 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Flying Hydraulically Amplified Electrostatic Gripper System for Aerial Object Manipulation
May 25, 2022
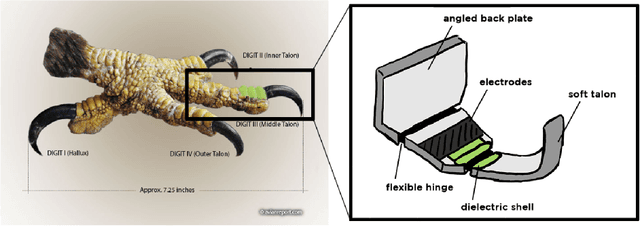
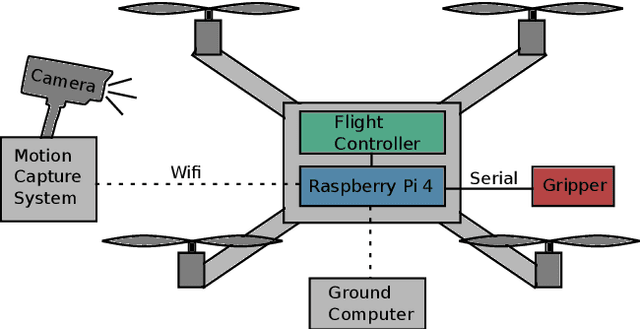


Rapid and versatile object manipulation in air is an open challenge. An energy-efficient and adaptive soft gripper combined with an agile aerial vehicle could revolutionize aerial robotic manipulation in areas such as warehousing. This paper presents a bio-inspired gripper powered by hydraulically amplified electrostatic actuators mounted to a quadcopter that can interact safely and naturally with its environment. Our gripping concept is motivated by an eagle's talon. Our custom multi-actuator type is inspired by a previous scorpion tail design (consisting of a base electrode and pouches stacked adjacently) and spider-inspired joints (classic pouch motors with a flexible hinge layer). A fusion of these two concepts realizes a higher force output than single-actuator types under considerable deflections of up to 25{\deg}. By adding a sandwich hinge layer structure to the classic pouch motor concept we improve the overall robustness of the gripper. We show, for the first time, that soft manipulation in air is possible using electrostatic actuation. This study demonstrates the high potential of untethered hydraulically amplified actuators for the future of robotic manipulation. Our lightweight and bio-inspired system opens up the use of hydraulic electrostatic actuators in aerial mobile systems.
A Simple and Optimal Policy Design for Online Learning with Safety against Heavy-tailed Risk
Jun 07, 2022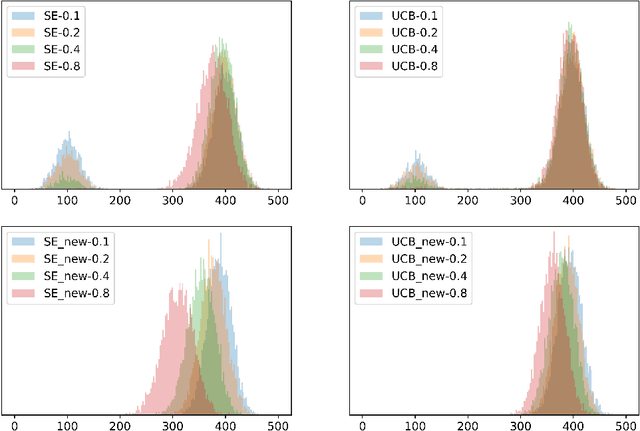
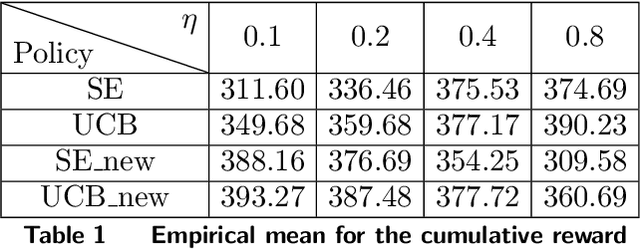
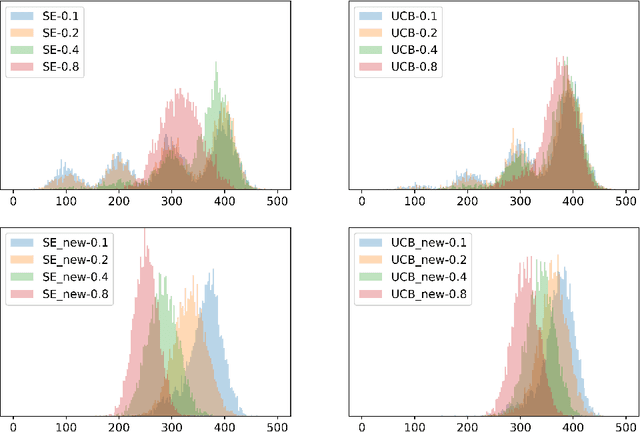
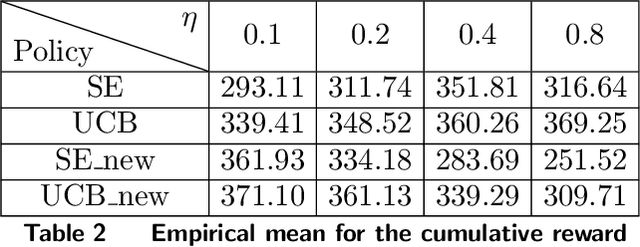
We design simple and optimal policies that ensure safety against heavy-tailed risk in the classical multi-armed bandit problem. We start by showing that some widely used policies such as the standard Upper Confidence Bound policy and the Thompson Sampling policy incur heavy-tailed risk; that is, the worst-case probability of incurring a linear regret slowly decays at a polynomial rate of $1/T$, where $T$ is the time horizon. We further show that this heavy-tailed risk exists for all "instance-dependent consistent" policies. To ensure safety against such heavy-tailed risk, for the two-armed bandit setting, we provide a simple policy design that (i) has the worst-case optimality for the expected regret at order $\tilde O(\sqrt{T})$ and (ii) has the worst-case tail probability of incurring a linear regret decay at an exponential rate $\exp(-\Omega(\sqrt{T}))$. We further prove that this exponential decaying rate of the tail probability is optimal across all policies that have worst-case optimality for the expected regret. Finally, we improve the policy design and analysis to the general $K$-armed bandit setting. We provide detailed characterization of the tail probability bound for any regret threshold under our policy design. Namely, the worst-case probability of incurring a regret larger than $x$ is upper bounded by $\exp(-\Omega(x/\sqrt{KT}))$. Numerical experiments are conducted to illustrate the theoretical findings. Our results reveal insights on the incompatibility between consistency and light-tailed risk, whereas indicate that worst-case optimality on expected regret and light-tailed risk are compatible.
Dual Skipping Guidance for Document Retrieval with Learned Sparse Representations
Apr 23, 2022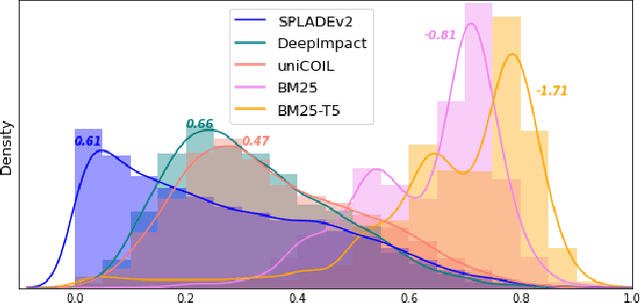
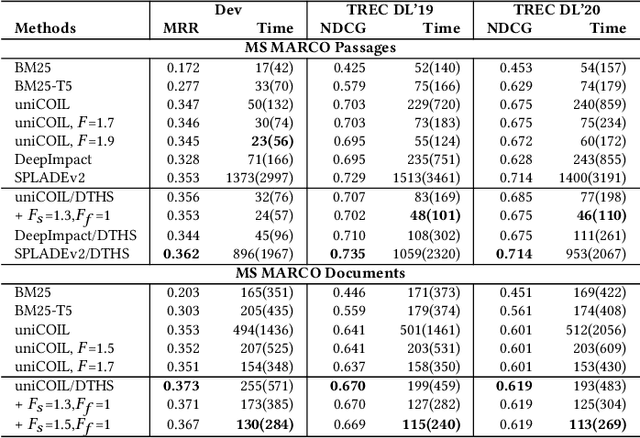
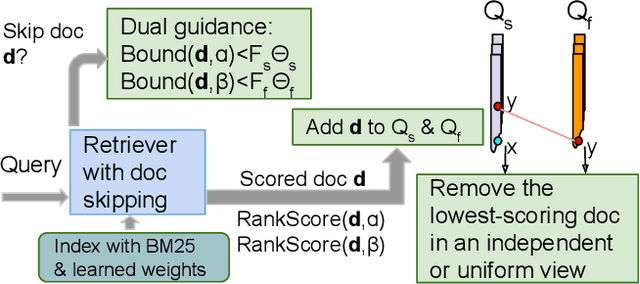
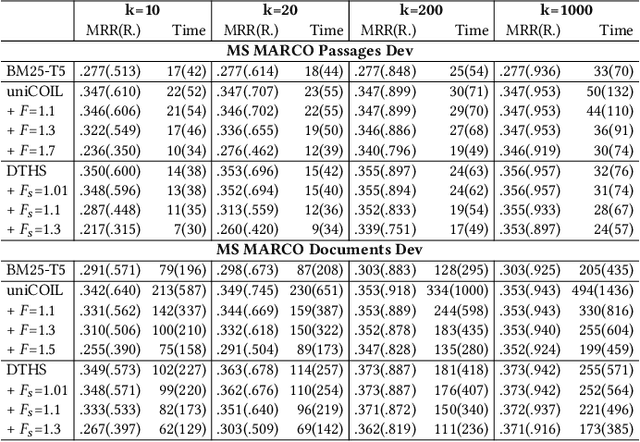
This paper proposes a dual skipping guidance scheme with hybrid scoring to accelerate document retrieval that uses learned sparse representations while still delivering a good relevance. This scheme uses both lexical BM25 and learned neural term weights to bound and compose the rank score of a candidate document separately for skipping and final ranking, and maintains two top-k thresholds during inverted index traversal. This paper evaluates time efficiency and ranking relevance of the proposed scheme in searching MS MARCO TREC datasets.
Label-Efficient Online Continual Object Detection in Streaming Video
Jun 01, 2022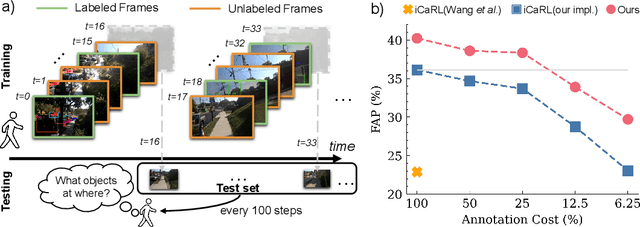
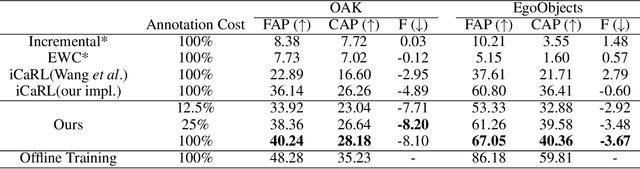
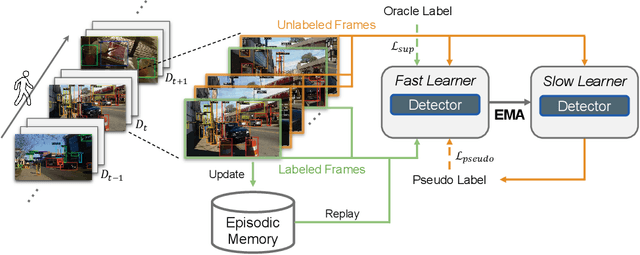

To thrive in evolving environments, humans are capable of continual acquisition and transfer of new knowledge, from a continuous video stream, with minimal supervisions, while retaining previously learnt experiences. In contrast to human learning, most standard continual learning benchmarks focus on learning from static iid images in fully supervised settings. Here, we examine a more realistic and challenging problem$\unicode{x2014}$Label-Efficient Online Continual Object Detection (LEOCOD) in video streams. By addressing this problem, it would greatly benefit many real-world applications with reduced annotation costs and retraining time. To tackle this problem, we seek inspirations from complementary learning systems (CLS) in human brains and propose a computational model, dubbed as Efficient-CLS. Functionally correlated with the hippocampus and the neocortex in CLS, Efficient-CLS posits a memory encoding mechanism involving bidirectional interaction between fast and slow learners via synaptic weight transfers and pattern replays. We test Efficient-CLS and competitive baselines in two challenging real-world video stream datasets. Like humans, Efficient-CLS learns to detect new object classes incrementally from a continuous temporal stream of non-repeating video with minimal forgetting. Remarkably, with only 25% annotated video frames, our Efficient-CLS still leads among all comparative models, which are trained with 100% annotations on all video frames. The data and source code will be publicly available at https://github.com/showlab/Efficient-CLS.
NaturalProver: Grounded Mathematical Proof Generation with Language Models
May 25, 2022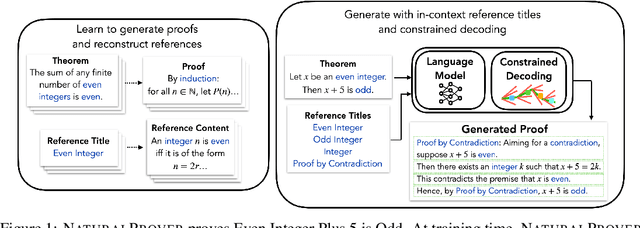

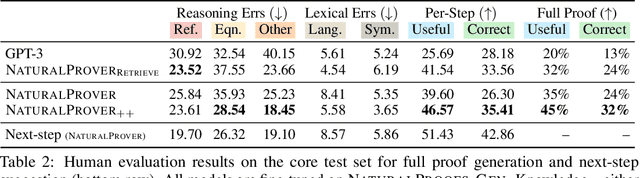
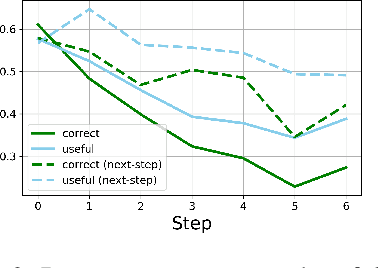
Theorem proving in natural mathematical language - the mixture of symbolic and natural language used by humans - plays a central role in mathematical advances and education, and tests aspects of reasoning that are core to intelligence. Yet it has remained underexplored with modern generative models. We study large-scale language models on two new generation tasks: suggesting the next step in a mathematical proof, and full proof generation. Naively applying language models to these problems yields proofs riddled with hallucinations and logical incoherence. We develop NaturalProver, a language model that generates proofs by conditioning on background references (e.g. theorems and definitions that are either retrieved or human-provided), and optionally enforces their presence with constrained decoding. On theorems from the NaturalProofs benchmark, NaturalProver improves the quality of next-step suggestions and generated proofs over fine-tuned GPT-3, according to human evaluations from university-level mathematics students. NaturalProver is capable of proving some theorems that require short (2-6 step) proofs, and providing next-step suggestions that are rated as correct and useful over 40% of the time, which is to our knowledge the first demonstration of these capabilities using neural language models.
An unsupervised approach for semantic place annotation of trajectories based on the prior probability
Apr 20, 2022
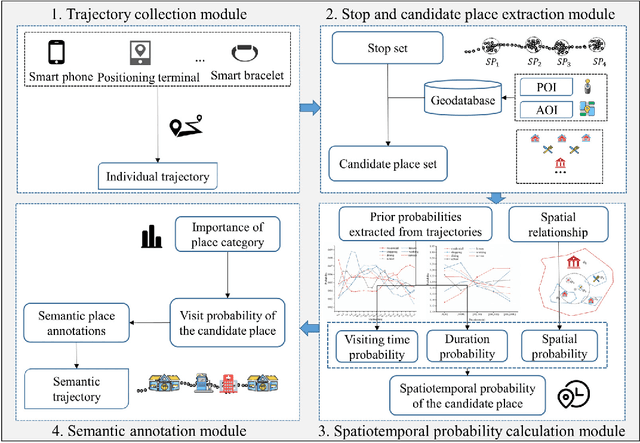
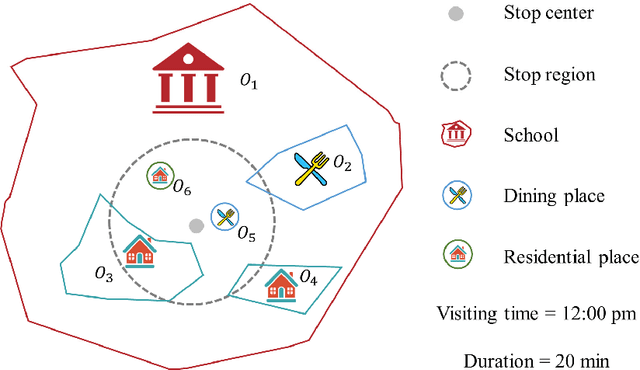
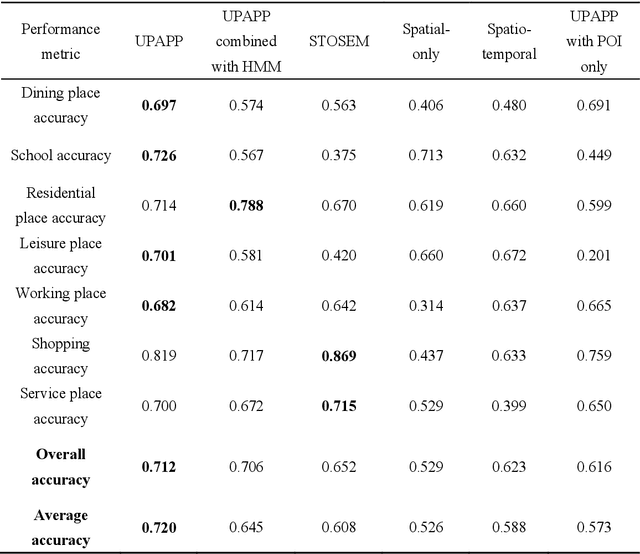
Semantic place annotation can provide individual semantics, which can be of great help in the field of trajectory data mining. Most existing methods rely on annotated or external data and require retraining following a change of region, thus preventing their large-scale applications. Herein, we propose an unsupervised method denoted as UPAPP for the semantic place annotation of trajectories using spatiotemporal information. The Bayesian Criterion is specifically employed to decompose the spatiotemporal probability of the candidate place into spatial probability, duration probability, and visiting time probability. Spatial information in ROI and POI data is subsequently adopted to calculate the spatial probability. In terms of the temporal probabilities, the Term Frequency Inverse Document Frequency weighting algorithm is used to count the potential visits to different place types in the trajectories, and generates the prior probabilities of the visiting time and duration. The spatiotemporal probability of the candidate place is then combined with the importance of the place category to annotate the visited places. Validation with a trajectory dataset collected by 709 volunteers in Beijing showed that our method achieved an overall and average accuracy of 0.712 and 0.720, respectively, indicating that the visited places can be annotated accurately without any external data.
Where were my keys? -- Aggregating Spatial-Temporal Instances of Objects for Efficient Retrieval over Long Periods of Time
Oct 25, 2021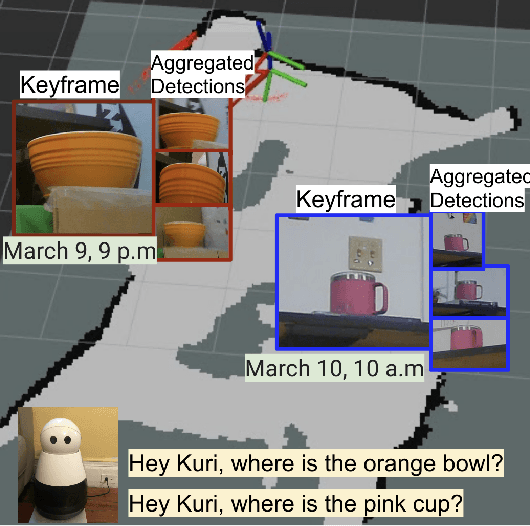

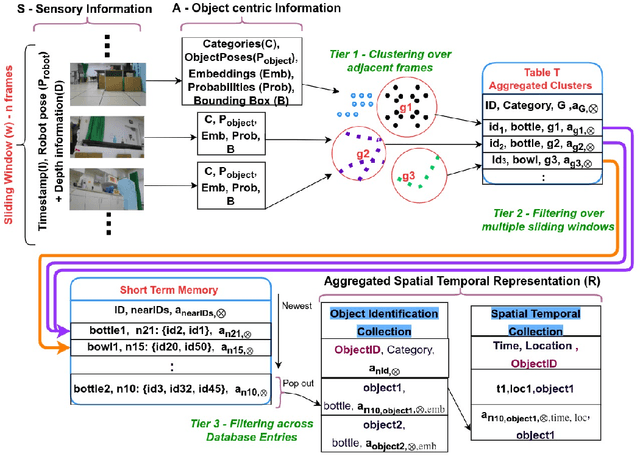
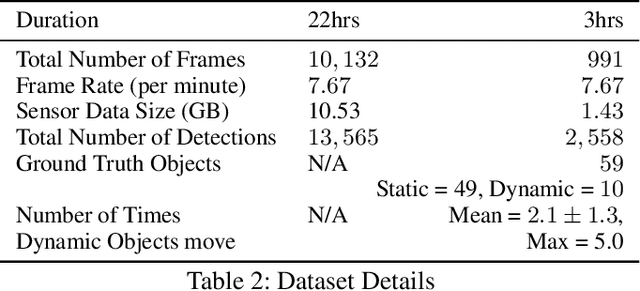
Robots equipped with situational awareness can help humans efficiently find their lost objects by leveraging spatial and temporal structure. Existing approaches to video and image retrieval do not take into account the unique constraints imposed by a moving camera with a partial view of the environment. We present a Detection-based 3-level hierarchical Association approach, D3A, to create an efficient query-able spatial-temporal representation of unique object instances in an environment. D3A performs online incremental and hierarchical learning to identify keyframes that best represent the unique objects in the environment. These keyframes are learned based on both spatial and temporal features and once identified their corresponding spatial-temporal information is organized in a key-value database. D3A allows for a variety of query patterns such as querying for objects with/without the following: 1) specific attributes, 2) spatial relationships with other objects, and 3) time slices. For a given set of 150 queries, D3A returns a small set of candidate keyframes (which occupy only 0.17% of the total sensory data) with 81.98\% mean accuracy in 11.7 ms. This is 47x faster and 33% more accurate than a baseline that naively stores the object matches (detections) in the database without associating spatial-temporal information.
Cervical Glandular Cell Detection from Whole Slide Image with Out-Of-Distribution Data
Jun 01, 2022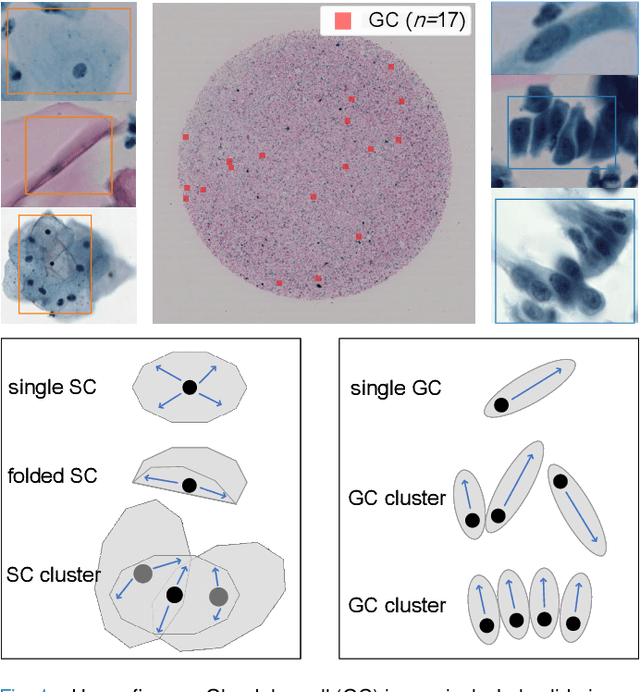
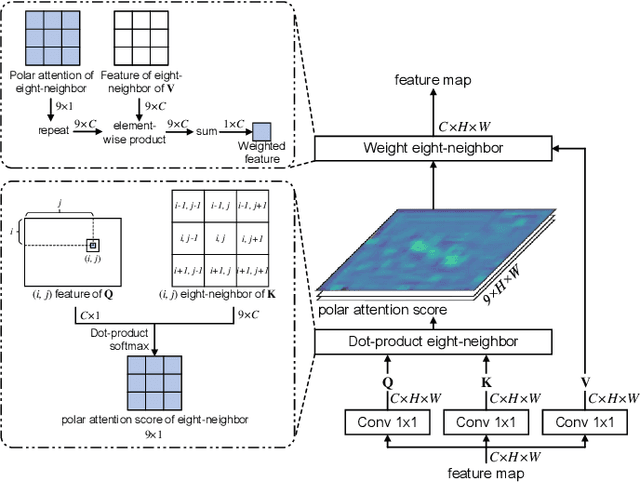
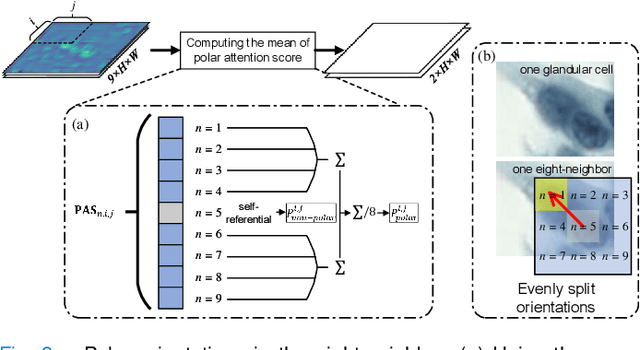
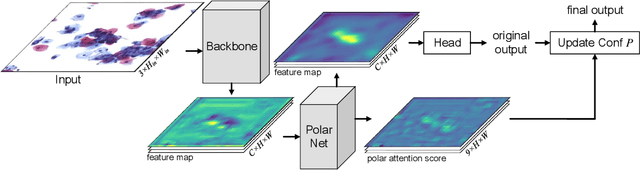
Cervical glandular cell (GC) detection is a key step in computer-aided diagnosis for cervical adenocarcinomas screening. It is challenging to accurately recognize GCs in cervical smears in which squamous cells are the major. Widely existing Out-Of-Distribution (OOD) data in the entire smear leads decreasing reliability of machine learning system for GC detection. Although, the State-Of-The-Art (SOTA) deep learning model can outperform pathologists in preselected regions of interest, the mass False Positive (FP) prediction with high probability is still unsolved when facing such gigapixel whole slide image. This paper proposed a novel PolarNet based on the morphological prior knowledge of GC trying to solve the FP problem via a self-attention mechanism in eight-neighbor. It estimates the polar orientation of nucleus of GC. As a plugin module, PolarNet can guide the deep feature and predicted confidence of general object detection models. In experiments, we discovered that general models based on four different frameworks can reject FP in small image set and increase the mean of average precision (mAP) by $\text{0.007}\sim\text{0.015}$ in average, where the highest exceeds the recent cervical cell detection model 0.037. By plugging PolarNet, the deployed C++ program improved by 8.8\% on accuracy of top-20 GC detection from external WSIs, while sacrificing 14.4 s of computational time. Code is available in https://github.com/Chrisa142857/PolarNet-GCdet
Explainable nonlinear modelling of multiple time series with invertible neural networks
Jul 01, 2021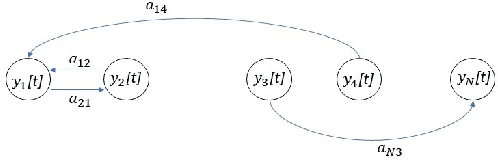
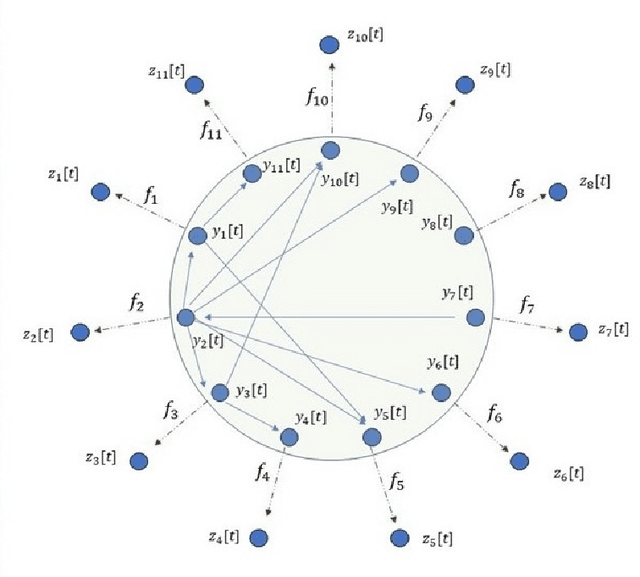
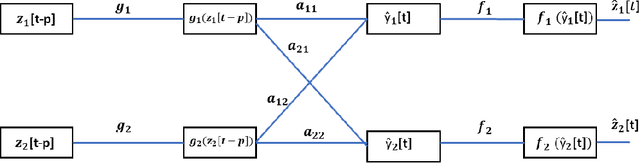
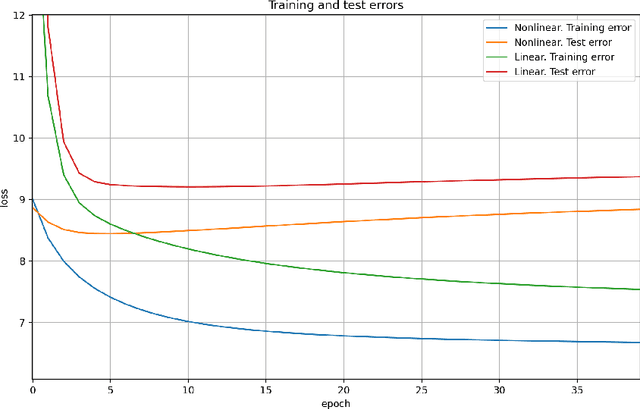
A method for nonlinear topology identification is proposed, based on the assumption that a collection of time series are generated in two steps: i) a vector autoregressive process in a latent space, and ii) a nonlinear, component-wise, monotonically increasing observation mapping. The latter mappings are assumed invertible, and are modelled as shallow neural networks, so that their inverse can be numerically evaluated, and their parameters can be learned using a technique inspired in deep learning. Due to the function inversion, the back-propagation step is not straightforward, and this paper explains the steps needed to calculate the gradients applying implicit differentiation. Whereas the model explainability is the same as that for linear VAR processes, preliminary numerical tests show that the prediction error becomes smaller.
Learning Purely Tactile In-Hand Manipulation with a Torque-Controlled Hand
Apr 12, 2022

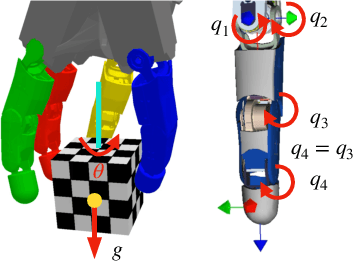
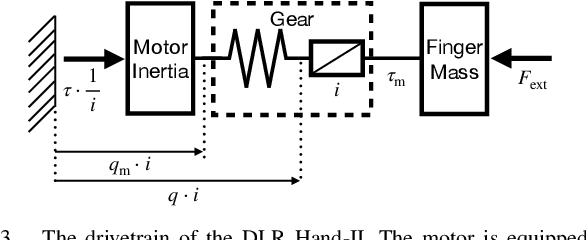
We show that a purely tactile dextrous in-hand manipulation task with continuous regrasping, requiring permanent force closure, can be learned from scratch and executed robustly on a torque-controlled humanoid robotic hand. The task is rotating a cube without dropping it, but in contrast to OpenAI's seminal cube manipulation task, the palm faces downwards and no cameras but only the hand's position and torque sensing are used. Although the task seems simple, it combines for the first time all the challenges in execution as well as learning that are important for using in-hand manipulation in real-world applications. We efficiently train in a precisely modeled and identified rigid body simulation with off-policy deep reinforcement learning, significantly sped up by a domain adapted curriculum, leading to a moderate 600 CPU hours of training time. The resulting policy is robustly transferred to the real humanoid DLR Hand-II, e.g., reaching more than 46 full 2${\pi}$ rotations of the cube in a single run and allowing for disturbances like different cube sizes, hand orientation, or pulling a finger.