 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discrete Graph Structure Learning for Forecasting Multiple Time Series
Feb 15, 2021
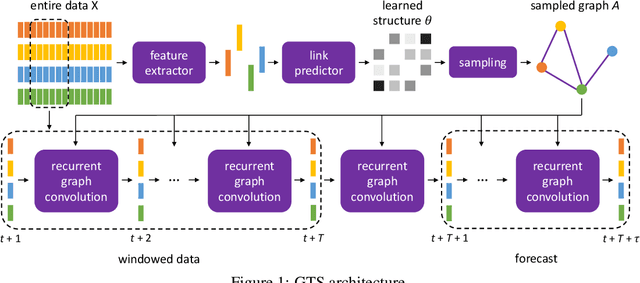
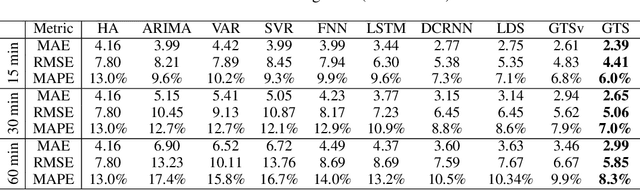
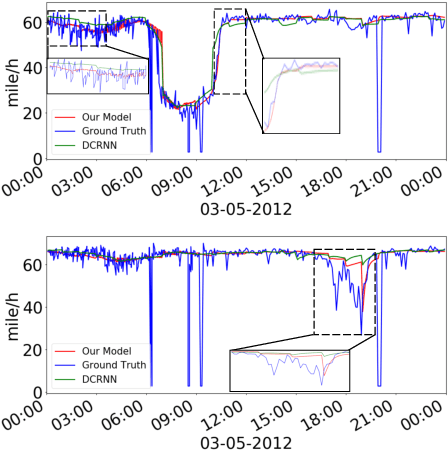
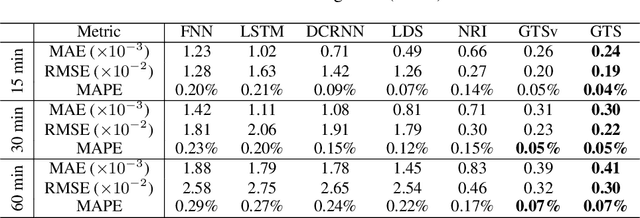
Time series forecasting is an extensively studied subject in statistics, economics, and computer science. Exploration of the correlation and causation among the variables in a multivariate time series shows promise in enhancing the performance of a time series model. When using deep neural networks as forecasting models, we hypothesize that exploiting the pairwise information among multiple (multivariate) time series also improves their forecast. If an explicit graph structure is known, graph neural networks (GNNs) have been demonstrated as powerful tools to exploit the structure. In this work, we propose learning the structure simultaneously with the GNN if the graph is unknown. We cast the problem as learning a probabilistic graph model through optimizing the mean performance over the graph distribution. The distribution is parameterized by a neural network so that discrete graphs can be sampled differentiably through reparameterization. Empirical evaluations show that our method is simpler, more efficient, and better performing than a recently proposed bilevel learning approach for graph structure learning, as well as a broad array of forecasting models, either deep or non-deep learning based, and graph or non-graph based.
Forecast-based Multi-aspect Framework for Multivariate Time-series Anomaly Detection
Jan 13, 2022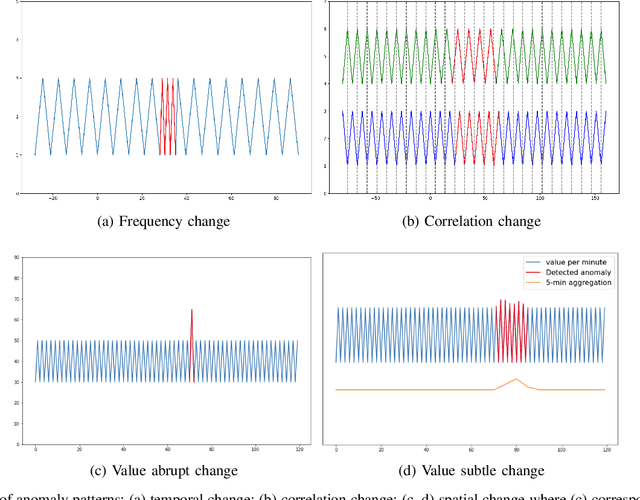
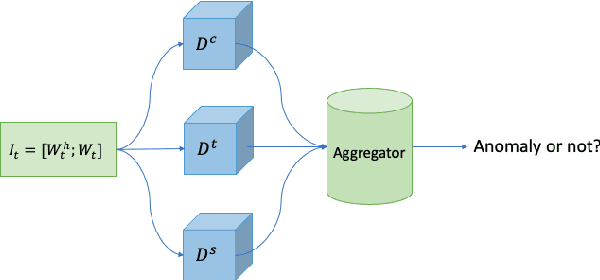
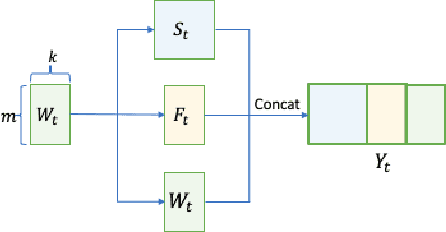
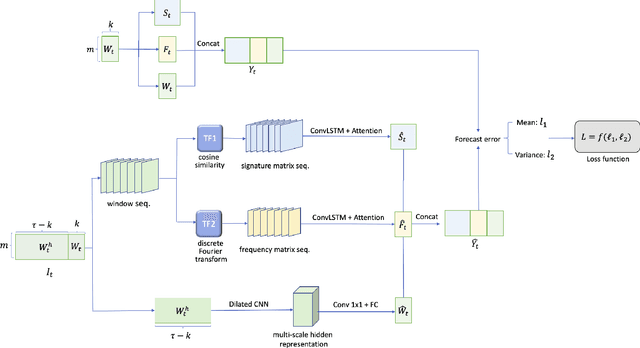
Today's cyber-world is vastly multivariate. Metrics collected at extreme varieties demand multivariate algorithms to properly detect anomalies. However, forecast-based algorithms, as widely proven approaches, often perform sub-optimally or inconsistently across datasets. A key common issue is they strive to be one-size-fits-all but anomalies are distinctive in nature. We propose a method that tailors to such distinction. Presenting FMUAD - a Forecast-based, Multi-aspect, Unsupervised Anomaly Detection framework. FMUAD explicitly and separately captures the signature traits of anomaly types - spatial change, temporal change and correlation change - with independent modules. The modules then jointly learn an optimal feature representation, which is highly flexible and intuitive, unlike most other models in the category. Extensive experiments show our FMUAD framework consistently outperforms other state-of-the-art forecast-based anomaly detectors.
A Unified Analysis of Federated Learning with Arbitrary Client Participation
Jun 01, 2022
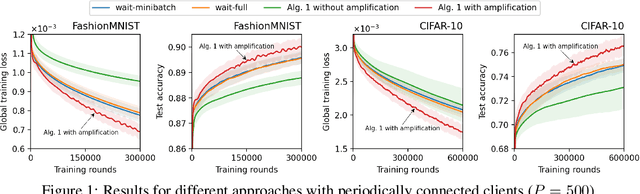

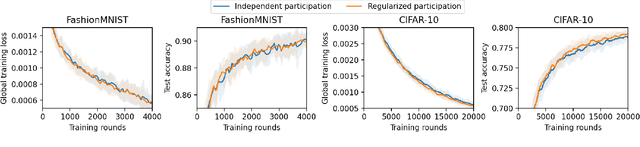
Federated learning (FL) faces challenges of intermittent client availability and computation/communication efficiency. As a result, only a small subset of clients can participate in FL at a given time. It is important to understand how partial client participation affects convergence, but most existing works have either considered idealized participation patterns or obtained results with non-zero optimality error for generic patterns. In this paper, we provide a unified convergence analysis for FL with arbitrary client participation. We first introduce a generalized version of federated averaging (FedAvg) that amplifies parameter updates at an interval of multiple FL rounds. Then, we present a novel analysis that captures the effect of client participation in a single term. By analyzing this term, we obtain convergence upper bounds for a wide range of participation patterns, including both non-stochastic and stochastic cases, which match either the lower bound of stochastic gradient descent (SGD) or the state-of-the-art results in specific settings. We also discuss various insights, recommendations, and experimental results.
Deep Learning Neural Networks for Emotion Classification from Text: Enhanced Leaky Rectified Linear Unit Activation and Weighted Loss
Mar 04, 2022
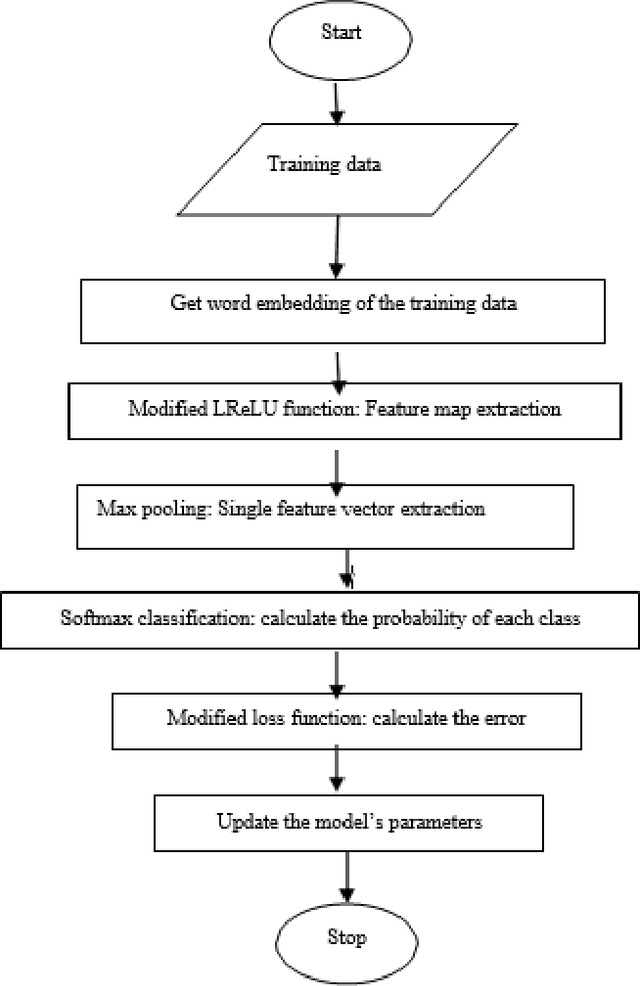
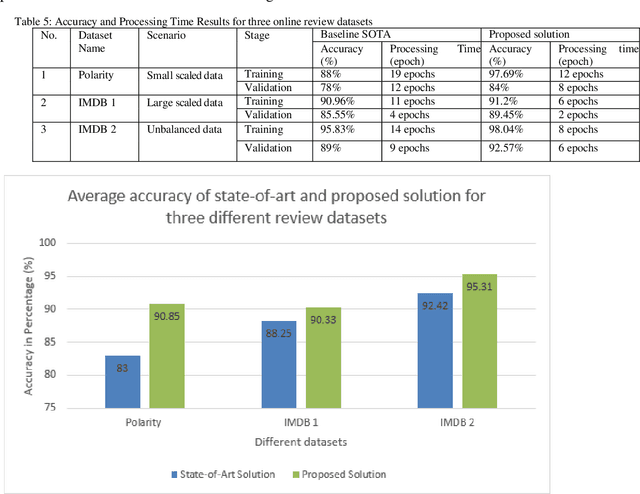
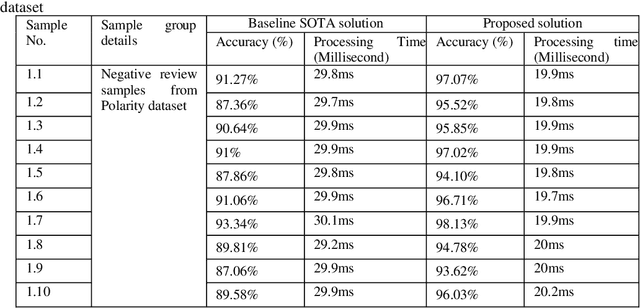
Accurate emotion classification for online reviews is vital for business organizations to gain deeper insights into markets. Although deep learning has been successfully implemented in this area, accuracy and processing time are still major problems preventing it from reaching its full potential. This paper proposes an Enhanced Leaky Rectified Linear Unit activation and Weighted Loss (ELReLUWL) algorithm for enhanced text emotion classification and faster parameter convergence speed. This algorithm includes the definition of the inflection point and the slope for inputs on the left side of the inflection point to avoid gradient saturation. It also considers the weight of samples belonging to each class to compensate for the influence of data imbalance. Convolutional Neural Network (CNN) combined with the proposed algorithm to increase the classification accuracy and decrease the processing time by eliminating the gradient saturation problem and minimizing the negative effect of data imbalance, demonstrated on a binary sentiment problem. The results show that the proposed solution achieves better classification performance in different data scenarios and different review types. The proposed model takes less convergence time to achieve model optimization with seven epochs against the current convergence time of 11.5 epochs on average. The proposed solution improves accuracy and reduces the processing time of text emotion classification. The solution provides an average class accuracy of 96.63% against a current average accuracy of 91.56%. It also provides a processing time of 23.3 milliseconds compared to the current average processing time of 33.2 milliseconds. Finally, this study solves the issues of gradient saturation and data imbalance. It enhances overall average class accuracy and decreases processing time.
* 28 pages
Safety-guaranteed trajectory planning and control based on GP estimation for unmanned surface vessels
May 10, 2022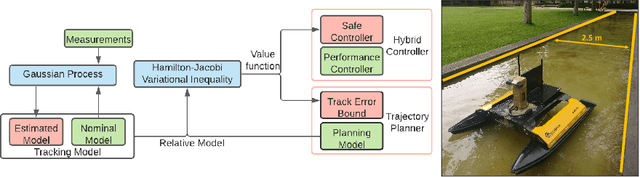
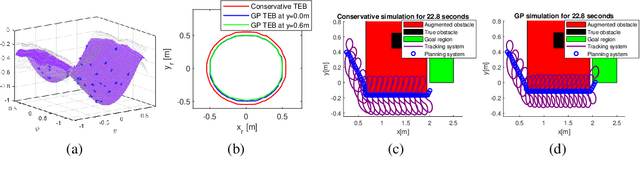
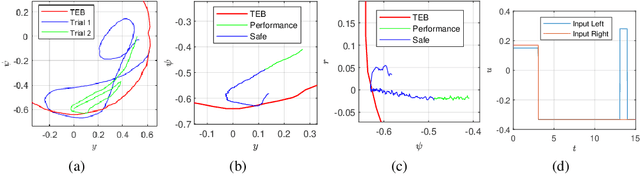
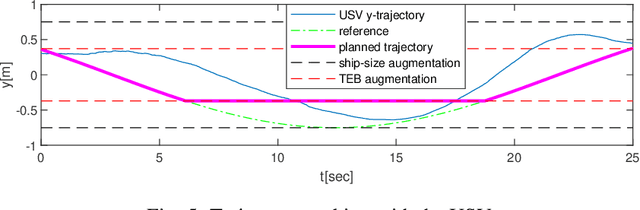
We propose a safety-guaranteed planning and control framework for unmanned surface vessels (USVs), using Gaussian processes (GPs) to learn uncertainties. The uncertainties encountered by USVs, including external disturbances and model mismatches, are potentially state-dependent, time-varying, and hard to capture with constant models. GP is a powerful learning-based tool that can be integrated with a model-based planning and control framework, which employs a Hamilton-Jacobi differential game formulation. Such a combination yields less conservative trajectories and safety-guaranteeing control strategies. We demonstrate the proposed framework in simulations and experiments on a CLEARPATH Heron USV.
Learning Sequential Contexts using Transformer for 3D Hand Pose Estimation
Jun 01, 2022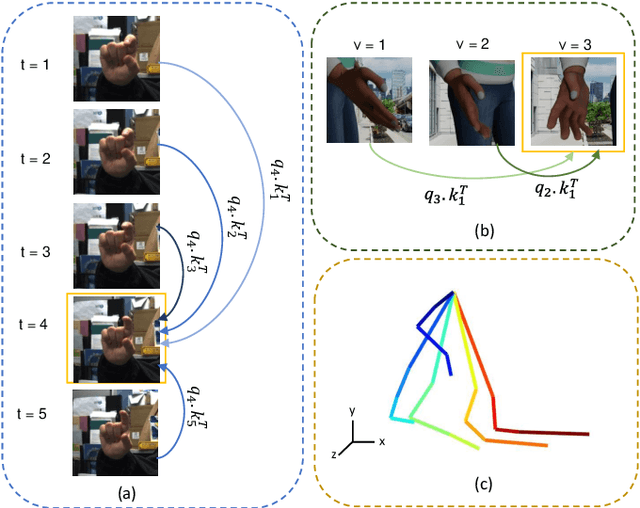
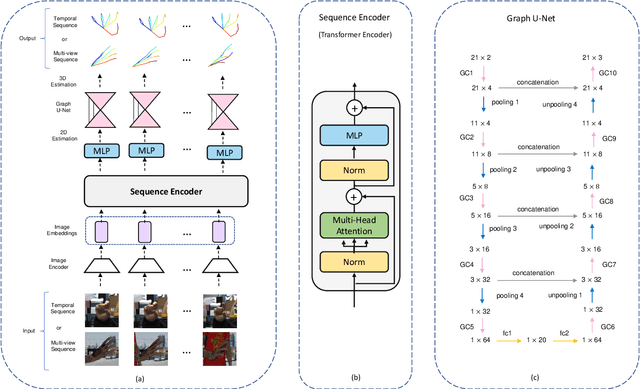
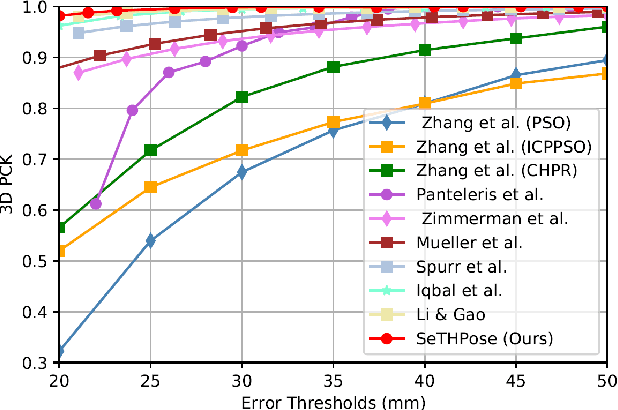
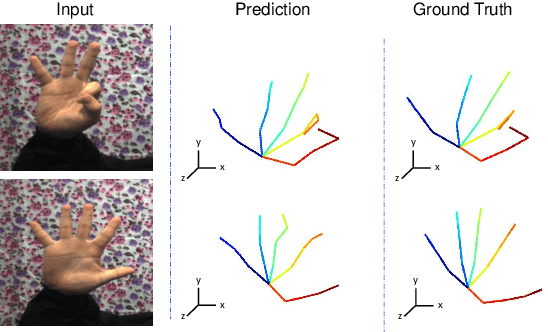
3D hand pose estimation (HPE) is the process of locating the joints of the hand in 3D from any visual input. HPE has recently received an increased amount of attention due to its key role in a variety of human-computer interaction applications. Recent HPE methods have demonstrated the advantages of employing videos or multi-view images, allowing for more robust HPE systems. Accordingly, in this study, we propose a new method to perform Sequential learning with Transformer for Hand Pose (SeTHPose) estimation. Our SeTHPose pipeline begins by extracting visual embeddings from individual hand images. We then use a transformer encoder to learn the sequential context along time or viewing angles and generate accurate 2D hand joint locations. Then, a graph convolutional neural network with a U-Net configuration is used to convert the 2D hand joint locations to 3D poses. Our experiments show that SeTHPose performs well on both hand sequence varieties, temporal and angular. Also, SeTHPose outperforms other methods in the field to achieve new state-of-the-art results on two public available sequential datasets, STB and MuViHand.
WHIS: Hearing impairment simulator based on the gammachirp auditory filterbank
Jun 14, 2022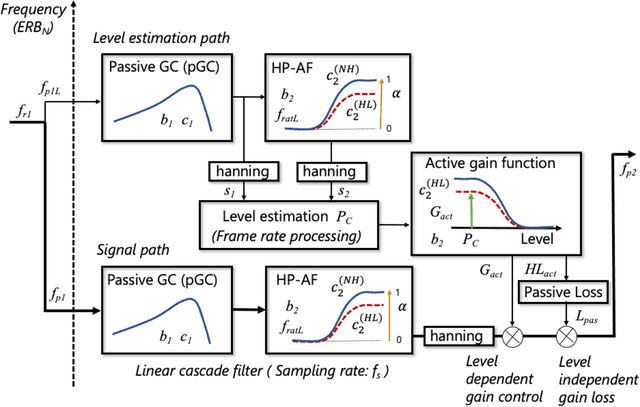
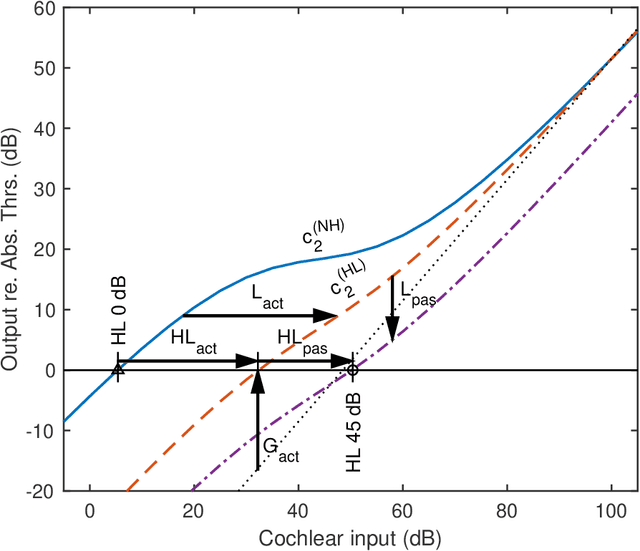
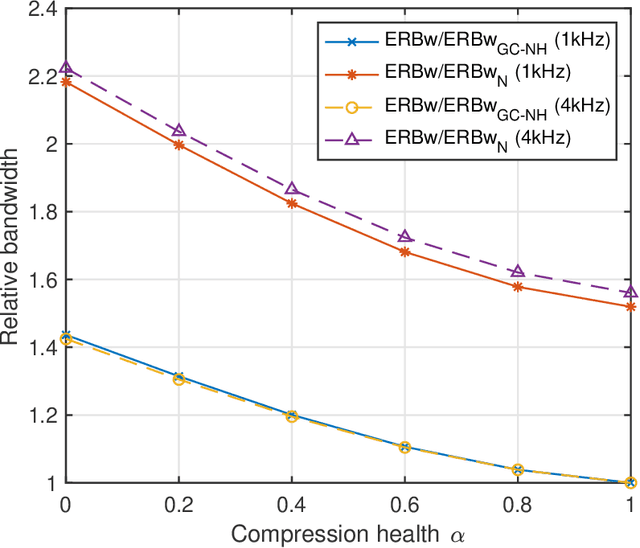
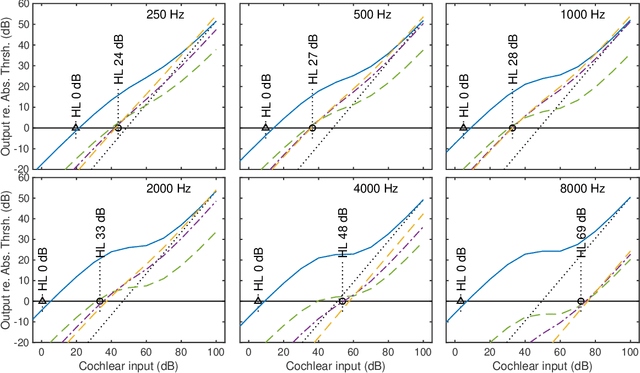
A new version of a hearing impairment simulator (WHIS) was implemented based on a revised version of the gammachirp filterbank (GCFB), which incorporates fast frame-based processing, absolute threshold (AT), an audiogram of a hearing-impaired (HI) listener, and a parameter to control the cochlear input-output (IO) function. The parameter referred to as the compression health $\alpha$ controlled the slope of the IO function to range from normal hearing (NH) listeners to HI listeners, without largely changing the total hearing loss (HL). The new WHIS was designed provide an NH listener the same EPs as those of a target HI listener.The analysis part of WHIS was almost the same as that of the revised GCFB, except that the IO function was used instead of the gain function. We proposed two synthesis methods: a direct time-varying filter for perceptually small distortion and a filterbank analysis-synthesis for further HI simulations including temporal smearing. We evaluated the WHIS family and a Cambridge version of the HL simulator (CamHLS) in terms of differences in the IO function and spectral distance. The IO functions were simulated fairly well at $\alpha$ less than 0.5 but not at $\alpha$ equal to 1. Thus, it is difficult to simulate the HL when the IO function is sufficiently healthy. This is a fundamental limit of any existing HL simulator as well as WHIS. The new WHIS yielded a smaller spectral distortion than CamHLS and was fairly compatible with the previous version.
BiT: Robustly Binarized Multi-distilled Transformer
May 25, 2022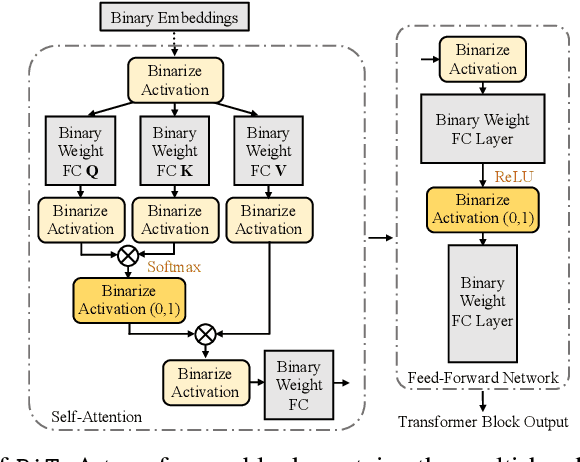
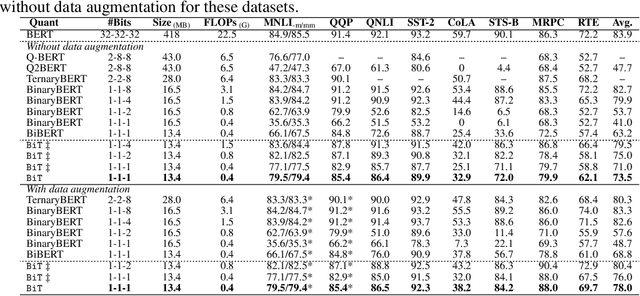

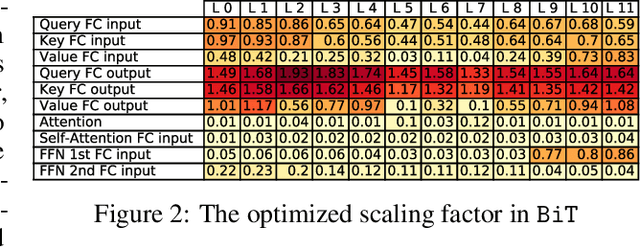
Modern pre-trained transformers have rapidly advanced the state-of-the-art in machine learning, but have also grown in parameters and computational complexity, making them increasingly difficult to deploy in resource-constrained environments. Binarization of the weights and activations of the network can significantly alleviate these issues, however is technically challenging from an optimization perspective. In this work, we identify a series of improvements which enables binary transformers at a much higher accuracy than what was possible previously. These include a two-set binarization scheme, a novel elastic binary activation function with learned parameters, and a method to quantize a network to its limit by successively distilling higher precision models into lower precision students. These approaches allow for the first time, fully binarized transformer models that are at a practical level of accuracy, approaching a full-precision BERT baseline on the GLUE language understanding benchmark within as little as 5.9%.
Scalable Kernel-Based Minimum Mean Square Error Estimator for Accelerated Image Error Concealment
May 23, 2022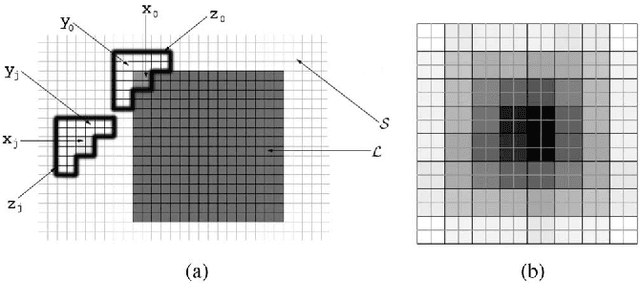

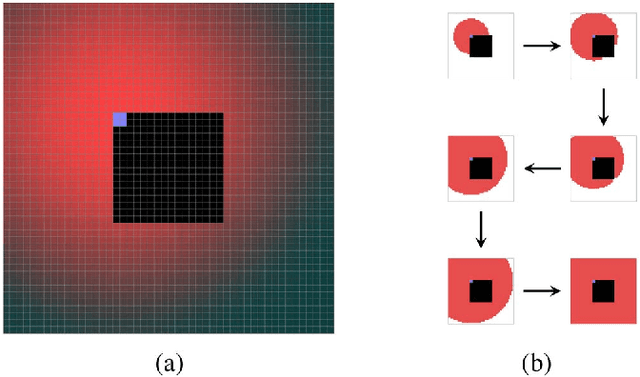
Error concealment is of great importance for block-based video systems, such as DVB or video streaming services. In this paper, we propose a novel scalable spatial error concealment algorithm that aims at obtaining high quality reconstructions with reduced computational burden. The proposed technique exploits the excellent reconstructing abilities of the kernel-based minimum mean square error K-MMSE estimator. We propose to decompose this approach into a set of hierarchically stacked layers. The first layer performs the basic reconstruction that the subsequent layers can eventually refine. In addition, we design a layer management mechanism, based on profiles, that dynamically adapts the use of higher layers to the visual complexity of the area being reconstructed. The proposed technique outperforms other state-of-the-art algorithms and produces high quality reconstructions, equivalent to K-MMSE, while requiring around one tenth of its computational time.
Focal Sparse Convolutional Networks for 3D Object Detection
Apr 26, 2022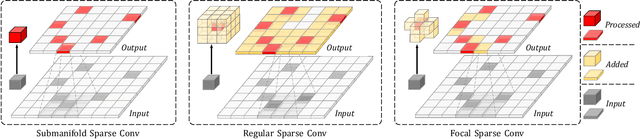
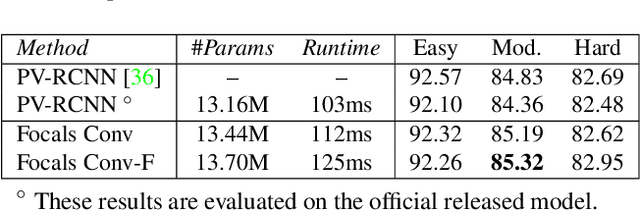

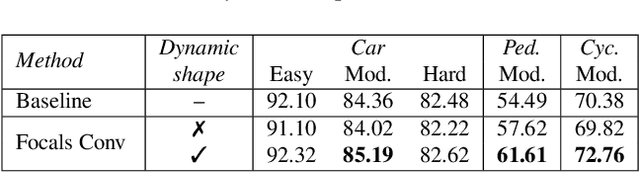
Non-uniformed 3D sparse data, e.g., point clouds or voxels in different spatial positions, make contribution to the task of 3D object detection in different ways. Existing basic components in sparse convolutional networks (Sparse CNNs) process all sparse data, regardless of regular or submanifold sparse convolution. In this paper, we introduce two new modules to enhance the capability of Sparse CNNs, both are based on making feature sparsity learnable with position-wise importance prediction. They are focal sparse convolution (Focals Conv) and its multi-modal variant of focal sparse convolution with fusion, or Focals Conv-F for short. The new modules can readily substitute their plain counterparts in existing Sparse CNNs and be jointly trained in an end-to-end fashion. For the first time, we show that spatially learnable sparsity in sparse convolution is essential for sophisticated 3D object detection. Extensive experiments on the KITTI, nuScenes and Waymo benchmarks validate the effectiveness of our approach. Without bells and whistles, our results outperform all existing single-model entries on the nuScenes test benchmark at the paper submission time. Code and models are at https://github.com/dvlab-research/FocalsConv.