 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
(Quasi-)Real-Time Inversion of Airborne Time-Domain Electromagnetic Data via Artificial Neural Network
Nov 06, 2020
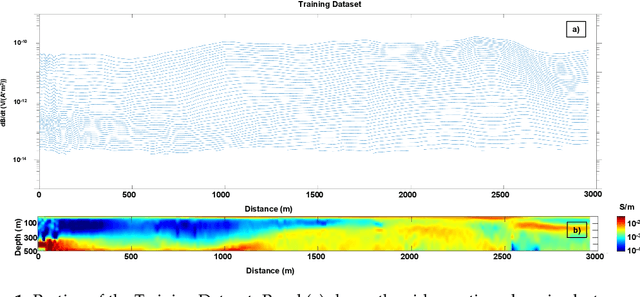
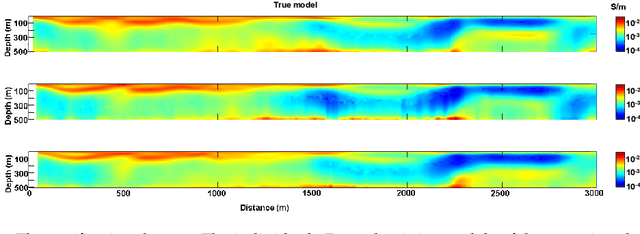
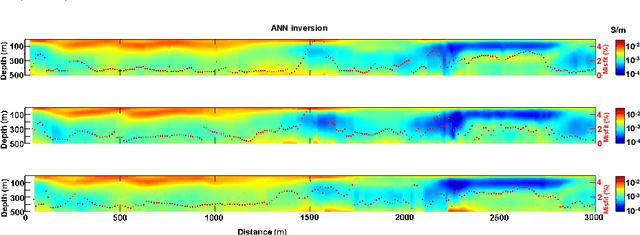
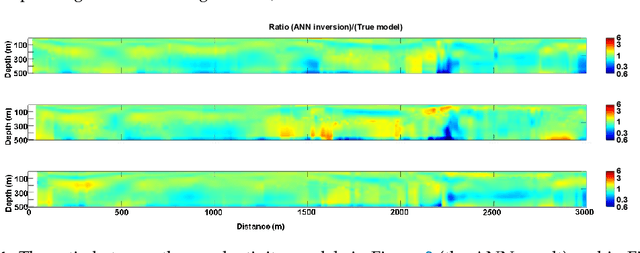
The possibility to have results very quickly after, or even during, the collection of electromagnetic data would be important, not only for quality check purposes, but also for adjusting the location of the proposed flight lines during an airborne time-domain acquisition. This kind of readiness could have a large impact in terms of optimization of the Value of Information of the measurements to be acquired. In addition, the importance of having fast tools for retrieving resistivity models from airborne time-domain data is demonstrated by the fact that Conductivity-Depth Imaging methodologies are still the standard in mineral exploration. In fact, they are extremely computationally efficient, and, at the same time, they preserve a very high lateral resolution. For these reasons, they are often preferred to inversion strategies even if the latter approaches are generally more accurate in terms of proper reconstruction of the depth of the targets and of reliable retrieval of true resistivity values of the subsurface. In this research, we discuss a novel approach, based on neural network techniques, capable of retrieving resistivity models with a quality comparable with the inversion strategy, but in a fraction of the time. We demonstrate the advantages of the proposed novel approach on synthetic and field datasets.
Zero-Shot Audio Classification using Image Embeddings
Jun 10, 2022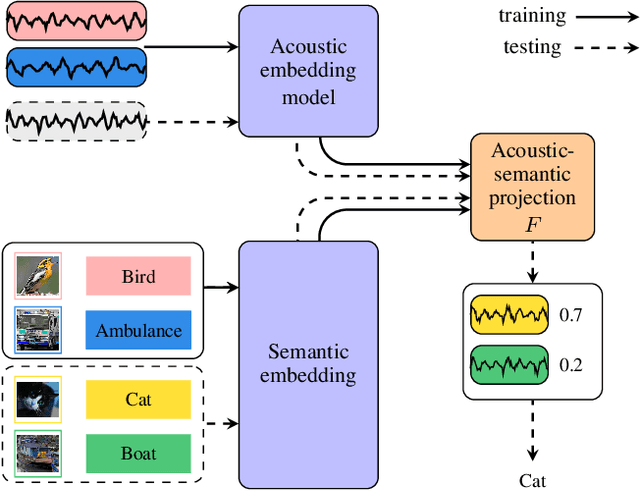
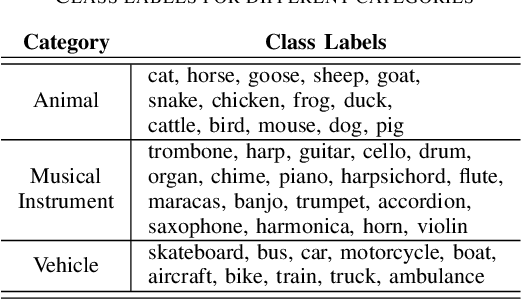
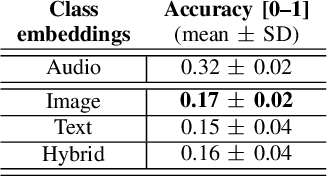
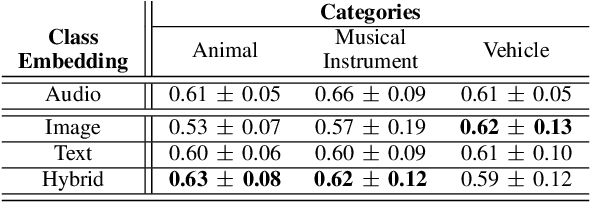
Supervised learning methods can solve the given problem in the presence of a large set of labeled data. However, the acquisition of a dataset covering all the target classes typically requires manual labeling which is expensive and time-consuming. Zero-shot learning models are capable of classifying the unseen concepts by utilizing their semantic information. The present study introduces image embeddings as side information on zero-shot audio classification by using a nonlinear acoustic-semantic projection. We extract the semantic image representations from the Open Images dataset and evaluate the performance of the models on an audio subset of AudioSet using semantic information in different domains; image, audio, and textual. We demonstrate that the image embeddings can be used as semantic information to perform zero-shot audio classification. The experimental results show that the image and textual embeddings display similar performance both individually and together. We additionally calculate the semantic acoustic embeddings from the test samples to provide an upper limit to the performance. The results show that the classification performance is highly sensitive to the semantic relation between test and training classes and textual and image embeddings can reach up to the semantic acoustic embeddings when the seen and unseen classes are semantically similar.
Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables
Aug 19, 2021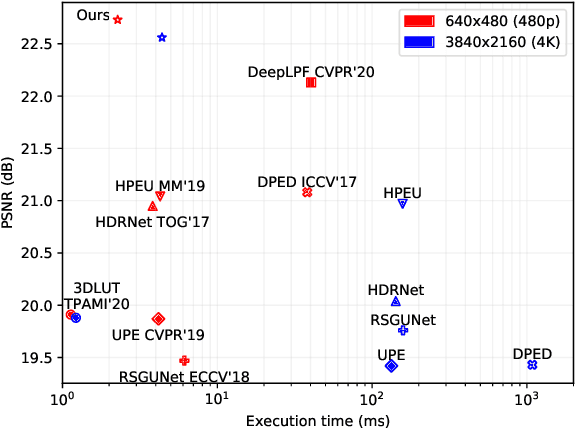
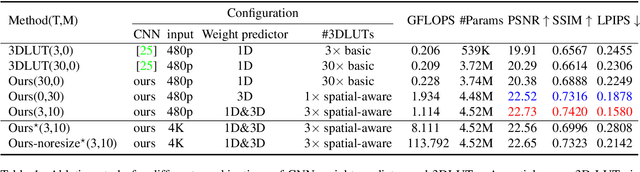
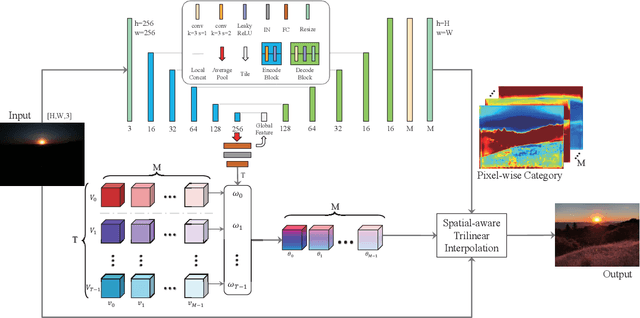
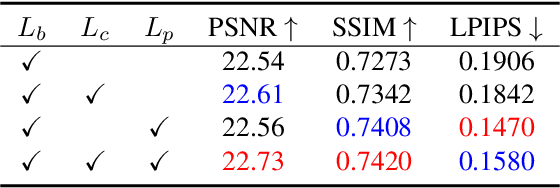
Recently, deep learning-based image enhancement algorithms achieved state-of-the-art (SOTA) performance on several publicly available datasets. However, most existing methods fail to meet practical requirements either for visual perception or for computation efficiency, especially for high-resolution images. In this paper, we propose a novel real-time image enhancer via learnable spatial-aware 3-dimentional lookup tables(3D LUTs), which well considers global scenario and local spatial information. Specifically, we introduce a light weight two-head weight predictor that has two outputs. One is a 1D weight vector used for image-level scenario adaptation, the other is a 3D weight map aimed for pixel-wise category fusion. We learn the spatial-aware 3D LUTs and fuse them according to the aforementioned weights in an end-to-end manner. The fused LUT is then used to transform the source image into the target tone in an efficient way. Extensive results show that our model outperforms SOTA image enhancement methods on public datasets both subjectively and objectively, and that our model only takes about 4ms to process a 4K resolution image on one NVIDIA V100 GPU.
A multi-model-based deep learning framework for short text multiclass classification with the imbalanced and extremely small data set
Jun 24, 2022
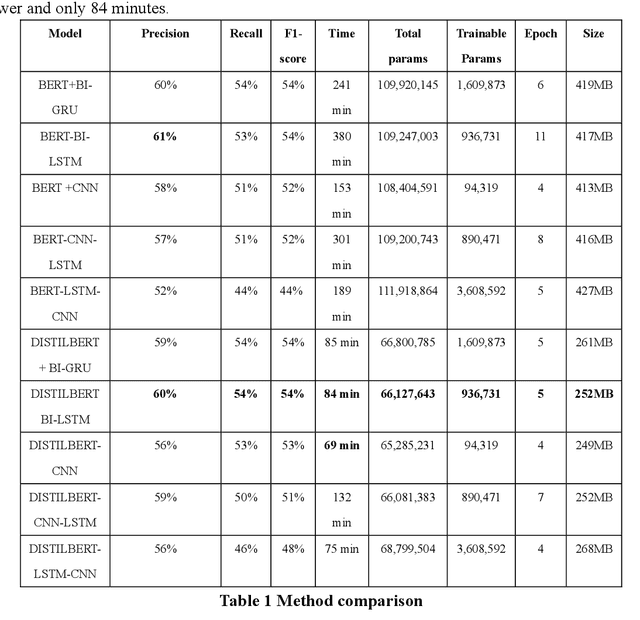
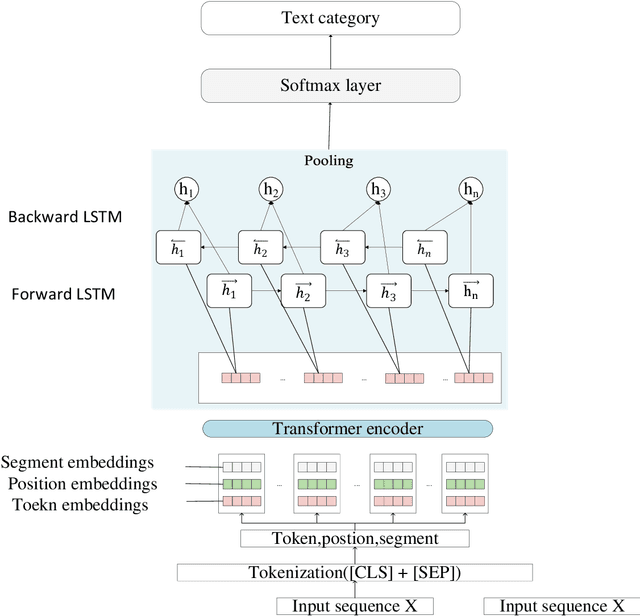

Text classification plays an important role in many practical applications. In the real world, there are extremely small datasets. Most existing methods adopt pre-trained neural network models to handle this kind of dataset. However, these methods are either difficult to deploy on mobile devices because of their large output size or cannot fully extract the deep semantic information between phrases and clauses. This paper proposes a multimodel-based deep learning framework for short-text multiclass classification with an imbalanced and extremely small data set. Our framework mainly includes five layers: The encoder layer uses DISTILBERT to obtain context-sensitive dynamic word vectors that are difficult to represent in traditional feature engineering methods. Since the transformer part of this layer is distilled, our framework is compressed. Then, we use the next two layers to extract deep semantic information. The output of the encoder layer is sent to a bidirectional LSTM network, and the feature matrix is extracted hierarchically through the LSTM at the word and sentence level to obtain the fine-grained semantic representation. After that, the max-pooling layer converts the feature matrix into a lower-dimensional matrix, preserving only the obvious features. Finally, the feature matrix is taken as the input of a fully connected softmax layer, which contains a function that can convert the predicted linear vector into the output value as the probability of the text in each classification. Extensive experiments on two public benchmarks demonstrate the effectiveness of our proposed approach on an extremely small data set. It retains the state-of-the-art baseline performance in terms of precision, recall, accuracy, and F1 score, and through the model size, training time, and convergence epoch, we can conclude that our method can be deployed faster and lighter on mobile devices.
Twitter conversations predict the daily confirmed COVID-19 cases
Jun 21, 2022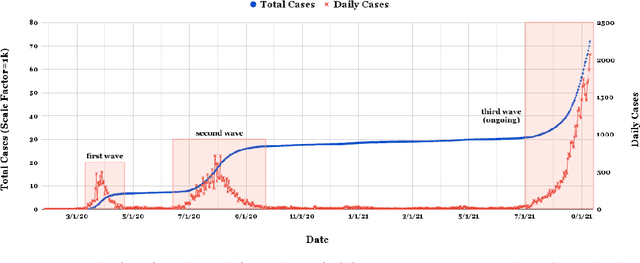
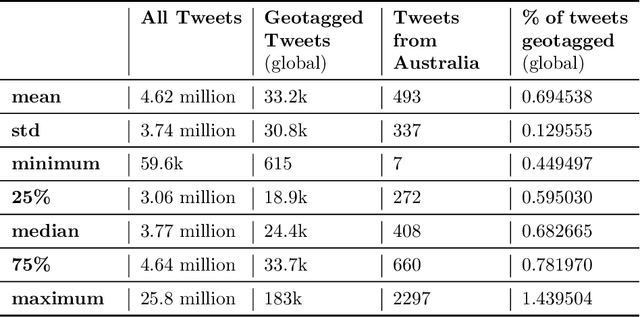
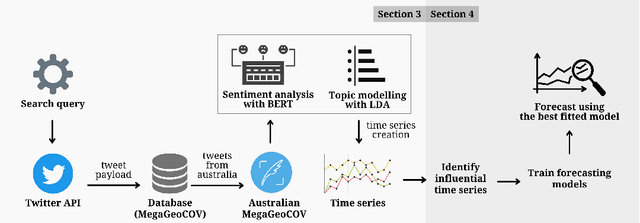
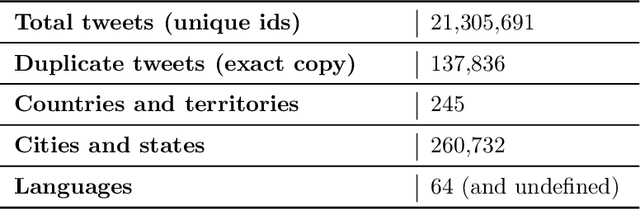
As of writing this paper, COVID-19 (Coronavirus disease 2019) has spread to more than 220 countries and territories. Following the outbreak, the pandemic's seriousness has made people more active on social media, especially on the microblogging platforms such as Twitter and Weibo. The pandemic-specific discourse has remained on-trend on these platforms for months now. Previous studies have confirmed the contributions of such socially generated conversations towards situational awareness of crisis events. The early forecasts of cases are essential to authorities to estimate the requirements of resources needed to cope with the outgrowths of the virus. Therefore, this study attempts to incorporate the public discourse in the design of forecasting models particularly targeted for the steep-hill region of an ongoing wave. We propose a sentiment-involved topic-based methodology for designing multiple time series from publicly available COVID-19 related Twitter conversations. As a use case, we implement the proposed methodology on Australian COVID-19 daily cases and Twitter conversations generated within the country. Experimental results: (i) show the presence of latent social media variables that Granger-cause the daily COVID-19 confirmed cases, and (ii) confirm that those variables offer additional prediction capability to forecasting models. Further, the results show that the inclusion of social media variables for modeling introduces 48.83--51.38% improvements on RMSE over the baseline models. We also release the large-scale COVID-19 specific geotagged global tweets dataset, MegaGeoCOV, to the public anticipating that the geotagged data of this scale would aid in understanding the conversational dynamics of the pandemic through other spatial and temporal contexts.
Spectral Bias Outside the Training Set for Deep Networks in the Kernel Regime
Jun 06, 2022
We provide quantitative bounds measuring the $L^2$ difference in function space between the trajectory of a finite-width network trained on finitely many samples from the idealized kernel dynamics of infinite width and infinite data. An implication of the bounds is that the network is biased to learn the top eigenfunctions of the Neural Tangent Kernel not just on the training set but over the entire input space. This bias depends on the model architecture and input distribution alone and thus does not depend on the target function which does not need to be in the RKHS of the kernel. The result is valid for deep architectures with fully connected, convolutional, and residual layers. Furthermore the width does not need to grow polynomially with the number of samples in order to obtain high probability bounds up to a stopping time. The proof exploits the low-effective-rank property of the Fisher Information Matrix at initialization, which implies a low effective dimension of the model (far smaller than the number of parameters). We conclude that local capacity control from the low effective rank of the Fisher Information Matrix is still underexplored theoretically.
FRI-TEM: Time Encoding Sampling of Finite-Rate-of-Innovation Signals
Jun 10, 2021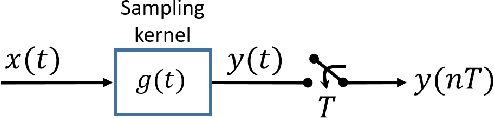
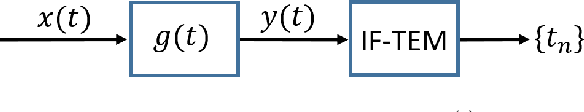
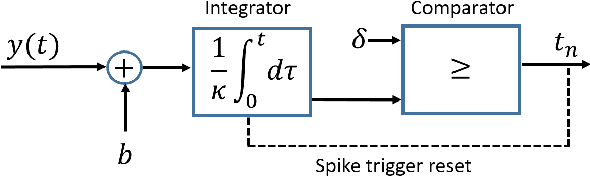
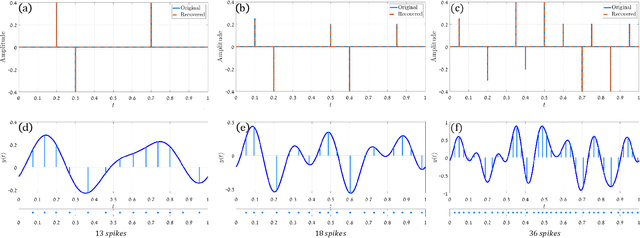
Classical sampling is based on acquiring signal amplitudes at specific points in time, with the minimal sampling rate dictated by the degrees of freedom in the signal. The samplers in this framework are controlled by a global clock that operates at a rate greater than or equal to the minimal sampling rate. At high sampling rates, clocks are power-consuming and prone to electromagnetic interference. An integrate-and-fire time encoding machine (IF-TEM) is an alternative power-efficient sampling mechanism which does not require a global clock. Here, the samples are irregularly spaced threshold-based samples. In this paper, we investigate the problem of sampling finite-rate-of-innovation (FRI) signals using an IF-TEM. We provide theoretical recovery guarantees for an FRI signal with arbitrary pulse shape and without any constraint on the minimum separation between the pulses. In particular, we show how to design a sampling kernel, IF-TEM, and recovery method such that the FRI signals are perfectly reconstructed. We then propose a modification to the sampling kernel to improve noise robustness. Our results enable designing low-cost and energy-efficient analog-to-digital converters for FRI signals.
Boundary informed inverse PDE problems on discrete Riemann surfaces
Jun 06, 2022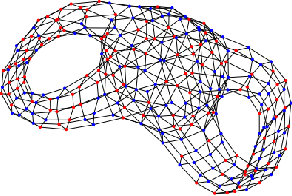
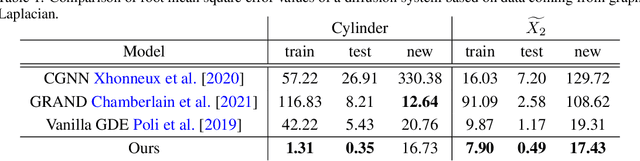

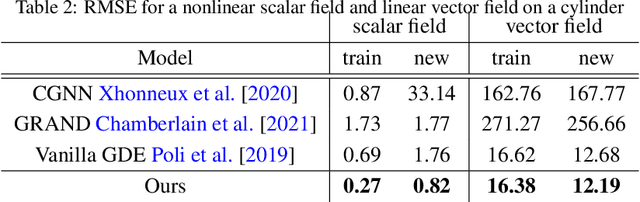
We employ neural networks to tackle inverse partial differential equations on discretized Riemann surfaces with boundary. To this end, we introduce the concept of a graph with boundary which models these surfaces in a natural way. Our method uses a message passing technique to keep track of an unknown differential operator while using neural ODE solvers through the method of lines to capture the evolution in time. As training data, we use noisy and incomplete observations of sheaves on graphs at various timestamps. The novelty of this approach is in working with manifolds with nontrivial topology and utilizing the data on the graph boundary through a teacher forcing technique. Despite the increasing interest in learning dynamical systems from finite observations, many current methods are limited in two general ways: first, they work with topologically trivial spaces, and second, they fail to handle the boundary data on the ground space in a systematic way. The present work is an attempt at addressing these limitations. We run experiments with synthetic data of linear and nonlinear diffusion systems on orientable surfaces with positive genus and boundary, and moreover, provide evidences for improvements upon the existing paradigms.
ED2LM: Encoder-Decoder to Language Model for Faster Document Re-ranking Inference
Apr 25, 2022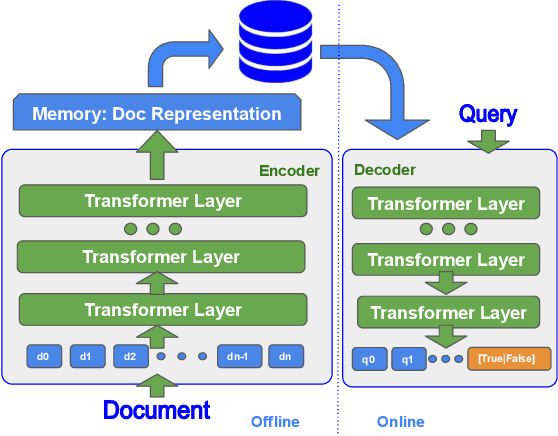
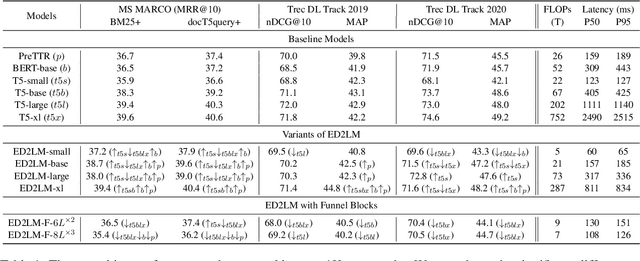
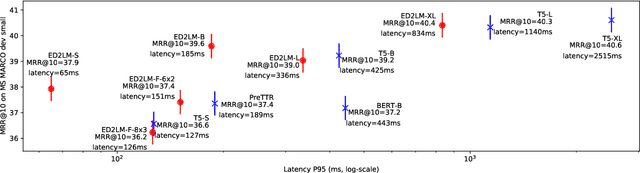
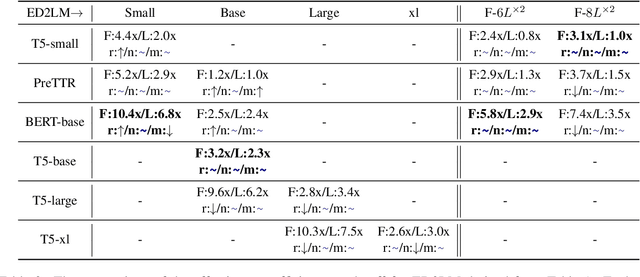
State-of-the-art neural models typically encode document-query pairs using cross-attention for re-ranking. To this end, models generally utilize an encoder-only (like BERT) paradigm or an encoder-decoder (like T5) approach. These paradigms, however, are not without flaws, i.e., running the model on all query-document pairs at inference-time incurs a significant computational cost. This paper proposes a new training and inference paradigm for re-ranking. We propose to finetune a pretrained encoder-decoder model using in the form of document to query generation. Subsequently, we show that this encoder-decoder architecture can be decomposed into a decoder-only language model during inference. This results in significant inference time speedups since the decoder-only architecture only needs to learn to interpret static encoder embeddings during inference. Our experiments show that this new paradigm achieves results that are comparable to the more expensive cross-attention ranking approaches while being up to 6.8X faster. We believe this work paves the way for more efficient neural rankers that leverage large pretrained models.
Norm Participation Grounds Language
Jun 06, 2022The striking recent advances in eliciting seemingly meaningful language behaviour from language-only machine learning models have only made more apparent, through the surfacing of clear limitations, the need to go beyond the language-only mode and to ground these models "in the world". Proposals for doing so vary in the details, but what unites them is that the solution is sought in the addition of non-linguistic data types such as images or video streams, while largely keeping the mode of learning constant. I propose a different, and more wide-ranging conception of how grounding should be understood: What grounds language is its normative nature. There are standards for doing things right, these standards are public and authoritative, while at the same time acceptance of authority can and must be disputed and negotiated, in interactions in which only bearers of normative status can rightfully participate. What grounds language, then, is the determined use that language users make of it, and what it is grounded in is the community of language users. I sketch this idea, and draw some conclusions for work on computational modelling of meaningful language use.