 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dense Crowd Flow-Informed Path Planning
Jun 01, 2022
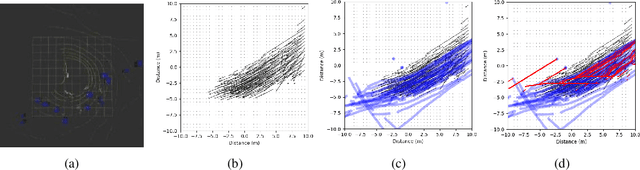
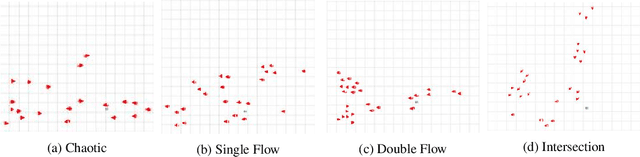
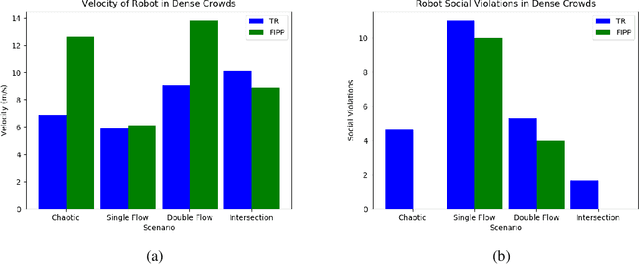
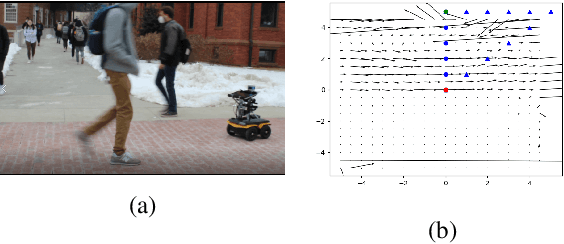
Both pedestrian and robot comfort are of the highest priority whenever a robot is placed in an environment containing human beings. In the case of pedestrian-unaware mobile robots this desire for safety leads to the freezing robot problem, where a robot confronted with a large dynamic group of obstacles (such as a crowd of pedestrians) would determine all forward navigation unsafe causing the robot to stop in place. In order to navigate in a socially compliant manner while avoiding the freezing robot problem we are interested in understanding the flow of pedestrians in crowded scenarios. By treating the pedestrians in the crowd as particles moved along by the crowd itself we can model the system as a time dependent flow field. From this flow field we can extract different flow segments that reflect the motion patterns emerging from the crowd. These motion patterns can then be accounted for during the control and navigation of a mobile robot allowing it to move safely within the flow of the crowd to reach a desired location within or beyond the flow. We combine flow-field extraction with a discrete heuristic search to create Flow-Informed path planning (FIPP). We provide empirical results showing that when compared against a trajectory-rollout local path planner, a robot using FIPP was able not only to reach its goal more quickly but also was shown to be more socially compliant than a robot using traditional techniques both in simulation and on real robots.
Data augmentation with mixtures of max-entropy transformations for filling-level classification
Mar 08, 2022

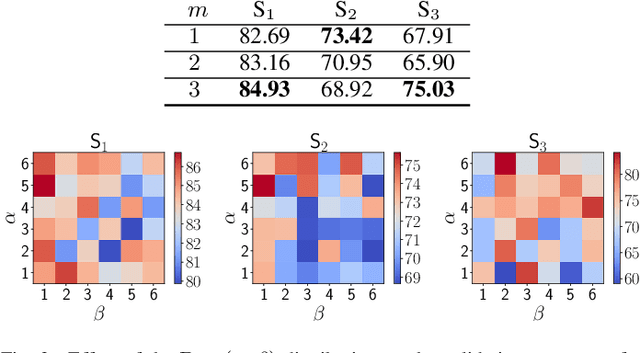
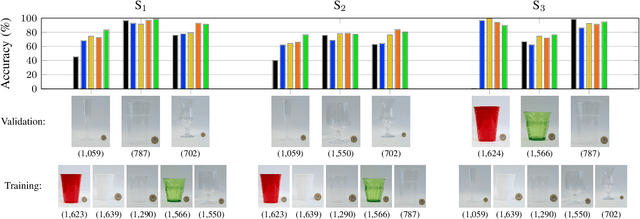
We address the problem of distribution shifts in test-time data with a principled data augmentation scheme for the task of content-level classification. In such a task, properties such as shape or transparency of test-time containers (cup or drinking glass) may differ from those represented in the training data. Dealing with such distribution shifts using standard augmentation schemes is challenging and transforming the training images to cover the properties of the test-time instances requires sophisticated image manipulations. We therefore generate diverse augmentations using a family of max-entropy transformations that create samples with new shapes, colors and spectral characteristics. We show that such a principled augmentation scheme, alone, can replace current approaches that use transfer learning or can be used in combination with transfer learning to improve its performance.
Disentangling A Single MR Modality
May 10, 2022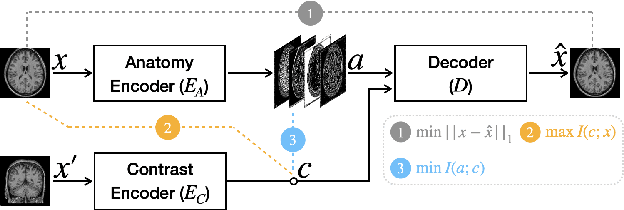
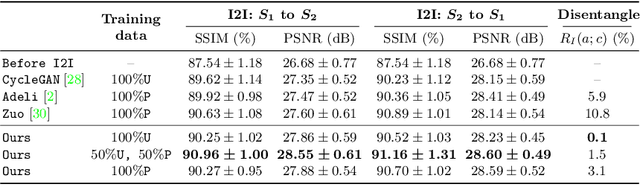
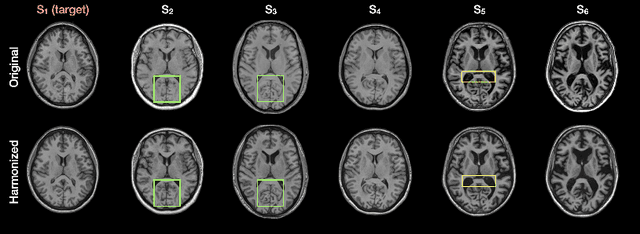
Disentangling anatomical and contrast information from medical images has gained attention recently, demonstrating benefits for various image analysis tasks. Current methods learn disentangled representations using either paired multi-modal images with the same underlying anatomy or auxiliary labels (e.g., manual delineations) to provide inductive bias for disentanglement. However, these requirements could significantly increase the time and cost in data collection and limit the applicability of these methods when such data are not available. Moreover, these methods generally do not guarantee disentanglement. In this paper, we present a novel framework that learns theoretically and practically superior disentanglement from single modality magnetic resonance images. Moreover, we propose a new information-based metric to quantitatively evaluate disentanglement. Comparisons over existing disentangling methods demonstrate that the proposed method achieves superior performance in both disentanglement and cross-domain image-to-image translation tasks.
Dataset Pruning: Reducing Training Data by Examining Generalization Influence
May 19, 2022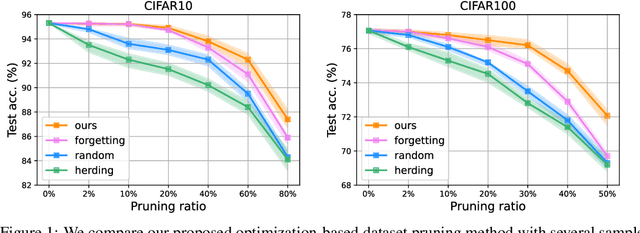

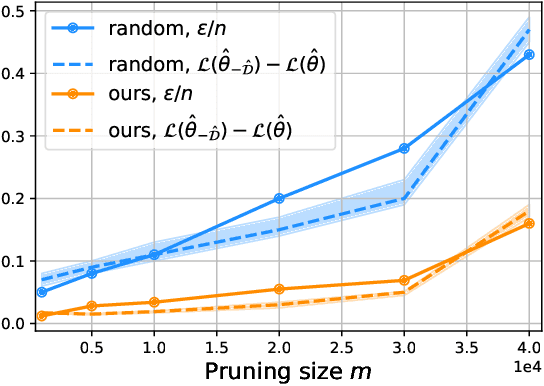
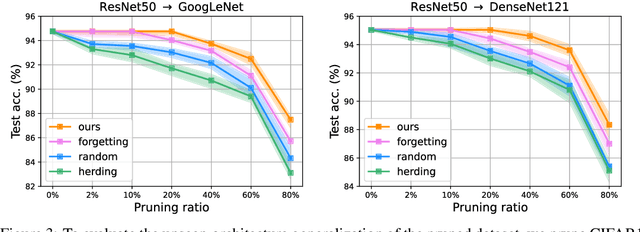
The great success of deep learning heavily relies on increasingly larger training data, which comes at a price of huge computational and infrastructural costs. This poses crucial questions that, do all training data contribute to model's performance? How much does each individual training sample or a sub-training-set affect the model's generalization, and how to construct a smallest subset from the entire training data as a proxy training set without significantly sacrificing the model's performance? To answer these, we propose dataset pruning, an optimization-based sample selection method that can (1) examine the influence of removing a particular set of training samples on model's generalization ability with theoretical guarantee, and (2) construct a smallest subset of training data that yields strictly constrained generalization gap. The empirically observed generalization gap of dataset pruning is substantially consistent with our theoretical expectations. Furthermore, the proposed method prunes 40% training examples on the CIFAR-10 dataset, halves the convergence time with only 1.3% test accuracy decrease, which is superior to previous score-based sample selection methods.
Identical Image Retrieval using Deep Learning
May 10, 2022
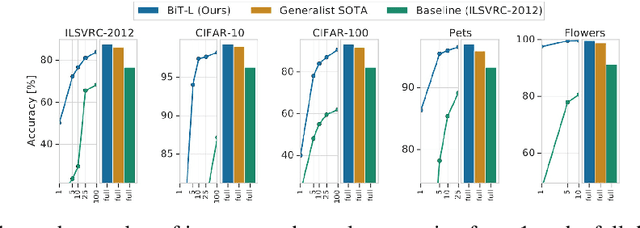
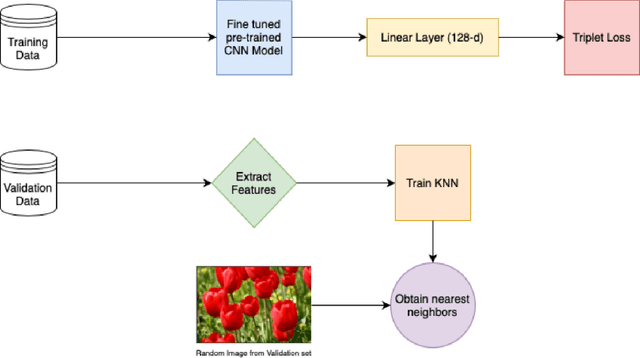

In recent years, we know that the interaction with images has increased. Image similarity involves fetching similar-looking images abiding by a given reference image. The target is to find out whether the image searched as a query can result in similar pictures. We are using the BigTransfer Model, which is a state-of-art model itself. BigTransfer(BiT) is essentially a ResNet but pre-trained on a larger dataset like ImageNet and ImageNet-21k with additional modifications. Using the fine-tuned pre-trained Convolution Neural Network Model, we extract the key features and train on the K-Nearest Neighbor model to obtain the nearest neighbor. The application of our model is to find similar images, which are hard to achieve through text queries within a low inference time. We analyse the benchmark of our model based on this application.
Less is More: Proxy Datasets in NAS approaches
Mar 14, 2022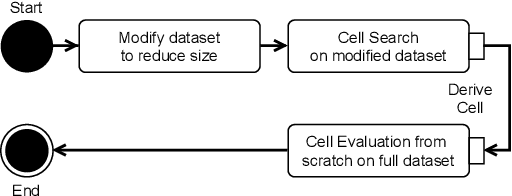
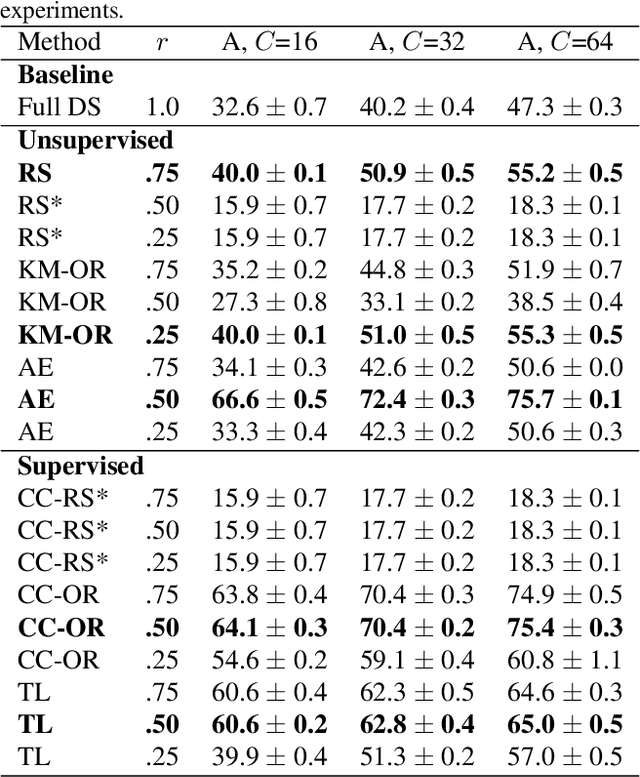
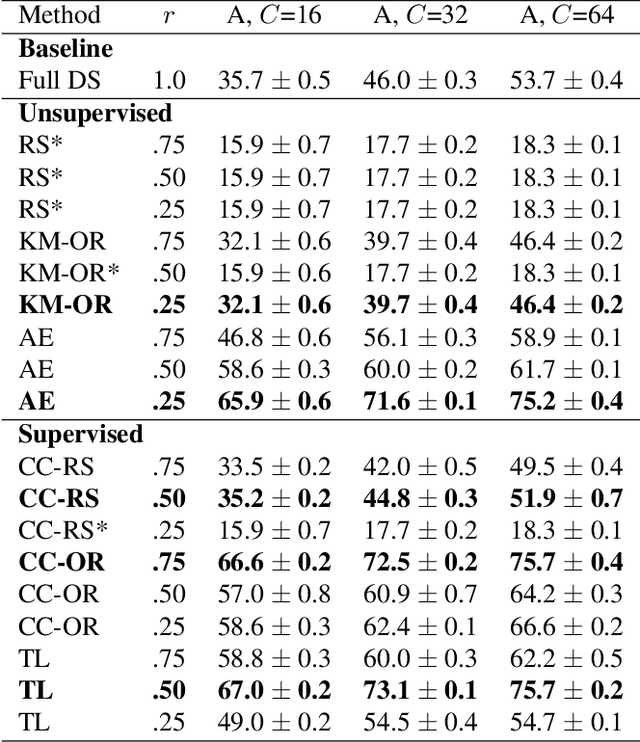
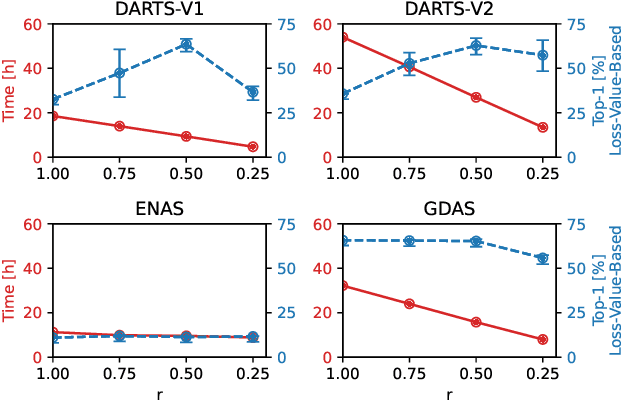
Neural Architecture Search (NAS) defines the design of Neural Networks as a search problem. Unfortunately, NAS is computationally intensive because of various possibilities depending on the number of elements in the design and the possible connections between them. In this work, we extensively analyze the role of the dataset size based on several sampling approaches for reducing the dataset size (unsupervised and supervised cases) as an agnostic approach to reduce search time. We compared these techniques with four common NAS approaches in NAS-Bench-201 in roughly 1,400 experiments on CIFAR-100. One of our surprising findings is that in most cases we can reduce the amount of training data to 25\%, consequently reducing search time to 25\%, while at the same time maintaining the same accuracy as if training on the full dataset. Additionally, some designs derived from subsets out-perform designs derived from the full dataset by up to 22 p.p. accuracy.
Asymptotically Optimal Strategies For Combinatorial Semi-Bandits in Polynomial Time
Feb 14, 2021
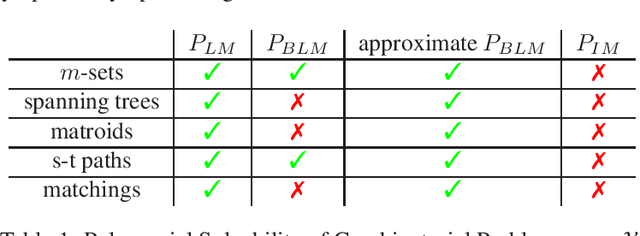


We consider combinatorial semi-bandits with uncorrelated Gaussian rewards. In this article, we propose the first method, to the best of our knowledge, that enables to compute the solution of the Graves-Lai optimization problem in polynomial time for many combinatorial structures of interest. In turn, this immediately yields the first known approach to implement asymptotically optimal algorithms in polynomial time for combinatorial semi-bandits.
AutoJoin: Efficient Adversarial Training for Robust Maneuvering via Denoising Autoencoder and Joint Learning
May 22, 2022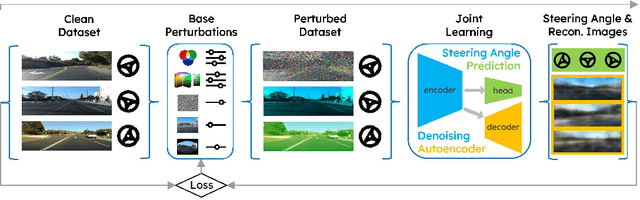
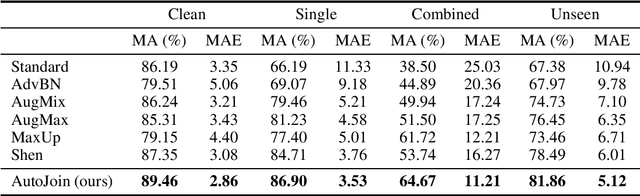

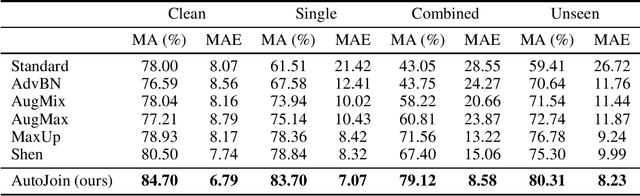
As a result of increasingly adopted machine learning algorithms and ubiquitous sensors, many 'perception-to-control' systems have been deployed in various settings. For these systems to be trustworthy, we need to improve their robustness with adversarial training being one approach. In this work, we propose a gradient-free adversarial training technique, called AutoJoin. AutoJoin is a very simple yet effective and efficient approach to produce robust models for imaged-based autonomous maneuvering. Compared to other SOTA methods with testing on over 5M perturbed and clean images, AutoJoin achieves significant performance increases up to the 40% range under perturbed datasets while improving on clean performance for almost every dataset tested. In particular, AutoJoin can triple the clean performance improvement compared to the SOTA work by Shen et al. Regarding efficiency, AutoJoin demonstrates strong advantages over other SOTA techniques by saving up to 83% time per training epoch and 90% training data. The core idea of AutoJoin is to use a decoder attachment to the original regression model creating a denoising autoencoder within the architecture. This allows the tasks 'steering' and 'denoising sensor input' to be jointly learnt and enable the two tasks to reinforce each other's performance.
Mixture Models for the Analysis, Edition, and Synthesis of Continuous Time Series
Apr 21, 2021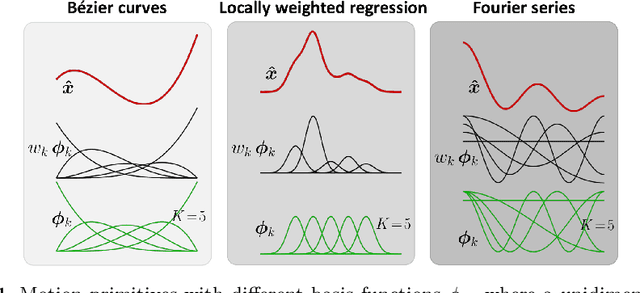

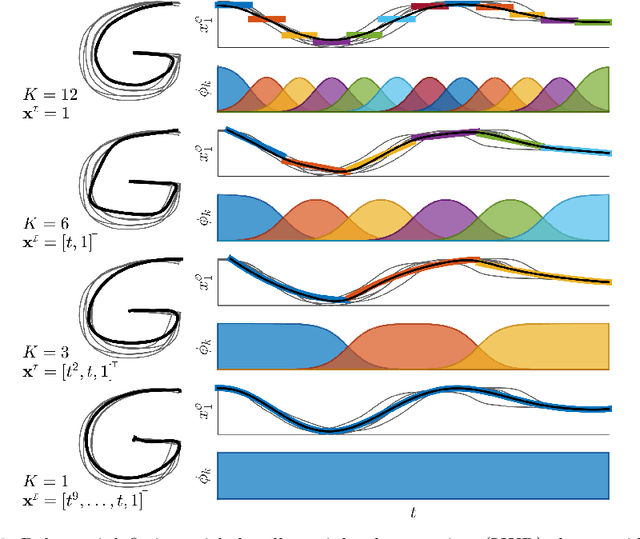
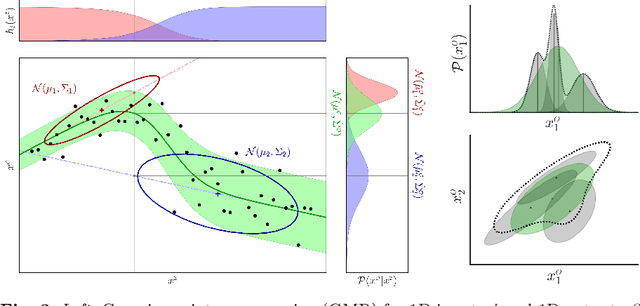
This chapter presents an overview of techniques used for the analysis, edition, and synthesis of time series, with a particular emphasis on motion data. The use of mixture models allows the decomposition of time signals as a superposition of basis functions. It provides a compact representation that aims at keeping the essential characteristics of the signals. Various types of basis functions have been proposed, with developments originating from different fields of research, including computer graphics, human motion science, robotics, control, and neuroscience. Examples of applications with radial, Bernstein and Fourier basis functions will be presented, with associated source codes to get familiar with these techniques.
* 20 pages, 7 figures
NetCut: Real-Time DNN Inference Using Layer Removal
Jan 13, 2021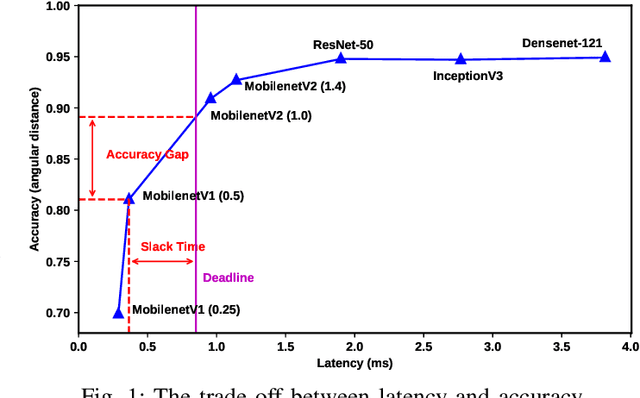
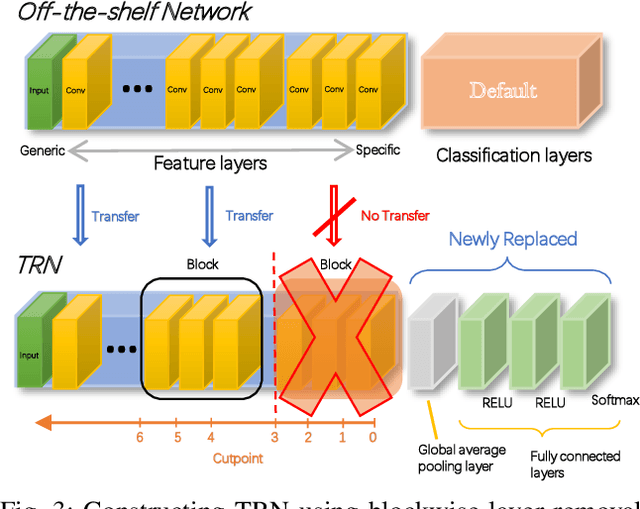
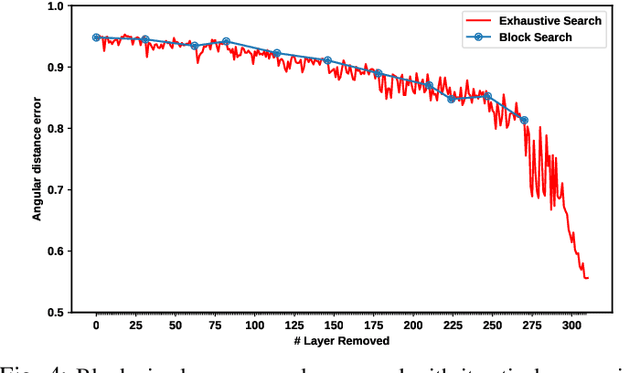
Deep Learning plays a significant role in assisting humans in many aspects of their lives. As these networks tend to get deeper over time, they extract more features to increase accuracy at the cost of additional inference latency. This accuracy-performance trade-off makes it more challenging for Embedded Systems, as resource-constrained processors with strict deadlines, to deploy them efficiently. This can lead to selection of networks that can prematurely meet a specified deadline with excess slack time that could have potentially contributed to increased accuracy. In this work, we propose: (i) the concept of layer removal as a means of constructing TRimmed Networks (TRNs) that are based on removing problem-specific features of a pretrained network used in transfer learning, and (ii) NetCut, a methodology based on an empirical or an analytical latency estimator, which only proposes and retrains TRNs that can meet the application's deadline, hence reducing the exploration time significantly. We demonstrate that TRNs can expand the Pareto frontier that trades off latency and accuracy to provide networks that can meet arbitrary deadlines with potential accuracy improvement over off-the-shelf networks. Our experimental results show that such utilization of TRNs, while transferring to a simpler dataset, in combination with NetCut, can lead to the proposal of networks that can achieve relative accuracy improvement of up to 10.43% among existing off-the-shelf neural architectures while meeting a specific deadline, and 27x speedup in exploration time.