 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ontology-Mediated Querying on Databases of Bounded Cliquewidth
May 04, 2022
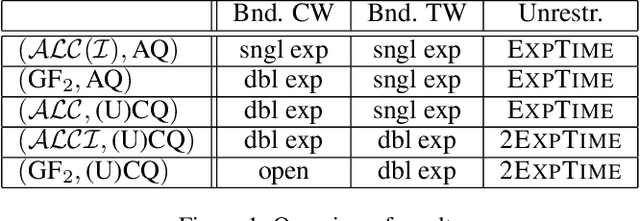
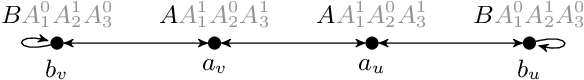
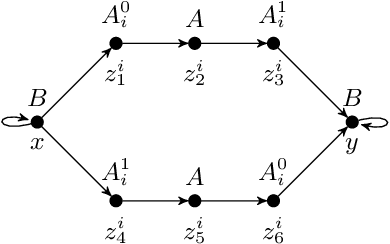
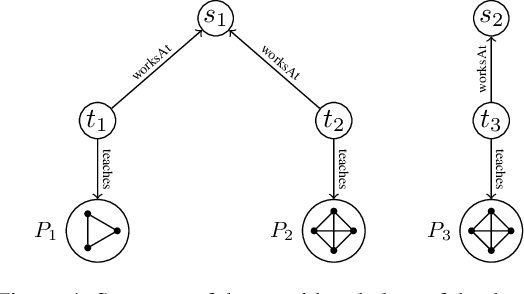
We study the evaluation of ontology-mediated queries (OMQs) on databases of bounded cliquewidth from the viewpoint of parameterized complexity theory. As the ontology language, we consider the description logics $\mathcal{ALC}$ and $\mathcal{ALCI}$ as well as the guarded two-variable fragment GF$_2$ of first-order logic. Queries are atomic queries (AQs), conjunctive queries (CQs), and unions of CQs. All studied OMQ problems are fixed-parameter linear (FPL) when the parameter is the size of the OMQ plus the cliquewidth. Our main contribution is a detailed analysis of the dependence of the running time on the parameter, exhibiting several interesting effects.
Quantum Transfer Learning for Wi-Fi Sensing
May 17, 2022
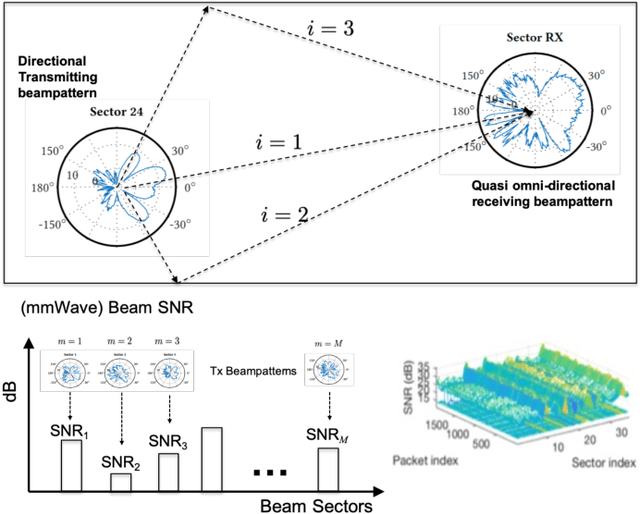
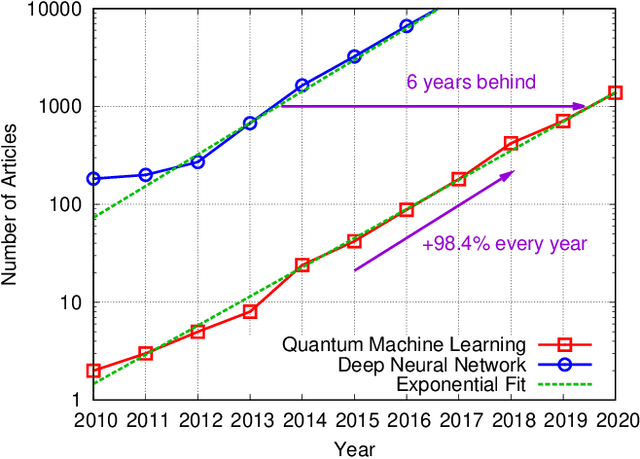
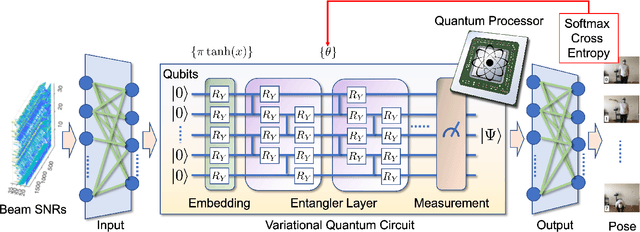
Beyond data communications, commercial-off-the-shelf Wi-Fi devices can be used to monitor human activities, track device locomotion, and sense the ambient environment. In particular, spatial beam attributes that are inherently available in the 60-GHz IEEE 802.11ad/ay standards have shown to be effective in terms of overhead and channel measurement granularity for these indoor sensing tasks. In this paper, we investigate transfer learning to mitigate domain shift in human monitoring tasks when Wi-Fi settings and environments change over time. As a proof-of-concept study, we consider quantum neural networks (QNN) as well as classical deep neural networks (DNN) for the future quantum-ready society. The effectiveness of both DNN and QNN is validated by an in-house experiment for human pose recognition, achieving greater than 90% accuracy with a limited data size.
Turing's cascade instability supports the coordination of the mind, brain, and behavior
Apr 17, 2022
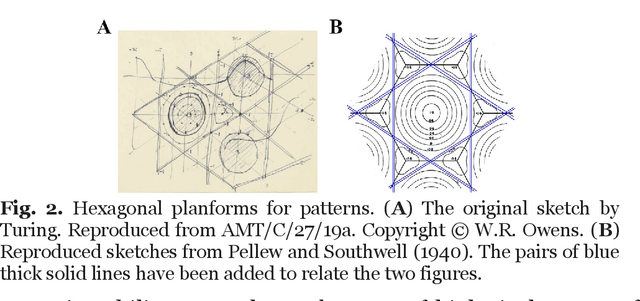

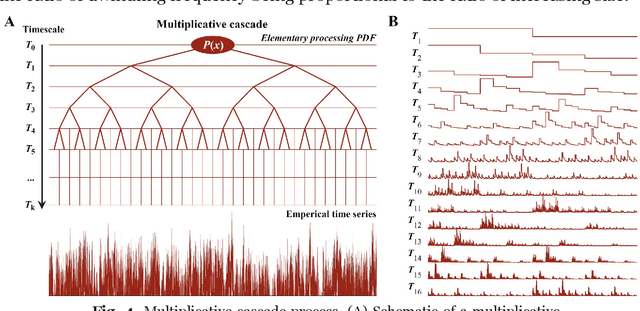
Turing inspired a computer metaphor of the mind and brain that has been handy and has spawned decades of empirical investigation, but he did much more and offered behavioral and cognitive sciences another metaphor--that of the cascade. The time has come to confront Turing's cascading instability, which suggests a geometrical framework driven by power laws and can be studied using multifractal formalism and multiscale probability density function analysis. Here, we review a rapidly growing body of scientific investigations revealing signatures of cascade instability and their consequences for a perceiving, acting, and thinking organism. We review work related to executive functioning (planning to act), postural control (bodily poise for turning plans into action), and effortful perception (action to gather information in a single modality and action to blend multimodal information). We also review findings on neuronal avalanches in the brain, specifically about neural participation in body-wide cascades. Turing's cascade instability blends the mind, brain, and behavior across space and time scales and provides an alternative to the dominant computer metaphor.
Accelerated Gradient Tracking over Time-varying Graphs for Decentralized Optimization
Apr 06, 2021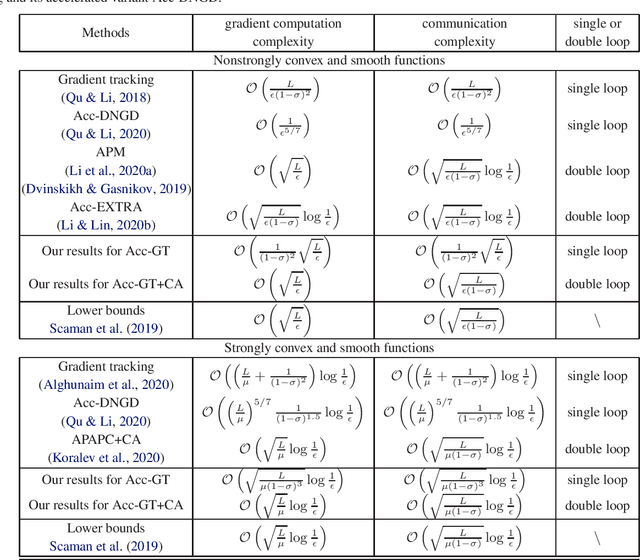
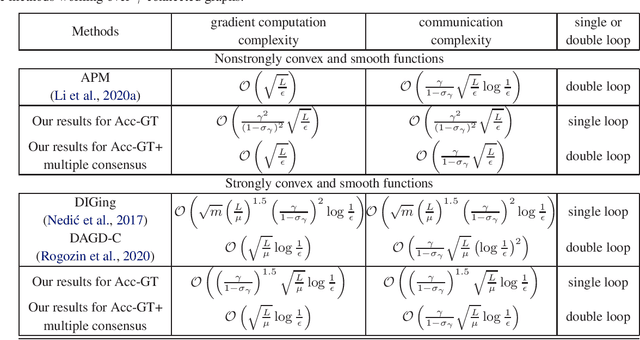
Decentralized optimization over time-varying graphs has been increasingly common in modern machine learning with massive data stored on millions of mobile devices, such as in federated learning. This paper revisits and extends the widely used accelerated gradient tracking. We prove the $\cal O(\frac{\gamma^2}{(1-\sigma_{\gamma})^2}\sqrt{\frac{L}{\epsilon}})$ and $\cal O((\frac{\gamma}{1-\sigma_{\gamma}})^{1.5}\sqrt{\frac{L}{\mu}}\log\frac{1}{\epsilon})$ complexities for the practical single loop accelerated gradient tracking over time-varying graphs when the problems are nonstrongly convex and strongly convex, respectively, where $\gamma$ and $\sigma_{\gamma}$ are two common constants charactering the network connectivity, $\epsilon$ is the desired precision, and $L$ and $\mu$ are the smoothness and strong convexity constants, respectively. Our complexities improve significantly on the ones of $\cal O(\frac{1}{\epsilon^{5/7}})$ and $\cal O((\frac{L}{\mu})^{5/7}\frac{1}{(1-\sigma)^{1.5}}\log\frac{1}{\epsilon})$ proved in the original literature only for static graph. When combining with a multiple consensus subroutine, the dependence on the network connectivity constants can be further improved. When the network is time-invariant, our complexities exactly match the lower bounds without hiding any poly-logarithmic factor for both nonstrongly convex and strongly convex problems.
Continuously-Tempered PDMP Samplers
May 29, 2022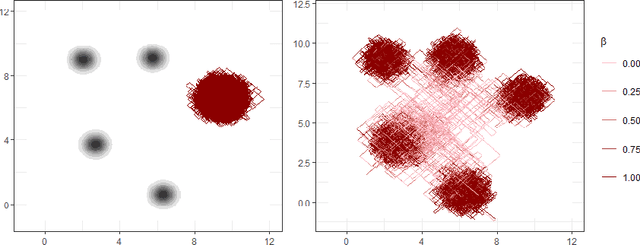
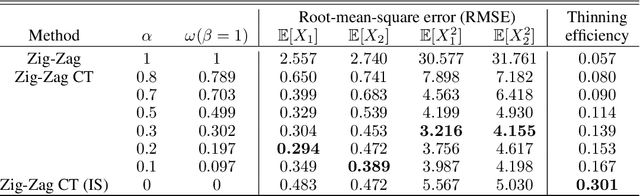
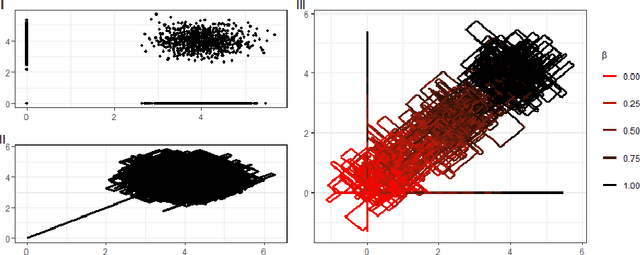
New sampling algorithms based on simulating continuous-time stochastic processes called piece-wise deterministic Markov processes (PDMPs) have shown considerable promise. However, these methods can struggle to sample from multi-modal or heavy-tailed distributions. We show how tempering ideas can improve the mixing of PDMPs in such cases. We introduce an extended distribution defined over the state of the posterior distribution and an inverse temperature, which interpolates between a tractable distribution when the inverse temperature is 0 and the posterior when the inverse temperature is 1. The marginal distribution of the inverse temperature is a mixture of a continuous distribution on [0,1) and a point mass at 1: which means that we obtain samples when the inverse temperature is 1, and these are draws from the posterior, but sampling algorithms will also explore distributions at lower temperatures which will improve mixing. We show how PDMPs, and particularly the Zig-Zag sampler, can be implemented to sample from such an extended distribution. The resulting algorithm is easy to implement and we show empirically that it can outperform existing PDMP-based samplers on challenging multimodal posteriors.
Explorative Data Analysis of Time Series based AlgorithmFeatures of CMA-ES Variants
Apr 16, 2021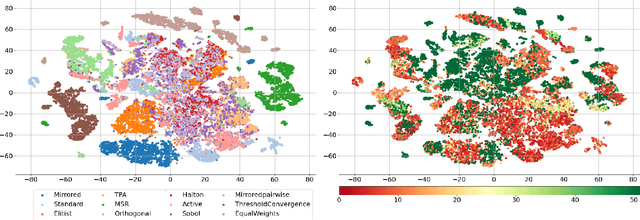
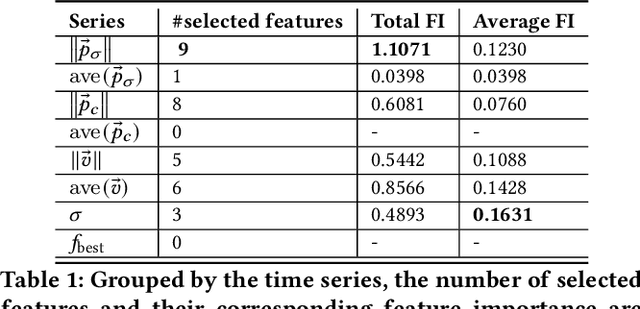
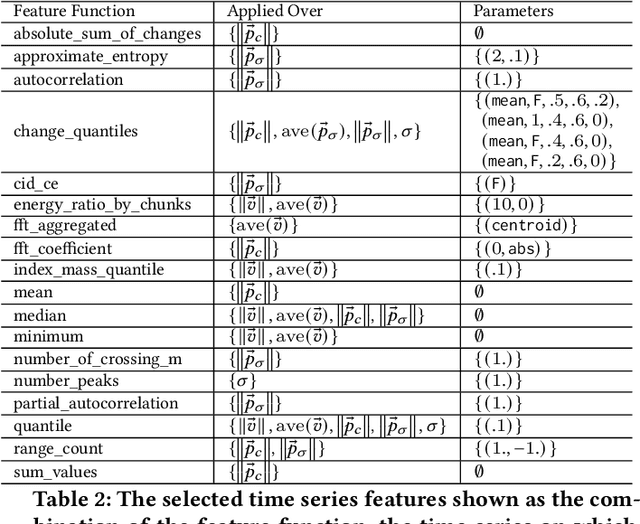
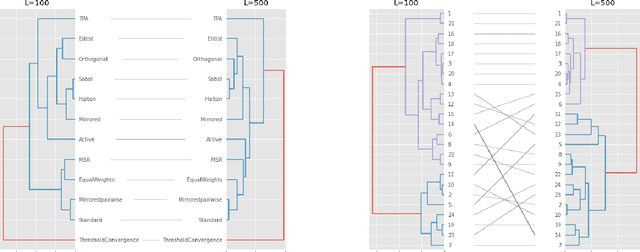
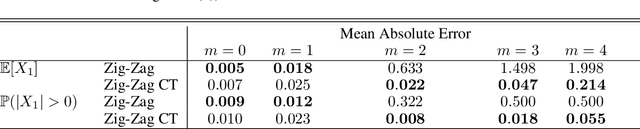
In this study, we analyze behaviours of the well-known CMA-ES by extracting the time-series features on its dynamic strategy parameters. An extensive experiment was conducted on twelve CMA-ES variants and 24 test problems taken from the BBOB (Black-Box Optimization Bench-marking) testbed, where we used two different cutoff times to stop those variants. We utilized the tsfresh package for extracting the features and performed the feature selection procedure using the Boruta algorithm, resulting in 32 features to distinguish either CMA-ES variants or the problems. After measuring the number of predefined targets reached by those variants, we contrive to predict those measured values on each test problem using the feature. From our analysis, we saw that the features can classify the CMA-ES variants, or the function groups decently, and show a potential for predicting the performance of those variants. We conducted a hierarchical clustering analysis on the test problems and noticed a drastic change in the clustering outcome when comparing the longer cutoff time to the shorter one, indicating a huge change in search behaviour of the algorithm. In general, we found that with longer time series, the predictive power of the time series features increase.
Explainability-by-Design: A Methodology to Support Explanations in Decision-Making Systems
Jun 13, 2022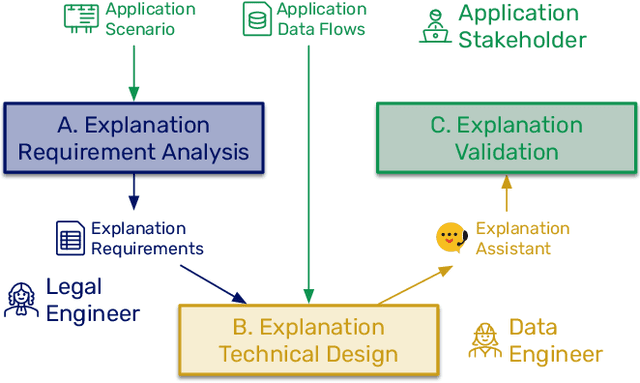

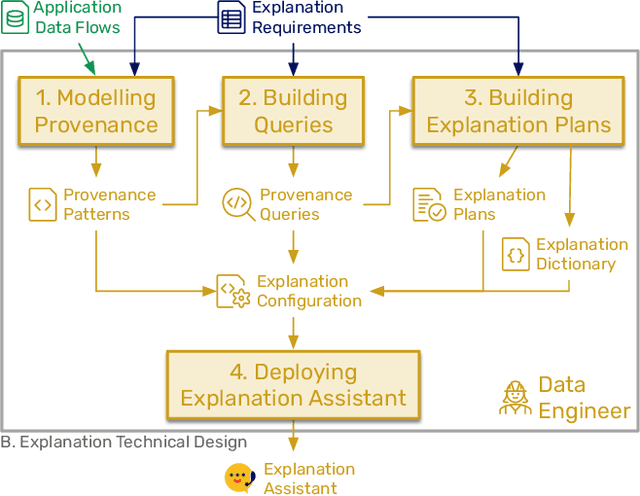

Algorithms play a key role nowadays in many technological systems that control or affect various aspects of our lives. As a result, providing explanations to address the needs of users and organisations is increasingly expected by the laws and regulations, codes of conduct, and the public. However, as laws and regulations do not prescribe how to meet such expectations, organisations are often left to devise their own approaches to explainability, inevitably increasing the cost of compliance and good governance. Hence, we put forth "Explainability by Design", a holistic methodology characterised by proactive measures to include explanation capability in the design of decision-making systems. This paper describes the technical steps of the Explainability-by-Design methodology in a software engineering workflow to implement explanation capability from requirements elicited by domain experts for a specific application context. Outputs of the Explainability-by-Design methodology are a set of configurations, allowing a reusable service, called the Explanation Assistant, to exploit logs provided by applications and create provenance traces that can be queried to extract relevant data points, which in turn can be used in explanation plans to construct explanations personalised to their consumers. Following those steps, organisations will be able to design their decision-making systems to produce explanations that meet the specified requirements, be it from laws, regulations, or business needs. We apply the methodology to two applications, resulting in a deployment of the Explanation Assistant demonstrating explanations capabilities. Finally, the associated development costs are measured, showing that the approach to construct explanations is tractable in terms of development time, which can be as low as two hours per explanation sentence.
Transformer with Memory Replay
May 19, 2022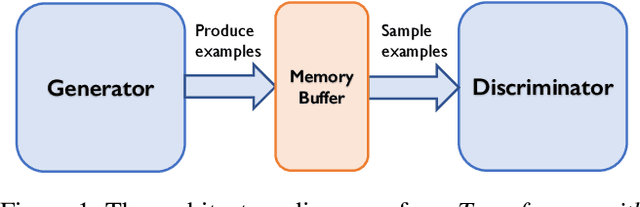

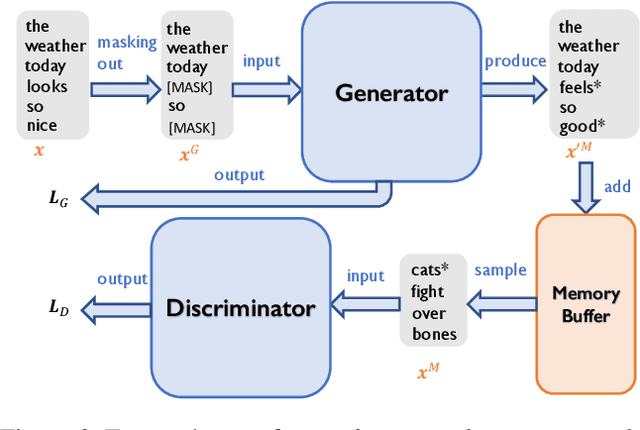
Transformers achieve state-of-the-art performance for natural language processing tasks by pre-training on large-scale text corpora. They are extremely compute-intensive and have very high sample complexity. Memory replay is a mechanism that remembers and reuses past examples by saving to and replaying from a memory buffer. It has been successfully used in reinforcement learning and GANs due to better sample efficiency. In this paper, we propose \emph{Transformer with Memory Replay} (TMR), which integrates memory replay with transformer, making transformer more sample-efficient. Experiments on GLUE and SQuAD benchmark datasets show that Transformer with Memory Replay achieves at least $1\%$ point increase compared to the baseline transformer model when pretrained with the same number of examples. Further, by adopting a careful design that reduces the wall-clock time overhead of memory replay, we also empirically achieve a better runtime efficiency.
Spikemax: Spike-based Loss Methods for Classification
May 19, 2022



Spiking Neural Networks~(SNNs) are a promising research paradigm for low power edge-based computing. Recent works in SNN backpropagation has enabled training of SNNs for practical tasks. However, since spikes are binary events in time, standard loss formulations are not directly compatible with spike output. As a result, current works are limited to using mean-squared loss of spike count. In this paper, we formulate the output probability interpretation from the spike count measure and introduce spike-based negative log-likelihood measure which are more suited for classification tasks especially in terms of the energy efficiency and inference latency. We compare our loss measures with other existing alternatives and evaluate using classification performances on three neuromorphic benchmark datasets: NMNIST, DVS Gesture and N-TIDIGITS18. In addition, we demonstrate state of the art performances on these datasets, achieving faster inference speed and less energy consumption.
SyntheX: Scaling Up Learning-based X-ray Image Analysis Through In Silico Experiments
Jun 13, 2022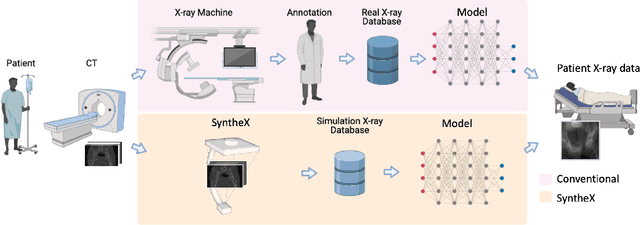

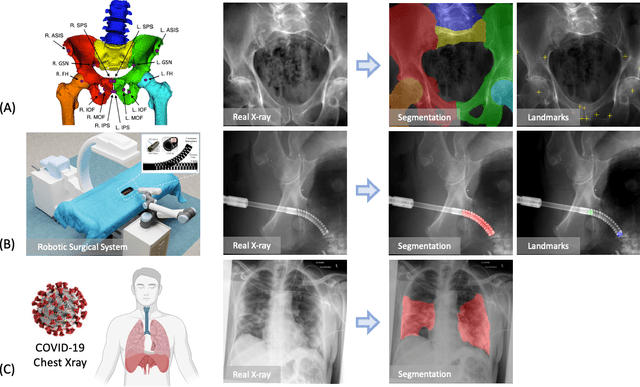

Artificial intelligence (AI) now enables automated interpretation of medical images for clinical use. However, AI's potential use for interventional images (versus those involved in triage or diagnosis), such as for guidance during surgery, remains largely untapped. This is because surgical AI systems are currently trained using post hoc analysis of data collected during live surgeries, which has fundamental and practical limitations, including ethical considerations, expense, scalability, data integrity, and a lack of ground truth. Here, we demonstrate that creating realistic simulated images from human models is a viable alternative and complement to large-scale in situ data collection. We show that training AI image analysis models on realistically synthesized data, combined with contemporary domain generalization or adaptation techniques, results in models that on real data perform comparably to models trained on a precisely matched real data training set. Because synthetic generation of training data from human-based models scales easily, we find that our model transfer paradigm for X-ray image analysis, which we refer to as SyntheX, can even outperform real data-trained models due to the effectiveness of training on a larger dataset. We demonstrate the potential of SyntheX on three clinical tasks: Hip image analysis, surgical robotic tool detection, and COVID-19 lung lesion segmentation. SyntheX provides an opportunity to drastically accelerate the conception, design, and evaluation of intelligent systems for X-ray-based medicine. In addition, simulated image environments provide the opportunity to test novel instrumentation, design complementary surgical approaches, and envision novel techniques that improve outcomes, save time, or mitigate human error, freed from the ethical and practical considerations of live human data collection.