 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RADAR: Run-time Adversarial Weight Attack Detection and Accuracy Recovery
Jan 20, 2021
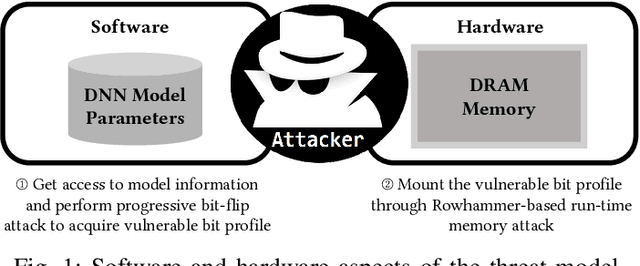
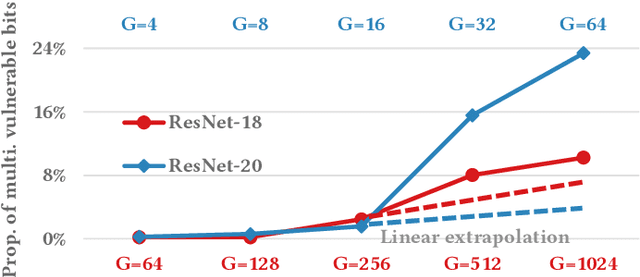
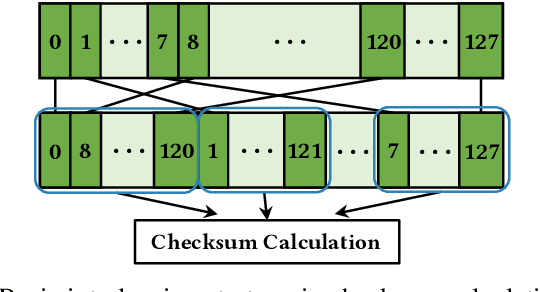
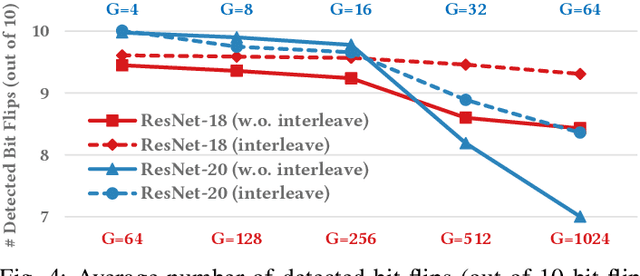
Adversarial attacks on Neural Network weights, such as the progressive bit-flip attack (PBFA), can cause a catastrophic degradation in accuracy by flipping a very small number of bits. Furthermore, PBFA can be conducted at run time on the weights stored in DRAM main memory. In this work, we propose RADAR, a Run-time adversarial weight Attack Detection and Accuracy Recovery scheme to protect DNN weights against PBFA. We organize weights that are interspersed in a layer into groups and employ a checksum-based algorithm on weights to derive a 2-bit signature for each group. At run time, the 2-bit signature is computed and compared with the securely stored golden signature to detect the bit-flip attacks in a group. After successful detection, we zero out all the weights in a group to mitigate the accuracy drop caused by malicious bit-flips. The proposed scheme is embedded in the inference computation stage. For the ResNet-18 ImageNet model, our method can detect 9.6 bit-flips out of 10 on average. For this model, the proposed accuracy recovery scheme can restore the accuracy from below 1% caused by 10 bit flips to above 69%. The proposed method has extremely low time and storage overhead. System-level simulation on gem5 shows that RADAR only adds <1% to the inference time, making this scheme highly suitable for run-time attack detection and mitigation.
License Plate Privacy in Collaborative Visual Analysis of Traffic Scenes
May 03, 2022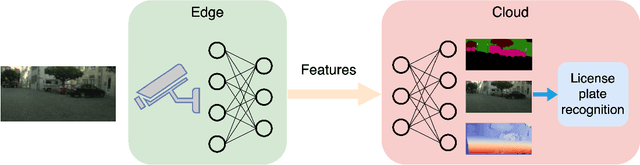
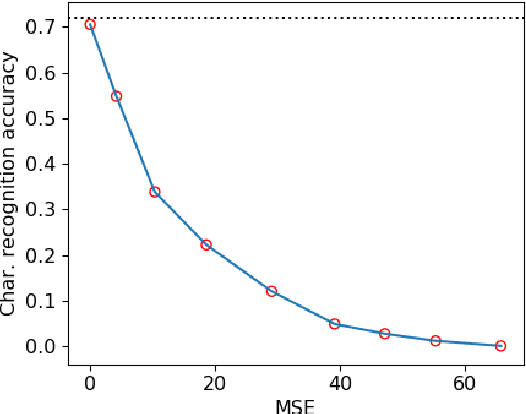
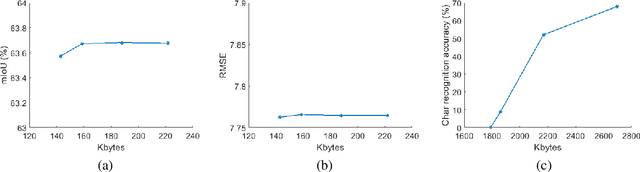

Traffic scene analysis is important for emerging technologies such as smart traffic management and autonomous vehicles. However, such analysis also poses potential privacy threats. For example, a system that can recognize license plates may construct patterns of behavior of the corresponding vehicles' owners and use that for various illegal purposes. In this paper we present a system that enables traffic scene analysis while at the same time preserving license plate privacy. The system is based on a multi-task model whose latent space is selectively compressed depending on the amount of information the specific features carry about analysis tasks and private information. Effectiveness of the proposed method is illustrated by experiments on the Cityscapes dataset, for which we also provide license plate annotations.
Simple and Effective Relation-based Embedding Propagation for Knowledge Representation Learning
May 13, 2022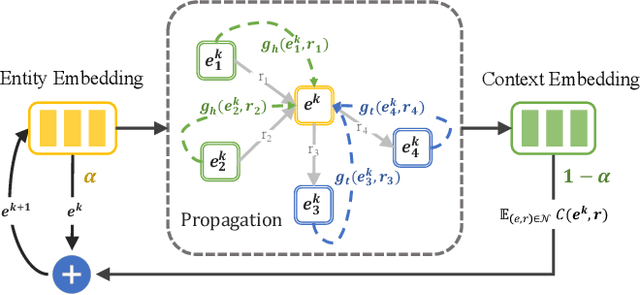

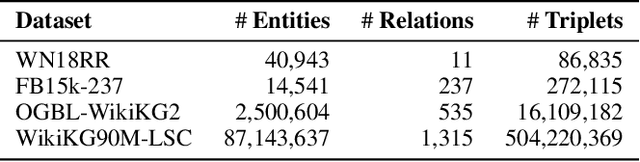
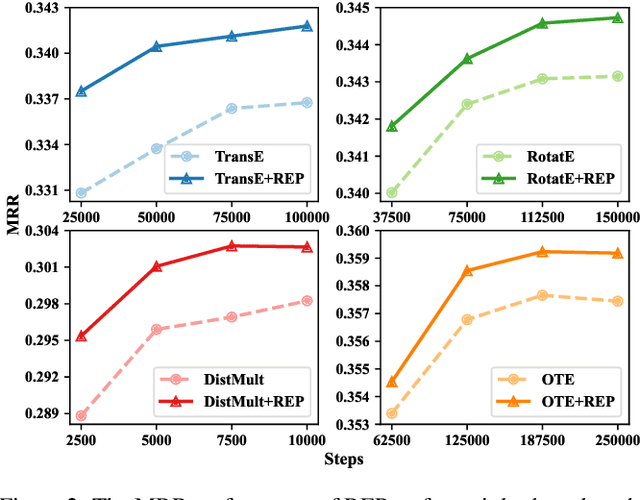
Relational graph neural networks have garnered particular attention to encode graph context in knowledge graphs (KGs). Although they achieved competitive performance on small KGs, how to efficiently and effectively utilize graph context for large KGs remains an open problem. To this end, we propose the Relation-based Embedding Propagation (REP) method. It is a post-processing technique to adapt pre-trained KG embeddings with graph context. As relations in KGs are directional, we model the incoming head context and the outgoing tail context separately. Accordingly, we design relational context functions with no external parameters. Besides, we use averaging to aggregate context information, making REP more computation-efficient. We theoretically prove that such designs can avoid information distortion during propagation. Extensive experiments also demonstrate that REP has significant scalability while improving or maintaining prediction quality. Notably, it averagely brings about 10% relative improvement to triplet-based embedding methods on OGBL-WikiKG2 and takes 5%-83% time to achieve comparable results as the state-of-the-art GC-OTE.
Long-time simulations with high fidelity on quantum hardware
Feb 08, 2021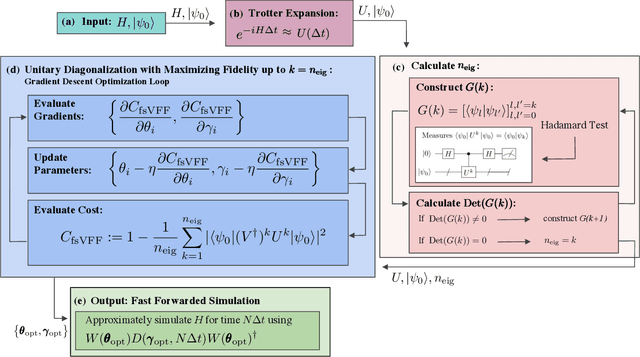
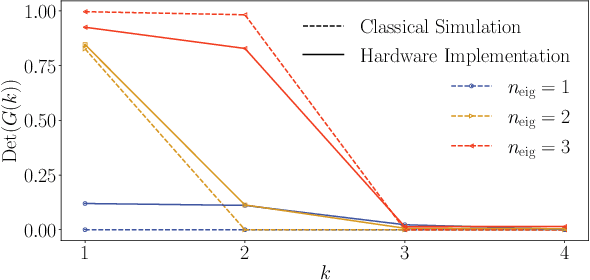

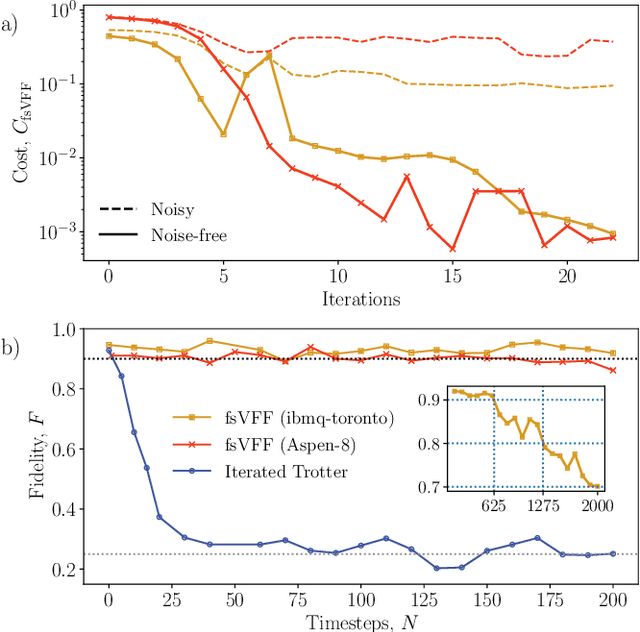
Moderate-size quantum computers are now publicly accessible over the cloud, opening the exciting possibility of performing dynamical simulations of quantum systems. However, while rapidly improving, these devices have short coherence times, limiting the depth of algorithms that may be successfully implemented. Here we demonstrate that, despite these limitations, it is possible to implement long-time, high fidelity simulations on current hardware. Specifically, we simulate an XY-model spin chain on the Rigetti and IBM quantum computers, maintaining a fidelity of at least 0.9 for over 600 time steps. This is a factor of 150 longer than is possible using the iterated Trotter method. Our simulations are performed using a new algorithm that we call the fixed state Variational Fast Forwarding (fsVFF) algorithm. This algorithm decreases the circuit depth and width required for a quantum simulation by finding an approximate diagonalization of a short time evolution unitary. Crucially, fsVFF only requires finding a diagonalization on the subspace spanned by the initial state, rather than on the total Hilbert space as with previous methods, substantially reducing the required resources.
Arrhythmia Classifier using Binarized Convolutional Neural Network for Resource-Constrained Devices
May 13, 2022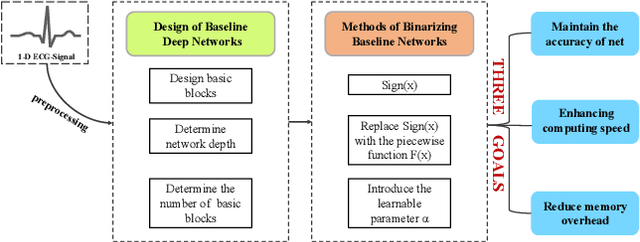
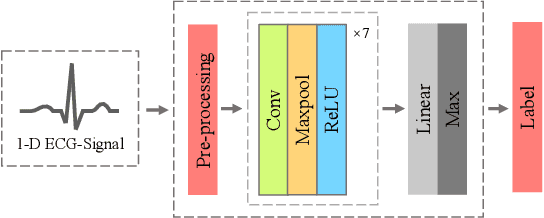
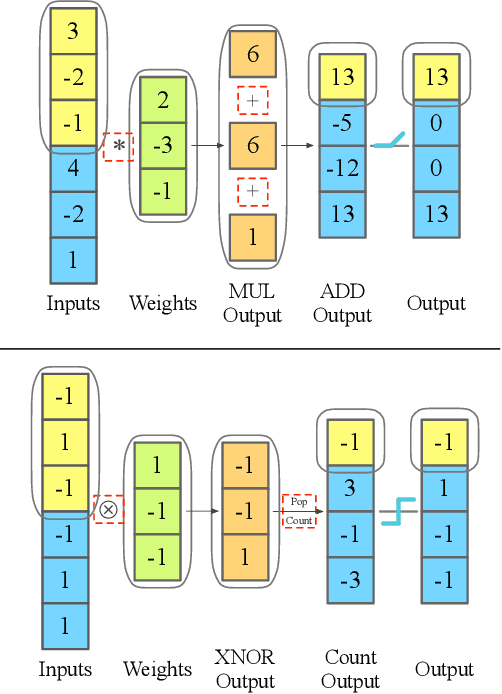
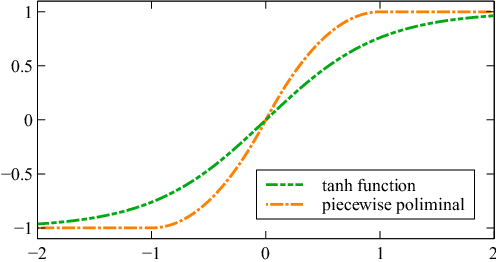
Monitoring electrocardiogram signals is of great significance for the diagnosis of arrhythmias. In recent years, deep learning and convolutional neural networks have been widely used in the classification of cardiac arrhythmias. However, the existing neural network applied to ECG signal detection usually requires a lot of computing resources, which is not friendlyF to resource-constrained equipment, and it is difficult to realize real-time monitoring. In this paper, a binarized convolutional neural network suitable for ECG monitoring is proposed, which is hardware-friendly and more suitable for use in resource-constrained wearable devices. Targeting the MIT-BIH arrhythmia database, the classifier based on this network reached an accuracy of 95.67% in the five-class test. Compared with the proposed baseline full-precision network with an accuracy of 96.45%, it is only 0.78% lower. Importantly, it achieves 12.65 times the computing speedup, 24.8 times the storage compression ratio, and only requires a quarter of the memory overhead.
Learning Coded Apertures for Time-Division Multiplexing Light Field Display
Jul 13, 2021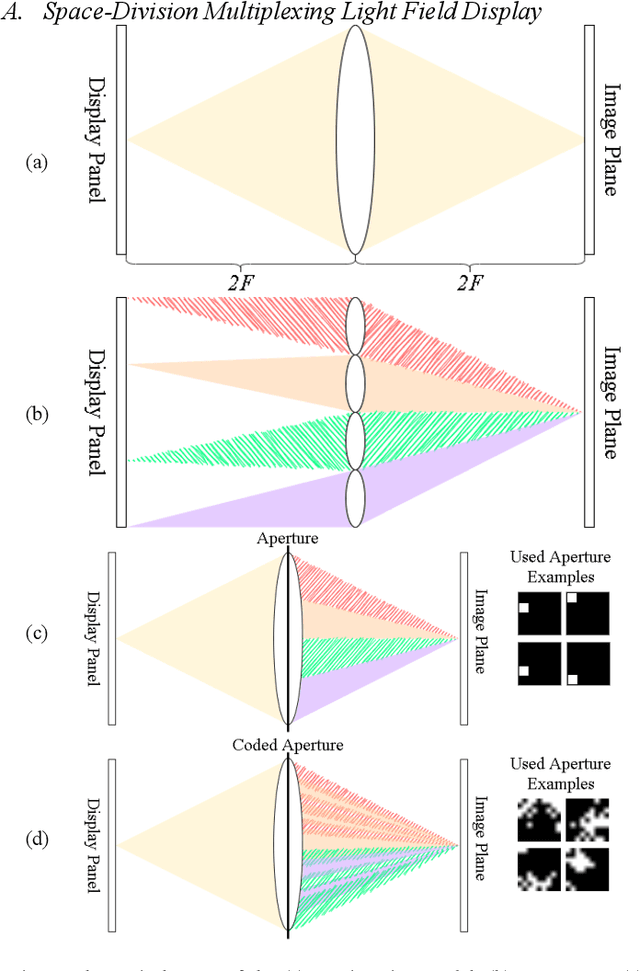



Conventional stereoscopic displays suffer from vergence-accommodation conflict which cause visual fatigue. Integral imaging-based (II) displays resolves this problem by directly projecting light field sub-views into the eye using microlens arrays. However, II-based light field displays has inherent trade-off between angular and spatial resolutions. In this paper, we propose a novel display concept called coded time-division light field display (C-TDM-LFD), which projects encoded light field sub-views to the viewers' eyes, offering correct cues for vergence-accommodation reflex. By jointly optimizing display inputs and pattern of coded apertures, our pipeline can render high resolution refocused images from sparse light field sub-views with minimal aliasing effects. By simulating light transport and image formation with Fourier optics, we can learn display inputs and coded aperture patterns via deep learning in an end-to-end fashion. To our knowledge, we are among the first to optimize the light field display pipeline with deep learning. We verify our concept with objective image quality metrics (PSNR, SSIM) and optics software simulation, and perform extensive studies on the various customizable design variables in our display pipeline. Experiments results show that our method can generate refocused images with higher quality both quantitatively and qualitatively compared to baseline display designs.
FedGBF: An efficient vertical federated learning framework via gradient boosting and bagging
Apr 03, 2022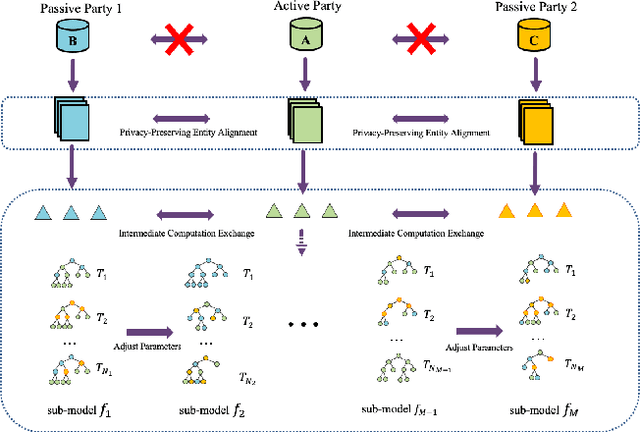
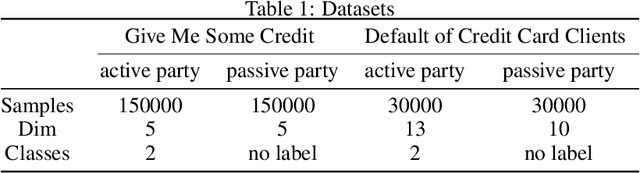
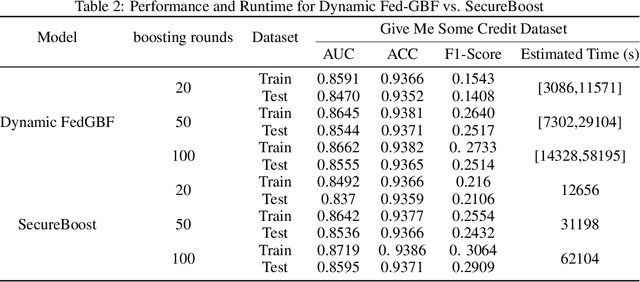
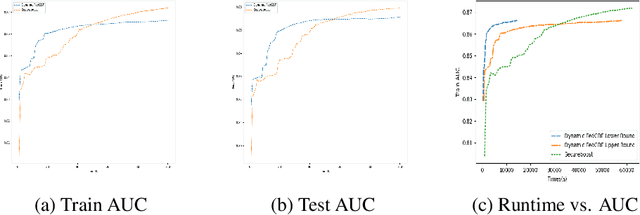
Federated learning, conducive to solving data privacy and security problems, has attracted increasing attention recently. However, the existing federated boosting model sequentially builds a decision tree model with the weak base learner, resulting in redundant boosting steps and high interactive communication costs. In contrast, the federated bagging model saves time by building multi-decision trees in parallel, but it suffers from performance loss. With the aim of obtaining an outstanding performance with less time cost, we propose a novel model in a vertically federated setting termed as Federated Gradient Boosting Forest (FedGBF). FedGBF simultaneously integrates the boosting and bagging's preponderance by building the decision trees in parallel as a base learner for boosting. Subsequent to FedGBF, the problem of hyperparameters tuning is rising. Then we propose the Dynamic FedGBF, which dynamically changes each forest's parameters and thus reduces the complexity. Finally, the experiments based on the benchmark datasets demonstrate the superiority of our method.
Mathematical Models of Human Drivers Using Artificial Risk Fields
May 24, 2022
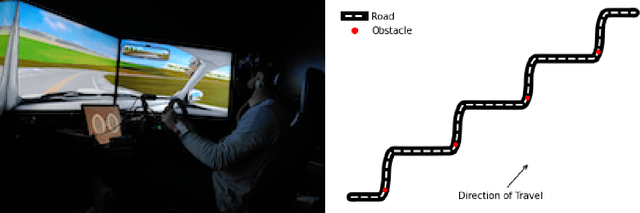
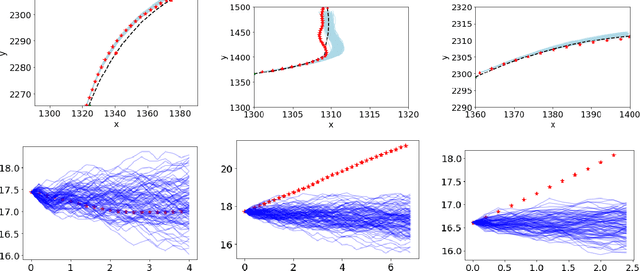
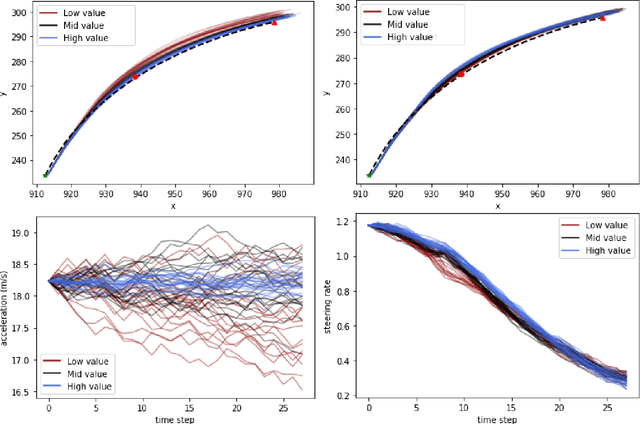
In this paper, we use the concept of artificial risk fields to predict how human operators control a vehicle in response to upcoming road situations. A risk field assigns a non-negative risk measure to the state of the system in order to model how close that state is to violating a safety property, such as hitting an obstacle or exiting the road. Using risk fields, we construct a stochastic model of the operator that maps from states to likely actions. We demonstrate our approach on a driving task wherein human subjects are asked to drive a car inside a realistic driving simulator while avoiding obstacles placed on the road. We show that the most likely risk field given the driving data is obtained by solving a convex optimization problem. Next, we apply the inferred risk fields to generate distinct driving behaviors while comparing predicted trajectories against ground truth measurements. We observe that the risk fields are excellent at predicting future trajectory distributions with high prediction accuracy for up to twenty seconds prediction horizons. At the same time, we observe some challenges such as the inability to account for how drivers choose to accelerate/decelerate based on the road conditions.
Greedy-GQ with Variance Reduction: Finite-time Analysis and Improved Complexity
Mar 30, 2021



Greedy-GQ is a value-based reinforcement learning (RL) algorithm for optimal control. Recently, the finite-time analysis of Greedy-GQ has been developed under linear function approximation and Markovian sampling, and the algorithm is shown to achieve an $\epsilon$-stationary point with a sample complexity in the order of $\mathcal{O}(\epsilon^{-3})$. Such a high sample complexity is due to the large variance induced by the Markovian samples. In this paper, we propose a variance-reduced Greedy-GQ (VR-Greedy-GQ) algorithm for off-policy optimal control. In particular, the algorithm applies the SVRG-based variance reduction scheme to reduce the stochastic variance of the two time-scale updates. We study the finite-time convergence of VR-Greedy-GQ under linear function approximation and Markovian sampling and show that the algorithm achieves a much smaller bias and variance error than the original Greedy-GQ. In particular, we prove that VR-Greedy-GQ achieves an improved sample complexity that is in the order of $\mathcal{O}(\epsilon^{-2})$. We further compare the performance of VR-Greedy-GQ with that of Greedy-GQ in various RL experiments to corroborate our theoretical findings.
Benchmarking Deep Learning Interpretability in Time Series Predictions
Oct 26, 2020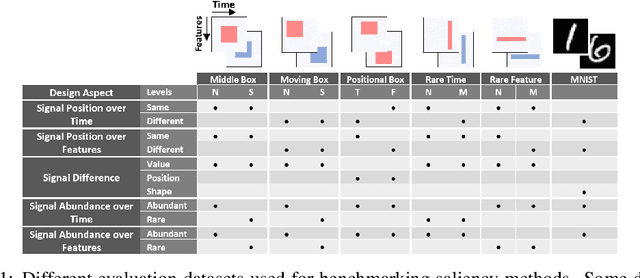
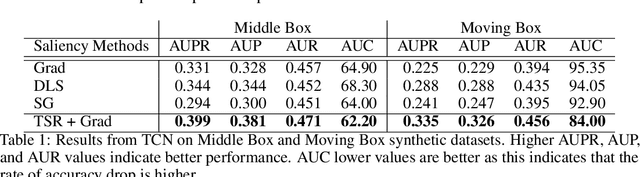
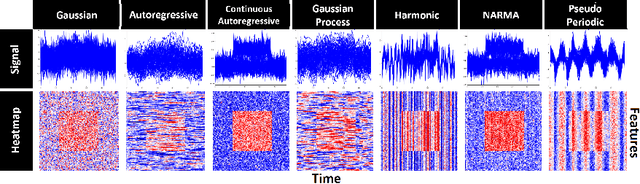

Saliency methods are used extensively to highlight the importance of input features in model predictions. These methods are mostly used in vision and language tasks, and their applications to time series data is relatively unexplored. In this paper, we set out to extensively compare the performance of various saliency-based interpretability methods across diverse neural architectures, including Recurrent Neural Network, Temporal Convolutional Networks, and Transformers in a new benchmark of synthetic time series data. We propose and report multiple metrics to empirically evaluate the performance of saliency methods for detecting feature importance over time using both precision (i.e., whether identified features contain meaningful signals) and recall (i.e., the number of features with signal identified as important). Through several experiments, we show that (i) in general, network architectures and saliency methods fail to reliably and accurately identify feature importance over time in time series data, (ii) this failure is mainly due to the conflation of time and feature domains, and (iii) the quality of saliency maps can be improved substantially by using our proposed two-step temporal saliency rescaling (TSR) approach that first calculates the importance of each time step before calculating the importance of each feature at a time step.