 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic Optimization Fabrics for Motion Generation
May 17, 2022

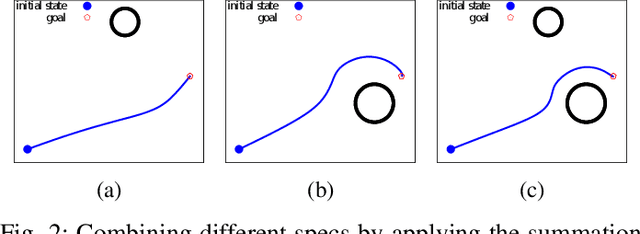
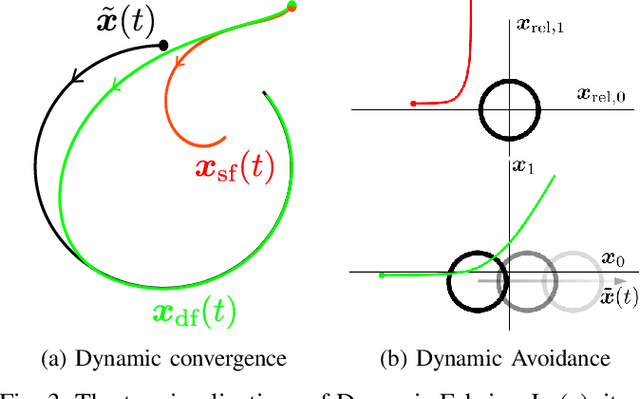
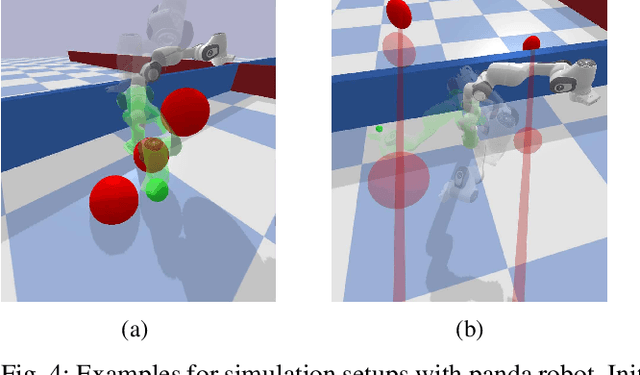
Optimization fabrics represent a geometric approach to real-time motion planning, where trajectories are designed by the composition of several differential equations that exhibit a desired motion behavior. We generalize this framework to dynamic scenarios and prove that fundamental properties can be conserved. We show that convergence to trajectories and avoidance of moving obstacles can be guaranteed using simple construction rules of the components. Additionally, we present the first quantitative comparisons between optimization fabrics and model predictive control and show that optimization fabrics can generate similar trajectories with better scalability, and thus, much higher replanning frequency (up to 500 Hz with a 7 degrees of freedom robotic arm). Finally, we present empirical results on several robots, including a non-holonomic mobile manipulator with 10 degrees of freedom, supporting the theoretical findings.
Deep Learning Workload Scheduling in GPU Datacenters: Taxonomy, Challenges and Vision
May 24, 2022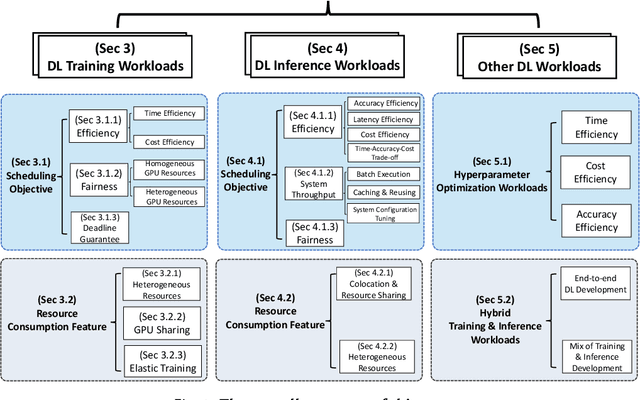
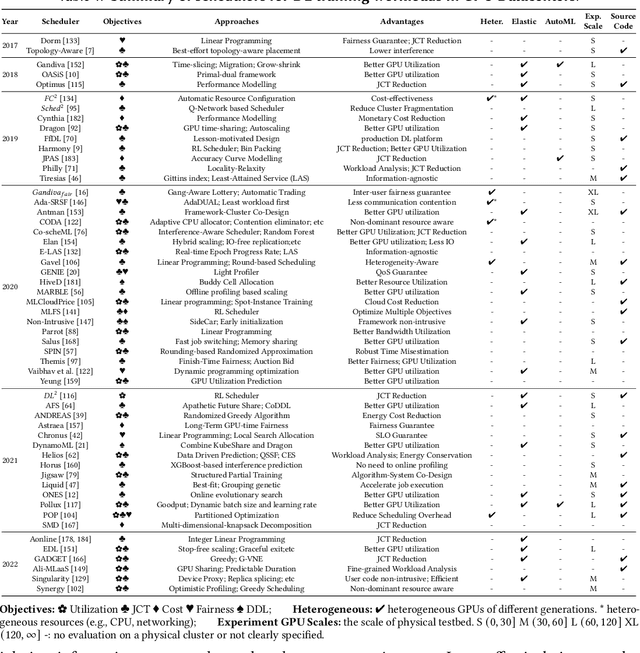
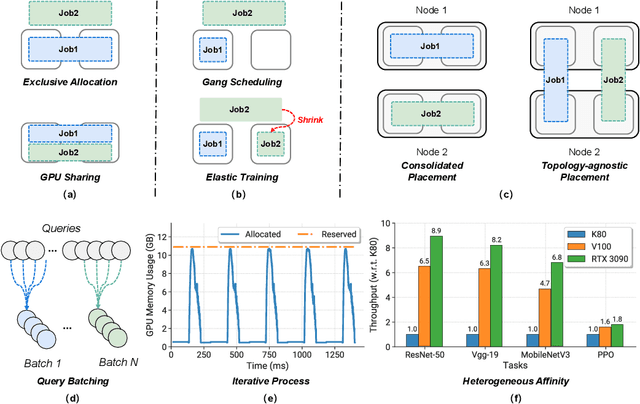

Deep learning (DL) shows its prosperity in a wide variety of fields. The development of a DL model is a time-consuming and resource-intensive procedure. Hence, dedicated GPU accelerators have been collectively constructed into a GPU datacenter. An efficient scheduler design for such GPU datacenter is crucially important to reduce the operational cost and improve resource utilization. However, traditional approaches designed for big data or high performance computing workloads can not support DL workloads to fully utilize the GPU resources. Recently, substantial schedulers are proposed to tailor for DL workloads in GPU datacenters. This paper surveys existing research efforts for both training and inference workloads. We primarily present how existing schedulers facilitate the respective workloads from the scheduling objectives and resource consumption features. Finally, we prospect several promising future research directions. More detailed summary with the surveyed paper and code links can be found at our project website: https://github.com/S-Lab-SystemGroup/Awesome-DL-Scheduling-Papers
Efficient Accelerator for Dilated and Transposed Convolution with Decomposition
May 02, 2022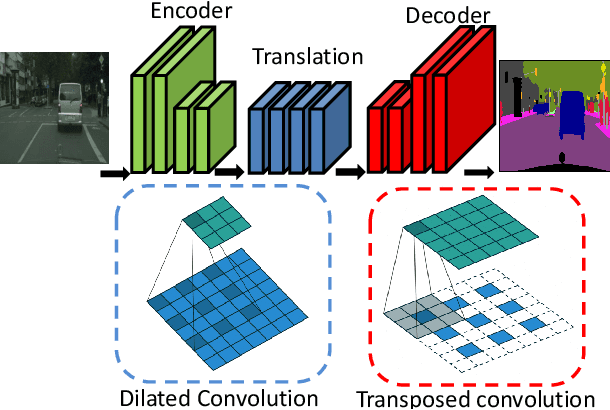
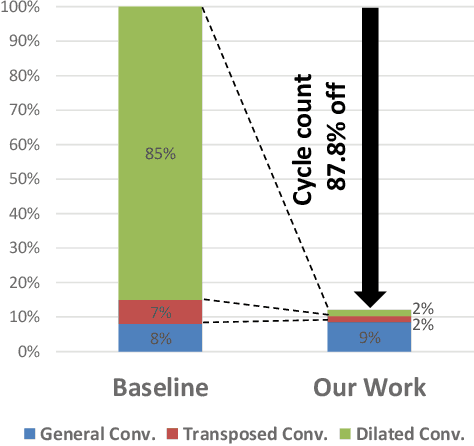
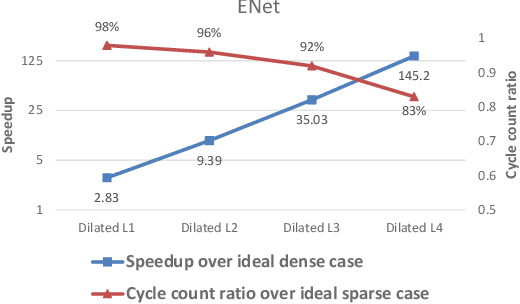
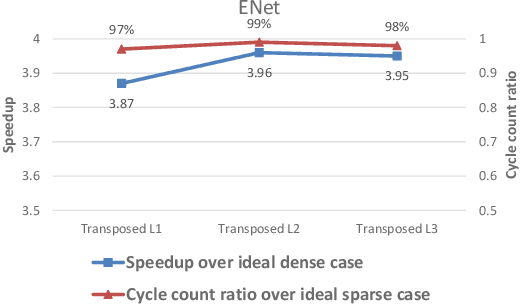
Hardware acceleration for dilated and transposed convolution enables real time execution of related tasks like segmentation, but current designs are specific for these convolutional types or suffer from complex control for reconfigurable designs. This paper presents a design that decomposes input or weight for dilated and transposed convolutions respectively to skip redundant computations and thus executes efficiently on existing dense CNN hardware as well. The proposed architecture can cut down 87.8\% of the cycle counts to achieve 8.2X speedup over a naive execution for the ENet case.
All Birds with One Stone: Multi-task Text Classification for Efficient Inference with One Forward Pass
May 22, 2022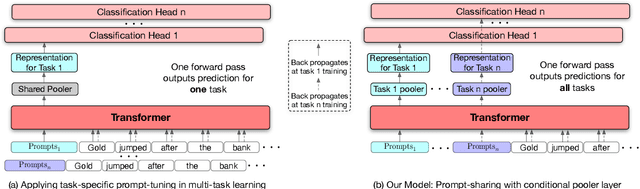
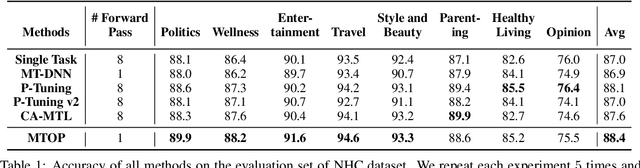
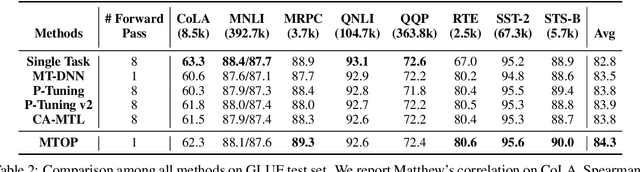
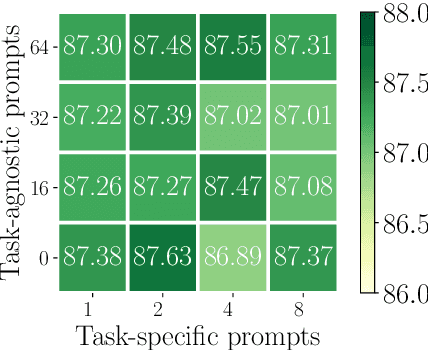
Multi-Task Learning (MTL) models have shown their robustness, effectiveness, and efficiency for transferring learned knowledge across tasks. In real industrial applications such as web content classification, multiple classification tasks are predicted from the same input text such as a web article. However, at the serving time, the existing multitask transformer models such as prompt or adaptor based approaches need to conduct N forward passes for N tasks with O(N) computation cost. To tackle this problem, we propose a scalable method that can achieve stronger performance with close to O(1) computation cost via only one forward pass. To illustrate real application usage, we release a multitask dataset on news topic and style classification. Our experiments show that our proposed method outperforms strong baselines on both the GLUE benchmark and our news dataset. Our code and dataset are publicly available at https://bit.ly/mtop-code.
Physics-Inspired Temporal Learning of Quadrotor Dynamics for Accurate Model Predictive Trajectory Tracking
Jun 07, 2022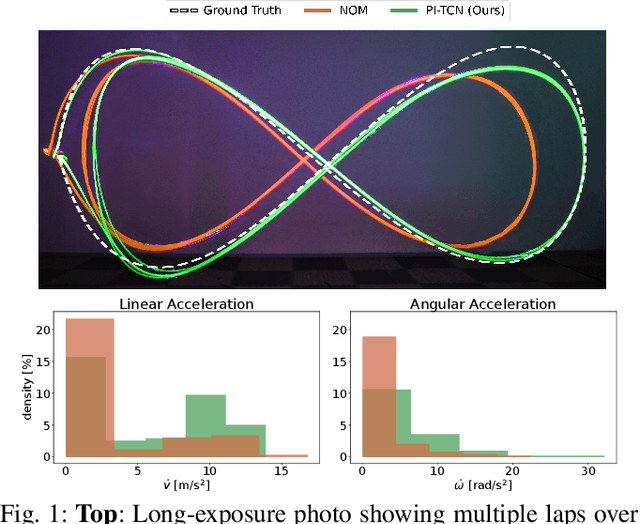
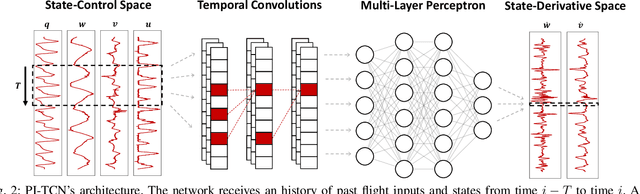
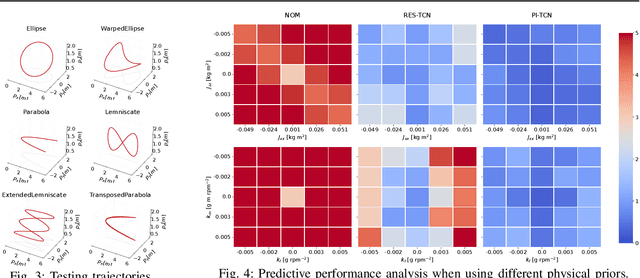
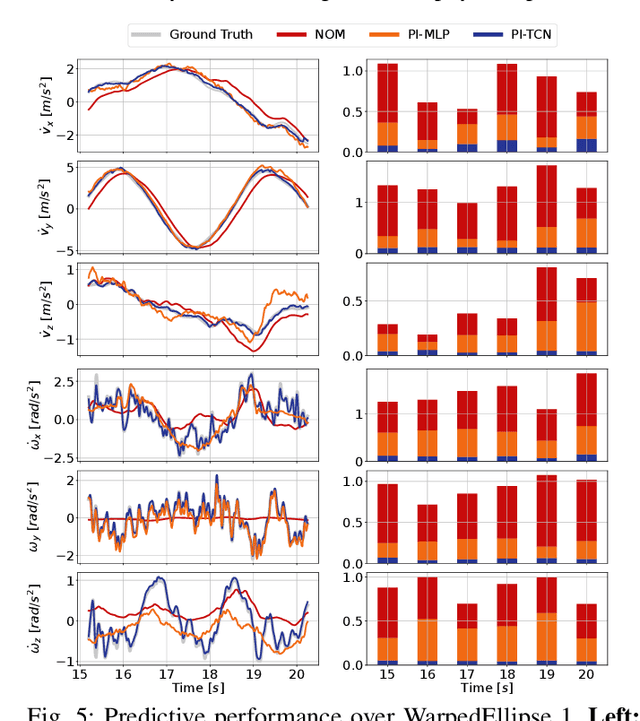
Accurately modeling quadrotor's system dynamics is critical for guaranteeing agile, safe, and stable navigation. The model needs to capture the system behavior in multiple flight regimes and operating conditions, including those producing highly nonlinear effects such as aerodynamic forces and torques, rotor interactions, or possible system configuration modifications. Classical approaches rely on handcrafted models and struggle to generalize and scale to capture these effects. In this paper, we present a novel Physics-Inspired Temporal Convolutional Network (PI-TCN) approach to learning quadrotor's system dynamics purely from robot experience. Our approach combines the expressive power of sparse temporal convolutions and dense feed-forward connections to make accurate system predictions. In addition, physics constraints are embedded in the training process to facilitate the network's generalization capabilities to data outside the training distribution. Finally, we design a model predictive control approach that incorporates the learned dynamics for accurate closed-loop trajectory tracking fully exploiting the learned model predictions in a receding horizon fashion. Experimental results demonstrate that our approach accurately extracts the structure of the quadrotor's dynamics from data, capturing effects that would remain hidden to classical approaches. To the best of our knowledge, this is the first time physics-inspired deep learning is successfully applied to temporal convolutional networks and to the system identification task, while concurrently enabling predictive control.
Ensemble Augmentation for Deep Neural Networks Using 1-D Time Series Vibration Data
Aug 06, 2021
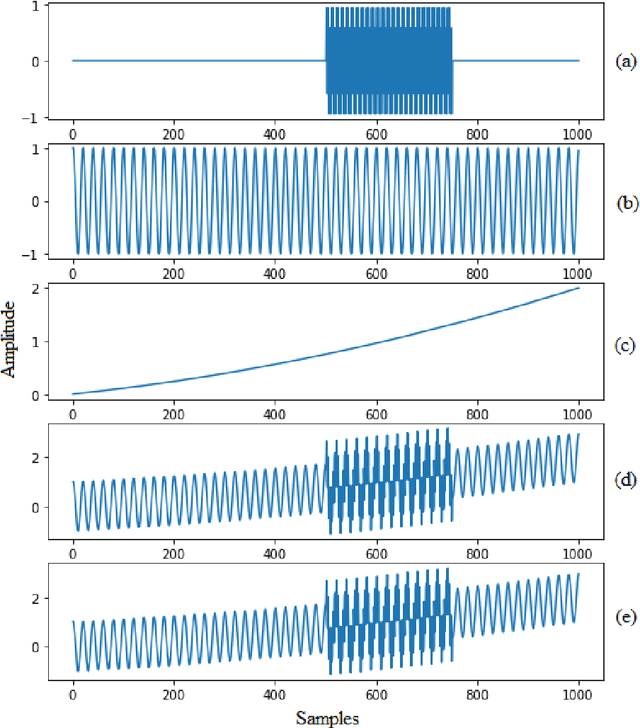
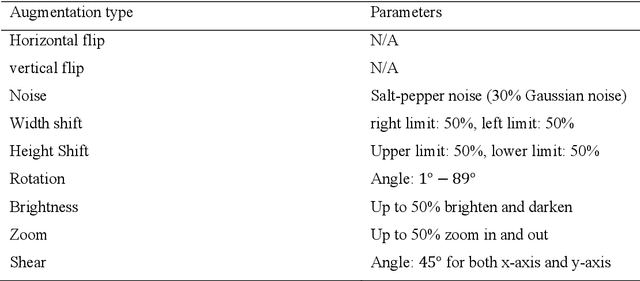
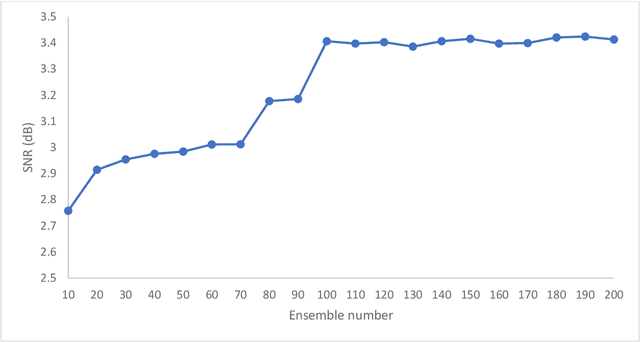
Time-series data are one of the fundamental types of raw data representation used in data-driven techniques. In machine condition monitoring, time-series vibration data are overly used in data mining for deep neural networks. Typically, vibration data is converted into images for classification using Deep Neural Networks (DNNs), and scalograms are the most effective form of image representation. However, the DNN classifiers require huge labeled training samples to reach their optimum performance. So, many forms of data augmentation techniques are applied to the classifiers to compensate for the lack of training samples. However, the scalograms are graphical representations where the existing augmentation techniques suffer because they either change the graphical meaning or have too much noise in the samples that change the physical meaning. In this study, a data augmentation technique named ensemble augmentation is proposed to overcome this limitation. This augmentation method uses the power of white noise added in ensembles to the original samples to generate real-like samples. After averaging the signal with ensembles, a new signal is obtained that contains the characteristics of the original signal. The parameters for the ensemble augmentation are validated using a simulated signal. The proposed method is evaluated using 10 class bearing vibration data using three state-of-the-art Transfer Learning (TL) models, namely, Inception-V3, MobileNet-V2, and ResNet50. Augmented samples are generated in two increments: the first increment generates the same number of fake samples as the training samples, and in the second increment, the number of samples is increased gradually. The outputs from the proposed method are compared with no augmentation, augmentations using deep convolution generative adversarial network (DCGAN), and several geometric transformation-based augmentations...
Large-scale multi-objective influence maximisation with network downscaling
Apr 13, 2022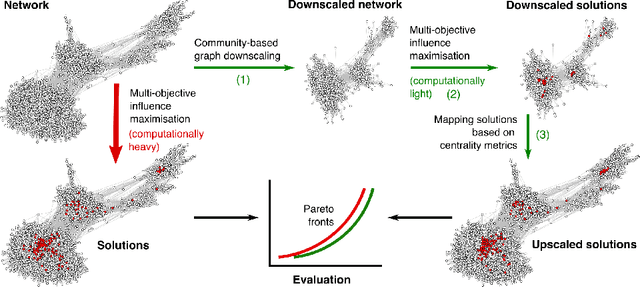

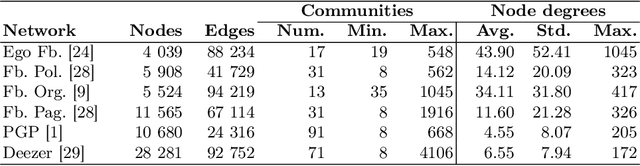
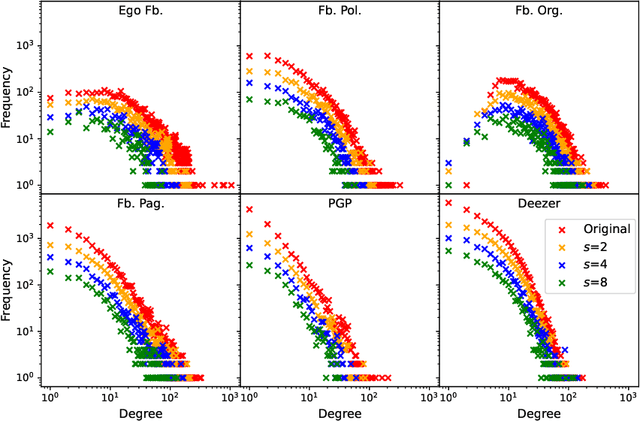
Finding the most influential nodes in a network is a computationally hard problem with several possible applications in various kinds of network-based problems. While several methods have been proposed for tackling the influence maximisation (IM) problem, their runtime typically scales poorly when the network size increases. Here, we propose an original method, based on network downscaling, that allows a multi-objective evolutionary algorithm (MOEA) to solve the IM problem on a reduced scale network, while preserving the relevant properties of the original network. The downscaled solution is then upscaled to the original network, using a mechanism based on centrality metrics such as PageRank. Our results on eight large networks (including two with $\sim$50k nodes) demonstrate the effectiveness of the proposed method with a more than 10-fold runtime gain compared to the time needed on the original network, and an up to $82\%$ time reduction compared to CELF.
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022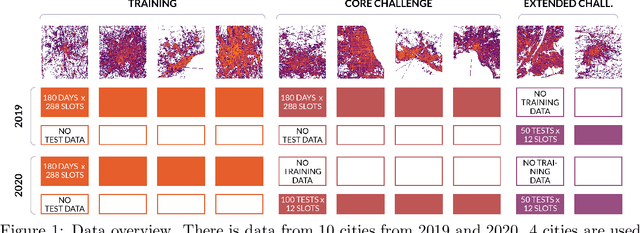
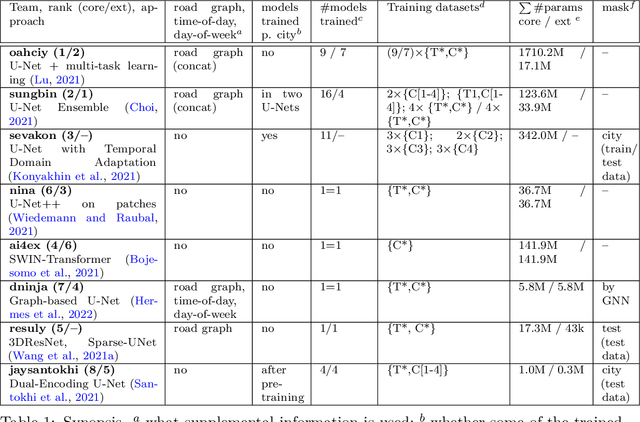
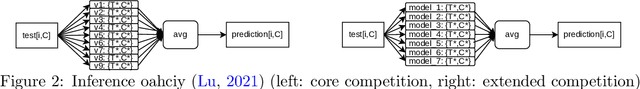
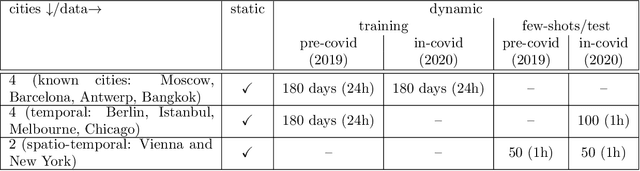
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
On the Effectiveness of Fine-tuning Versus Meta-reinforcement Learning
Jun 07, 2022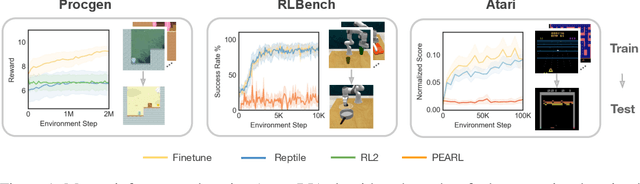
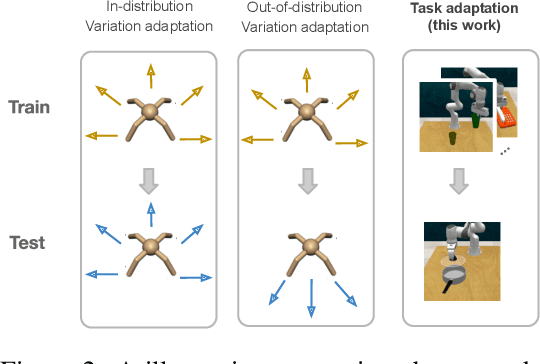
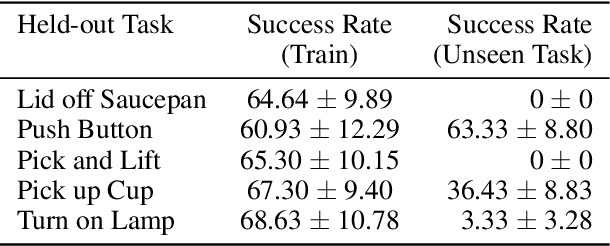
Intelligent agents should have the ability to leverage knowledge from previously learned tasks in order to learn new ones quickly and efficiently. Meta-learning approaches have emerged as a popular solution to achieve this. However, meta-reinforcement learning (meta-RL) algorithms have thus far been restricted to simple environments with narrow task distributions. Moreover, the paradigm of pretraining followed by fine-tuning to adapt to new tasks has emerged as a simple yet effective solution in supervised and self-supervised learning. This calls into question the benefits of meta-learning approaches also in reinforcement learning, which typically come at the cost of high complexity. We hence investigate meta-RL approaches in a variety of vision-based benchmarks, including Procgen, RLBench, and Atari, where evaluations are made on completely novel tasks. Our findings show that when meta-learning approaches are evaluated on different tasks (rather than different variations of the same task), multi-task pretraining with fine-tuning on new tasks performs equally as well, or better, than meta-pretraining with meta test-time adaptation. This is encouraging for future research, as multi-task pretraining tends to be simpler and computationally cheaper than meta-RL. From these findings, we advocate for evaluating future meta-RL methods on more challenging tasks and including multi-task pretraining with fine-tuning as a simple, yet strong baseline.
Beyond Labels: Visual Representations for Bone Marrow Cell Morphology Recognition
May 19, 2022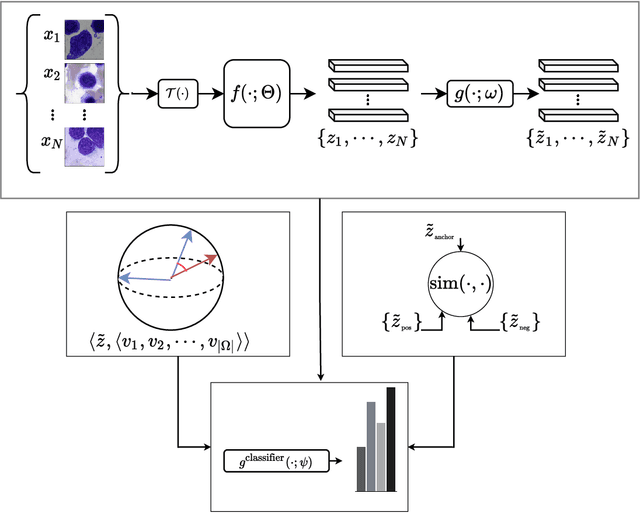
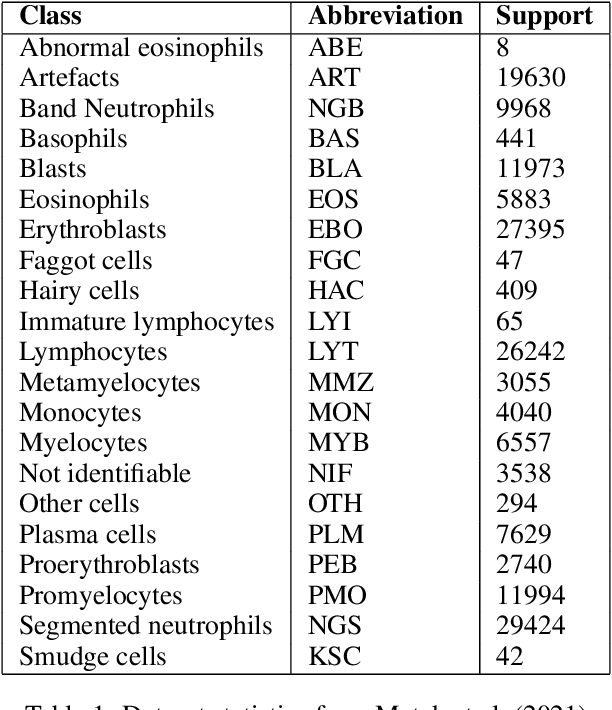
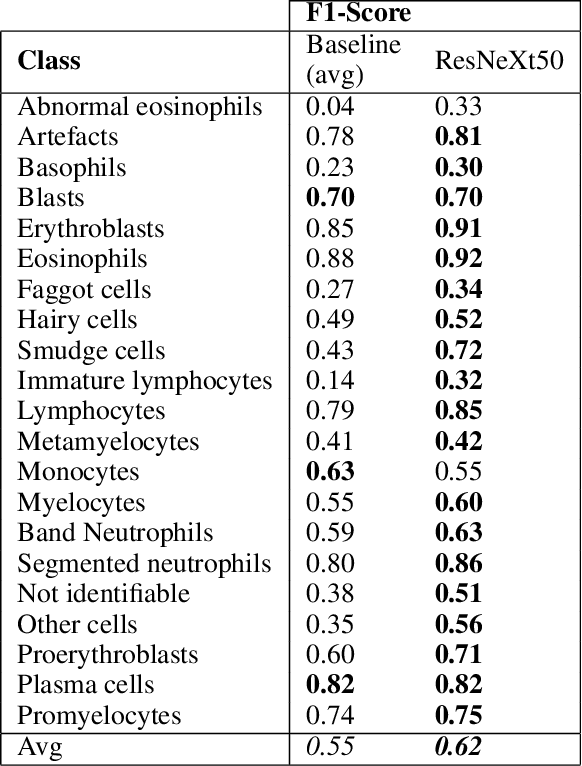
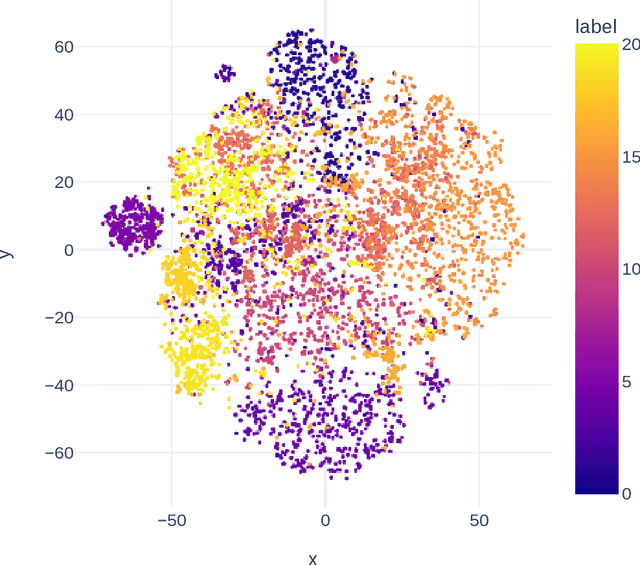
Analyzing and inspecting bone marrow cell cytomorphology is a critical but highly complex and time-consuming component of hematopathology diagnosis. Recent advancements in artificial intelligence have paved the way for the application of deep learning algorithms to complex medical tasks. Nevertheless, there are many challenges in applying effective learning algorithms to medical image analysis, such as the lack of sufficient and reliably annotated training datasets and the highly class-imbalanced nature of most medical data. Here, we improve on the state-of-the-art methodologies of bone marrow cell recognition by deviating from sole reliance on labeled data and leveraging self-supervision in training our learning models. We investigate our approach's effectiveness in identifying bone marrow cell types. Our experiments demonstrate significant performance improvements in conducting different bone marrow cell recognition tasks compared to the current state-of-the-art methodologies.