 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continual Object Detection: A review of definitions, strategies, and challenges
May 30, 2022
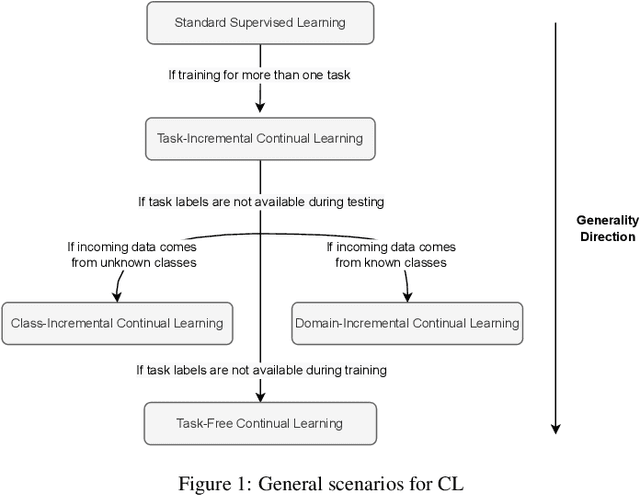

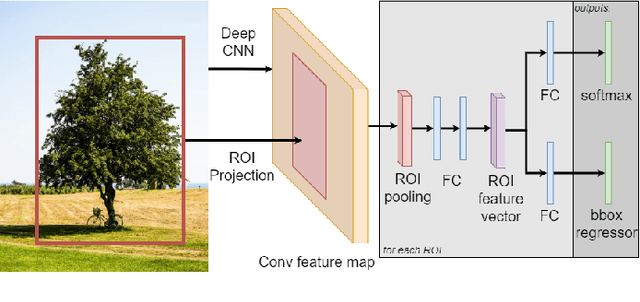
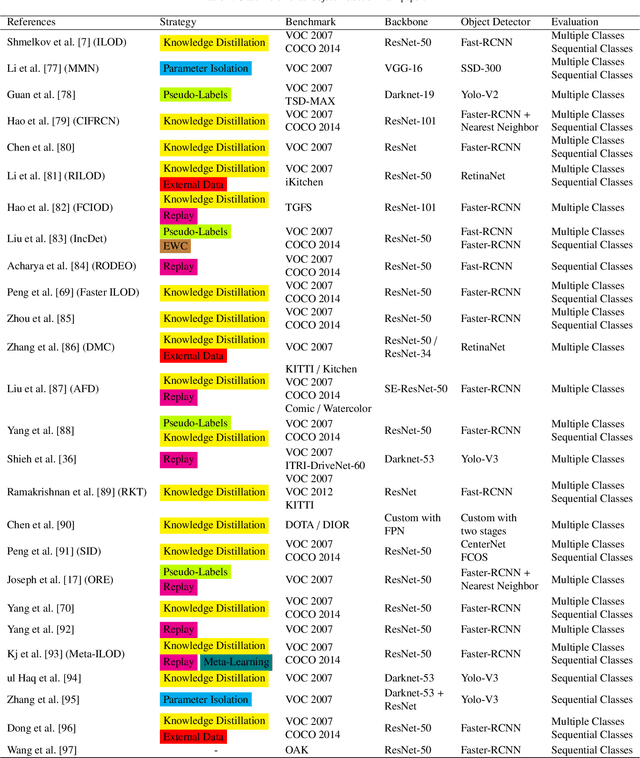
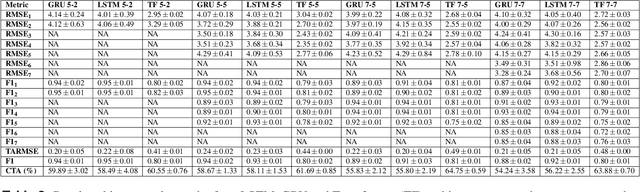
The field of Continual Learning investigates the ability to learn consecutive tasks without losing performance on those previously learned. Its focus has been mainly on incremental classification tasks. We believe that research in continual object detection deserves even more attention due to its vast range of applications in robotics and autonomous vehicles. This scenario is more complex than conventional classification given the occurrence of instances of classes that are unknown at the time, but can appear in subsequent tasks as a new class to be learned, resulting in missing annotations and conflicts with the background label. In this review, we analyze the current strategies proposed to tackle the problem of class-incremental object detection. Our main contributions are: (1) a short and systematic review of the methods that propose solutions to traditional incremental object detection scenarios; (2) A comprehensive evaluation of the existing approaches using a new metric to quantify the stability and plasticity of each technique in a standard way; (3) an overview of the current trends within continual object detection and a discussion of possible future research directions.
A Fast and Efficient Conditional Learning for Tunable Trade-Off between Accuracy and Robustness
Mar 28, 2022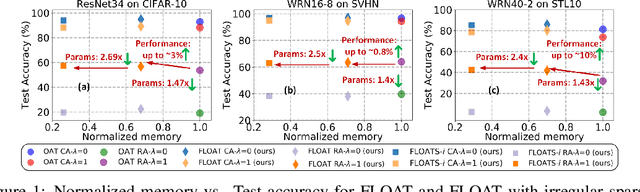

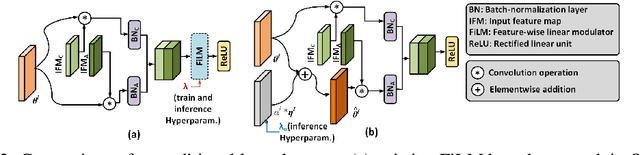
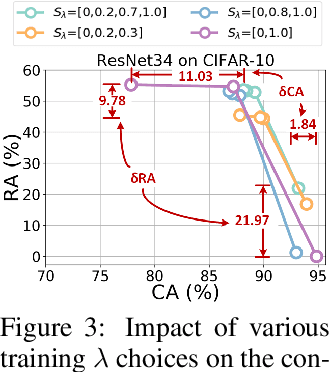
Existing models that achieve state-of-the-art (SOTA) performance on both clean and adversarially-perturbed images rely on convolution operations conditioned with feature-wise linear modulation (FiLM) layers. These layers require many new parameters and are hyperparameter sensitive. They significantly increase training time, memory cost, and potential latency which can prove costly for resource-limited or real-time applications. In this paper, we present a fast learnable once-for-all adversarial training (FLOAT) algorithm, which instead of the existing FiLM-based conditioning, presents a unique weight conditioned learning that requires no additional layer, thereby incurring no significant increase in parameter count, training time, or network latency compared to standard adversarial training. In particular, we add configurable scaled noise to the weight tensors that enables a trade-off between clean and adversarial performance. Extensive experiments show that FLOAT can yield SOTA performance improving both clean and perturbed image classification by up to ~6% and ~10%, respectively. Moreover, real hardware measurement shows that FLOAT can reduce the training time by up to 1.43x with fewer model parameters of up to 1.47x on iso-hyperparameter settings compared to the FiLM-based alternatives. Additionally, to further improve memory efficiency we introduce FLOAT sparse (FLOATS), a form of non-iterative model pruning and provide detailed empirical analysis to provide a three way accuracy-robustness-complexity trade-off for these new class of pruned conditionally trained models.
Identifying Cause-and-Effect Relationships of Manufacturing Errors using Sequence-to-Sequence Learning
May 05, 2022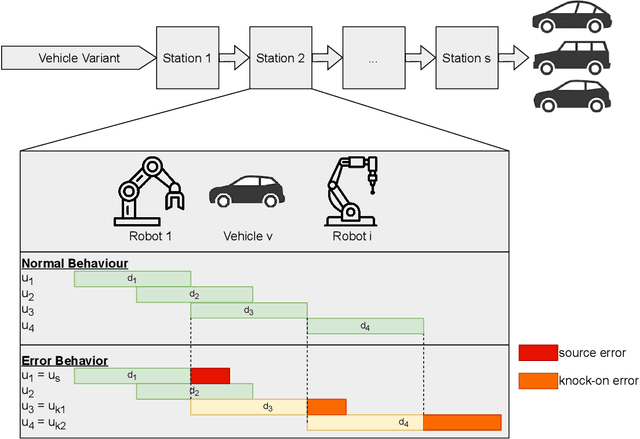
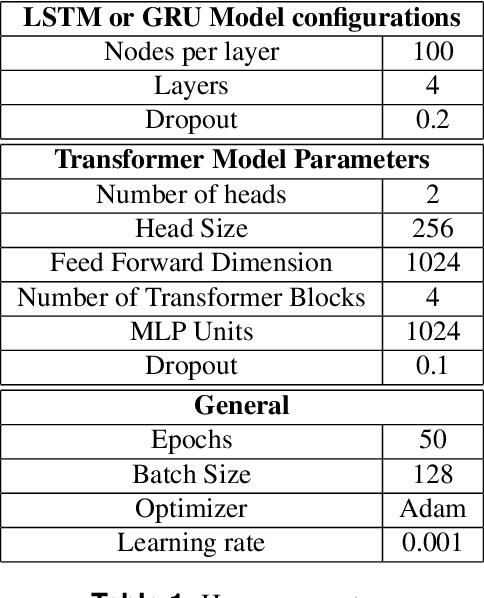
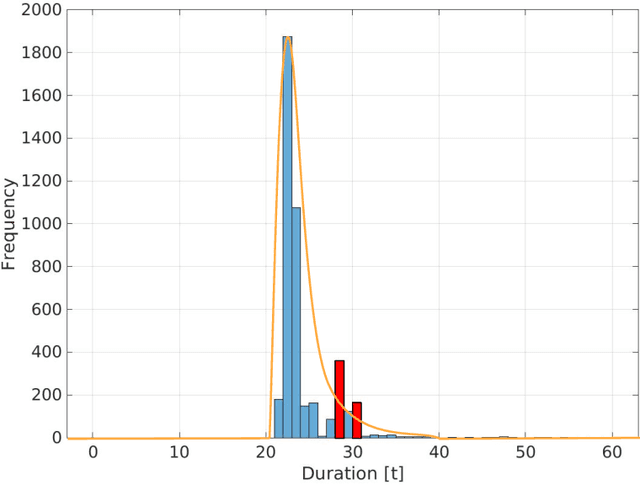
In car-body production the pre-formed sheet metal parts of the body are assembled on fully-automated production lines. The body passes through multiple stations in succession, and is processed according to the order requirements. The timely completion of orders depends on the individual station-based operations concluding within their scheduled cycle times. If an error occurs in one station, it can have a knock-on effect, resulting in delays on the downstream stations. To the best of our knowledge, there exist no methods for automatically distinguishing between source and knock-on errors in this setting, as well as establishing a causal relation between them. Utilizing real-time information about conditions collected by a production data acquisition system, we propose a novel vehicle manufacturing analysis system, which uses deep learning to establish a link between source and knock-on errors. We benchmark three sequence-to-sequence models, and introduce a novel composite time-weighted action metric for evaluating models in this context. We evaluate our framework on a real-world car production dataset recorded by Volkswagen Commercial Vehicles. Surprisingly we find that 71.68% of sequences contain either a source or knock-on error. With respect to seq2seq model training, we find that the Transformer demonstrates a better performance compared to LSTM and GRU in this domain, in particular when the prediction range with respect to the durations of future actions is increased.
Safety Guarantees for Neural Network Dynamic Systems via Stochastic Barrier Functions
Jun 15, 2022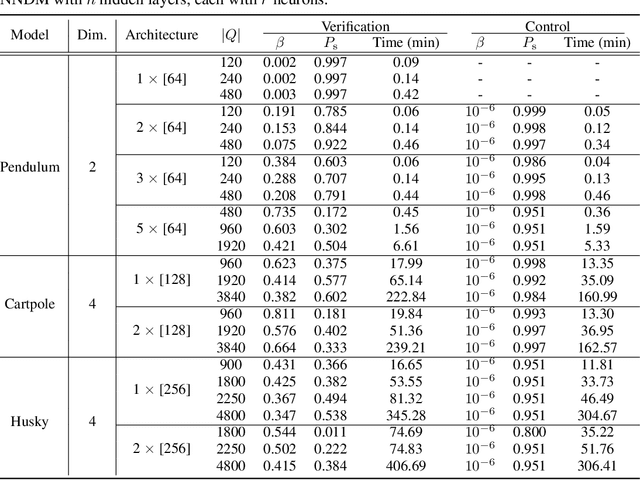
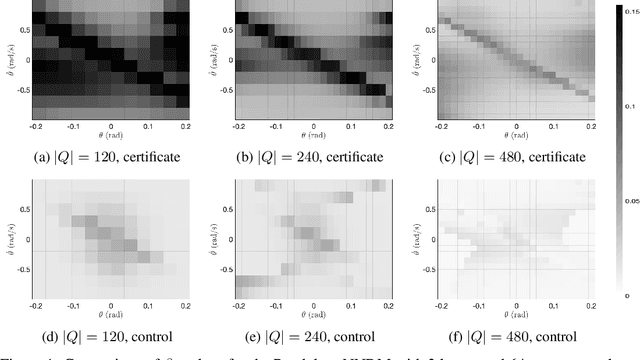
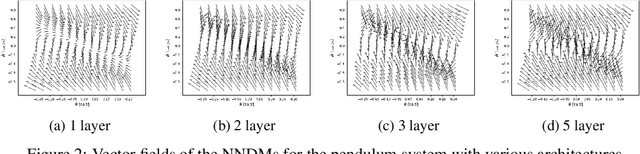
Neural Networks (NNs) have been successfully employed to represent the state evolution of complex dynamical systems. Such models, referred to as NN dynamic models (NNDMs), use iterative noisy predictions of NN to estimate a distribution of system trajectories over time. Despite their accuracy, safety analysis of NNDMs is known to be a challenging problem and remains largely unexplored. To address this issue, in this paper, we introduce a method of providing safety guarantees for NNDMs. Our approach is based on stochastic barrier functions, whose relation with safety are analogous to that of Lyapunov functions with stability. We first show a method of synthesizing stochastic barrier functions for NNDMs via a convex optimization problem, which in turn provides a lower bound on the system's safety probability. A key step in our method is the employment of the recent convex approximation results for NNs to find piece-wise linear bounds, which allow the formulation of the barrier function synthesis problem as a sum-of-squares optimization program. If the obtained safety probability is above the desired threshold, the system is certified. Otherwise, we introduce a method of generating controls for the system that robustly maximizes the safety probability in a minimally-invasive manner. We exploit the convexity property of the barrier function to formulate the optimal control synthesis problem as a linear program. Experimental results illustrate the efficacy of the method. Namely, they show that the method can scale to multi-dimensional NNDMs with multiple layers and hundreds of neurons per layer, and that the controller can significantly improve the safety probability.
Low-rank lottery tickets: finding efficient low-rank neural networks via matrix differential equations
May 26, 2022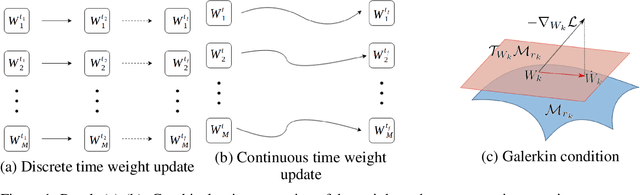
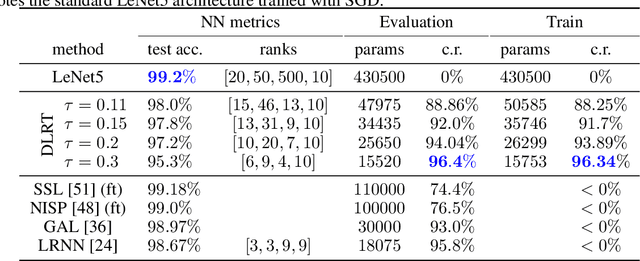
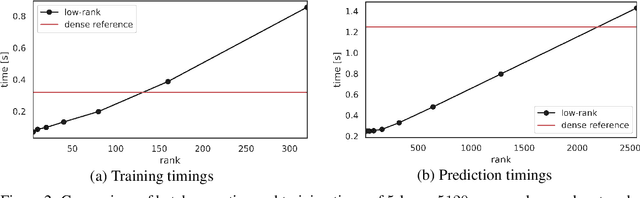
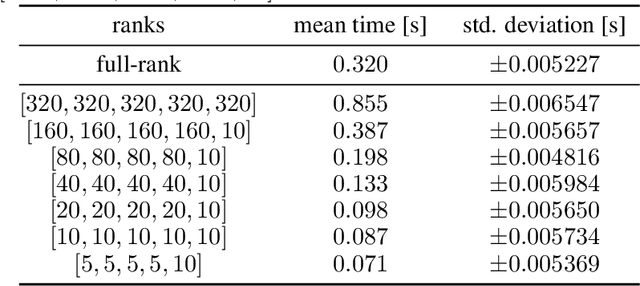
Neural networks have achieved tremendous success in a large variety of applications. However, their memory footprint and computational demand can render them impractical in application settings with limited hardware or energy resources. In this work, we propose a novel algorithm to find efficient low-rank subnetworks. Remarkably, these subnetworks are determined and adapted already during the training phase and the overall time and memory resources required by both training and evaluating them is significantly reduced. The main idea is to restrict the weight matrices to a low-rank manifold and to update the low-rank factors rather than the full matrix during training. To derive training updates that are restricted to the prescribed manifold, we employ techniques from dynamic model order reduction for matrix differential equations. Moreover, our method automatically and dynamically adapts the ranks during training to achieve a desired approximation accuracy. The efficiency of the proposed method is demonstrated through a variety of numerical experiments on fully-connected and convolutional networks.
Disentangling Epistemic and Aleatoric Uncertainty in Reinforcement Learning
Jun 03, 2022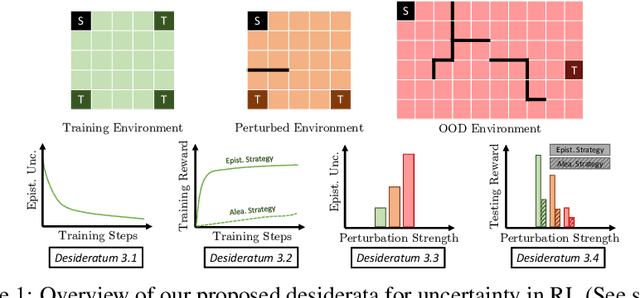

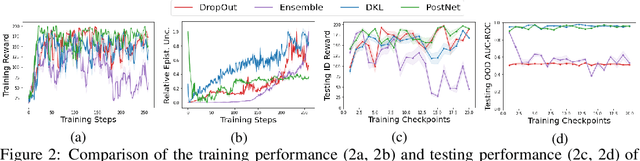
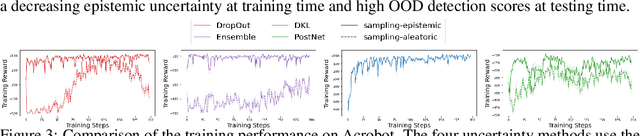
Characterizing aleatoric and epistemic uncertainty on the predicted rewards can help in building reliable reinforcement learning (RL) systems. Aleatoric uncertainty results from the irreducible environment stochasticity leading to inherently risky states and actions. Epistemic uncertainty results from the limited information accumulated during learning to make informed decisions. Characterizing aleatoric and epistemic uncertainty can be used to speed up learning in a training environment, improve generalization to similar testing environments, and flag unfamiliar behavior in anomalous testing environments. In this work, we introduce a framework for disentangling aleatoric and epistemic uncertainty in RL. (1) We first define four desiderata that capture the desired behavior for aleatoric and epistemic uncertainty estimation in RL at both training and testing time. (2) We then present four RL models inspired by supervised learning (i.e. Monte Carlo dropout, ensemble, deep kernel learning models, and evidential networks) to instantiate aleatoric and epistemic uncertainty. Finally, (3) we propose a practical evaluation method to evaluate uncertainty estimation in model-free RL based on detection of out-of-distribution environments and generalization to perturbed environments. We present theoretical and experimental evidence to validate that carefully equipping model-free RL agents with supervised learning uncertainty methods can fulfill our desiderata.
Truly Deterministic Policy Optimization
May 30, 2022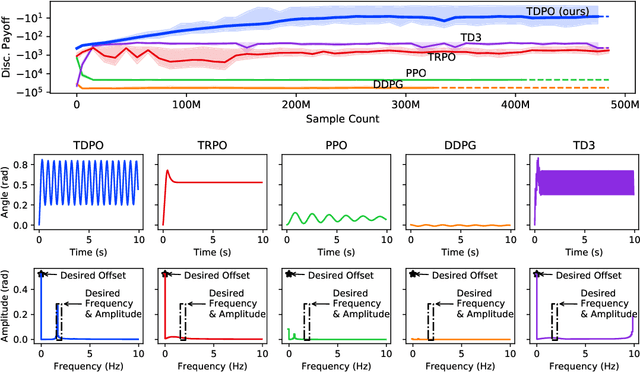

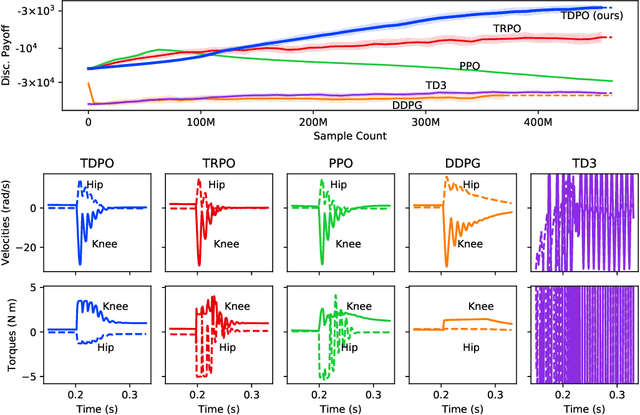

In this paper, we present a policy gradient method that avoids exploratory noise injection and performs policy search over the deterministic landscape. By avoiding noise injection all sources of estimation variance can be eliminated in systems with deterministic dynamics (up to the initial state distribution). Since deterministic policy regularization is impossible using traditional non-metric measures such as the KL divergence, we derive a Wasserstein-based quadratic model for our purposes. We state conditions on the system model under which it is possible to establish a monotonic policy improvement guarantee, propose a surrogate function for policy gradient estimation, and show that it is possible to compute exact advantage estimates if both the state transition model and the policy are deterministic. Finally, we describe two novel robotic control environments -- one with non-local rewards in the frequency domain and the other with a long horizon (8000 time-steps) -- for which our policy gradient method (TDPO) significantly outperforms existing methods (PPO, TRPO, DDPG, and TD3). Our implementation with all the experimental settings is available at https://github.com/ehsansaleh/code_tdpo
TubeFormer-DeepLab: Video Mask Transformer
May 30, 2022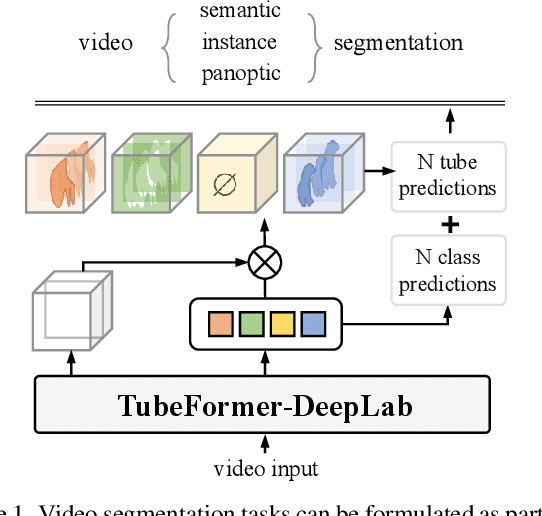
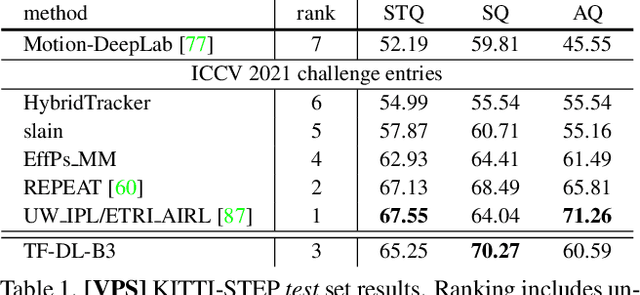
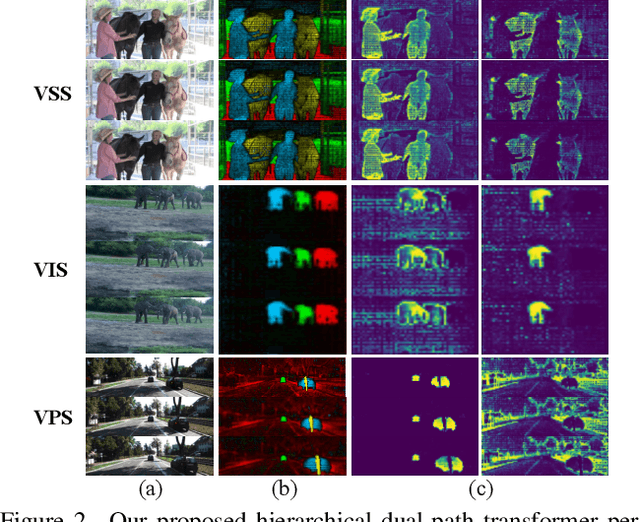
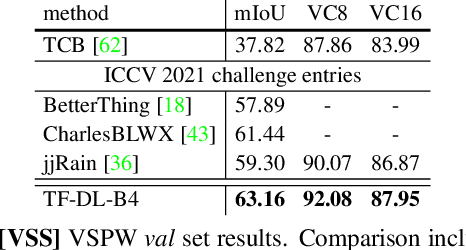
We present TubeFormer-DeepLab, the first attempt to tackle multiple core video segmentation tasks in a unified manner. Different video segmentation tasks (e.g., video semantic/instance/panoptic segmentation) are usually considered as distinct problems. State-of-the-art models adopted in the separate communities have diverged, and radically different approaches dominate in each task. By contrast, we make a crucial observation that video segmentation tasks could be generally formulated as the problem of assigning different predicted labels to video tubes (where a tube is obtained by linking segmentation masks along the time axis) and the labels may encode different values depending on the target task. The observation motivates us to develop TubeFormer-DeepLab, a simple and effective video mask transformer model that is widely applicable to multiple video segmentation tasks. TubeFormer-DeepLab directly predicts video tubes with task-specific labels (either pure semantic categories, or both semantic categories and instance identities), which not only significantly simplifies video segmentation models, but also advances state-of-the-art results on multiple video segmentation benchmarks
Explore User Neighborhood for Real-time E-commerce Recommendation
Feb 28, 2021
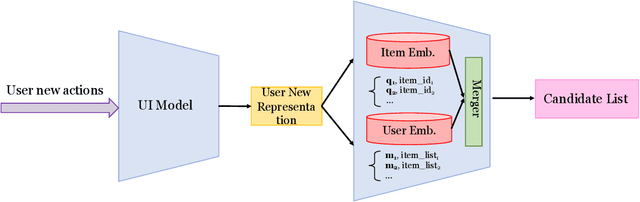
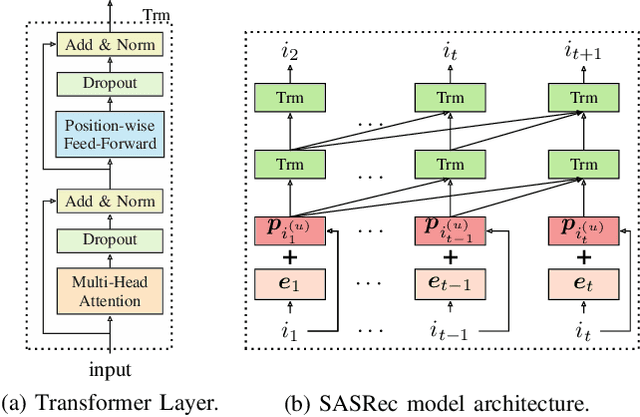
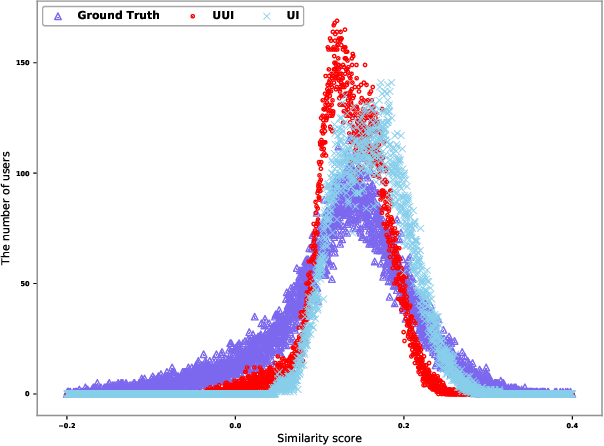
Recommender systems play a vital role in modern online services, such as Amazon and Taobao. Traditional personalized methods, which focus on user-item (UI) relations, have been widely applied in industrial settings, owing to their efficiency and effectiveness. Despite their success, we argue that these approaches ignore local information hidden in similar users. To tackle this problem, user-based methods exploit similar user relations to make recommendations in a local perspective. Nevertheless, traditional user-based methods, like userKNN and matrix factorization, are intractable to be deployed in the real-time applications since such transductive models have to be recomputed or retrained with any new interaction. To overcome this challenge, we propose a framework called self-complementary collaborative filtering~(SCCF) which can make recommendations with both global and local information in real time. On the one hand, it utilizes UI relations and user neighborhood to capture both global and local information. On the other hand, it can identify similar users for each user in real time by inferring user representations on the fly with an inductive model. The proposed framework can be seamlessly incorporated into existing inductive UI approach and benefit from user neighborhood with little additional computation. It is also the first attempt to apply user-based methods in real-time settings. The effectiveness and efficiency of SCCF are demonstrated through extensive offline experiments on four public datasets, as well as a large scale online A/B test in Taobao.
Learning Coded Apertures for Time-Division Multiplexing Light Field Display
Aug 02, 2021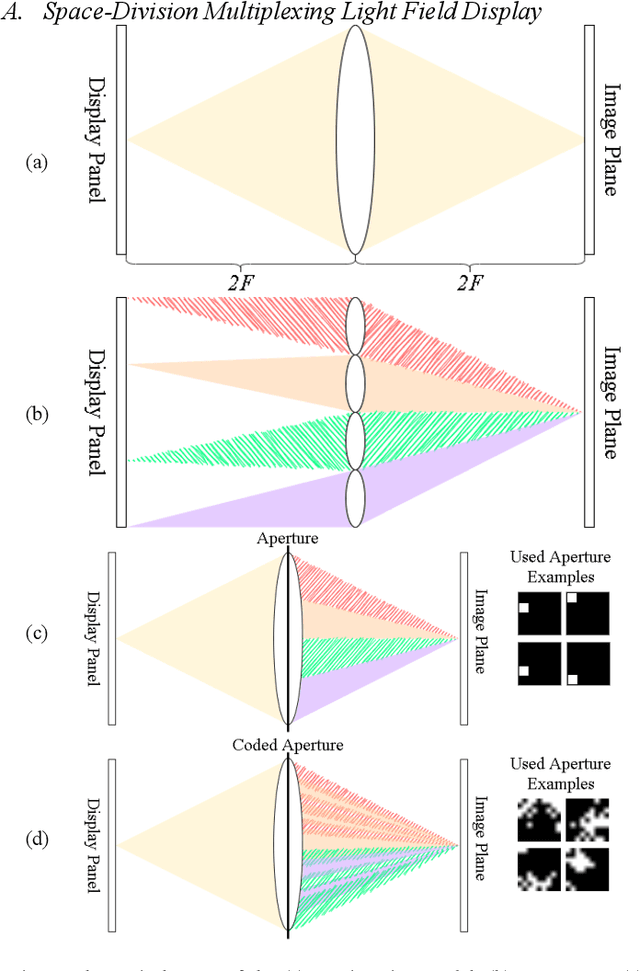



Conventional stereoscopic displays suffer from vergence-accommodation conflict and cause visual fatigue. Integral-imaging-based displays resolve the problem by directly projecting the sub-aperture views of a light field into the eyes using a microlens array or a similar structure. However, such displays have an inherent trade-off between angular and spatial resolutions. In this paper, we propose a novel coded time-division multiplexing technique that projects encoded sub-aperture views to the eyes of a viewer with correct cues for vergence-accommodation reflex. Given sparse light field sub-aperture views, our pipeline can provide a perception of high-resolution refocused images with minimal aliasing by jointly optimizing the sub-aperture views for display and the coded aperture pattern. This is achieved via deep learning in an end-to-end fashion by simulating light transport and image formation with Fourier optics. To our knowledge, this work is among the first that optimize the light field display pipeline with deep learning. We verify our idea with objective image quality metrics (PSNR and SSIM) and perform an extensive study on various customizable design variables in our display pipeline. Experimental results show that light fields displayed using the proposed technique indeed have higher quality than that of baseline display designs.