Comparison of Traditional and Hybrid Time Series Models for Forecasting COVID-19 Cases
May 05, 2021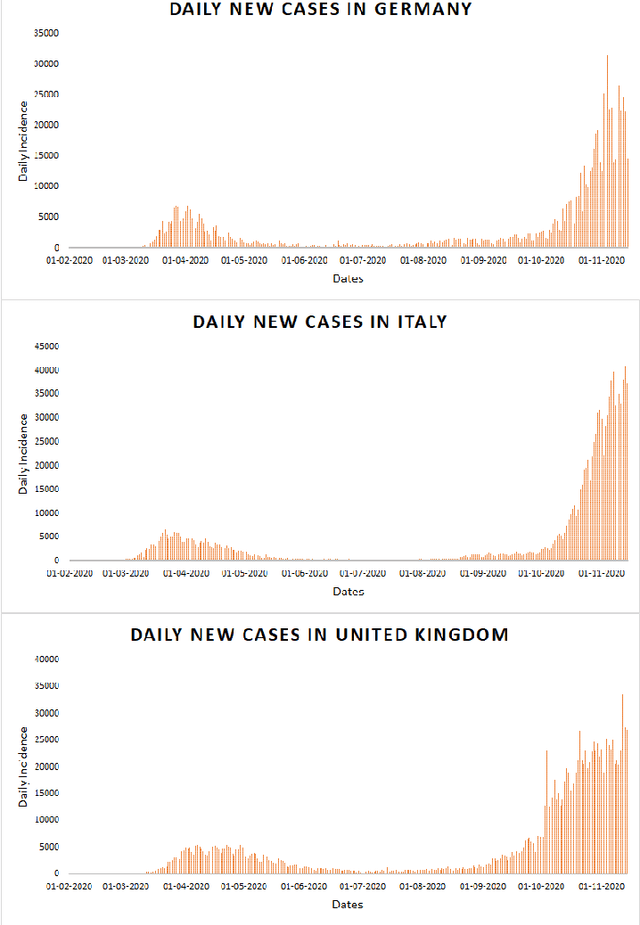
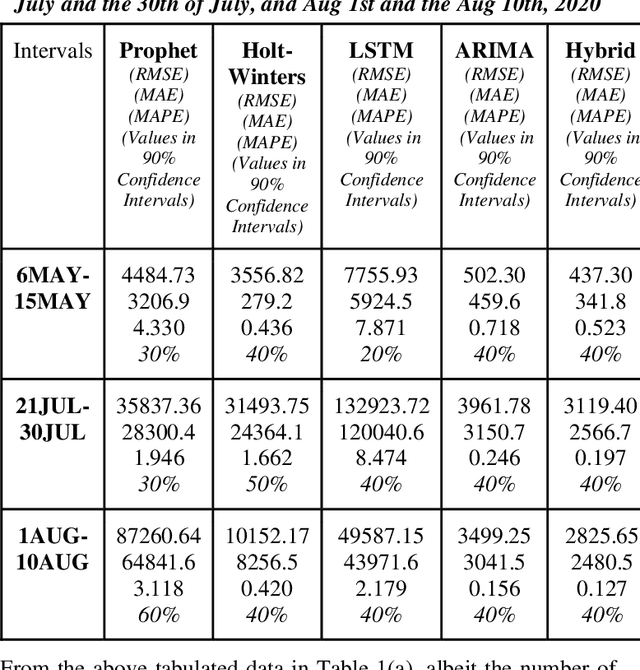
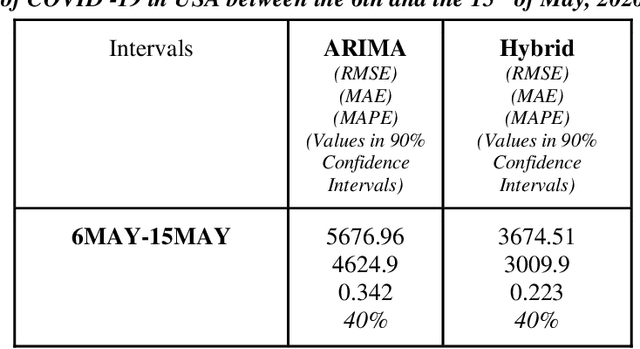
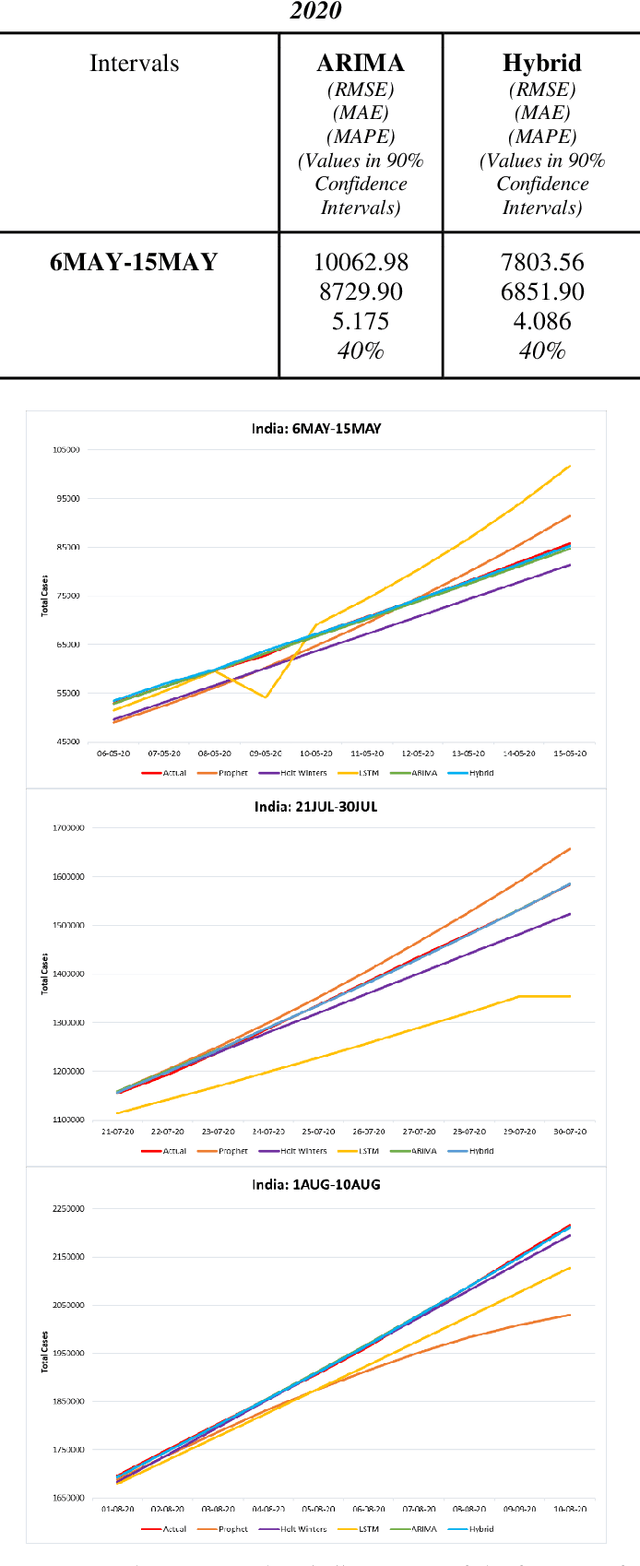
Time series forecasting methods play critical role in estimating the spread of an epidemic. The coronavirus outbreak of December 2019 has already infected millions all over the world and continues to spread on. Just when the curve of the outbreak had started to flatten, many countries have again started to witness a rise in cases which is now being referred as the 2nd wave of the pandemic. A thorough analysis of time-series forecasting models is therefore required to equip state authorities and health officials with immediate strategies for future times. This aims of the study are three-fold: (a) To model the overall trend of the spread; (b) To generate a short-term forecast of 10 days in countries with the highest incidence of confirmed cases (USA, India and Brazil); (c) To quantitatively determine the algorithm that is best suited for precise modelling of the linear and non-linear features of the time series. The comparison of forecasting models for the total cumulative cases of each country is carried out by comparing the reported data and the predicted value, and then ranking the algorithms (Prophet, Holt-Winters, LSTM, ARIMA, and ARIMA-NARNN) based on their RMSE, MAE and MAPE values. The hybrid combination of ARIMA and NARNN (Nonlinear Auto-Regression Neural Network) gave the best result among the selected models with a reduced RMSE, which proved to be almost 35.3% better than one of the most prevalent method of time-series prediction (ARIMA). The results demonstrated the efficacy of the hybrid implementation of the ARIMA-NARNN model over other forecasting methods such as Prophet, Holt Winters, LSTM, and the ARIMA model in encapsulating the linear as well as non-linear patterns of the epidemical datasets.
Mathematical Models of Human Drivers Using Artificial Risk Fields
May 24, 2022
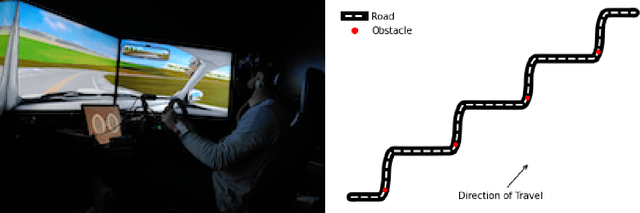
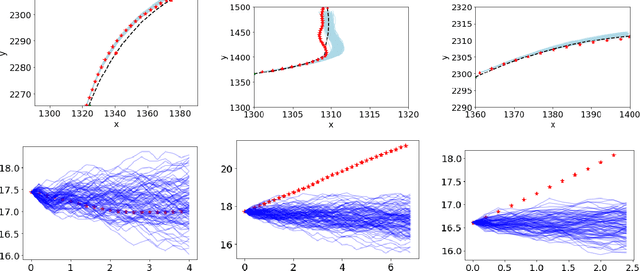
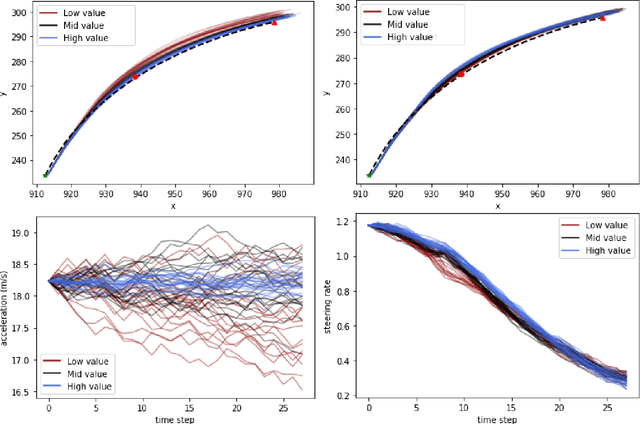
In this paper, we use the concept of artificial risk fields to predict how human operators control a vehicle in response to upcoming road situations. A risk field assigns a non-negative risk measure to the state of the system in order to model how close that state is to violating a safety property, such as hitting an obstacle or exiting the road. Using risk fields, we construct a stochastic model of the operator that maps from states to likely actions. We demonstrate our approach on a driving task wherein human subjects are asked to drive a car inside a realistic driving simulator while avoiding obstacles placed on the road. We show that the most likely risk field given the driving data is obtained by solving a convex optimization problem. Next, we apply the inferred risk fields to generate distinct driving behaviors while comparing predicted trajectories against ground truth measurements. We observe that the risk fields are excellent at predicting future trajectory distributions with high prediction accuracy for up to twenty seconds prediction horizons. At the same time, we observe some challenges such as the inability to account for how drivers choose to accelerate/decelerate based on the road conditions.
Subspace Diffusion Generative Models
May 03, 2022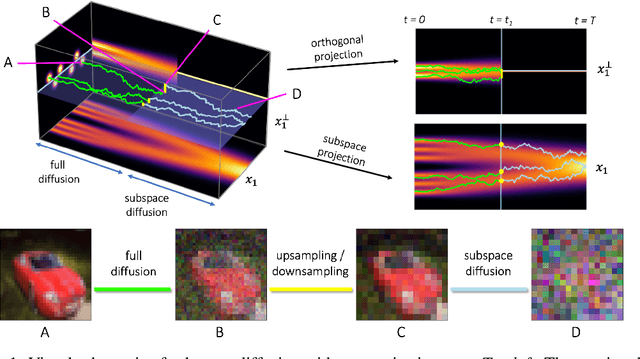
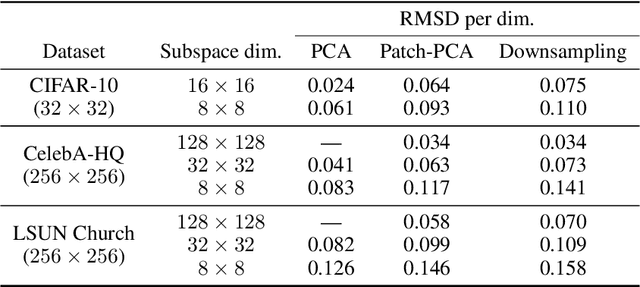
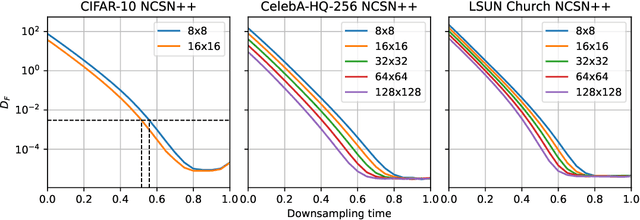

Score-based models generate samples by mapping noise to data (and vice versa) via a high-dimensional diffusion process. We question whether it is necessary to run this entire process at high dimensionality and incur all the inconveniences thereof. Instead, we restrict the diffusion via projections onto subspaces as the data distribution evolves toward noise. When applied to state-of-the-art models, our framework simultaneously improves sample quality -- reaching an FID of 2.17 on unconditional CIFAR-10 -- and reduces the computational cost of inference for the same number of denoising steps. Our framework is fully compatible with continuous-time diffusion and retains its flexible capabilities, including exact log-likelihoods and controllable generation. Code is available at https://github.com/bjing2016/subspace-diffusion.