 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CitySpec: An Intelligent Assistant System for Requirement Specification in Smart Cities
Jun 07, 2022
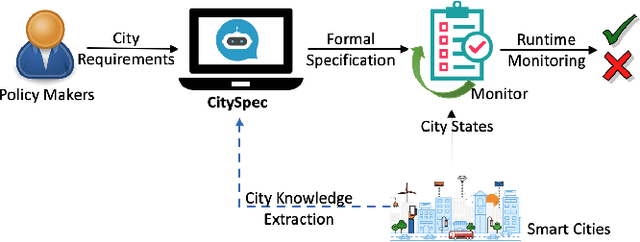
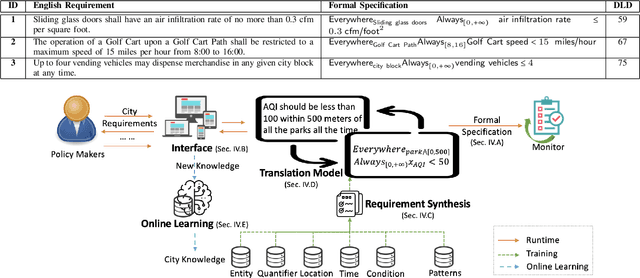
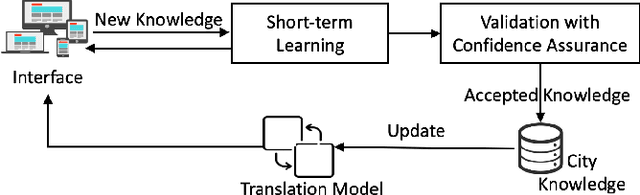
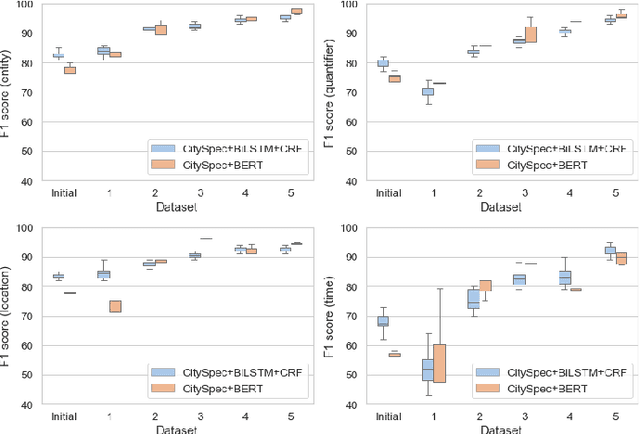
An increasing number of monitoring systems have been developed in smart cities to ensure that real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policy makers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with validation under uncertainty. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning).
Development of a hybrid model-based data-driven collision avoidance algorithm for vehicles in low adhesion conditions
May 30, 2022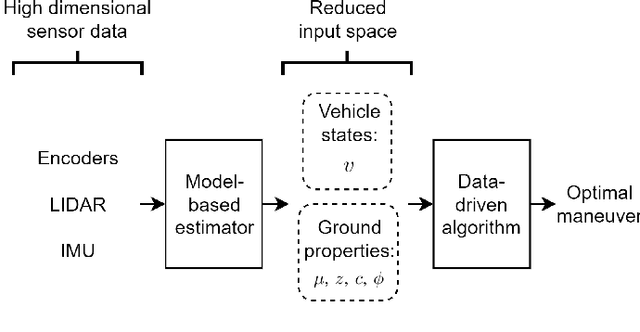
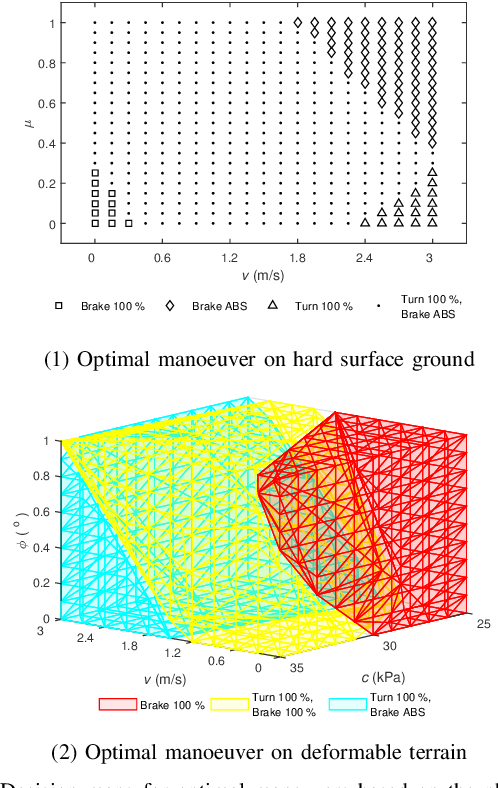
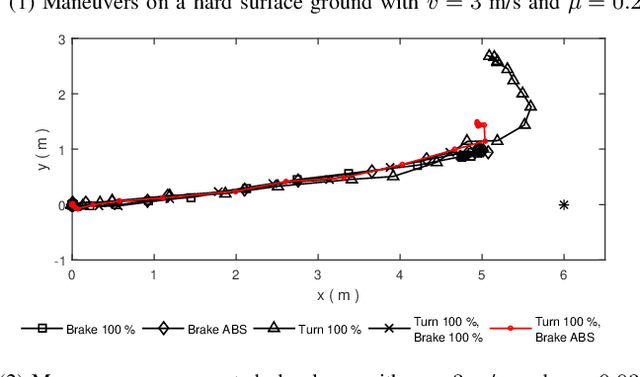

Winter conditions, characterized by the presence of ice and snow on the ground, are more likely to lead to road accidents. This paper presents an experimental proof of concept of a collision avoidance algorithm for vehicles evolving in low adhesion conditions, implemented on a 1/5th scale car platform. In the proposed approach, a model-based estimator first processes the high-dimensional sensors data of the IMU, LIDAR and encoders to estimate physically relevant vehicle and ground conditions parameters such as the inertial velocity of the vehicle $v$, the friction coefficient $\mu$, the cohesion $c$ and the internal shear angle $\phi$. Then, a data-driven predictor is trained to predict the optimal maneuver to perform in the situation characterized by the estimated parameters. Experiments show that it is possible to 1) produce a real-time estimate of the relevant ground parameters, and 2) determine an optimal collision avoidance maneuver based on the estimated parameters.
D'ARTAGNAN: Counterfactual Video Generation
Jun 03, 2022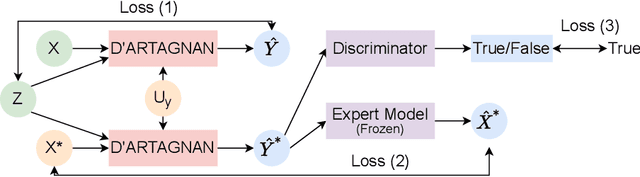


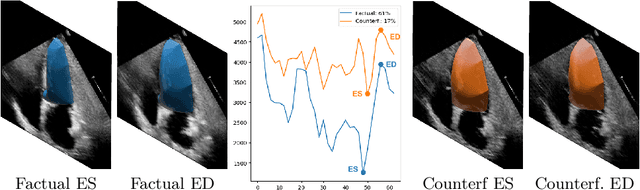
Causally-enabled machine learning frameworks could help clinicians to identify the best course of treatments by answering counterfactual questions. We explore this path for the case of echocardiograms by looking into the variation of the Left Ventricle Ejection Fraction, the most essential clinical metric gained from these examinations. We combine deep neural networks, twin causal networks and generative adversarial methods for the first time to build D'ARTAGNAN (Deep ARtificial Twin-Architecture GeNerAtive Networks), a novel causal generative model. We demonstrate the soundness of our approach on a synthetic dataset before applying it to cardiac ultrasound videos by answering the question: "What would this echocardiogram look like if the patient had a different ejection fraction?". To do so, we generate new ultrasound videos, retaining the video style and anatomy of the original patient, with variations of the Ejection Fraction conditioned on a given input. We achieve an SSIM score of 0.79 and an R2 score of 0.51 on the counterfactual videos. Code and models are available at https://github.com/HReynaud/dartagnan.
Balanced Product of Experts for Long-Tailed Recognition
Jun 10, 2022



Many real-world recognition problems suffer from an imbalanced or long-tailed label distribution. Those distributions make representation learning more challenging due to limited generalization over the tail classes. If the test distribution differs from the training distribution, e.g. uniform versus long-tailed, the problem of the distribution shift needs to be addressed. To this aim, recent works have extended softmax cross-entropy using margin modifications, inspired by Bayes' theorem. In this paper, we generalize several approaches with a Balanced Product of Experts (BalPoE), which combines a family of models with different test-time target distributions to tackle the imbalance in the data. The proposed experts are trained in a single stage, either jointly or independently, and fused seamlessly into a BalPoE. We show that BalPoE is Fisher consistent for minimizing the balanced error and perform extensive experiments to validate the effectiveness of our approach. Finally, we investigate the effect of Mixup in this setting, discovering that regularization is a key ingredient for learning calibrated experts. Our experiments show that a regularized BalPoE can perform remarkably well in test accuracy and calibration metrics, leading to state-of-the-art results on CIFAR-100-LT, ImageNet-LT, and iNaturalist-2018 datasets. The code will be made publicly available upon paper acceptance.
Universal Speech Enhancement with Score-based Diffusion
Jun 07, 2022
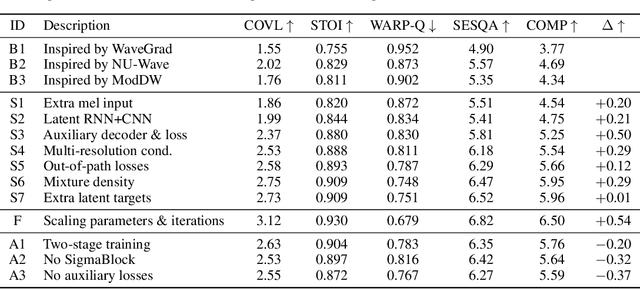
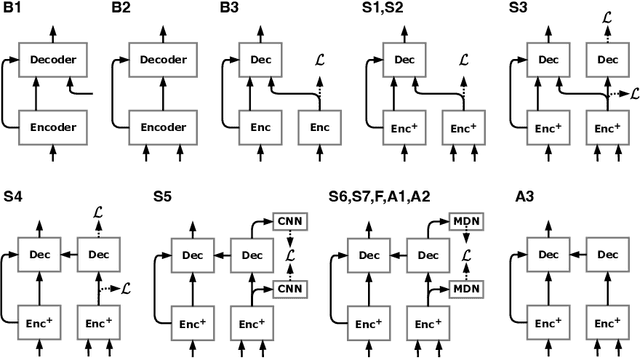
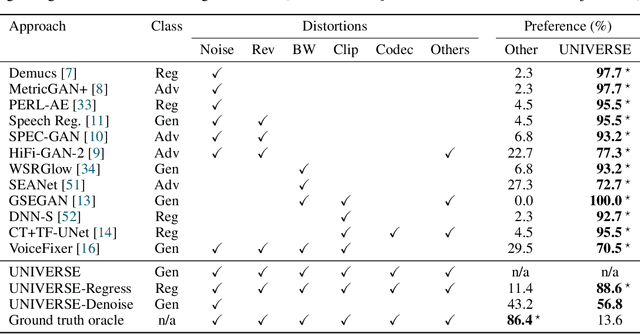
Removing background noise from speech audio has been the subject of considerable research and effort, especially in recent years due to the rise of virtual communication and amateur sound recording. Yet background noise is not the only unpleasant disturbance that can prevent intelligibility: reverb, clipping, codec artifacts, problematic equalization, limited bandwidth, or inconsistent loudness are equally disturbing and ubiquitous. In this work, we propose to consider the task of speech enhancement as a holistic endeavor, and present a universal speech enhancement system that tackles 55 different distortions at the same time. Our approach consists of a generative model that employs score-based diffusion, together with a multi-resolution conditioning network that performs enhancement with mixture density networks. We show that this approach significantly outperforms the state of the art in a subjective test performed by expert listeners. We also show that it achieves competitive objective scores with just 4-8 diffusion steps, despite not considering any particular strategy for fast sampling. We hope that both our methodology and technical contributions encourage researchers and practitioners to adopt a universal approach to speech enhancement, possibly framing it as a generative task.
Real-time Image Enhancer via Learnable Spatial-aware 3D Lookup Tables
Aug 19, 2021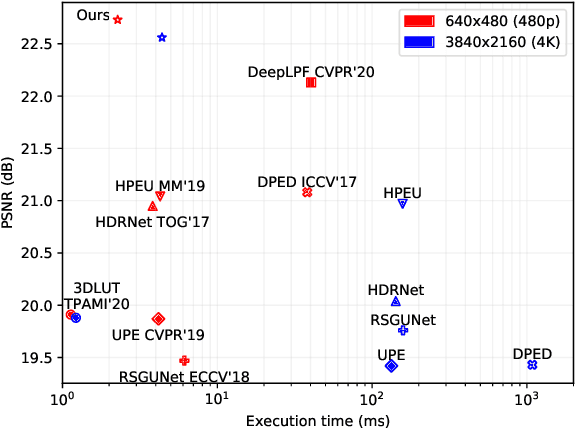
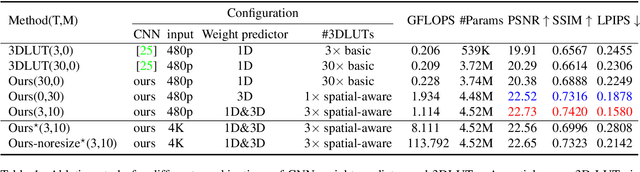
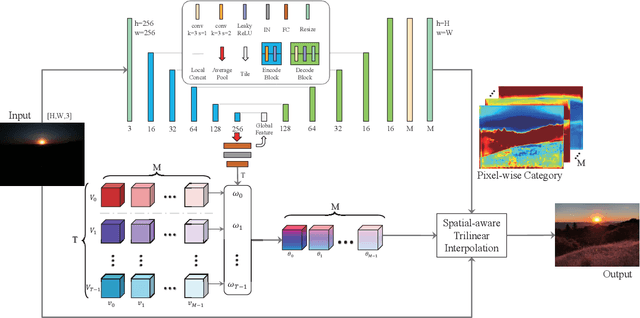
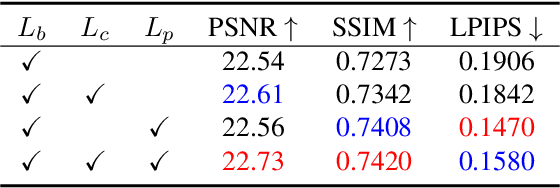
Recently, deep learning-based image enhancement algorithms achieved state-of-the-art (SOTA) performance on several publicly available datasets. However, most existing methods fail to meet practical requirements either for visual perception or for computation efficiency, especially for high-resolution images. In this paper, we propose a novel real-time image enhancer via learnable spatial-aware 3-dimentional lookup tables(3D LUTs), which well considers global scenario and local spatial information. Specifically, we introduce a light weight two-head weight predictor that has two outputs. One is a 1D weight vector used for image-level scenario adaptation, the other is a 3D weight map aimed for pixel-wise category fusion. We learn the spatial-aware 3D LUTs and fuse them according to the aforementioned weights in an end-to-end manner. The fused LUT is then used to transform the source image into the target tone in an efficient way. Extensive results show that our model outperforms SOTA image enhancement methods on public datasets both subjectively and objectively, and that our model only takes about 4ms to process a 4K resolution image on one NVIDIA V100 GPU.
Faster Sampling from Log-Concave Distributions over Polytopes via a Soft-Threshold Dikin Walk
Jun 19, 2022We consider the problem of sampling from a $d$-dimensional log-concave distribution $\pi(\theta) \propto e^{-f(\theta)}$ constrained to a polytope $K$ defined by $m$ inequalities. Our main result is a "soft-threshold'' variant of the Dikin walk Markov chain that requires at most $O((md + d L^2 R^2) \times md^{\omega-1}) \log(\frac{w}{\delta}))$ arithmetic operations to sample from $\pi$ within error $\delta>0$ in the total variation distance from a $w$-warm start, where $L$ is the Lipschitz-constant of $f$, $K$ is contained in a ball of radius $R$ and contains a ball of smaller radius $r$, and $\omega$ is the matrix-multiplication constant. When a warm start is not available, it implies an improvement of $\tilde{O}(d^{3.5-\omega})$ arithmetic operations on the previous best bound for sampling from $\pi$ within total variation error $\delta$, which was obtained with the hit-and-run algorithm, in the setting where $K$ is a polytope given by $m=O(d)$ inequalities and $LR = O(\sqrt{d})$. When a warm start is available, our algorithm improves by a factor of $d^2$ arithmetic operations on the best previous bound in this setting, which was obtained for a different version of the Dikin walk algorithm. Plugging our Dikin walk Markov chain into the post-processing algorithm of Mangoubi and Vishnoi (2021), we achieve further improvements in the dependence of the running time for the problem of generating samples from $\pi$ with infinity distance bounds in the special case when $K$ is a polytope.
Automated Coronary Calcium Scoring using U-Net Models through Semi-supervised Learning on Non-Gated CT Scans
Jun 13, 2022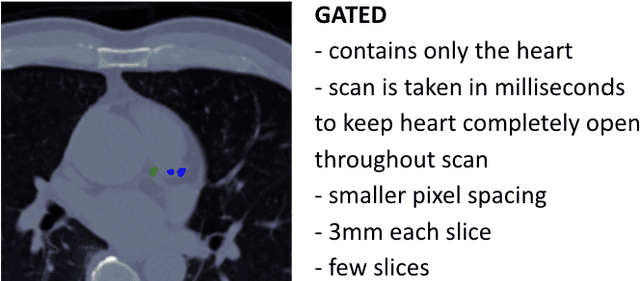

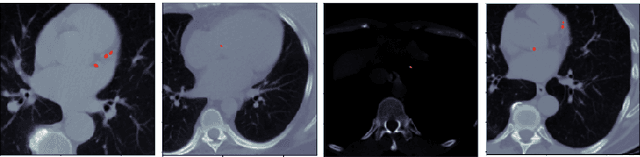
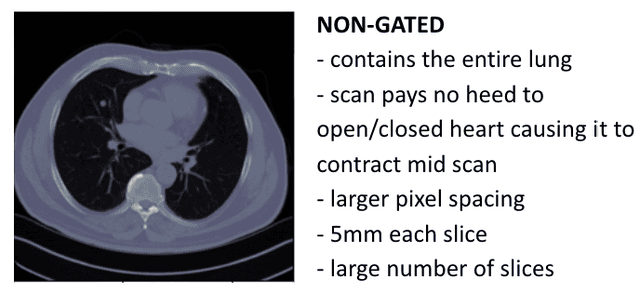
Every year, thousands of innocent people die due to heart attacks. Often undiagnosed heart attacks can hit people by surprise since many current medical plans don't cover the costs to require the searching of calcification on these scans. Only if someone is suspected to have a heart problem, a gated CT scan is taken, otherwise, there's no way for the patient to be aware of a possible heart attack/disease. While nongated CT scans are more periodically taken, it is harder to detect calcification and is usually taken for a purpose other than locating calcification in arteries. In fact, in real time coronary artery calcification scores are only calculated on gated CT scans, not nongated CT scans. After training a unet model on the Coronary Calcium and chest CT's gated scans, it received a DICE coefficient of 0.95 on its untouched test set. This model was used to predict on nongated CT scans, performing with a mean absolute error (MAE) of 674.19 and bucket classification accuracy of 41% (5 classes). Through the analysis of the images and the information stored in the images, mathematical equations were derived and used to automatically crop the images around the location of the heart. By performing semi-supervised learning the new cropped nongated scans were able to closely resemble gated CT scans, improving the performance by 91% in MAE (62.38) and 23% in accuracy.
Putting GPT-3's Creativity to the (Alternative Uses) Test
Jun 10, 2022
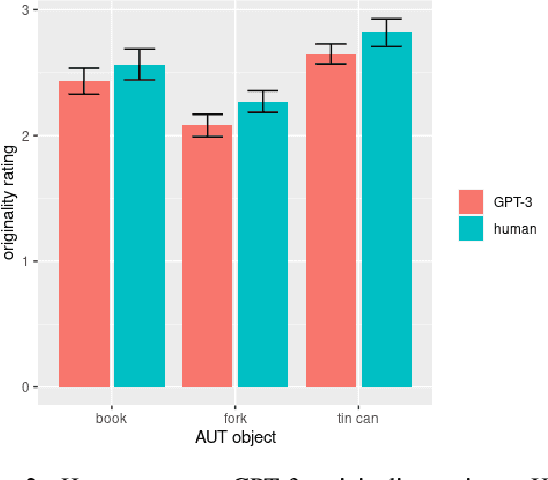
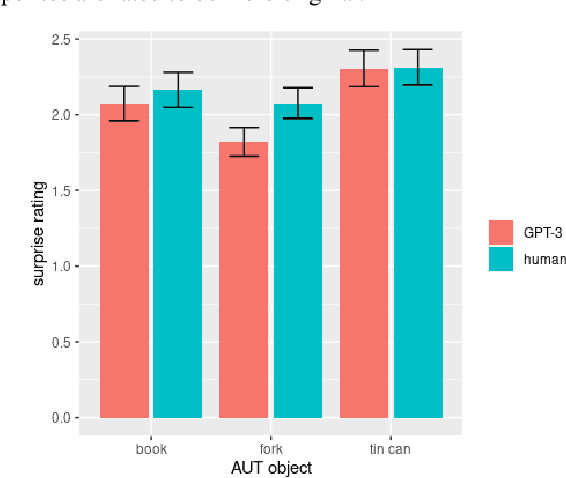
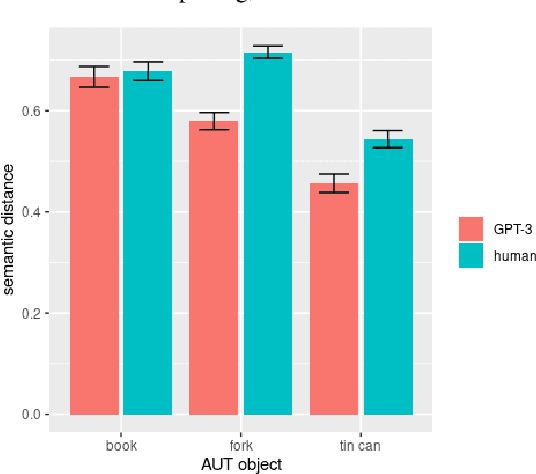
AI large language models have (co-)produced amazing written works from newspaper articles to novels and poetry. These works meet the standards of the standard definition of creativity: being original and useful, and sometimes even the additional element of surprise. But can a large language model designed to predict the next text fragment provide creative, out-of-the-box, responses that still solve the problem at hand? We put Open AI's generative natural language model, GPT-3, to the test. Can it provide creative solutions to one of the most commonly used tests in creativity research? We assessed GPT-3's creativity on Guilford's Alternative Uses Test and compared its performance to previously collected human responses on expert ratings of originality, usefulness and surprise of responses, flexibility of each set of ideas as well as an automated method to measure creativity based on the semantic distance between a response and the AUT object in question. Our results show that -- on the whole -- humans currently outperform GPT-3 when it comes to creative output. But, we believe it is only a matter of time before GPT-3 catches up on this particular task. We discuss what this work reveals about human and AI creativity, creativity testing and our definition of creativity.
FRI-TEM: Time Encoding Sampling of Finite-Rate-of-Innovation Signals
Jun 10, 2021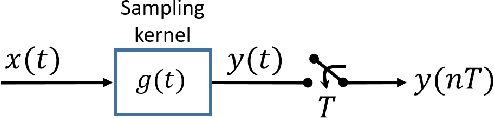
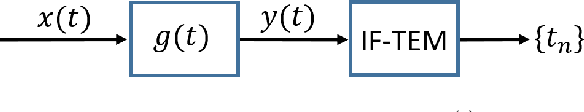
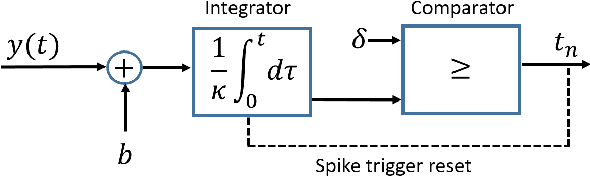
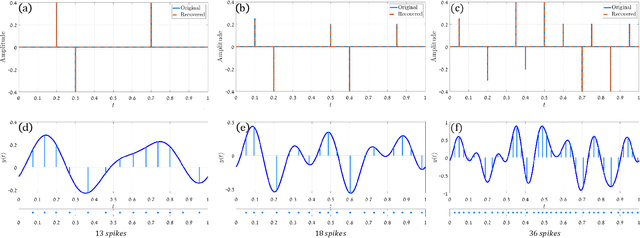
Classical sampling is based on acquiring signal amplitudes at specific points in time, with the minimal sampling rate dictated by the degrees of freedom in the signal. The samplers in this framework are controlled by a global clock that operates at a rate greater than or equal to the minimal sampling rate. At high sampling rates, clocks are power-consuming and prone to electromagnetic interference. An integrate-and-fire time encoding machine (IF-TEM) is an alternative power-efficient sampling mechanism which does not require a global clock. Here, the samples are irregularly spaced threshold-based samples. In this paper, we investigate the problem of sampling finite-rate-of-innovation (FRI) signals using an IF-TEM. We provide theoretical recovery guarantees for an FRI signal with arbitrary pulse shape and without any constraint on the minimum separation between the pulses. In particular, we show how to design a sampling kernel, IF-TEM, and recovery method such that the FRI signals are perfectly reconstructed. We then propose a modification to the sampling kernel to improve noise robustness. Our results enable designing low-cost and energy-efficient analog-to-digital converters for FRI signals.