 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning a Single Neuron with Adversarial Label Noise via Gradient Descent
Jun 17, 2022
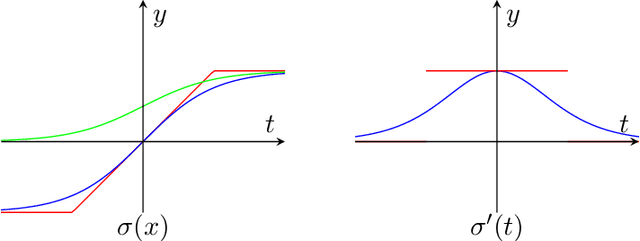

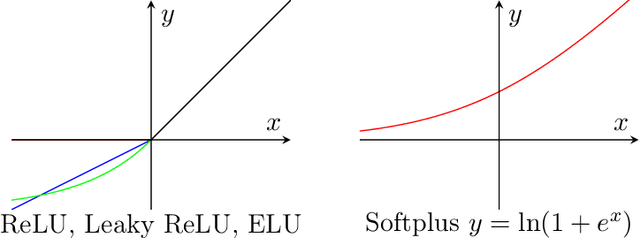
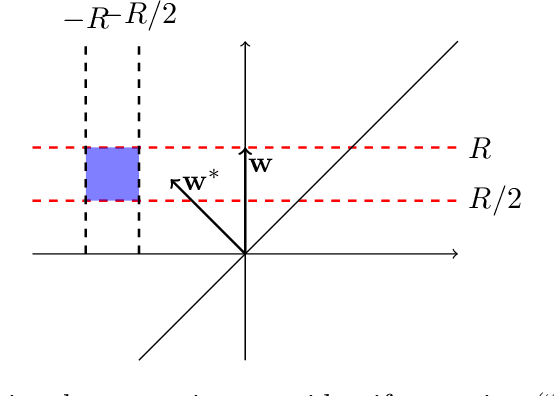
We study the fundamental problem of learning a single neuron, i.e., a function of the form $\mathbf{x}\mapsto\sigma(\mathbf{w}\cdot\mathbf{x})$ for monotone activations $\sigma:\mathbb{R}\mapsto\mathbb{R}$, with respect to the $L_2^2$-loss in the presence of adversarial label noise. Specifically, we are given labeled examples from a distribution $D$ on $(\mathbf{x}, y)\in\mathbb{R}^d \times \mathbb{R}$ such that there exists $\mathbf{w}^\ast\in\mathbb{R}^d$ achieving $F(\mathbf{w}^\ast)=\epsilon$, where $F(\mathbf{w})=\mathbf{E}_{(\mathbf{x},y)\sim D}[(\sigma(\mathbf{w}\cdot \mathbf{x})-y)^2]$. The goal of the learner is to output a hypothesis vector $\mathbf{w}$ such that $F(\mathbb{w})=C\, \epsilon$ with high probability, where $C>1$ is a universal constant. As our main contribution, we give efficient constant-factor approximate learners for a broad class of distributions (including log-concave distributions) and activation functions. Concretely, for the class of isotropic log-concave distributions, we obtain the following important corollaries: For the logistic activation, we obtain the first polynomial-time constant factor approximation (even under the Gaussian distribution). Our algorithm has sample complexity $\widetilde{O}(d/\epsilon)$, which is tight within polylogarithmic factors. For the ReLU activation, we give an efficient algorithm with sample complexity $\tilde{O}(d\, \polylog(1/\epsilon))$. Prior to our work, the best known constant-factor approximate learner had sample complexity $\tilde{\Omega}(d/\epsilon)$. In both of these settings, our algorithms are simple, performing gradient-descent on the (regularized) $L_2^2$-loss. The correctness of our algorithms relies on novel structural results that we establish, showing that (essentially all) stationary points of the underlying non-convex loss are approximately optimal.
Rethinking Reinforcement Learning for Recommendation: A Prompt Perspective
Jun 15, 2022
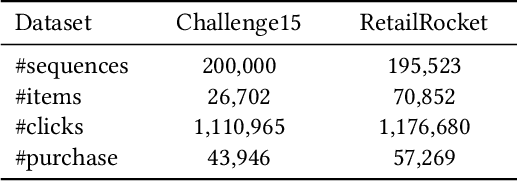
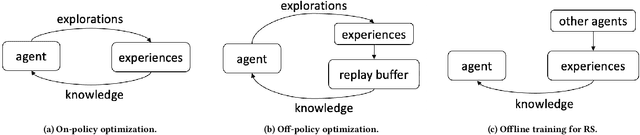
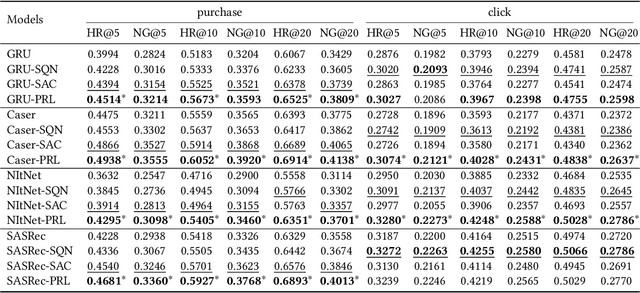
Modern recommender systems aim to improve user experience. As reinforcement learning (RL) naturally fits this objective -- maximizing an user's reward per session -- it has become an emerging topic in recommender systems. Developing RL-based recommendation methods, however, is not trivial due to the \emph{offline training challenge}. Specifically, the keystone of traditional RL is to train an agent with large amounts of online exploration making lots of `errors' in the process. In the recommendation setting, though, we cannot afford the price of making `errors' online. As a result, the agent needs to be trained through offline historical implicit feedback, collected under different recommendation policies; traditional RL algorithms may lead to sub-optimal policies under these offline training settings. Here we propose a new learning paradigm -- namely Prompt-Based Reinforcement Learning (PRL) -- for the offline training of RL-based recommendation agents. While traditional RL algorithms attempt to map state-action input pairs to their expected rewards (e.g., Q-values), PRL directly infers actions (i.e., recommended items) from state-reward inputs. In short, the agents are trained to predict a recommended item given the prior interactions and an observed reward value -- with simple supervised learning. At deployment time, this historical (training) data acts as a knowledge base, while the state-reward pairs are used as a prompt. The agents are thus used to answer the question: \emph{ Which item should be recommended given the prior interactions \& the prompted reward value}? We implement PRL with four notable recommendation models and conduct experiments on two real-world e-commerce datasets. Experimental results demonstrate the superior performance of our proposed methods.
Scenario-based Multi-product Advertising Copywriting Generation for E-Commerce
May 21, 2022

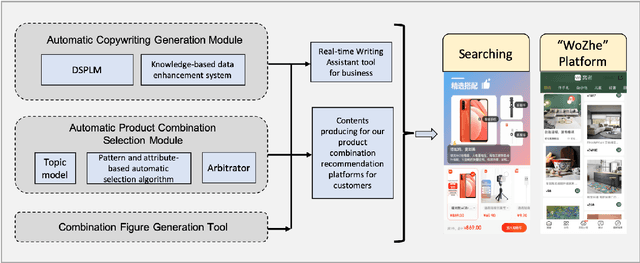
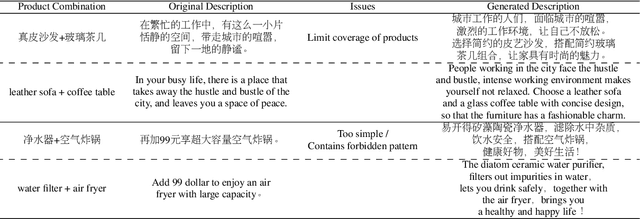
In this paper, we proposed an automatic Scenario-based Multi-product Advertising Copywriting Generation system (SMPACG) for E-Commerce, which has been deployed on a leading Chinese e-commerce platform. The proposed SMPACG consists of two main components: 1) an automatic multi-product combination selection module, which itself is consisted of a topic prediction model, a pattern and attribute-based selection model and an arbitrator model; and 2) an automatic multi-product advertising copywriting generation module, which combines our proposed domain-specific pretrained language model and knowledge-based data enhancement model. The SMPACG is the first system that realizes automatic scenario-based multi-product advertising contents generation, which achieves significant improvements over other state-of-the-art methods. The SMPACG has been not only developed for directly serving for our e-commerce recommendation system, but also used as a real-time writing assistant tool for merchants.
hmBERT: Historical Multilingual Language Models for Named Entity Recognition
May 31, 2022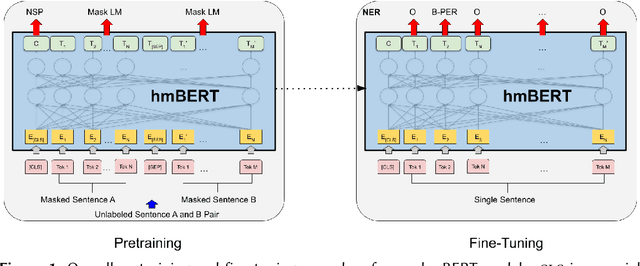



Compared to standard Named Entity Recognition (NER), identifying persons, locations, and organizations in historical texts forms a big challenge. To obtain machine-readable corpora, the historical text is usually scanned and optical character recognition (OCR) needs to be performed. As a result, the historical corpora contain errors. Also, entities like location or organization can change over time, which poses another challenge. Overall historical texts come with several peculiarities that differ greatly from modern texts and large labeled corpora for training a neural tagger are hardly available for this domain. In this work, we tackle NER for historical German, English, French, Swedish, and Finnish by training large historical language models. We circumvent the need for labeled data by using unlabeled data for pretraining a language model. hmBERT, a historical multilingual BERT-based language model is proposed, with different sizes of it being publicly released. Furthermore, we evaluate the capability of hmBERT by solving downstream NER as part of this year's HIPE-2022 shared task and provide detailed analysis and insights. For the Multilingual Classical Commentary coarse-grained NER challenge, our tagger HISTeria outperforms the other teams' models for two out of three languages.
Soft Robotic Mannequin: Design and Algorithm for Deformation Control
May 23, 2022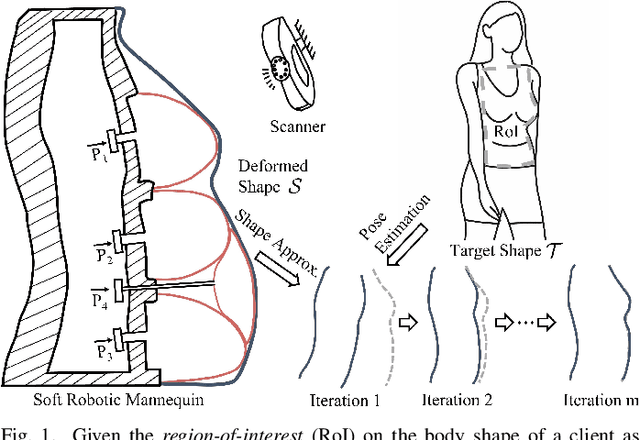
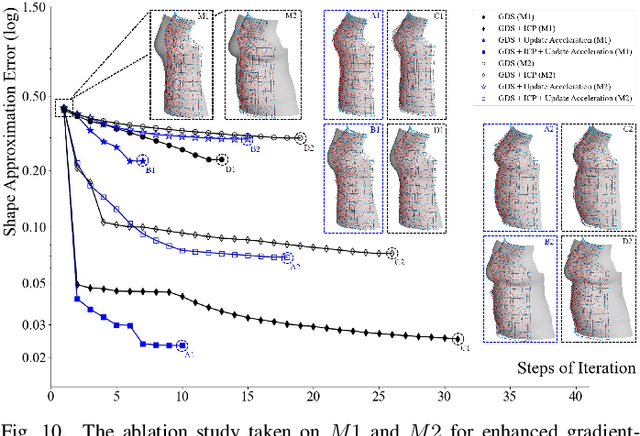
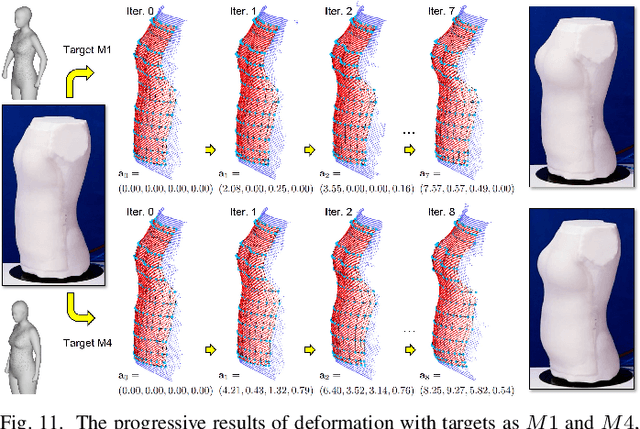
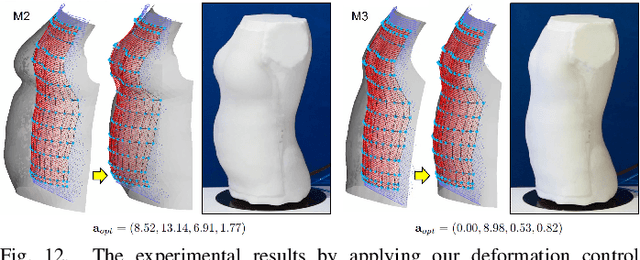
This paper presents a novel soft robotic system for a deformable mannequin that can be employed to physically realize the 3D geometry of different human bodies. The soft membrane on a mannequin is deformed by inflating several curved chambers using pneumatic actuation. Controlling the freeform surface of a soft membrane by adjusting the pneumatic actuation in different chambers is challenging as the membrane's shape is commonly determined by the interaction between all chambers. Using vision feedback provided by a structured-light based 3D scanner, we developed an efficient algorithm to compute the optimized actuation of all chambers which could drive the soft membrane to deform into the best approximation of different target shapes. Our algorithm converges quickly by including pose estimation in the loop of optimization. The time-consuming step of evaluating derivatives on the deformable membrane is avoided by using the Broyden update when possible. The effectiveness of our soft robotic mannequin with controlled deformation has been verified in experiments.
Controllable Video Generation through Global and Local Motion Dynamics
Apr 13, 2022
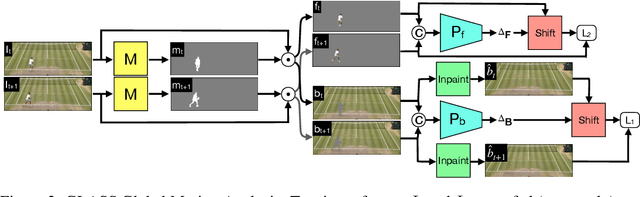
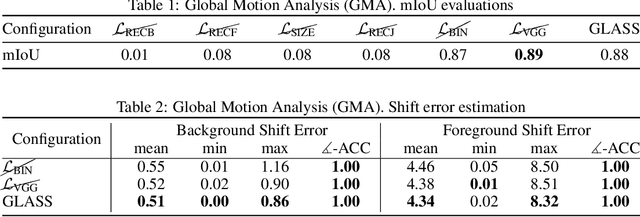
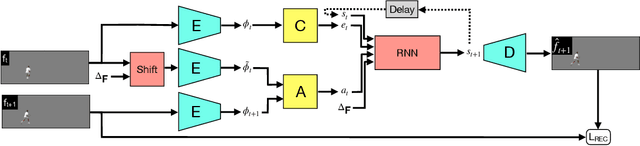
We present GLASS, a method for Global and Local Action-driven Sequence Synthesis. GLASS is a generative model that is trained on video sequences in an unsupervised manner and that can animate an input image at test time. The method learns to segment frames into foreground-background layers and to generate transitions of the foregrounds over time through a global and local action representation. Global actions are explicitly related to 2D shifts, while local actions are instead related to (both geometric and photometric) local deformations. GLASS uses a recurrent neural network to transition between frames and is trained through a reconstruction loss. We also introduce W-Sprites (Walking Sprites), a novel synthetic dataset with a predefined action space. We evaluate our method on both W-Sprites and real datasets, and find that GLASS is able to generate realistic video sequences from a single input image and to successfully learn a more advanced action space than in prior work.
Transformers from an Optimization Perspective
May 27, 2022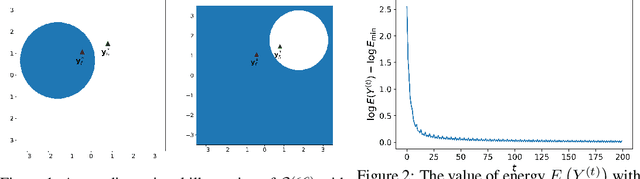
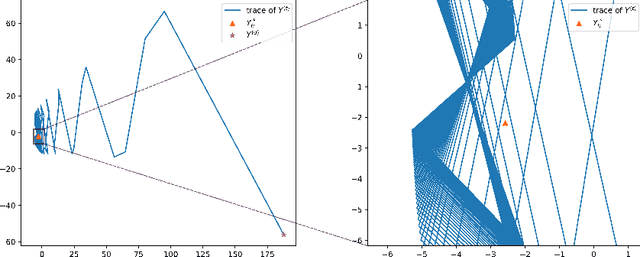
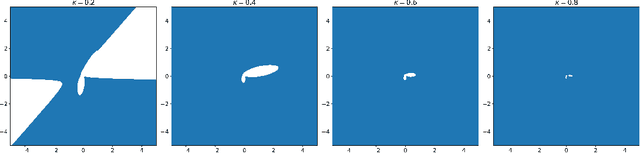
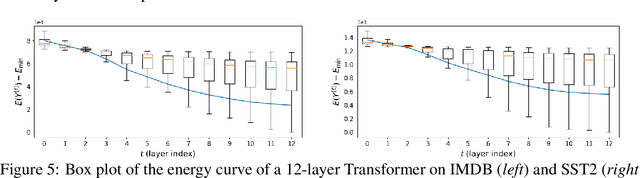
Deep learning models such as the Transformer are often constructed by heuristics and experience. To provide a complementary foundation, in this work we study the following problem: Is it possible to find an energy function underlying the Transformer model, such that descent steps along this energy correspond with the Transformer forward pass? By finding such a function, we can reinterpret Transformers as the unfolding of an interpretable optimization process across iterations. This unfolding perspective has been frequently adopted in the past to elucidate more straightforward deep models such as MLPs and CNNs; however, it has thus far remained elusive obtaining a similar equivalence for more complex models with self-attention mechanisms like the Transformer. To this end, we first outline several major obstacles before providing companion techniques to at least partially address them, demonstrating for the first time a close association between energy function minimization and deep layers with self-attention. This interpretation contributes to our intuition and understanding of Transformers, while potentially laying the ground-work for new model designs.
Linear-Time Gromov Wasserstein Distances using Low Rank Couplings and Costs
Jun 02, 2021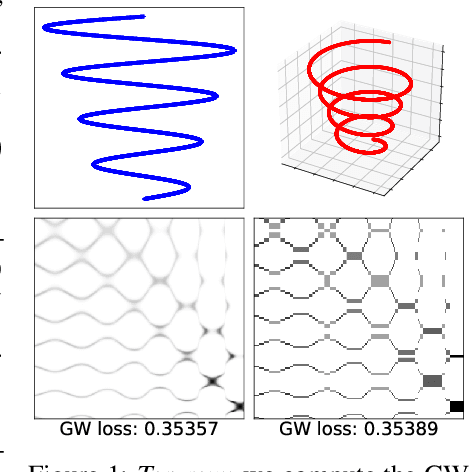
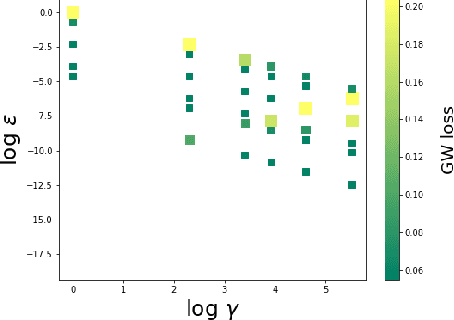
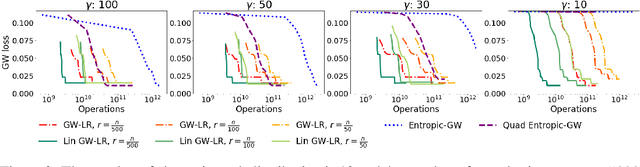
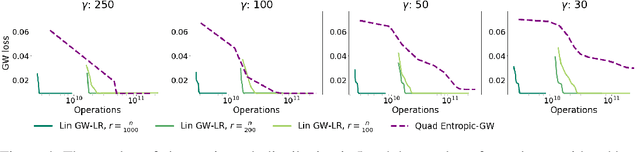
The ability to compare and align related datasets living in heterogeneous spaces plays an increasingly important role in machine learning. The Gromov-Wasserstein (GW) formalism can help tackle this problem. Its main goal is to seek an assignment (more generally a coupling matrix) that can register points across otherwise incomparable datasets. As a non-convex and quadratic generalization of optimal transport (OT), GW is NP-hard. Yet, heuristics are known to work reasonably well in practice, the state of the art approach being to solve a sequence of nested regularized OT problems. While popular, that heuristic remains too costly to scale, with cubic complexity in the number of samples $n$. We show in this paper how a recent variant of the Sinkhorn algorithm can substantially speed up the resolution of GW. That variant restricts the set of admissible couplings to those admitting a low rank factorization as the product of two sub-couplings. By updating alternatively each sub-coupling, our algorithm computes a stationary point of the problem in quadratic time with respect to the number of samples. When cost matrices have themselves low rank, our algorithm has time complexity $\mathcal{O}(n)$. We demonstrate the efficiency of our method on simulated and real data.
Forecasting the abnormal events at well drilling with machine learning
Mar 10, 2022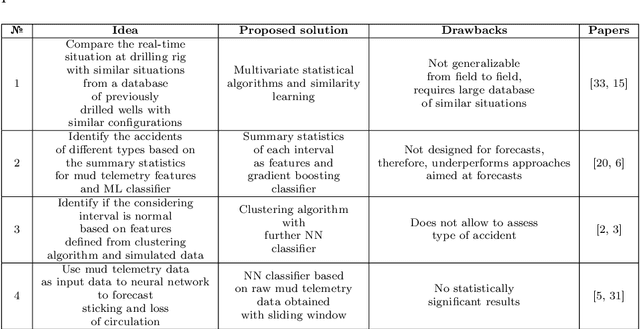
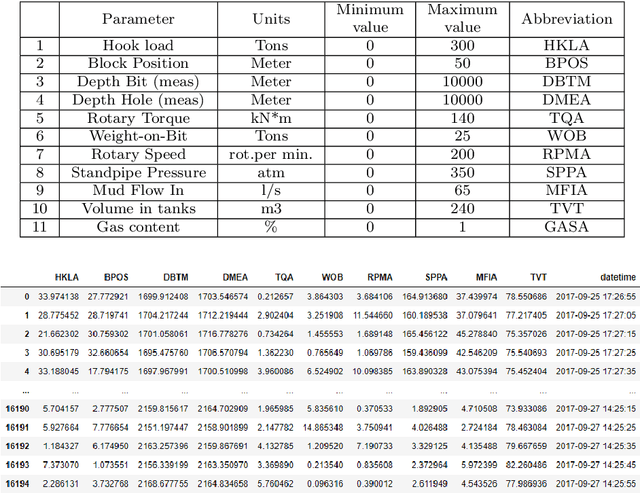
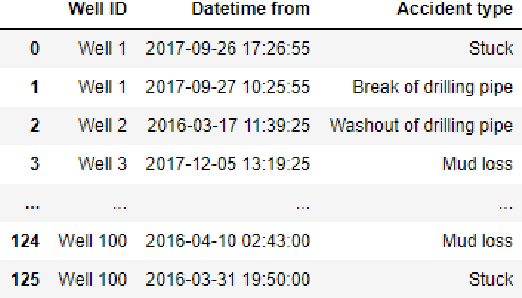
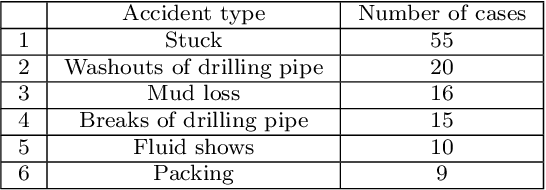
We present a data-driven and physics-informed algorithm for drilling accident forecasting. The core machine-learning algorithm uses the data from the drilling telemetry representing the time-series. We have developed a Bag-of-features representation of the time series that enables the algorithm to predict the probabilities of six types of drilling accidents in real-time. The machine-learning model is trained on the 125 past drilling accidents from 100 different Russian oil and gas wells. Validation shows that the model can forecast 70% of drilling accidents with a false positive rate equals to 40%. The model addresses partial prevention of the drilling accidents at the well construction.
RF Interference in Lens-Based Massive MIMO Systems -- An Application Note
May 05, 2022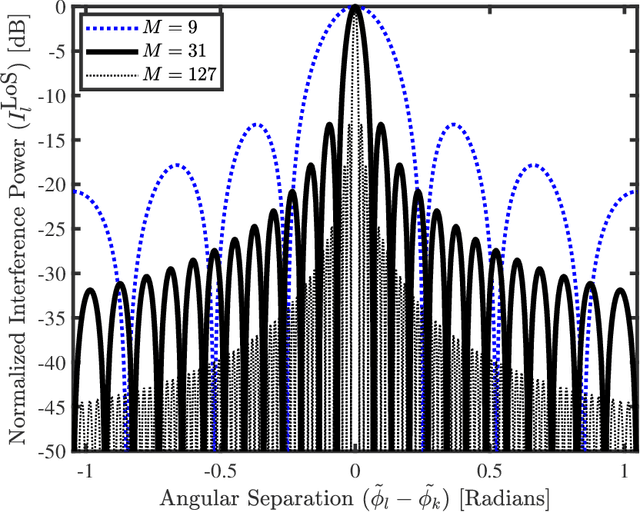
We analyze the uplink radio frequency (RF) interference from a multiplicity of single-antenna user equipments transmitting to a cellular base station (BS) within the same time-frequency resource. The BS is assumed to operate with a lens antenna array, which induces additional focusing gain for the incoming signals. Considering line-of-sight propagation conditions, we characterize the multiuser RF interference properties via approximation of the mainlobe interference as well as the effective interferer probability. The results derived in this application note are foundational to more general multiuser interference analysis across different propagation conditions, which we present in a follow up paper.