 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Intelligent End-to-End Neural Architecture Search Framework for Electricity Forecasting Model Development
Mar 25, 2022
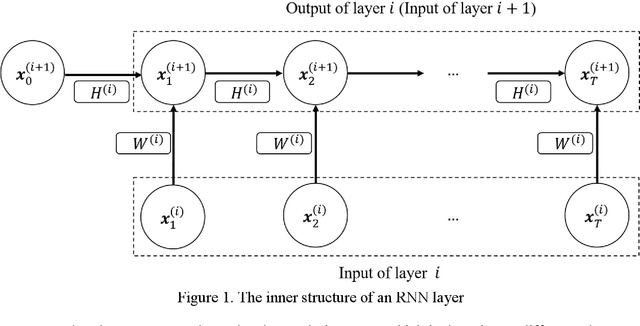

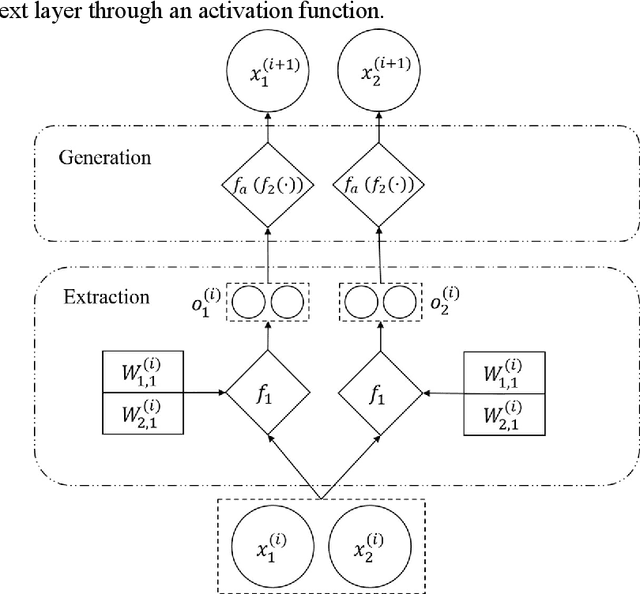

Recent years have witnessed an exponential growth in developing deep learning (DL) models for the time-series electricity forecasting in power systems. However, most of the proposed models are designed based on the designers' inherent knowledge and experience without elaborating on the suitability of the proposed neural architectures. Moreover, these models cannot be self-adjusted to the dynamically changing data patterns due to an inflexible design of their structures. Even though several latest studies have considered application of the neural architecture search (NAS) technique for obtaining a network with an optimized structure in the electricity forecasting sector, their training process is quite time-consuming, computationally expensive and not intelligent, indicating that the NAS application in electricity forecasting area is still at an infancy phase. In this research study, we propose an intelligent automated architecture search (IAAS) framework for the development of time-series electricity forecasting models. The proposed framework contains two primary components, i.e., network function-preserving transformation operation and reinforcement learning (RL)-based network transformation control. In the first component, we introduce a theoretical function-preserving transformation of recurrent neural networks (RNN) to the literature for capturing the hidden temporal patterns within the time-series data. In the second component, we develop three RL-based transformation actors and a net pool to intelligently and effectively search a high-quality neural architecture. After conducting comprehensive experiments on two publicly-available electricity load datasets and two wind power datasets, we demonstrate that the proposed IAAS framework significantly outperforms the ten existing models or methods in terms of forecasting accuracy and stability.
Teacher Perception of Automatically Extracted Grammar Concepts for L2 Language Learning
Jun 10, 2022
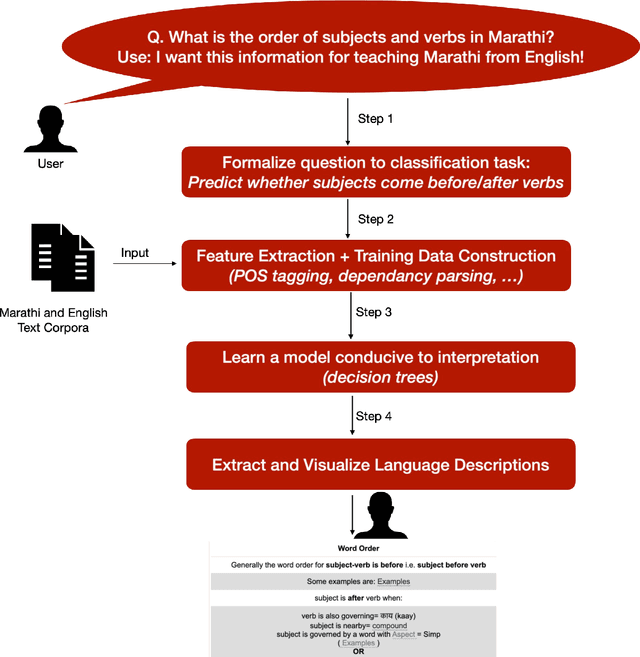

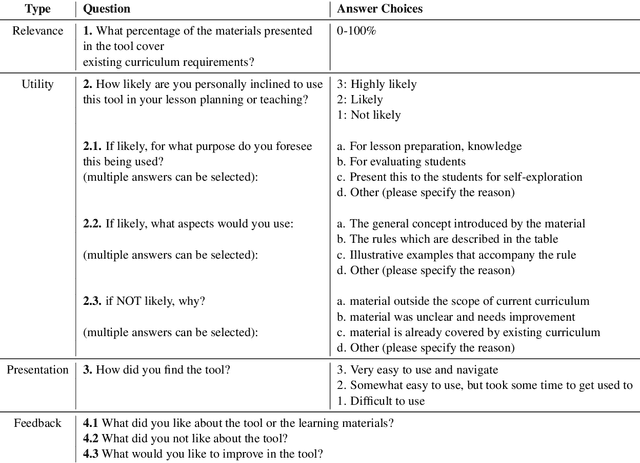
One of the challenges of language teaching is how to organize the rules regarding syntax, semantics, or phonology of the language in a meaningful manner. This not only requires pedagogical skills, but also requires a deep understanding of that language. While comprehensive materials to develop such curricula are available in English and some broadly spoken languages, for many other languages, teachers need to manually create them in response to their students' needs. This process is challenging because i) it requires that such experts be accessible and have the necessary resources, and ii) even if there are such experts, describing all the intricacies of a language is time-consuming and prone to omission. In this article, we present an automatic framework that aims to facilitate this process by automatically discovering and visualizing descriptions of different aspects of grammar. Specifically, we extract descriptions from a natural text corpus that answer questions about morphosyntax (learning of word order, agreement, case marking, or word formation) and semantics (learning of vocabulary) and show illustrative examples. We apply this method for teaching the Indian languages, Kannada and Marathi, which, unlike English, do not have well-developed pedagogical resources and, therefore, are likely to benefit from this exercise. To assess the perceived utility of the extracted material, we enlist the help of language educators from schools in North America who teach these languages to perform a manual evaluation. Overall, teachers find the materials to be interesting as a reference material for their own lesson preparation or even for learner evaluation.
Collaborative Bimanual Manipulation Using Optimal Motion Adaptation and Interaction Control
Jun 01, 2022
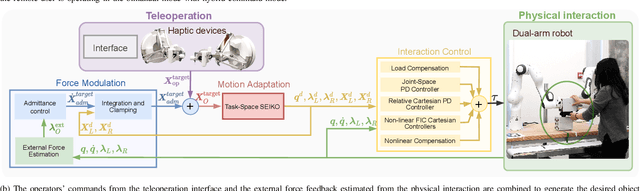
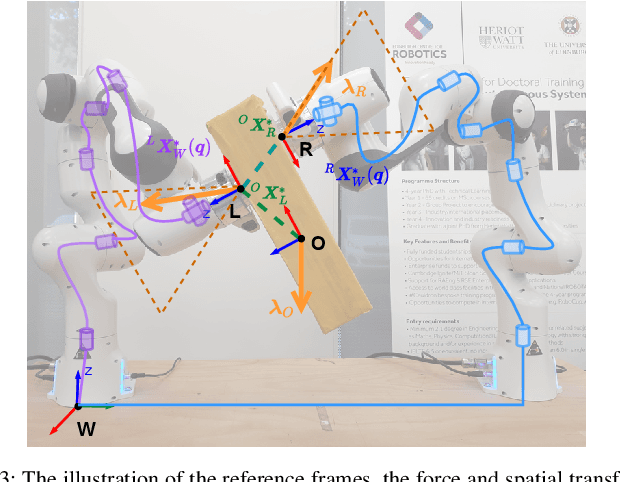
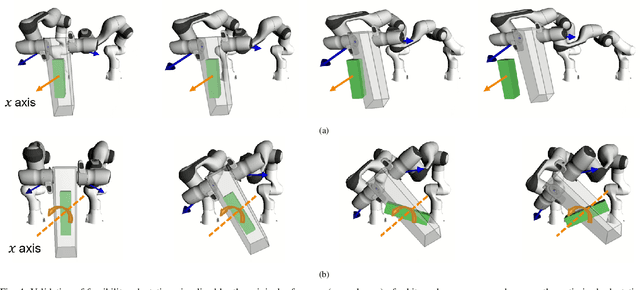
This work developed collaborative bimanual manipulation for reliable and safe human-robot collaboration, which allows remote and local human operators to work interactively for bimanual tasks. We proposed an optimal motion adaptation to retarget arbitrary commands from multiple human operators into feasible control references. The collaborative manipulation framework has three main modules: (1) contact force modulation for compliant physical interactions with objects via admittance control; (2) task-space sequential equilibrium and inverse kinematics optimization, which adapts interactive commands from multiple operators to feasible motions by satisfying the task constraints and physical limits of the robots; and (3) an interaction controller adopted from the fractal impedance control, which is robust to time delay and stable to superimpose multiple control efforts for generating desired joint torques and controlling the dual-arm robots. Extensive experiments demonstrated the capability of the collaborative bimanual framework, including (1) dual-arm teleoperation that adapts arbitrary infeasible commands that violate joint torque limits into continuous operations within safe boundaries, compared to failures without the proposed optimization; (2) robust maneuver of a stack of objects via physical interactions in presence of model inaccuracy; (3) collaborative multi-operator part assembly, and teleoperated industrial connector insertion, which validate the guaranteed stability of reliable human-robot co-manipulation.
A Survey of Research on Fair Recommender Systems
May 25, 2022
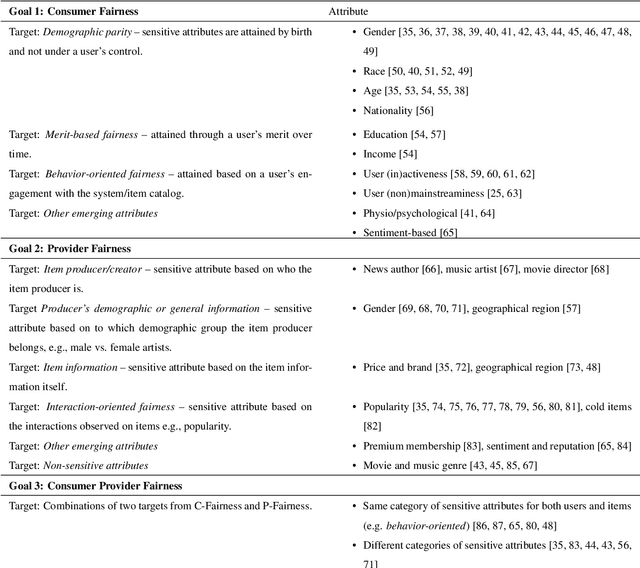
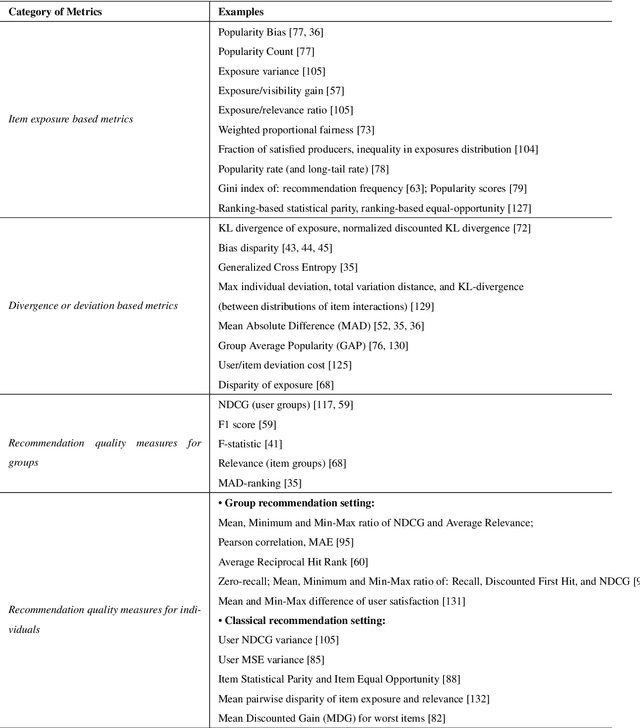
Recommender systems can strongly influence which information we see online, e.g, on social media, and thus impact our beliefs, decisions, and actions. At the same time, these systems can create substantial business value for different stakeholders. Given the growing potential impact of such AI-based systems on individuals, organizations, and society, questions of fairness have gained increased attention in recent years. However, research on fairness in recommender systems is still a developing area. In this survey, we first review the fundamental concepts and notions of fairness that were put forward in the area in the recent past. Afterward, we provide a survey of how research in this area is currently operationalized, for example, in terms of the general research methodology, fairness metrics, and algorithmic approaches. Overall, our analysis of recent works points to certain research gaps. In particular, we find that in many research works in computer science very abstract problem operationalizations are prevalent, which circumvent the fundamental and important question of what represents a fair recommendation in the context of a given application.
Is a Question Decomposition Unit All We Need?
May 25, 2022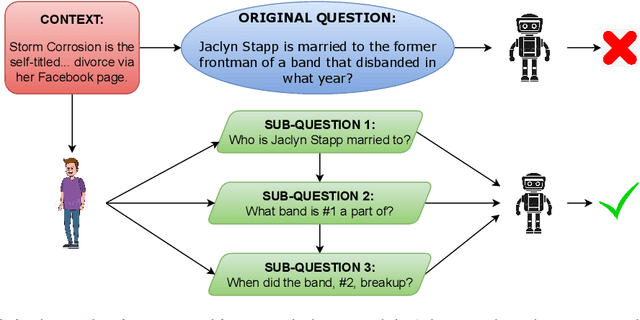


Large Language Models (LMs) have achieved state-of-the-art performance on many Natural Language Processing (NLP) benchmarks. With the growing number of new benchmarks, we build bigger and more complex LMs. However, building new LMs may not be an ideal option owing to the cost, time and environmental impact associated with it. We explore an alternative route: can we modify data by expressing it in terms of the model's strengths, so that a question becomes easier for models to answer? We investigate if humans can decompose a hard question into a set of simpler questions that are relatively easier for models to solve. We analyze a range of datasets involving various forms of reasoning and find that it is indeed possible to significantly improve model performance (24% for GPT3 and 29% for RoBERTa-SQuAD along with a symbolic calculator) via decomposition. Our approach provides a viable option to involve people in NLP research in a meaningful way. Our findings indicate that Human-in-the-loop Question Decomposition (HQD) can potentially provide an alternate path to building large LMs.
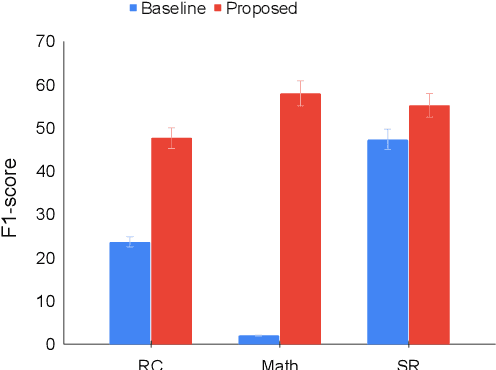
Collective Relevance Labeling for Passage Retrieval
May 09, 2022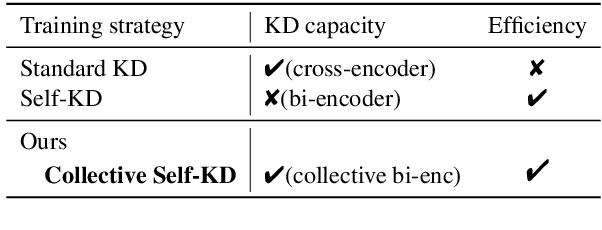
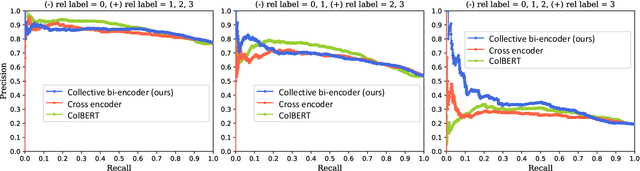
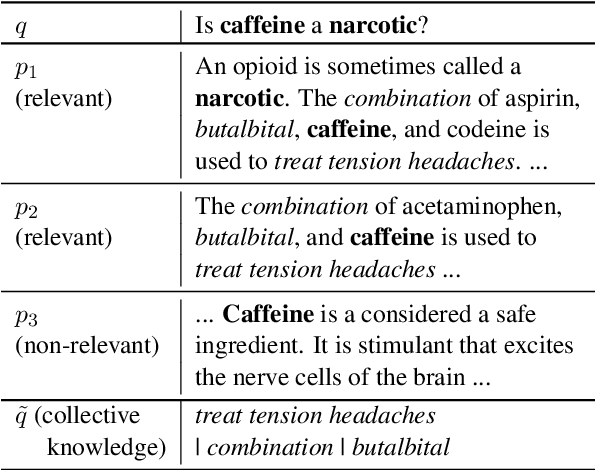
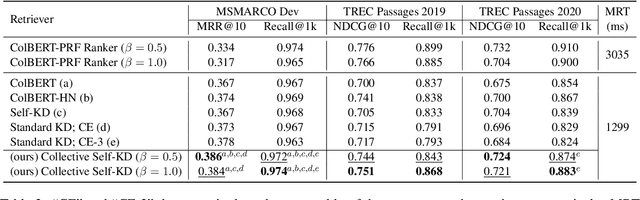
Deep learning for Information Retrieval (IR) requires a large amount of high-quality query-document relevance labels, but such labels are inherently sparse. Label smoothing redistributes some observed probability mass over unobserved instances, often uniformly, uninformed of the true distribution. In contrast, we propose knowledge distillation for informed labeling, without incurring high computation overheads at evaluation time. Our contribution is designing a simple but efficient teacher model which utilizes collective knowledge, to outperform state-of-the-arts distilled from a more complex teacher model. Specifically, we train up to x8 faster than the state-of-the-art teacher, while distilling the rankings better. Our code is publicly available at https://github.com/jihyukkim-nlp/CollectiveKD
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022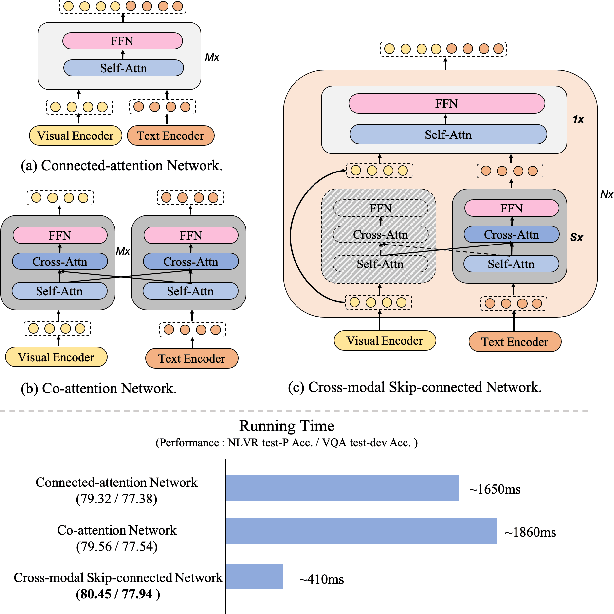
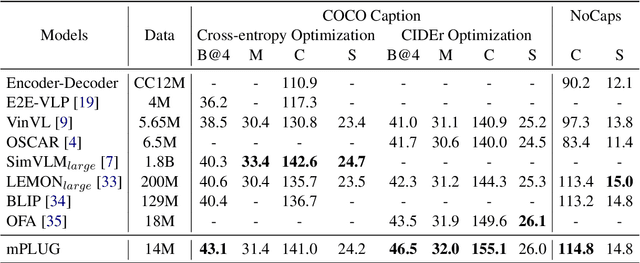
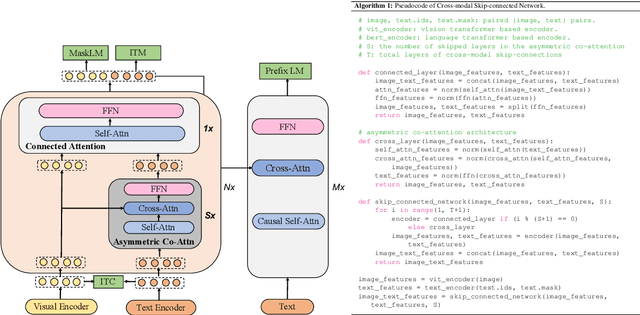
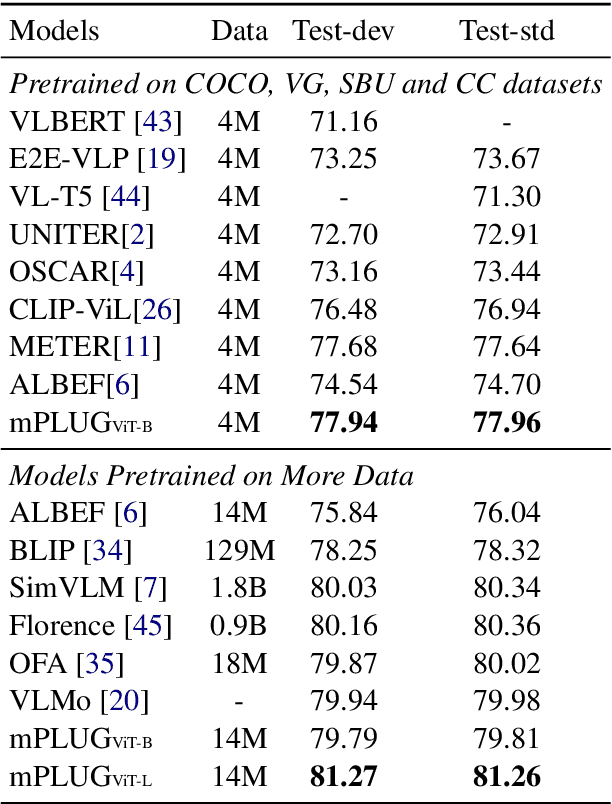
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision
Jul 20, 2021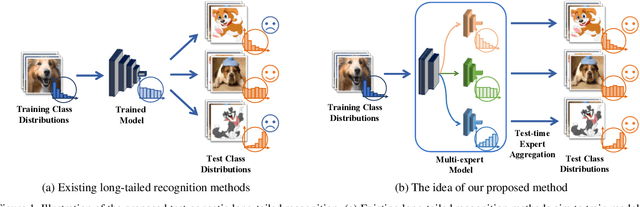
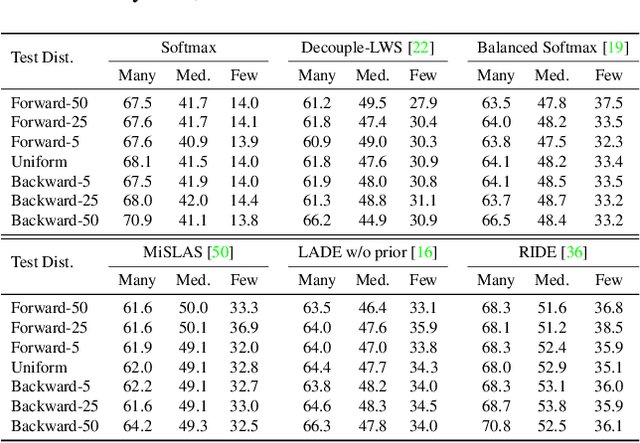
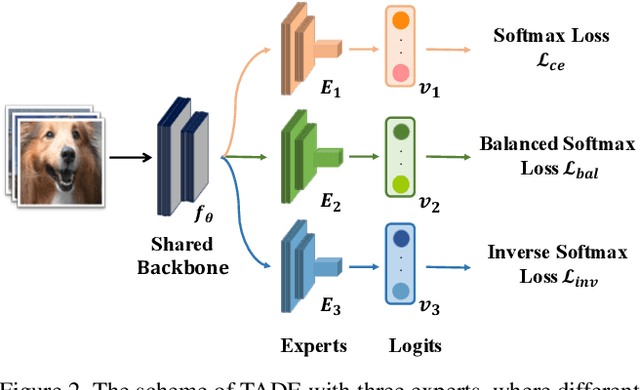
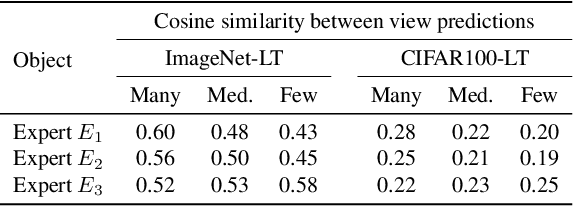
Existing long-tailed recognition methods, aiming to train class-balance models from long-tailed data, generally assume the models would be evaluated on the uniform test class distribution. However, the practical test class distribution often violates such an assumption (e.g., being long-tailed or even inversely long-tailed), which would lead existing methods to fail in real-world applications. In this work, we study a more practical task setting, called test-agnostic long-tailed recognition, where the training class distribution is long-tailed while the test class distribution is unknown and can be skewed arbitrarily. In addition to the issue of class imbalance, this task poses another challenge: the class distribution shift between the training and test samples is unidentified. To address this task, we propose a new method, called Test-time Aggregating Diverse Experts (TADE), that presents two solution strategies: (1) a novel skill-diverse expert learning strategy that trains diverse experts to excel at handling different test distributions from a single long-tailed training distribution; (2) a novel test-time expert aggregation strategy that leverages self-supervision to aggregate multiple experts for handling various test distributions. Moreover, we theoretically show that our method has provable ability to simulate unknown test class distributions. Promising results on both vanilla and test-agnostic long-tailed recognition verify the effectiveness of TADE. Code is available at https://github.com/Vanint/TADE-AgnosticLT.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022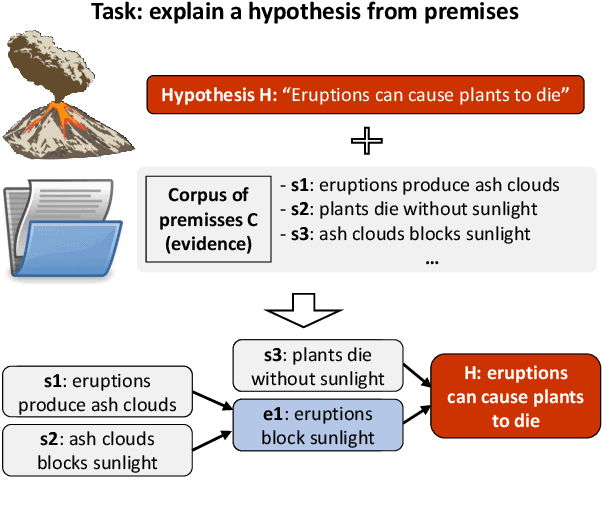
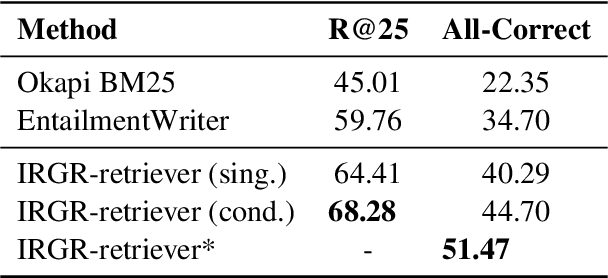
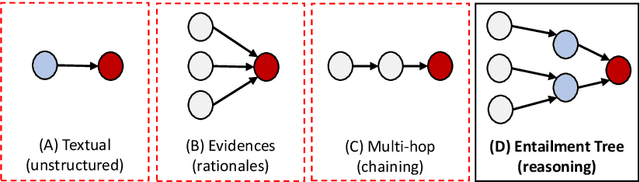
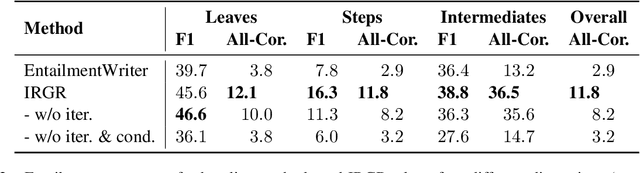
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
Data Stealing Attack on Medical Images: Is it Safe to Export Networks from Data Lakes?
Jun 07, 2022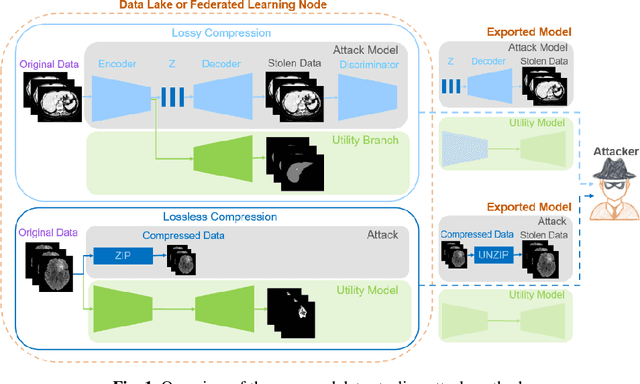
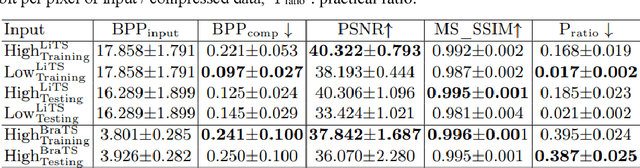
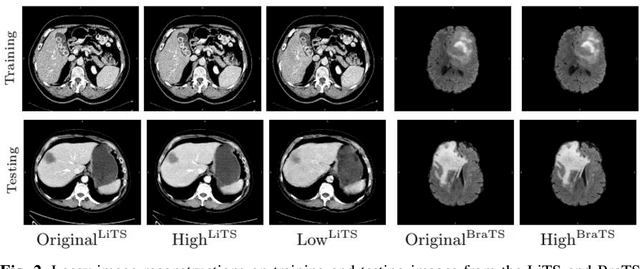

In privacy-preserving machine learning, it is common that the owner of the learned model does not have any physical access to the data. Instead, only a secured remote access to a data lake is granted to the model owner without any ability to retrieve data from the data lake. Yet, the model owner may want to export the trained model periodically from the remote repository and a question arises whether this may cause is a risk of data leakage. In this paper, we introduce the concept of data stealing attack during the export of neural networks. It consists in hiding some information in the exported network that allows the reconstruction outside the data lake of images initially stored in that data lake. More precisely, we show that it is possible to train a network that can perform lossy image compression and at the same time solve some utility tasks such as image segmentation. The attack then proceeds by exporting the compression decoder network together with some image codes that leads to the image reconstruction outside the data lake. We explore the feasibility of such attacks on databases of CT and MR images, showing that it is possible to obtain perceptually meaningful reconstructions of the target dataset, and that the stolen dataset can be used in turns to solve a broad range of tasks. Comprehensive experiments and analyses show that data stealing attacks should be considered as a threat for sensitive imaging data sources.