 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Synthetic Point Cloud Generation for Class Segmentation Applications
May 07, 2022




Maintenance of industrial facilities is a growing hazard due to the cumbersome process needed to identify infrastructure degradation. Digital Twins have the potential to improve maintenance by monitoring the continuous digital representation of infrastructure. However, the time needed to map the existing geometry makes their use prohibitive. We previously developed class segmentation algorithms to automate digital twinning, however a vast amount of annotated point clouds is needed. Currently, synthetic data generation for automated segmentation is non-existent. We used Helios++ to automatically segment point clouds from 3D models. Our research has the potential to pave the ground for efficient industrial class segmentation.
Rectify ViT Shortcut Learning by Visual Saliency
Jun 17, 2022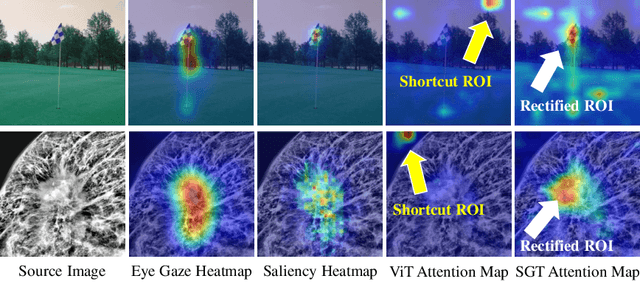
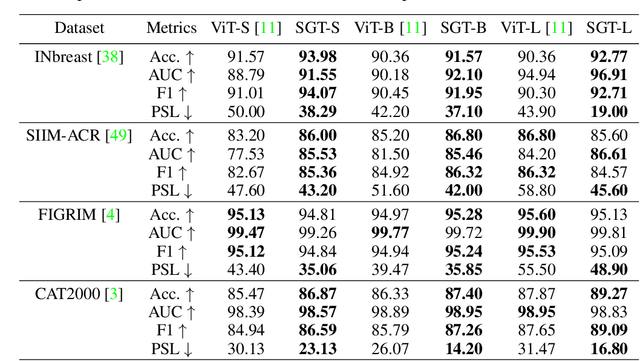
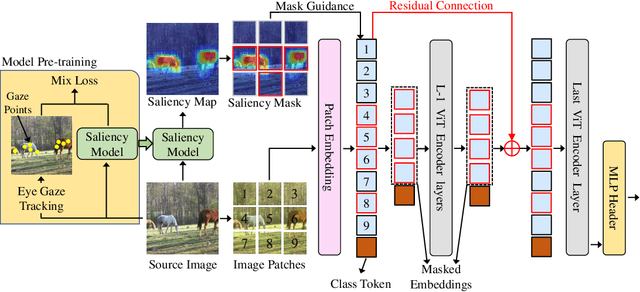
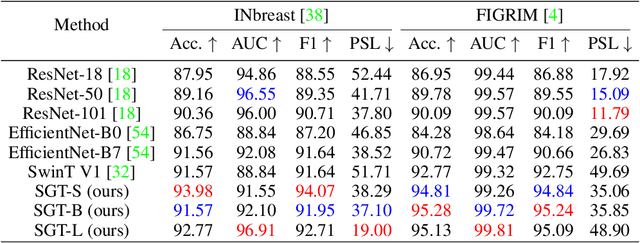
Shortcut learning is common but harmful to deep learning models, leading to degenerated feature representations and consequently jeopardizing the model's generalizability and interpretability. However, shortcut learning in the widely used Vision Transformer framework is largely unknown. Meanwhile, introducing domain-specific knowledge is a major approach to rectifying the shortcuts, which are predominated by background related factors. For example, in the medical imaging field, eye-gaze data from radiologists is an effective human visual prior knowledge that has the great potential to guide the deep learning models to focus on meaningful foreground regions of interest. However, obtaining eye-gaze data is time-consuming, labor-intensive and sometimes even not practical. In this work, we propose a novel and effective saliency-guided vision transformer (SGT) model to rectify shortcut learning in ViT with the absence of eye-gaze data. Specifically, a computational visual saliency model is adopted to predict saliency maps for input image samples. Then, the saliency maps are used to distil the most informative image patches. In the proposed SGT, the self-attention among image patches focus only on the distilled informative ones. Considering this distill operation may lead to global information lost, we further introduce, in the last encoder layer, a residual connection that captures the self-attention across all the image patches. The experiment results on four independent public datasets show that our SGT framework can effectively learn and leverage human prior knowledge without eye gaze data and achieves much better performance than baselines. Meanwhile, it successfully rectifies the harmful shortcut learning and significantly improves the interpretability of the ViT model, demonstrating the promise of transferring human prior knowledge derived visual saliency in rectifying shortcut learning
Confidence-Guided Unsupervised Domain Adaptation for Cerebellum Segmentation
Jun 14, 2022
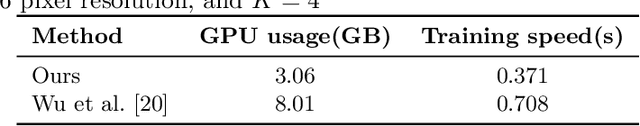
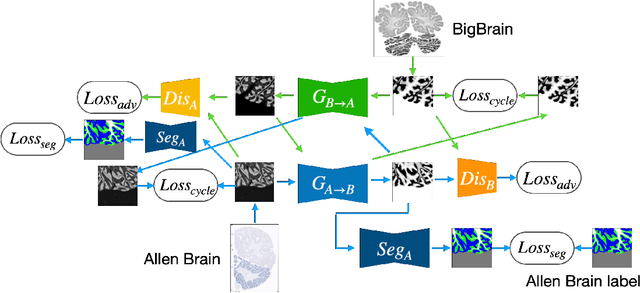
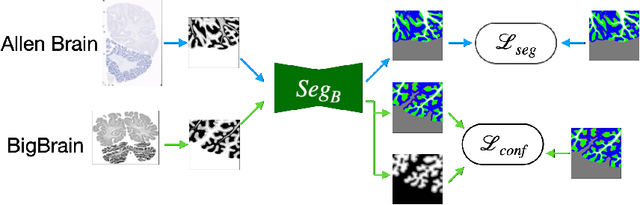
The lack of a comprehensive high-resolution atlas of the cerebellum has hampered studies of cerebellar involvement in normal brain function and disease. A good representation of the tightly foliated aspect of the cerebellar cortex is difficult to achieve because of the highly convoluted surface and the time it would take for manual delineation. The quality of manual segmentation is influenced by human expert judgment, and automatic labelling is constrained by the limited robustness of existing segmentation algorithms. The 20umisotropic BigBrain dataset provides an unprecedented high resolution framework for semantic segmentation compared to the 1000um(1mm) resolution afforded by magnetic resonance imaging. To dispense with the manual annotation requirement, we propose to train a model to adaptively transfer the annotation from the cerebellum on the Allen Brain Human Brain Atlas to the BigBrain in an unsupervised manner, taking into account the different staining and spacing between sections. The distinct visual discrepancy between the Allen Brain and BigBrain prevents existing approaches to provide meaningful segmentation masks, and artifacts caused by sectioning and histological slice preparation in the BigBrain data pose an extra challenge. To address these problems, we propose a two-stage framework where we first transfer the Allen Brain cerebellum to a space sharing visual similarity with the BigBrain. We then introduce a self-training strategy with a confidence map to guide the model learning from the noisy pseudo labels iteratively. Qualitative results validate the effectiveness of our approach, and quantitative experiments reveal that our method can achieve over 2.6% loss reduction compared with other approaches.
Ultra-low Latency Spiking Neural Networks with Spatio-Temporal Compression and Synaptic Convolutional Block
Mar 18, 2022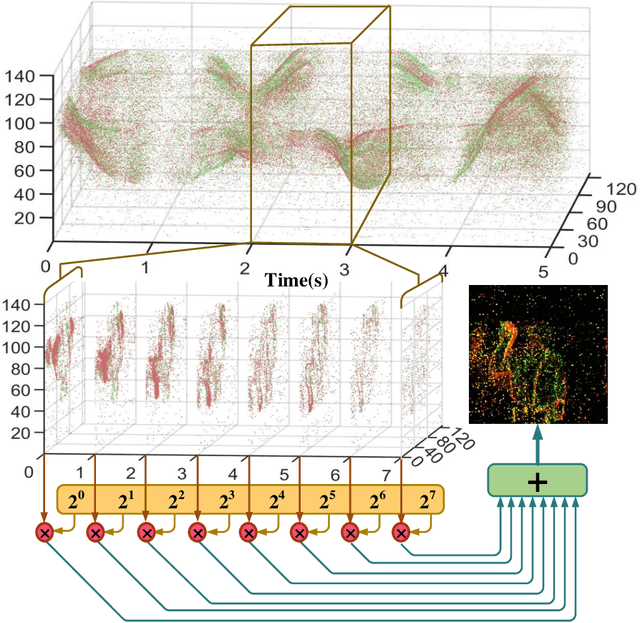
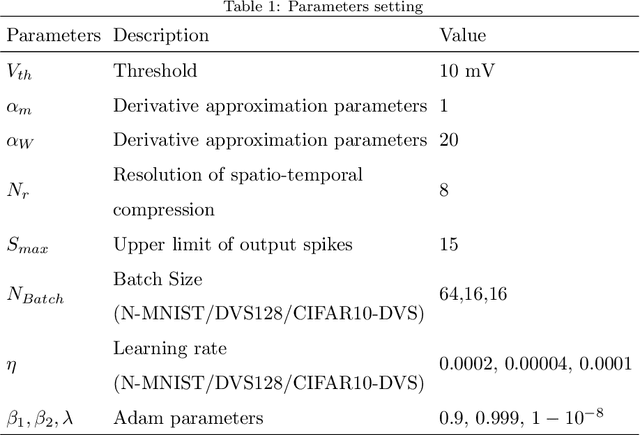
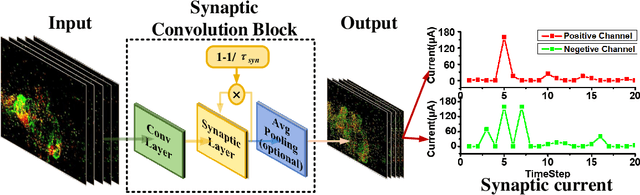
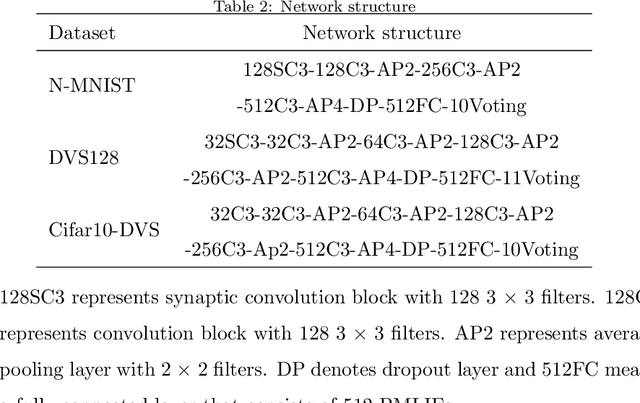
Spiking neural networks (SNNs), as one of the brain-inspired models, has spatio-temporal information processing capability, low power feature, and high biological plausibility. The effective spatio-temporal feature makes it suitable for event streams classification. However, neuromorphic datasets, such as N-MNIST, CIFAR10-DVS, DVS128-gesture, need to aggregate individual events into frames with a new higher temporal resolution for event stream classification, which causes high training and inference latency. In this work, we proposed a spatio-temporal compression method to aggregate individual events into a few time steps of synaptic current to reduce the training and inference latency. To keep the accuracy of SNNs under high compression ratios, we also proposed a synaptic convolutional block to balance the dramatic change between adjacent time steps. And multi-threshold Leaky Integrate-and-Fire (LIF) with learnable membrane time constant is introduced to increase its information processing capability. We evaluate the proposed method for event streams classification tasks on neuromorphic N-MNIST, CIFAR10-DVS, DVS128 gesture datasets. The experiment results show that our proposed method outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps.
Machine learning method for return direction forecasting of Exchange Traded Funds using classification and regression models
May 25, 2022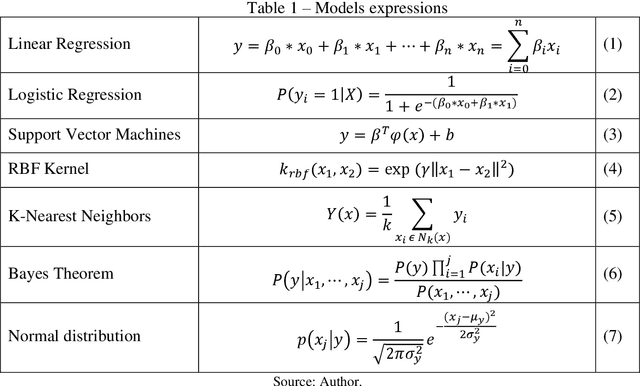
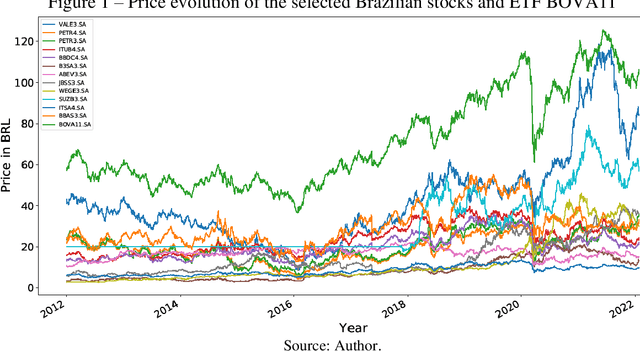

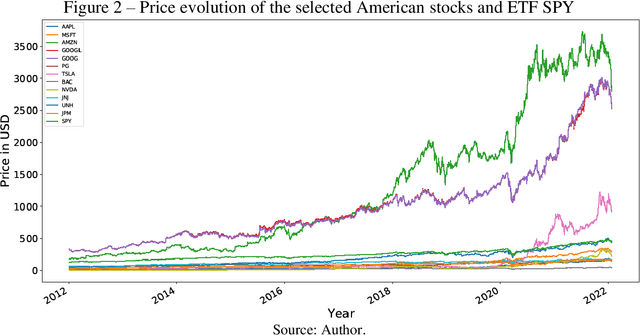
This article aims to propose and apply a machine learning method to analyze the direction of returns from Exchange Traded Funds (ETFs) using the historical return data of its components, helping to make investment strategy decisions through a trading algorithm. In methodological terms, regression and classification models were applied, using standard datasets from Brazilian and American markets, in addition to algorithmic error metrics. In terms of research results, they were analyzed and compared to those of the Na\"ive forecast and the returns obtained by the buy & hold technique in the same period of time. In terms of risk and return, the models mostly performed better than the control metrics, with emphasis on the linear regression model and the classification models by logistic regression, support vector machine (using the LinearSVC model), Gaussian Naive Bayes and K-Nearest Neighbors, where in certain datasets the returns exceeded by two times and the Sharpe ratio by up to four times those of the buy & hold control model.
Urban Road Safety Prediction: A Satellite Navigation Perspective
Jun 08, 2022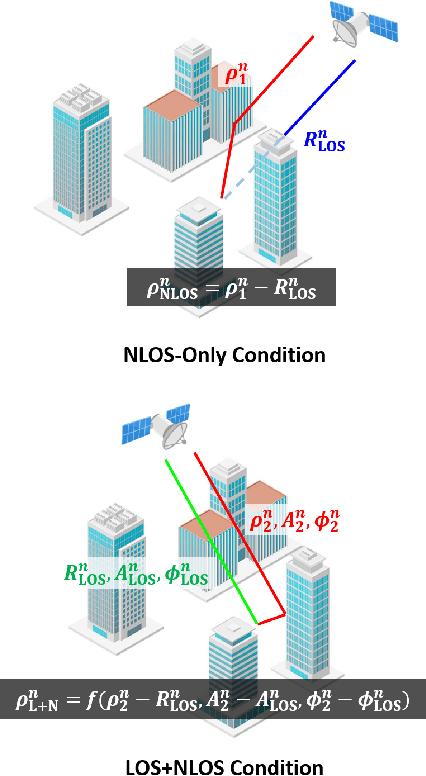
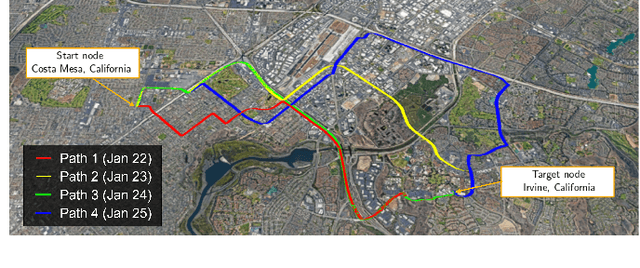
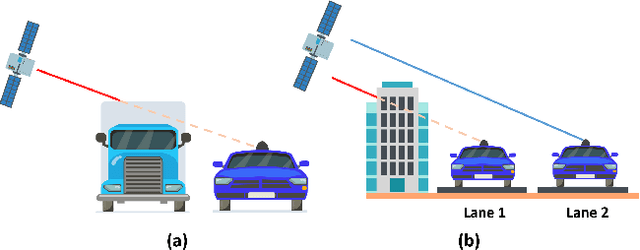
Predicting the safety of urban roads for navigation via global navigation satellite systems (GNSS) signals is considered. To ensure safe driving of automated vehicles, the vehicle must plan its trajectory to avoid navigating on unsafe roads (e.g., icy conditions, construction zones, narrow streets, etc.). Such information can be derived from the roads' physical properties, vehicle's capabilities, and weather conditions. From a GNSS-based navigation perspective, the reliability of GNSS signals in different locales, which is heavily dependent on the road layout within the surrounding environment, is crucial to ensure safe automated driving. An urban road environment surrounded by tall objects can significantly degrade the accuracy and availability of GNSS signals. This article proposes an approach to predict the reliability of GNSS-based navigation to ensure safe urban navigation. Satellite navigation reliability at a given location and time on a road is determined based on the probabilistic position error bound of the vehicle-mounted GNSS receiver. A metric for GNSS reliability for ground vehicles is suggested, and a method to predict the conservative probabilistic error bound of the GNSS navigation solution is proposed. A satellite navigation reliability map is generated for various navigation applications. As a case study, the reliability map is used in the proposed optimization problem formulation for automated ground vehicle safety-constrained path planning.
Can pruning improve certified robustness of neural networks?
Jun 17, 2022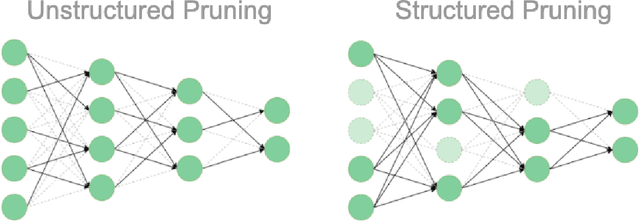
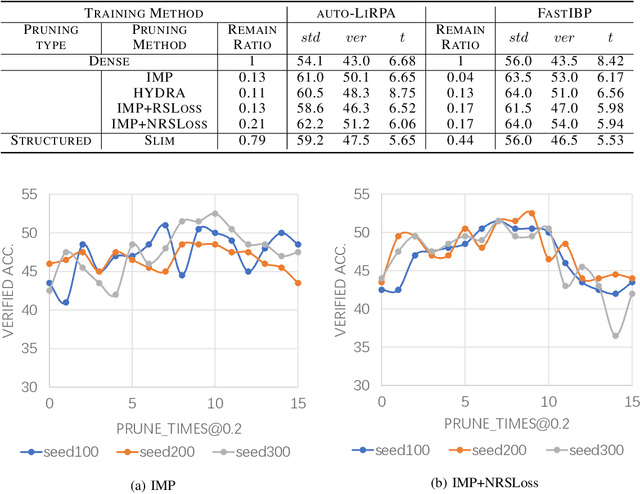
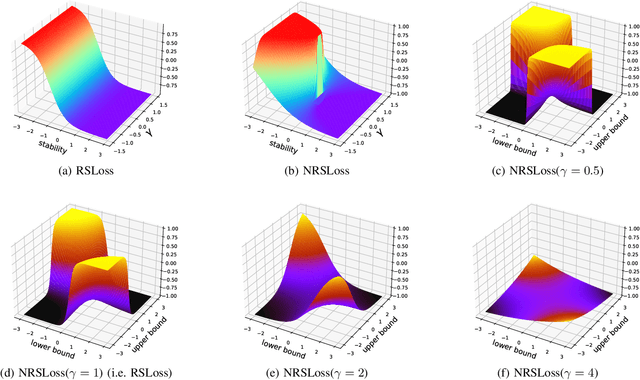
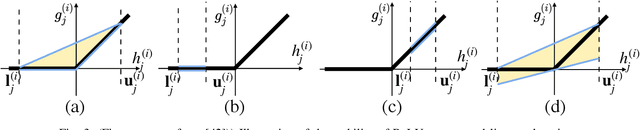
With the rapid development of deep learning, the sizes of neural networks become larger and larger so that the training and inference often overwhelm the hardware resources. Given the fact that neural networks are often over-parameterized, one effective way to reduce such computational overhead is neural network pruning, by removing redundant parameters from trained neural networks. It has been recently observed that pruning can not only reduce computational overhead but also can improve empirical robustness of deep neural networks (NNs), potentially owing to removing spurious correlations while preserving the predictive accuracies. This paper for the first time demonstrates that pruning can generally improve certified robustness for ReLU-based NNs under the complete verification setting. Using the popular Branch-and-Bound (BaB) framework, we find that pruning can enhance the estimated bound tightness of certified robustness verification, by alleviating linear relaxation and sub-domain split problems. We empirically verify our findings with off-the-shelf pruning methods and further present a new stability-based pruning method tailored for reducing neuron instability, that outperforms existing pruning methods in enhancing certified robustness. Our experiments show that by appropriately pruning an NN, its certified accuracy can be boosted up to 8.2% under standard training, and up to 24.5% under adversarial training on the CIFAR10 dataset. We additionally observe the existence of certified lottery tickets that can match both standard and certified robust accuracies of the original dense models across different datasets. Our findings offer a new angle to study the intriguing interaction between sparsity and robustness, i.e. interpreting the interaction of sparsity and certified robustness via neuron stability. Codes are available at: https://github.com/VITA-Group/CertifiedPruning.
Compositional Visual Generation with Composable Diffusion Models
Jun 08, 2022
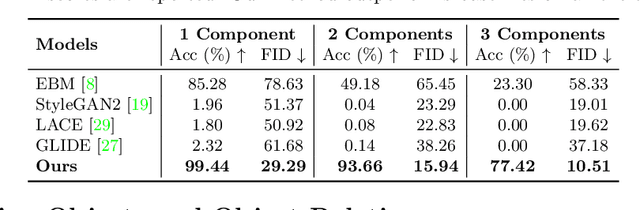

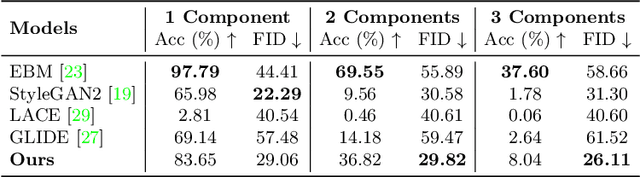
Large text-guided diffusion models, such as DALLE-2, are able to generate stunning photorealistic images given natural language descriptions. While such models are highly flexible, they struggle to understand the composition of certain concepts, such as confusing the attributes of different objects or relations between objects. In this paper, we propose an alternative structured approach for compositional generation using diffusion models. An image is generated by composing a set of diffusion models, with each of them modeling a certain component of the image. To do this, we interpret diffusion models as energy-based models in which the data distributions defined by the energy functions may be explicitly combined. The proposed method can generate scenes at test time that are substantially more complex than those seen in training, composing sentence descriptions, object relations, human facial attributes, and even generalizing to new combinations that are rarely seen in the real world. We further illustrate how our approach may be used to compose pre-trained text-guided diffusion models and generate photorealistic images containing all the details described in the input descriptions, including the binding of certain object attributes that have been shown difficult for DALLE-2. These results point to the effectiveness of the proposed method in promoting structured generalization for visual generation. Project page: https://energy-based-model.github.io/Compositional-Visual-Generation-with-Composable-Diffusion-Models/
Efficient and practical quantum compiler towards multi-qubit systems with deep reinforcement learning
Apr 14, 2022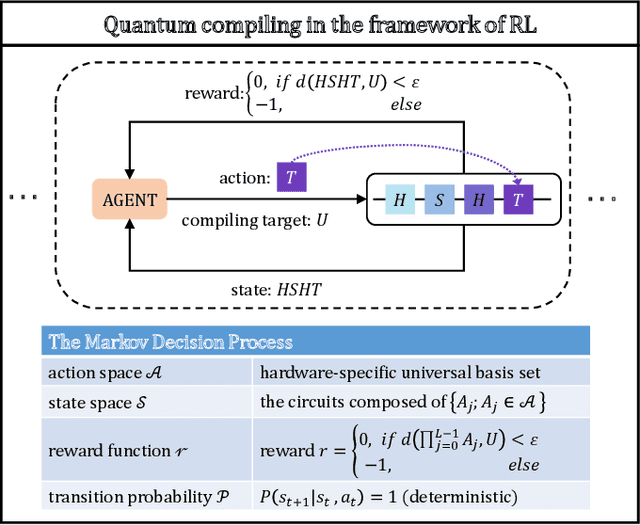
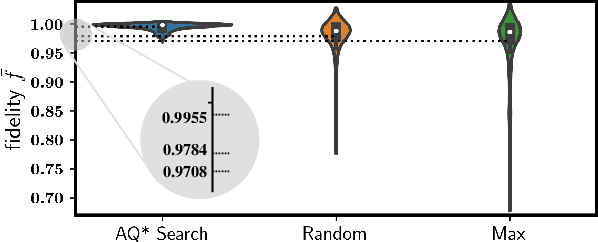
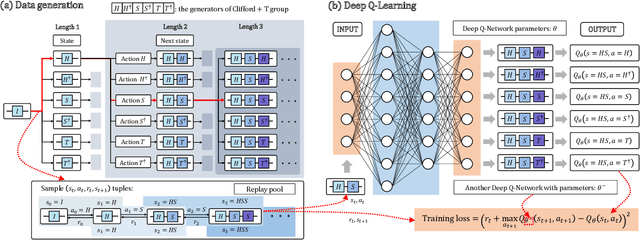
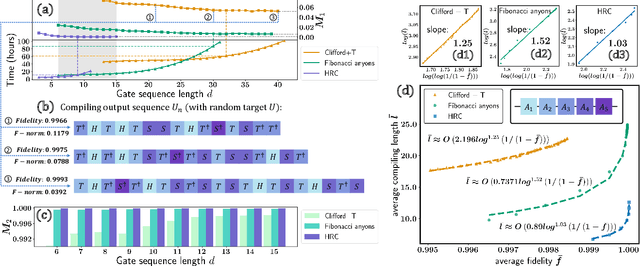
Efficient quantum compiling tactics greatly enhance the capability of quantum computers to execute complicated quantum algorithms. Due to its fundamental importance, a plethora of quantum compilers has been designed in past years. However, there are several caveats to current protocols, which are low optimality, high inference time, limited scalability, and lack of universality. To compensate for these defects, here we devise an efficient and practical quantum compiler assisted by advanced deep reinforcement learning (RL) techniques, i.e., data generation, deep Q-learning, and AQ* search. In this way, our protocol is compatible with various quantum machines and can be used to compile multi-qubit operators. We systematically evaluate the performance of our proposal in compiling quantum operators with both inverse-closed and inverse-free universal basis sets. In the task of single-qubit operator compiling, our proposal outperforms other RL-based quantum compilers in the measure of compiling sequence length and inference time. Meanwhile, the output solution is near-optimal, guaranteed by the Solovay-Kitaev theorem. Notably, for the inverse-free universal basis set, the achieved sequence length complexity is comparable with the inverse-based setting and dramatically advances previous methods. These empirical results contribute to improving the inverse-free Solovay-Kitaev theorem. In addition, for the first time, we demonstrate how to leverage RL-based quantum compilers to accomplish two-qubit operator compiling. The achieved results open an avenue for integrating RL with quantum compiling to unify efficiency and practicality and thus facilitate the exploration of quantum advantages.
Fully Automated Assessment of Cardiac Coverage in Cine Cardiovascular Magnetic Resonance Images using an Explainable Deep Visual Salient Region Detection Model
Jun 14, 2022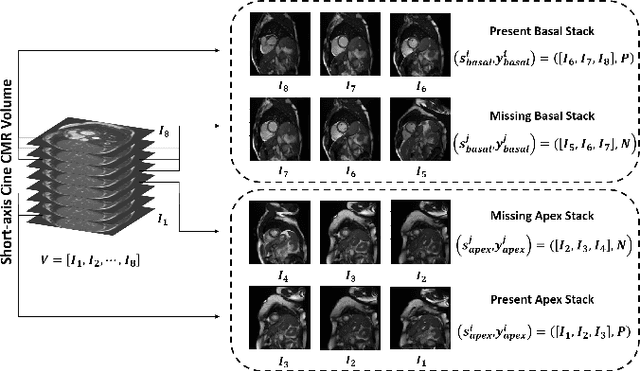

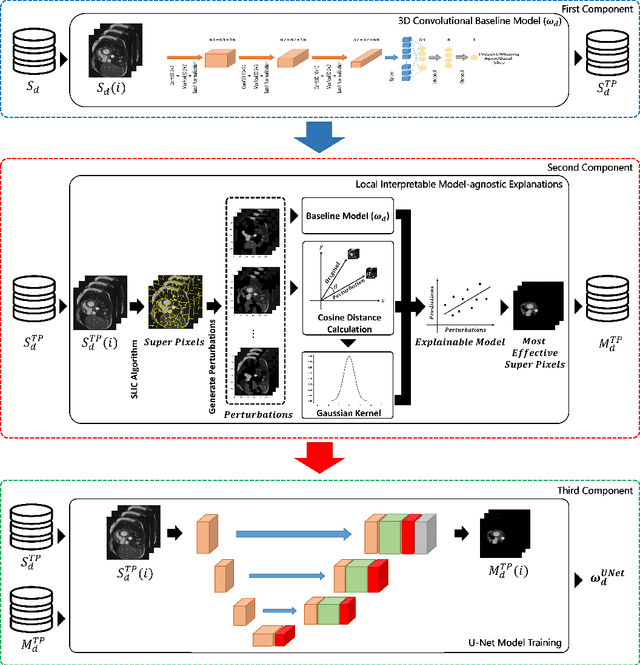
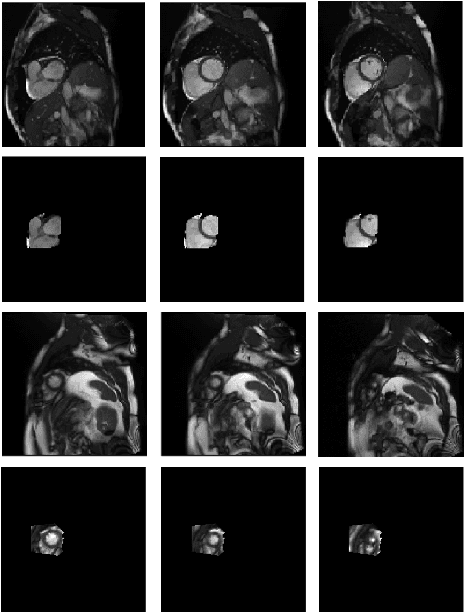
Cardiovascular magnetic resonance (CMR) imaging has become a modality with superior power for the diagnosis and prognosis of cardiovascular diseases. One of the essential basic quality controls of CMR images is to investigate the complete cardiac coverage, which is necessary for the volumetric and functional assessment. This study examines the full cardiac coverage using a 3D convolutional model and then reduces the number of false predictions using an innovative salient region detection model. Salient regions are extracted from the short-axis cine CMR stacks using a three-step proposed algorithm. Combining the 3D CNN baseline model with the proposed salient region detection model provides a cascade detector that can reduce the number of false negatives of the baseline model. The results obtained on the images of over 6,200 participants of the UK Biobank population cohort study show the superiority of the proposed model over the previous state-of-the-art studies. The dataset is the largest regarding the number of participants to control the cardiac coverage. The accuracy of the baseline model in identifying the presence/absence of basal/apical slices is 96.25\% and 94.51\%, respectively, which increases to 96.88\% and 95.72\% after improving using the proposed salient region detection model. Using the salient region detection model by forcing the baseline model to focus on the most informative areas of the images can help the model correct misclassified samples' predictions. The proposed fully automated model's performance indicates that this model can be used in image quality control in population cohort datasets and also real-time post-imaging quality assessments.