 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Video Prediction at Multiple Scales with Hierarchical Recurrent Networks
Mar 17, 2022
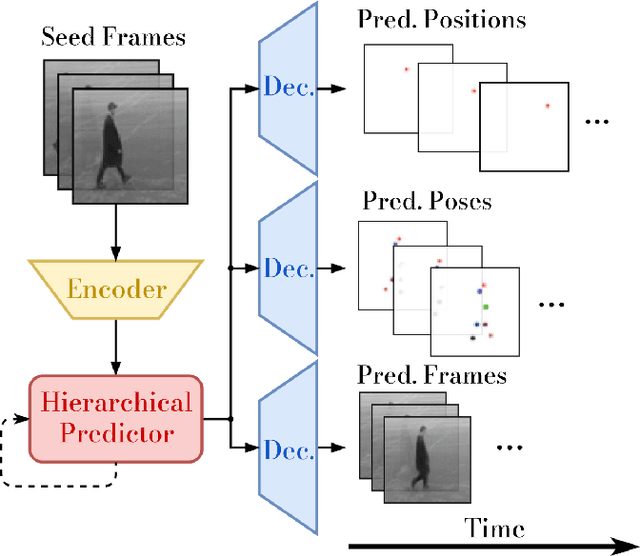
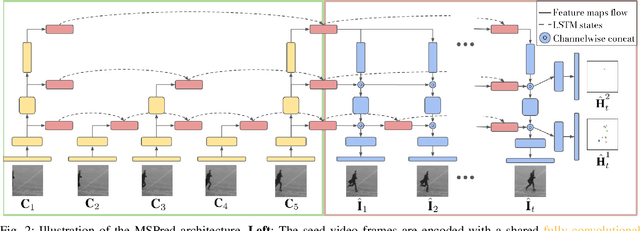


Autonomous systems not only need to understand their current environment, but should also be able to predict future actions conditioned on past states, for instance based on captured camera frames. For certain tasks, detailed predictions such as future video frames are required in the near future, whereas for others it is beneficial to also predict more abstract representations for longer time horizons. However, existing video prediction models mainly focus on forecasting detailed possible outcomes for short time-horizons, hence being of limited use for robot perception and spatial reasoning. We propose Multi-Scale Hierarchical Prediction (MSPred), a novel video prediction model able to forecast future possible outcomes of different levels of granularity at different time-scales simultaneously. By combining spatial and temporal downsampling, MSPred is able to efficiently predict abstract representations such as human poses or object locations over long time horizons, while still maintaining a competitive performance for video frame prediction. In our experiments, we demonstrate that our proposed model accurately predicts future video frames as well as other representations (e.g. keypoints or positions) on various scenarios, including bin-picking scenes or action recognition datasets, consistently outperforming popular approaches for video frame prediction. Furthermore, we conduct an ablation study to investigate the importance of the different modules and design choices in MSPred. In the spirit of reproducible research, we open-source VP-Suite, a general framework for deep-learning-based video prediction, as well as pretrained models to reproduce our results.
AmbiPun: Generating Humorous Puns with Ambiguous Context
May 04, 2022
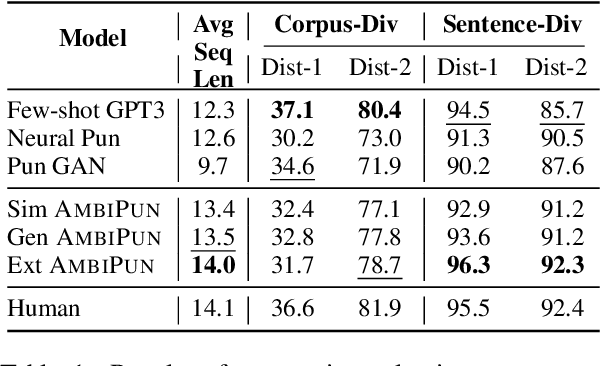

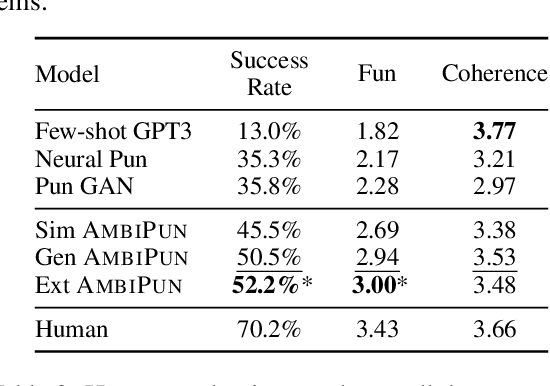
In this paper, we propose a simple yet effective way to generate pun sentences that does not require any training on existing puns. Our approach is inspired by humor theories that ambiguity comes from the context rather than the pun word itself. Given a pair of definitions of a pun word, our model first produces a list of related concepts through a reverse dictionary. We then utilize one-shot GPT3 to generate context words and then generate puns incorporating context words from both concepts. Human evaluation shows that our method successfully generates pun 52\% of the time, outperforming well-crafted baselines and the state-of-the-art models by a large margin.
A Novel Dual Dense Connection Network for Video Super-resolution
Mar 05, 2022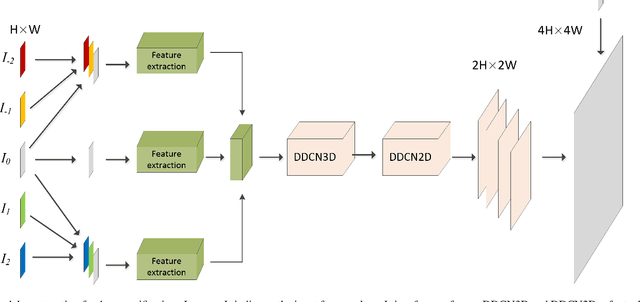
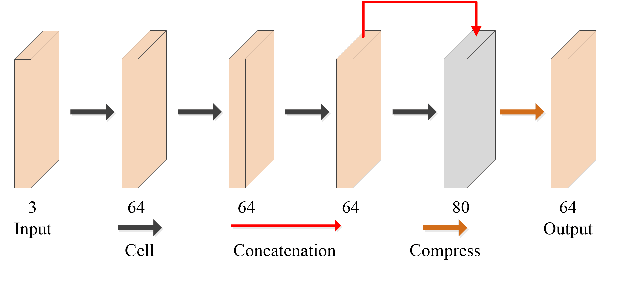
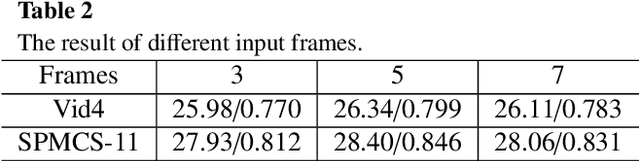
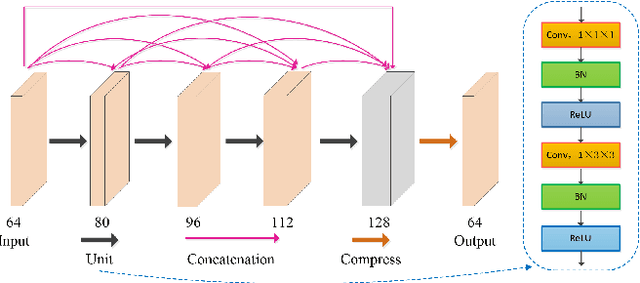
Video super-resolution (VSR) refers to the reconstruction of high-resolution (HR) video from the corresponding low-resolution (LR) video. Recently, VSR has received increasing attention. In this paper, we propose a novel dual dense connection network that can generate high-quality super-resolution (SR) results. The input frames are creatively divided into reference frame, pre-temporal group and post-temporal group, representing information in different time periods. This grouping method provides accurate information of different time periods without causing time information disorder. Meanwhile, we produce a new loss function, which is beneficial to enhance the convergence ability of the model. Experiments show that our model is superior to other advanced models in Vid4 datasets and SPMCS-11 datasets.
Multivariate Probabilistic Forecasting of Intraday Electricity Prices using Normalizing Flows
May 27, 2022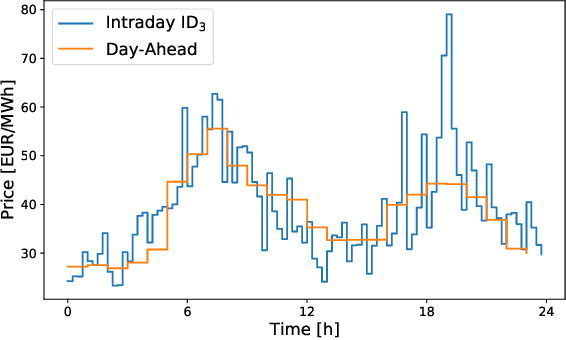
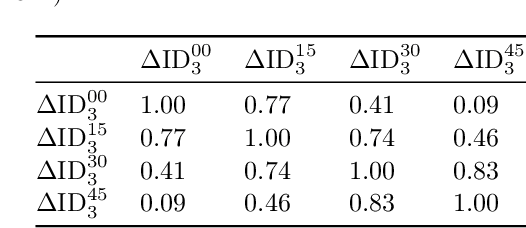
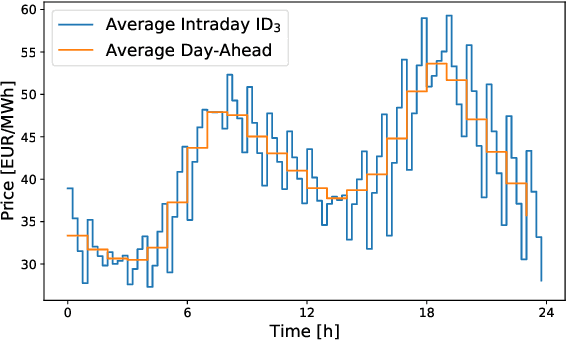
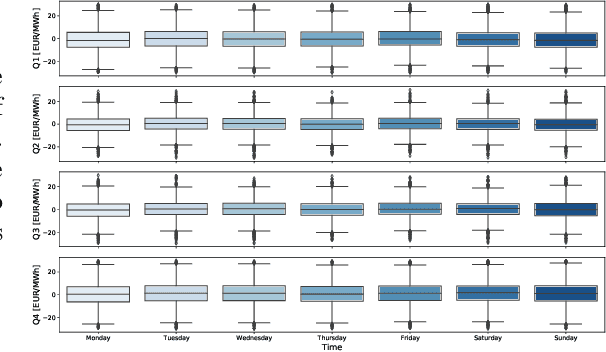
Electricity is traded on various markets with different time horizons and regulations. Short-term trading becomes increasingly important due to higher penetration of renewables. In Germany, the intraday electricity price typically fluctuates around the day-ahead price of the EPEX spot markets in a distinct hourly pattern. This work proposes a probabilistic modeling approach that models the intraday price difference to the day-ahead contracts. The model captures the emerging hourly pattern by considering the four 15 min intervals in each day-ahead price interval as a four-dimensional joint distribution. The resulting nontrivial, multivariate price difference distribution is learned using a normalizing flow, i.e., a deep generative model that combines conditional multivariate density estimation and probabilistic regression. The normalizing flow is compared to a selection of historical data, a Gaussian copula, and a Gaussian regression model. Among the different models, the normalizing flow identifies the trends most accurately and has the narrowest prediction intervals. Notably, the normalizing flow is the only approach that identifies rare price peaks. Finally, this work discusses the influence of different external impact factors and finds that, individually, most of these factors have negligible impact. Only the immediate history of the price difference realization and the combination of all input factors lead to notable improvements in the forecasts.
The Wavefunction of Continuous-Time Recurrent Neural Networks
Feb 13, 2021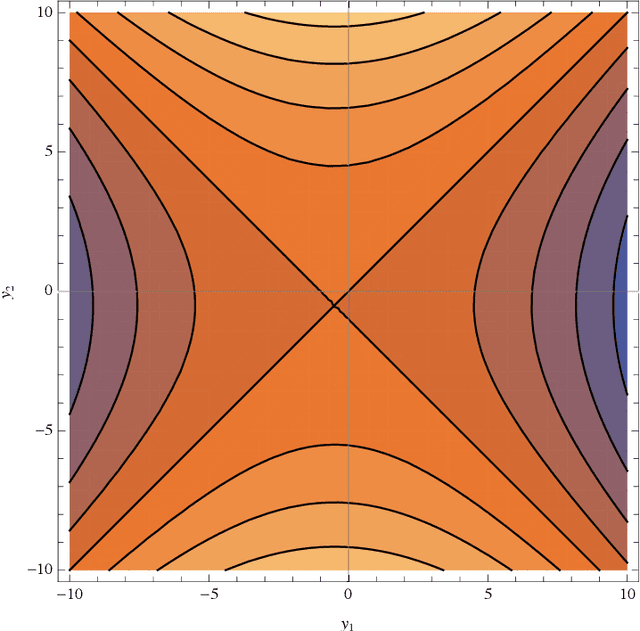
In this paper, we explore the possibility of deriving a quantum wavefunction for continuous-time recurrent neural network (CTRNN). We did this by first starting with a two-dimensional dynamical system that describes the classical dynamics of a continuous-time recurrent neural network, and then deriving a Hamiltonian. After this, we quantized this Hamiltonian on a Hilbert space $\mathbb{H} = L^2(\mathbb{R})$ using Weyl quantization. We then solved the Schrodinger equation which gave us the wavefunction in terms of Kummer's confluent hypergeometric function corresponding to the neural network structure. Upon applying spatial boundary conditions at infinity, we were able to derive conditions/restrictions on the weights and hyperparameters of the neural network, which could potentially give insights on the the nature of finding optimal weights of said neural networks.
Text-Based Automatic Personality Prediction Using KGrAt-Net; A Knowledge Graph Attention Network Classifier
May 27, 2022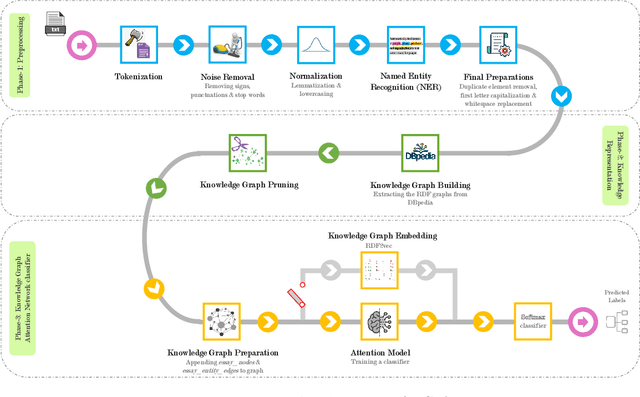

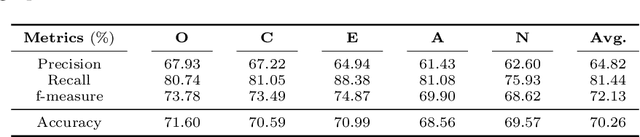
Nowadays, a tremendous amount of human communications take place on the Internet-based communication infrastructures, like social networks, email, forums, organizational communication platforms, etc. Indeed, the automatic prediction or assessment of individuals' personalities through their written or exchanged text would be advantageous to ameliorate the relationships among them. To this end, this paper aims to propose KGrAt-Net which is a Knowledge Graph Attention Network text classifier. For the first time, it applies the knowledge graph attention network to perform Automatic Personality Prediction (APP), according to the Big Five personality traits. After performing some preprocessing activities, first, it tries to acquire a knowingful representation of the knowledge behind the concepts in the input text through building its equivalent knowledge graph. A knowledge graph is a graph-based data model that formally represents the semantics of the existing concepts in the input text and models the knowledge behind them. Then, applying the attention mechanism, it efforts to pay attention to the most relevant parts of the graph to predict the personality traits of the input text. The results demonstrated that KGrAt-Net considerably improved the personality prediction accuracies. Furthermore, KGrAt-Net also uses the knowledge graphs' embeddings to enrich the classification, which makes it even more accurate in APP.
Inference of stochastic time series with missing data
Jan 28, 2021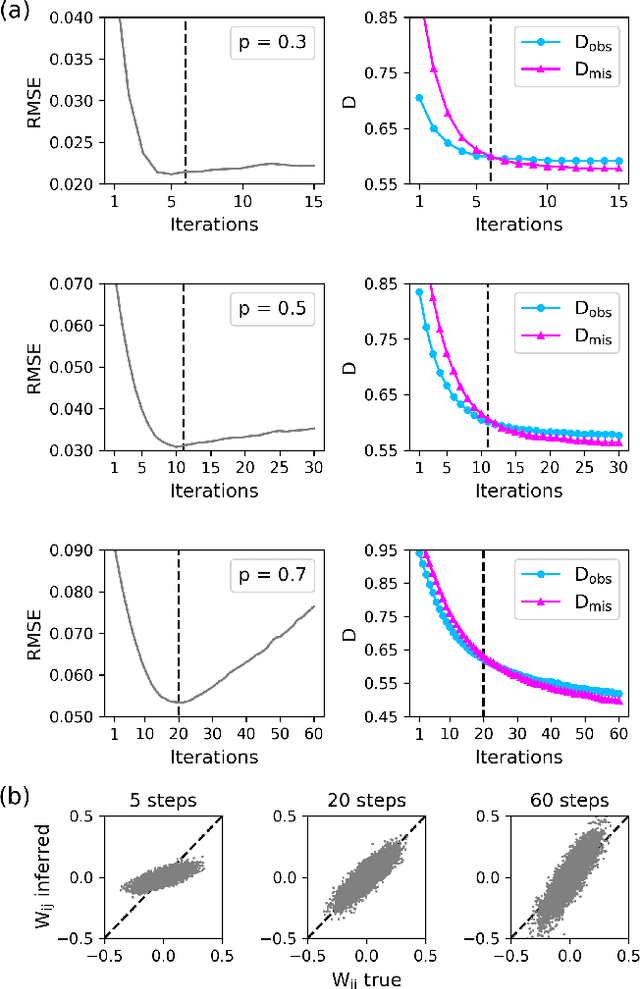
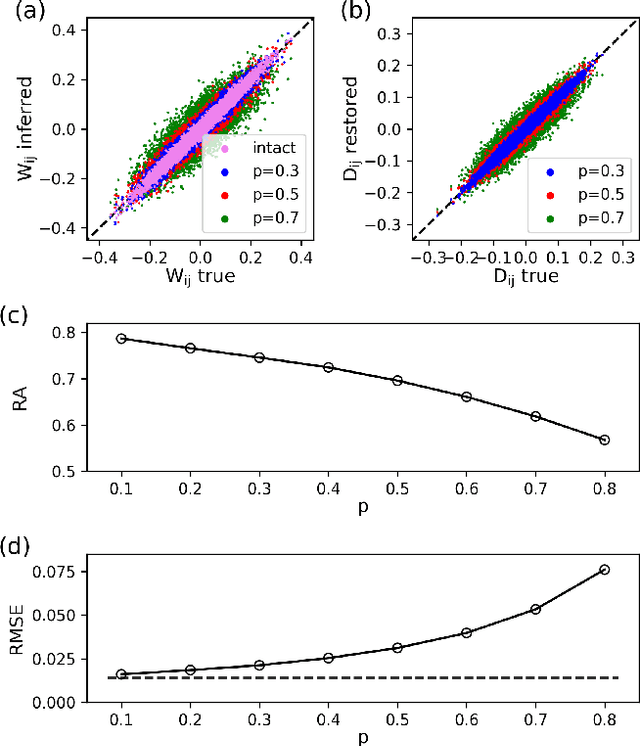
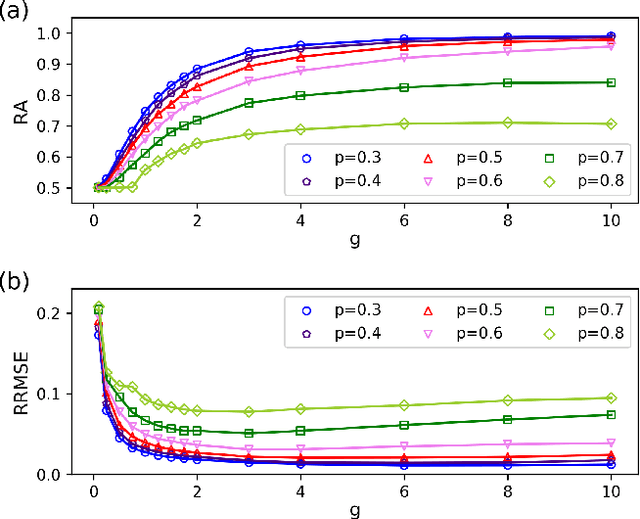
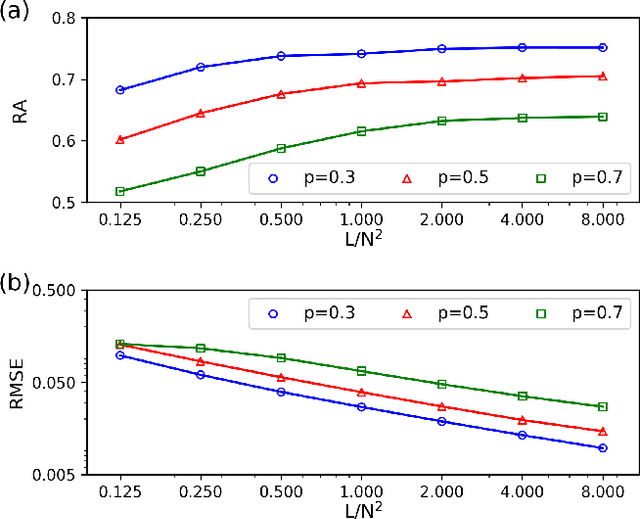
Inferring dynamics from time series is an important objective in data analysis. In particular, it is challenging to infer stochastic dynamics given incomplete data. We propose an expectation maximization (EM) algorithm that iterates between alternating two steps: E-step restores missing data points, while M-step infers an underlying network model of restored data. Using synthetic data generated by a kinetic Ising model, we confirm that the algorithm works for restoring missing data points as well as inferring the underlying model. At the initial iteration of the EM algorithm, the model inference shows better model-data consistency with observed data points than with missing data points. As we keep iterating, however, missing data points show better model-data consistency. We find that demanding equal consistency of observed and missing data points provides an effective stopping criterion for the iteration to prevent overshooting the most accurate model inference. Armed with this EM algorithm with this stopping criterion, we infer missing data points and an underlying network from a time-series data of real neuronal activities. Our method recovers collective properties of neuronal activities, such as time correlations and firing statistics, which have previously never been optimized to fit.
Spirit Distillation: Precise Real-time Prediction with Insufficient Data
Mar 25, 2021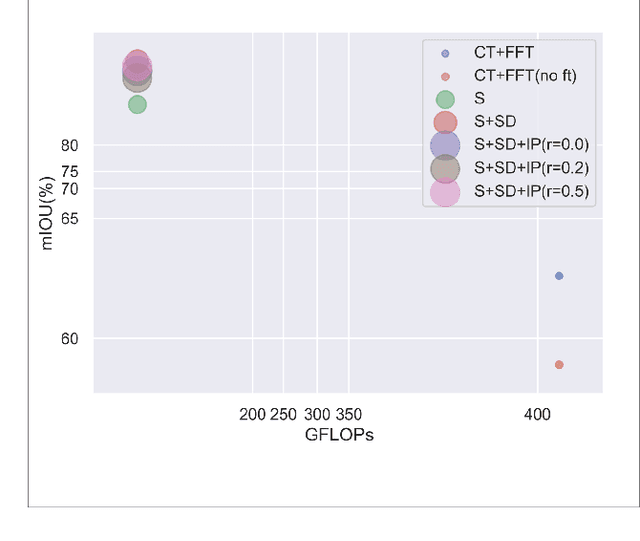
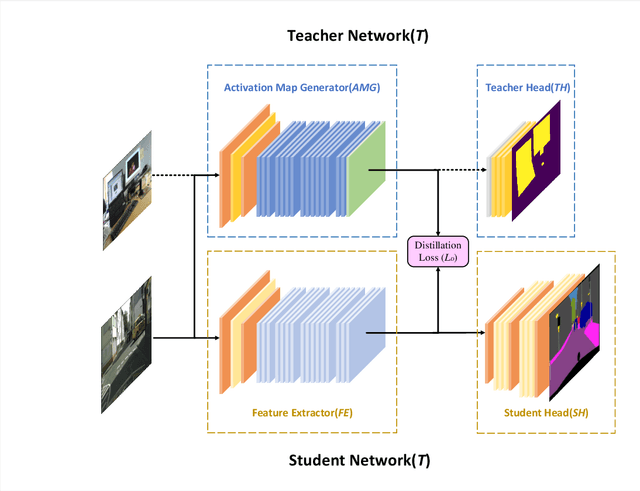
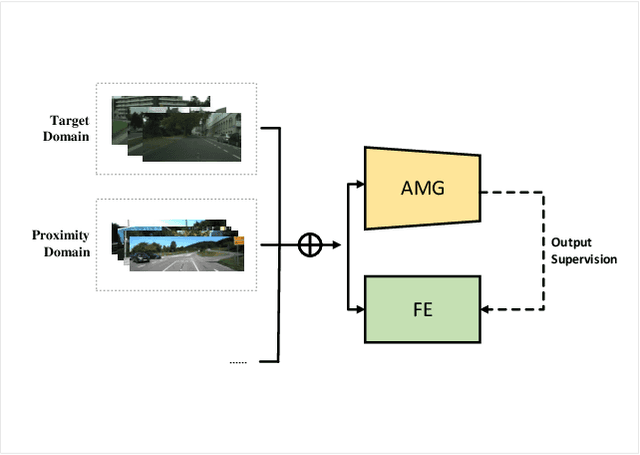
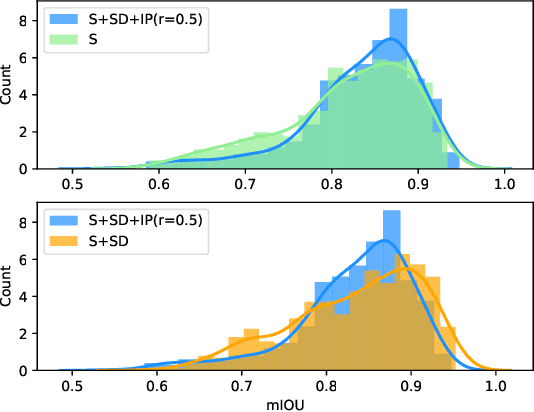
Recent trend demonstrates the effectiveness of deep neural networks (DNNs) apply on the task of environment perception in autonomous driving system. While large-scale and complete data can train out fine DNNs, collecting it is always difficult, expensive, and time-consuming. Also, the significance of both accuracy and efficiency cannot be over-emphasized due to the requirement of real-time recognition. To alleviate the conflicts between weak data and high computational consumption of DNNs, we propose a new training framework named Spirit Distillation(SD). It extends the ideas of fine-tuning-based transfer learning(FTT) and feature-based knowledge distillation. By allowing the student to mimic its teacher in feature extraction, the gap of general features between the teacher-student networks is bridged. The Image Party distillation enhancement method(IP) is also proposed, which shuffling images from various domains, and randomly selecting a few as mini-batch. With this approach, the overfitting that the student network to the general features of the teacher network can be easily avoided. Persuasive experiments and discussions are conducted on CityScapes with the prompt of COCO2017 and KITTI. Results demonstrate the boosting performance in segmentation(mIOU and high-precision accuracy boost by 1.4% and 8.2% respectively, with 78.2% output variance), and can gain a precise compact network with only 41.8\% FLOPs(see Fig. 1). This paper is a pioneering work on knowledge distillation applied to few-shot learning. The proposed methods significantly reduce the dependence on data of DNNs training, and improves the robustness of DNNs when facing rare situations, with real-time requirement satisfied. We provide important technical support for the advancement of scene perception technology for autonomous driving.
Improved Evaluation and Generation of Grid Layouts using Distance Preservation Quality and Linear Assignment Sorting
May 11, 2022



Images sorted by similarity enables more images to be viewed simultaneously, and can be very useful for stock photo agencies or e-commerce applications. Visually sorted grid layouts attempt to arrange images so that their proximity on the grid corresponds as closely as possible to their similarity. Various metrics exist for evaluating such arrangements, but there is low experimental evidence on correlation between human perceived quality and metric value. We propose Distance Preservation Quality (DPQ) as a new metric to evaluate the quality of an arrangement. Extensive user testing revealed stronger correlation of DPQ with user-perceived quality and performance in image retrieval tasks compared to other metrics. In addition, we introduce Fast Linear Assignment Sorting (FLAS) as a new algorithm for creating visually sorted grid layouts. FLAS achieves very good sorting qualities while improving run time and computational resources.
Enhanced Prototypical Learning for Unsupervised Domain Adaptation in LiDAR Semantic Segmentation
May 23, 2022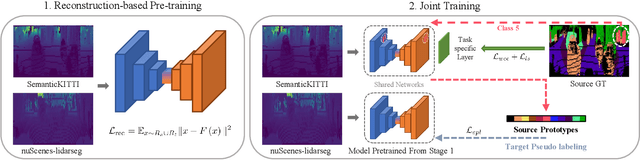

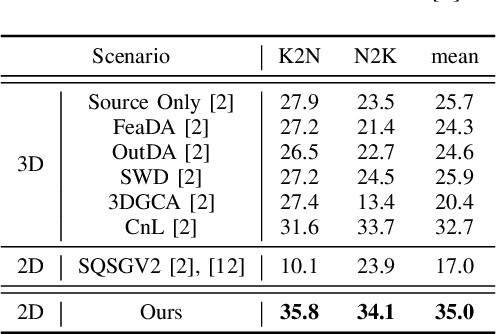
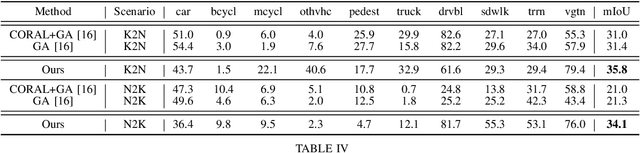
Despite its importance, unsupervised domain adaptation (UDA) on LiDAR semantic segmentation is a task that has not received much attention from the research community. Only recently, a completion-based 3D method has been proposed to tackle the problem and formally set up the adaptive scenarios. However, the proposed pipeline is complex, voxel-based and requires multi-stage inference, which inhibits it for real-time inference. We propose a range image-based, effective and efficient method for solving UDA on LiDAR segmentation. The method exploits class prototypes from the source domain to pseudo label target domain pixels, which is a research direction showing good performance in UDA for natural image semantic segmentation. Applying such approaches to LiDAR scans has not been considered because of the severe domain shift and lack of pre-trained feature extractor that is unavailable in the LiDAR segmentation setup. However, we show that proper strategies, including reconstruction-based pre-training, enhanced prototypes, and selective pseudo labeling based on distance to prototypes, is sufficient enough to enable the use of prototypical approaches. We evaluate the performance of our method on the recently proposed LiDAR segmentation UDA scenarios. Our method achieves remarkable performance among contemporary methods.