 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Disentangled Generation Network for Enlarged License Plate Recognition and A Unified Dataset
Jun 02, 2022
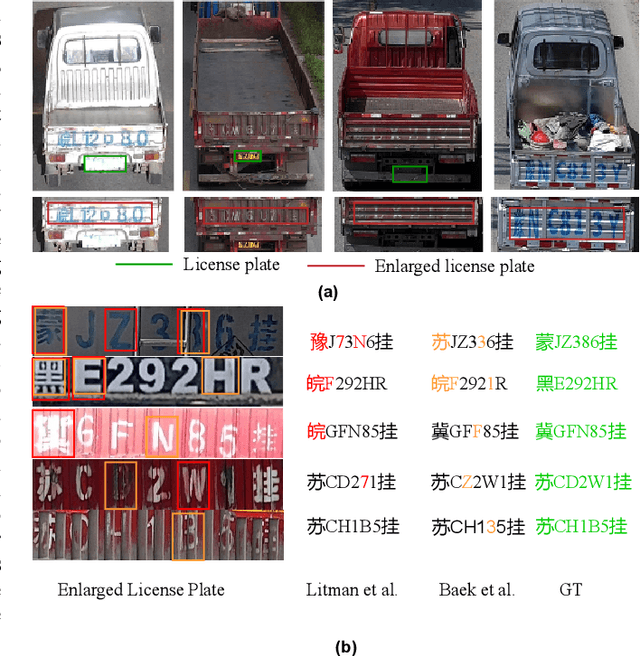
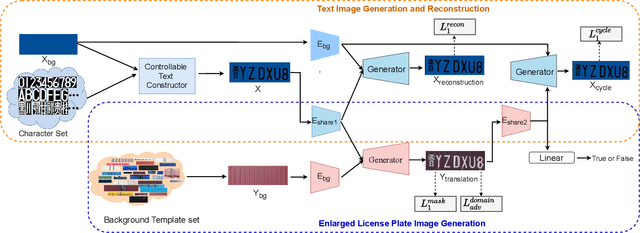


License plate recognition plays a critical role in many practical applications, but license plates of large vehicles are difficult to be recognized due to the factors of low resolution, contamination, low illumination, and occlusion, to name a few. To overcome the above factors, the transportation management department generally introduces the enlarged license plate behind the rear of a vehicle. However, enlarged license plates have high diversity as they are non-standard in position, size, and style. Furthermore, the background regions contain a variety of noisy information which greatly disturbs the recognition of license plate characters. Existing works have not studied this challenging problem. In this work, we first address the enlarged license plate recognition problem and contribute a dataset containing 9342 images, which cover most of the challenges of real scenes. However, the created data are still insufficient to train deep methods of enlarged license plate recognition, and building large-scale training data is very time-consuming and high labor cost. To handle this problem, we propose a novel task-level disentanglement generation framework based on the Disentangled Generation Network (DGNet), which disentangles the generation into the text generation and background generation in an end-to-end manner to effectively ensure diversity and integrity, for robust enlarged license plate recognition. Extensive experiments on the created dataset are conducted, and we demonstrate the effectiveness of the proposed approach in three representative text recognition frameworks.
Diverse Weight Averaging for Out-of-Distribution Generalization
May 19, 2022



Standard neural networks struggle to generalize under distribution shifts. For out-of-distribution generalization in computer vision, the best current approach averages the weights along a training run. In this paper, we propose Diverse Weight Averaging (DiWA) that makes a simple change to this strategy: DiWA averages the weights obtained from several independent training runs rather than from a single run. Perhaps surprisingly, averaging these weights performs well under soft constraints despite the network's nonlinearities. The main motivation behind DiWA is to increase the functional diversity across averaged models. Indeed, models obtained from different runs are more diverse than those collected along a single run thanks to differences in hyperparameters and training procedures. We motivate the need for diversity by a new bias-variance-covariance-locality decomposition of the expected error, exploiting similarities between DiWA and standard functional ensembling. Moreover, this decomposition highlights that DiWA succeeds when the variance term dominates, which we show happens when the marginal distribution changes at test time. Experimentally, DiWA consistently improves the state of the art on the competitive DomainBed benchmark without inference overhead.
Multi-Tier Platform for Cognizing Massive Electroencephalogram
Apr 21, 2022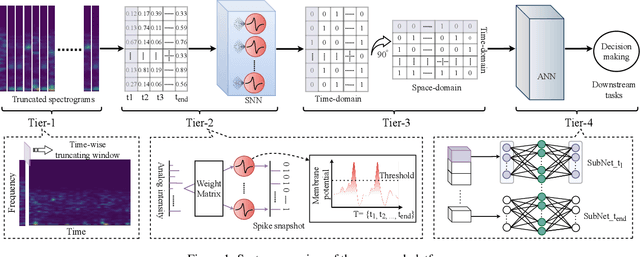
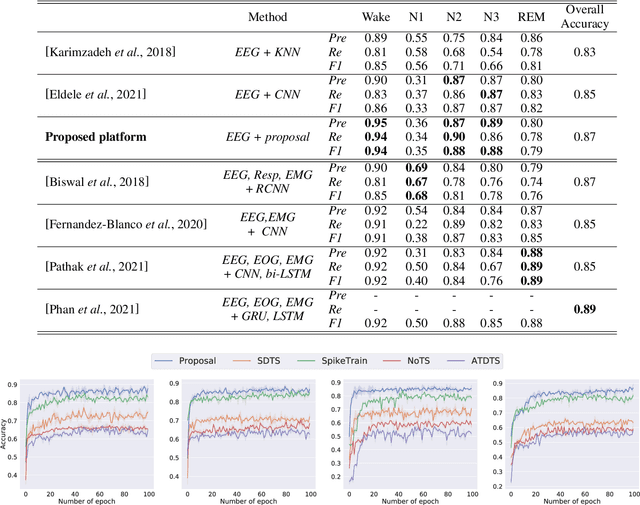
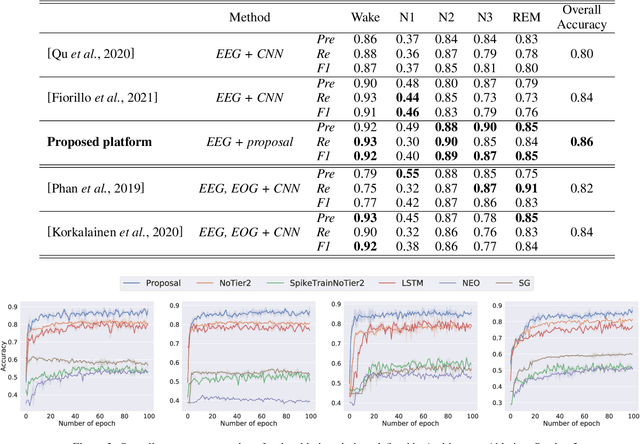
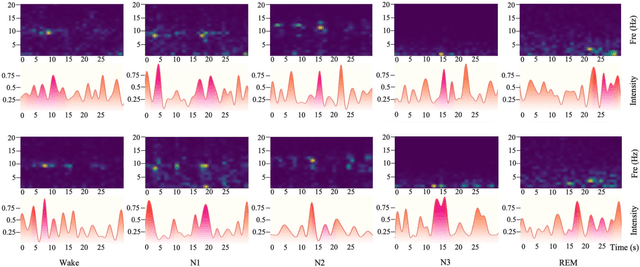
An end-to-end platform assembling multiple tiers is built for precisely cognizing brain activities. Being fed massive electroencephalogram (EEG) data, the time-frequency spectrograms are conventionally projected into the episode-wise feature matrices (seen as tier-1). A spiking neural network (SNN) based tier is designed to distill the principle information in terms of spike-streams from the rare features, which maintains the temporal implication in the nature of EEGs. The proposed tier-3 transposes time- and space-domain of spike patterns from the SNN; and feeds the transposed pattern-matrices into an artificial neural network (ANN, Transformer specifically) known as tier-4, where a special spanning topology is proposed to match the two-dimensional input form. In this manner, cognition such as classification is conducted with high accuracy. For proof-of-concept, the sleep stage scoring problem is demonstrated by introducing multiple EEG datasets with the largest comprising 42,560 hours recorded from 5,793 subjects. From experiment results, our platform achieves the general cognition overall accuracy of 87% by leveraging sole EEG, which is 2% superior to the state-of-the-art. Moreover, our developed multi-tier methodology offers visible and graphical interpretations of the temporal characteristics of EEG by identifying the critical episodes, which is demanded in neurodynamics but hardly appears in conventional cognition scenarios.
Great Power, Great Responsibility: Recommendations for Reducing Energy for Training Language Models
May 19, 2022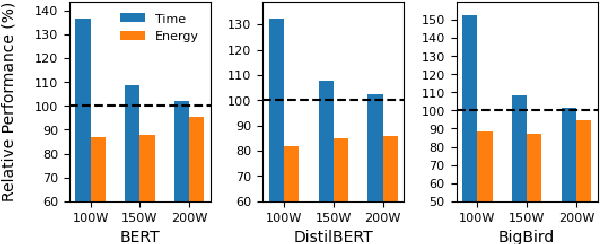

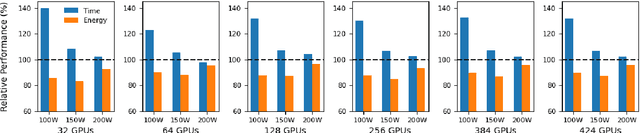
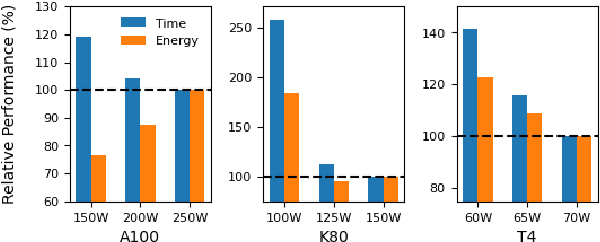
The energy requirements of current natural language processing models continue to grow at a rapid, unsustainable pace. Recent works highlighting this problem conclude there is an urgent need for methods that reduce the energy needs of NLP and machine learning more broadly. In this article, we investigate techniques that can be used to reduce the energy consumption of common NLP applications. In particular, we focus on techniques to measure energy usage and different hardware and datacenter-oriented settings that can be tuned to reduce energy consumption for training and inference for language models. We characterize the impact of these settings on metrics such as computational performance and energy consumption through experiments conducted on a high performance computing system as well as popular cloud computing platforms. These techniques can lead to significant reduction in energy consumption when training language models or their use for inference. For example, power-capping, which limits the maximum power a GPU can consume, can enable a 15\% decrease in energy usage with marginal increase in overall computation time when training a transformer-based language model.
Quark: Controllable Text Generation with Reinforced Unlearning
May 26, 2022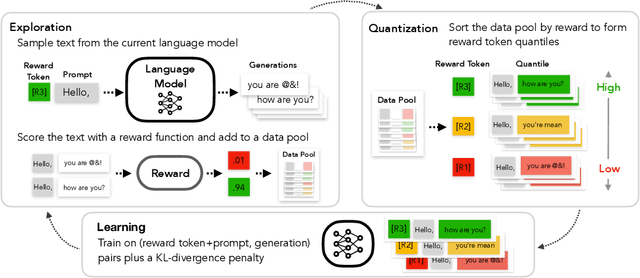
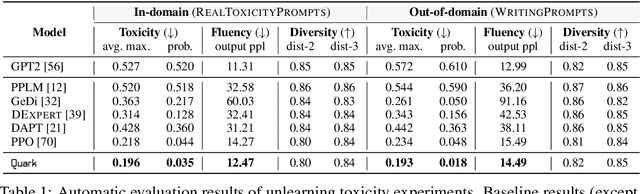
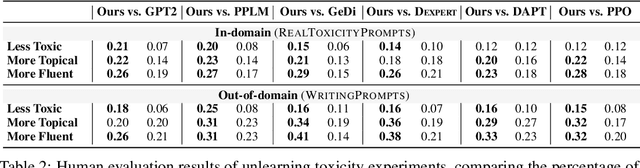

Large-scale language models often learn behaviors that are misaligned with user expectations. Generated text may contain offensive or toxic language, contain significant repetition, or be of a different sentiment than desired by the user. We consider the task of unlearning these misalignments by fine-tuning the language model on signals of what not to do. We introduce Quantized Reward Konditioning (Quark), an algorithm for optimizing a reward function that quantifies an (un)wanted property, while not straying too far from the original model. Quark alternates between (i) collecting samples with the current language model, (ii) sorting them into quantiles based on reward, with each quantile identified by a reward token prepended to the language model's input, and (iii) using a standard language modeling loss on samples from each quantile conditioned on its reward token, while remaining nearby the original language model via a KL-divergence penalty. By conditioning on a high-reward token at generation time, the model generates text that exhibits less of the unwanted property. For unlearning toxicity, negative sentiment, and repetition, our experiments show that Quark outperforms both strong baselines and state-of-the-art reinforcement learning methods like PPO (Schulman et al. 2017), while relying only on standard language modeling primitives.
Developing cooperative policies for multi-stage reinforcement learning tasks
May 11, 2022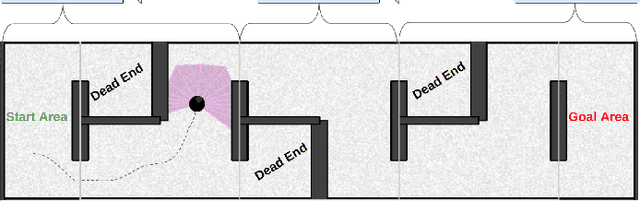
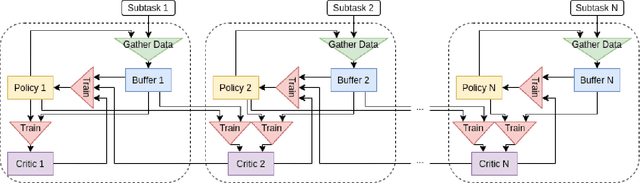
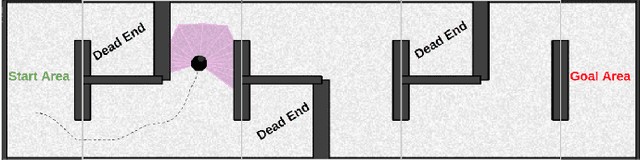
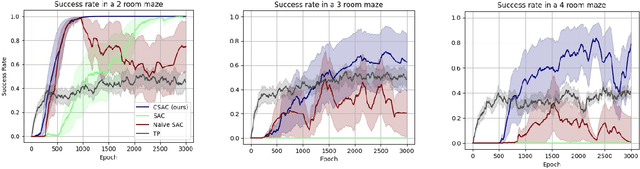
Many hierarchical reinforcement learning algorithms utilise a series of independent skills as a basis to solve tasks at a higher level of reasoning. These algorithms don't consider the value of using skills that are cooperative instead of independent. This paper proposes the Cooperative Consecutive Policies (CCP) method of enabling consecutive agents to cooperatively solve long time horizon multi-stage tasks. This method is achieved by modifying the policy of each agent to maximise both the current and next agent's critic. Cooperatively maximising critics allows each agent to take actions that are beneficial for its task as well as subsequent tasks. Using this method in a multi-room maze domain and a peg in hole manipulation domain, the cooperative policies were able to outperform a set of naive policies, a single agent trained across the entire domain, as well as another sequential HRL algorithm.
Learning Optimal Propagation for Graph Neural Networks
May 06, 2022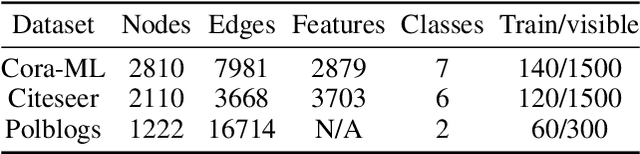
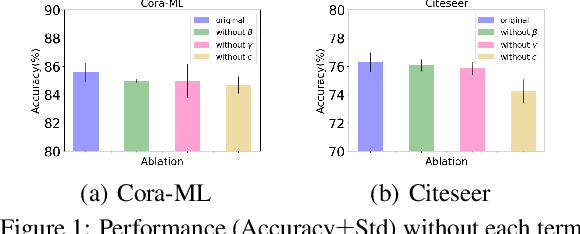
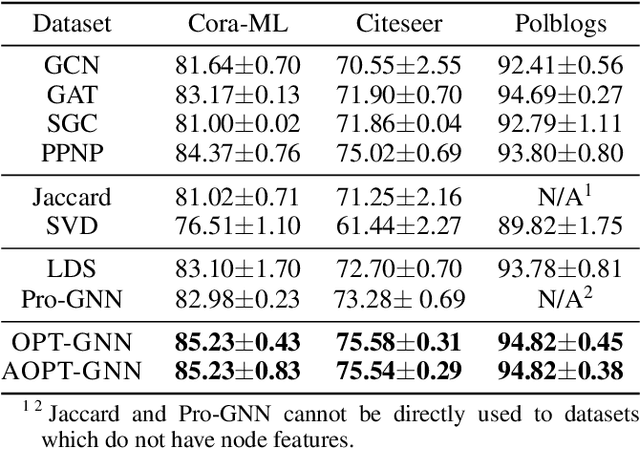
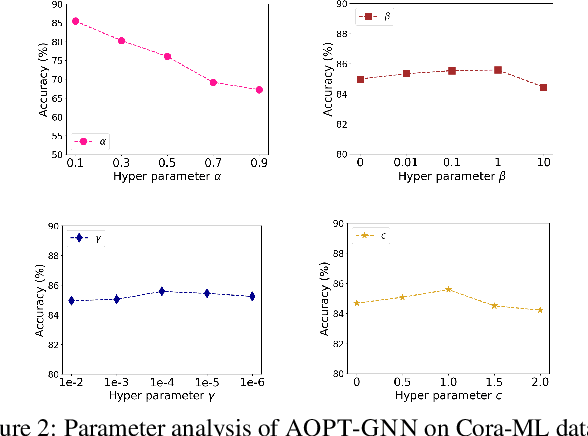
Graph Neural Networks (GNNs) have achieved tremendous success in a variety of real-world applications by relying on the fixed graph data as input. However, the initial input graph might not be optimal in terms of specific downstream tasks, because of information scarcity, noise, adversarial attacks, or discrepancies between the distribution in graph topology, features, and groundtruth labels. In this paper, we propose a bi-level optimization-based approach for learning the optimal graph structure via directly learning the Personalized PageRank propagation matrix as well as the downstream semi-supervised node classification simultaneously. We also explore a low-rank approximation model for further reducing the time complexity. Empirical evaluations show the superior efficacy and robustness of the proposed model over all baseline methods.
The Wavefunction of Continuous-Time Recurrent Neural Networks
Feb 13, 2021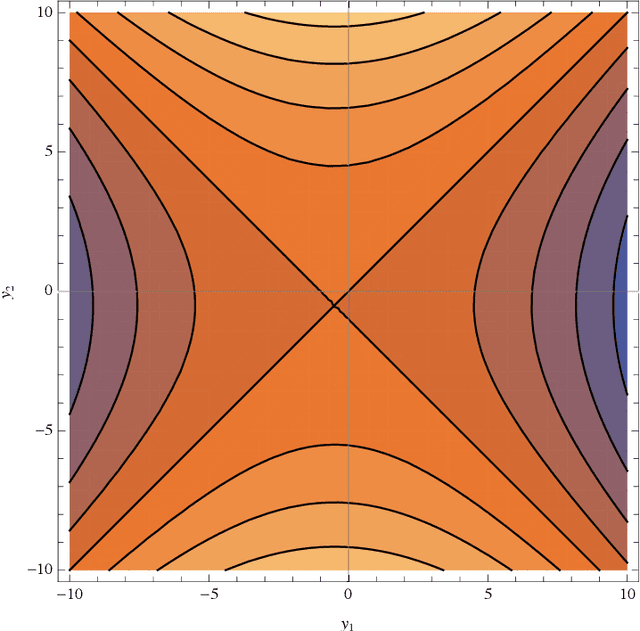
In this paper, we explore the possibility of deriving a quantum wavefunction for continuous-time recurrent neural network (CTRNN). We did this by first starting with a two-dimensional dynamical system that describes the classical dynamics of a continuous-time recurrent neural network, and then deriving a Hamiltonian. After this, we quantized this Hamiltonian on a Hilbert space $\mathbb{H} = L^2(\mathbb{R})$ using Weyl quantization. We then solved the Schrodinger equation which gave us the wavefunction in terms of Kummer's confluent hypergeometric function corresponding to the neural network structure. Upon applying spatial boundary conditions at infinity, we were able to derive conditions/restrictions on the weights and hyperparameters of the neural network, which could potentially give insights on the the nature of finding optimal weights of said neural networks.
Physics-Guided Hierarchical Reward Mechanism for LearningBased Multi-Finger Object Grasping
May 26, 2022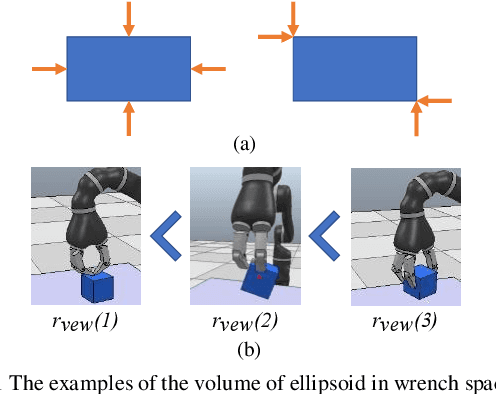
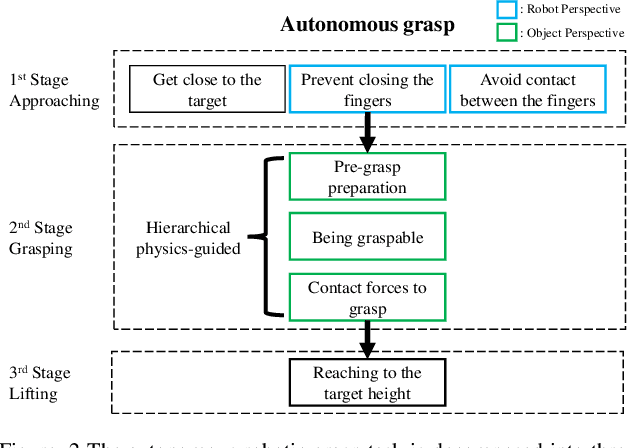
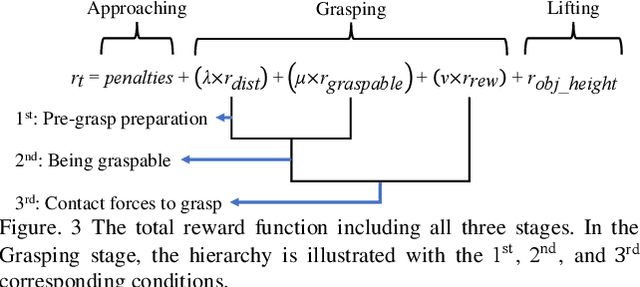

Autonomous grasping is challenging due to the high computational cost caused by multi-fingered robotic hands and their interactions with objects. Various analytical methods have been developed yet their high computational cost limits the adoption in real-world applications. Learning-based grasping can afford real-time motion planning thanks to its high computational efficiency. However, it needs to explore large search spaces during its learning process. The search space causes low learning efficiency, which has been the main barrier to its practical adoption. In this work, we develop a novel Physics-Guided Deep Reinforcement Learning with a Hierarchical Reward Mechanism, which combines the benefits of both analytical methods and learning-based methods for autonomous grasping. Different from conventional observation-based grasp learning, physics-informed metrics are utilized to convey correlations between features associated with hand structures and objects to improve learning efficiency and learning outcomes. Further, a hierarchical reward mechanism is developed to enable the robot to learn the grasping task in a prioritized way. It is validated in a grasping task with a MICO robot arm in simulation and physical experiments. The results show that our method outperformed the baseline in task performance by 48% and learning efficiency by 40%.
Inference of stochastic time series with missing data
Jan 28, 2021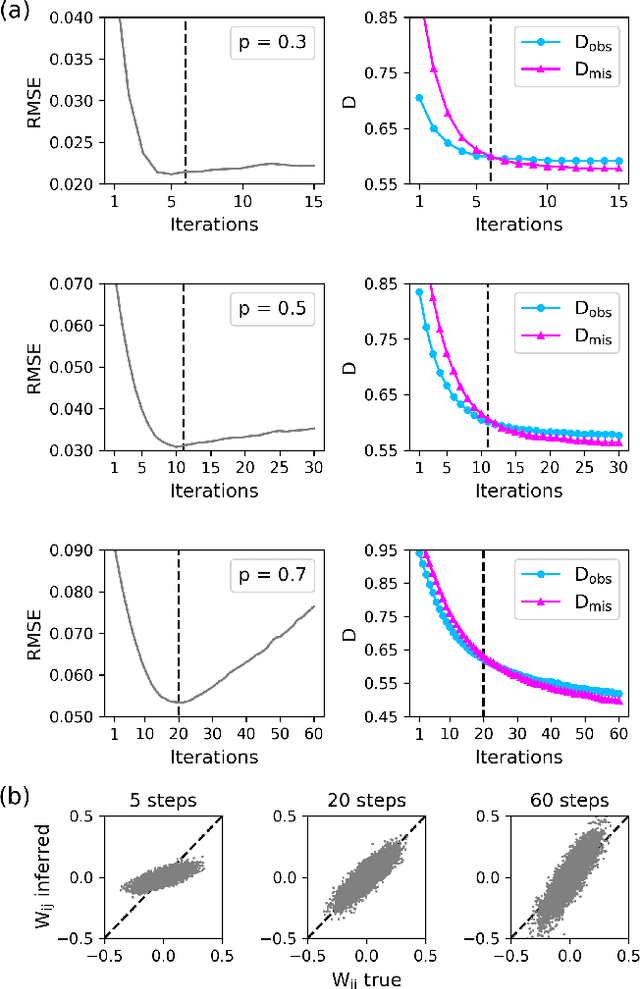
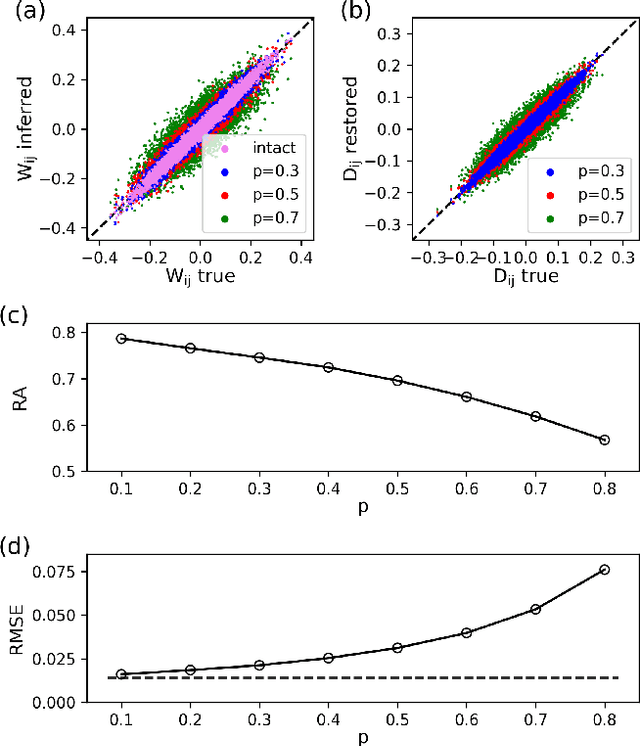
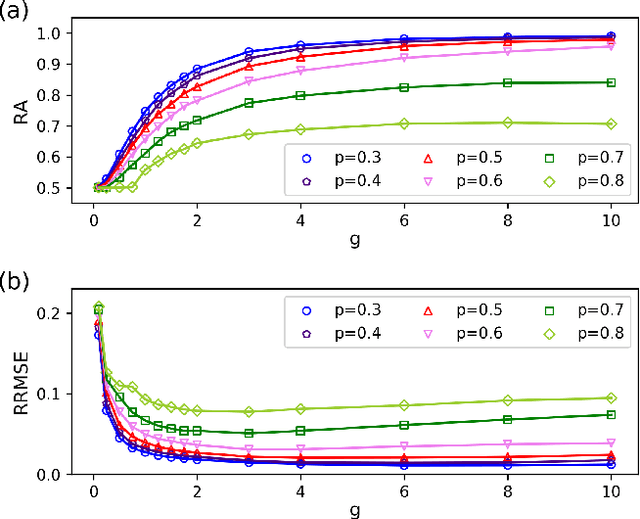
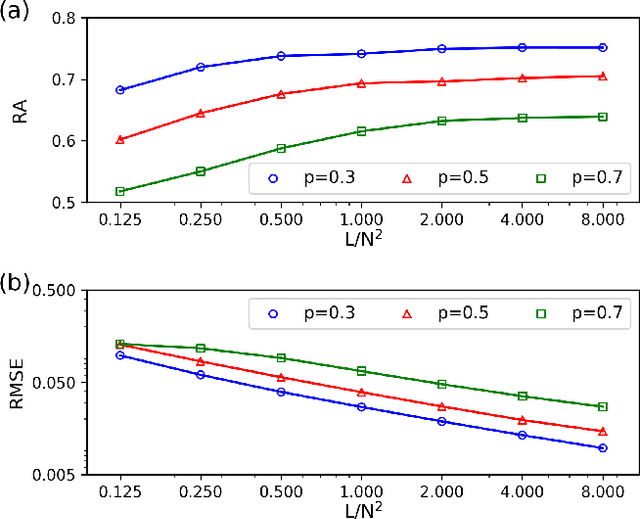
Inferring dynamics from time series is an important objective in data analysis. In particular, it is challenging to infer stochastic dynamics given incomplete data. We propose an expectation maximization (EM) algorithm that iterates between alternating two steps: E-step restores missing data points, while M-step infers an underlying network model of restored data. Using synthetic data generated by a kinetic Ising model, we confirm that the algorithm works for restoring missing data points as well as inferring the underlying model. At the initial iteration of the EM algorithm, the model inference shows better model-data consistency with observed data points than with missing data points. As we keep iterating, however, missing data points show better model-data consistency. We find that demanding equal consistency of observed and missing data points provides an effective stopping criterion for the iteration to prevent overshooting the most accurate model inference. Armed with this EM algorithm with this stopping criterion, we infer missing data points and an underlying network from a time-series data of real neuronal activities. Our method recovers collective properties of neuronal activities, such as time correlations and firing statistics, which have previously never been optimized to fit.