 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Solve Combinatorial Graph Partitioning Problems via Efficient Exploration
May 27, 2022
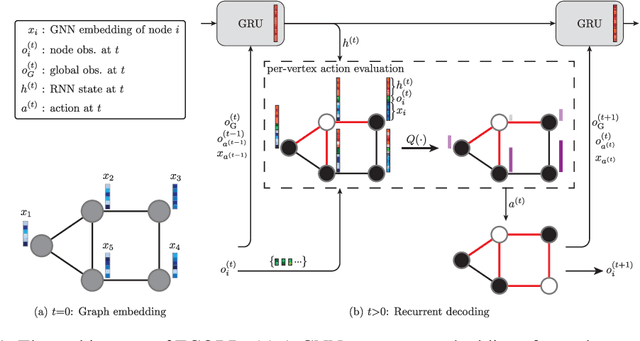
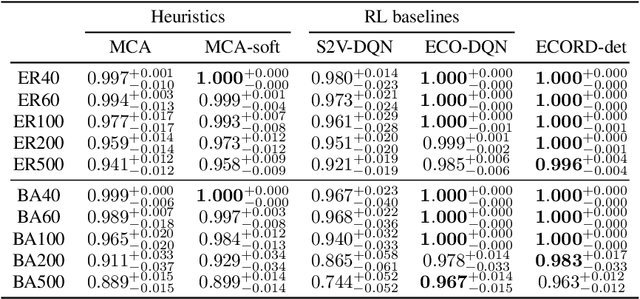
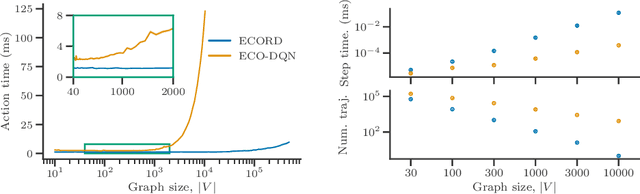
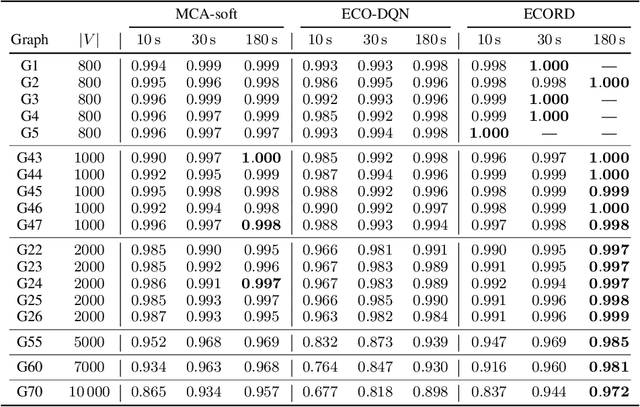
From logistics to the natural sciences, combinatorial optimisation on graphs underpins numerous real-world applications. Reinforcement learning (RL) has shown particular promise in this setting as it can adapt to specific problem structures and does not require pre-solved instances for these, often NP-hard, problems. However, state-of-the-art (SOTA) approaches typically suffer from severe scalability issues, primarily due to their reliance on expensive graph neural networks (GNNs) at each decision step. We introduce ECORD; a novel RL algorithm that alleviates this expense by restricting the GNN to a single pre-processing step, before entering a fast-acting exploratory phase directed by a recurrent unit. Experimentally, ECORD achieves a new SOTA for RL algorithms on the Maximum Cut problem, whilst also providing orders of magnitude improvement in speed and scalability. Compared to the nearest competitor, ECORD reduces the optimality gap by up to 73% on 500 vertex graphs with a decreased wall-clock time. Moreover, ECORD retains strong performance when generalising to larger graphs with up to 10000 vertices.
Exploring the limits of multifunctionality across different reservoir computers
May 23, 2022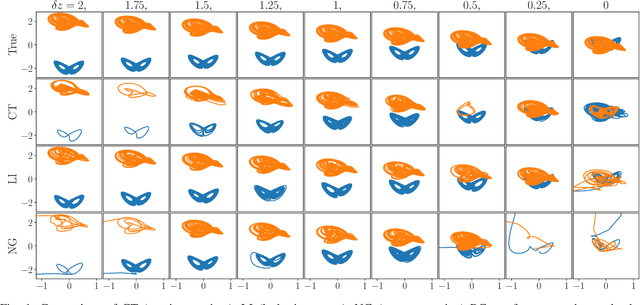
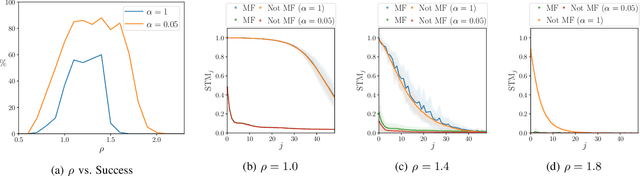
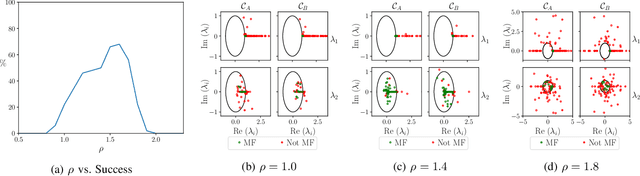
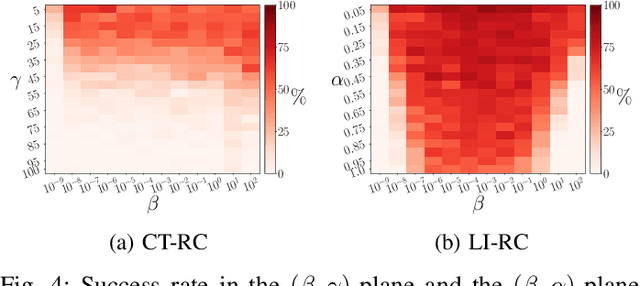
Multifunctional neural networks are capable of performing more than one task without changing any network connections. In this paper we explore the performance of a continuous-time, leaky-integrator, and next-generation `reservoir computer' (RC), when trained on tasks which test the limits of multifunctionality. In the first task we train each RC to reconstruct a coexistence of chaotic attractors from different dynamical systems. By moving the data describing these attractors closer together, we find that the extent to which each RC can reconstruct both attractors diminishes as they begin to overlap in state space. In order to provide a greater understanding of this inhibiting effect, in the second task we train each RC to reconstruct a coexistence of two circular orbits which differ only in the direction of rotation. We examine the critical effects that certain parameters can have in each RC to achieve multifunctionality in this extreme case of completely overlapping training data.
Learning a Single Neuron with Adversarial Label Noise via Gradient Descent
Jun 17, 2022

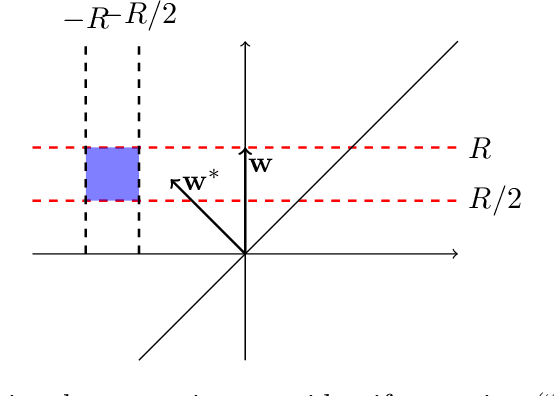
We study the fundamental problem of learning a single neuron, i.e., a function of the form $\mathbf{x}\mapsto\sigma(\mathbf{w}\cdot\mathbf{x})$ for monotone activations $\sigma:\mathbb{R}\mapsto\mathbb{R}$, with respect to the $L_2^2$-loss in the presence of adversarial label noise. Specifically, we are given labeled examples from a distribution $D$ on $(\mathbf{x}, y)\in\mathbb{R}^d \times \mathbb{R}$ such that there exists $\mathbf{w}^\ast\in\mathbb{R}^d$ achieving $F(\mathbf{w}^\ast)=\epsilon$, where $F(\mathbf{w})=\mathbf{E}_{(\mathbf{x},y)\sim D}[(\sigma(\mathbf{w}\cdot \mathbf{x})-y)^2]$. The goal of the learner is to output a hypothesis vector $\mathbf{w}$ such that $F(\mathbb{w})=C\, \epsilon$ with high probability, where $C>1$ is a universal constant. As our main contribution, we give efficient constant-factor approximate learners for a broad class of distributions (including log-concave distributions) and activation functions. Concretely, for the class of isotropic log-concave distributions, we obtain the following important corollaries: For the logistic activation, we obtain the first polynomial-time constant factor approximation (even under the Gaussian distribution). Our algorithm has sample complexity $\widetilde{O}(d/\epsilon)$, which is tight within polylogarithmic factors. For the ReLU activation, we give an efficient algorithm with sample complexity $\tilde{O}(d\, \polylog(1/\epsilon))$. Prior to our work, the best known constant-factor approximate learner had sample complexity $\tilde{\Omega}(d/\epsilon)$. In both of these settings, our algorithms are simple, performing gradient-descent on the (regularized) $L_2^2$-loss. The correctness of our algorithms relies on novel structural results that we establish, showing that (essentially all) stationary points of the underlying non-convex loss are approximately optimal.
Rethinking Reinforcement Learning for Recommendation: A Prompt Perspective
Jun 15, 2022
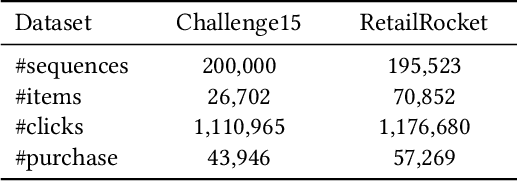
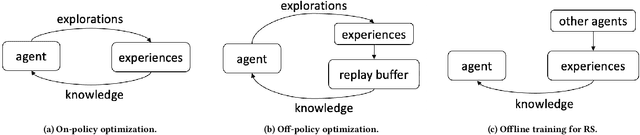
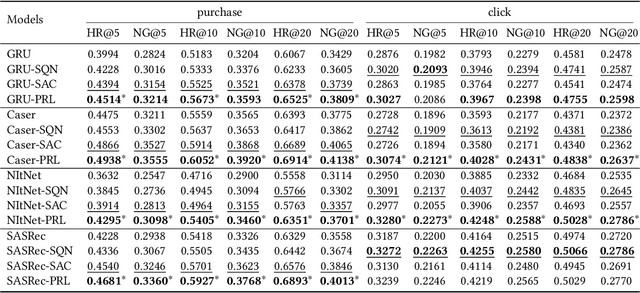
Modern recommender systems aim to improve user experience. As reinforcement learning (RL) naturally fits this objective -- maximizing an user's reward per session -- it has become an emerging topic in recommender systems. Developing RL-based recommendation methods, however, is not trivial due to the \emph{offline training challenge}. Specifically, the keystone of traditional RL is to train an agent with large amounts of online exploration making lots of `errors' in the process. In the recommendation setting, though, we cannot afford the price of making `errors' online. As a result, the agent needs to be trained through offline historical implicit feedback, collected under different recommendation policies; traditional RL algorithms may lead to sub-optimal policies under these offline training settings. Here we propose a new learning paradigm -- namely Prompt-Based Reinforcement Learning (PRL) -- for the offline training of RL-based recommendation agents. While traditional RL algorithms attempt to map state-action input pairs to their expected rewards (e.g., Q-values), PRL directly infers actions (i.e., recommended items) from state-reward inputs. In short, the agents are trained to predict a recommended item given the prior interactions and an observed reward value -- with simple supervised learning. At deployment time, this historical (training) data acts as a knowledge base, while the state-reward pairs are used as a prompt. The agents are thus used to answer the question: \emph{ Which item should be recommended given the prior interactions \& the prompted reward value}? We implement PRL with four notable recommendation models and conduct experiments on two real-world e-commerce datasets. Experimental results demonstrate the superior performance of our proposed methods.
Autonomous In-Situ Soundscape Augmentation via Joint Selection of Masker and Gain
Apr 29, 2022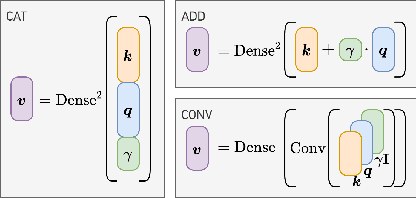
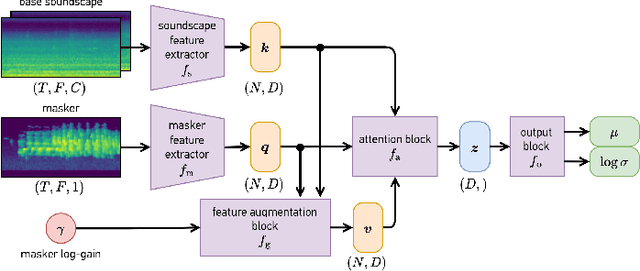
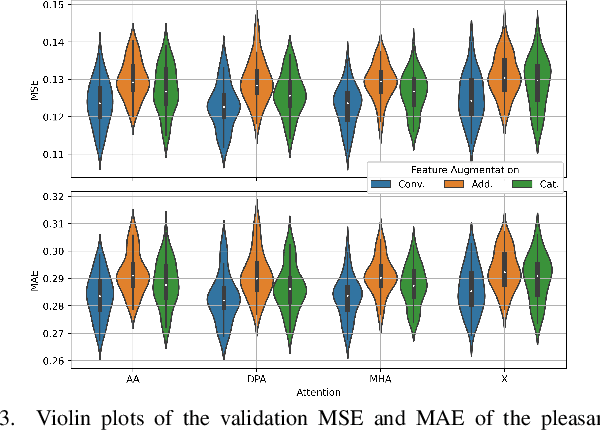
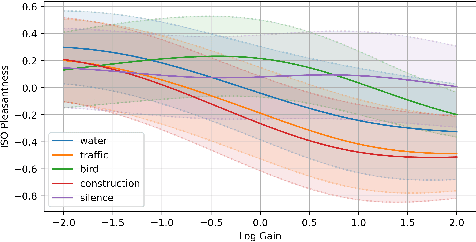
The selection of maskers and playback gain levels in a soundscape augmentation system is crucial to its effectiveness in improving the overall acoustic comfort of a given environment. Traditionally, the selection of appropriate maskers and gain levels has been informed by expert opinion, which may not representative of the target population, or by listening tests, which can be time-consuming and labour-intensive. Furthermore, the resulting static choices of masker and gain are often inflexible to the dynamic nature of real-world soundscapes. In this work, we utilized a deep learning model to perform joint selection of the optimal masker and its gain level for a given soundscape. The proposed model was designed with highly modular building blocks, allowing for an optimized inference process that can quickly search through a large number of masker and gain combinations. In addition, we introduced the use of feature-domain soundscape augmentation conditioned on the digital gain level, eliminating the computationally expensive waveform-domain mixing process during inference time, as well as the tedious pre-calibration process required for new maskers. The proposed system was validated on a large-scale dataset of subjective responses to augmented soundscapes with more than 440 participants, ensuring the ability of the model to predict combined effect of the masker and its gain level on the perceptual pleasantness level.
Multiple Offsets Multilateration: a new paradigm for sensor network calibration with unsynchronized reference nodes
May 23, 2022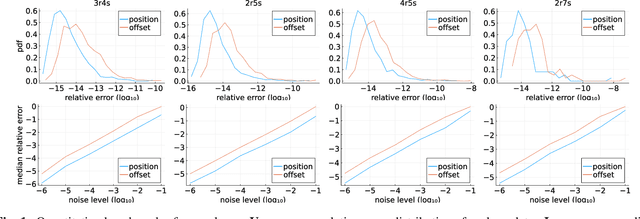
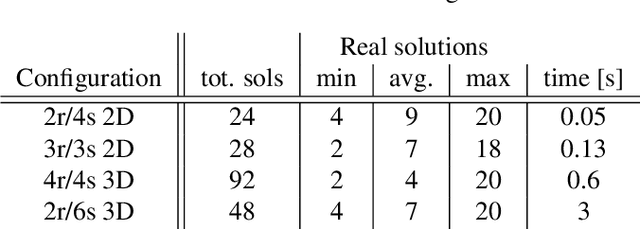
Positioning using wave signal measurements is used in several applications, such as GPS systems, structure from sound and Wifi based positioning. Mathematically, such problems require the computation of the positions of receivers and/or transmitters as well as time offsets if the devices are unsynchronized. In this paper, we expand the previous state-of-the-art on positioning formulations by introducing Multiple Offsets Multilateration (MOM), a new mathematical framework to compute the receivers positions with pseudoranges from unsynchronized reference transmitters at known positions. This could be applied in several scenarios, for example structure from sound and positioning with LEO satellites. We mathematically describe MOM, determining how many receivers and transmitters are needed for the network to be solvable, a study on the number of possible distinct solutions is presented and stable solvers based on homotopy continuation are derived. The solvers are shown to be efficient and robust to noise both for synthetic and real audio data.
Time-Reversal Symmetric ODE Network
Jul 22, 2020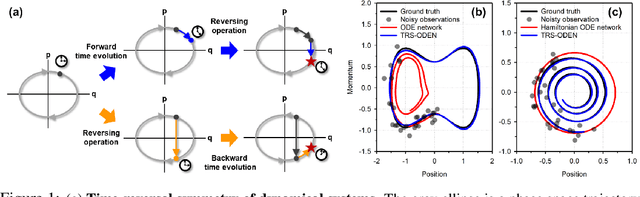
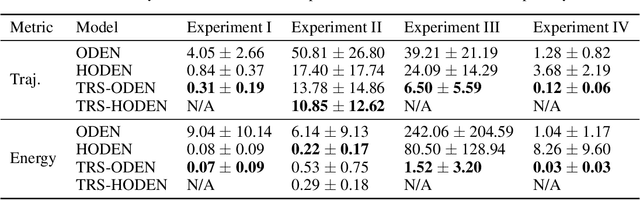
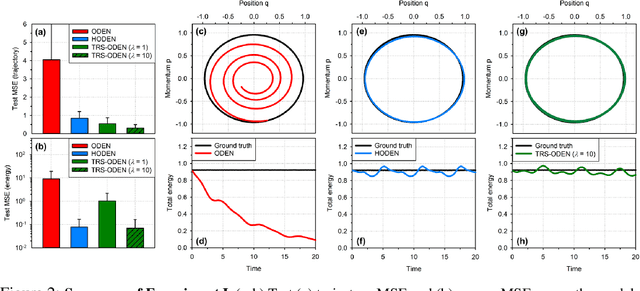
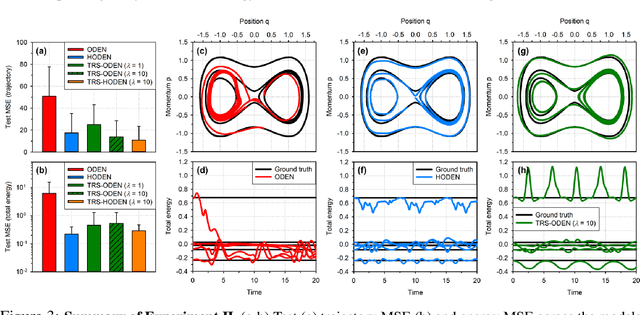
Time-reversal symmetry, which requires that the dynamics of a system should not change with the reversal of time axis, is a fundamental property that frequently holds in classical and quantum mechanics. In this paper, we propose a novel loss function that measures how well our ordinary differential equation (ODE) networks comply with this time-reversal symmetry; it is formally defined by the discrepancy in the time evolution of ODE networks between forward and backward dynamics. Then, we design a new framework, which we name as Time-Reversal Symmetric ODE Networks (TRS-ODENs), that can learn the dynamics of physical systems more sample-efficiently by learning with the proposed loss function. We evaluate TRS-ODENs on several classical dynamics, and find they can learn the desired time evolution from observed noisy and complex trajectories. We also show that, even for systems that do not possess the full time-reversal symmetry, TRS-ODENs can achieve better predictive errors over baselines.
Scenario-based Multi-product Advertising Copywriting Generation for E-Commerce
May 21, 2022

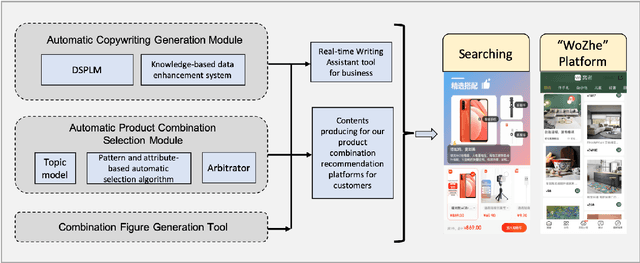
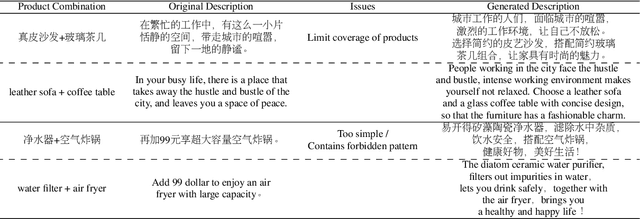
In this paper, we proposed an automatic Scenario-based Multi-product Advertising Copywriting Generation system (SMPACG) for E-Commerce, which has been deployed on a leading Chinese e-commerce platform. The proposed SMPACG consists of two main components: 1) an automatic multi-product combination selection module, which itself is consisted of a topic prediction model, a pattern and attribute-based selection model and an arbitrator model; and 2) an automatic multi-product advertising copywriting generation module, which combines our proposed domain-specific pretrained language model and knowledge-based data enhancement model. The SMPACG is the first system that realizes automatic scenario-based multi-product advertising contents generation, which achieves significant improvements over other state-of-the-art methods. The SMPACG has been not only developed for directly serving for our e-commerce recommendation system, but also used as a real-time writing assistant tool for merchants.
hmBERT: Historical Multilingual Language Models for Named Entity Recognition
May 31, 2022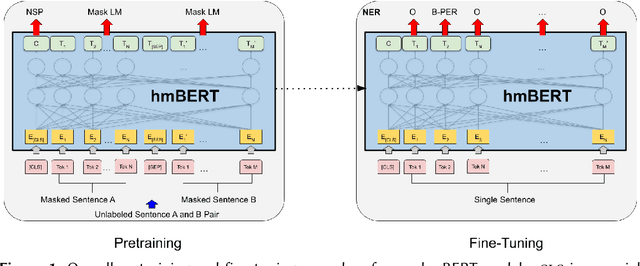



Compared to standard Named Entity Recognition (NER), identifying persons, locations, and organizations in historical texts forms a big challenge. To obtain machine-readable corpora, the historical text is usually scanned and optical character recognition (OCR) needs to be performed. As a result, the historical corpora contain errors. Also, entities like location or organization can change over time, which poses another challenge. Overall historical texts come with several peculiarities that differ greatly from modern texts and large labeled corpora for training a neural tagger are hardly available for this domain. In this work, we tackle NER for historical German, English, French, Swedish, and Finnish by training large historical language models. We circumvent the need for labeled data by using unlabeled data for pretraining a language model. hmBERT, a historical multilingual BERT-based language model is proposed, with different sizes of it being publicly released. Furthermore, we evaluate the capability of hmBERT by solving downstream NER as part of this year's HIPE-2022 shared task and provide detailed analysis and insights. For the Multilingual Classical Commentary coarse-grained NER challenge, our tagger HISTeria outperforms the other teams' models for two out of three languages.
Soft Robotic Mannequin: Design and Algorithm for Deformation Control
May 23, 2022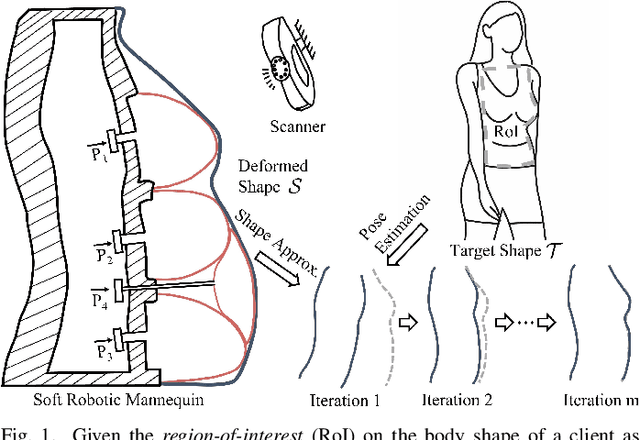
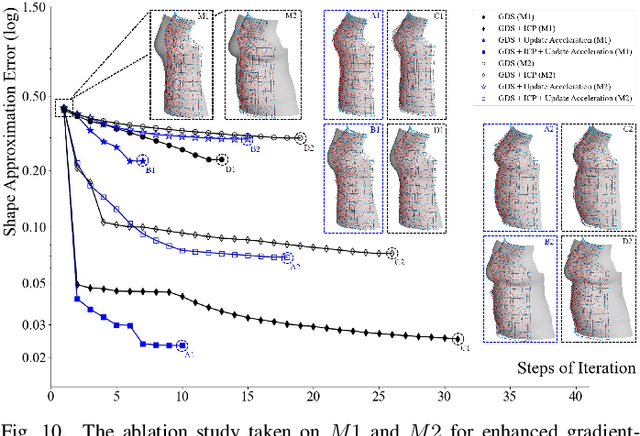
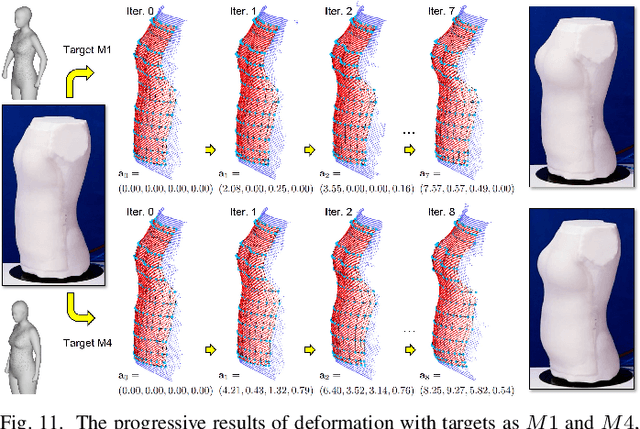
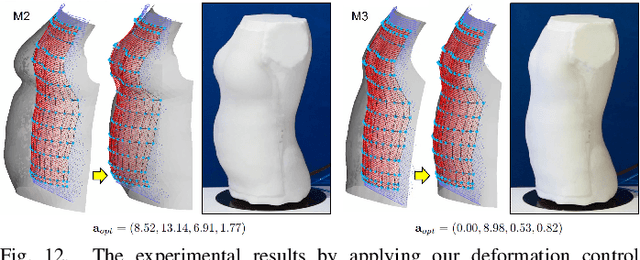
This paper presents a novel soft robotic system for a deformable mannequin that can be employed to physically realize the 3D geometry of different human bodies. The soft membrane on a mannequin is deformed by inflating several curved chambers using pneumatic actuation. Controlling the freeform surface of a soft membrane by adjusting the pneumatic actuation in different chambers is challenging as the membrane's shape is commonly determined by the interaction between all chambers. Using vision feedback provided by a structured-light based 3D scanner, we developed an efficient algorithm to compute the optimized actuation of all chambers which could drive the soft membrane to deform into the best approximation of different target shapes. Our algorithm converges quickly by including pose estimation in the loop of optimization. The time-consuming step of evaluating derivatives on the deformable membrane is avoided by using the Broyden update when possible. The effectiveness of our soft robotic mannequin with controlled deformation has been verified in experiments.