 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Regularized Gradient Descent Ascent for Two-Player Zero-Sum Markov Games
May 27, 2022
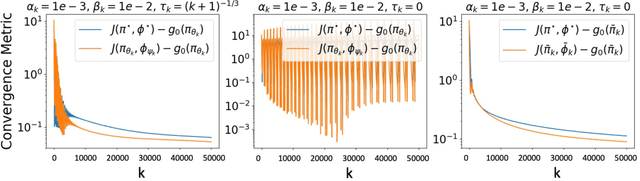
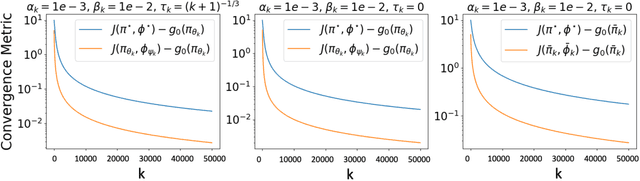
We study the problem of finding the Nash equilibrium in a two-player zero-sum Markov game. Due to its formulation as a minimax optimization program, a natural approach to solve the problem is to perform gradient descent/ascent with respect to each player in an alternating fashion. However, due to the non-convexity/non-concavity of the underlying objective function, theoretical understandings of this method are limited. In our paper, we consider solving an entropy-regularized variant of the Markov game. The regularization introduces structure into the optimization landscape that make the solutions more identifiable and allow the problem to be solved more efficiently. Our main contribution is to show that under proper choices of the regularization parameter, the gradient descent ascent algorithm converges to the Nash equilibrium of the original unregularized problem. We explicitly characterize the finite-time performance of the last iterate of our algorithm, which vastly improves over the existing convergence bound of the gradient descent ascent algorithm without regularization. Finally, we complement the analysis with numerical simulations that illustrate the accelerated convergence of the algorithm.
PolypConnect: Image inpainting for generating realistic gastrointestinal tract images with polyps
May 30, 2022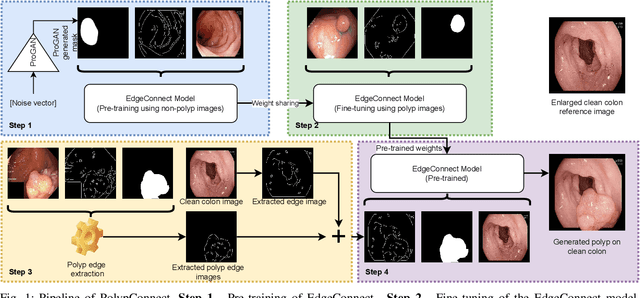



Early identification of a polyp in the lower gastrointestinal (GI) tract can lead to prevention of life-threatening colorectal cancer. Developing computer-aided diagnosis (CAD) systems to detect polyps can improve detection accuracy and efficiency and save the time of the domain experts called endoscopists. Lack of annotated data is a common challenge when building CAD systems. Generating synthetic medical data is an active research area to overcome the problem of having relatively few true positive cases in the medical domain. To be able to efficiently train machine learning (ML) models, which are the core of CAD systems, a considerable amount of data should be used. In this respect, we propose the PolypConnect pipeline, which can convert non-polyp images into polyp images to increase the size of training datasets for training. We present the whole pipeline with quantitative and qualitative evaluations involving endoscopists. The polyp segmentation model trained using synthetic data, and real data shows a 5.1% improvement of mean intersection over union (mIOU), compared to the model trained only using real data. The codes of all the experiments are available on GitHub to reproduce the results.
Understanding Audio Features via Trainable Basis Functions
Apr 25, 2022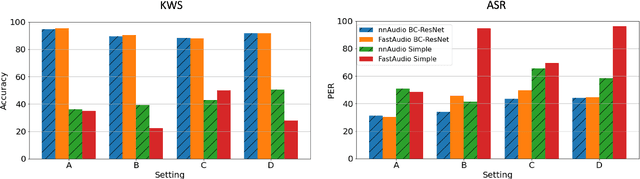

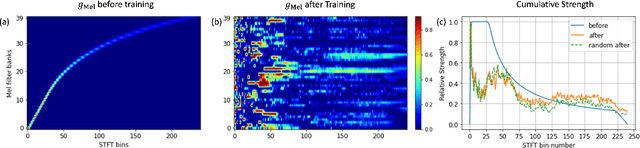
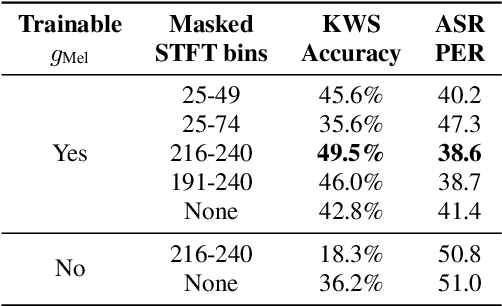
In this paper we explore the possibility of maximizing the information represented in spectrograms by making the spectrogram basis functions trainable. We experiment with two different tasks, namely keyword spotting (KWS) and automatic speech recognition (ASR). For most neural network models, the architecture and hyperparameters are typically fine-tuned and optimized in experiments. Input features, however, are often treated as fixed. In the case of audio, signals can be mainly expressed in two main ways: raw waveforms (time-domain) or spectrograms (time-frequency-domain). In addition, different spectrogram types are often used and tailored to fit different applications. In our experiments, we allow for this tailoring directly as part of the network. Our experimental results show that using trainable basis functions can boost the accuracy of Keyword Spotting (KWS) by 14.2 percentage points, and lower the Phone Error Rate (PER) by 9.5 percentage points. Although models using trainable basis functions become less effective as the model complexity increases, the trained filter shapes could still provide us with insights on which frequency bins are important for that specific task. From our experiments, we can conclude that trainable basis functions are a useful tool to boost the performance when the model complexity is limited.
Value Memory Graph: A Graph-Structured World Model for Offline Reinforcement Learning
Jun 09, 2022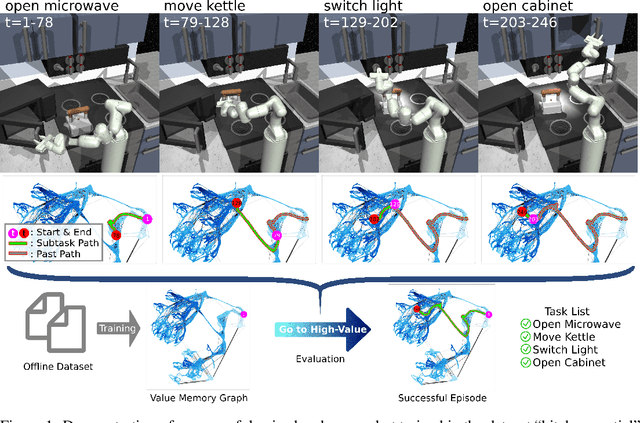
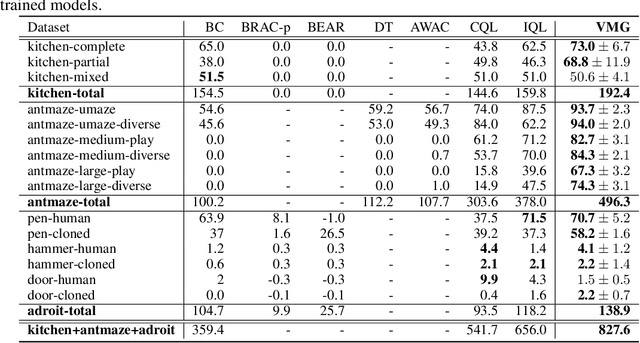
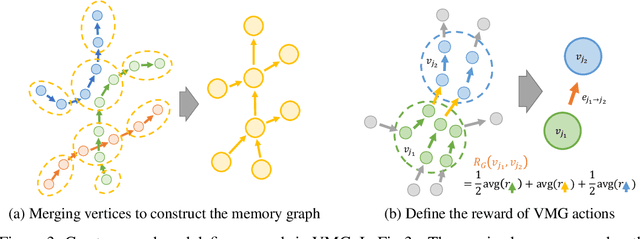
World models in model-based reinforcement learning usually face unrealistic long-time-horizon prediction issues due to compounding errors as the prediction errors accumulate over timesteps. Recent works in graph-structured world models improve the long-horizon reasoning ability via building a graph to represent the environment, but they are designed in a goal-conditioned setting and cannot guide the agent to maximize episode returns in a traditional reinforcement learning setting without externally given target states. To overcome this limitation, we design a graph-structured world model in offline reinforcement learning by building a directed-graph-based Markov decision process (MDP) with rewards allocated to each directed edge as an abstraction of the original continuous environment. As our world model has small and finite state/action spaces compared to the original environment, value iteration can be easily applied here to estimate state values on the graph and figure out the best future. Unlike previous graph-structured world models that requires externally provided targets, our world model, dubbed Value Memory Graph (VMG), can provide the desired targets with high values by itself. VMG can be used to guide low-level goal-conditioned policies that are trained via supervised learning to maximize episode returns. Experiments on the D4RL benchmark show that VMG can outperform state-of-the-art methods in several tasks where long horizon reasoning ability is crucial. Code will be made publicly available.
Machine Learning-based Lung and Colon Cancer Detection using Deep Feature Extraction and Ensemble Learning
Jun 03, 2022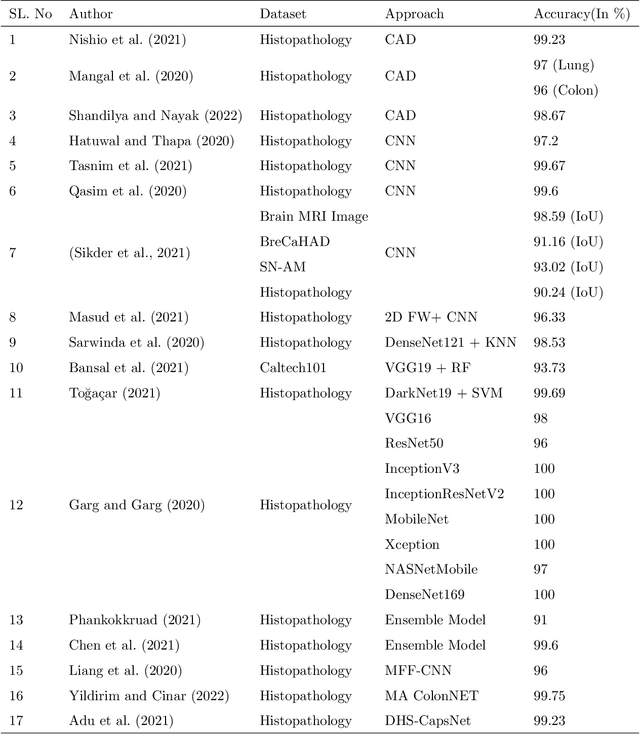
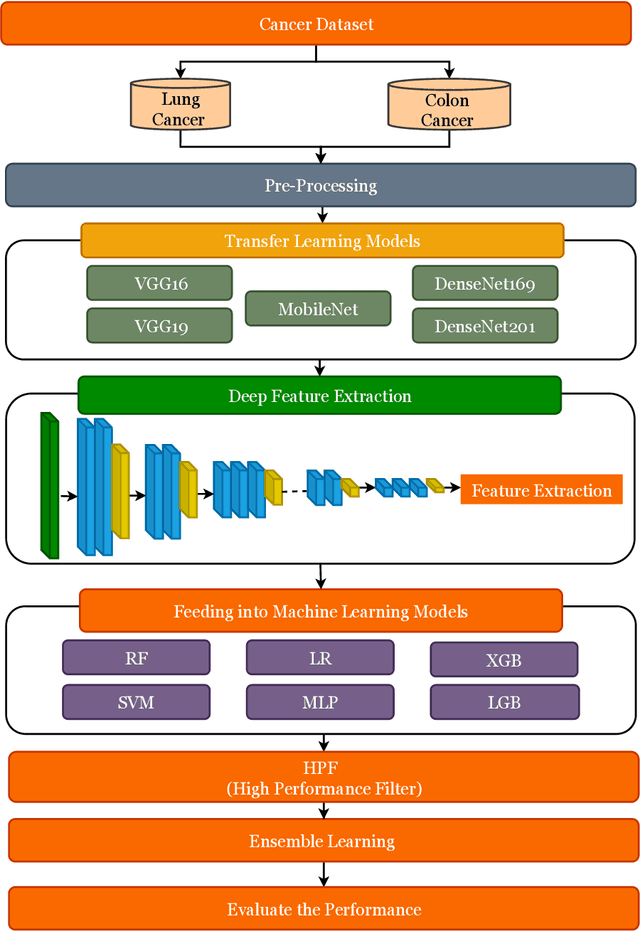

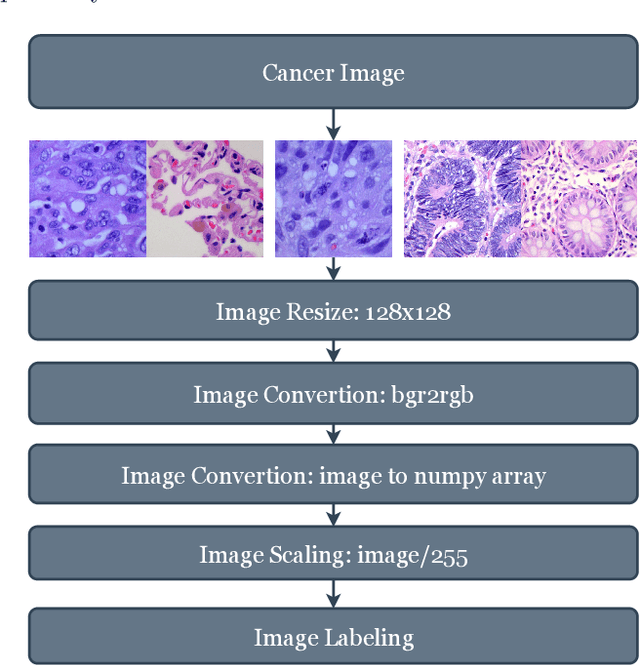
Cancer is a fatal disease caused by a combination of genetic diseases and a variety of biochemical abnormalities. Lung and colon cancer have emerged as two of the leading causes of death and disability in humans. The histopathological detection of such malignancies is usually the most important component in determining the best course of action. Early detection of the ailment on either front considerably decreases the likelihood of mortality. Machine learning and deep learning techniques can be utilized to speed up such cancer detection, allowing researchers to study a large number of patients in a much shorter amount of time and at a lower cost. In this research work, we introduced a hybrid ensemble feature extraction model to efficiently identify lung and colon cancer. It integrates deep feature extraction and ensemble learning with high-performance filtering for cancer image datasets. The model is evaluated on histopathological (LC25000) lung and colon datasets. According to the study findings, our hybrid model can detect lung, colon, and (lung and colon) cancer with accuracy rates of 99.05%, 100%, and 99.30%, respectively. The study's findings show that our proposed strategy outperforms existing models significantly. Thus, these models could be applicable in clinics to support the doctor in the diagnosis of cancers.
Identical Image Retrieval using Deep Learning
May 18, 2022
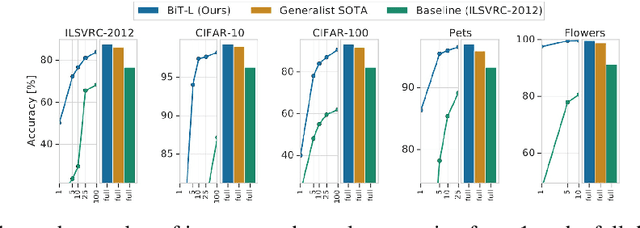
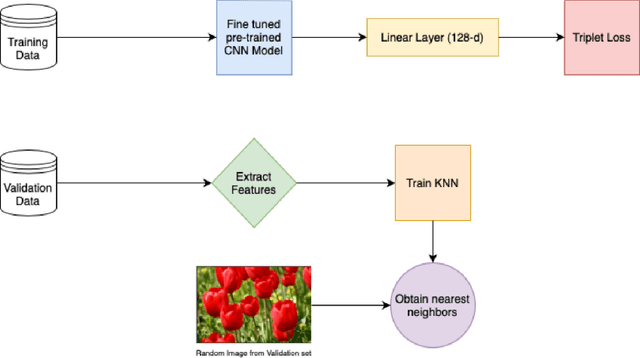

In recent years, we know that the interaction with images has increased. Image similarity involves fetching similar-looking images abiding by a given reference image. The target is to find out whether the image searched as a query can result in similar pictures. We are using the BigTransfer Model, which is a state-of-art model itself. BigTransfer(BiT) is essentially a ResNet but pre-trained on a larger dataset like ImageNet and ImageNet-21k with additional modifications. Using the fine-tuned pre-trained Convolution Neural Network Model, we extract the key features and train on the K-Nearest Neighbor model to obtain the nearest neighbor. The application of our model is to find similar images, which are hard to achieve through text queries within a low inference time. We analyse the benchmark of our model based on this application.
Forecasting the abnormal events at well drilling with machine learning
Mar 10, 2022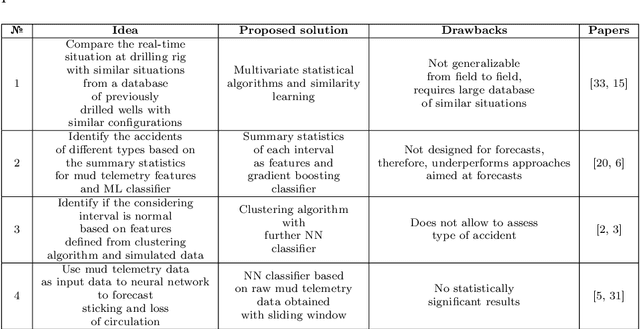
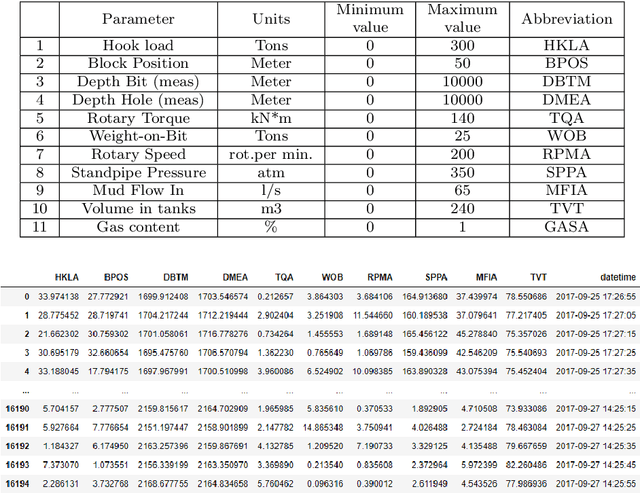
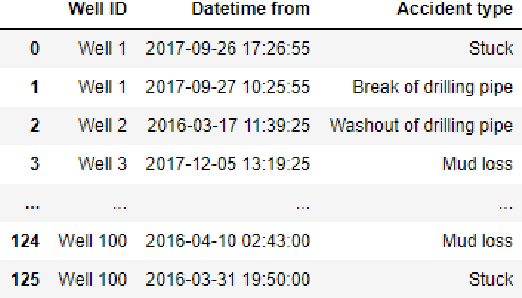
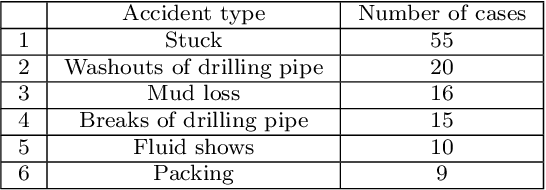
We present a data-driven and physics-informed algorithm for drilling accident forecasting. The core machine-learning algorithm uses the data from the drilling telemetry representing the time-series. We have developed a Bag-of-features representation of the time series that enables the algorithm to predict the probabilities of six types of drilling accidents in real-time. The machine-learning model is trained on the 125 past drilling accidents from 100 different Russian oil and gas wells. Validation shows that the model can forecast 70% of drilling accidents with a false positive rate equals to 40%. The model addresses partial prevention of the drilling accidents at the well construction.
Time-Reversal Symmetric ODE Network
Jul 22, 2020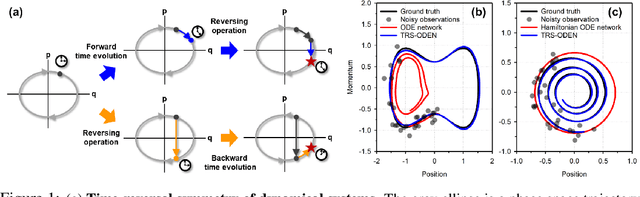
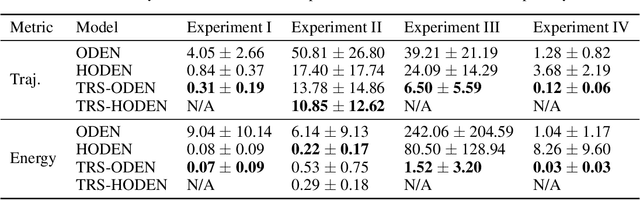
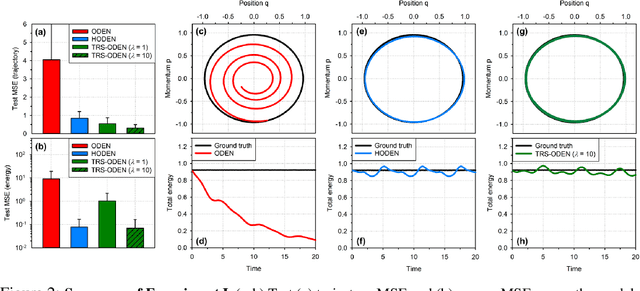
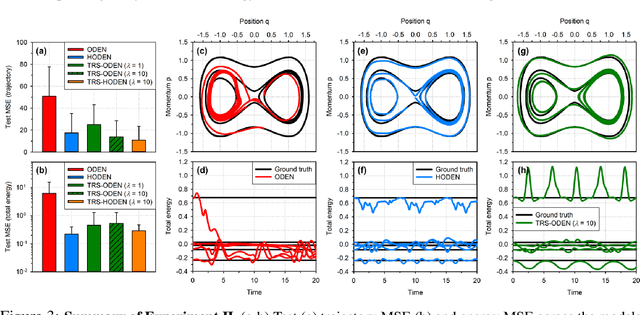
Time-reversal symmetry, which requires that the dynamics of a system should not change with the reversal of time axis, is a fundamental property that frequently holds in classical and quantum mechanics. In this paper, we propose a novel loss function that measures how well our ordinary differential equation (ODE) networks comply with this time-reversal symmetry; it is formally defined by the discrepancy in the time evolution of ODE networks between forward and backward dynamics. Then, we design a new framework, which we name as Time-Reversal Symmetric ODE Networks (TRS-ODENs), that can learn the dynamics of physical systems more sample-efficiently by learning with the proposed loss function. We evaluate TRS-ODENs on several classical dynamics, and find they can learn the desired time evolution from observed noisy and complex trajectories. We also show that, even for systems that do not possess the full time-reversal symmetry, TRS-ODENs can achieve better predictive errors over baselines.
Machine Learning Prediction of Time-Varying Rayleigh Channels
Mar 10, 2021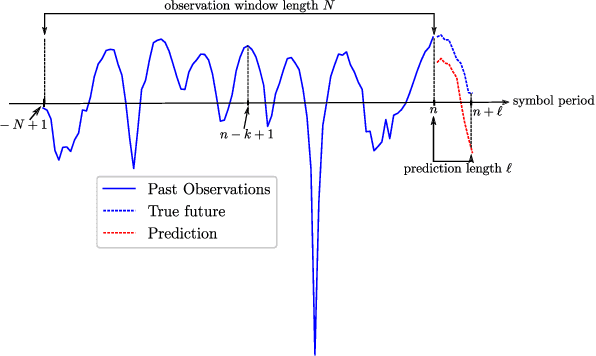
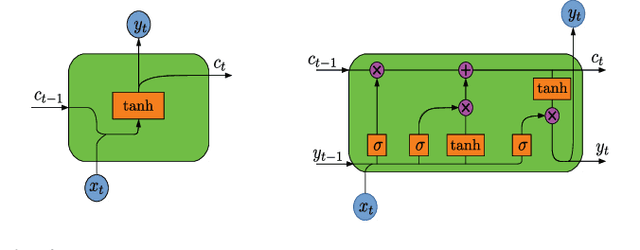
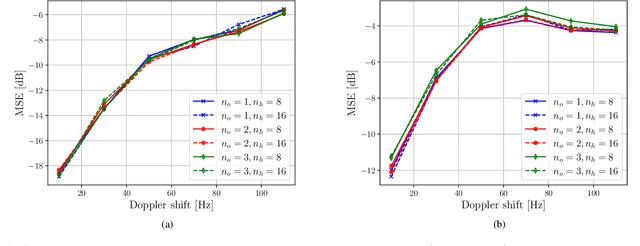
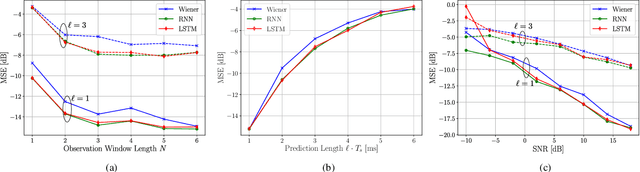
Channel state information (CSI) rapidly becomes outdated in high mobility scenarios, degrading the performance of wireless communication systems. In these cases, time series prediction techniques can be applied to combat the effects of outdated CSI. Recently, it has been shown that recurrent neural networks (RNNs) exhibit outstanding performance in time series prediction tasks. In this paper, we investigate the performance of RNN and long short term memory (LSTM) predictors in a simple Rayleigh flat-fading channel. We conduct numerical experiments to evaluate whether these machine-learning (ML)-based predictors can outperform the optimal linear minimum mean square error Wiener predictor. Our simulation results indicate that the considered neural network predictors outperform the Wiener predictor for small observation window lengths and are more robust under weak channel correlation as well as in the presence of noise. Furthermore, we show that simple shallow RNNs are sufficient to model Rayleigh channels over a wide range of Doppler shifts.
Optimal Gradient Sliding and its Application to Distributed Optimization Under Similarity
May 30, 2022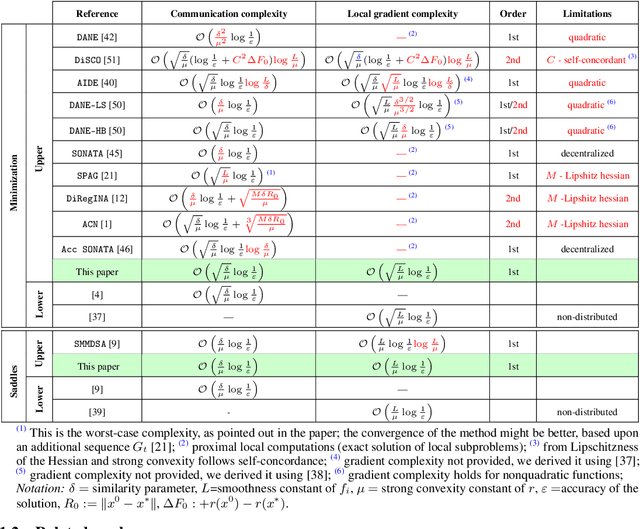


We study structured convex optimization problems, with additive objective $r:=p + q$, where $r$ is ($\mu$-strongly) convex, $q$ is $L_q$-smooth and convex, and $p$ is $L_p$-smooth, possibly nonconvex. For such a class of problems, we proposed an inexact accelerated gradient sliding method that can skip the gradient computation for one of these components while still achieving optimal complexity of gradient calls of $p$ and $q$, that is, $\mathcal{O}(\sqrt{L_p/\mu})$ and $\mathcal{O}(\sqrt{L_q/\mu})$, respectively. This result is much sharper than the classic black-box complexity $\mathcal{O}(\sqrt{(L_p+L_q)/\mu})$, especially when the difference between $L_q$ and $L_q$ is large. We then apply the proposed method to solve distributed optimization problems over master-worker architectures, under agents' function similarity, due to statistical data similarity or otherwise. The distributed algorithm achieves for the first time lower complexity bounds on {\it both} communication and local gradient calls, with the former having being a long-standing open problem. Finally the method is extended to distributed saddle-problems (under function similarity) by means of solving a class of variational inequalities, achieving lower communication and computation complexity bounds.