 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Classification of ECG based on Hybrid Features using CNNs for Wearable Applications
Jun 14, 2022
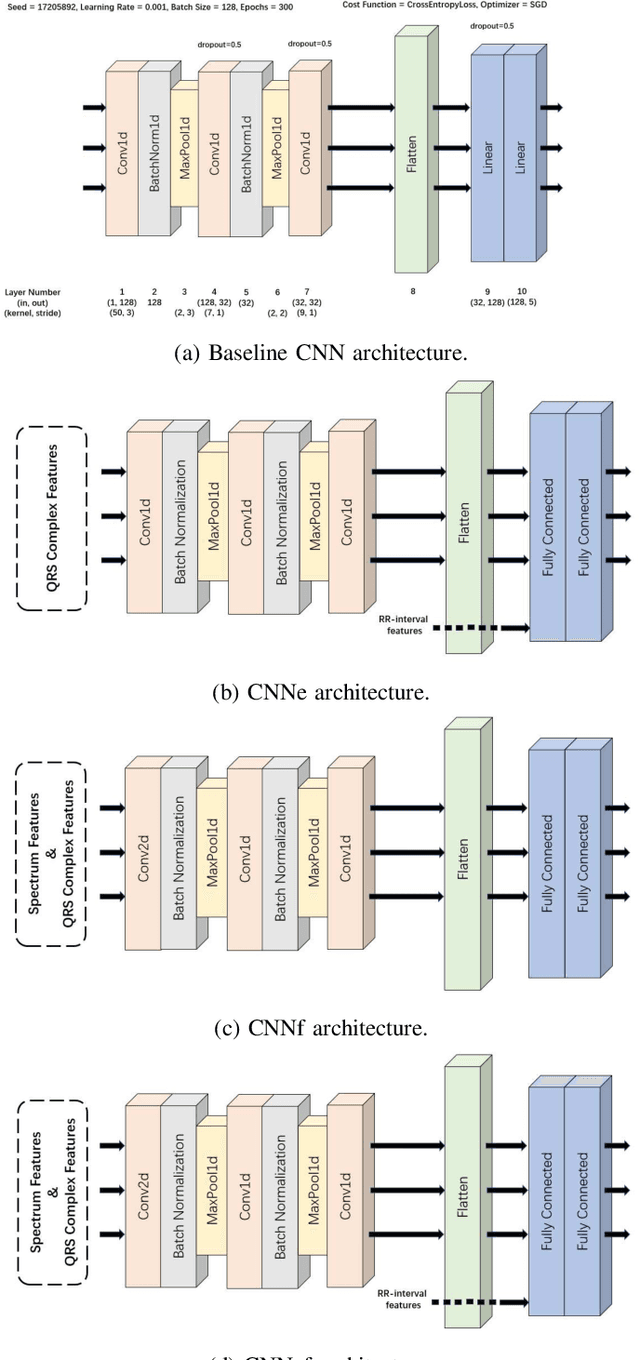
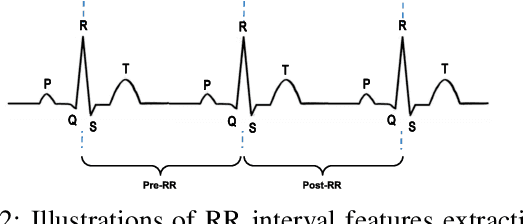
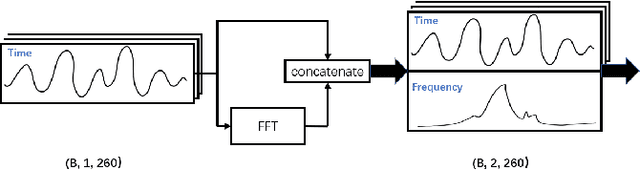
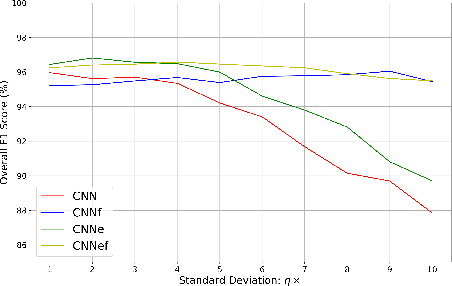
Sudden cardiac death and arrhythmia account for a large percentage of all deaths worldwide. Electrocardiography (ECG) is the most widely used screening tool for cardiovascular diseases. Traditionally, ECG signals are classified manually, requiring experience and great skill, while being time-consuming and prone to error. Thus machine learning algorithms have been widely adopted because of their ability to perform complex data analysis. Features derived from the points of interest in ECG - mainly Q, R, and S, are widely used for arrhythmia detection. In this work, we demonstrate improved performance for ECG classification using hybrid features and three different models, building on a 1-D convolutional neural network (CNN) model that we had proposed in the past. An RR interval features based model proposed in this work achieved an accuracy of 98.98%, which is an improvement over the baseline model. To make the model immune to noise, we updated the model using frequency features and achieved good sustained performance in presence of noise with a slightly lower accuracy of 98.69%. Further, another model combining the frequency features and the RR interval features was developed, which achieved a high accuracy of 99% with good sustained performance in noisy environments. Due to its high accuracy and noise immunity, the proposed model which combines multiple hybrid features, is well suited for ambulatory wearable sensing applications.
Life after BERT: What do Other Muppets Understand about Language?
May 21, 2022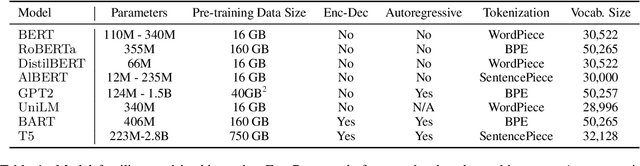

Existing pre-trained transformer analysis works usually focus only on one or two model families at a time, overlooking the variability of the architecture and pre-training objectives. In our work, we utilize the oLMpics benchmark and psycholinguistic probing datasets for a diverse set of 29 models including T5, BART, and ALBERT. Additionally, we adapt the oLMpics zero-shot setup for autoregressive models and evaluate GPT networks of different sizes. Our findings show that none of these models can resolve compositional questions in a zero-shot fashion, suggesting that this skill is not learnable using existing pre-training objectives. Furthermore, we find that global model decisions such as architecture, directionality, size of the dataset, and pre-training objective are not predictive of a model's linguistic capabilities.
Learning Dense Features for Point Cloud Registration Using Graph Attention Network
Jun 14, 2022
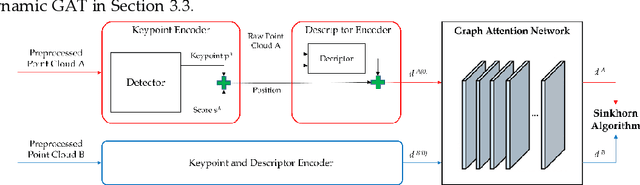
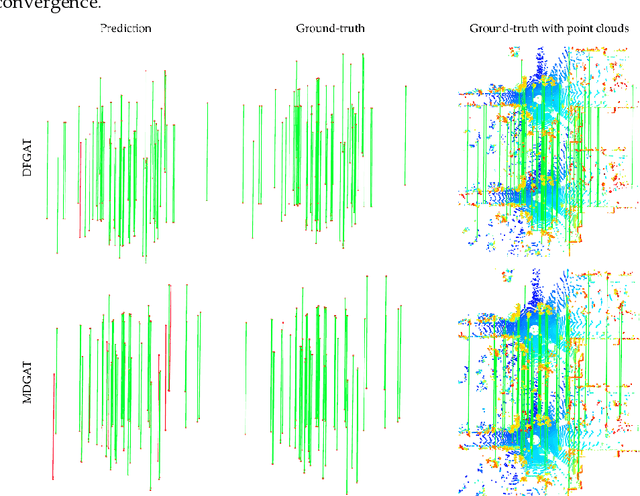
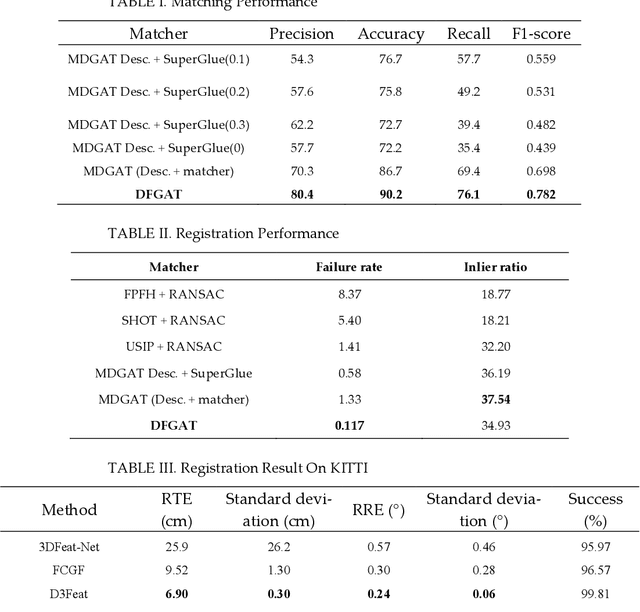
Point cloud registration is a fundamental task in many applications such as localization, mapping, tracking, and reconstruction. The successful registration relies on extracting robust and discriminative geometric features. Existing learning-based methods require high computing capacity for processing a large number of raw points at the same time. Although these approaches achieve convincing results, they are difficult to apply in real-world situations due to high computational costs. In this paper, we introduce a framework that efficiently and economically extracts dense features using graph attention network for point cloud matching and registration (DFGAT). The detector of the DFGAT is responsible for finding highly reliable key points in large raw data sets. The descriptor of the DFGAT takes these key points combined with their neighbors to extract invariant density features in preparation for the matching. The graph attention network uses the attention mechanism that enriches the relationships between point clouds. Finally, we consider this as an optimal transport problem and use the Sinkhorn algorithm to find positive and negative matches. We perform thorough tests on the KITTI dataset and evaluate the effectiveness of this approach. The results show that this method with the efficiently compact keypoint selection and description can achieve the best performance matching metrics and reach highest success ratio of 99.88% registration in comparison with other state-of-the-art approaches.
Addressing Confounding Feature Issue for Causal Recommendation
May 13, 2022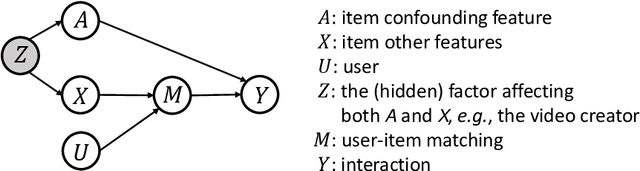

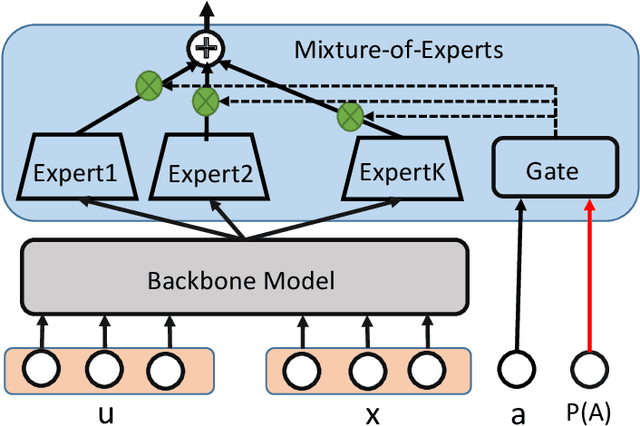
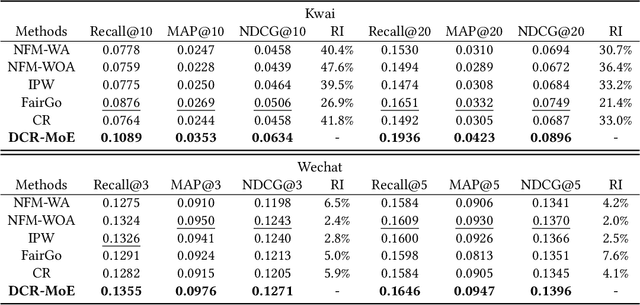
In recommender system, some feature directly affects whether an interaction would happen, making the happened interactions not necessarily indicate user preference. For instance, short videos are objectively easier to be finished even though the user does not like the video. We term such feature as confounding feature, and video length is a confounding feature in video recommendation. If we fit a model on such interaction data, just as done by most data-driven recommender systems, the model will be biased to recommend short videos more, and deviate from user actual requirement. This work formulates and addresses the problem from the causal perspective. Assuming there are some factors affecting both the confounding feature and other item features, e.g., the video creator, we find the confounding feature opens a backdoor path behind user item matching and introduces spurious correlation. To remove the effect of backdoor path, we propose a framework named Deconfounding Causal Recommendation (DCR), which performs intervened inference with do-calculus. Nevertheless, evaluating do calculus requires to sum over the prediction on all possible values of confounding feature, significantly increasing the time cost. To address the efficiency challenge, we further propose a mixture-of experts (MoE) model architecture, modeling each value of confounding feature with a separate expert module. Through this way, we retain the model expressiveness with few additional costs. We demonstrate DCR on the backbone model of neural factorization machine (NFM), showing that DCR leads to more accurate prediction of user preference with small inference time cost.
Beyond Value: CHECKLIST for Testing Inferences in Planning-Based RL
Jun 07, 2022
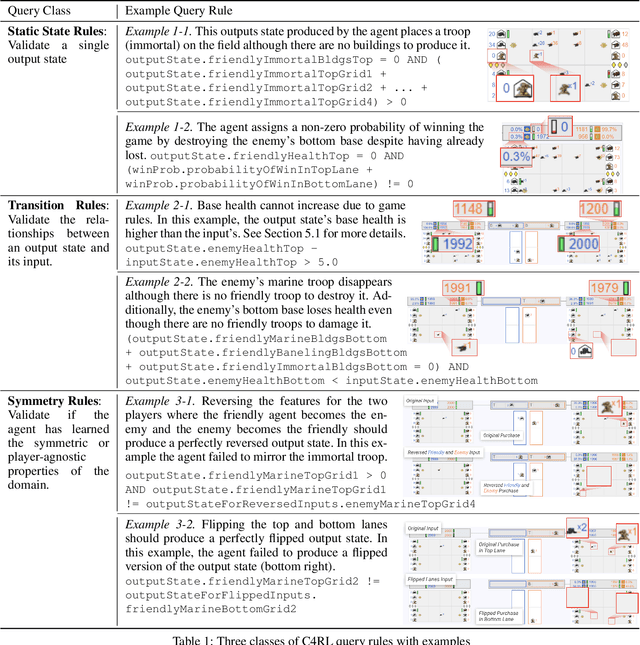
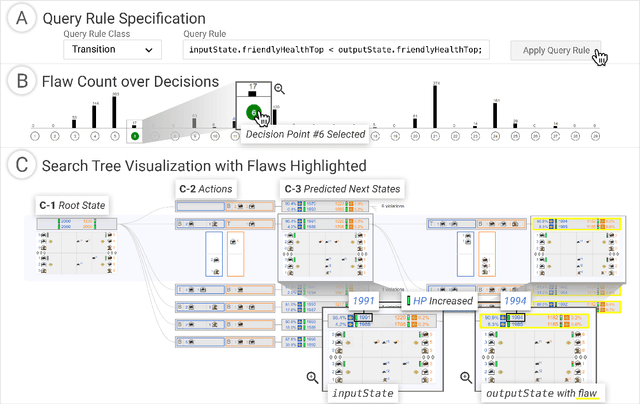
Reinforcement learning (RL) agents are commonly evaluated via their expected value over a distribution of test scenarios. Unfortunately, this evaluation approach provides limited evidence for post-deployment generalization beyond the test distribution. In this paper, we address this limitation by extending the recent CheckList testing methodology from natural language processing to planning-based RL. Specifically, we consider testing RL agents that make decisions via online tree search using a learned transition model and value function. The key idea is to improve the assessment of future performance via a CheckList approach for exploring and assessing the agent's inferences during tree search. The approach provides the user with an interface and general query-rule mechanism for identifying potential inference flaws and validating expected inference invariances. We present a user study involving knowledgeable AI researchers using the approach to evaluate an agent trained to play a complex real-time strategy game. The results show the approach is effective in allowing users to identify previously-unknown flaws in the agent's reasoning. In addition, our analysis provides insight into how AI experts use this type of testing approach, which may help improve future instantiations.
Participation and Data Valuation in IoT Data Markets through Distributed Coalitions
Jun 17, 2022
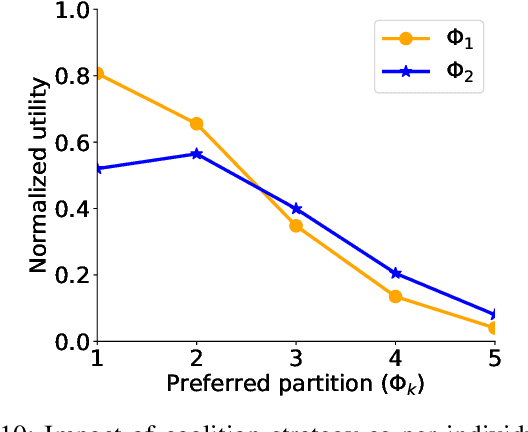
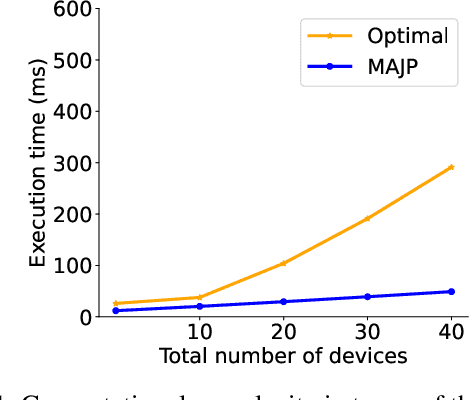
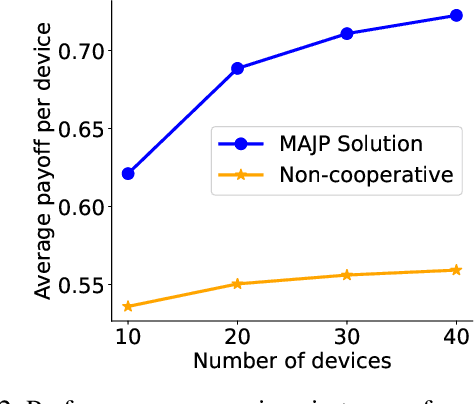
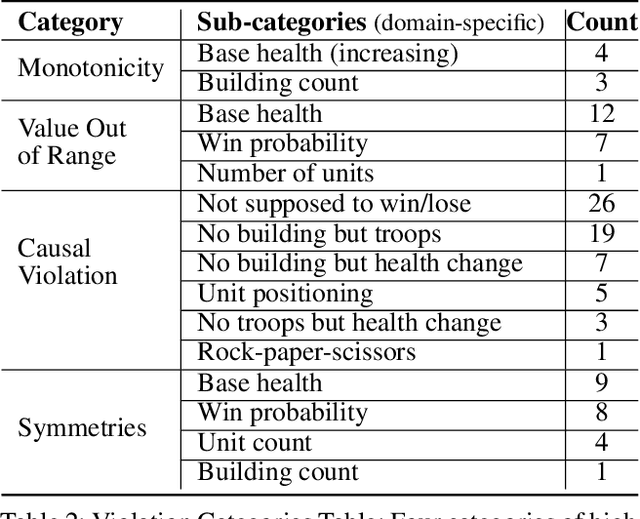
This paper considers a market for Internet of Things (IoT) data that is used to train machine learning models. The data is supplied to the market platform through a network and the price of the data is controlled based on the value it brings to the machine learning model. We explore the correlation property of data in a game-theoretical setting to eventually derive a simplified distributed solution for a data trading mechanism that emphasizes the mutual benefit of devices and the market. The key proposal is an efficient algorithm for markets that jointly addresses the challenges of availability and heterogeneity in participation, as well as the transfer of trust and the economic value of data exchange in IoT networks. The proposed approach establishes the data market by reinforcing collaboration opportunities between devices with correlated data to avoid information leakage. Therein, we develop a network-wide optimization problem that maximizes the social value of coalition among the IoT devices of similar data types; at the same time, it minimizes the cost due to network externalities, i.e., the impact of information leakage due to data correlation, as well as the opportunity costs. Finally, we reveal the structure of the formulated problem as a distributed coalition game and solve it following the simplified split-and-merge algorithm. Simulation results show the efficacy of our proposed mechanism design toward a trusted IoT data market, with up to 32.72% gain in the average payoff for each seller.
No Pain, Big Gain: Classify Dynamic Point Cloud Sequences with Static Models by Fitting Feature-level Space-time Surfaces
Mar 23, 2022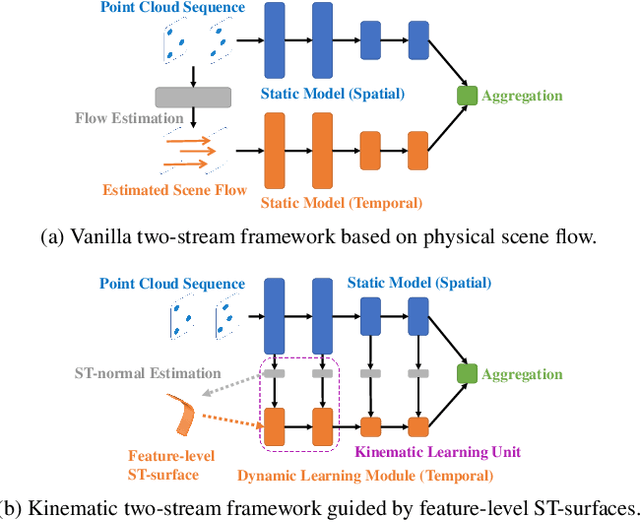
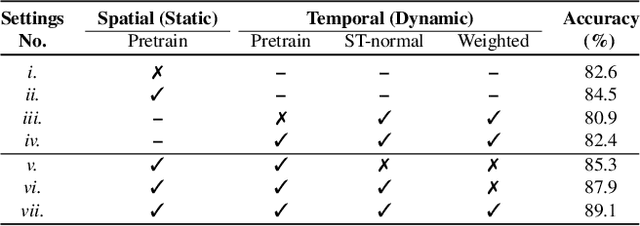
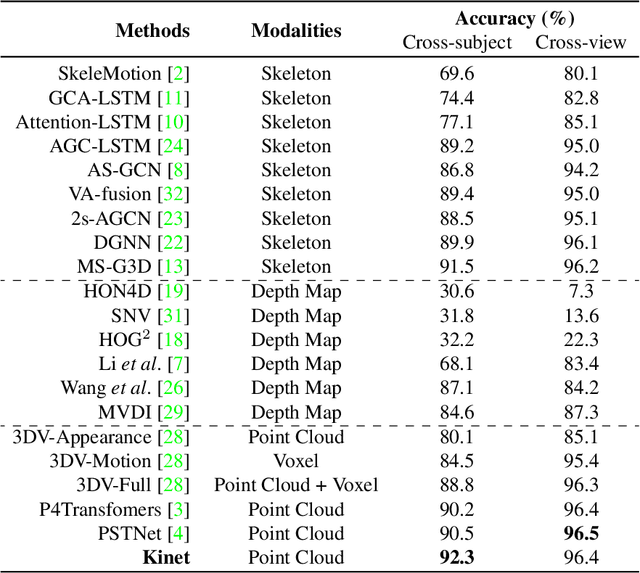
Scene flow is a powerful tool for capturing the motion field of 3D point clouds. However, it is difficult to directly apply flow-based models to dynamic point cloud classification since the unstructured points make it hard or even impossible to efficiently and effectively trace point-wise correspondences. To capture 3D motions without explicitly tracking correspondences, we propose a kinematics-inspired neural network (Kinet) by generalizing the kinematic concept of ST-surfaces to the feature space. By unrolling the normal solver of ST-surfaces in the feature space, Kinet implicitly encodes feature-level dynamics and gains advantages from the use of mature backbones for static point cloud processing. With only minor changes in network structures and low computing overhead, it is painless to jointly train and deploy our framework with a given static model. Experiments on NvGesture, SHREC'17, MSRAction-3D, and NTU-RGBD demonstrate its efficacy in performance, efficiency in both the number of parameters and computational complexity, as well as its versatility to various static backbones. Noticeably, Kinet achieves the accuracy of 93.27% on MSRAction-3D with only 3.20M parameters and 10.35G FLOPS.
Surface Reconstruction from Point Clouds by Learning Predictive Context Priors
Apr 23, 2022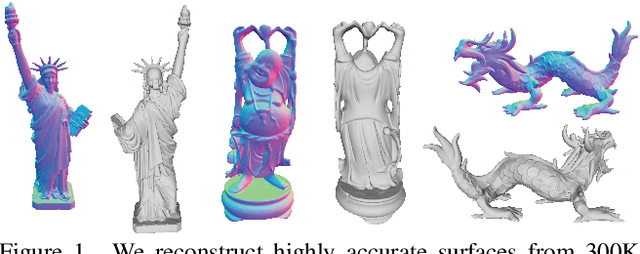
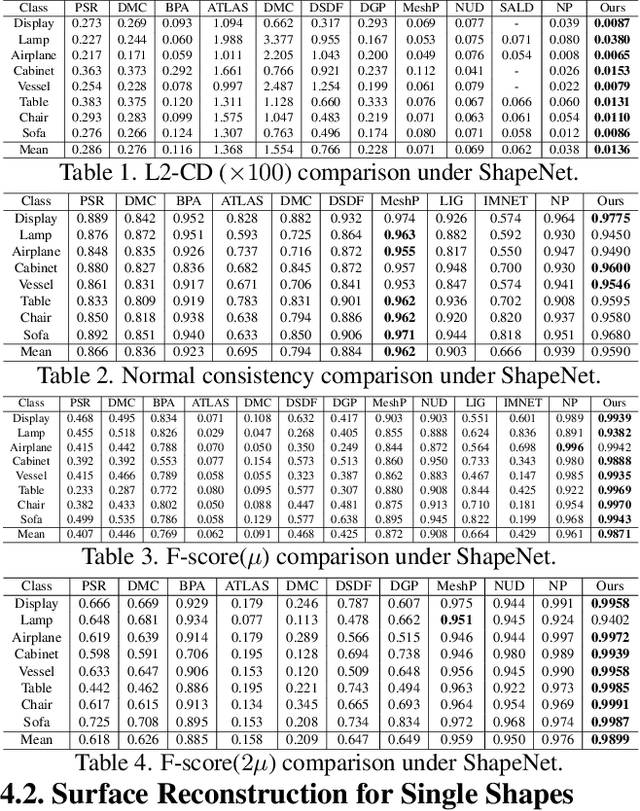
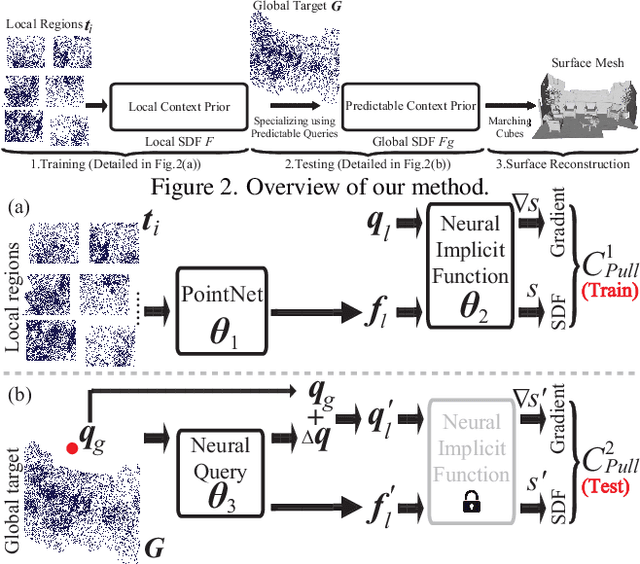
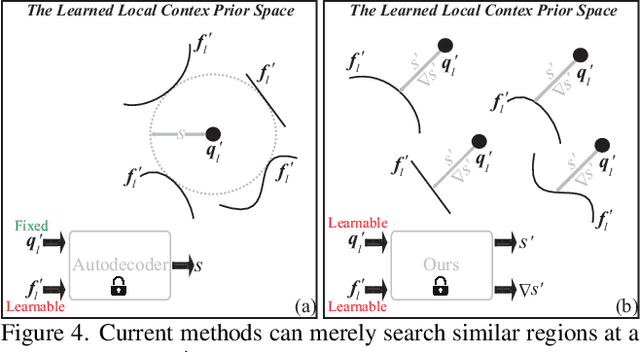
Surface reconstruction from point clouds is vital for 3D computer vision. State-of-the-art methods leverage large datasets to first learn local context priors that are represented as neural network-based signed distance functions (SDFs) with some parameters encoding the local contexts. To reconstruct a surface at a specific query location at inference time, these methods then match the local reconstruction target by searching for the best match in the local prior space (by optimizing the parameters encoding the local context) at the given query location. However, this requires the local context prior to generalize to a wide variety of unseen target regions, which is hard to achieve. To resolve this issue, we introduce Predictive Context Priors by learning Predictive Queries for each specific point cloud at inference time. Specifically, we first train a local context prior using a large point cloud dataset similar to previous techniques. For surface reconstruction at inference time, however, we specialize the local context prior into our Predictive Context Prior by learning Predictive Queries, which predict adjusted spatial query locations as displacements of the original locations. This leads to a global SDF that fits the specific point cloud the best. Intuitively, the query prediction enables us to flexibly search the learned local context prior over the entire prior space, rather than being restricted to the fixed query locations, and this improves the generalizability. Our method does not require ground truth signed distances, normals, or any additional procedure of signed distance fusion across overlapping regions. Our experimental results in surface reconstruction for single shapes or complex scenes show significant improvements over the state-of-the-art under widely used benchmarks.
Transfer Learning as a Method to Reproduce High-Fidelity NLTE Opacities in Simulations
May 28, 2022
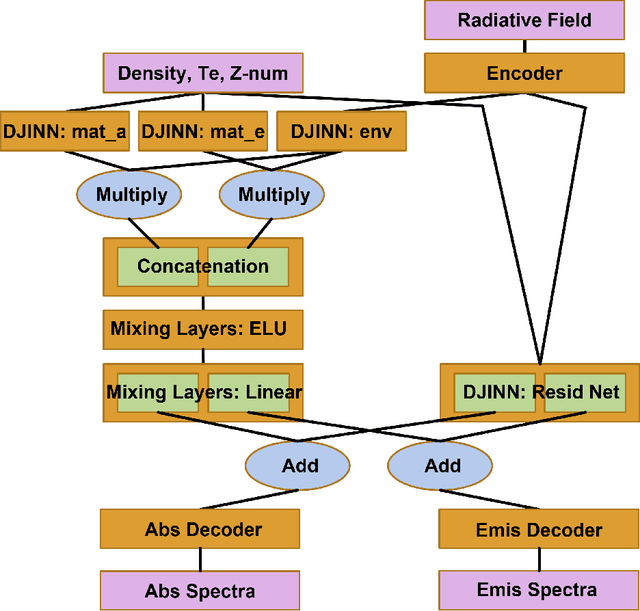
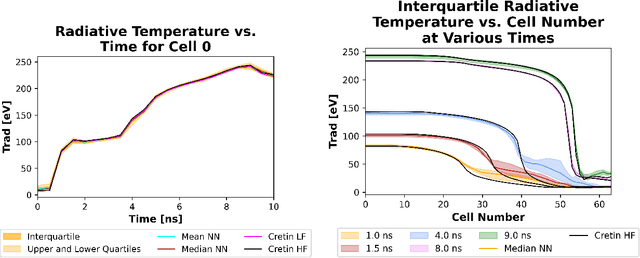
Simulations of high-energy density physics often need non-local thermodynamic equilibrium (NLTE) opacity data. This data, however, is expensive to produce at relatively low-fidelity. It is even more so at high-fidelity such that the opacity calculations can contribute ninety-five percent of the total computation time. This proportion can even reach large proportions. Neural networks can be used to replace the standard calculations of low-fidelity data, and the neural networks can be trained to reproduce artificial, high-fidelity opacity spectra. In this work, it is demonstrated that a novel neural network architecture trained to reproduce high-fidelity krypton spectra through transfer learning can be used in simulations. Further, it is demonstrated that this can be done while achieving a relative percent error of the peak radiative temperature of the hohlraum of approximately 1\% to 4\% while achieving a 19.4x speed up.
Discrete State-Action Abstraction via the Successor Representation
Jun 07, 2022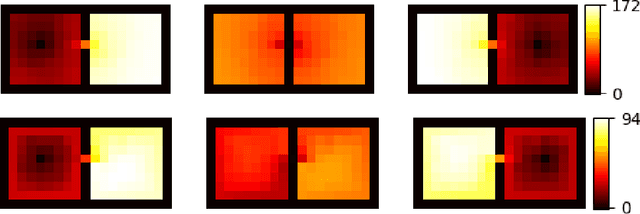
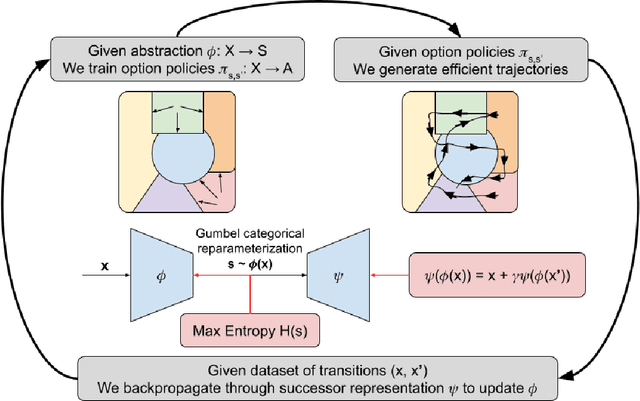
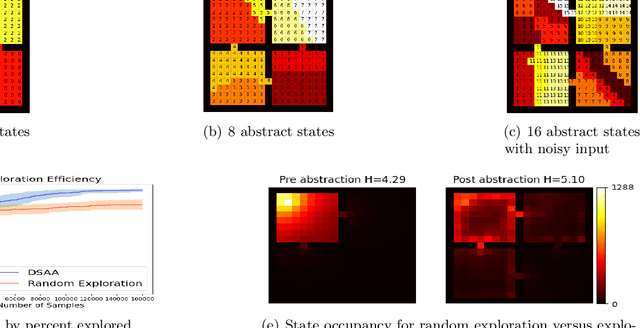
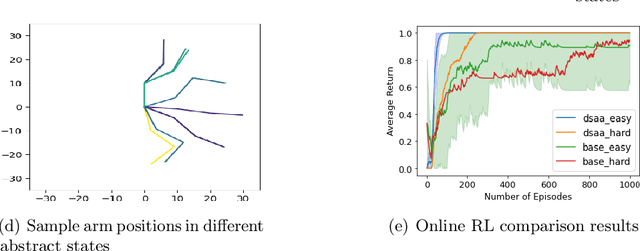
When reinforcement learning is applied with sparse rewards, agents must spend a prohibitively long time exploring the unknown environment without any learning signal. Abstraction is one approach that provides the agent with an intrinsic reward for transitioning in a latent space. Prior work focuses on dense continuous latent spaces, or requires the user to manually provide the representation. Our approach is the first for automatically learning a discrete abstraction of the underlying environment. Moreover, our method works on arbitrary input spaces, using an end-to-end trainable regularized successor representation model. For transitions between abstract states, we train a set of temporally extended actions in the form of options, i.e., an action abstraction. Our proposed algorithm, Discrete State-Action Abstraction (DSAA), iteratively swaps between training these options and using them to efficiently explore more of the environment to improve the state abstraction. As a result, our model is not only useful for transfer learning but also in the online learning setting. We empirically show that our agent is able to explore the environment and solve provided tasks more efficiently than baseline reinforcement learning algorithms. Our code is publicly available at \url{https://github.com/amnonattali/dsaa}.