 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stochastic Recurrent Neural Network for Multistep Time Series Forecasting
Apr 26, 2021
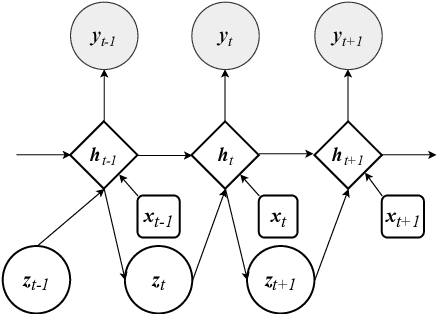
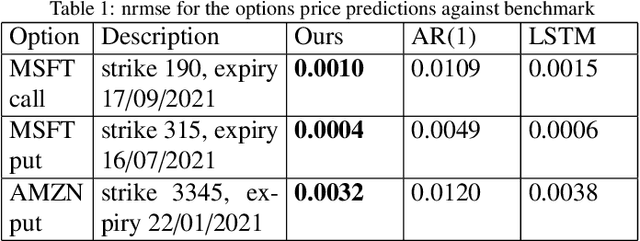
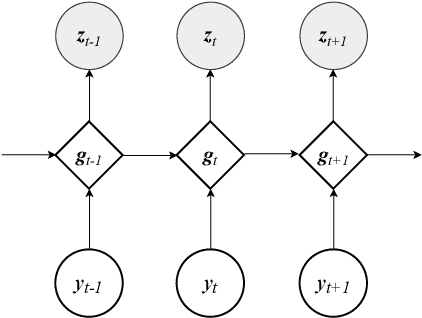
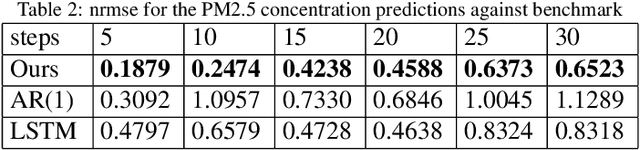
Time series forecasting based on deep architectures has been gaining popularity in recent years due to their ability to model complex non-linear temporal dynamics. The recurrent neural network is one such model capable of handling variable-length input and output. In this paper, we leverage recent advances in deep generative models and the concept of state space models to propose a stochastic adaptation of the recurrent neural network for multistep-ahead time series forecasting, which is trained with stochastic gradient variational Bayes. In our model design, the transition function of the recurrent neural network, which determines the evolution of the hidden states, is stochastic rather than deterministic as in a regular recurrent neural network; this is achieved by incorporating a latent random variable into the transition process which captures the stochasticity of the temporal dynamics. Our model preserves the architectural workings of a recurrent neural network for which all relevant information is encapsulated in its hidden states, and this flexibility allows our model to be easily integrated into any deep architecture for sequential modelling. We test our model on a wide range of datasets from finance to healthcare; results show that the stochastic recurrent neural network consistently outperforms its deterministic counterpart.
Machine Learning Prediction of Time-Varying Rayleigh Channels
Mar 10, 2021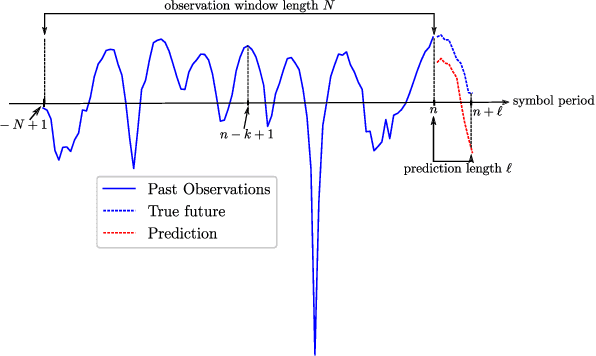
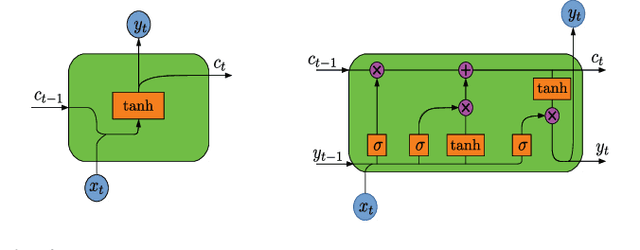
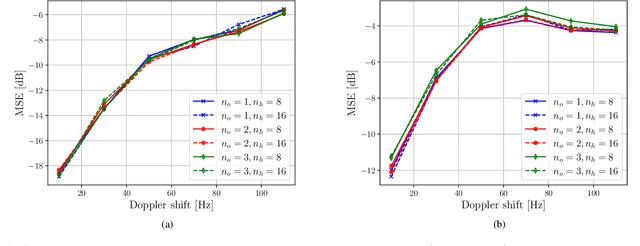
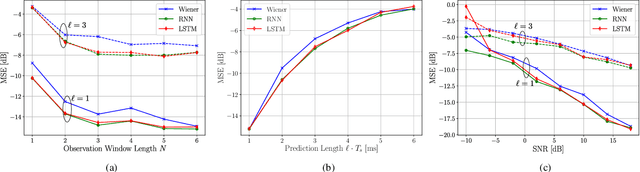
Channel state information (CSI) rapidly becomes outdated in high mobility scenarios, degrading the performance of wireless communication systems. In these cases, time series prediction techniques can be applied to combat the effects of outdated CSI. Recently, it has been shown that recurrent neural networks (RNNs) exhibit outstanding performance in time series prediction tasks. In this paper, we investigate the performance of RNN and long short term memory (LSTM) predictors in a simple Rayleigh flat-fading channel. We conduct numerical experiments to evaluate whether these machine-learning (ML)-based predictors can outperform the optimal linear minimum mean square error Wiener predictor. Our simulation results indicate that the considered neural network predictors outperform the Wiener predictor for small observation window lengths and are more robust under weak channel correlation as well as in the presence of noise. Furthermore, we show that simple shallow RNNs are sufficient to model Rayleigh channels over a wide range of Doppler shifts.
Linear Algorithms for Nonparametric Multiclass Probability Estimation
May 25, 2022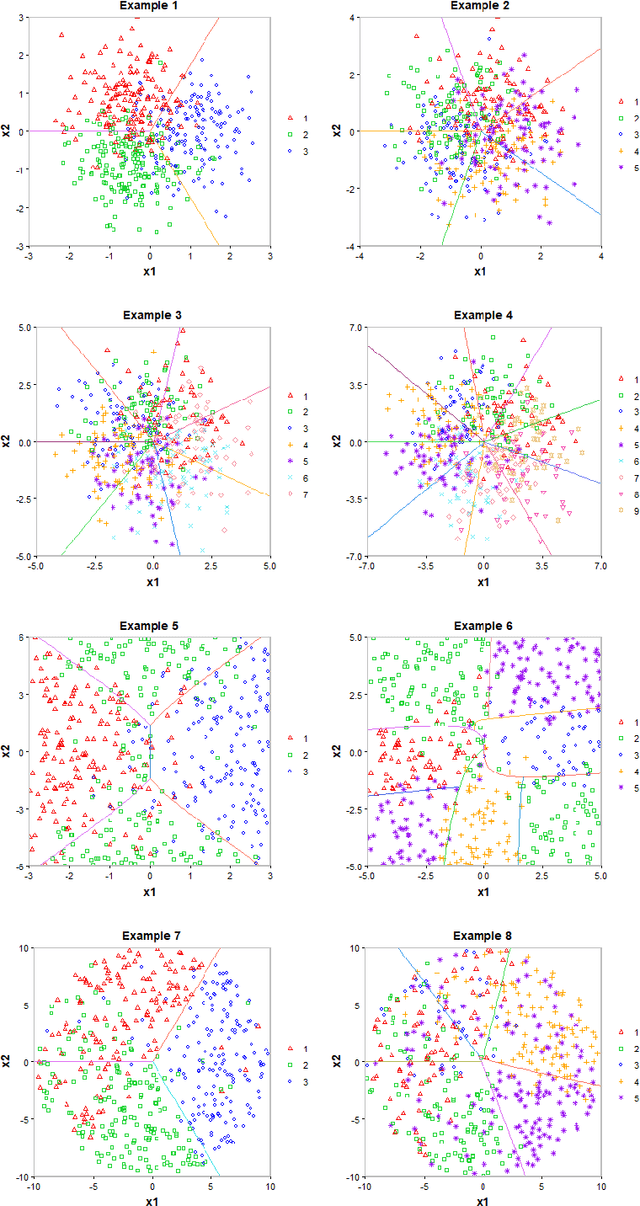
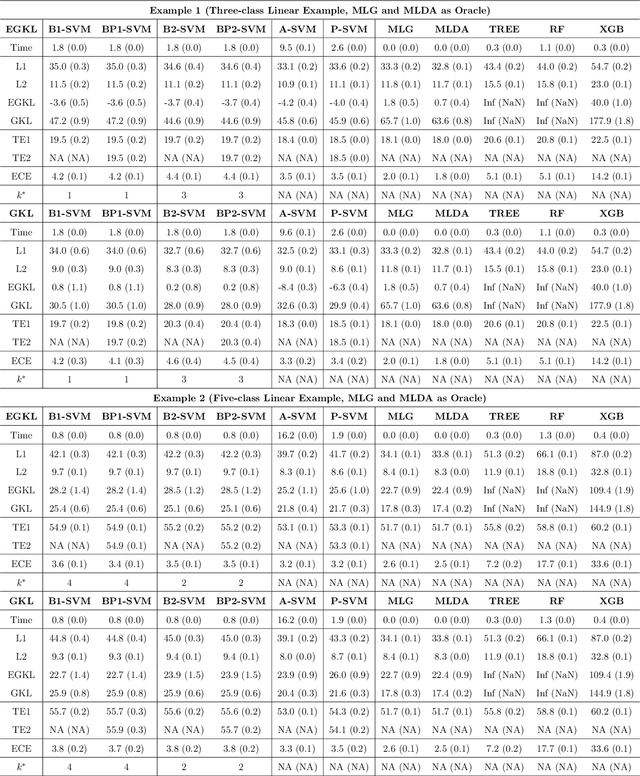
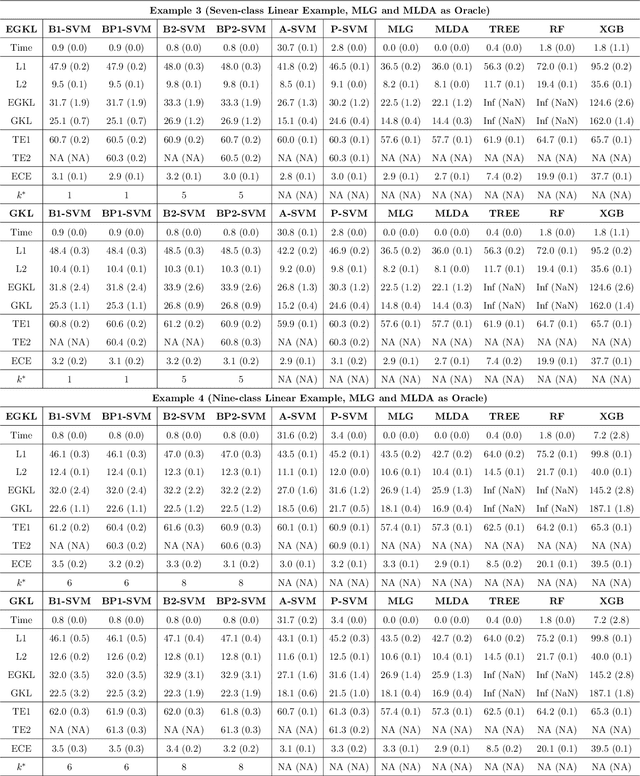
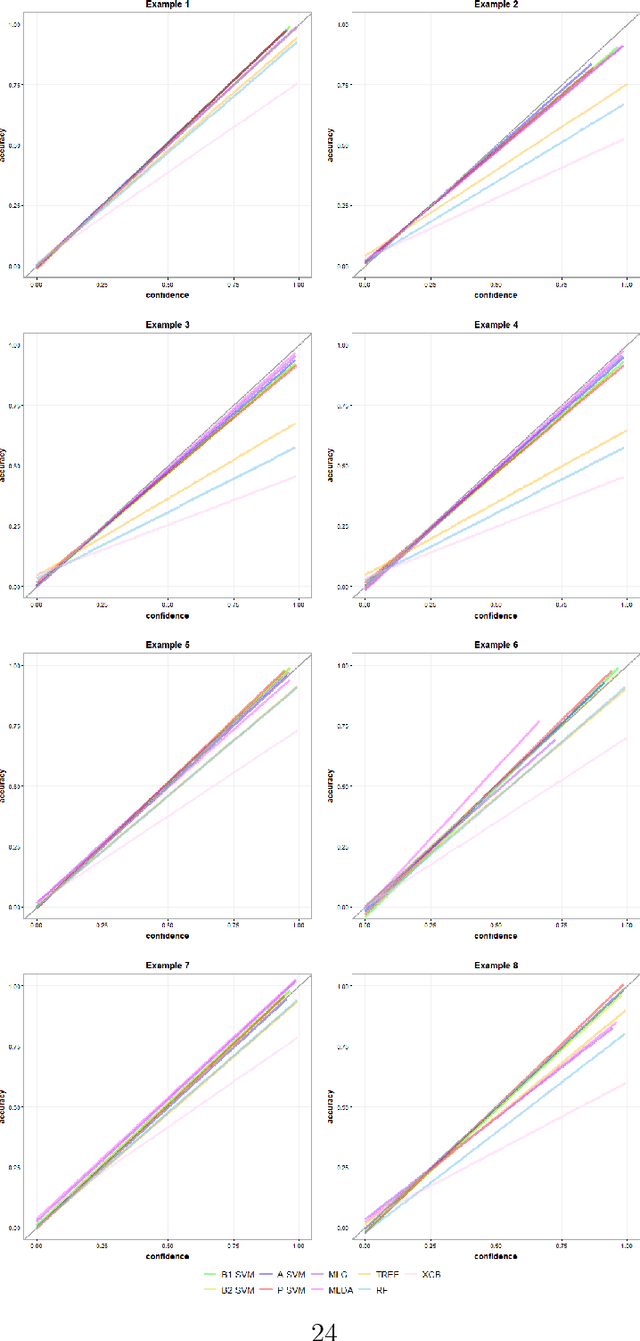
Multiclass probability estimation is the problem of estimating conditional probabilities of a data point belonging to a class given its covariate information. It has broad applications in statistical analysis and data science. Recently a class of weighted Support Vector Machines (wSVMs) have been developed to estimate class probabilities through ensemble learning for $K$-class problems (Wang, Shen and Liu, 2008; Wang, Zhang and Wu, 2019), where $K$ is the number of classes. The estimators are robust and achieve high accuracy for probability estimation, but their learning is implemented through pairwise coupling, which demand polynomial time in $K$. In this paper, we propose two new learning schemes, the baseline learning and the One-vs-All (OVA) learning, to further improve wSVMs in terms of computational efficiency and estimation accuracy. In particular, the baseline learning has optimal computational complexity in the sense that it is linear in $K$. The resulting estimators are distribution-free and shown to be consistent. We further conduct extensive numerical experiments to demonstrate finite sample performance.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022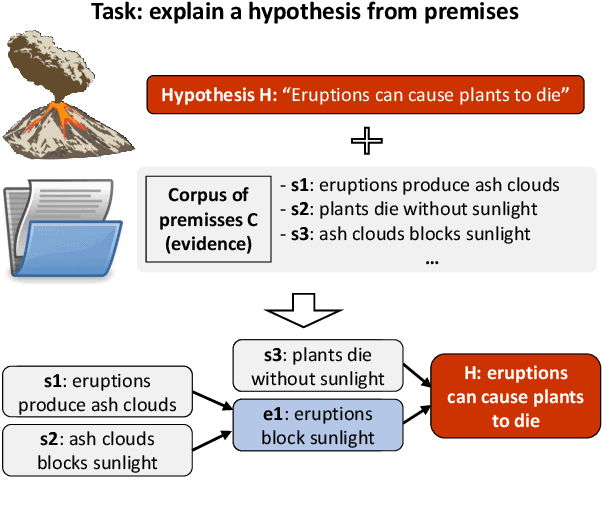
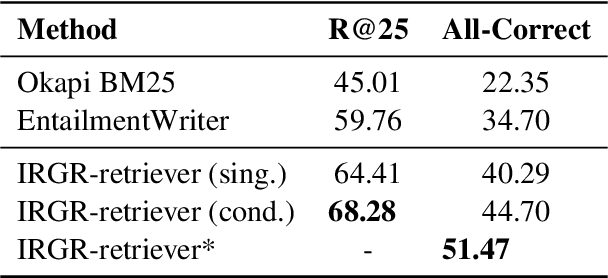
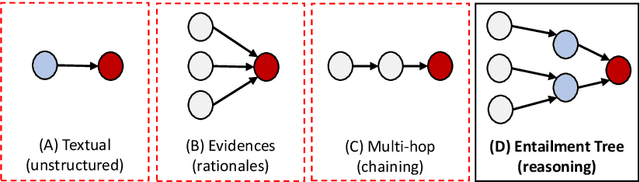
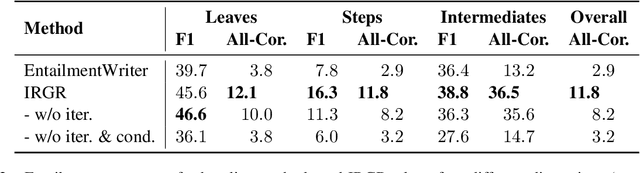
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
Privacy for Free: How does Dataset Condensation Help Privacy?
Jun 01, 2022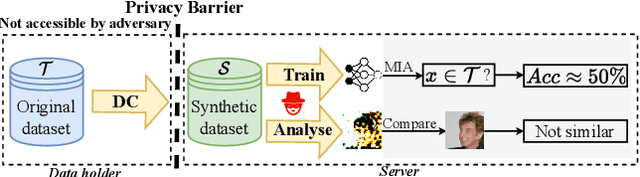
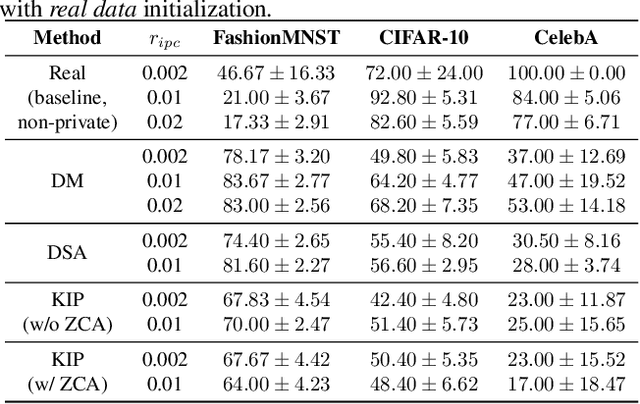
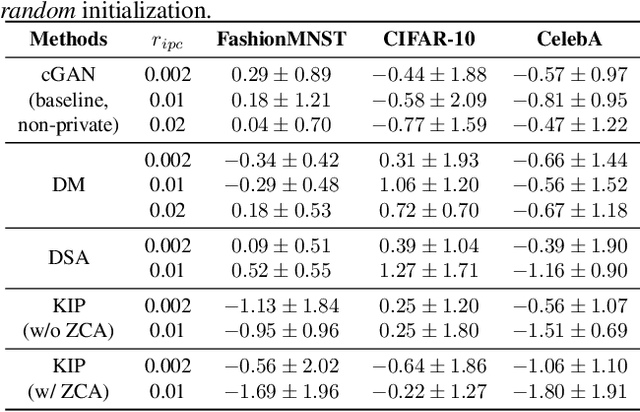
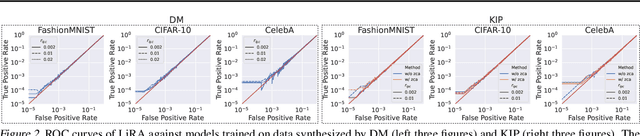
To prevent unintentional data leakage, research community has resorted to data generators that can produce differentially private data for model training. However, for the sake of the data privacy, existing solutions suffer from either expensive training cost or poor generalization performance. Therefore, we raise the question whether training efficiency and privacy can be achieved simultaneously. In this work, we for the first time identify that dataset condensation (DC) which is originally designed for improving training efficiency is also a better solution to replace the traditional data generators for private data generation, thus providing privacy for free. To demonstrate the privacy benefit of DC, we build a connection between DC and differential privacy, and theoretically prove on linear feature extractors (and then extended to non-linear feature extractors) that the existence of one sample has limited impact ($O(m/n)$) on the parameter distribution of networks trained on $m$ samples synthesized from $n (n \gg m)$ raw samples by DC. We also empirically validate the visual privacy and membership privacy of DC-synthesized data by launching both the loss-based and the state-of-the-art likelihood-based membership inference attacks. We envision this work as a milestone for data-efficient and privacy-preserving machine learning.
NanoNet: Real-Time Polyp Segmentation in Video Capsule Endoscopy and Colonoscopy
Apr 22, 2021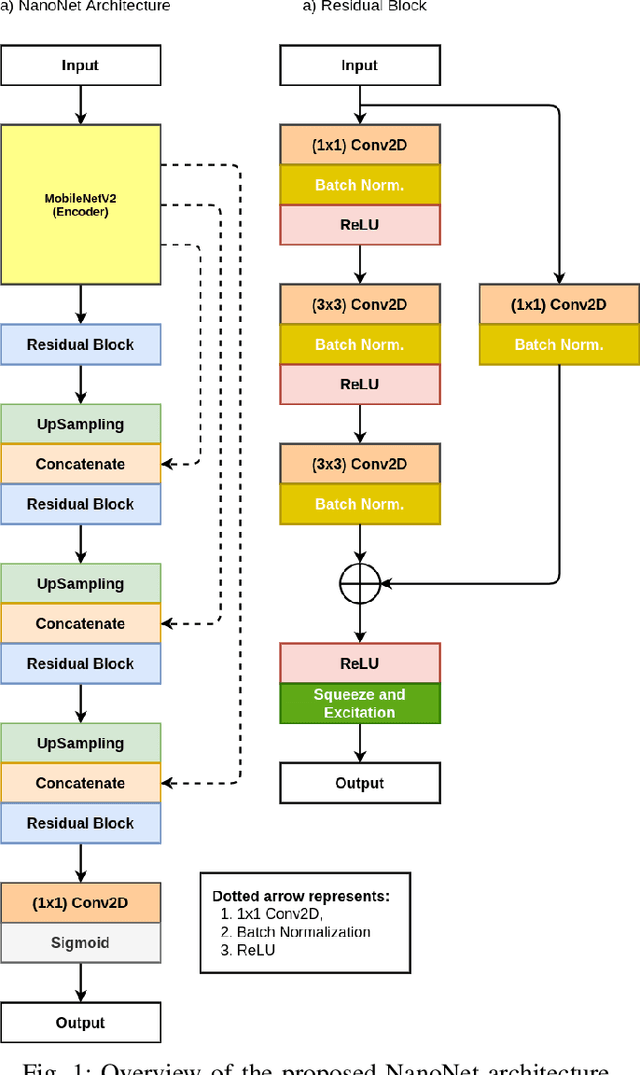
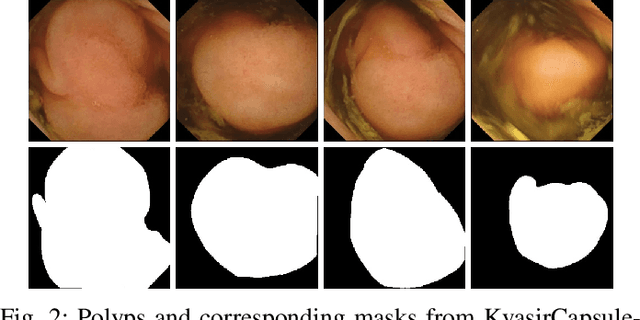
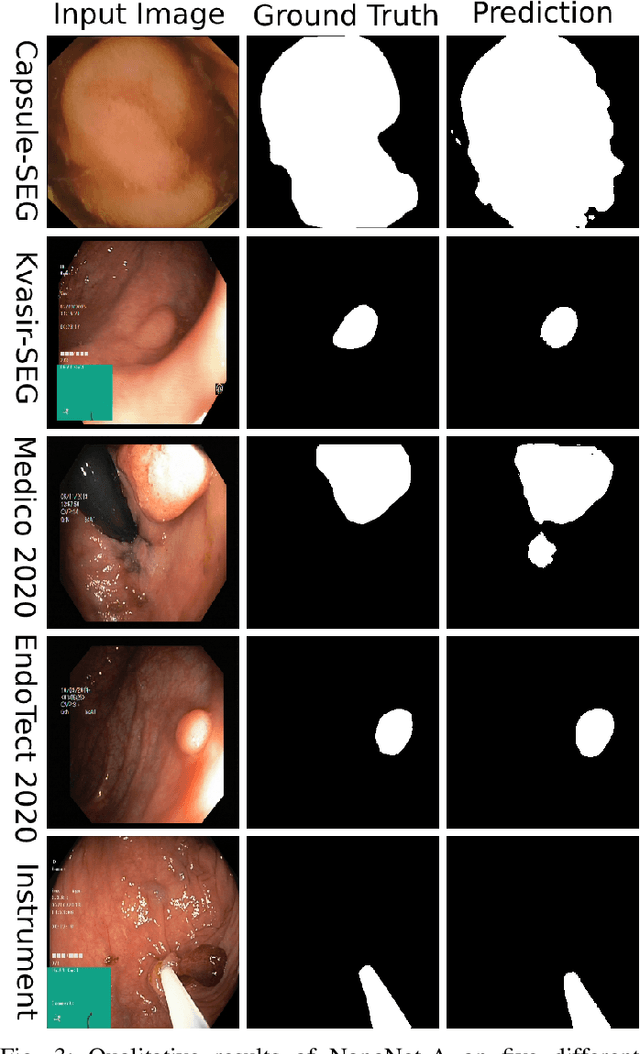

Deep learning in gastrointestinal endoscopy can assist to improve clinical performance and be helpful to assess lesions more accurately. To this extent, semantic segmentation methods that can perform automated real-time delineation of a region-of-interest, e.g., boundary identification of cancer or precancerous lesions, can benefit both diagnosis and interventions. However, accurate and real-time segmentation of endoscopic images is extremely challenging due to its high operator dependence and high-definition image quality. To utilize automated methods in clinical settings, it is crucial to design lightweight models with low latency such that they can be integrated with low-end endoscope hardware devices. In this work, we propose NanoNet, a novel architecture for the segmentation of video capsule endoscopy and colonoscopy images. Our proposed architecture allows real-time performance and has higher segmentation accuracy compared to other more complex ones. We use video capsule endoscopy and standard colonoscopy datasets with polyps, and a dataset consisting of endoscopy biopsies and surgical instruments, to evaluate the effectiveness of our approach. Our experiments demonstrate the increased performance of our architecture in terms of a trade-off between model complexity, speed, model parameters, and metric performances. Moreover, the resulting model size is relatively tiny, with only nearly 36,000 parameters compared to traditional deep learning approaches having millions of parameters.
Collective Relevance Labeling for Passage Retrieval
May 09, 2022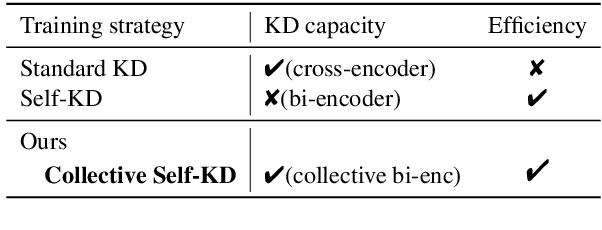
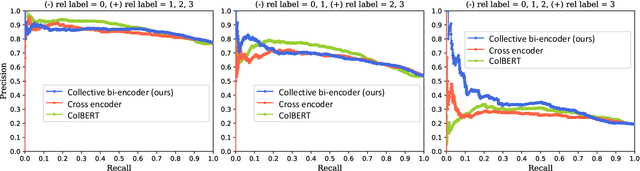
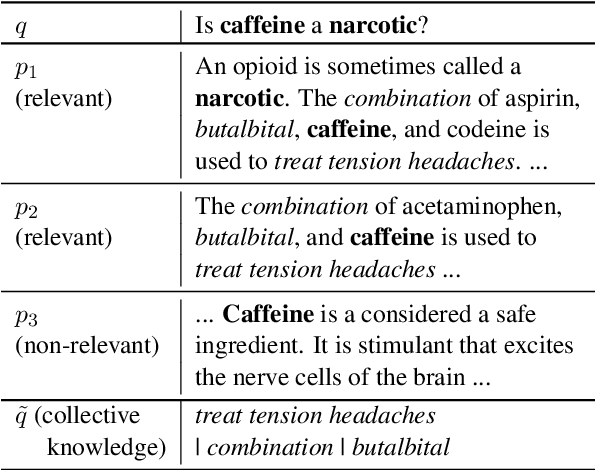
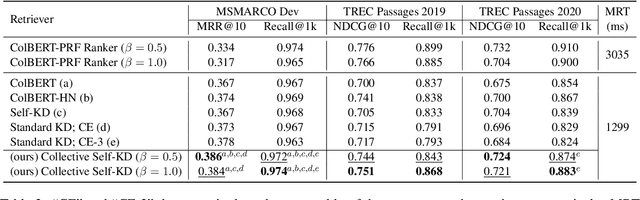
Deep learning for Information Retrieval (IR) requires a large amount of high-quality query-document relevance labels, but such labels are inherently sparse. Label smoothing redistributes some observed probability mass over unobserved instances, often uniformly, uninformed of the true distribution. In contrast, we propose knowledge distillation for informed labeling, without incurring high computation overheads at evaluation time. Our contribution is designing a simple but efficient teacher model which utilizes collective knowledge, to outperform state-of-the-arts distilled from a more complex teacher model. Specifically, we train up to x8 faster than the state-of-the-art teacher, while distilling the rankings better. Our code is publicly available at https://github.com/jihyukkim-nlp/CollectiveKD
Espresso: Revisiting Gradient Compression from the System Perspective
May 28, 2022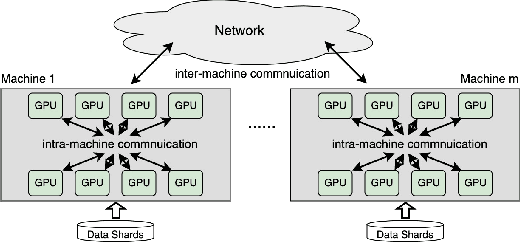
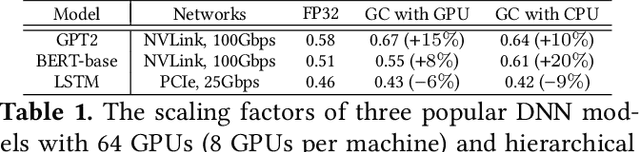


Gradient compression (GC) is a promising approach to addressing the communication bottleneck in distributed deep learning (DDL). However, it is challenging to find the optimal compression strategy for applying GC to DDL because of the intricate interactions among tensors. To fully unleash the benefits of GC, two questions must be addressed: 1) How to express all compression strategies and the corresponding interactions among tensors of any DDL training job? 2) How to quickly select a near-optimal compression strategy? In this paper, we propose Espresso to answer these questions. It first designs a decision tree abstraction to express all the compression strategies and develops empirical models to timeline tensor computation, communication, and compression to enable Espresso to derive the intricate interactions among tensors. It then designs a compression decision algorithm that analyzes tensor interactions to eliminate and prioritize strategies and optimally offloads compression to CPUs. Experimental evaluations show that Espresso can improve the training throughput over the start-of-the-art compression-enabled system by up to 77% for representative DDL training jobs. Moreover, the computational time needed to select the compression strategy is measured in milliseconds, and the selected strategy is only a few percent from optimal.
TLSAN: Time-aware Long- and Short-term Attention Network for Next-item Recommendation
Mar 16, 2021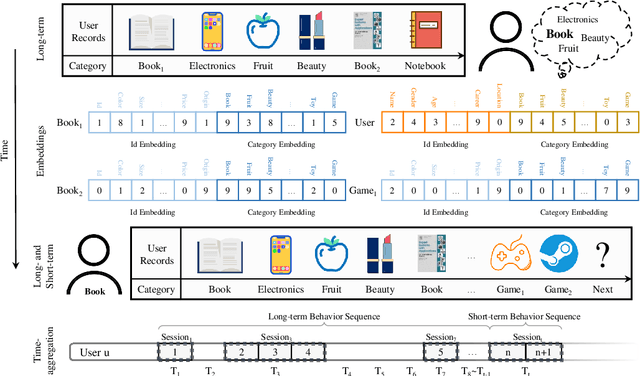

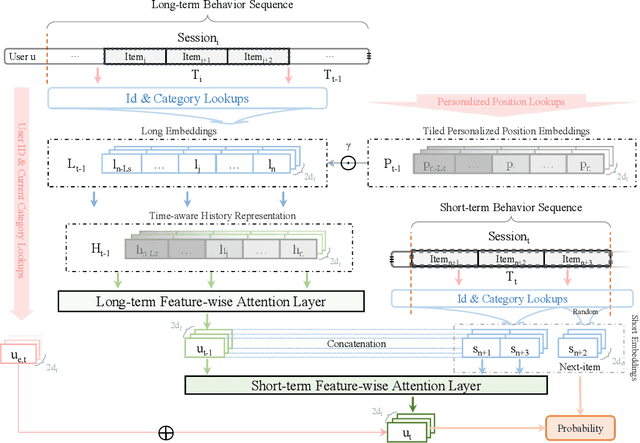
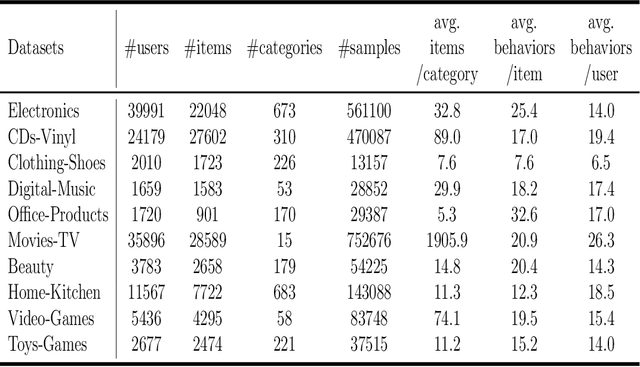
Recently, deep neural networks are widely applied in recommender systems for their effectiveness in capturing/modeling users' preferences. Especially, the attention mechanism in deep learning enables recommender systems to incorporate various features in an adaptive way. Specifically, as for the next item recommendation task, we have the following three observations: 1) users' sequential behavior records aggregate at time positions ("time-aggregation"), 2) users have personalized taste that is related to the "time-aggregation" phenomenon ("personalized time-aggregation"), and 3) users' short-term interests play an important role in the next item prediction/recommendation. In this paper, we propose a new Time-aware Long- and Short-term Attention Network (TLSAN) to address those observations mentioned above. Specifically, TLSAN consists of two main components. Firstly, TLSAN models "personalized time-aggregation" and learn user-specific temporal taste via trainable personalized time position embeddings with category-aware correlations in long-term behaviors. Secondly, long- and short-term feature-wise attention layers are proposed to effectively capture users' long- and short-term preferences for accurate recommendation. Especially, the attention mechanism enables TLSAN to utilize users' preferences in an adaptive way, and its usage in long- and short-term layers enhances TLSAN's ability of dealing with sparse interaction data. Extensive experiments are conducted on Amazon datasets from different fields (also with different size), and the results show that TLSAN outperforms state-of-the-art baselines in both capturing users' preferences and performing time-sensitive next-item recommendation.
Development of Interpretable Machine Learning Models to Detect Arrhythmia based on ECG Data
May 05, 2022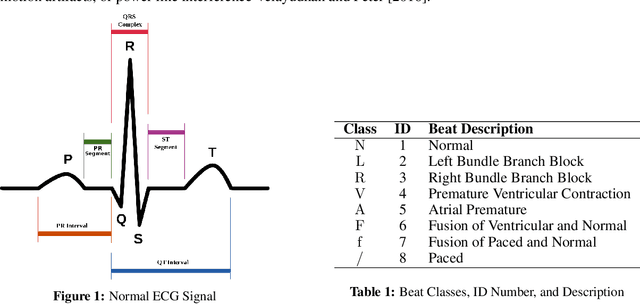
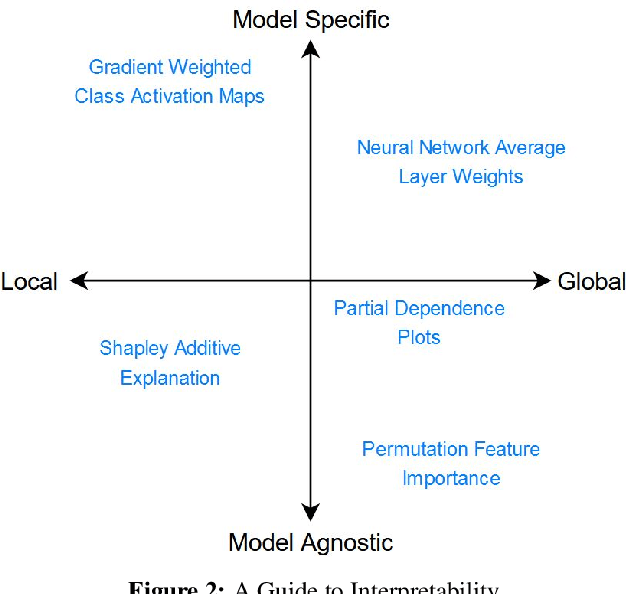
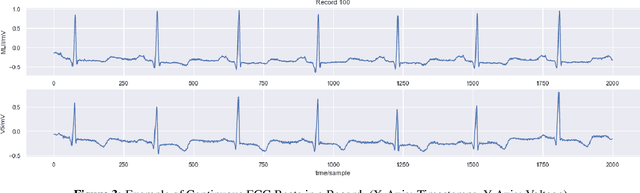

The analysis of electrocardiogram (ECG) signals can be time consuming as it is performed manually by cardiologists. Therefore, automation through machine learning (ML) classification is being increasingly proposed which would allow ML models to learn the features of a heartbeat and detect abnormalities. The lack of interpretability hinders the application of Deep Learning in healthcare. Through interpretability of these models, we would understand how a machine learning algorithm makes its decisions and what patterns are being followed for classification. This thesis builds Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) classifiers based on state-of-the-art models and compares their performance and interpretability to shallow classifiers. Here, both global and local interpretability methods are exploited to understand the interaction between dependent and independent variables across the entire dataset and to examine model decisions in each sample, respectively. Partial Dependence Plots, Shapley Additive Explanations, Permutation Feature Importance, and Gradient Weighted Class Activation Maps (Grad-Cam) are the four interpretability techniques implemented on time-series ML models classifying ECG rhythms. In particular, we exploit Grad-Cam, which is a local interpretability technique and examine whether its interpretability varies between correctly and incorrectly classified ECG beats within each class. Furthermore, the classifiers are evaluated using K-Fold cross-validation and Leave Groups Out techniques, and we use non-parametric statistical testing to examine whether differences are significant. It was found that Grad-CAM was the most effective interpretability technique at explaining predictions of proposed CNN and LSTM models. We concluded that all high performing classifiers looked at the QRS complex of the ECG rhythm when making predictions.