 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Reversal Symmetric ODE Network
Jul 22, 2020
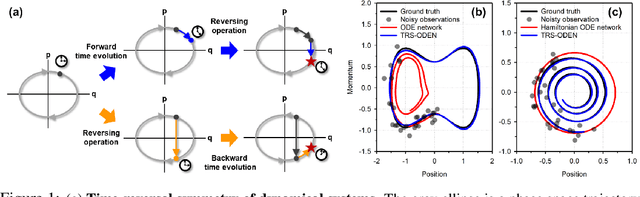
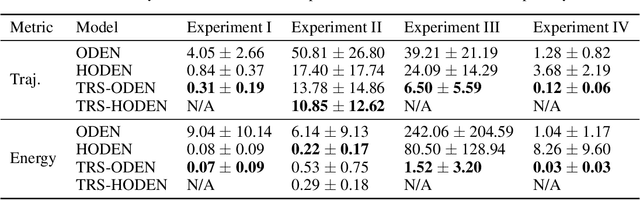
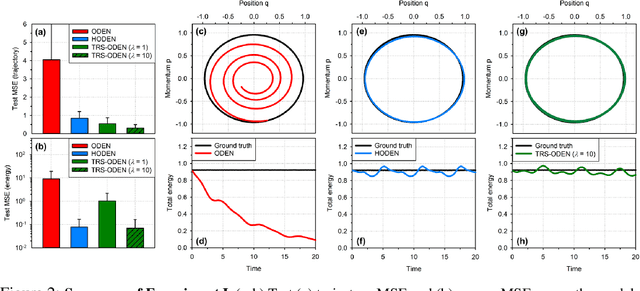
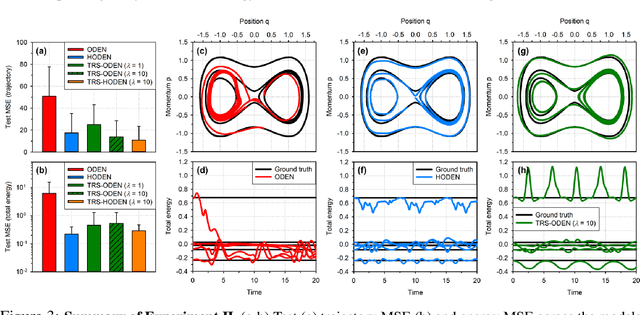
Time-reversal symmetry, which requires that the dynamics of a system should not change with the reversal of time axis, is a fundamental property that frequently holds in classical and quantum mechanics. In this paper, we propose a novel loss function that measures how well our ordinary differential equation (ODE) networks comply with this time-reversal symmetry; it is formally defined by the discrepancy in the time evolution of ODE networks between forward and backward dynamics. Then, we design a new framework, which we name as Time-Reversal Symmetric ODE Networks (TRS-ODENs), that can learn the dynamics of physical systems more sample-efficiently by learning with the proposed loss function. We evaluate TRS-ODENs on several classical dynamics, and find they can learn the desired time evolution from observed noisy and complex trajectories. We also show that, even for systems that do not possess the full time-reversal symmetry, TRS-ODENs can achieve better predictive errors over baselines.
DeepTimeAnomalyViz: A Tool for Visualizing and Post-processing Deep Learning Anomaly Detection Results for Industrial Time-Series
Sep 21, 2021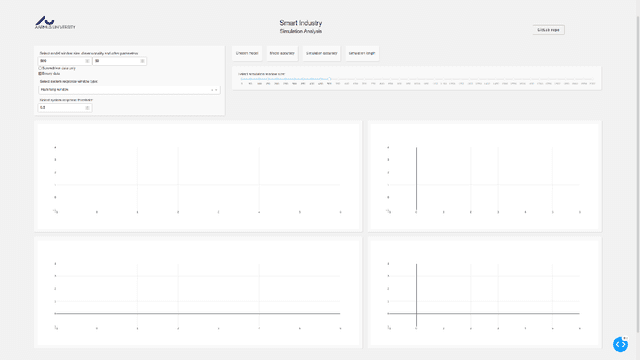
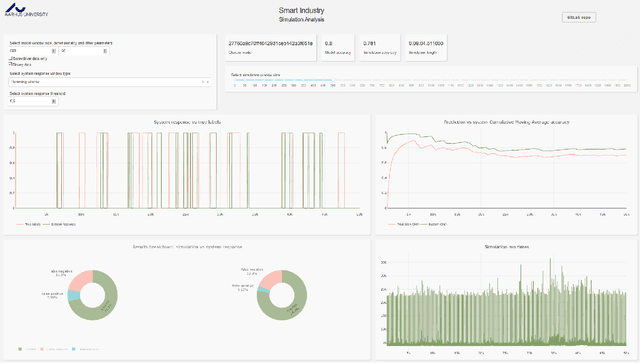
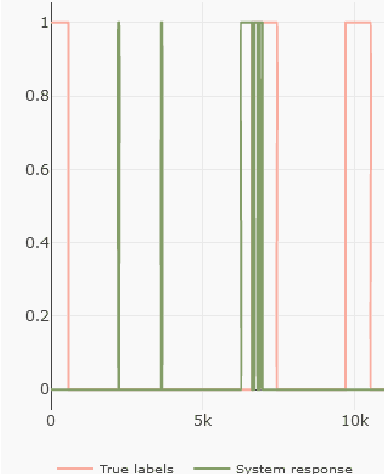
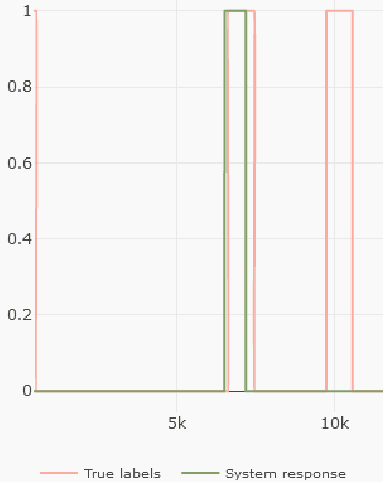
Industrial processes are monitored by a large number of various sensors that produce time-series data. Deep Learning offers a possibility to create anomaly detection methods that can aid in preventing malfunctions and increasing efficiency. But creating such a solution can be a complicated task, with factors such as inference speed, amount of available data, number of sensors, and many more, influencing the feasibility of such implementation. We introduce the DeTAVIZ interface, which is a web browser based visualization tool for quick exploration and assessment of feasibility of DL based anomaly detection in a given problem. Provided with a pool of pretrained models and simulation results, DeTAVIZ allows the user to easily and quickly iterate through multiple post processing options and compare different models, and allows for manual optimisation towards a chosen metric.
NLU for Game-based Learning in Real: Initial Evaluations
May 27, 2022
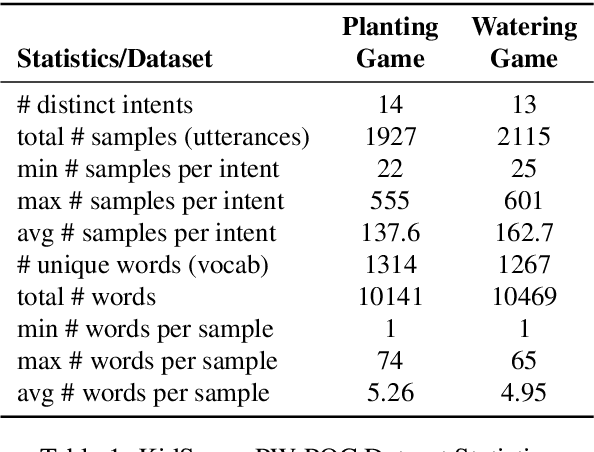
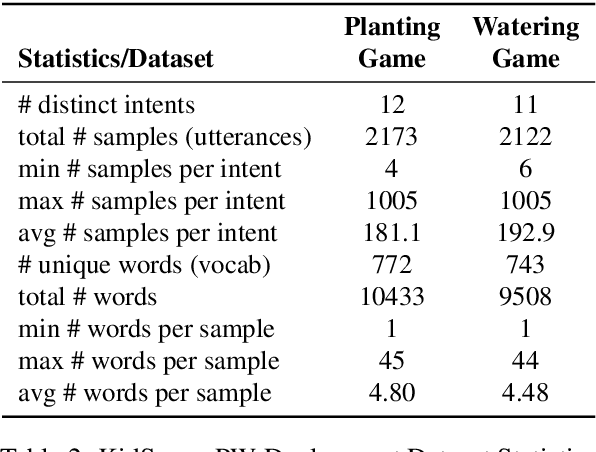
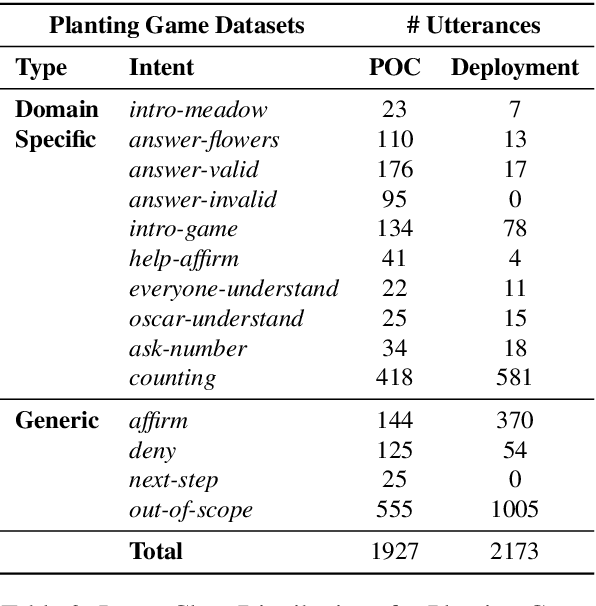
Intelligent systems designed for play-based interactions should be contextually aware of the users and their surroundings. Spoken Dialogue Systems (SDS) are critical for these interactive agents to carry out effective goal-oriented communication with users in real-time. For the real-world (i.e., in-the-wild) deployment of such conversational agents, improving the Natural Language Understanding (NLU) module of the goal-oriented SDS pipeline is crucial, especially with limited task-specific datasets. This study explores the potential benefits of a recently proposed transformer-based multi-task NLU architecture, mainly to perform Intent Recognition on small-size domain-specific educational game datasets. The evaluation datasets were collected from children practicing basic math concepts via play-based interactions in game-based learning settings. We investigate the NLU performances on the initial proof-of-concept game datasets versus the real-world deployment datasets and observe anticipated performance drops in-the-wild. We have shown that compared to the more straightforward baseline approaches, Dual Intent and Entity Transformer (DIET) architecture is robust enough to handle real-world data to a large extent for the Intent Recognition task on these domain-specific in-the-wild game datasets.
Retrieving and Ranking Relevant JavaScript Technologies from Web Repositories
May 30, 2022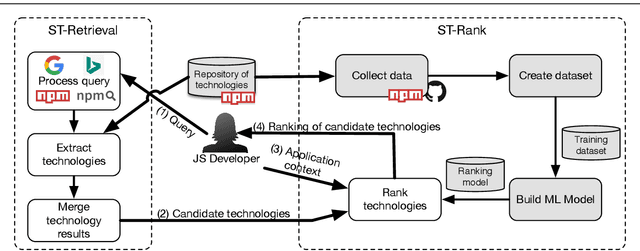

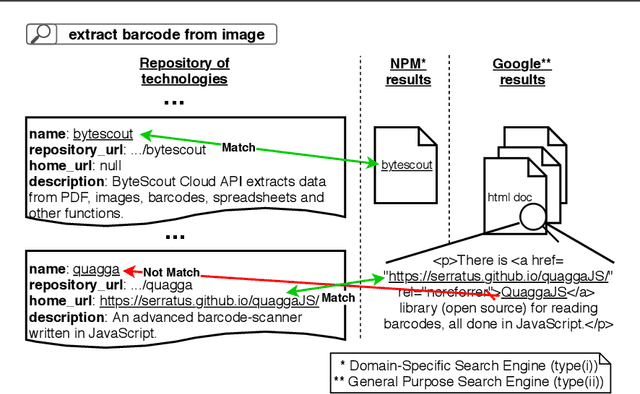

The selection of software technologies is an important but complex task. We consider developers of JavaScript (JS) applications, for whom the assessment of JS libraries has become difficult and time-consuming due to the growing number of technology options available. A common strategy is to browse software repositories via search engines (e.g., NPM, or Google), although it brings some problems. First, given a technology need, the engines might return a long list of results, which often causes information overload issues. Second, the results should be ranked according to criteria of interest for the developer. However, deciding how to weight these criteria to make a decision is not straightforward. In this work, we propose a two-phase approach for assisting developers to retrieve and rank JS technologies in a semi-automated fashion. The first-phase (ST-Retrieval) uses a meta-search technique for collecting JS technologies that meet the developer's needs. The second-phase (called ST-Rank), relies on a machine learning technique to infer, based on criteria used by other projects in the Web, a ranking of the output of ST-Retrieval. We evaluated our approach with NPM and obtained satisfactory results in terms of the accuracy of the technologies retrieved and the order in which they were ranked.
Efficient $Φ$-Regret Minimization in Extensive-Form Games via Online Mirror Descent
Jun 02, 2022A conceptually appealing approach for learning Extensive-Form Games (EFGs) is to convert them to Normal-Form Games (NFGs). This approach enables us to directly translate state-of-the-art techniques and analyses in NFGs to learning EFGs, but typically suffers from computational intractability due to the exponential blow-up of the game size introduced by the conversion. In this paper, we address this problem in natural and important setups for the \emph{$\Phi$-Hedge} algorithm -- A generic algorithm capable of learning a large class of equilibria for NFGs. We show that $\Phi$-Hedge can be directly used to learn Nash Equilibria (zero-sum settings), Normal-Form Coarse Correlated Equilibria (NFCCE), and Extensive-Form Correlated Equilibria (EFCE) in EFGs. We prove that, in those settings, the \emph{$\Phi$-Hedge} algorithms are equivalent to standard Online Mirror Descent (OMD) algorithms for EFGs with suitable dilated regularizers, and run in polynomial time. This new connection further allows us to design and analyze a new class of OMD algorithms based on modifying its log-partition function. In particular, we design an improved algorithm with balancing techniques that achieves a sharp $\widetilde{\mathcal{O}}(\sqrt{XAT})$ EFCE-regret under bandit-feedback in an EFG with $X$ information sets, $A$ actions, and $T$ episodes. To our best knowledge, this is the first such rate and matches the information-theoretic lower bound.
Toward Ambient Intelligence: Federated Edge Learning with Task-Oriented Sensing, Computation, and Communication Integration
Jun 13, 2022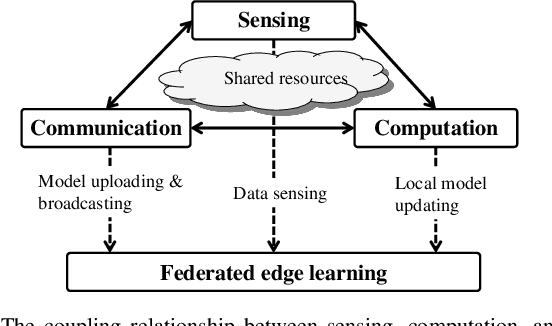
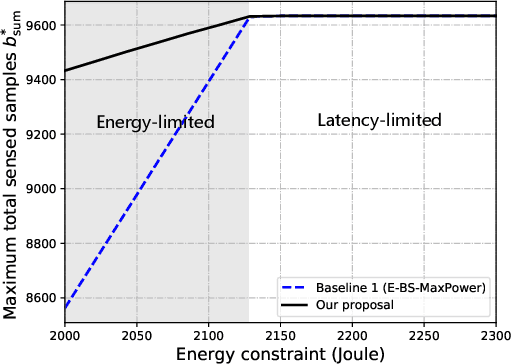
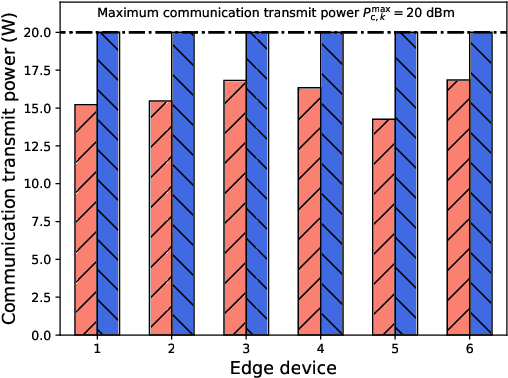
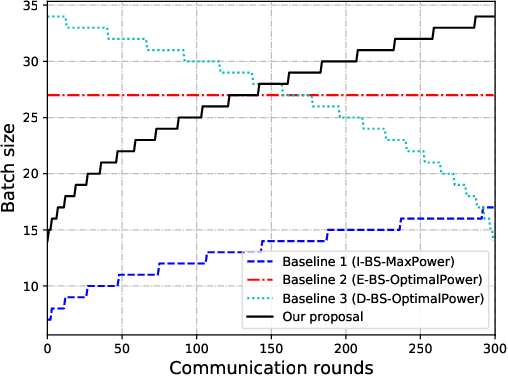
In this paper, we address the problem of joint sensing, computation, and communication (SC$^{2}$) resource allocation for federated edge learning (FEEL) via a concrete case study of human motion recognition based on wireless sensing in ambient intelligence. First, by analyzing the wireless sensing process in human motion recognition, we find that there exists a thresholding value for the sensing transmit power, exceeding which yields sensing data samples with approximately the same satisfactory quality. Then, the joint SC$^{2}$ resource allocation problem is cast to maximize the convergence speed of FEEL, under the constraints on training time, energy supply, and sensing quality of each edge device. Solving this problem entails solving two subproblems in order: the first one reduces to determine the joint sensing and communication resource allocation that maximizes the total number of samples that can be sensed during the entire training process; the second one concerns the partition of the attained total number of sensed samples over all the communication rounds to determine the batch size at each round for convergence speed maximization. The first subproblem on joint sensing and communication resource allocation is converted to a single-variable optimization problem by exploiting the derived relation between different control variables (resources), which thus allows an efficient solution via one-dimensional grid search. For the second subproblem, it is found that the number of samples to be sensed (or batch size) at each round is a decreasing function of the loss function value attained at the round. Based on this relationship, the approximate optimal batch size at each communication round is derived in closed-form as a function of the round index. Finally, extensive simulation results are provided to validate the superiority of the proposed joint SC$^{2}$ resource allocation scheme.
A Survey of Research on Fair Recommender Systems
May 23, 2022
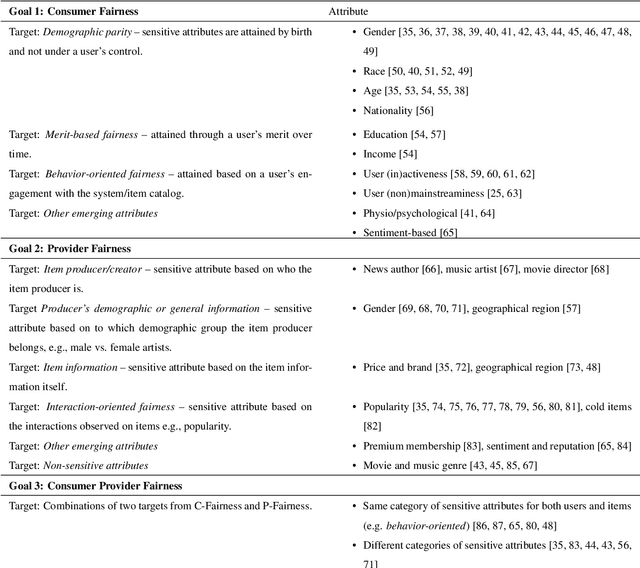
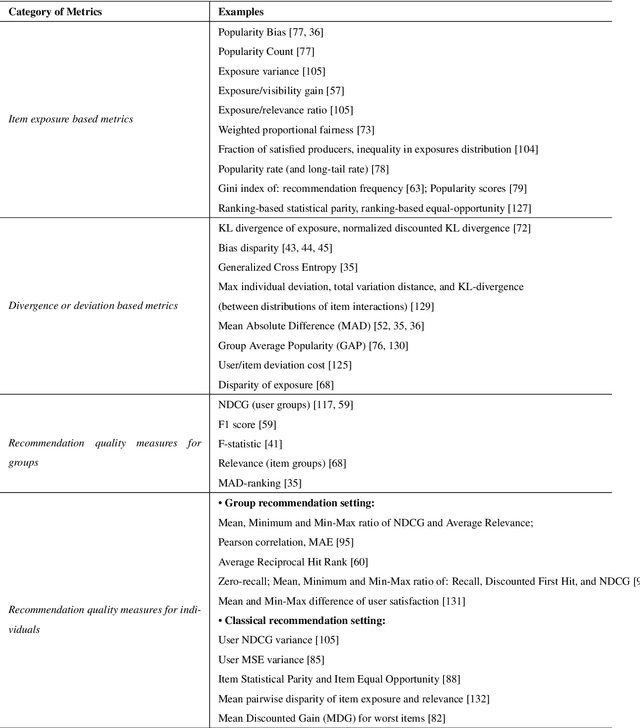
Recommender systems can strongly influence which information we see online, e.g, on social media, and thus impact our beliefs, decisions, and actions. At the same time, these systems can create substantial business value for different stakeholders. Given the growing potential impact of such AI-based systems on individuals, organizations, and society, questions of fairness have gained increased attention in recent years. However, research on fairness in recommender systems is still a developing area. In this survey, we first review the fundamental concepts and notions of fairness that were put forward in the area in the recent past. Afterward, we provide a survey of how research in this area is currently operationalized, for example, in terms of the general research methodology, fairness metrics, and algorithmic approaches. Overall, our analysis of recent works points to certain research gaps. In particular, we find that in many research works in computer science very abstract problem operationalizations are prevalent, which circumvent the fundamental and important question of what represents a fair recommendation in the context of a given application.
Functional Ensemble Distillation
Jun 05, 2022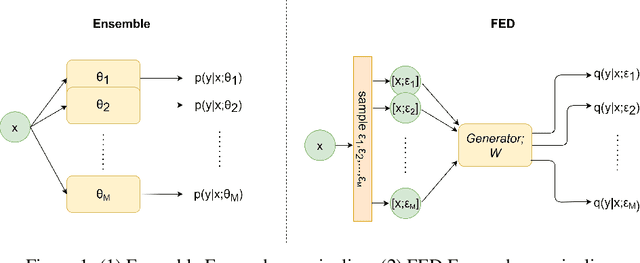

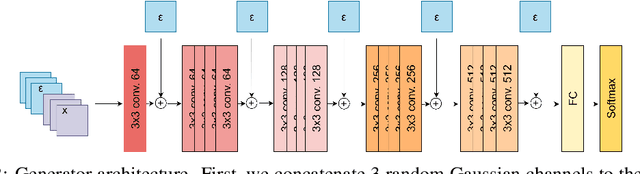
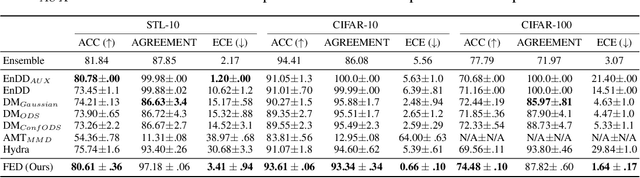
Bayesian models have many desirable properties, most notable is their ability to generalize from limited data and to properly estimate the uncertainty in their predictions. However, these benefits come at a steep computational cost as Bayesian inference, in most cases, is computationally intractable. One popular approach to alleviate this problem is using a Monte-Carlo estimation with an ensemble of models sampled from the posterior. However, this approach still comes at a significant computational cost, as one needs to store and run multiple models at test time. In this work, we investigate how to best distill an ensemble's predictions using an efficient model. First, we argue that current approaches that simply return distribution over predictions cannot compute important properties, such as the covariance between predictions, which can be valuable for further processing. Second, in many limited data settings, all ensemble members achieve nearly zero training loss, namely, they produce near-identical predictions on the training set which results in sub-optimal distilled models. To address both problems, we propose a novel and general distillation approach, named Functional Ensemble Distillation (FED), and we investigate how to best distill an ensemble in this setting. We find that learning the distilled model via a simple augmentation scheme in the form of mixup augmentation significantly boosts the performance. We evaluated our method on several tasks and showed that it achieves superior results in both accuracy and uncertainty estimation compared to current approaches.
Deep Depth Completion: A Survey
May 17, 2022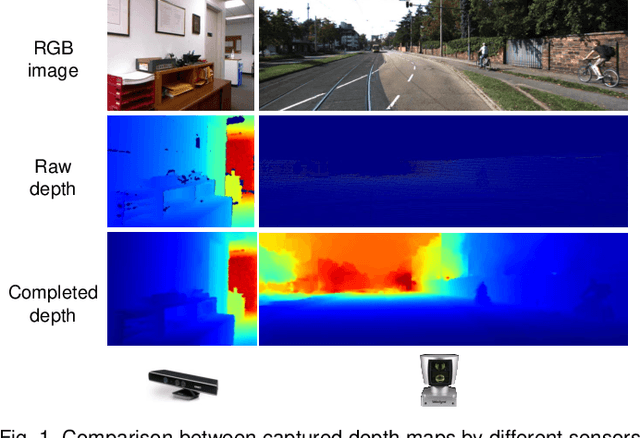
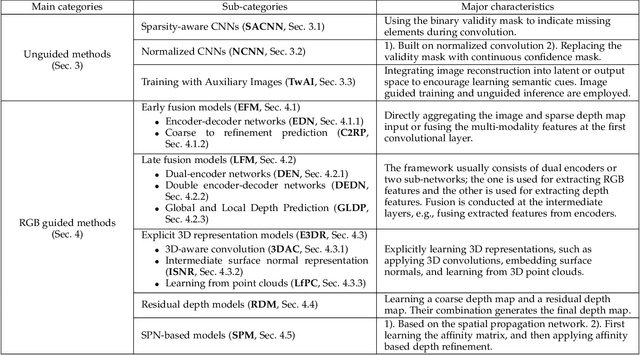
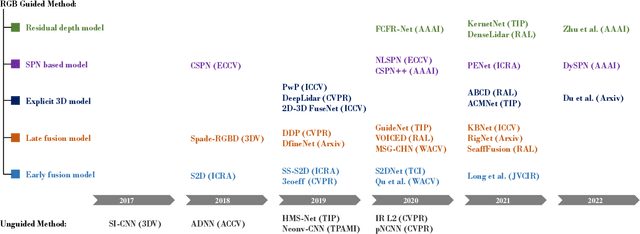
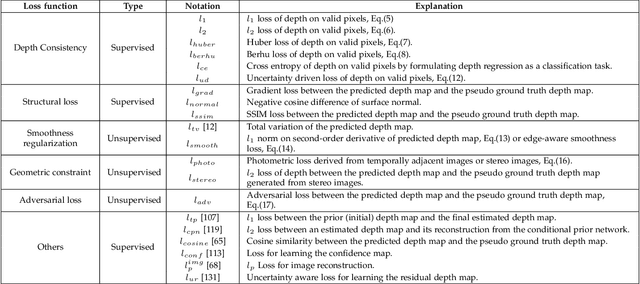
Depth completion aims at predicting dense pixel-wise depth from a sparse map captured from a depth sensor. It plays an essential role in various applications such as autonomous driving, 3D reconstruction, augmented reality, and robot navigation. Recent successes on the task have been demonstrated and dominated by deep learning based solutions. In this article, for the first time, we provide a comprehensive literature review that helps readers better grasp the research trends and clearly understand the current advances. We investigate the related studies from the design aspects of network architectures, loss functions, benchmark datasets, and learning strategies with a proposal of a novel taxonomy that categorizes existing methods. Besides, we present a quantitative comparison of model performance on two widely used benchmark datasets, including an indoor and an outdoor dataset. Finally, we discuss the challenges of prior works and provide readers with some insights for future research directions.
FV-UPatches: Enhancing Universality in Finger Vein Recognition
Jun 02, 2022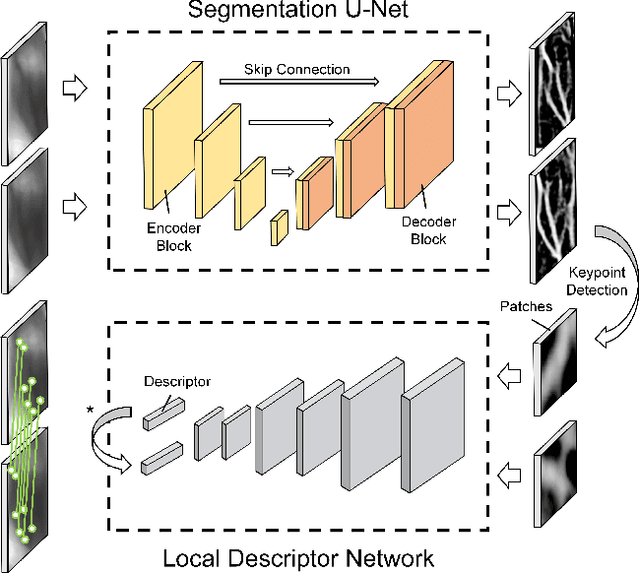


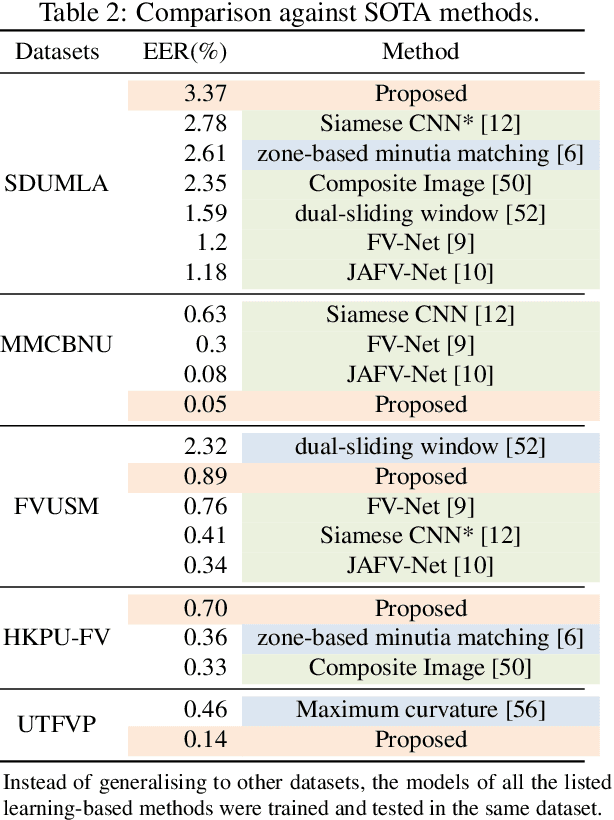
Many deep learning-based models have been introduced in finger vein recognition in recent years. These solutions, however, suffer from data dependency and are difficult to achieve model generalization. To address this problem, we are inspired by the idea of domain adaptation and propose a universal learning-based framework, which achieves generalization while training with limited data. To reduce differences between data distributions, a compressed U-Net is introduced as a domain mapper to map the raw region of interest image onto a target domain. The concentrated target domain is a unified feature space for the subsequent matching, in which a local descriptor model SOSNet is employed to embed patches into descriptors measuring the similarity of matching pairs. In the proposed framework, the domain mapper is an approximation to a specific extraction function thus the training is only a one-time effort with limited data. Moreover, the local descriptor model can be trained to be representative enough based on a public dataset of non-finger-vein images. The whole pipeline enables the framework to be well generalized, making it possible to enhance universality and helps to reduce costs of data collection, tuning and retraining. The comparable experimental results to state-of-the-art (SOTA) performance in five public datasets prove the effectiveness of the proposed framework. Furthermore, the framework shows application potential in other vein-based biometric recognition as well.