 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Order of Encoding for Gaussian MIMO Multi-Receiver Wiretap Channel
May 13, 2022
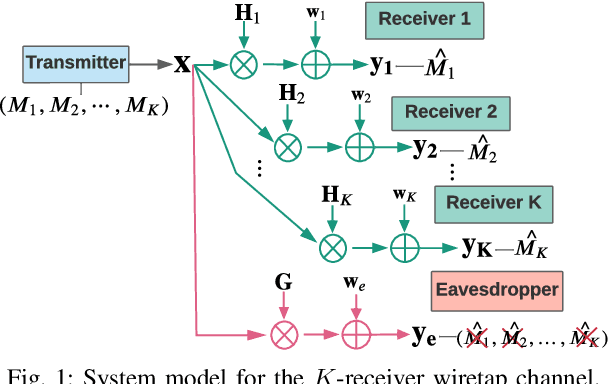
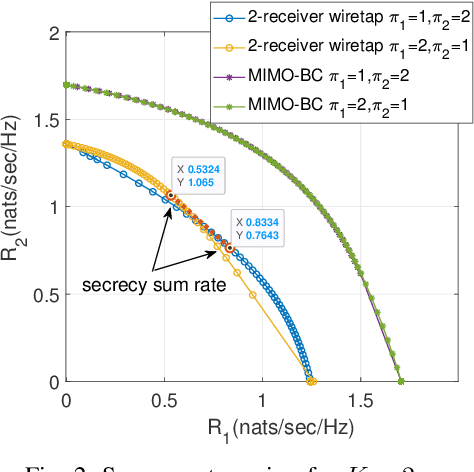
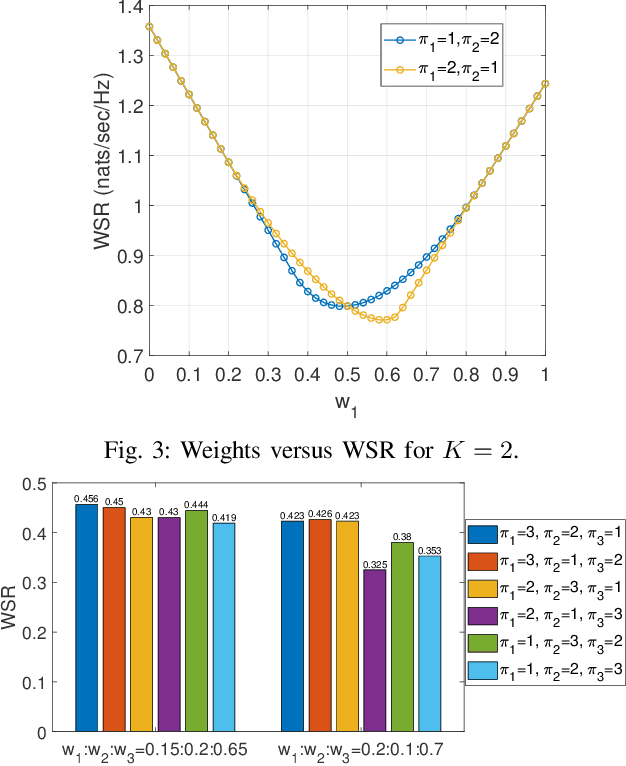
The Gaussian multiple-input multiple-output (MIMO) multi-receiver wiretap channel is studied in this paper. The base station broadcasts confidential messages to K intended users while keeping the messages secret from an eavesdropper. The capacity of this channel has already been characterized by applying dirty-paper coding and stochastic encoding. However, K factorial encoding orders may need to be enumerated for that, which makes the problem intractable. We prove that there exists one optimal encoding order and reduced the K factorial times to a one-time encoding. The optimal encoding order is proved by forming a secrecy weighted sum rate (WSR) maximization problem. The optimal order is the same as that for the MIMO broadcast channel without secrecy constraint, that is, the weight of users' rate in the WSR maximization problem determines the optimal encoding order. Numerical results verify the optimal encoding order.
Creating Multimedia Summaries Using Tweets and Videos
Mar 16, 2022

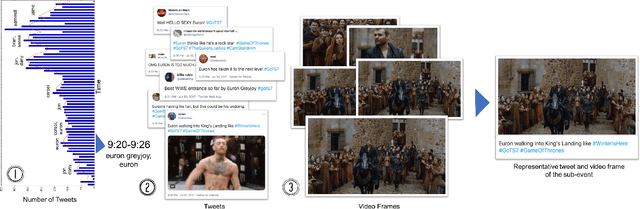
While popular televised events such as presidential debates or TV shows are airing, people provide commentary on them in real-time. In this paper, we propose a simple yet effective approach to combine social media commentary and videos to create a multimedia summary of televised events. Our approach identifies scenes from these events based on spikes of mentions of people involved in the event and automatically selects tweets and frames from the videos that occur during the time period of the spike that talk about and show the people being discussed.
Simplifying Node Classification on Heterophilous Graphs with Compatible Label Propagation
May 19, 2022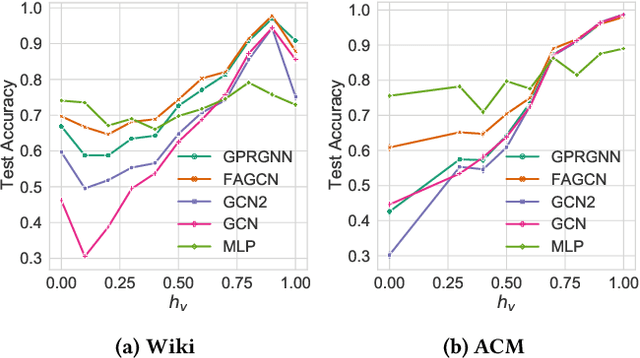

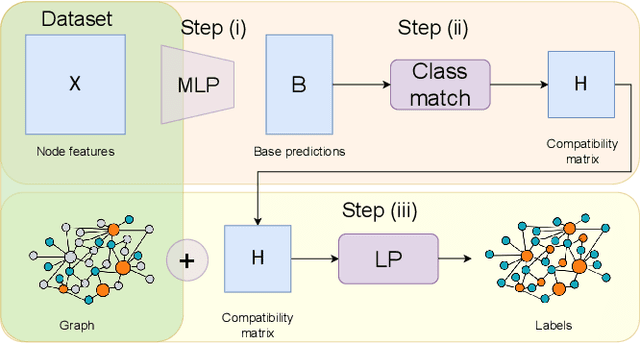
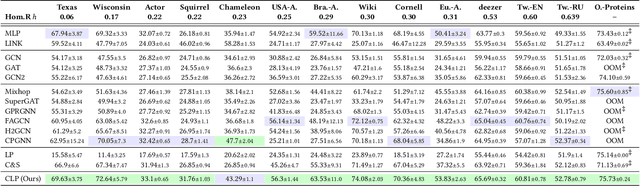
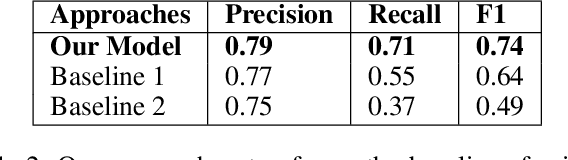
Graph Neural Networks (GNNs) have been predominant for graph learning tasks; however, recent studies showed that a well-known graph algorithm, Label Propagation (LP), combined with a shallow neural network can achieve comparable performance to GNNs in semi-supervised node classification on graphs with high homophily. In this paper, we show that this approach falls short on graphs with low homophily, where nodes often connect to the nodes of the opposite classes. To overcome this, we carefully design a combination of a base predictor with LP algorithm that enjoys a closed-form solution as well as convergence guarantees. Our algorithm first learns the class compatibility matrix and then aggregates label predictions using LP algorithm weighted by class compatibilities. On a wide variety of benchmarks, we show that our approach achieves the leading performance on graphs with various levels of homophily. Meanwhile, it has orders of magnitude fewer parameters and requires less execution time. Empirical evaluations demonstrate that simple adaptations of LP can be competitive in semi-supervised node classification in both homophily and heterophily regimes.
Autonomous Vehicle Calibration via Linear Optimization
Apr 27, 2022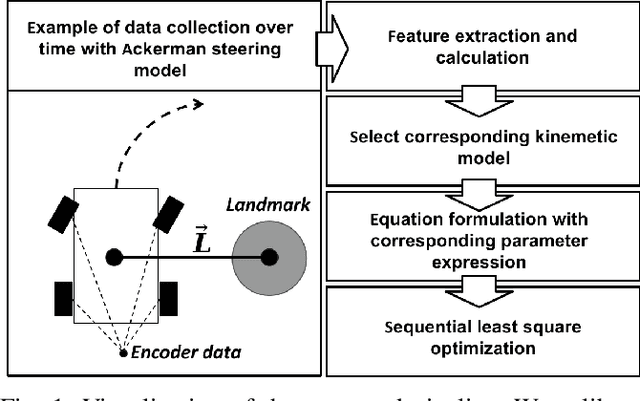
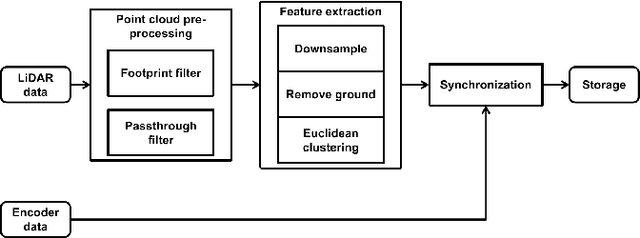
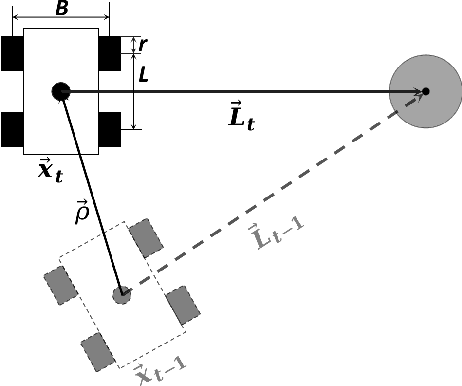
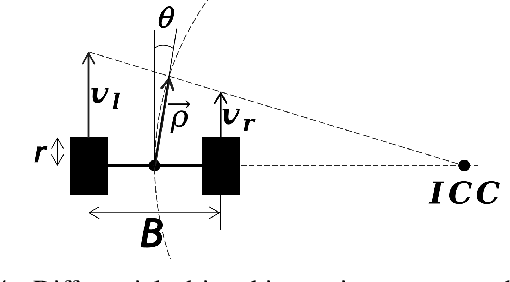
In navigation activities, kinematic parameters of a mobile vehicle play a significant role. Odometry is most commonly used for dead reckoning. However, the unrestricted accumulation of errors is a disadvantage using this method. As a result, it is necessary to calibrate odometry parameters to minimize the error accumulation. This paper presents a pipeline based on sequential least square programming to minimize the relative position displacement of an arbitrary landmark in consecutive time steps of a kinematic vehicle model by calibrating the parameters of applied model. Results showed that the developed pipeline produced accurate results with small datasets.
Dense Crowd Flow-Informed Path Planning
Jun 01, 2022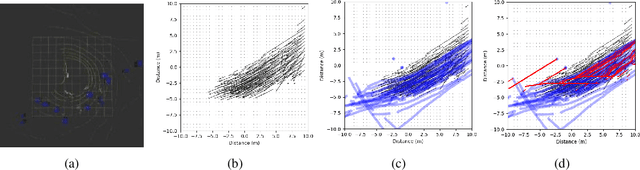
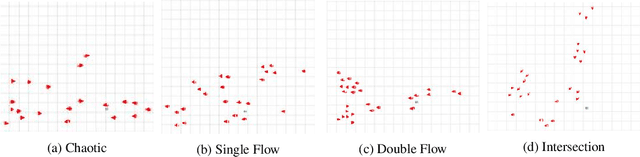
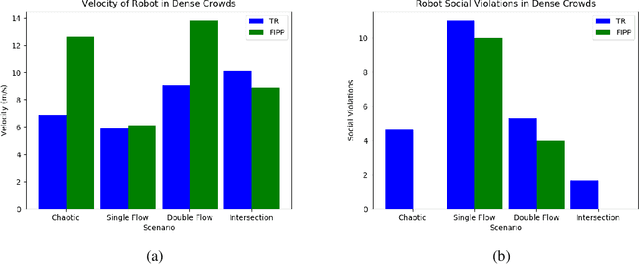
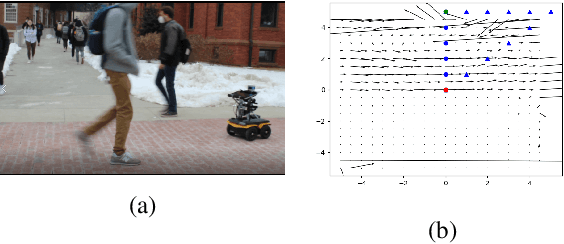
Both pedestrian and robot comfort are of the highest priority whenever a robot is placed in an environment containing human beings. In the case of pedestrian-unaware mobile robots this desire for safety leads to the freezing robot problem, where a robot confronted with a large dynamic group of obstacles (such as a crowd of pedestrians) would determine all forward navigation unsafe causing the robot to stop in place. In order to navigate in a socially compliant manner while avoiding the freezing robot problem we are interested in understanding the flow of pedestrians in crowded scenarios. By treating the pedestrians in the crowd as particles moved along by the crowd itself we can model the system as a time dependent flow field. From this flow field we can extract different flow segments that reflect the motion patterns emerging from the crowd. These motion patterns can then be accounted for during the control and navigation of a mobile robot allowing it to move safely within the flow of the crowd to reach a desired location within or beyond the flow. We combine flow-field extraction with a discrete heuristic search to create Flow-Informed path planning (FIPP). We provide empirical results showing that when compared against a trajectory-rollout local path planner, a robot using FIPP was able not only to reach its goal more quickly but also was shown to be more socially compliant than a robot using traditional techniques both in simulation and on real robots.
Disentangling A Single MR Modality
May 10, 2022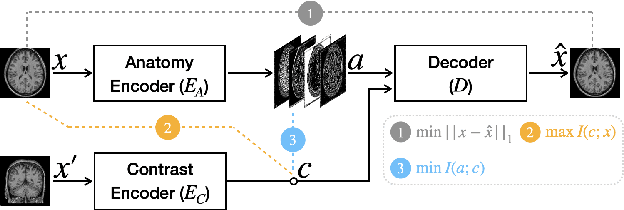
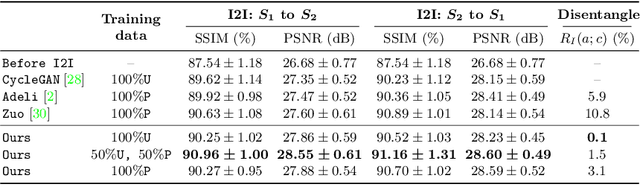
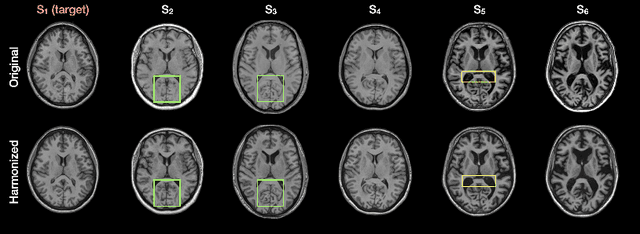
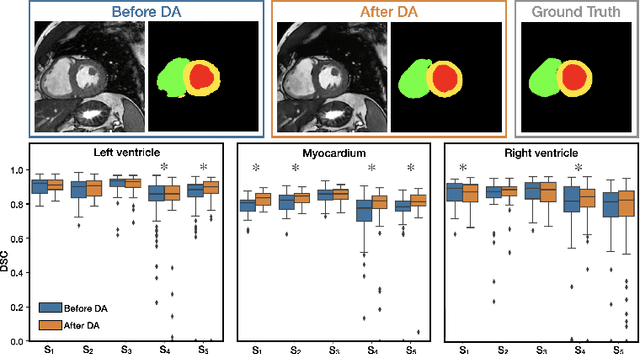
Disentangling anatomical and contrast information from medical images has gained attention recently, demonstrating benefits for various image analysis tasks. Current methods learn disentangled representations using either paired multi-modal images with the same underlying anatomy or auxiliary labels (e.g., manual delineations) to provide inductive bias for disentanglement. However, these requirements could significantly increase the time and cost in data collection and limit the applicability of these methods when such data are not available. Moreover, these methods generally do not guarantee disentanglement. In this paper, we present a novel framework that learns theoretically and practically superior disentanglement from single modality magnetic resonance images. Moreover, we propose a new information-based metric to quantitatively evaluate disentanglement. Comparisons over existing disentangling methods demonstrate that the proposed method achieves superior performance in both disentanglement and cross-domain image-to-image translation tasks.
Dataset Pruning: Reducing Training Data by Examining Generalization Influence
May 19, 2022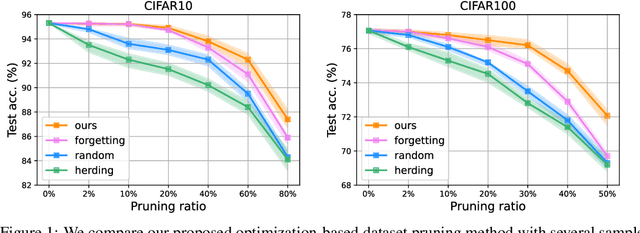

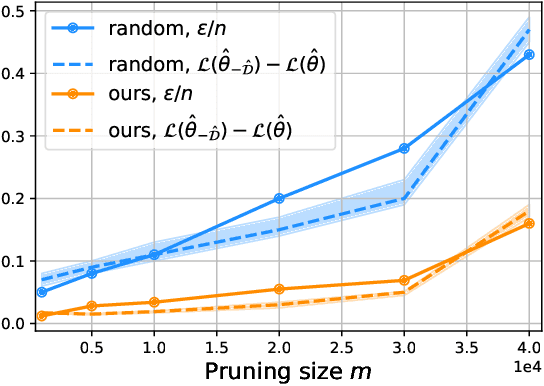
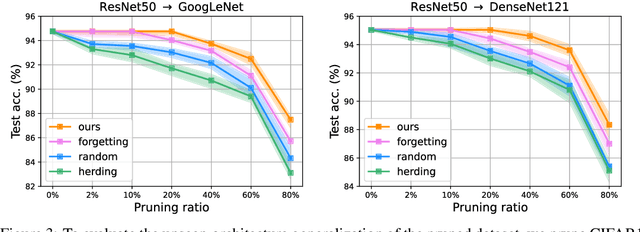
The great success of deep learning heavily relies on increasingly larger training data, which comes at a price of huge computational and infrastructural costs. This poses crucial questions that, do all training data contribute to model's performance? How much does each individual training sample or a sub-training-set affect the model's generalization, and how to construct a smallest subset from the entire training data as a proxy training set without significantly sacrificing the model's performance? To answer these, we propose dataset pruning, an optimization-based sample selection method that can (1) examine the influence of removing a particular set of training samples on model's generalization ability with theoretical guarantee, and (2) construct a smallest subset of training data that yields strictly constrained generalization gap. The empirically observed generalization gap of dataset pruning is substantially consistent with our theoretical expectations. Furthermore, the proposed method prunes 40% training examples on the CIFAR-10 dataset, halves the convergence time with only 1.3% test accuracy decrease, which is superior to previous score-based sample selection methods.
Identical Image Retrieval using Deep Learning
May 10, 2022
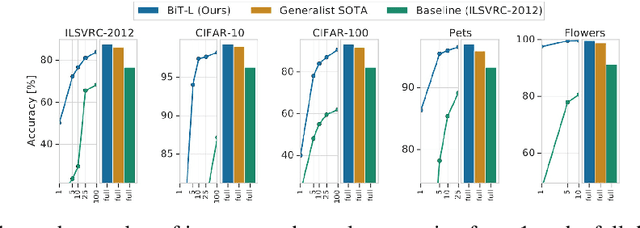
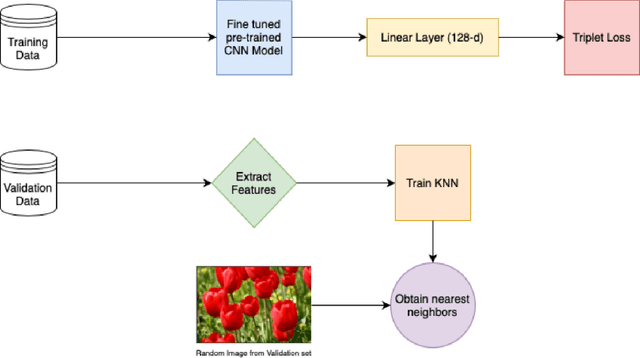

In recent years, we know that the interaction with images has increased. Image similarity involves fetching similar-looking images abiding by a given reference image. The target is to find out whether the image searched as a query can result in similar pictures. We are using the BigTransfer Model, which is a state-of-art model itself. BigTransfer(BiT) is essentially a ResNet but pre-trained on a larger dataset like ImageNet and ImageNet-21k with additional modifications. Using the fine-tuned pre-trained Convolution Neural Network Model, we extract the key features and train on the K-Nearest Neighbor model to obtain the nearest neighbor. The application of our model is to find similar images, which are hard to achieve through text queries within a low inference time. We analyse the benchmark of our model based on this application.
NRTSI: Non-Recurrent Time Series Imputation for Irregularly-sampled Data
Feb 17, 2021
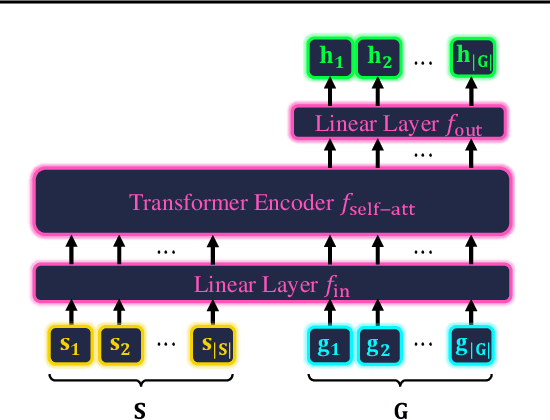

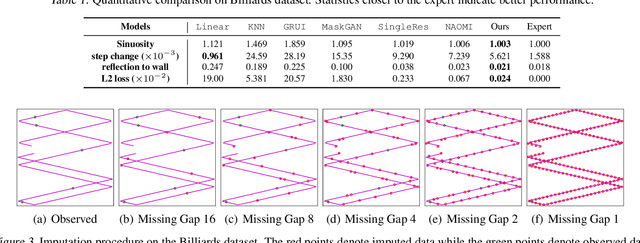
Time series imputation is a fundamental task for understanding time series with missing data. Existing imputation methods often rely on recurrent models such as RNNs and ordinary differential equations, both of which suffer from the error compounding problems of recurrent models. In this work, we view the imputation task from the perspective of permutation equivariant modeling of sets and propose a novel imputation model called NRTSI without any recurrent modules. Taking advantage of the permutation equivariant nature of NRTSI, we design a principled and efficient hierarchical imputation procedure. NRTSI can easily handle irregularly-sampled data, perform multiple-mode stochastic imputation, and handle the scenario where dimensions are partially observed. We show that NRTSI achieves state-of-the-art performance across a wide range of commonly used time series imputation benchmarks.
Meta-Learning for Time Series Forecasting Ensemble
Nov 20, 2020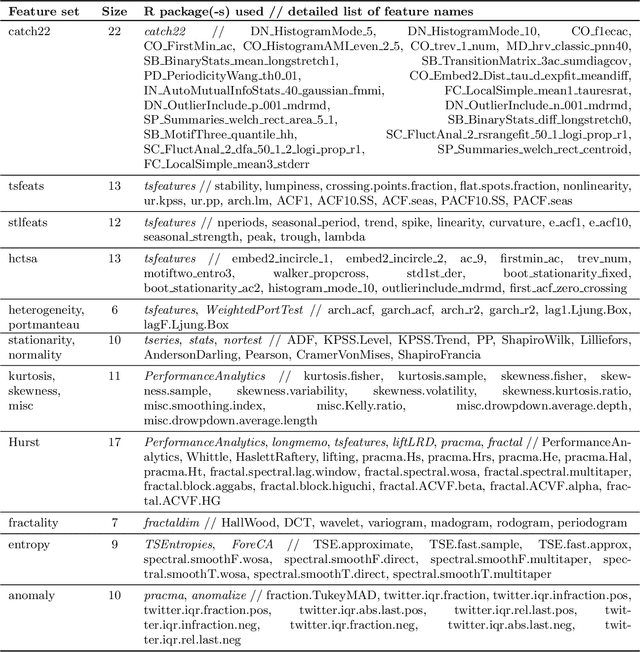

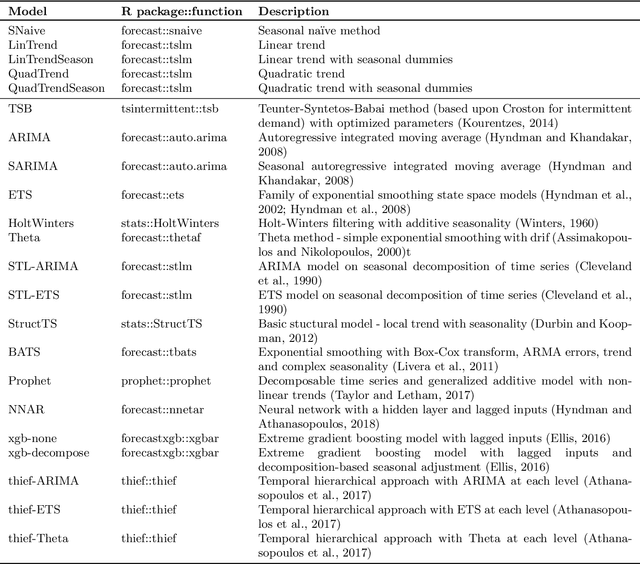
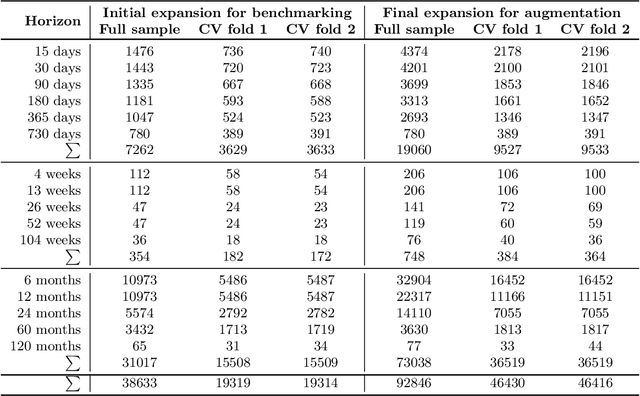
Amounts of historical data collected increase together with business intelligence applicability and demands for automatic forecasting of time series. While no single time series modeling method is universal to all types of dynamics, forecasting using ensemble of several methods is often seen as a compromise. Instead of fixing ensemble diversity and size we propose to adaptively predict these aspects using meta-learning. Meta-learning here considers two separate random forest regression models, built on 390 time series features, to rank 22 univariate forecasting methods and to recommend ensemble size. Forecasting ensemble is consequently formed from methods ranked as the best and forecasts are pooled using either simple or weighted average (with weight corresponding to reciprocal rank). Proposed approach was tested on 12561 micro-economic time series (expanded to 38633 for various forecasting horizons) of M4 competition where meta-learning outperformed Theta and Comb benchmarks by relative forecasting errors for all data types and horizons. Best overall results were achieved by weighted pooling with symmetric mean absolute percentage error of 9.21% versus 11.05% obtained using Theta method.