 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
InducT-GCN: Inductive Graph Convolutional Networks for Text Classification
Jun 01, 2022

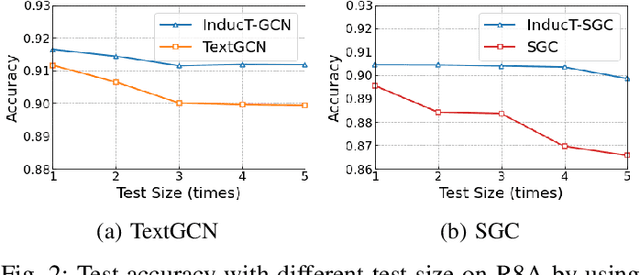
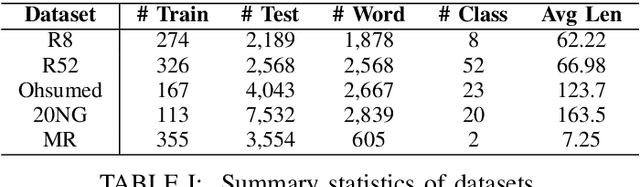
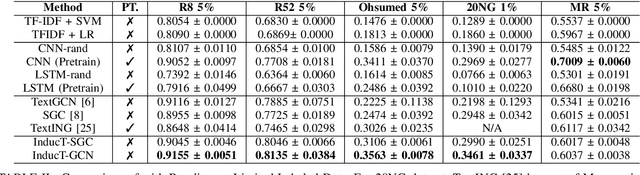
Text classification aims to assign labels to textual units by making use of global information. Recent studies have applied graph neural network (GNN) to capture the global word co-occurrence in a corpus. Existing approaches require that all the nodes (training and test) in a graph are present during training, which are transductive and do not naturally generalise to unseen nodes. To make those models inductive, they use extra resources, like pretrained word embedding. However, high-quality resource is not always available and hard to train. Under the extreme settings with no extra resource and limited amount of training set, can we still learn an inductive graph-based text classification model? In this paper, we introduce a novel inductive graph-based text classification framework, InducT-GCN (InducTive Graph Convolutional Networks for Text classification). Compared to transductive models that require test documents in training, we construct a graph based on the statistics of training documents only and represent document vectors with a weighted sum of word vectors. We then conduct one-directional GCN propagation during testing. Across five text classification benchmarks, our InducT-GCN outperformed state-of-the-art methods that are either transductive in nature or pre-trained additional resources. We also conducted scalability testing by gradually increasing the data size and revealed that our InducT-GCN can reduce the time and space complexity. The code is available on: https://github.com/usydnlp/InductTGCN.
Masked Autoencoders As Spatiotemporal Learners
May 18, 2022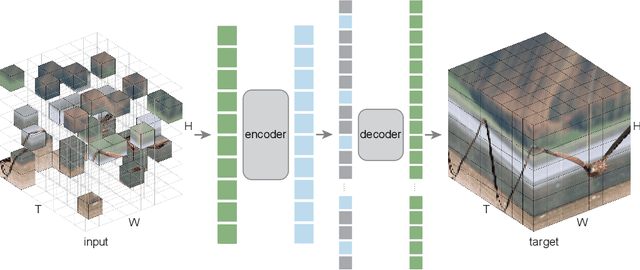



This paper studies a conceptually simple extension of Masked Autoencoders (MAE) to spatiotemporal representation learning from videos. We randomly mask out spacetime patches in videos and learn an autoencoder to reconstruct them in pixels. Interestingly, we show that our MAE method can learn strong representations with almost no inductive bias on spacetime (only except for patch and positional embeddings), and spacetime-agnostic random masking performs the best. We observe that the optimal masking ratio is as high as 90% (vs. 75% on images), supporting the hypothesis that this ratio is related to information redundancy of the data. A high masking ratio leads to a large speedup, e.g., > 4x in wall-clock time or even more. We report competitive results on several challenging video datasets using vanilla Vision Transformers. We observe that MAE can outperform supervised pre-training by large margins. We further report encouraging results of training on real-world, uncurated Instagram data. Our study suggests that the general framework of masked autoencoding (BERT, MAE, etc.) can be a unified methodology for representation learning with minimal domain knowledge.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
May 26, 2022
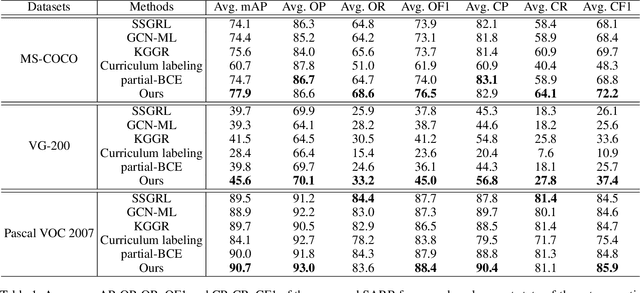
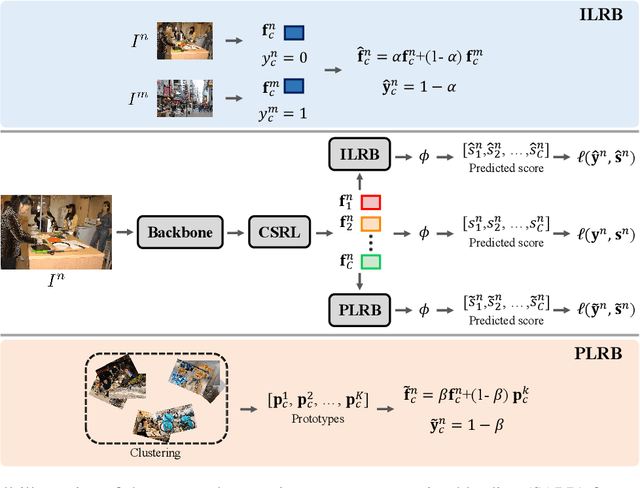
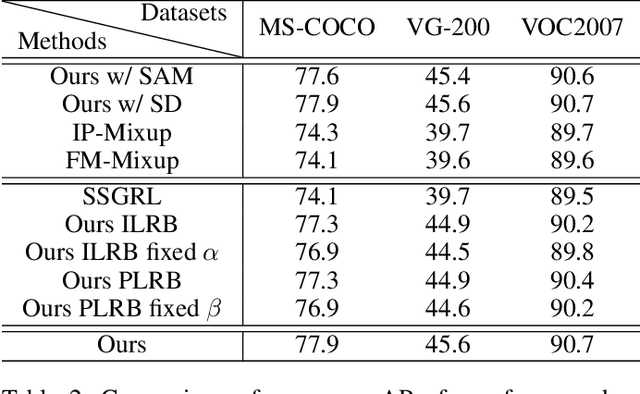
Despite achieving impressive progress, current multi-label image recognition (MLR) algorithms heavily depend on large-scale datasets with complete labels, making collecting large-scale datasets extremely time-consuming and labor-intensive. Training the multi-label image recognition models with partial labels (MLR-PL) is an alternative way to address this issue, in which merely some labels are known while others are unknown for each image (see Figure 1). However, current MLP-PL algorithms mainly rely on the pre-trained image classification or similarity models to generate pseudo labels for the unknown labels. Thus, they depend on a certain amount of data annotations and inevitably suffer from obvious performance drops, especially when the known label proportion is low. To address this dilemma, we propose a unified semantic-aware representation blending (SARB) that consists of two crucial modules to blend multi-granularity category-specific semantic representation across different images to transfer information of known labels to complement unknown labels. Extensive experiments on the MS-COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed SARB consistently outperforms current state-of-the-art algorithms on all known label proportion settings. Concretely, it obtain the average mAP improvement of 1.9%, 4.5%, 1.0% on the three benchmark datasets compared with the second-best algorithm.
Dynamic physical activity recommendation on personalised mobile health information service: A deep reinforcement learning approach
Apr 03, 2022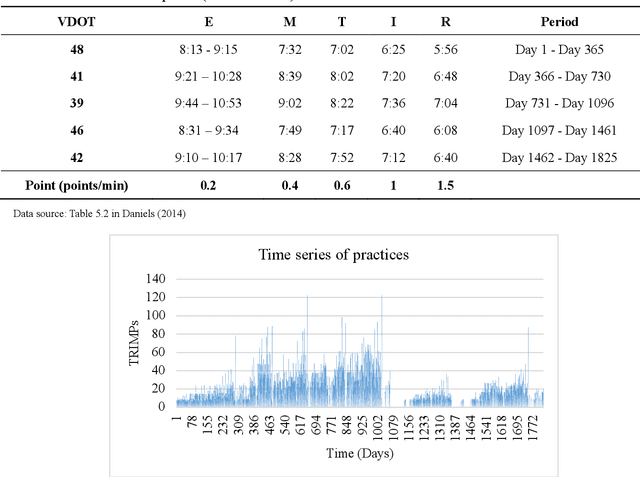


Mobile health (mHealth) information service makes healthcare management easier for users, who want to increase physical activity and improve health. However, the differences in activity preference among the individual, adherence problems, and uncertainty of future health outcomes may reduce the effect of the mHealth information service. The current health service system usually provides recommendations based on fixed exercise plans that do not satisfy the user specific needs. This paper seeks an efficient way to make physical activity recommendation decisions on physical activity promotion in personalised mHealth information service by establishing data-driven model. In this study, we propose a real-time interaction model to select the optimal exercise plan for the individual considering the time-varying characteristics in maximising the long-term health utility of the user. We construct a framework for mHealth information service system comprising a personalised AI module, which is based on the scientific knowledge about physical activity to evaluate the individual exercise performance, which may increase the awareness of the mHealth artificial intelligence system. The proposed deep reinforcement learning (DRL) methodology combining two classes of approaches to improve the learning capability for the mHealth information service system. A deep learning method is introduced to construct the hybrid neural network combing long-short term memory (LSTM) network and deep neural network (DNN) techniques to infer the individual exercise behavior from the time series data. A reinforcement learning method is applied based on the asynchronous advantage actor-critic algorithm to find the optimal policy through exploration and exploitation.
A Learning Approach for Joint Design of Event-triggered Control and Power-Efficient Resource Allocation
May 14, 2022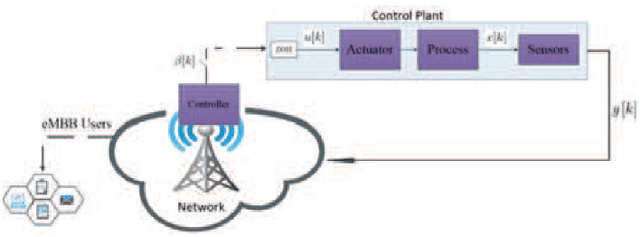
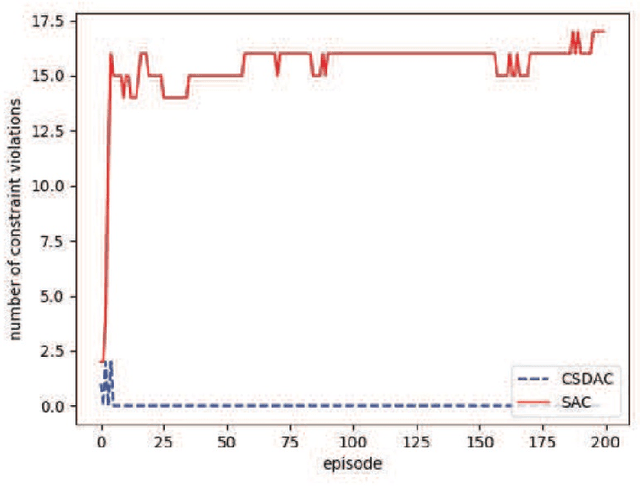
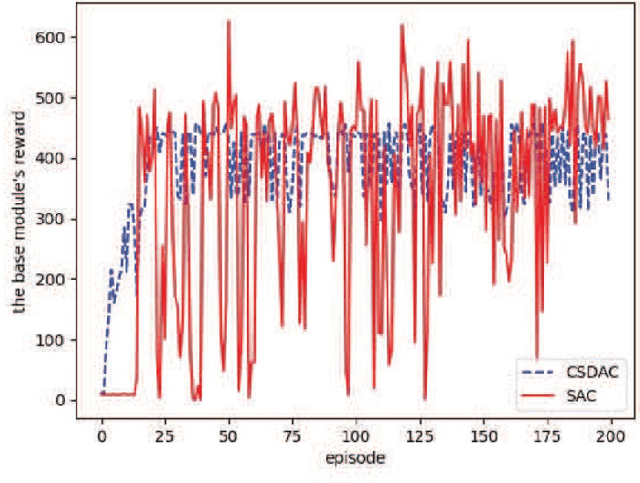
In emerging Industrial Cyber-Physical Systems (ICPSs), the joint design of communication and control sub-systems is essential, as these sub-systems are interconnected. In this paper, we study the joint design problem of an event-triggered control and an energy-efficient resource allocation in a fifth generation (5G) wireless network. We formally state the problem as a multi-objective optimization one, aiming to minimize the number of updates on the actuators' input and the power consumption in the downlink transmission. To address the problem, we propose a model-free hierarchical reinforcement learning approach \textcolor{blue}{with uniformly ultimate boundedness stability guarantee} that learns four policies simultaneously. These policies contain an update time policy on the actuators' input, a control policy, and energy-efficient sub-carrier and power allocation policies. Our simulation results show that the proposed approach can properly control a simulated ICPS and significantly decrease the number of updates on the actuators' input as well as the downlink power consumption.
A Flow-Based Neural Network for Time Domain Speech Enhancement
Jun 16, 2021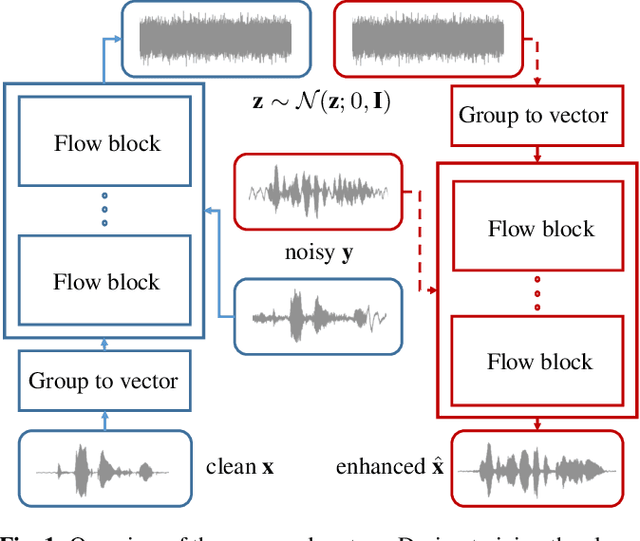
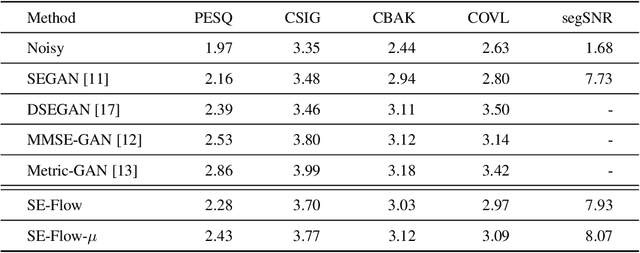
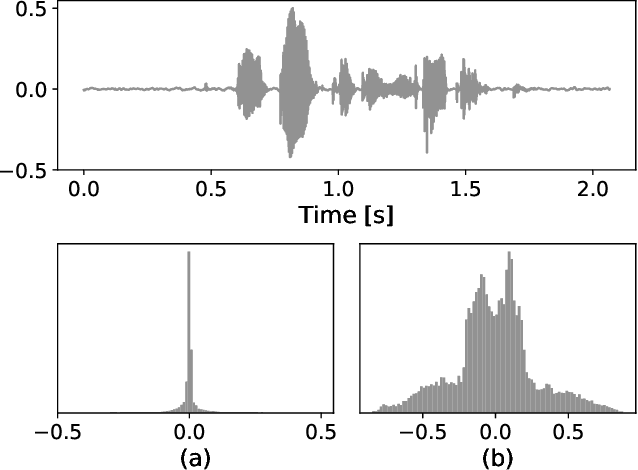
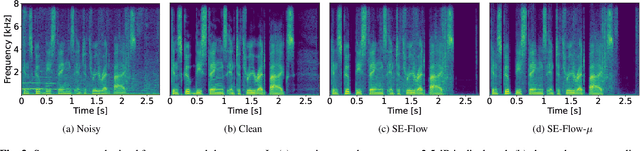
Speech enhancement involves the distinction of a target speech signal from an intrusive background. Although generative approaches using Variational Autoencoders or Generative Adversarial Networks (GANs) have increasingly been used in recent years, normalizing flow (NF) based systems are still scarse, despite their success in related fields. Thus, in this paper we propose a NF framework to directly model the enhancement process by density estimation of clean speech utterances conditioned on their noisy counterpart. The WaveGlow model from speech synthesis is adapted to enable direct enhancement of noisy utterances in time domain. In addition, we demonstrate that nonlinear input companding benefits the model performance by equalizing the distribution of input samples. Experimental evaluation on a publicly available dataset shows comparable results to current state-of-the-art GAN-based approaches, while surpassing the chosen baselines using objective evaluation metrics.
PSEUDo: Interactive Pattern Search in Multivariate Time Series with Locality-Sensitive Hashing and Relevance Feedback
Apr 30, 2021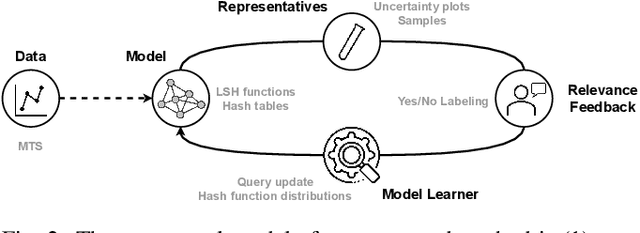
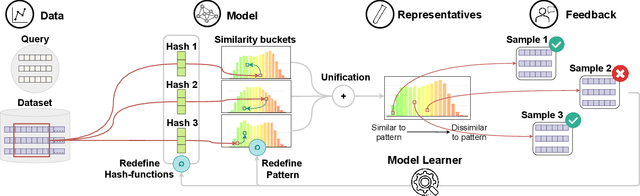
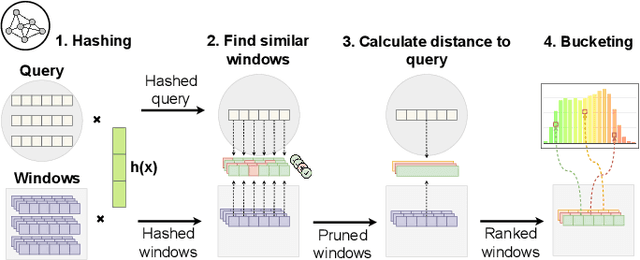
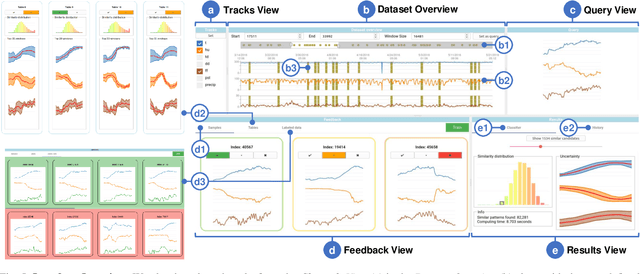
We present PSEUDo, an adaptive feature learning technique for exploring visual patterns in multi-track sequential data. Our approach is designed with the primary focus to overcome the uneconomic retraining requirements and inflexible representation learning in current deep learning-based systems. Multi-track time series data are generated on an unprecedented scale due to increased sensors and data storage. These datasets hold valuable patterns, like in neuromarketing, where researchers try to link patterns in multivariate sequential data from physiological sensors to the purchase behavior of products and services. But a lack of ground truth and high variance make automatic pattern detection unreliable. Our advancements are based on a novel query-aware locality-sensitive hashing technique to create a feature-based representation of multivariate time series windows. Most importantly, our algorithm features sub-linear training and inference time. We can even accomplish both the modeling and comparison of 10,000 different 64-track time series, each with 100 time steps (a typical EEG dataset) under 0.8 seconds. This performance gain allows for a rapid relevance feedback-driven adaption of the underlying pattern similarity model and enables the user to modify the speed-vs-accuracy trade-off gradually. We demonstrate superiority of PSEUDo in terms of efficiency, accuracy, and steerability through a quantitative performance comparison and a qualitative visual quality comparison to the state-of-the-art algorithms in the field. Moreover, we showcase the usability of PSEUDo through a case study demonstrating our visual pattern retrieval concepts in a large meteorological dataset. We find that our adaptive models can accurately capture the user's notion of similarity and allow for an understandable exploratory visual pattern retrieval in large multivariate time series datasets.
Exploring Deep Learning Methods for Real-Time Surgical Instrument Segmentation in Laparoscopy
Aug 03, 2021
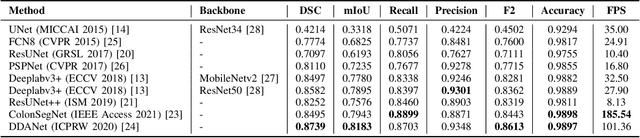
Minimally invasive surgery is a surgical intervention used to examine the organs inside the abdomen and has been widely used due to its effectiveness over open surgery. Due to the hardware improvements such as high definition cameras, this procedure has significantly improved and new software methods have demonstrated potential for computer-assisted procedures. However, there exists challenges and requirements to improve detection and tracking of the position of the instruments during these surgical procedures. To this end, we evaluate and compare some popular deep learning methods that can be explored for the automated segmentation of surgical instruments in laparoscopy, an important step towards tool tracking. Our experimental results exhibit that the Dual decoder attention network (DDANet) produces a superior result compared to other recent deep learning methods. DDANet yields a Dice coefficient of 0.8739 and mean intersection-over-union of 0.8183 for the Robust Medical Instrument Segmentation (ROBUST-MIS) Challenge 2019 dataset, at a real-time speed of 101.36 frames-per-second that is critical for such procedures.
Spectral Temporal Graph Neural Network for Multivariate Time-series Forecasting
Mar 13, 2021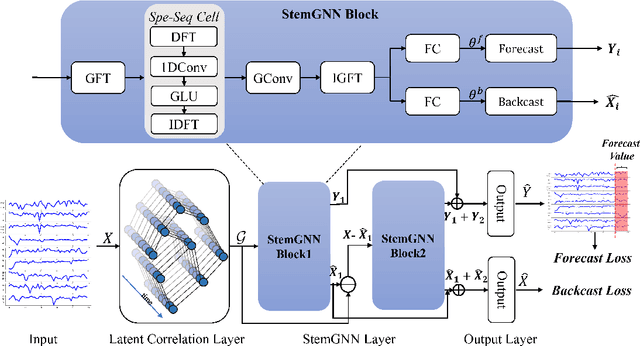

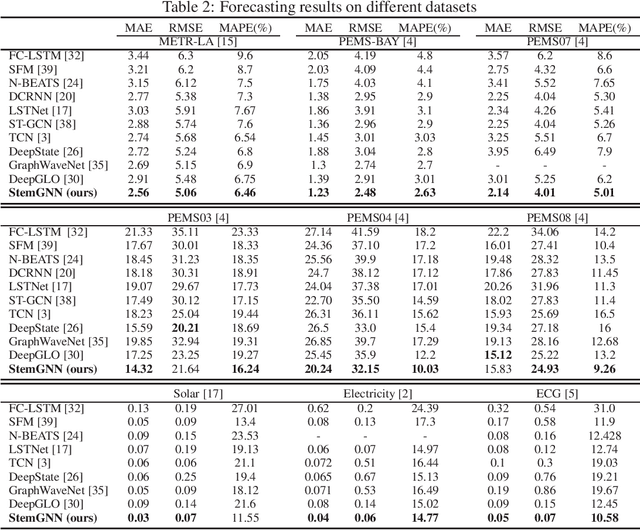
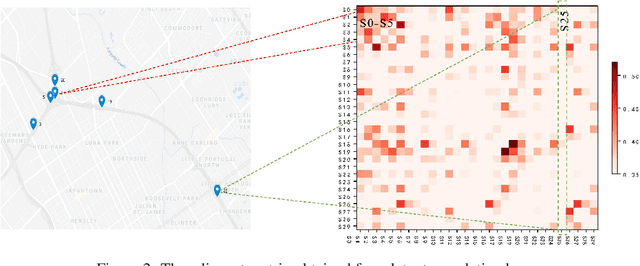
Multivariate time-series forecasting plays a crucial role in many real-world applications. It is a challenging problem as one needs to consider both intra-series temporal correlations and inter-series correlations simultaneously. Recently, there have been multiple works trying to capture both correlations, but most, if not all of them only capture temporal correlations in the time domain and resort to pre-defined priors as inter-series relationships. In this paper, we propose Spectral Temporal Graph Neural Network (StemGNN) to further improve the accuracy of multivariate time-series forecasting. StemGNN captures inter-series correlations and temporal dependencies \textit{jointly} in the \textit{spectral domain}. It combines Graph Fourier Transform (GFT) which models inter-series correlations and Discrete Fourier Transform (DFT) which models temporal dependencies in an end-to-end framework. After passing through GFT and DFT, the spectral representations hold clear patterns and can be predicted effectively by convolution and sequential learning modules. Moreover, StemGNN learns inter-series correlations automatically from the data without using pre-defined priors. We conduct extensive experiments on ten real-world datasets to demonstrate the effectiveness of StemGNN. Code is available at https://github.com/microsoft/StemGNN/
Virtual twins of nonlinear vibrating multiphysics microstructures: physics-based versus deep learning-based approaches
May 12, 2022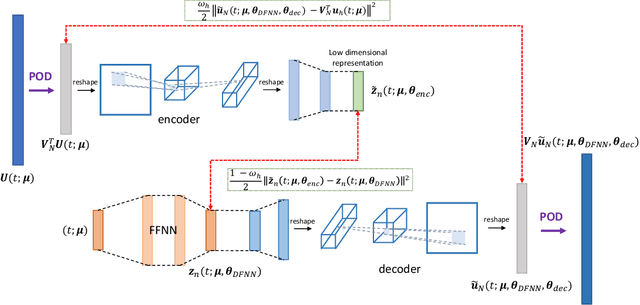
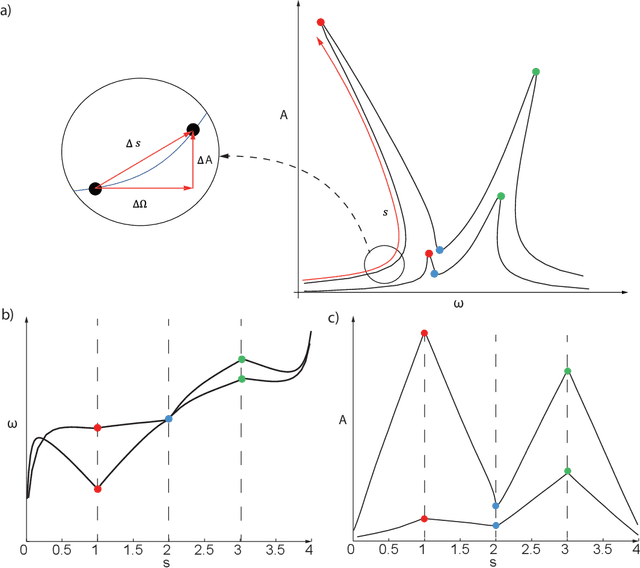
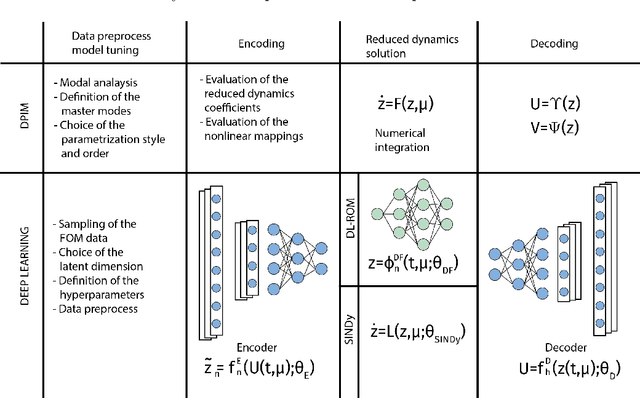
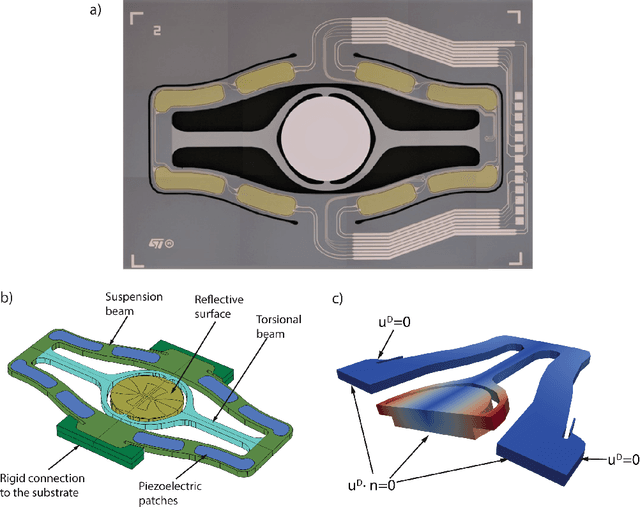
Micro-Electro-Mechanical-Systems are complex structures, often involving nonlinearites of geometric and multiphysics nature, that are used as sensors and actuators in countless applications. Starting from full-order representations, we apply deep learning techniques to generate accurate, efficient and real-time reduced order models to be used as virtual twin for the simulation and optimization of higher-level complex systems. We extensively test the reliability of the proposed procedures on micromirrors, arches and gyroscopes, also displaying intricate dynamical evolutions like internal resonances. In particular, we discuss the accuracy of the deep learning technique and its ability to replicate and converge to the invariant manifolds predicted using the recently developed direct parametrization approach that allows extracting the nonlinear normal modes of large finite element models. Finally, by addressing an electromechanical gyroscope, we show that the non-intrusive deep learning approach generalizes easily to complex multiphysics problems