 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AZ-whiteness test: a test for uncorrelated noise on spatio-temporal graphs
Apr 23, 2022
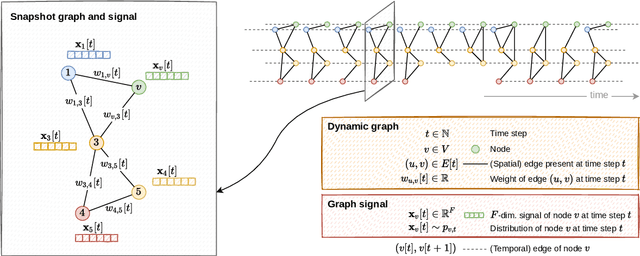

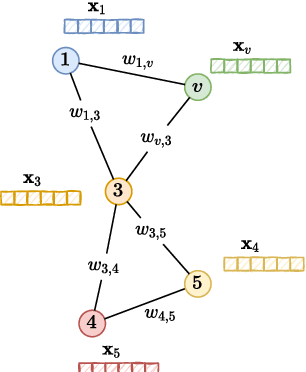
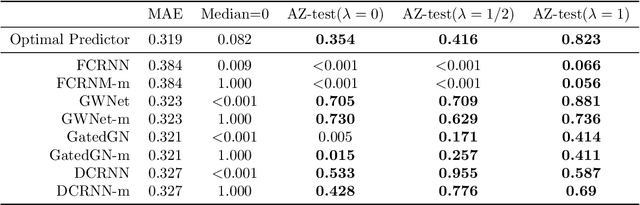
We present the first whiteness test for graphs, i.e., a whiteness test for multivariate time series associated with the nodes of a dynamic graph. The statistical test aims at finding serial dependencies among close-in-time observations, as well as spatial dependencies among neighboring observations given the underlying graph. The proposed test is a spatio-temporal extension of traditional tests from the system identification literature and finds applications in similar, yet more general, application scenarios involving graph signals. The AZ-test is versatile, allowing the underlying graph to be dynamic, changing in topology and set of nodes, and weighted, thus accounting for connections of different strength, as is the case in many application scenarios like transportation networks and sensor grids. The asymptotic distribution -- as the number of graph edges or temporal observations increases -- is known, and does not assume identically distributed data. We validate the practical value of the test on both synthetic and real-world problems, and show how the test can be employed to assess the quality of spatio-temporal forecasting models by analyzing the prediction residuals appended to the graphs stream.
HeadText: Exploring Hands-free Text Entry using Head Gestures by Motion Sensing on a Smart Earpiece
May 23, 2022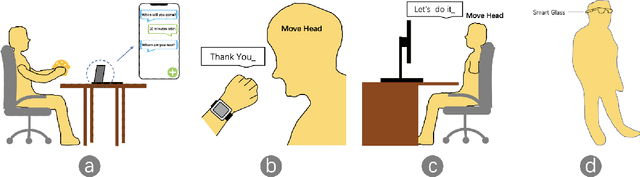
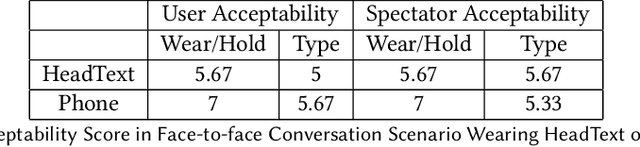
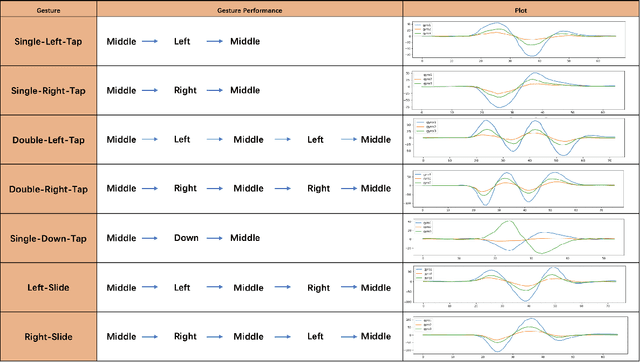
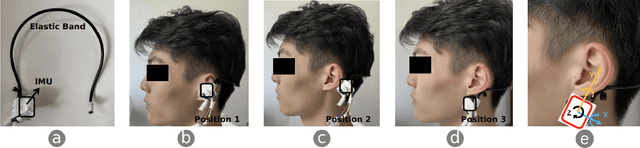
We present HeadText, a hands-free technique on a smart earpiece for text entry by motion sensing. Users input text utilizing only 7 head gestures for key selection, word selection, word commitment and word cancelling tasks. Head gesture recognition is supported by motion sensing on a smart earpiece to capture head moving signals and machine learning algorithms (K-Nearest-Neighbor (KNN) with a Dynamic Time Warping (DTW) distance measurement). A 10-participant user study proved that HeadText could recognize 7 head gestures at an accuracy of 94.29%. After that, the second user study presented that HeadText could achieve a maximum accuracy of 10.65 WPM and an average accuracy of 9.84 WPM for text entry. Finally, we demonstrate potential applications of HeadText in hands-free scenarios for (a). text entry of people with motor impairments, (b). private text entry, and (c). socially acceptable text entry.
Explorative Data Analysis of Time Series based AlgorithmFeatures of CMA-ES Variants
Apr 16, 2021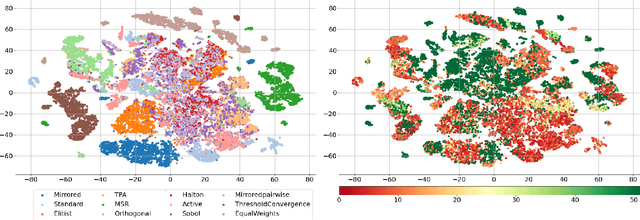
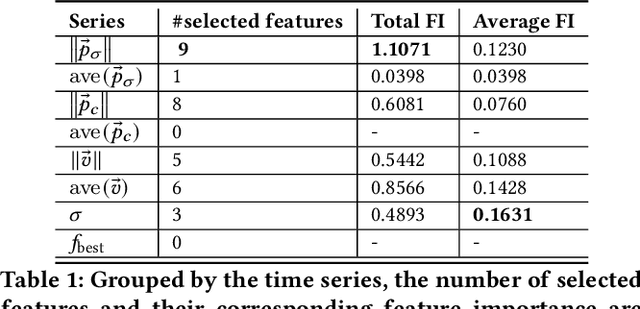
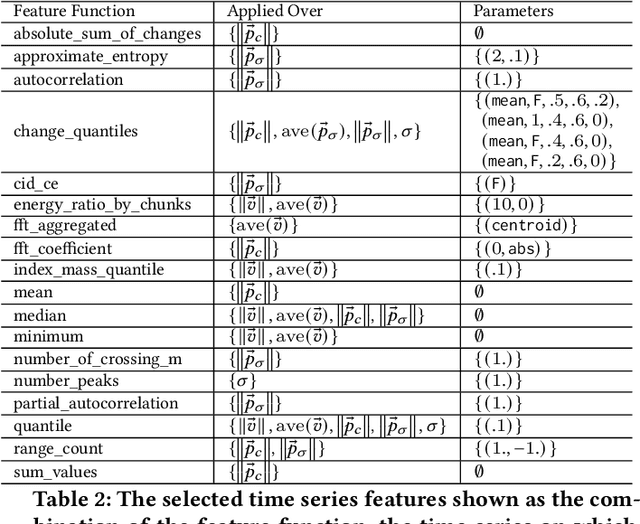
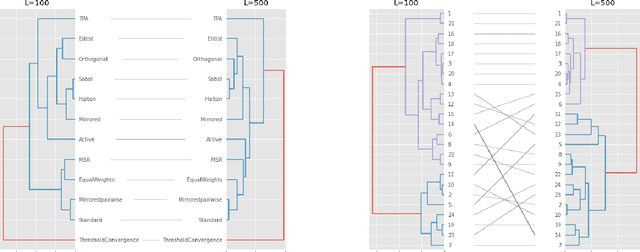
In this study, we analyze behaviours of the well-known CMA-ES by extracting the time-series features on its dynamic strategy parameters. An extensive experiment was conducted on twelve CMA-ES variants and 24 test problems taken from the BBOB (Black-Box Optimization Bench-marking) testbed, where we used two different cutoff times to stop those variants. We utilized the tsfresh package for extracting the features and performed the feature selection procedure using the Boruta algorithm, resulting in 32 features to distinguish either CMA-ES variants or the problems. After measuring the number of predefined targets reached by those variants, we contrive to predict those measured values on each test problem using the feature. From our analysis, we saw that the features can classify the CMA-ES variants, or the function groups decently, and show a potential for predicting the performance of those variants. We conducted a hierarchical clustering analysis on the test problems and noticed a drastic change in the clustering outcome when comparing the longer cutoff time to the shorter one, indicating a huge change in search behaviour of the algorithm. In general, we found that with longer time series, the predictive power of the time series features increase.
Probing Simile Knowledge from Pre-trained Language Models
Apr 27, 2022

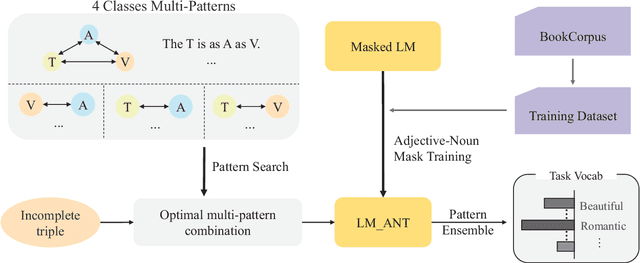
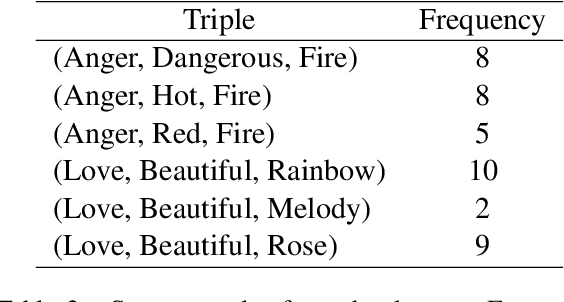
Simile interpretation (SI) and simile generation (SG) are challenging tasks for NLP because models require adequate world knowledge to produce predictions. Previous works have employed many hand-crafted resources to bring knowledge-related into models, which is time-consuming and labor-intensive. In recent years, pre-trained language models (PLMs) based approaches have become the de-facto standard in NLP since they learn generic knowledge from a large corpus. The knowledge embedded in PLMs may be useful for SI and SG tasks. Nevertheless, there are few works to explore it. In this paper, we probe simile knowledge from PLMs to solve the SI and SG tasks in the unified framework of simile triple completion for the first time. The backbone of our framework is to construct masked sentences with manual patterns and then predict the candidate words in the masked position. In this framework, we adopt a secondary training process (Adjective-Noun mask Training) with the masked language model (MLM) loss to enhance the prediction diversity of candidate words in the masked position. Moreover, pattern ensemble (PE) and pattern search (PS) are applied to improve the quality of predicted words. Finally, automatic and human evaluations demonstrate the effectiveness of our framework in both SI and SG tasks.
Streaming Align-Refine for Non-autoregressive Deliberation
Apr 15, 2022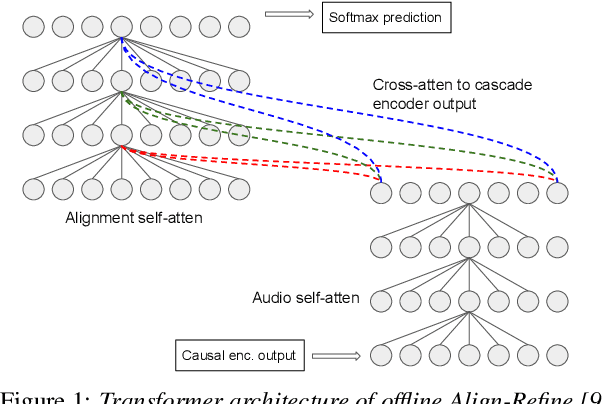
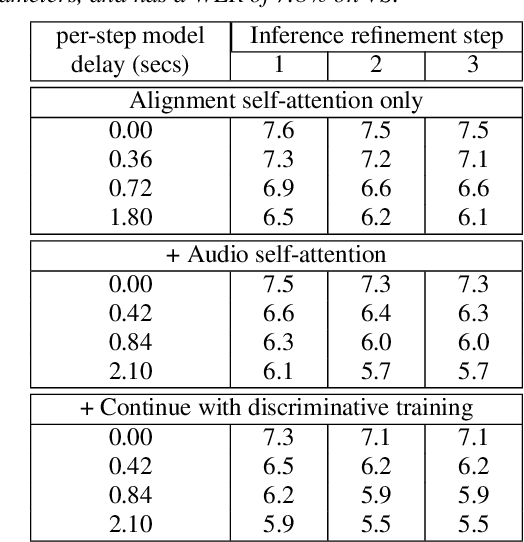
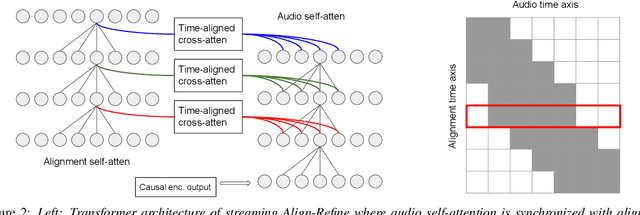
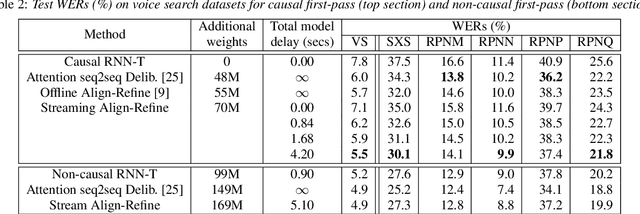
We propose a streaming non-autoregressive (non-AR) decoding algorithm to deliberate the hypothesis alignment of a streaming RNN-T model. Our algorithm facilitates a simple greedy decoding procedure, and at the same time is capable of producing the decoding result at each frame with limited right context, thus enjoying both high efficiency and low latency. These advantages are achieved by converting the offline Align-Refine algorithm to be streaming-compatible, with a novel transformer decoder architecture that performs local self-attentions for both text and audio, and a time-aligned cross-attention at each layer. Furthermore, we perform discriminative training of our model with the minimum word error rate (MWER) criterion, which has not been done in the non-AR decoding literature. Experiments on voice search datasets and Librispeech show that with reasonable right context, our streaming model performs as well as the offline counterpart, and discriminative training leads to further WER gain when the first-pass model has small capacity.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022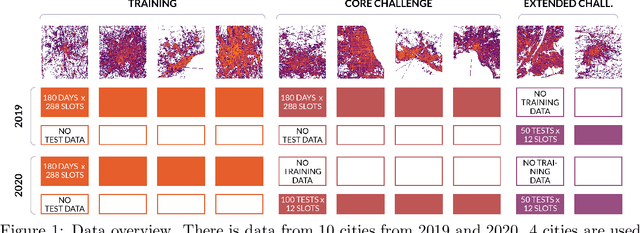
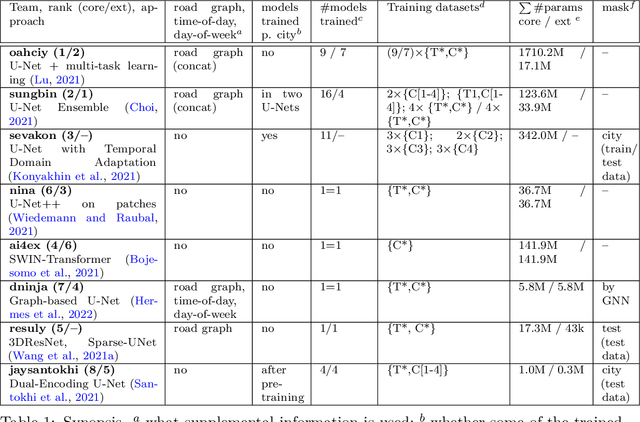
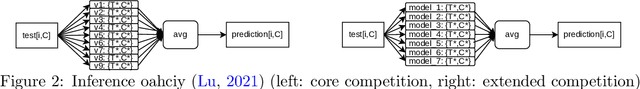
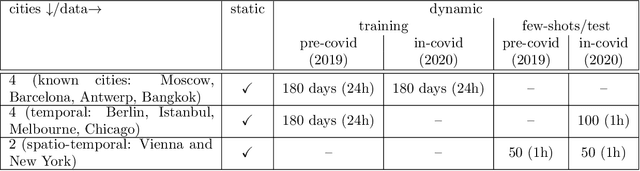
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
It Isn't Sh!tposting, It's My CAT Posting
May 18, 2022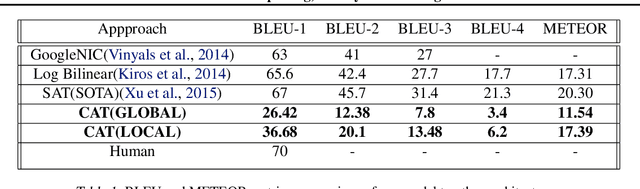


In this paper, we describe a novel architecture which can generate hilarious captions for a given input image. The architecture is split into two halves, i.e. image captioning and hilarious text conversion. The architecture starts with a pre-trained CNN model, VGG16 in this implementation, and applies attention LSTM on it to generate normal caption. These normal captions then are fed forward to our hilarious text conversion transformer which converts this text into something hilarious while maintaining the context of the input image. The architecture can also be split into two halves and only the seq2seq transformer can be used to generate hilarious caption by inputting a sentence.This paper aims to help everyday user to be more lazy and hilarious at the same time by generating captions using CATNet.
Deepfake histological images for enhancing digital pathology
Jun 16, 2022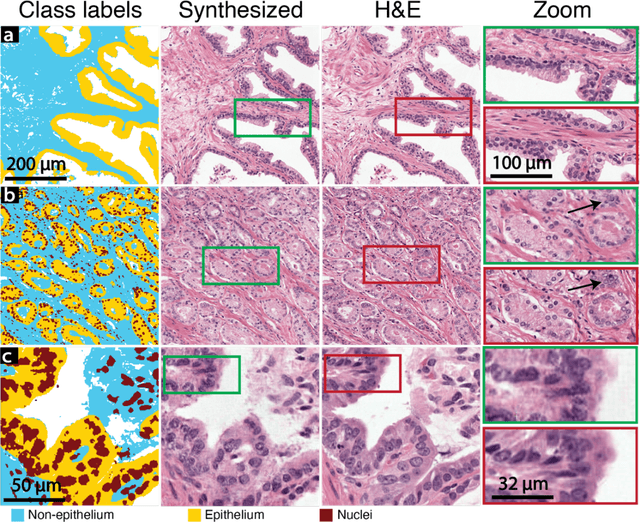
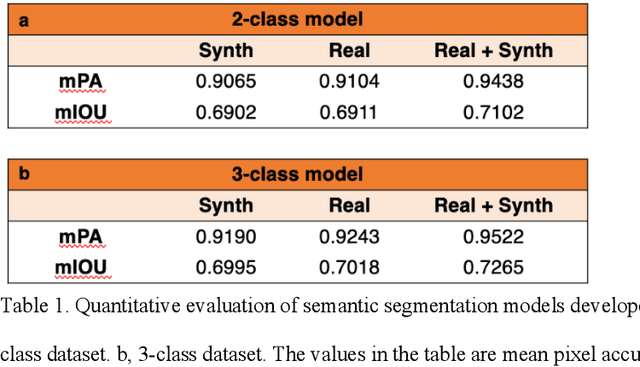
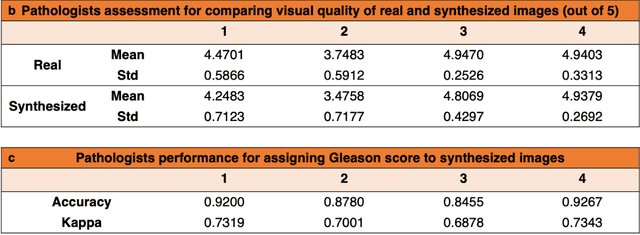
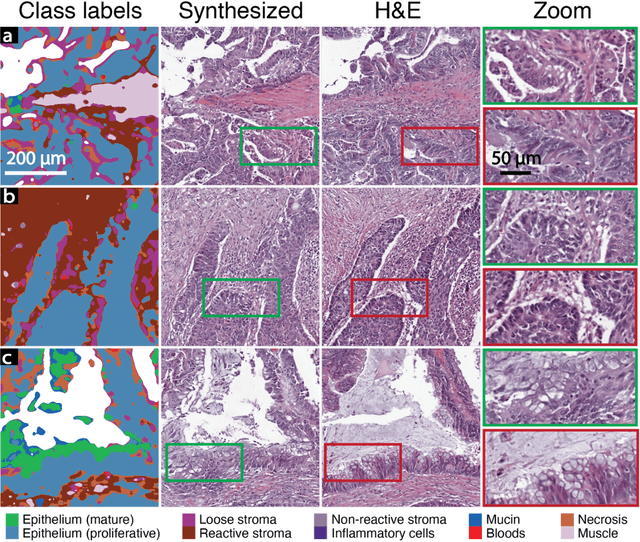
An optical microscopic examination of thinly cut stained tissue on glass slides prepared from a FFPE tissue blocks is the gold standard for tissue diagnostics. In addition, the diagnostic abilities and expertise of any pathologist is dependent on their direct experience with common as well as rarer variant morphologies. Recently, deep learning approaches have been used to successfully show a high level of accuracy for such tasks. However, obtaining expert-level annotated images is an expensive and time-consuming task and artificially synthesized histological images can prove greatly beneficial. Here, we present an approach to not only generate histological images that reproduce the diagnostic morphologic features of common disease but also provide a user ability to generate new and rare morphologies. Our approach involves developing a generative adversarial network model that synthesizes pathology images constrained by class labels. We investigated the ability of this framework in synthesizing realistic prostate and colon tissue images and assessed the utility of these images in augmenting diagnostic ability of machine learning methods as well as their usability by a panel of experienced anatomic pathologists. Synthetic data generated by our framework performed similar to real data in training a deep learning model for diagnosis. Pathologists were not able to distinguish between real and synthetic images and showed a similar level of inter-observer agreement for prostate cancer grading. We extended the approach to significantly more complex images from colon biopsies and showed that the complex microenvironment in such tissues can also be reproduced. Finally, we present the ability for a user to generate deepfake histological images via a simple markup of sematic labels.
Cooperative Multi-Agent Trajectory Generation with Modular Bayesian Optimization
Jun 01, 2022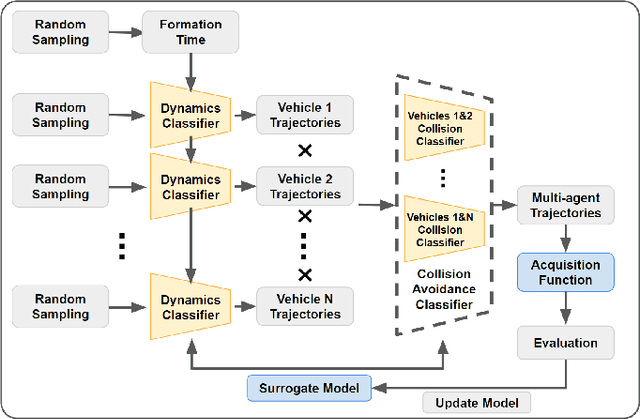
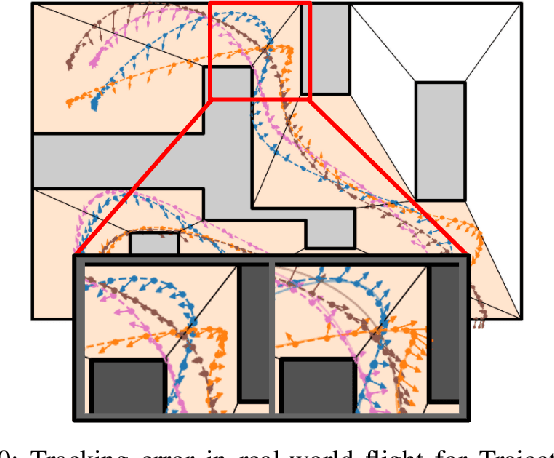
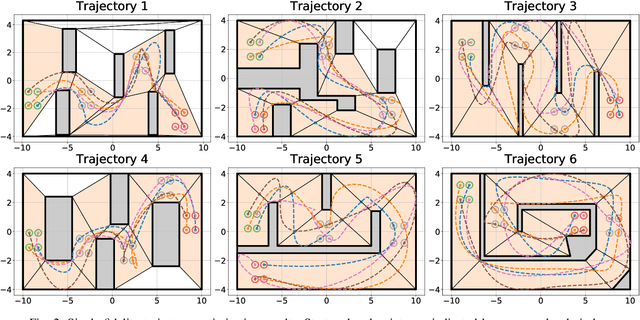
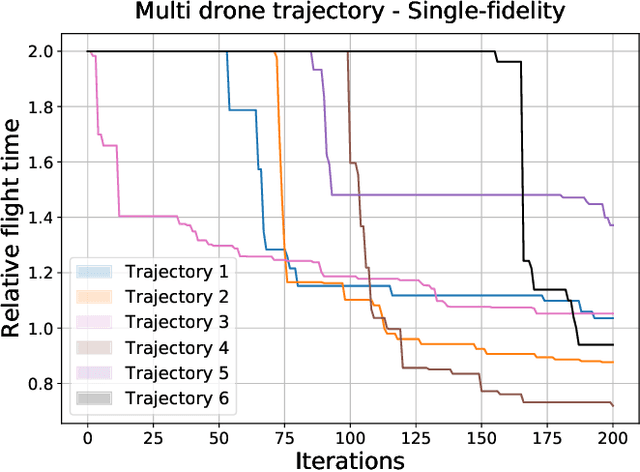
We present a modular Bayesian optimization framework that efficiently generates time-optimal trajectories for a cooperative multi-agent system, such as a team of UAVs. Existing methods for multi-agent trajectory generation often rely on overly conservative constraints to reduce the complexity of this high-dimensional planning problem, leading to suboptimal solutions. We propose a novel modular structure for the Bayesian optimization model that consists of multiple Gaussian process surrogate models that represent the dynamic feasibility and collision avoidance constraints. This modular structure alleviates the stark increase in computational cost with problem dimensionality and enables the use of minimal constraints in the joint optimization of the multi-agent trajectories. The efficiency of the algorithm is further improved by introducing a scheme for simultaneous evaluation of the Bayesian optimization acquisition function and random sampling. The modular BayesOpt algorithm was applied to optimize multi-agent trajectories through six unique environments using multi-fidelity evaluations from various data sources. It was found that the resulting trajectories are faster than those obtained from two baseline methods. The optimized trajectories were validated in real-world experiments using four quadcopters that fly within centimeters of each other at speeds up to 7.4 m/s.
Action Noise in Off-Policy Deep Reinforcement Learning: Impact on Exploration and Performance
Jun 08, 2022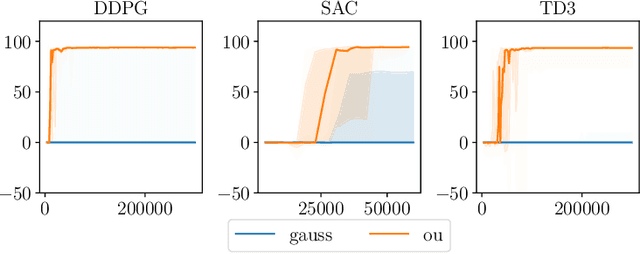
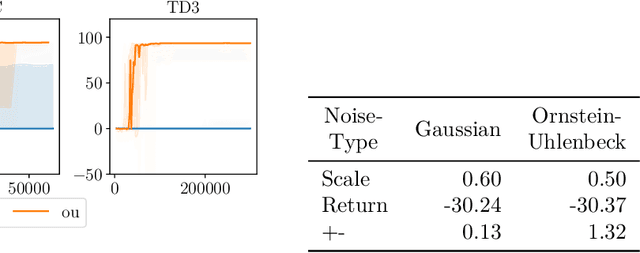
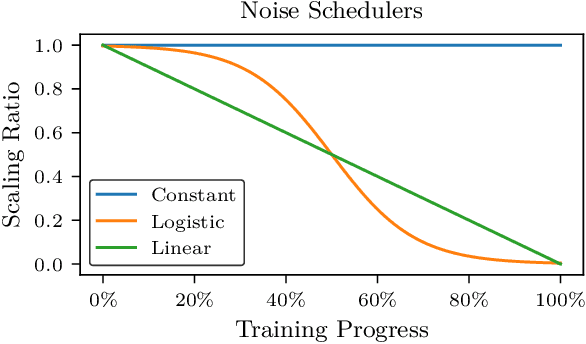
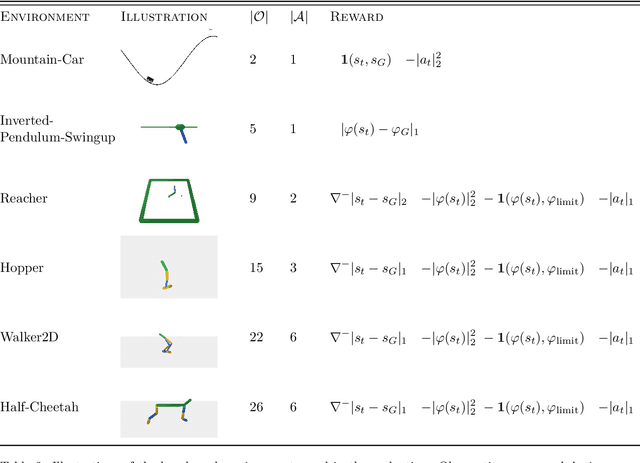
Many deep reinforcement learning algorithms rely on simple forms of exploration, such as the additive action-noise often used in continuous control domains. Typically, the scaling factor of this action noise is chosen as a hyper-parameter and kept constant during training. In this paper, we analyze how the learned policy is impacted by the noise type, scale, and reducing of the scaling factor over time. We consider the two most prominent types of action-noise: Gaussian and Ornstein-Uhlenbeck noise, and perform a vast experimental campaign by systematically varying the noise type and scale parameter, and by measuring variables of interest like the expected return of the policy and the state space coverage during exploration. For the latter, we propose a novel state-space coverage measure $\operatorname{X}_{\mathcal{U}\text{rel}}$ that is more robust to boundary artifacts than previously proposed measures. Larger noise scales generally increase state space coverage. However, we found that increasing the space coverage using a larger noise scale is often not beneficial. On the contrary, reducing the noise-scale over the training process reduces the variance and generally improves the learning performance. We conclude that the best noise-type and scale are environment dependent, and based on our observations, derive heuristic rules for guiding the choice of the action noise as a starting point for further optimization.