 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generating Natural Language Proofs with Verifier-Guided Search
May 25, 2022
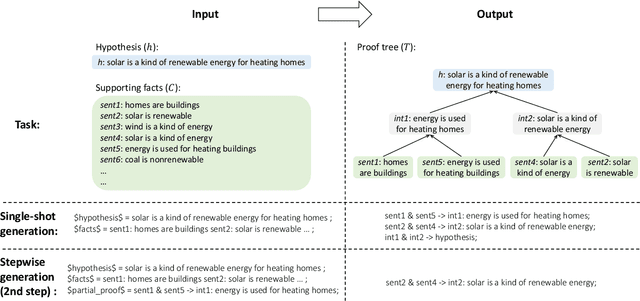


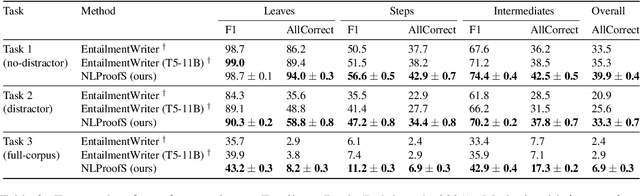
Deductive reasoning (drawing conclusions from assumptions) is a challenging problem in NLP. In this work, we focus on proof generation: given a hypothesis and a set of supporting facts in natural language, the model generates a proof tree indicating how to deduce the hypothesis from supporting facts. Instead of generating the entire proof in one shot, prior work has demonstrated the promise of stepwise generation but achieved limited success on real-world data. Existing stepwise methods struggle to generate proof steps that are both valid and relevant. In this paper, we present a novel stepwise method NLProofS (Natural Language Proof Search), which learns to generate relevant steps conditioning on the hypothesis. At the core of our approach, we train an independent verifier to check the validity of proof steps. Instead of generating steps greedily, we search for proofs maximizing a global proof score judged by the verifier. NLProofS achieves state-of-the-art performance on EntailmentBank and RuleTaker. For example, it improves the percentage of correctly predicted proofs from 20.9% to 33.3% in the distractor setting of EntailmentBank. This is the first time stepwise methods have led to better generation of challenging human-authored proofs.
NetCut: Real-Time DNN Inference Using Layer Removal
Jan 13, 2021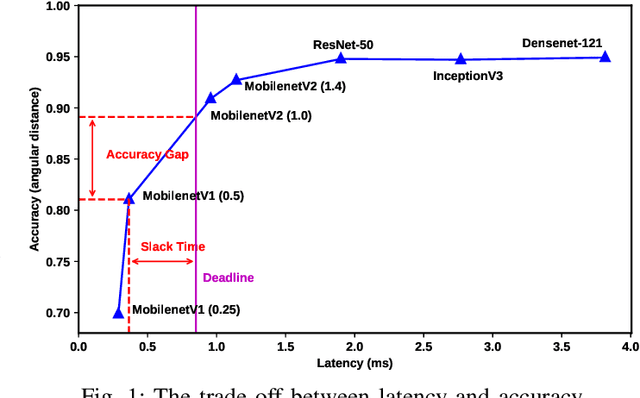
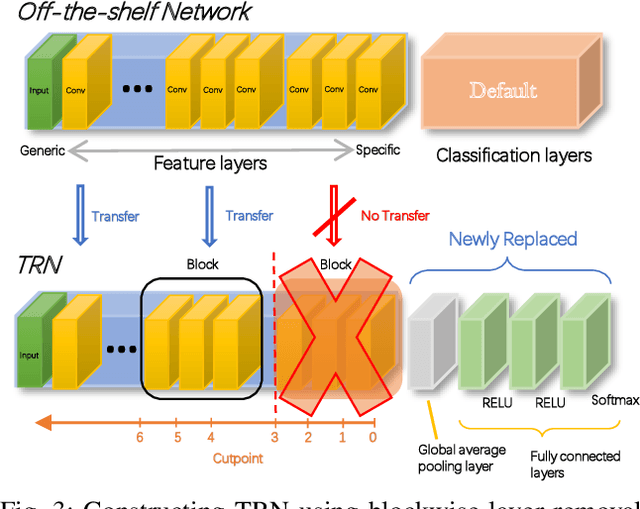
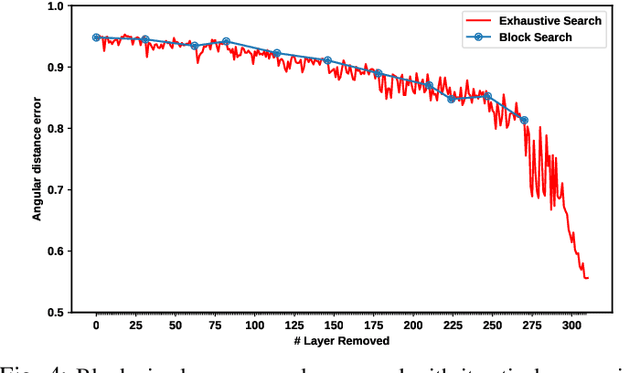
Deep Learning plays a significant role in assisting humans in many aspects of their lives. As these networks tend to get deeper over time, they extract more features to increase accuracy at the cost of additional inference latency. This accuracy-performance trade-off makes it more challenging for Embedded Systems, as resource-constrained processors with strict deadlines, to deploy them efficiently. This can lead to selection of networks that can prematurely meet a specified deadline with excess slack time that could have potentially contributed to increased accuracy. In this work, we propose: (i) the concept of layer removal as a means of constructing TRimmed Networks (TRNs) that are based on removing problem-specific features of a pretrained network used in transfer learning, and (ii) NetCut, a methodology based on an empirical or an analytical latency estimator, which only proposes and retrains TRNs that can meet the application's deadline, hence reducing the exploration time significantly. We demonstrate that TRNs can expand the Pareto frontier that trades off latency and accuracy to provide networks that can meet arbitrary deadlines with potential accuracy improvement over off-the-shelf networks. Our experimental results show that such utilization of TRNs, while transferring to a simpler dataset, in combination with NetCut, can lead to the proposal of networks that can achieve relative accuracy improvement of up to 10.43% among existing off-the-shelf neural architectures while meeting a specific deadline, and 27x speedup in exploration time.
Social learning via actions in bandit environments
May 12, 2022
I study a game of strategic exploration with private payoffs and public actions in a Bayesian bandit setting. In particular, I look at cascade equilibria, in which agents switch over time from the risky action to the riskless action only when they become sufficiently pessimistic. I show that these equilibria exist under some conditions and establish their salient properties. Individual exploration in these equilibria can be more or less than the single-agent level depending on whether the agents start out with a common prior or not, but the most optimistic agent always underexplores. I also show that allowing the agents to write enforceable ex-ante contracts will lead to the most ex-ante optimistic agent to buy all payoff streams, providing an explanation to the buying out of smaller start-ups by more established firms.
Enhancement of Healthcare Data Transmission using the Levenberg-Marquardt Algorithm
Jun 09, 2022
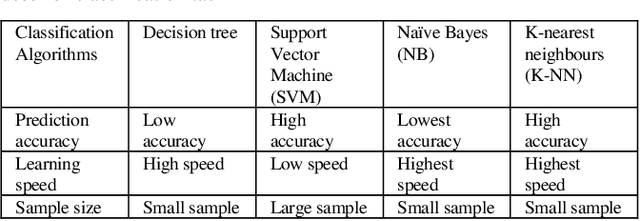
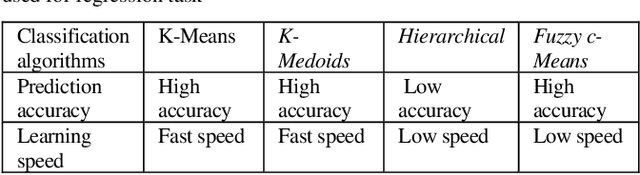
In the healthcare system, patients are required to use wearable devices for the remote data collection and real-time monitoring of health data and the status of health conditions. This adoption of wearables results in a significant increase in the volume of data that is collected and transmitted. As the devices are run by small battery power, they can be quickly diminished due to the high processing requirements of the device for data collection and transmission. Given the importance attached to medical data, it is imperative that all transmitted data adhere to strict integrity and availability requirements. Reducing the volume of healthcare data and the frequency of transmission will improve the device battery life via using inference algorithm. There is an issue of improving transmission metrics with accuracy and efficiency, which trade-off each other such as increasing accuracy reduces the efficiency. This paper demonstrates that machine learning can be used to analyze complex health data metrics such as the accuracy and efficiency of data transmission to overcome the trade-off problem using the Levenberg-Marquardt algorithm to enhance both metrics by taking fewer samples to transmit whilst maintaining the accuracy. The algorithm is tested with a standard heart rate dataset to compare the metrics. The result shows that the LMA has best performed with an efficiency of 3.33 times for reduced sample data size and accuracy of 79.17%, which has the similar accuracies in 7 different sampling cases adopted for testing but demonstrates improved efficiency. These proposed methods significantly improved both metrics using machine learning without sacrificing a metric over the other compared to the existing methods with high efficiency.
Object Permanence Emerges in a Random Walk along Memory
Apr 04, 2022
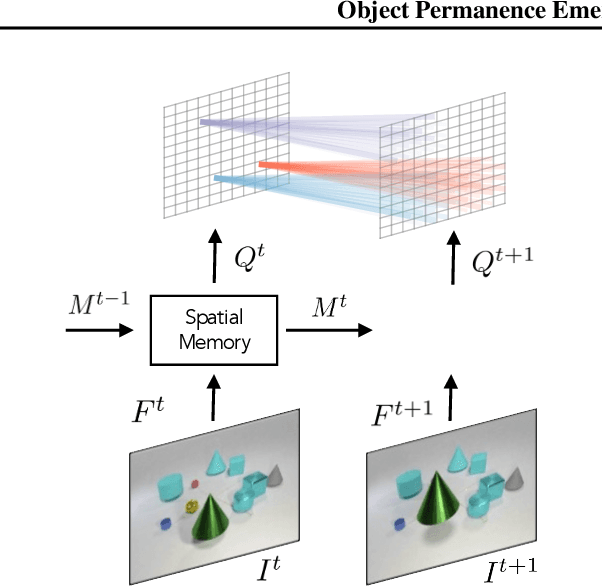

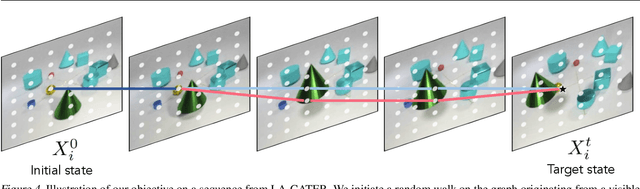
This paper proposes a self-supervised objective for learning representations that localize objects under occlusion - a property known as object permanence. A central question is the choice of learning signal in cases of total occlusion. Rather than directly supervising the locations of invisible objects, we propose a self-supervised objective that requires neither human annotation, nor assumptions about object dynamics. We show that object permanence can emerge by optimizing for temporal coherence of memory: we fit a Markov walk along a space-time graph of memories, where the states in each time step are non-Markovian features from a sequence encoder. This leads to a memory representation that stores occluded objects and predicts their motion, to better localize them. The resulting model outperforms existing approaches on several datasets of increasing complexity and realism, despite requiring minimal supervision and assumptions, and hence being broadly applicable.
Loop Closure Prioritization for Efficient and Scalable Multi-Robot SLAM
May 24, 2022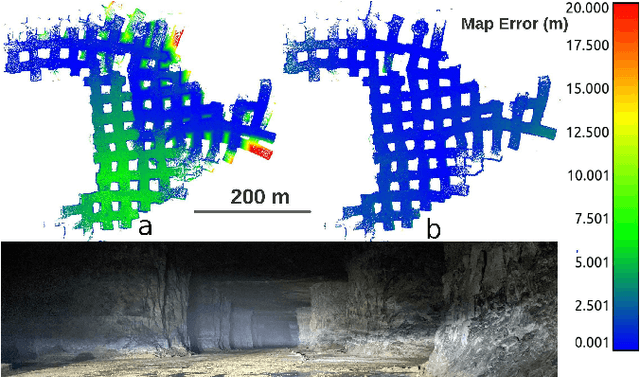
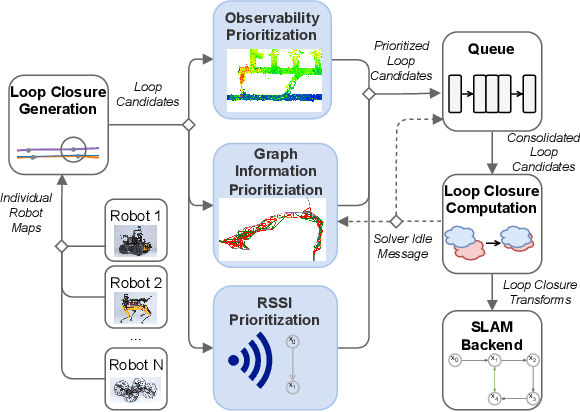
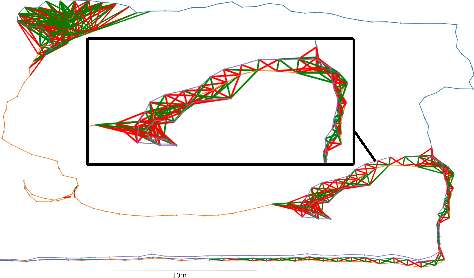
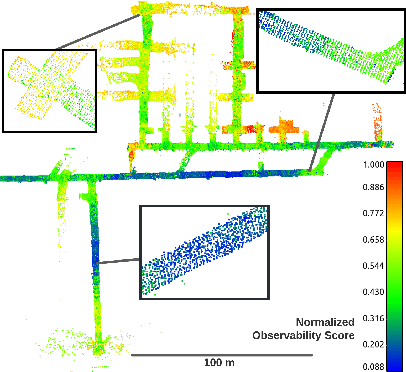
Multi-robot SLAM systems in GPS-denied environments require loop closures to maintain a drift-free centralized map. With an increasing number of robots and size of the environment, checking and computing the transformation for all the loop closure candidates becomes computationally infeasible. In this work, we describe a loop closure module that is able to prioritize which loop closures to compute based on the underlying pose graph, the proximity to known beacons, and the characteristics of the point clouds. We validate this system in the context of the DARPA Subterranean Challenge and on numerous challenging underground datasets and demonstrate the ability of this system to generate and maintain a map with low error. We find that our proposed techniques are able to select effective loop closures which results in 51% mean reduction in median error when compared to an odometric solution and 75% mean reduction in median error when compared to a baseline version of this system with no prioritization. We also find our proposed system is able to find a lower error in the mission time of one hour when compared to a system that processes every possible loop closure in four and a half hours.
Automated speech tools for helping communities process restricted-access corpora for language revival efforts
Apr 15, 2022
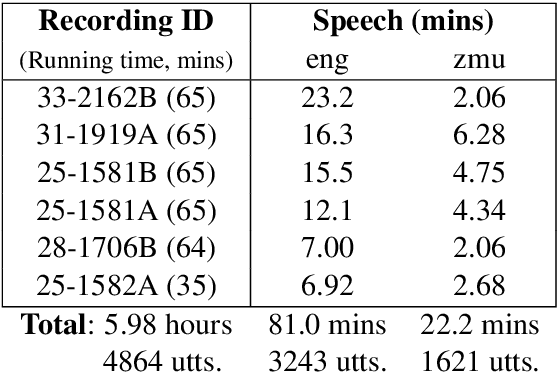
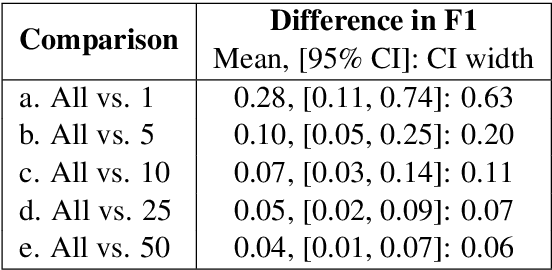
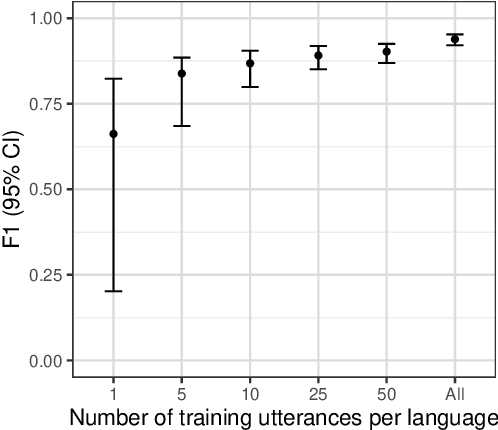
Many archival recordings of speech from endangered languages remain unannotated and inaccessible to community members and language learning programs. One bottleneck is the time-intensive nature of annotation. An even narrower bottleneck occurs for recordings with access constraints, such as language that must be vetted or filtered by authorised community members before annotation can begin. We propose a privacy-preserving workflow to widen both bottlenecks for recordings where speech in the endangered language is intermixed with a more widely-used language such as English for meta-linguistic commentary and questions (e.g. What is the word for 'tree'?). We integrate voice activity detection (VAD), spoken language identification (SLI), and automatic speech recognition (ASR) to transcribe the metalinguistic content, which an authorised person can quickly scan to triage recordings that can be annotated by people with lower levels of access. We report work-in-progress processing 136 hours archival audio containing a mix of English and Muruwari. Our collaborative work with the Muruwari custodian of the archival materials show that this workflow reduces metalanguage transcription time by 20% even given only minimal amounts of annotated training data: 10 utterances per language for SLI and 39 minutes of the English for ASR.
Mixture Models for the Analysis, Edition, and Synthesis of Continuous Time Series
Apr 21, 2021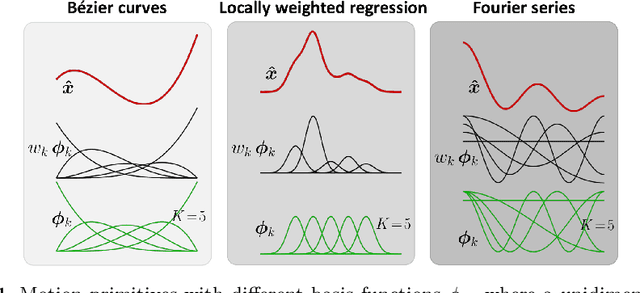

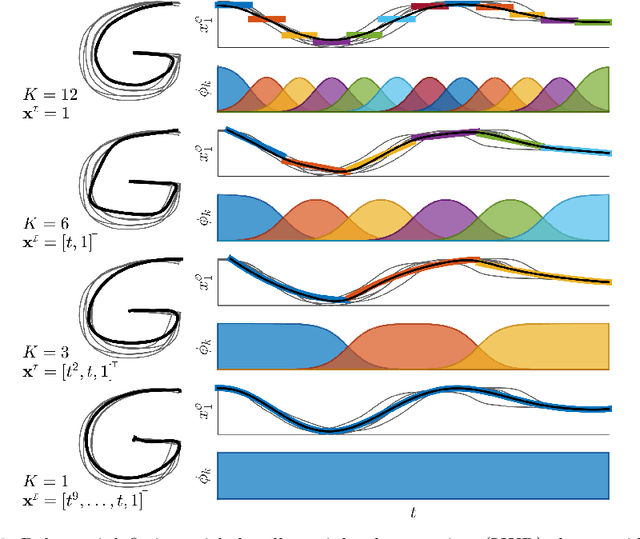
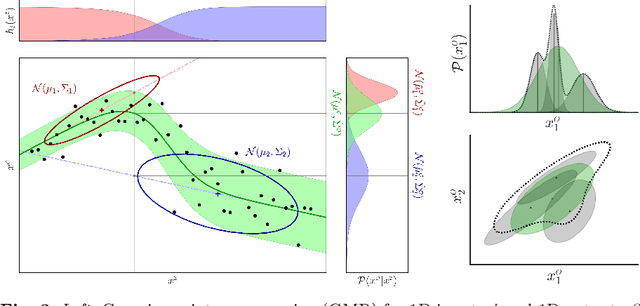
This chapter presents an overview of techniques used for the analysis, edition, and synthesis of time series, with a particular emphasis on motion data. The use of mixture models allows the decomposition of time signals as a superposition of basis functions. It provides a compact representation that aims at keeping the essential characteristics of the signals. Various types of basis functions have been proposed, with developments originating from different fields of research, including computer graphics, human motion science, robotics, control, and neuroscience. Examples of applications with radial, Bernstein and Fourier basis functions will be presented, with associated source codes to get familiar with these techniques.
* 20 pages, 7 figures
CodeS: A Distribution Shift Benchmark Dataset for Source Code Learning
Jun 11, 2022



Over the past few years, deep learning (DL) has been continuously expanding its applications and becoming a driving force for large-scale source code analysis in the big code era. Distribution shift, where the test set follows a different distribution from the training set, has been a longstanding challenge for the reliable deployment of DL models due to the unexpected accuracy degradation. Although recent progress on distribution shift benchmarking has been made in domains such as computer vision and natural language process. Limited progress has been made on distribution shift analysis and benchmarking for source code tasks, on which there comes a strong demand due to both its volume and its important role in supporting the foundations of almost all industrial sectors. To fill this gap, this paper initiates to propose CodeS, a distribution shift benchmark dataset, for source code learning. Specifically, CodeS supports 2 programming languages (i.e., Java and Python) and 5 types of code distribution shifts (i.e., task, programmer, time-stamp, token, and CST). To the best of our knowledge, we are the first to define the code representation-based distribution shifts. In the experiments, we first evaluate the effectiveness of existing out-of-distribution detectors and the reasonability of the distribution shift definitions and then measure the model generalization of popular code learning models (e.g., CodeBERT) on classification task. The results demonstrate that 1) only softmax score-based OOD detectors perform well on CodeS, 2) distribution shift causes the accuracy degradation in all code classification models, 3) representation-based distribution shifts have a higher impact on the model than others, and 4) pre-trained models are more resistant to distribution shifts. We make CodeS publicly available, enabling follow-up research on the quality assessment of code learning models.
Robotic and Generative Adversarial Attacks in Offline Writer-independent Signature Verification
Apr 14, 2022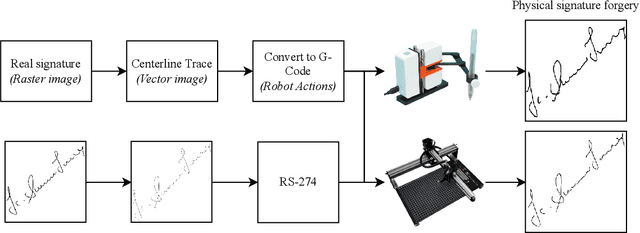
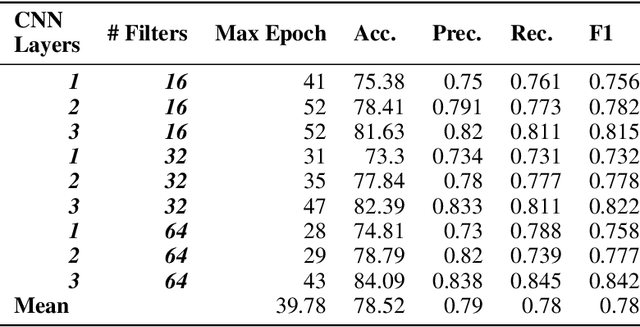

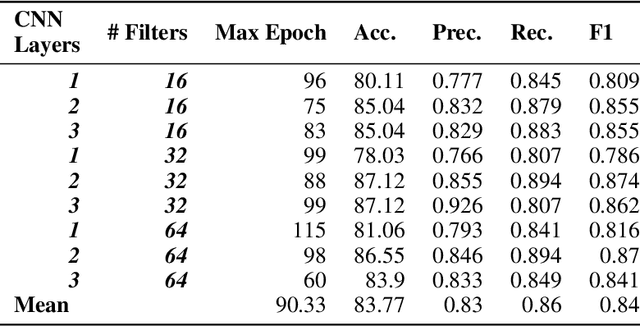
This study explores how robots and generative approaches can be used to mount successful false-acceptance adversarial attacks on signature verification systems. Initially, a convolutional neural network topology and data augmentation strategy are explored and tuned, producing an 87.12% accurate model for the verification of 2,640 human signatures. Two robots are then tasked with forging 50 signatures, where 25 are used for the verification attack, and the remaining 25 are used for tuning of the model to defend against them. Adversarial attacks on the system show that there exists an information security risk; the Line-us robotic arm can fool the system 24% of the time and the iDraw 2.0 robot 32% of the time. A conditional GAN finds similar success, with around 30% forged signatures misclassified as genuine. Following fine-tune transfer learning of robotic and generative data, adversarial attacks are reduced below the model threshold by both robots and the GAN. It is observed that tuning the model reduces the risk of attack by robots to 8% and 12%, and that conditional generative adversarial attacks can be reduced to 4% when 25 images are presented and 5% when 1000 images are presented.