 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning from All Vehicles
Apr 13, 2022
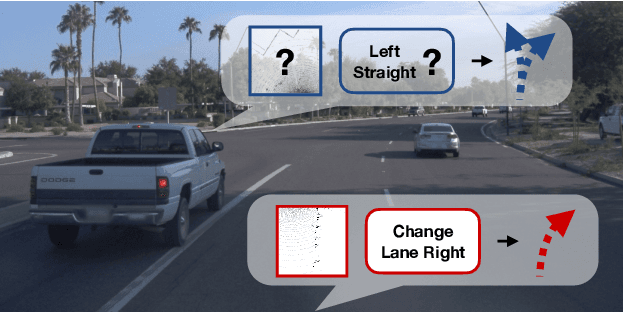
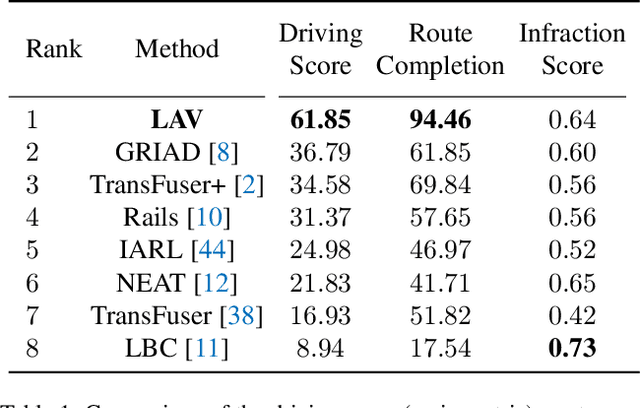
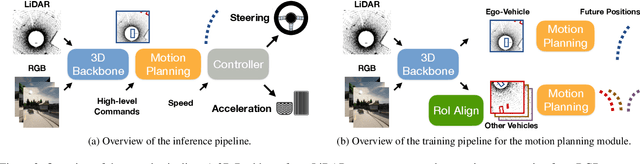

In this paper, we present a system to train driving policies from experiences collected not just from the ego-vehicle, but all vehicles that it observes. This system uses the behaviors of other agents to create more diverse driving scenarios without collecting additional data. The main difficulty in learning from other vehicles is that there is no sensor information. We use a set of supervisory tasks to learn an intermediate representation that is invariant to the viewpoint of the controlling vehicle. This not only provides a richer signal at training time but also allows more complex reasoning during inference. Learning how all vehicles drive helps predict their behavior at test time and can avoid collisions. We evaluate this system in closed-loop driving simulations. Our system outperforms all prior methods on the public CARLA Leaderboard by a wide margin, improving driving score by 25 and route completion rate by 24 points. Our method won the 2021 CARLA Autonomous Driving challenge. Code and data are available at https://github.com/dotchen/LAV.
Weakly-supervised segmentation using inherently-explainable classification models and their application to brain tumour classification
Jun 10, 2022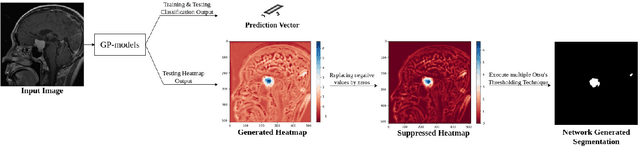
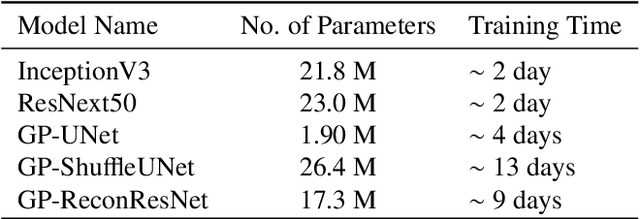
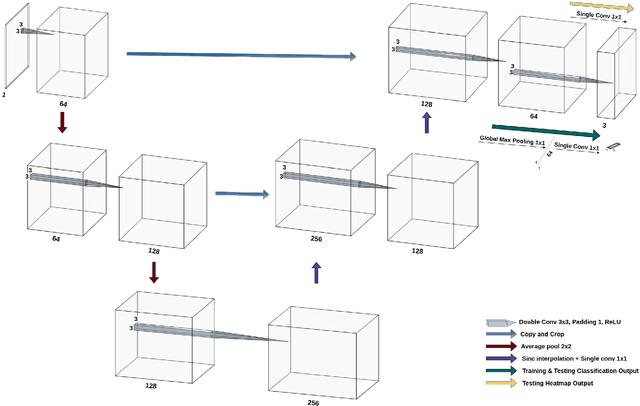

Deep learning models have shown their potential for several applications. However, most of the models are opaque and difficult to trust due to their complex reasoning - commonly known as the black-box problem. Some fields, such as medicine, require a high degree of transparency to accept and adopt such technologies. Consequently, creating explainable/interpretable models or applying post-hoc methods on classifiers to build trust in deep learning models are required. Moreover, deep learning methods can be used for segmentation tasks, which typically require hard-to-obtain, time-consuming manually-annotated segmentation labels for training. This paper introduces three inherently-explainable classifiers to tackle both of these problems as one. The localisation heatmaps provided by the networks -- representing the models' focus areas and being used in classification decision-making -- can be directly interpreted, without requiring any post-hoc methods to derive information for model explanation. The models are trained by using the input image and only the classification labels as ground-truth in a supervised fashion - without using any information about the location of the region of interest (i.e. the segmentation labels), making the segmentation training of the models weakly-supervised through classification labels. The final segmentation is obtained by thresholding these heatmaps. The models were employed for the task of multi-class brain tumour classification using two different datasets, resulting in the best F1-score of 0.93 for the supervised classification task while securing a median Dice score of 0.67$\pm$0.08 for the weakly-supervised segmentation task. Furthermore, the obtained accuracy on a subset of tumour-only images outperformed the state-of-the-art glioma tumour grading binary classifiers with the best model achieving 98.7\% accuracy.
Conversation Group Detection With Spatio-Temporal Context
Jun 02, 2022
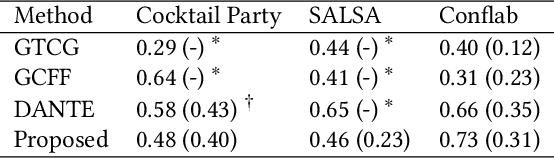

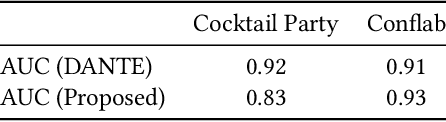
In this work, we propose an approach for detecting conversation groups in social scenarios like cocktail parties and networking events, from overhead camera recordings. We posit the detection of conversation groups as a learning problem that could benefit from leveraging the spatial context of the surroundings, and the inherent temporal context in interpersonal dynamics which is reflected in the temporal dynamics in human behavior signals, an aspect that has not been addressed in recent prior works. This motivates our approach which consists of a dynamic LSTM-based deep learning model that predicts continuous pairwise affinity values indicating how likely two people are in the same conversation group. These affinity values are also continuous in time, since relationships and group membership do not occur instantaneously, even though the ground truths of group membership are binary. Using the predicted affinity values, we apply a graph clustering method based on Dominant Set extraction to identify the conversation groups. We benchmark the proposed method against established methods on multiple social interaction datasets. Our results showed that the proposed method improves group detection performance in data that has more temporal granularity in conversation group labels. Additionally, we provide an analysis in the predicted affinity values in relation to the conversation group detection. Finally, we demonstrate the usability of the predicted affinity values in a forecasting framework to predict group membership for a given forecast horizon.
PSEUDo: Interactive Pattern Search in Multivariate Time Series with Locality-Sensitive Hashing and Relevance Feedback
May 10, 2021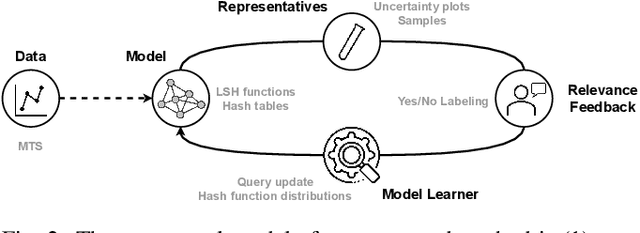
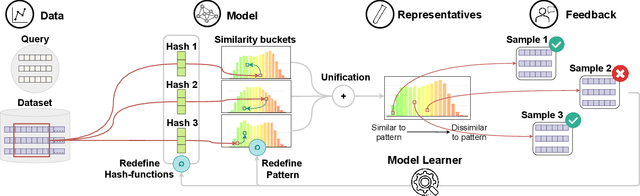
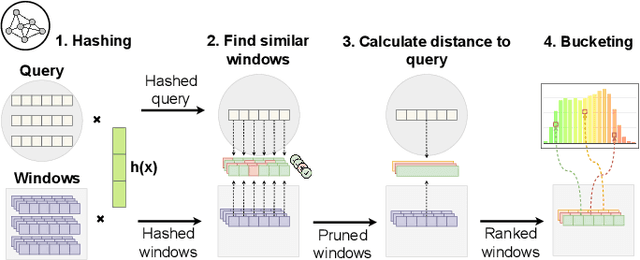
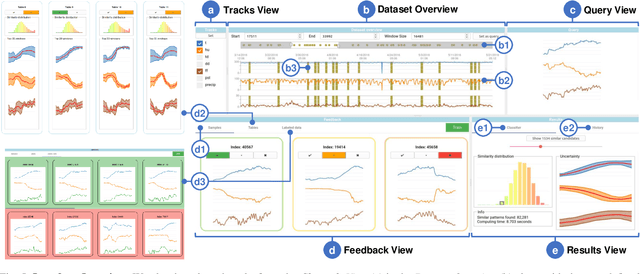
We present PSEUDo, an adaptive feature learning technique for exploring visual patterns in multi-track sequential data. Our approach is designed with the primary focus to overcome the uneconomic retraining requirements and inflexible representation learning in current deep learning-based systems. Multi-track time series data are generated on an unprecedented scale due to increased sensors and data storage. These datasets hold valuable patterns, like in neuromarketing, where researchers try to link patterns in multivariate sequential data from physiological sensors to the purchase behavior of products and services. But a lack of ground truth and high variance make automatic pattern detection unreliable. Our advancements are based on a novel query-aware locality-sensitive hashing technique to create a feature-based representation of multivariate time series windows. Most importantly, our algorithm features sub-linear training and inference time. We can even accomplish both the modeling and comparison of 10,000 different 64-track time series, each with 100 time steps (a typical EEG dataset) under 0.8 seconds. This performance gain allows for a rapid relevance feedback-driven adaption of the underlying pattern similarity model and enables the user to modify the speed-vs-accuracy trade-off gradually. We demonstrate superiority of PSEUDo in terms of efficiency, accuracy, and steerability through a quantitative performance comparison and a qualitative visual quality comparison to the state-of-the-art algorithms in the field. Moreover, we showcase the usability of PSEUDo through a case study demonstrating our visual pattern retrieval concepts in a large meteorological dataset. We find that our adaptive models can accurately capture the user's notion of similarity and allow for an understandable exploratory visual pattern retrieval in large multivariate time series datasets.
On Elimination Strategies for Bandit Fixed-Confidence Identification
May 22, 2022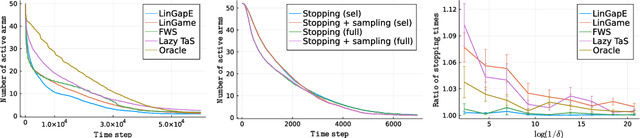
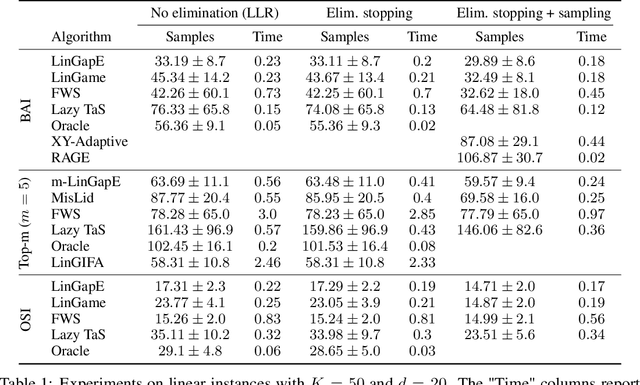
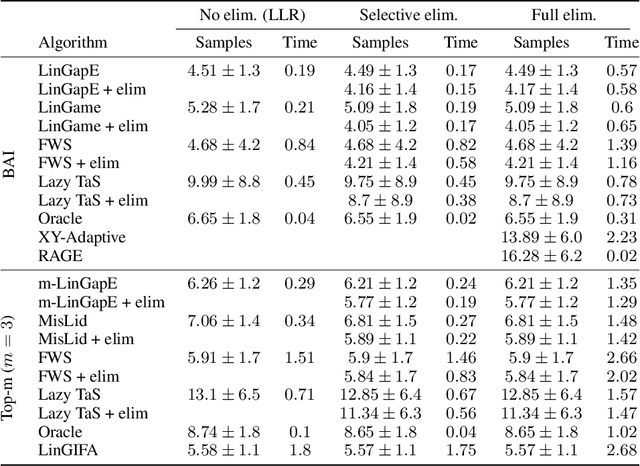
Elimination algorithms for bandit identification, which prune the plausible correct answers sequentially until only one remains, are computationally convenient since they reduce the problem size over time. However, existing elimination strategies are often not fully adaptive (they update their sampling rule infrequently) and are not easy to extend to combinatorial settings, where the set of answers is exponentially large in the problem dimension. On the other hand, most existing fully-adaptive strategies to tackle general identification problems are computationally demanding since they repeatedly test the correctness of every answer, without ever reducing the problem size. We show that adaptive methods can be modified to use elimination in both their stopping and sampling rules, hence obtaining the best of these two worlds: the algorithms (1) remain fully adaptive, (2) suffer a sample complexity that is never worse of their non-elimination counterpart, and (3) provably eliminate certain wrong answers early. We confirm these benefits experimentally, where elimination improves significantly the computational complexity of adaptive methods on common tasks like best-arm identification in linear bandits.
Multi-objective QUBO Solver: Bi-objective Quadratic Assignment
May 26, 2022
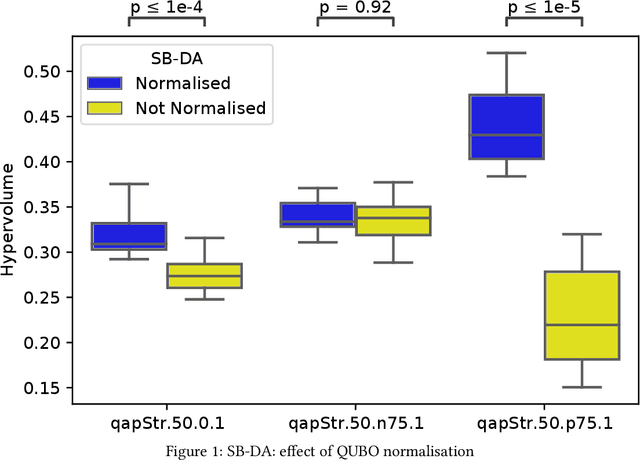
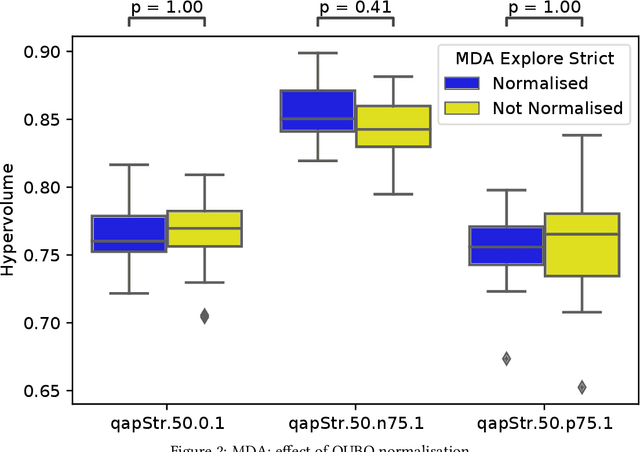

Quantum and quantum-inspired optimisation algorithms are designed to solve problems represented in binary, quadratic and unconstrained form. Combinatorial optimisation problems are therefore often formulated as Quadratic Unconstrained Binary Optimisation Problems (QUBO) to solve them with these algorithms. Moreover, these QUBO solvers are often implemented using specialised hardware to achieve enormous speedups, e.g. Fujitsu's Digital Annealer (DA) and D-Wave's Quantum Annealer. However, these are single-objective solvers, while many real-world problems feature multiple conflicting objectives. Thus, a common practice when using these QUBO solvers is to scalarise such multi-objective problems into a sequence of single-objective problems. Due to design trade-offs of these solvers, formulating each scalarisation may require more time than finding a local optimum. We present the first attempt to extend the algorithm supporting a commercial QUBO solver as a multi-objective solver that is not based on scalarisation. The proposed multi-objective DA algorithm is validated on the bi-objective Quadratic Assignment Problem. We observe that algorithm performance significantly depends on the archiving strategy adopted, and that combining DA with non-scalarisation methods to optimise multiple objectives outperforms the current scalarised version of the DA in terms of final solution quality.
Extending Momentum Contrast with Cross Similarity Consistency Regularization
Jun 07, 2022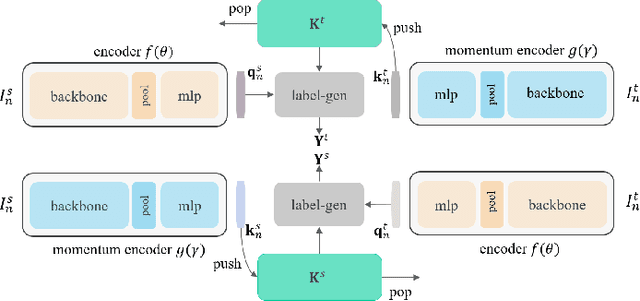
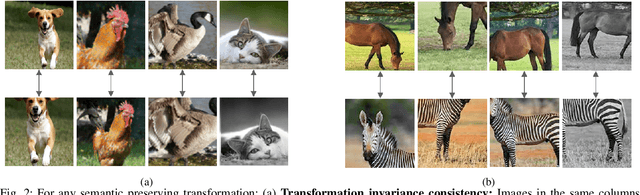
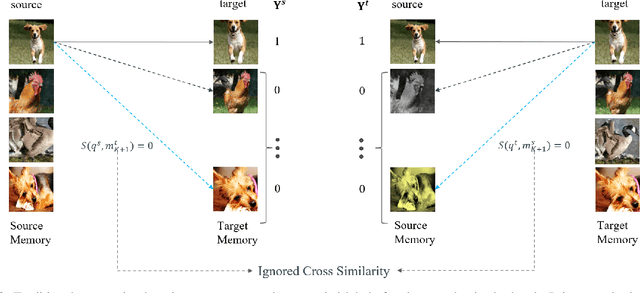
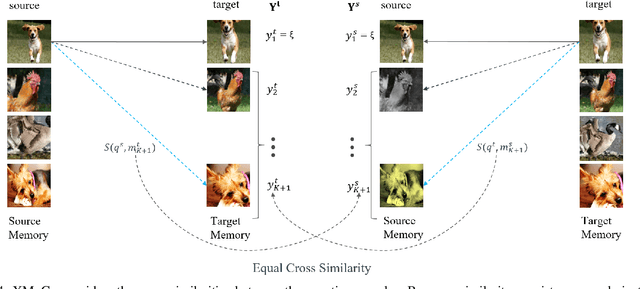
Contrastive self-supervised representation learning methods maximize the similarity between the positive pairs, and at the same time tend to minimize the similarity between the negative pairs. However, in general the interplay between the negative pairs is ignored as they do not put in place special mechanisms to treat negative pairs differently according to their specific differences and similarities. In this paper, we present Extended Momentum Contrast (XMoCo), a self-supervised representation learning method founded upon the legacy of the momentum-encoder unit proposed in the MoCo family configurations. To this end, we introduce a cross consistency regularization loss, with which we extend the transformation consistency to dissimilar images (negative pairs). Under the cross consistency regularization rule, we argue that semantic representations associated with any pair of images (positive or negative) should preserve their cross-similarity under pretext transformations. Moreover, we further regularize the training loss by enforcing a uniform distribution of similarity over the negative pairs across a batch. The proposed regularization can easily be added to existing self-supervised learning algorithms in a plug-and-play fashion. Empirically, we report a competitive performance on the standard Imagenet-1K linear head classification benchmark. In addition, by transferring the learned representations to common downstream tasks, we show that using XMoCo with the prevalently utilized augmentations can lead to improvements in the performance of such tasks. We hope the findings of this paper serve as a motivation for researchers to take into consideration the important interplay among the negative examples in self-supervised learning.
Automatic model training under restrictive time constraints
Apr 21, 2021
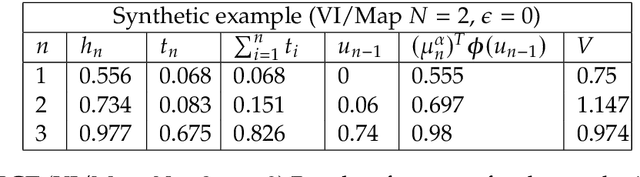

We develop a hyperparameter optimisation algorithm, Automated Budget Constrained Training (AutoBCT), which balances the quality of a model with the computational cost required to tune it. The relationship between hyperparameters, model quality and computational cost must be learnt and this learning is incorporated directly into the optimisation problem. At each training epoch, the algorithm decides whether to terminate or continue training, and, in the latter case, what values of hyperparameters to use. This decision weighs optimally potential improvements in the quality with the additional training time and the uncertainty about the learnt quantities. The performance of our algorithm is verified on a number of machine learning problems encompassing random forests and neural networks. Our approach is rooted in the theory of Markov decision processes with partial information and we develop a numerical method to compute the value function and an optimal strategy.
Analytical Interpretation of Latent Codes in InfoGAN with SAR Images
May 26, 2022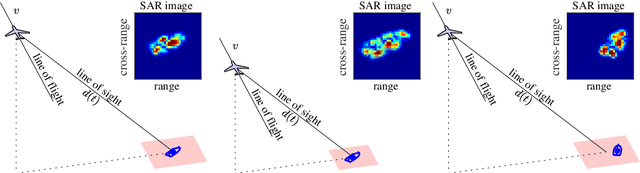
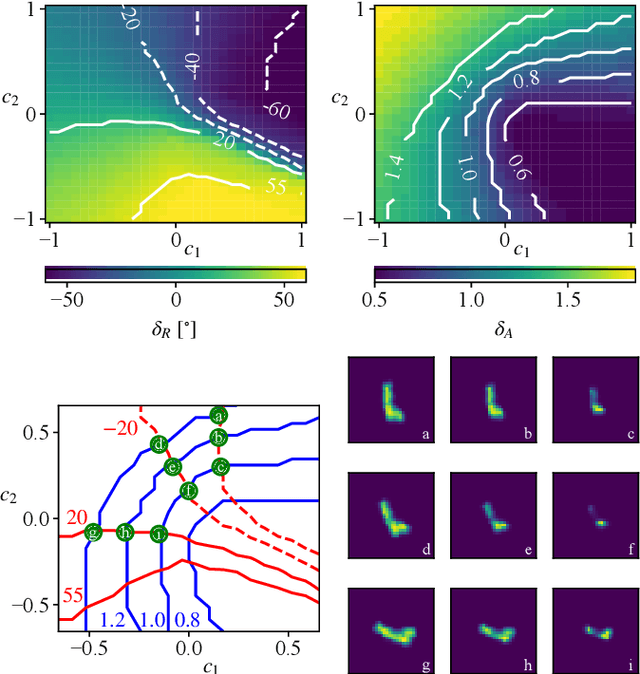
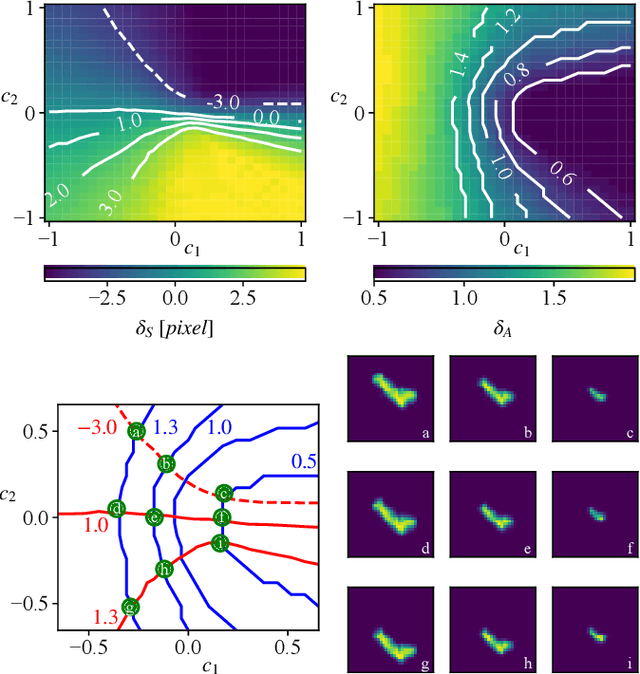
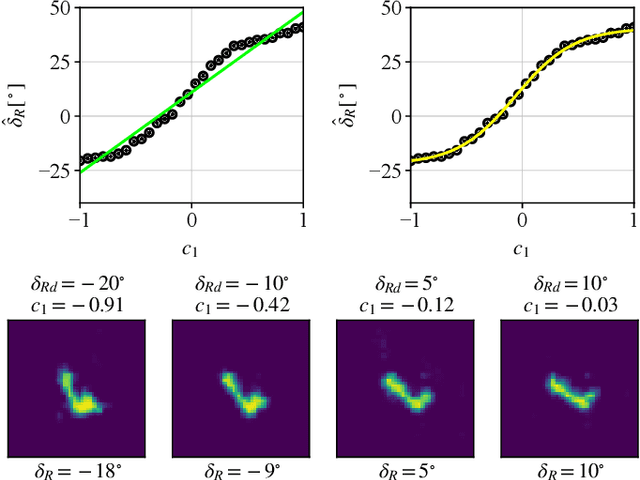
Generative Adversarial Networks (GANs) can synthesize abundant photo-realistic synthetic aperture radar (SAR) images. Some recent GANs (e.g., InfoGAN), are even able to edit specific properties of the synthesized images by introducing latent codes. It is crucial for SAR image synthesis since the targets in real SAR images are with different properties due to the imaging mechanism. Despite the success of InfoGAN in manipulating properties, there still lacks a clear explanation of how these latent codes affect synthesized properties, thus editing specific properties usually relies on empirical trials, unreliable and time-consuming. In this paper, we show that latent codes are disentangled to affect the properties of SAR images in a non-linear manner. By introducing some property estimators for latent codes, we are able to provide a completely analytical nonlinear model to decompose the entangled causality between latent codes and different properties. The qualitative and quantitative experimental results further reveal that the properties can be calculated by latent codes, inversely, the satisfying latent codes can be estimated given desired properties. In this case, properties can be manipulated by latent codes as we expect.
FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation
May 29, 2022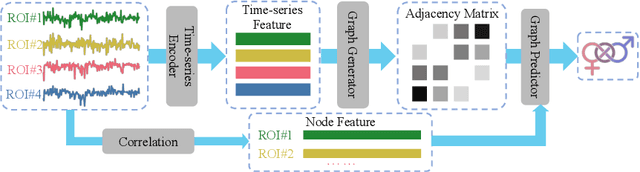
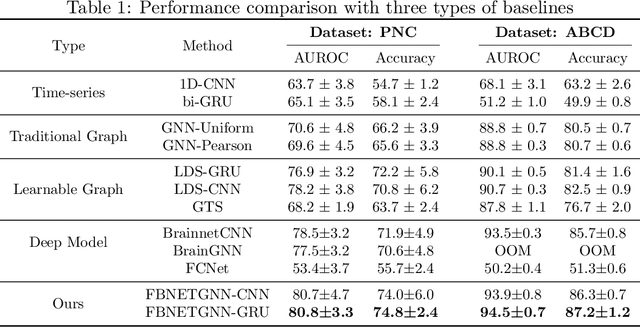

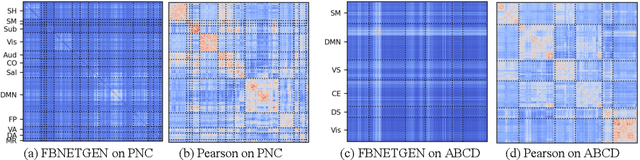
Functional magnetic resonance imaging (fMRI) is one of the most common imaging modalities to investigate brain functions. Recent studies in neuroscience stress the great potential of functional brain networks constructed from fMRI data for clinical predictions. Traditional functional brain networks, however, are noisy and unaware of downstream prediction tasks, while also incompatible with the deep graph neural network (GNN) models. In order to fully unleash the power of GNNs in network-based fMRI analysis, we develop FBNETGEN, a task-aware and interpretable fMRI analysis framework via deep brain network generation. In particular, we formulate (1) prominent region of interest (ROI) features extraction, (2) brain networks generation, and (3) clinical predictions with GNNs, in an end-to-end trainable model under the guidance of particular prediction tasks. Along with the process, the key novel component is the graph generator which learns to transform raw time-series features into task-oriented brain networks. Our learnable graphs also provide unique interpretations by highlighting prediction-related brain regions. Comprehensive experiments on two datasets, i.e., the recently released and currently largest publicly available fMRI dataset Adolescent Brain Cognitive Development (ABCD), and the widely-used fMRI dataset PNC, prove the superior effectiveness and interpretability of FBNETGEN. The implementation is available at https://github.com/Wayfear/FBNETGEN.