 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CHALLENGER: Training with Attribution Maps
May 30, 2022
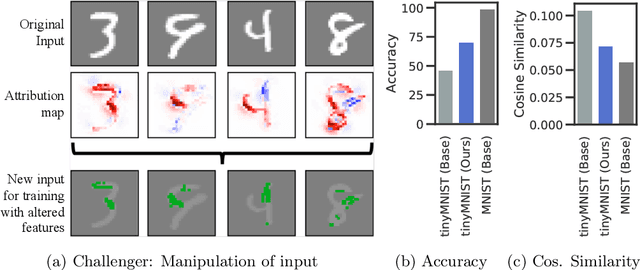


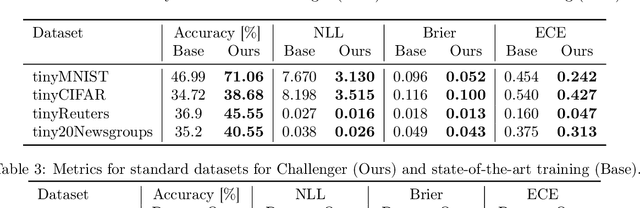
We show that utilizing attribution maps for training neural networks can improve regularization of models and thus increase performance. Regularization is key in deep learning, especially when training complex models on relatively small datasets. In order to understand inner workings of neural networks, attribution methods such as Layer-wise Relevance Propagation (LRP) have been extensively studied, particularly for interpreting the relevance of input features. We introduce Challenger, a module that leverages the explainable power of attribution maps in order to manipulate particularly relevant input patterns. Therefore, exposing and subsequently resolving regions of ambiguity towards separating classes on the ground-truth data manifold, an issue that arises particularly when training models on rather small datasets. Our Challenger module increases model performance through building more diverse filters within the network and can be applied to any input data domain. We demonstrate that our approach results in substantially better classification as well as calibration performance on datasets with only a few samples up to datasets with thousands of samples. In particular, we show that our generic domain-independent approach yields state-of-the-art results in vision, natural language processing and on time series tasks.
Price graphs: Utilizing the structural information of financial time series for stock prediction
Jun 04, 2021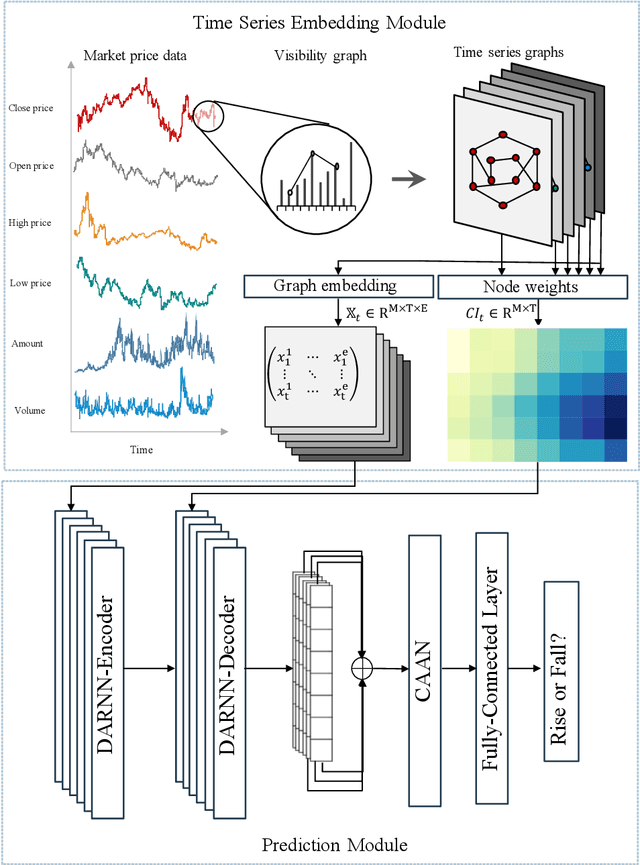
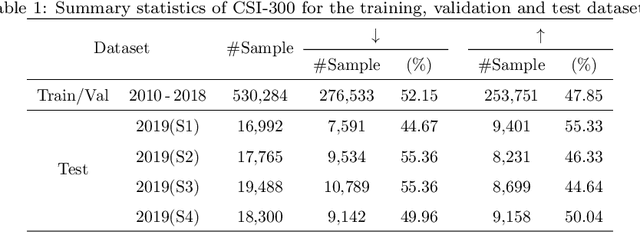
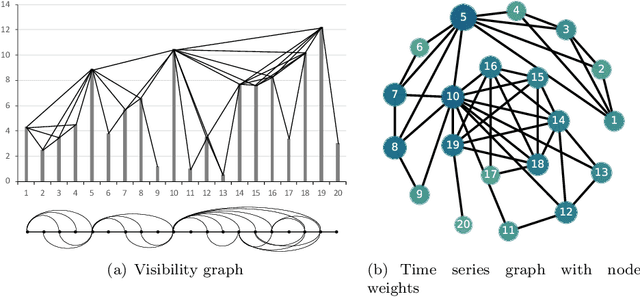
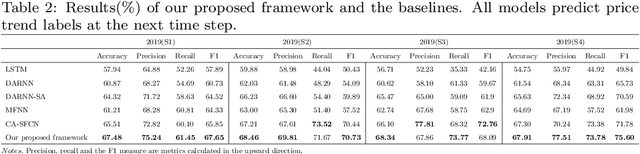
Stock prediction, with the purpose of forecasting the future price trends of stocks, is crucial for maximizing profits from stock investments. While great research efforts have been devoted to exploiting deep neural networks for improved stock prediction, the existing studies still suffer from two major issues. First, the long-range dependencies in time series are not sufficiently captured. Second, the chaotic property of financial time series fundamentally lowers prediction performance. In this study, we propose a novel framework to address both issues regarding stock prediction. Specifically, in terms of transforming time series into complex networks, we convert market price series into graphs. Then, structural information, referring to associations among temporal points and the node weights, is extracted from the mapped graphs to resolve the problems regarding long-range dependencies and the chaotic property. We take graph embeddings to represent the associations among temporal points as the prediction model inputs. Node weights are used as a priori knowledge to enhance the learning of temporal attention. The effectiveness of our proposed framework is validated using real-world stock data, and our approach obtains the best performance among several state-of-the-art benchmarks. Moreover, in the conducted trading simulations, our framework further obtains the highest cumulative profits. Our results supplement the existing applications of complex network methods in the financial realm and provide insightful implications for investment applications regarding decision support in financial markets.
No More Pesky Hyperparameters: Offline Hyperparameter Tuning for RL
May 18, 2022
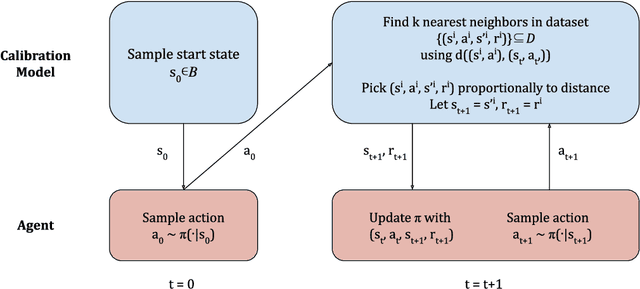
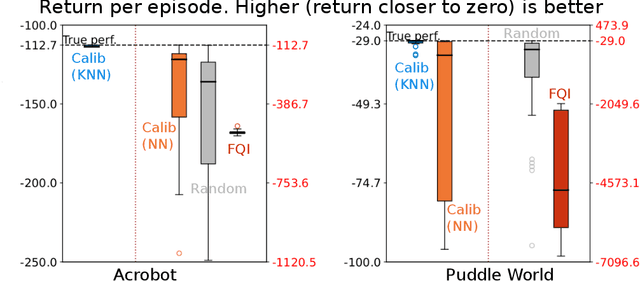
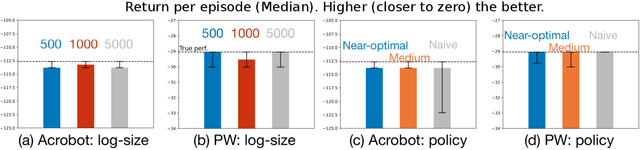
The performance of reinforcement learning (RL) agents is sensitive to the choice of hyperparameters. In real-world settings like robotics or industrial control systems, however, testing different hyperparameter configurations directly on the environment can be financially prohibitive, dangerous, or time consuming. We propose a new approach to tune hyperparameters from offline logs of data, to fully specify the hyperparameters for an RL agent that learns online in the real world. The approach is conceptually simple: we first learn a model of the environment from the offline data, which we call a calibration model, and then simulate learning in the calibration model to identify promising hyperparameters. We identify several criteria to make this strategy effective, and develop an approach that satisfies these criteria. We empirically investigate the method in a variety of settings to identify when it is effective and when it fails.
Synthetic PET via Domain Translation of 3D MRI
Jun 11, 2022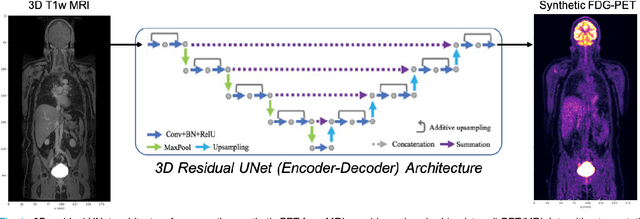
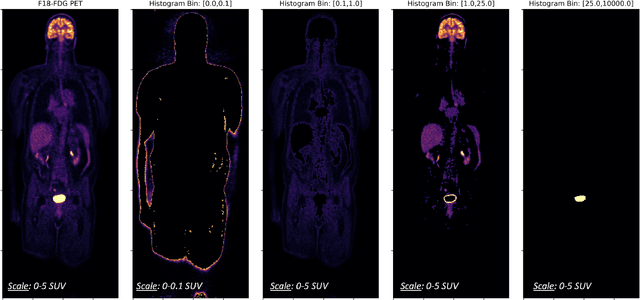
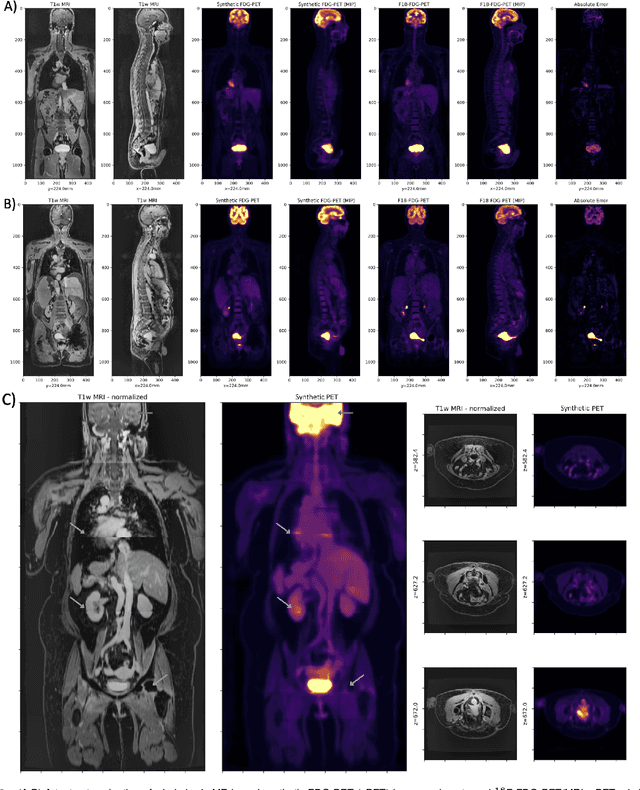
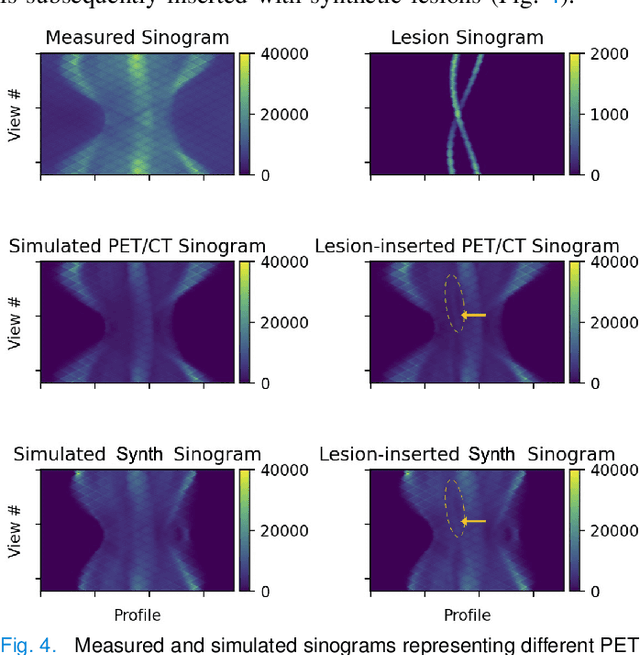
Historically, patient datasets have been used to develop and validate various reconstruction algorithms for PET/MRI and PET/CT. To enable such algorithm development, without the need for acquiring hundreds of patient exams, in this paper we demonstrate a deep learning technique to generate synthetic but realistic whole-body PET sinograms from abundantly-available whole-body MRI. Specifically, we use a dataset of 56 $^{18}$F-FDG-PET/MRI exams to train a 3D residual UNet to predict physiologic PET uptake from whole-body T1-weighted MRI. In training we implemented a balanced loss function to generate realistic uptake across a large dynamic range and computed losses along tomographic lines of response to mimic the PET acquisition. The predicted PET images are forward projected to produce synthetic PET time-of-flight (ToF) sinograms that can be used with vendor-provided PET reconstruction algorithms, including using CT-based attenuation correction (CTAC) and MR-based attenuation correction (MRAC). The resulting synthetic data recapitulates physiologic $^{18}$F-FDG uptake, e.g. high uptake localized to the brain and bladder, as well as uptake in liver, kidneys, heart and muscle. To simulate abnormalities with high uptake, we also insert synthetic lesions. We demonstrate that this synthetic PET data can be used interchangeably with real PET data for the PET quantification task of comparing CT and MR-based attenuation correction methods, achieving $\leq 7.6\%$ error in mean-SUV compared to using real data. These results together show that the proposed synthetic PET data pipeline can be reasonably used for development, evaluation, and validation of PET/MRI reconstruction methods.
OrdinalCLIP: Learning Rank Prompts for Language-Guided Ordinal Regression
Jun 06, 2022
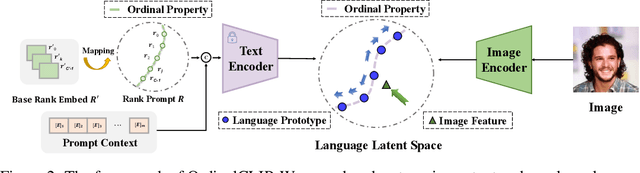
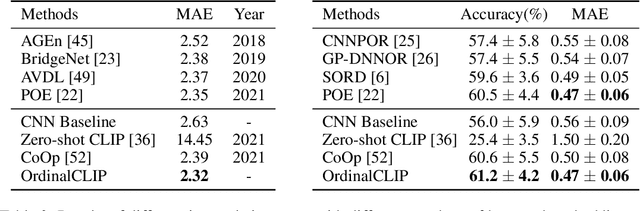
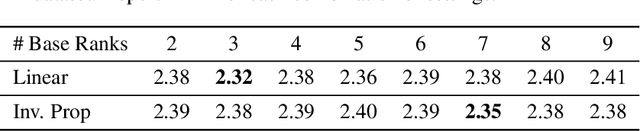
This paper presents a language-powered paradigm for ordinal regression. Existing methods usually treat each rank as a category and employ a set of weights to learn these concepts. These methods are easy to overfit and usually attain unsatisfactory performance as the learned concepts are mainly derived from the training set. Recent large pre-trained vision-language models like CLIP have shown impressive performance on various visual tasks. In this paper, we propose to learn the rank concepts from the rich semantic CLIP latent space. Specifically, we reformulate this task as an image-language matching problem with a contrastive objective, which regards labels as text and obtains a language prototype from a text encoder for each rank. While prompt engineering for CLIP is extremely time-consuming, we propose OrdinalCLIP, a differentiable prompting method for adapting CLIP for ordinal regression. OrdinalCLIP consists of learnable context tokens and learnable rank embeddings; The learnable rank embeddings are constructed by explicitly modeling numerical continuity, resulting in well-ordered, compact language prototypes in the CLIP space. Once learned, we can only save the language prototypes and discard the huge language model, resulting in zero additional computational overhead compared with the linear head counterpart. Experimental results show that our paradigm achieves competitive performance in general ordinal regression tasks, and gains improvements in few-shot and distribution shift settings for age estimation.
Turing's cascade instability supports the coordination of the mind, brain, and behavior
Apr 17, 2022
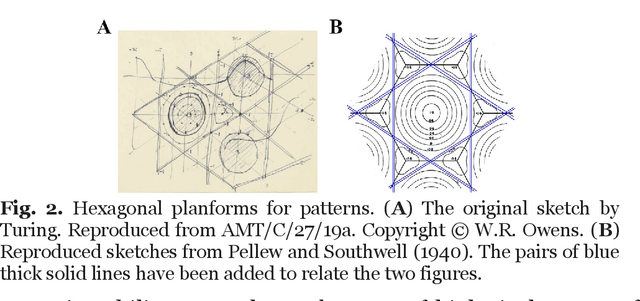

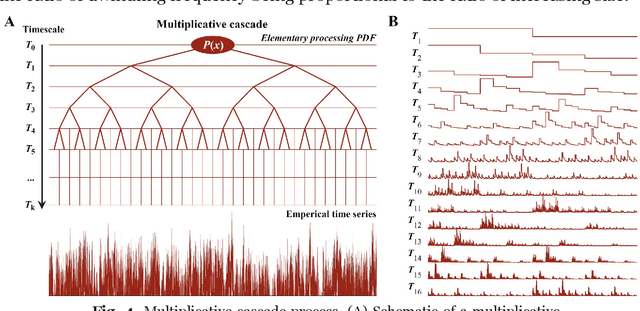
Turing inspired a computer metaphor of the mind and brain that has been handy and has spawned decades of empirical investigation, but he did much more and offered behavioral and cognitive sciences another metaphor--that of the cascade. The time has come to confront Turing's cascading instability, which suggests a geometrical framework driven by power laws and can be studied using multifractal formalism and multiscale probability density function analysis. Here, we review a rapidly growing body of scientific investigations revealing signatures of cascade instability and their consequences for a perceiving, acting, and thinking organism. We review work related to executive functioning (planning to act), postural control (bodily poise for turning plans into action), and effortful perception (action to gather information in a single modality and action to blend multimodal information). We also review findings on neuronal avalanches in the brain, specifically about neural participation in body-wide cascades. Turing's cascade instability blends the mind, brain, and behavior across space and time scales and provides an alternative to the dominant computer metaphor.
OmniXAI: A Library for Explainable AI
Jun 09, 2022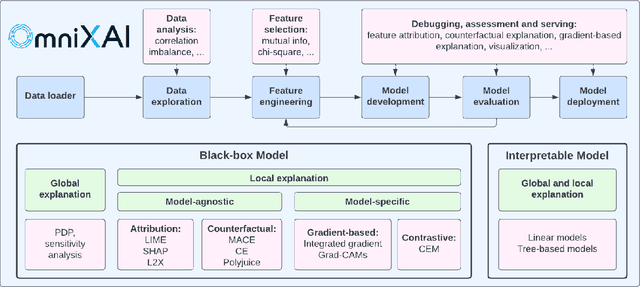
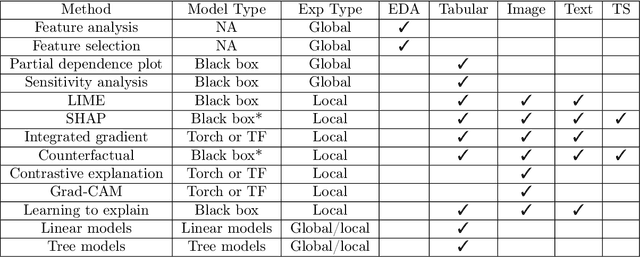
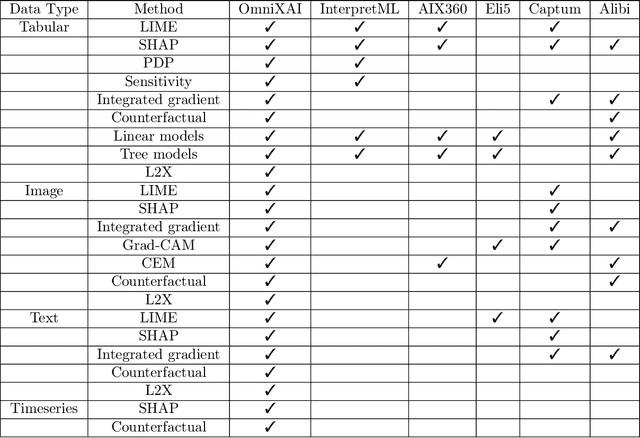
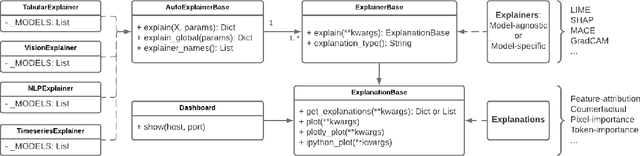
We introduce OmniXAI (short for Omni eXplainable AI), an open-source Python library of eXplainable AI (XAI), which offers omni-way explainable AI capabilities and various interpretable machine learning techniques to address the pain points of understanding and interpreting the decisions made by machine learning (ML) in practice. OmniXAI aims to be a one-stop comprehensive library that makes explainable AI easy for data scientists, ML researchers and practitioners who need explanation for various types of data, models and explanation methods at different stages of ML process (data exploration, feature engineering, model development, evaluation, and decision-making, etc). In particular, our library includes a rich family of explanation methods integrated in a unified interface, which supports multiple data types (tabular data, images, texts, time-series), multiple types of ML models (traditional ML in Scikit-learn and deep learning models in PyTorch/TensorFlow), and a range of diverse explanation methods including "model-specific" and "model-agnostic" ones (such as feature-attribution explanation, counterfactual explanation, gradient-based explanation, etc). For practitioners, the library provides an easy-to-use unified interface to generate the explanations for their applications by only writing a few lines of codes, and also a GUI dashboard for visualization of different explanations for more insights about decisions. In this technical report, we present OmniXAI's design principles, system architectures, and major functionalities, and also demonstrate several example use cases across different types of data, tasks, and models.
Underdetermined 2D-DOD and 2D-DOA Estimation for Bistatic Coprime EMVS-MIMO Radar: From the Difference Coarray Perspective
Jun 06, 2022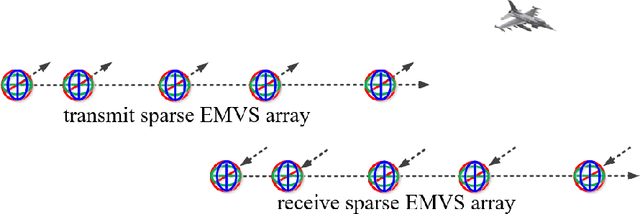
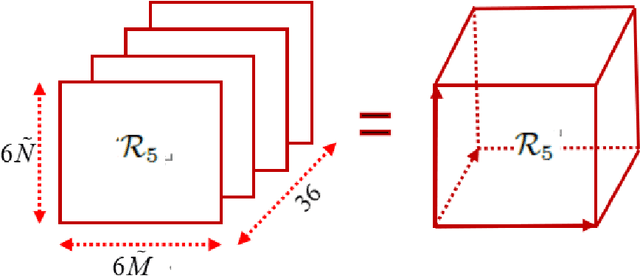
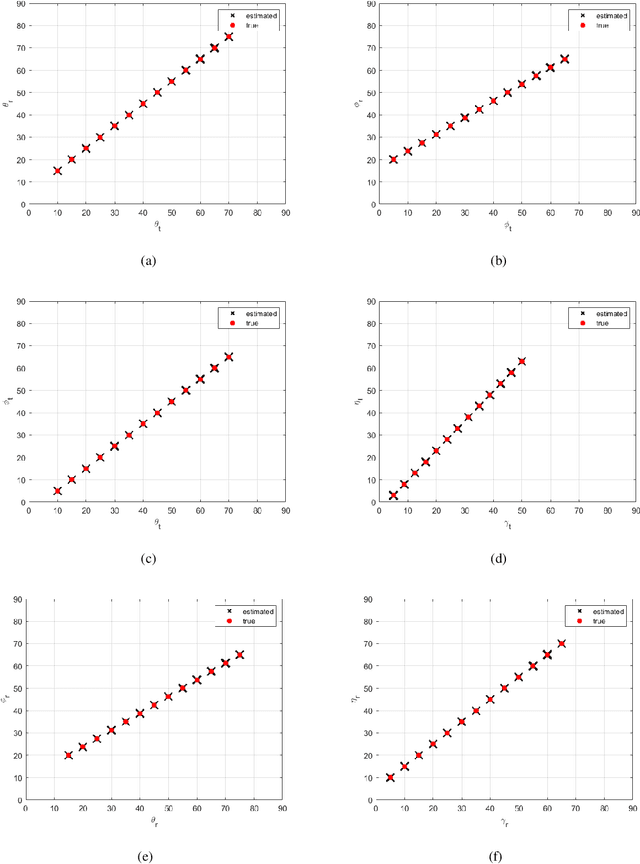
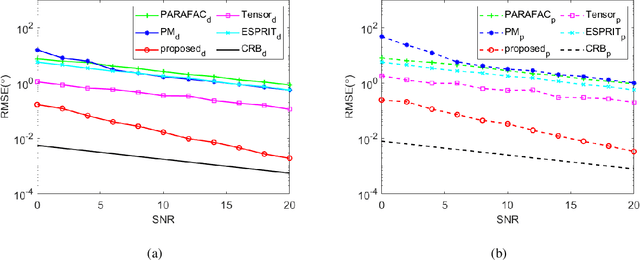
In this paper, the underdetermined 2D-DOD and 2D-DOA estimation for bistatic coprime EMVS-MIMO radar is considered. Firstly, a 5-D tensor model was constructed by using the multi-dimensional space-time characteristics of the received data. Then, an 8-D tensor has been obtained by using the auto-correlation calculation. To obtain the difference coarrays of transmit and receive EMVS, the de-coupling process between the spatial response of EMVS and the steering vector is inevitable. Thus, a new 6-D tensor can be constructed via the tensor permutation and the generalized tensorization of the canonical polyadic decomposition. {According} to the theory of the Tensor-Matrix Product operation, the duplicated elements in the difference coarrays can be removed by the utilization of two designed selection matrices. Due to the centrosymmetric geometry of the difference coarrays, two DFT beamspace matrices were subsequently designed to convert the complex steering matrices into the real-valued ones, whose advantage is to improve the estimation accuracy of the 2D-DODs and 2D-DOAs. Afterwards, a third-order tensor with the third-way fixed at 36 was constructed and the Parallel Factor algorithm was deployed, which can yield the closed-form automatically paired 2D-DOD and 2D-DOA estimation. The simulation results show that the proposed algorithm can exhibit superior estimation performance for the underdetermined 2D-DOD and 2D-DOA estimation.
Joint Depth and Normal Estimation from Real-world Time-of-flight Raw Data
Aug 08, 2021


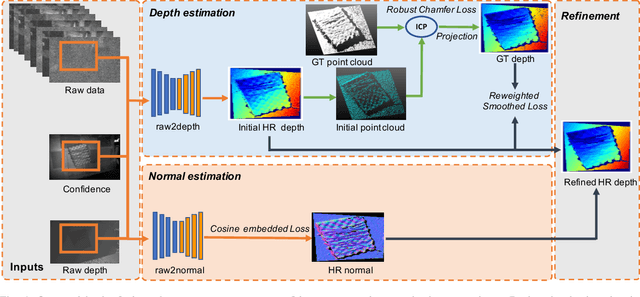
We present a novel approach to joint depth and normal estimation for time-of-flight (ToF) sensors. Our model learns to predict the high-quality depth and normal maps jointly from ToF raw sensor data. To achieve this, we meticulously constructed the first large-scale dataset (named ToF-100) with paired raw ToF data and ground-truth high-resolution depth maps provided by an industrial depth camera. In addition, we also design a simple but effective framework for joint depth and normal estimation, applying a robust Chamfer loss via jittering to improve the performance of our model. Our experiments demonstrate that our proposed method can efficiently reconstruct high-resolution depth and normal maps and significantly outperforms state-of-the-art approaches. Our code and data will be available at \url{https://github.com/hkustVisionRr/JointlyDepthNormalEstimation}
Series Saliency: Temporal Interpretation for Multivariate Time Series Forecasting
Dec 16, 2020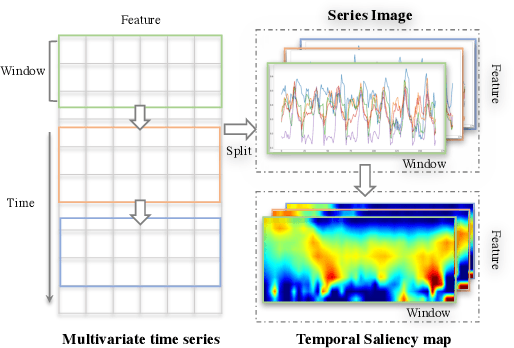
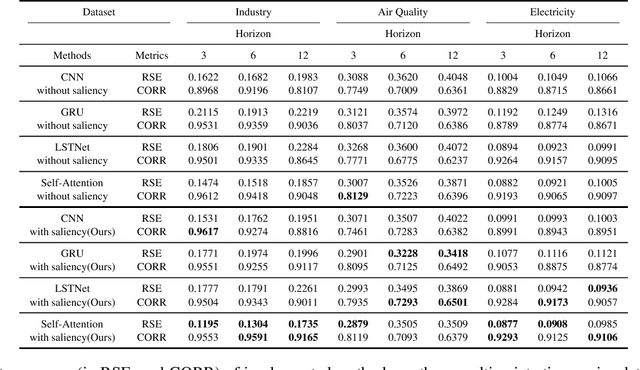
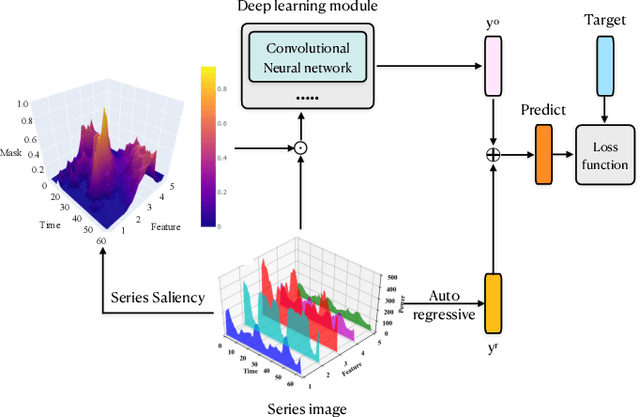

Time series forecasting is an important yet challenging task. Though deep learning methods have recently been developed to give superior forecasting results, it is crucial to improve the interpretability of time series models. Previous interpretation methods, including the methods for general neural networks and attention-based methods, mainly consider the interpretation in the feature dimension while ignoring the crucial temporal dimension. In this paper, we present the series saliency framework for temporal interpretation for multivariate time series forecasting, which considers the forecasting interpretation in both feature and temporal dimensions. By extracting the "series images" from the sliding windows of the time series, we apply the saliency map segmentation following the smallest destroying region principle. The series saliency framework can be employed to any well-defined deep learning models and works as a data augmentation to get more accurate forecasts. Experimental results on several real datasets demonstrate that our framework generates temporal interpretations for the time series forecasting task while produces accurate time series forecast.