 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Frequency Dynamic Convolution: Frequency-Adaptive Pattern Recognition for Sound Event Detection
Mar 29, 2022
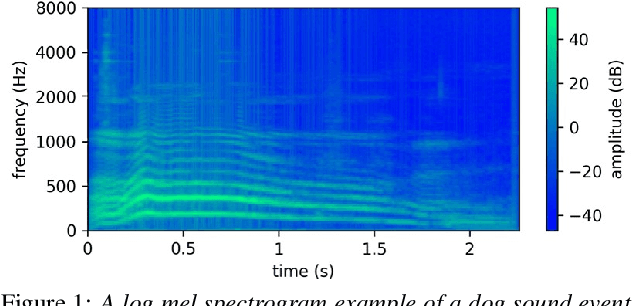
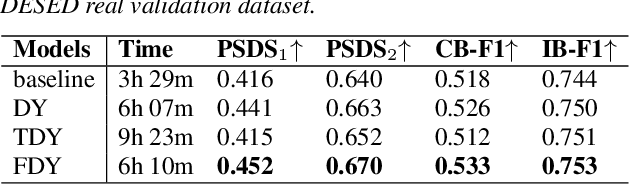
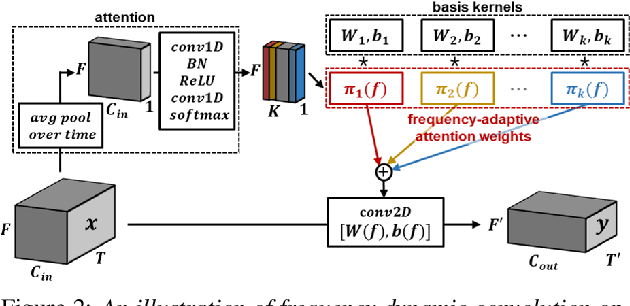
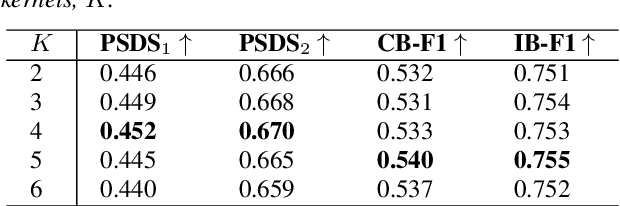
2D convolution is widely used in sound event detection (SED) to recognize 2D patterns of sound events in time-frequency domain. However, 2D convolution enforces translation-invariance on sound events along both time and frequency axis while sound events exhibit frequency-dependent patterns. In order to improve physical inconsistency in 2D convolution on SED, we propose frequency dynamic convolution which applies kernel that adapts to frequency components of input. Frequency dynamic convolution outperforms the baseline model by 6.3% in DESED dataset in terms of polyphonic sound detection score (PSDS). It also significantly outperforms dynamic convolution and temporal dynamic convolution on SED. In addition, by comparing class-wise F1 scores of baseline model and frequency dynamic convolution, we showed that frequency dynamic convolution is especially more effective for detection of non-stationary sound events. From this result, we verified that frequency dynamic convolution is superior in recognizing frequency-dependent patterns as non-stationary sound events show more intricate time-frequency patterns.
Optimal Decision Diagrams for Classification
May 28, 2022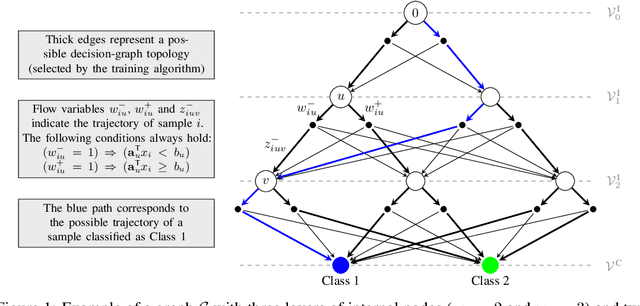
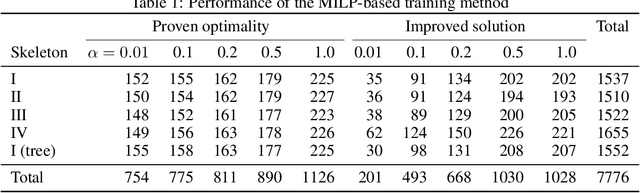
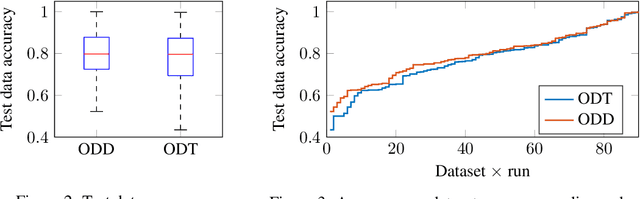
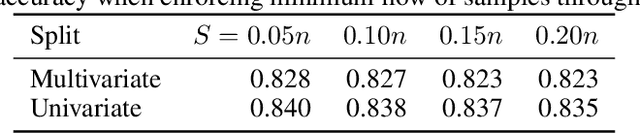
Decision diagrams for classification have some notable advantages over decision trees, as their internal connections can be determined at training time and their width is not bound to grow exponentially with their depth. Accordingly, decision diagrams are usually less prone to data fragmentation in internal nodes. However, the inherent complexity of training these classifiers acted as a long-standing barrier to their widespread adoption. In this context, we study the training of optimal decision diagrams (ODDs) from a mathematical programming perspective. We introduce a novel mixed-integer linear programming model for training and demonstrate its applicability for many datasets of practical importance. Further, we show how this model can be easily extended for fairness, parsimony, and stability notions. We present numerical analyses showing that our model allows training ODDs in short computational times, and that ODDs achieve better accuracy than optimal decision trees, while allowing for improved stability without significant accuracy losses.
Discrete Graph Structure Learning for Forecasting Multiple Time Series
Feb 15, 2021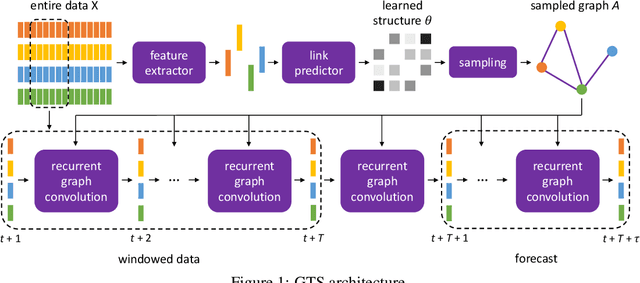
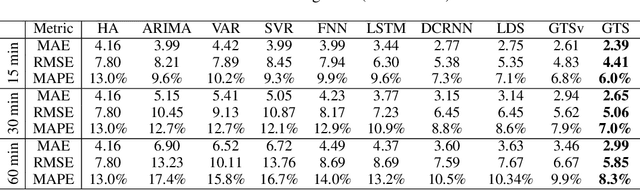
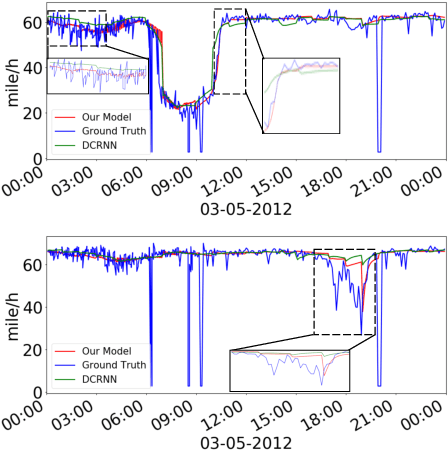
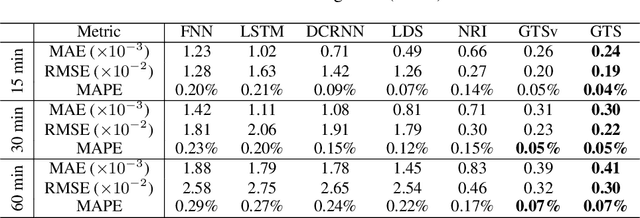
Time series forecasting is an extensively studied subject in statistics, economics, and computer science. Exploration of the correlation and causation among the variables in a multivariate time series shows promise in enhancing the performance of a time series model. When using deep neural networks as forecasting models, we hypothesize that exploiting the pairwise information among multiple (multivariate) time series also improves their forecast. If an explicit graph structure is known, graph neural networks (GNNs) have been demonstrated as powerful tools to exploit the structure. In this work, we propose learning the structure simultaneously with the GNN if the graph is unknown. We cast the problem as learning a probabilistic graph model through optimizing the mean performance over the graph distribution. The distribution is parameterized by a neural network so that discrete graphs can be sampled differentiably through reparameterization. Empirical evaluations show that our method is simpler, more efficient, and better performing than a recently proposed bilevel learning approach for graph structure learning, as well as a broad array of forecasting models, either deep or non-deep learning based, and graph or non-graph based.
Dataset Distillation using Neural Feature Regression
Jun 01, 2022
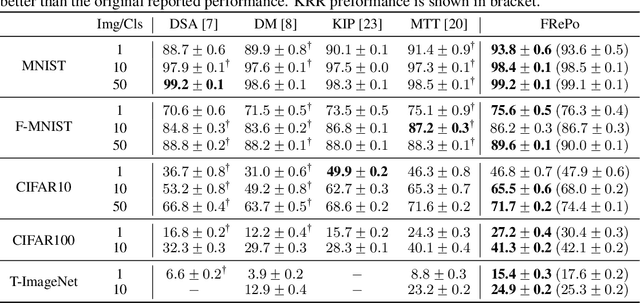
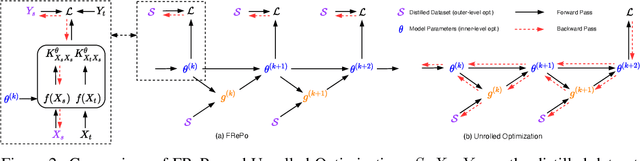

Dataset distillation aims to learn a small synthetic dataset that preserves most of the information from the original dataset. Dataset distillation can be formulated as a bi-level meta-learning problem where the outer loop optimizes the meta-dataset and the inner loop trains a model on the distilled data. Meta-gradient computation is one of the key challenges in this formulation, as differentiating through the inner loop learning procedure introduces significant computation and memory costs. In this paper, we address these challenges using neural Feature Regression with Pooling (FRePo), achieving the state-of-the-art performance with an order of magnitude less memory requirement and two orders of magnitude faster training than previous methods. The proposed algorithm is analogous to truncated backpropagation through time with a pool of models to alleviate various types of overfitting in dataset distillation. FRePo significantly outperforms the previous methods on CIFAR100, Tiny ImageNet, and ImageNet-1K. Furthermore, we show that high-quality distilled data can greatly improve various downstream applications, such as continual learning and membership inference defense.
PoseFusion2: Simultaneous Background Reconstruction and Human Shape Recovery in Real-time
Aug 02, 2021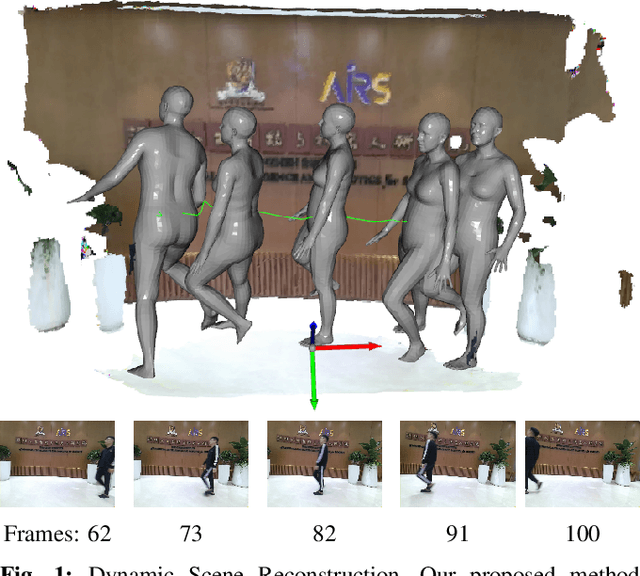



Dynamic environments that include unstructured moving objects pose a hard problem for Simultaneous Localization and Mapping (SLAM) performance. The motion of rigid objects can be typically tracked by exploiting their texture and geometric features. However, humans moving in the scene are often one of the most important, interactive targets - they are very hard to track and reconstruct robustly due to non-rigid shapes. In this work, we present a fast, learning-based human object detector to isolate the dynamic human objects and realise a real-time dense background reconstruction framework. We go further by estimating and reconstructing the human pose and shape. The final output environment maps not only provide the dense static backgrounds but also contain the dynamic human meshes and their trajectories. Our Dynamic SLAM system runs at around 26 frames per second (fps) on GPUs, while additionally turning on accurate human pose estimation can be executed at up to 10 fps.
Forecasting Urban Development from Satellite Images
Apr 27, 2022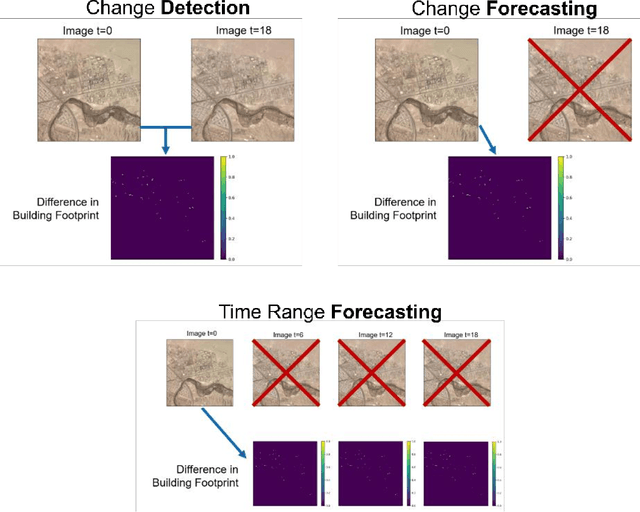
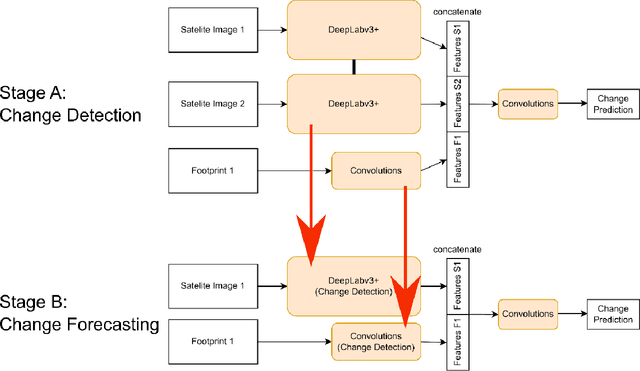
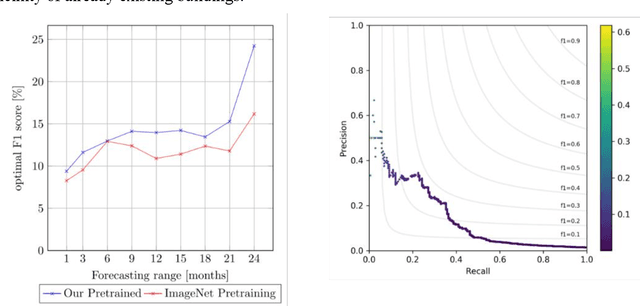
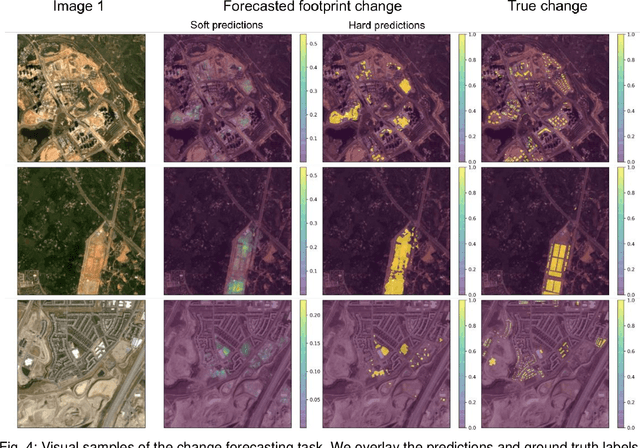
Forecasting where and when new buildings will emerge is a rather unexplored niche topic, but relevant in disciplines such as urban planning, agriculture, resource management, and even autonomous flight. In this work, we present a method that accomplishes this task using satellite images and a custom neural network training procedure. In stage A, a DeepLapv3+ backbone is pretrained through a Siamese network architecture aimed at solving a building change detection task. In stage B, we transfer the backbone into a change forecasting model that relies solely on the initial input image. We also transfer the backbone into a forecasting model predicting the correct time range of the future change. For our experiments, we use the SpaceNet7 dataset with 960 km2 spatial extension and 24 monthly frames. We found that our training strategy consistently outperforms the traditional pretraining on the ImageNet dataset. Especially with longer forecasting ranges of 24 months, we observe F1 scores of 24% instead of 16%. Furthermore, we found that our method performed well in forecasting the times of future building constructions. Hereby, the strengths of our custom pretraining become especially apparent when we increase the difficulty of the task by predicting finer time windows.
Characteristics of Interference in Licensed and Unlicensed Bands for Intelligent Spectrum Management
Jun 17, 2022
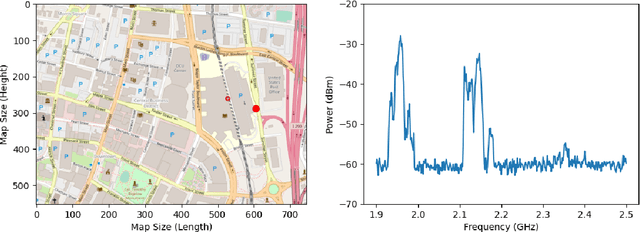
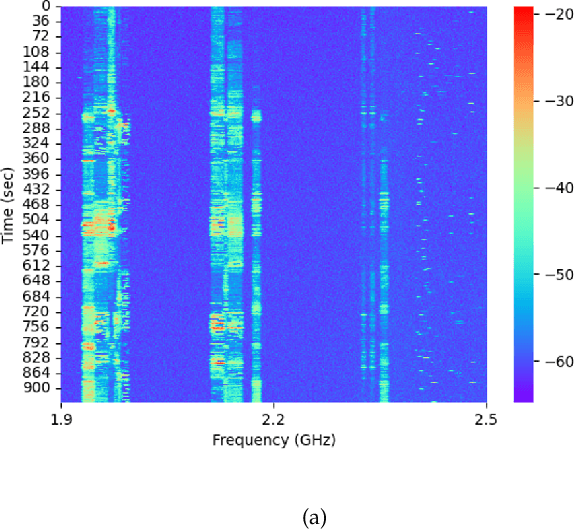
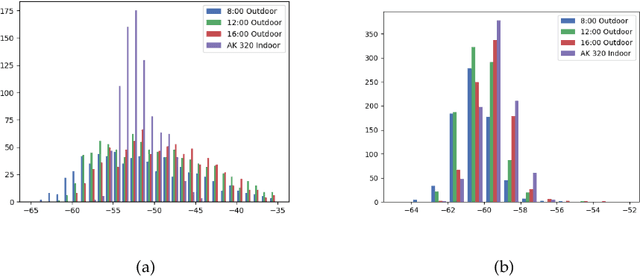
The exponential growth of IoT devices and the demand of smart devices for higher data rates has heightened the need for sharing and managing spectrum resources in cellular 5G/6G operating in licensed bands and Wi-Fi technologies operating in unlicensed bands. Intelligent spectrum management has emerged as a key concept in dynamic spectrum allocation. To understand the interference existing in the spectrum, researchers usually monitor the interference in a fixed location and either focus on the cellular band or Wi-Fi band. In this study, we conduct experiments for collecting real-time spectrum data in indoor and outdoor environments with a mobile receiver, the spectrum analyzer. For outdoor, we mount the spectrum analyzer on a car seat and drive on the selected route in an urban area. We put the analyzer on a cart and moved it around in the laboratory for indoor. The frequency of interest in this study is 1.9 - 2.5 GHz, including both licensed and unlicensed bands. Temporal and frequency domain behavior is compared between licensed and unlicensed bands. We first normalize and binarize the data with a threshold. Then we calculate the spectrum occupancy by counting how many consecutive ones. Based on our observation, the spectrum occupancy of the outdoor environment is more remarkable than the indoor environment. The interference in the licensed band shows more variations in the frequency domain than that in the unlicensed band. This study provides a better understanding of the interference behavior for different environments and frequency bands.
Speech Artifact Removal from EEG Recordings of Spoken Word Production with Tensor Decomposition
Jun 01, 2022
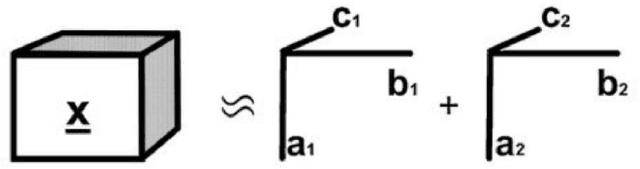
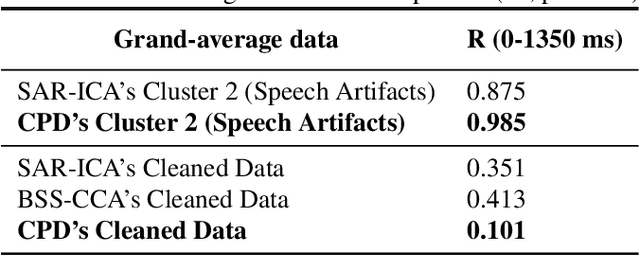
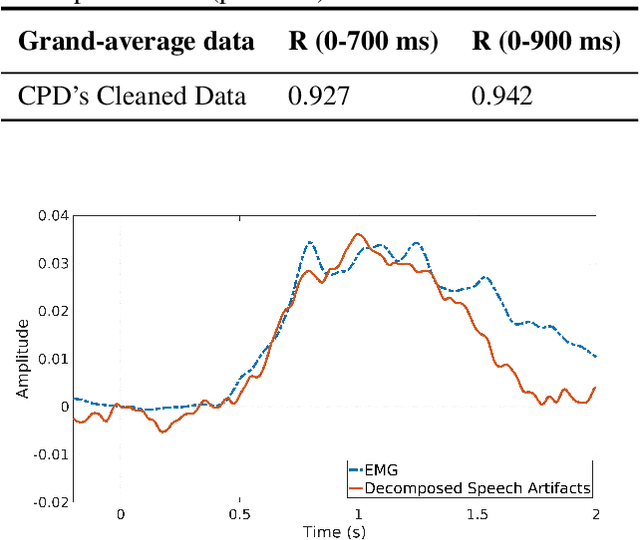
Research about brain activities involving spoken word production is considerably underdeveloped because of the undiscovered characteristics of speech artifacts, which contaminate electroencephalogram (EEG) signals and prevent the inspection of the underlying cognitive processes. To fuel further EEG research with speech production, a method using three-mode tensor decomposition (time x space x frequency) is proposed to perform speech artifact removal. Tensor decomposition enables simultaneous inspection of multiple modes, which suits the multi-way nature of EEG data. In a picture-naming task, we collected raw data with speech artifacts by placing two electrodes near the mouth to record lip EMG. Based on our evaluation, which calculated the correlation values between grand-averaged speech artifacts and the lip EMG, tensor decomposition outperformed the former methods that were based on independent component analysis (ICA) and blind source separation (BSS), both in detecting speech artifact (0.985) and producing clean data (0.101). Our proposed method correctly preserved the components unrelated to speech, which was validated by computing the correlation value between the grand-averaged raw data without EOG and cleaned data before the speech onset (0.92-0.94).
Queried Unlabeled Data Improves and Robustifies Class-Incremental Learning
Jun 17, 2022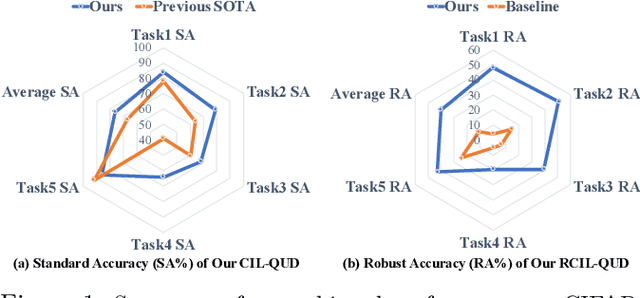
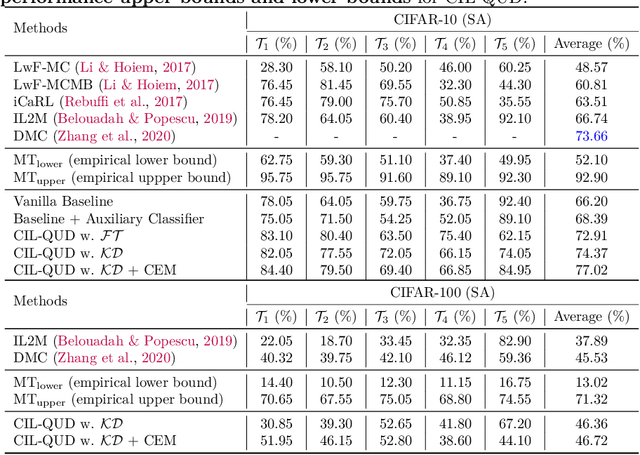
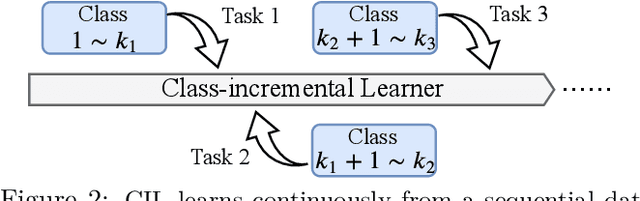
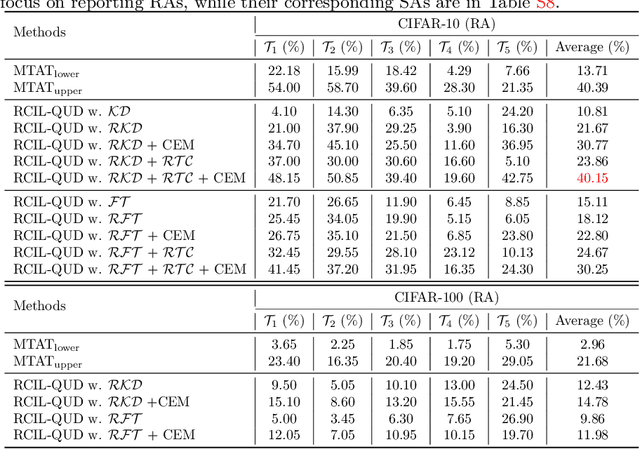
Class-incremental learning (CIL) suffers from the notorious dilemma between learning newly added classes and preserving previously learned class knowledge. That catastrophic forgetting issue could be mitigated by storing historical data for replay, which yet would cause memory overheads as well as imbalanced prediction updates. To address this dilemma, we propose to leverage "free" external unlabeled data querying in continual learning. We first present a CIL with Queried Unlabeled Data (CIL-QUD) scheme, where we only store a handful of past training samples as anchors and use them to query relevant unlabeled examples each time. Along with new and past stored data, the queried unlabeled are effectively utilized, through learning-without-forgetting (LwF) regularizers and class-balance training. Besides preserving model generalization over past and current tasks, we next study the problem of adversarial robustness for CIL-QUD. Inspired by the recent success of learning robust models with unlabeled data, we explore a new robustness-aware CIL setting, where the learned adversarial robustness has to resist forgetting and be transferred as new tasks come in continually. While existing options easily fail, we show queried unlabeled data can continue to benefit, and seamlessly extend CIL-QUD into its robustified versions, RCIL-QUD. Extensive experiments demonstrate that CIL-QUD achieves substantial accuracy gains on CIFAR-10 and CIFAR-100, compared to previous state-of-the-art CIL approaches. Moreover, RCIL-QUD establishes the first strong milestone for robustness-aware CIL. Codes are available in https://github.com/VITA-Group/CIL-QUD.
Towards on-sky adaptive optics control using reinforcement learning
May 16, 2022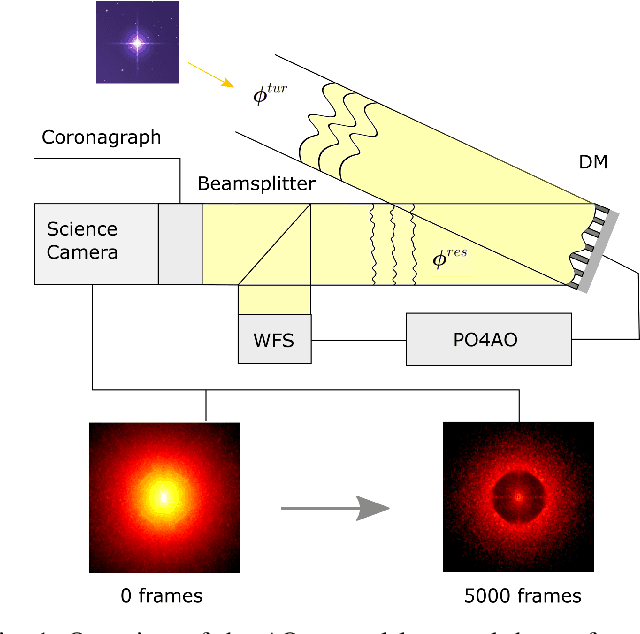
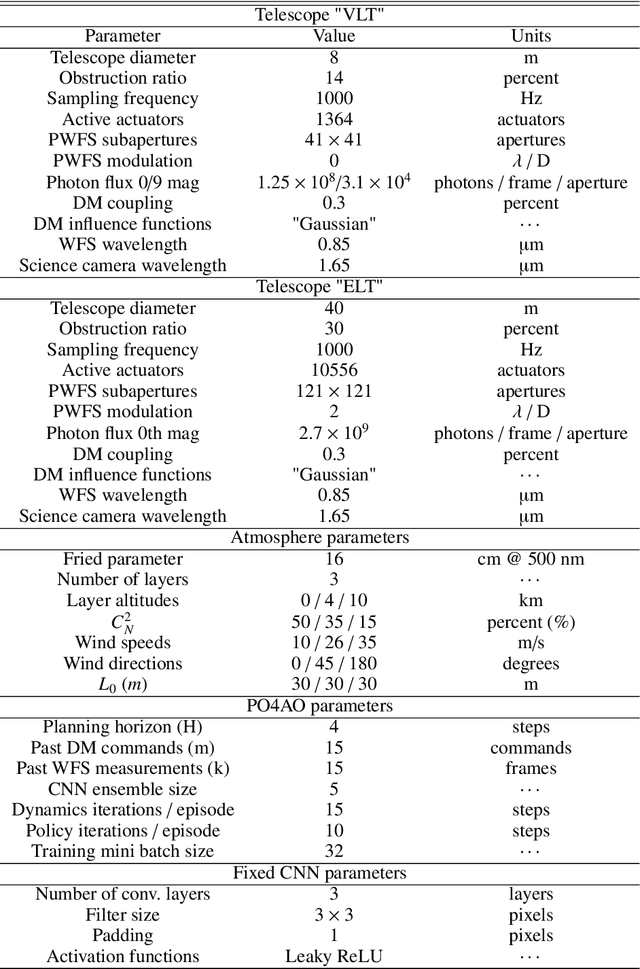
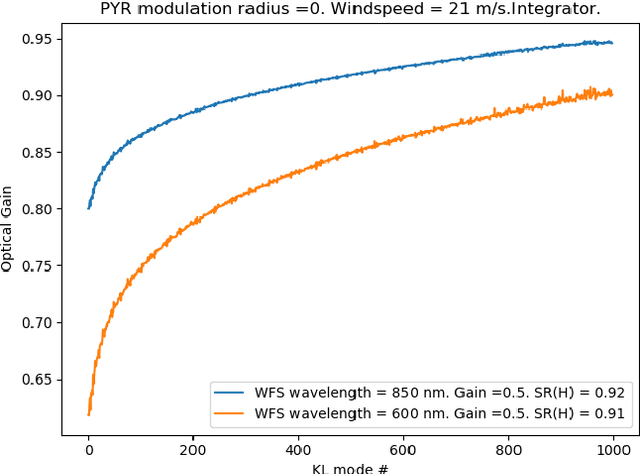

The direct imaging of potentially habitable Exoplanets is one prime science case for the next generation of high contrast imaging instruments on ground-based extremely large telescopes. To reach this demanding science goal, the instruments are equipped with eXtreme Adaptive Optics (XAO) systems which will control thousands of actuators at a framerate of kilohertz to several kilohertz. Most of the habitable exoplanets are located at small angular separations from their host stars, where the current XAO systems' control laws leave strong residuals.Current AO control strategies like static matrix-based wavefront reconstruction and integrator control suffer from temporal delay error and are sensitive to mis-registration, i.e., to dynamic variations of the control system geometry. We aim to produce control methods that cope with these limitations, provide a significantly improved AO correction and, therefore, reduce the residual flux in the coronagraphic point spread function. We extend previous work in Reinforcement Learning for AO. The improved method, called PO4AO, learns a dynamics model and optimizes a control neural network, called a policy. We introduce the method and study it through numerical simulations of XAO with Pyramid wavefront sensing for the 8-m and 40-m telescope aperture cases. We further implemented PO4AO and carried out experiments in a laboratory environment using MagAO-X at the Steward laboratory. PO4AO provides the desired performance by improving the coronagraphic contrast in numerical simulations by factors 3-5 within the control region of DM and Pyramid WFS, in simulation and in the laboratory. The presented method is also quick to train, i.e., on timescales of typically 5-10 seconds, and the inference time is sufficiently small (< ms) to be used in real-time control for XAO with currently available hardware even for extremely large telescopes.