 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Probing Simile Knowledge from Pre-trained Language Models
Apr 27, 2022


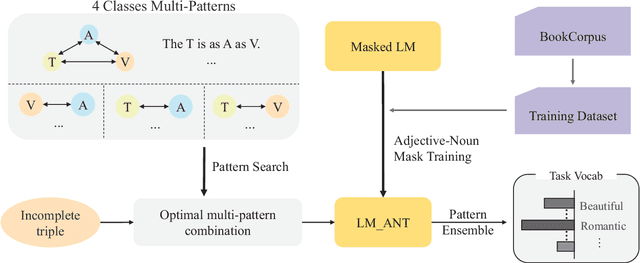
Simile interpretation (SI) and simile generation (SG) are challenging tasks for NLP because models require adequate world knowledge to produce predictions. Previous works have employed many hand-crafted resources to bring knowledge-related into models, which is time-consuming and labor-intensive. In recent years, pre-trained language models (PLMs) based approaches have become the de-facto standard in NLP since they learn generic knowledge from a large corpus. The knowledge embedded in PLMs may be useful for SI and SG tasks. Nevertheless, there are few works to explore it. In this paper, we probe simile knowledge from PLMs to solve the SI and SG tasks in the unified framework of simile triple completion for the first time. The backbone of our framework is to construct masked sentences with manual patterns and then predict the candidate words in the masked position. In this framework, we adopt a secondary training process (Adjective-Noun mask Training) with the masked language model (MLM) loss to enhance the prediction diversity of candidate words in the masked position. Moreover, pattern ensemble (PE) and pattern search (PS) are applied to improve the quality of predicted words. Finally, automatic and human evaluations demonstrate the effectiveness of our framework in both SI and SG tasks.
PanopticDepth: A Unified Framework for Depth-aware Panoptic Segmentation
Jun 01, 2022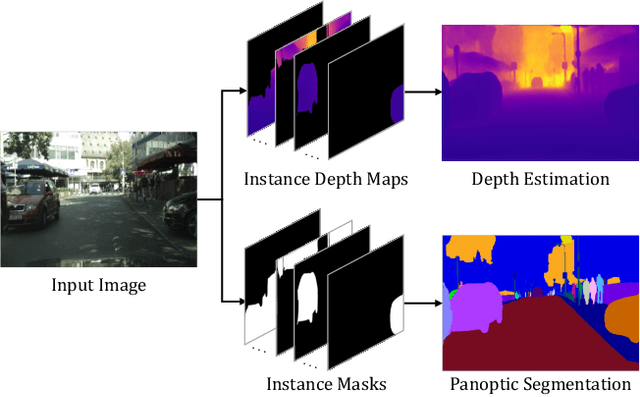
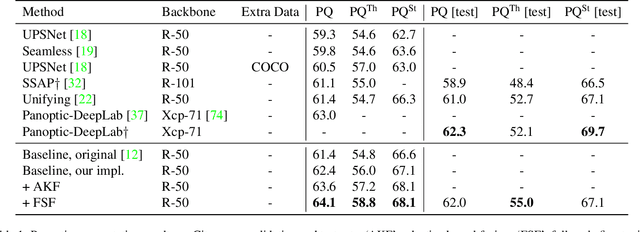
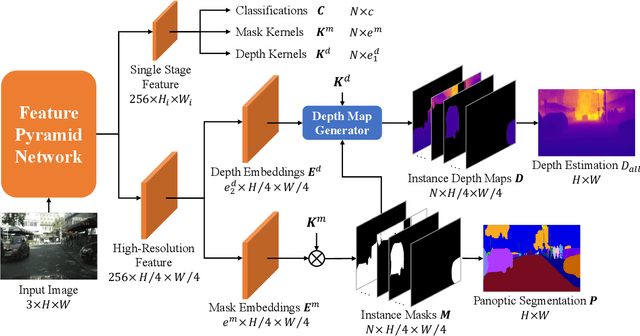

This paper presents a unified framework for depth-aware panoptic segmentation (DPS), which aims to reconstruct 3D scene with instance-level semantics from one single image. Prior works address this problem by simply adding a dense depth regression head to panoptic segmentation (PS) networks, resulting in two independent task branches. This neglects the mutually-beneficial relations between these two tasks, thus failing to exploit handy instance-level semantic cues to boost depth accuracy while also producing sub-optimal depth maps. To overcome these limitations, we propose a unified framework for the DPS task by applying a dynamic convolution technique to both the PS and depth prediction tasks. Specifically, instead of predicting depth for all pixels at a time, we generate instance-specific kernels to predict depth and segmentation masks for each instance. Moreover, leveraging the instance-wise depth estimation scheme, we add additional instance-level depth cues to assist with supervising the depth learning via a new depth loss. Extensive experiments on Cityscapes-DPS and SemKITTI-DPS show the effectiveness and promise of our method. We hope our unified solution to DPS can lead a new paradigm in this area. Code is available at https://github.com/NaiyuGao/PanopticDepth.
Performance Analysis of SPAD-Based Optical Wireless Communication with OFDM
Jun 04, 2022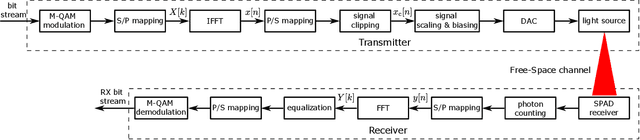
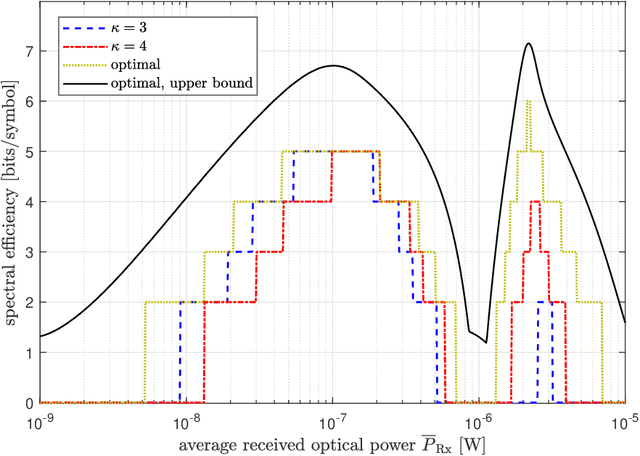
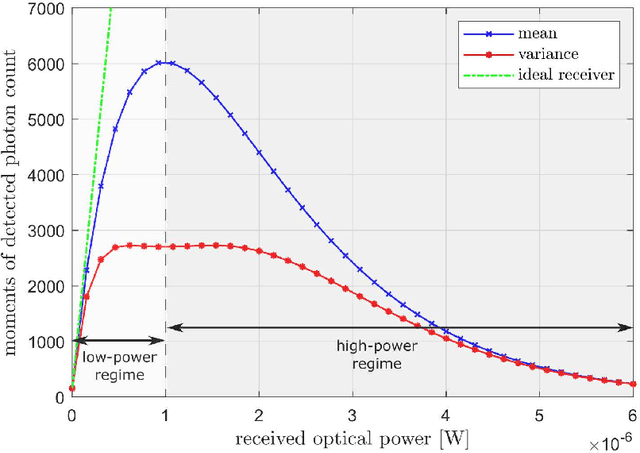
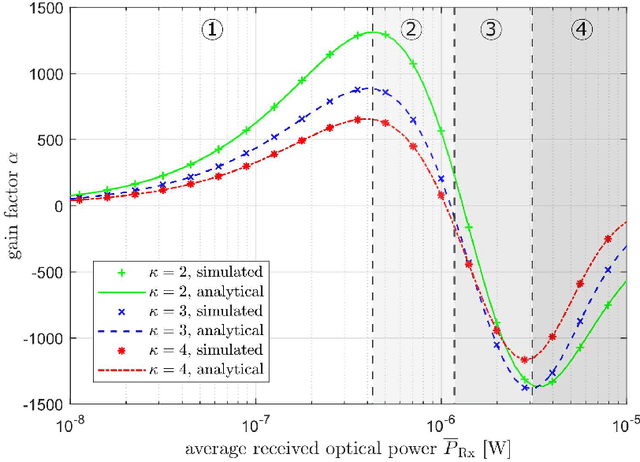
In recent years, there has been a growing interest in the use of single-photon avalanche diode (SPAD) in optical wireless communication (OWC). SPAD operates in the Geiger mode and can act as a photon counting receiver obviating the need for a transimpedance amplifier (TIA). Although a SPAD receiver can provide higher sensitivity compared to the traditional linear photodetectors, it suffers from the dead-time-induced nonlinearity. To improve the data rates of SPAD-based OWC systems, optical orthogonal frequency division multiplexing (OFDM) can be employed. This paper provides a comprehensive theoretical analysis of the SPAD-based OWC systems using OFDM signalling considering the effects of signal clipping, SPAD nonlinearity, and signal-dependent shot noise. An equivalent additive Gaussian noise channel model is proposed to describe the performance of the SPAD-based OFDM system. The statistics of the proposed channel model and the analytical expressions of the signal-to-noise ratio (SNR) and bit error rate (BER) are derived in closed forms. By means of extensive numerical results, the impact of the unique receiver nonlinearity on the system performance is investigated. The results demonstrate new insights into different optical power regimes of reliable operation for SPAD-based OFDM systems even well beyond SPAD saturation level.
Additive Higher-Order Factorization Machines
May 28, 2022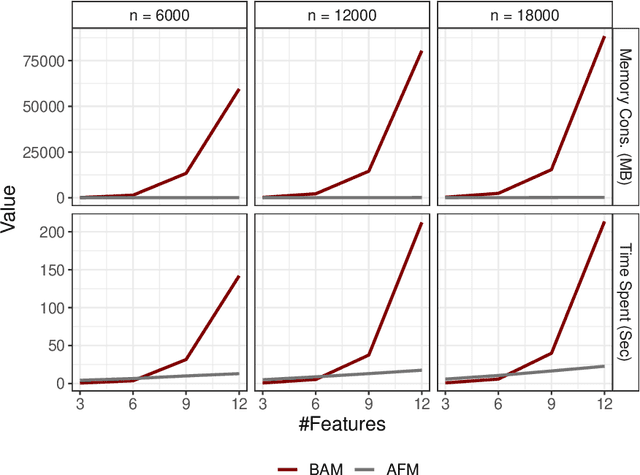
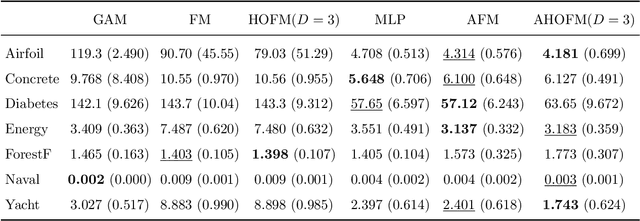
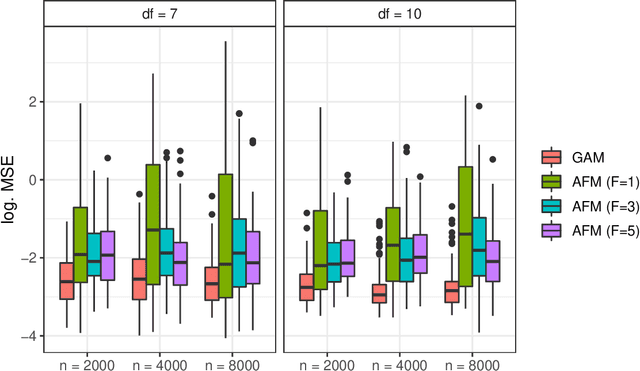

In the age of big data and interpretable machine learning, approaches need to work at scale and at the same time allow for a clear mathematical understanding of the method's inner workings. While there exist inherently interpretable semi-parametric regression techniques for large-scale applications to account for non-linearity in the data, their model complexity is still often restricted. One of the main limitations are missing interactions in these models, which are not included for the sake of better interpretability, but also due to untenable computational costs. To address this shortcoming, we derive a scalable high-order tensor product spline model using a factorization approach. Our method allows to include all (higher-order) interactions of non-linear feature effects while having computational costs proportional to a model without interactions. We prove both theoretically and empirically that our methods scales notably better than existing approaches, derive meaningful penalization schemes and also discuss further theoretical aspects. We finally investigate predictive and estimation performance both with synthetic and real data.
Real-Time Vehicular Wireless System-Level Simulation
Dec 22, 2020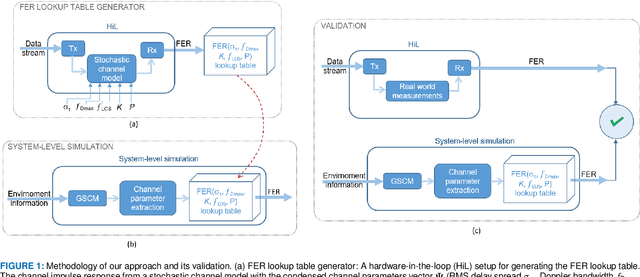
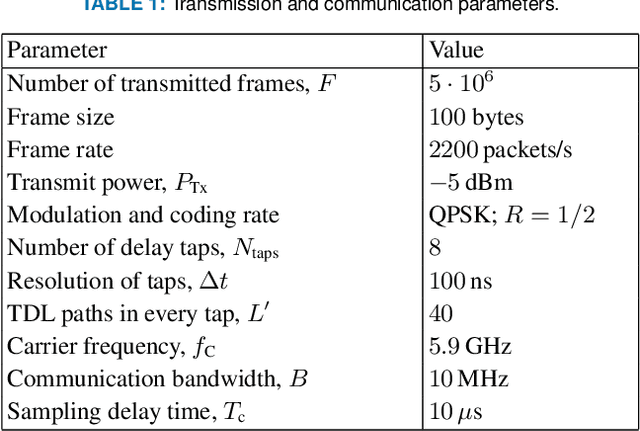
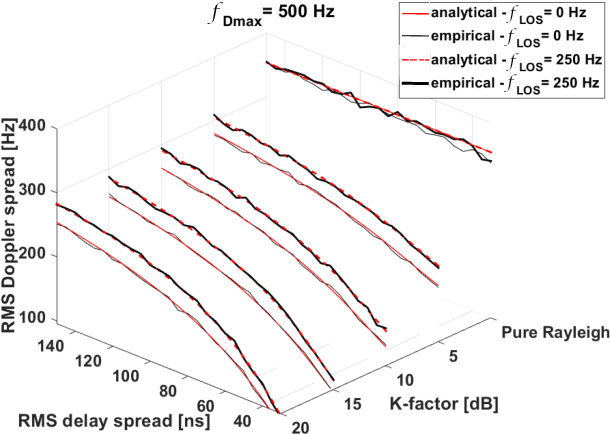
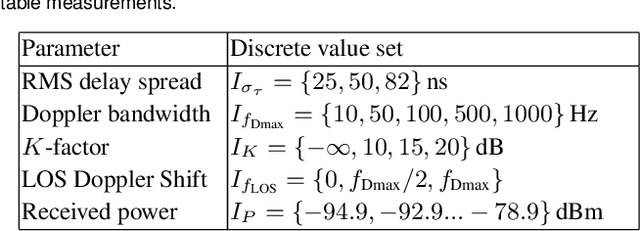
Future automation and control units for advanced driver assistance systems (ADAS) will exchange sensor and kinematic data with nearby vehicles using wireless communication links to improve traffic safety. In this paper we present an accurate real-time system-level simulation for multi-vehicle communication scenarios to support the development and test of connected ADAS systems. The physical and data-link layer are abstracted and provide the frame error rate (FER) to a network simulator. The FER is strongly affected by the non-stationary doubly dispersive fading process of the vehicular radio communication channel. We use a geometry-based stochastic channel model (GSCM) to enable a simplified but still accurate representation of the non-stationary vehicular fading process. The propagation path parameters of the GSCM are used to efficiently compute the time-variant condensed radio channel parameters per stationarity region of each communication link during run-time. Five condensed radio channel parameters mainly determine the FER forming a parameter vector: path loss, root mean square delay spread, Doppler bandwidth, $K$-factor, and line-of-sight Doppler shift. We measure the FER for a pre-defined set of discrete grid points of the parameter vector using a channel emulator and a given transmitter-receiver modem pair. The FER data is stored in a table and looked up during run-time of the real-time system-level simulation. We validate our methodology using empirical measurement data from a street crossing scenarios demonstrating a close match in terms of FER between simulation and measurement.
OnePose: One-Shot Object Pose Estimation without CAD Models
May 24, 2022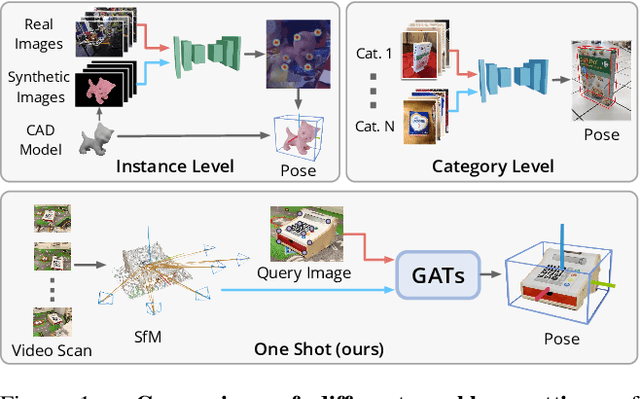

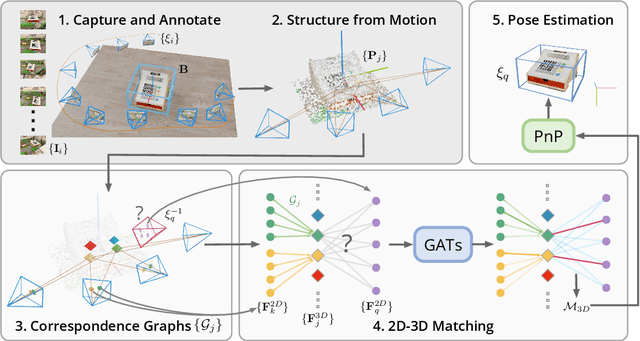
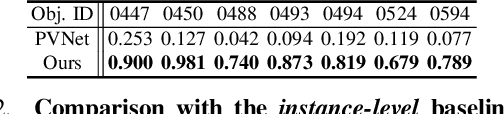
We propose a new method named OnePose for object pose estimation. Unlike existing instance-level or category-level methods, OnePose does not rely on CAD models and can handle objects in arbitrary categories without instance- or category-specific network training. OnePose draws the idea from visual localization and only requires a simple RGB video scan of the object to build a sparse SfM model of the object. Then, this model is registered to new query images with a generic feature matching network. To mitigate the slow runtime of existing visual localization methods, we propose a new graph attention network that directly matches 2D interest points in the query image with the 3D points in the SfM model, resulting in efficient and robust pose estimation. Combined with a feature-based pose tracker, OnePose is able to stably detect and track 6D poses of everyday household objects in real-time. We also collected a large-scale dataset that consists of 450 sequences of 150 objects.
Graph-Survival: A Survival Analysis Framework for Machine Learning on Temporal Networks
Mar 15, 2022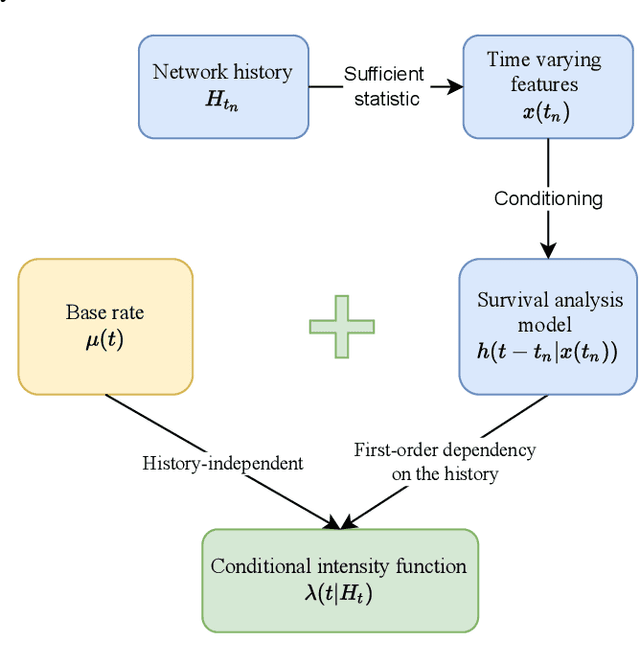
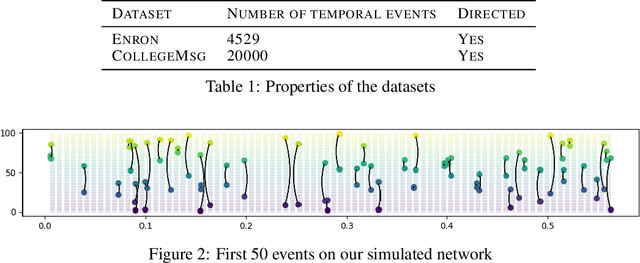
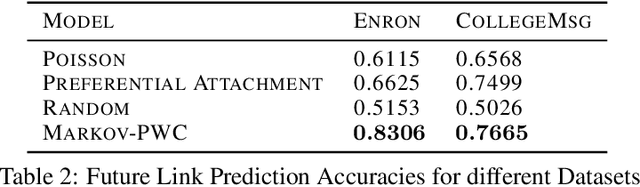
Continuous time temporal networks are attracting increasing attention due their omnipresence in real-world datasets and they manifold applications. While static network models have been successful in capturing static topological regularities, they often fail to model effects coming from the causal nature that explain the generation of networks. Exploiting the temporal aspect of networks has thus been the focus of various studies in the last decades. We propose a framework for designing generative models for continuous time temporal networks. Assuming a first order Markov assumption on the edge-specific temporal point processes enables us to flexibly apply survival analysis models directly on the waiting time between events, while using time-varying history-based features as covariates for these predictions. This approach links the well-documented field of temporal networks analysis through multivariate point processes, with methodological tools adapted from survival analysis. We propose a fitting method for models within this framework, and an algorithm for simulating new temporal networks having desired properties. We evaluate our method on a downstream future link prediction task, and provide a qualitative assessment of the network simulations.
Ensemble Augmentation for Deep Neural Networks Using 1-D Time Series Vibration Data
Aug 06, 2021
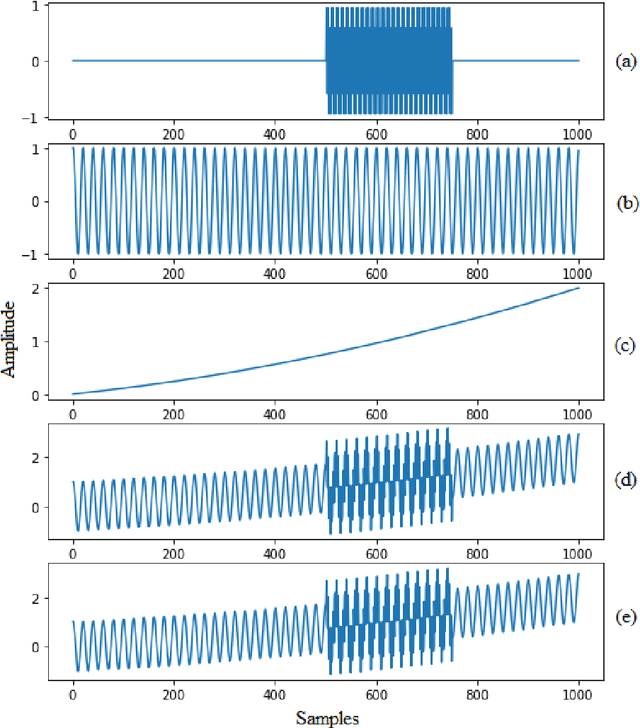
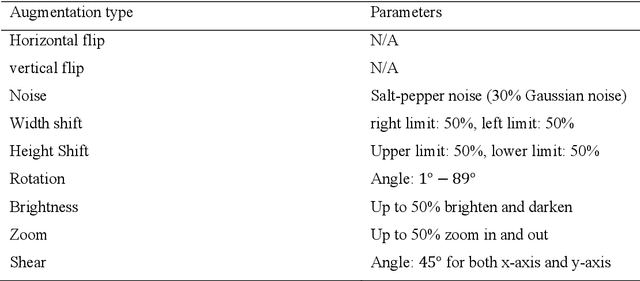
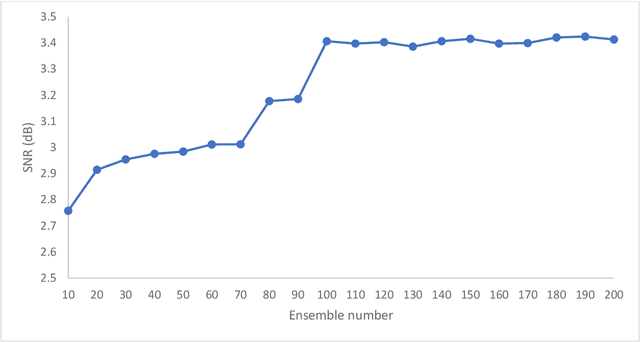
Time-series data are one of the fundamental types of raw data representation used in data-driven techniques. In machine condition monitoring, time-series vibration data are overly used in data mining for deep neural networks. Typically, vibration data is converted into images for classification using Deep Neural Networks (DNNs), and scalograms are the most effective form of image representation. However, the DNN classifiers require huge labeled training samples to reach their optimum performance. So, many forms of data augmentation techniques are applied to the classifiers to compensate for the lack of training samples. However, the scalograms are graphical representations where the existing augmentation techniques suffer because they either change the graphical meaning or have too much noise in the samples that change the physical meaning. In this study, a data augmentation technique named ensemble augmentation is proposed to overcome this limitation. This augmentation method uses the power of white noise added in ensembles to the original samples to generate real-like samples. After averaging the signal with ensembles, a new signal is obtained that contains the characteristics of the original signal. The parameters for the ensemble augmentation are validated using a simulated signal. The proposed method is evaluated using 10 class bearing vibration data using three state-of-the-art Transfer Learning (TL) models, namely, Inception-V3, MobileNet-V2, and ResNet50. Augmented samples are generated in two increments: the first increment generates the same number of fake samples as the training samples, and in the second increment, the number of samples is increased gradually. The outputs from the proposed method are compared with no augmentation, augmentations using deep convolution generative adversarial network (DCGAN), and several geometric transformation-based augmentations...
Ultra-low Latency Spiking Neural Networks with Spatio-Temporal Compression and Synaptic Convolutional Block
Mar 18, 2022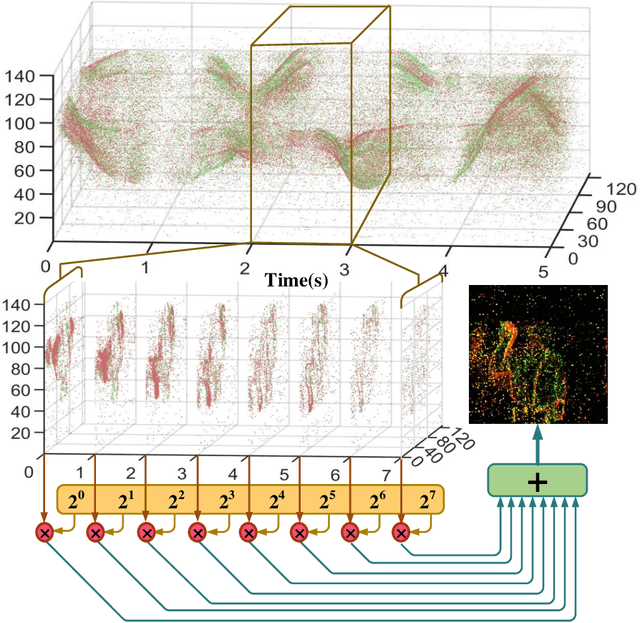
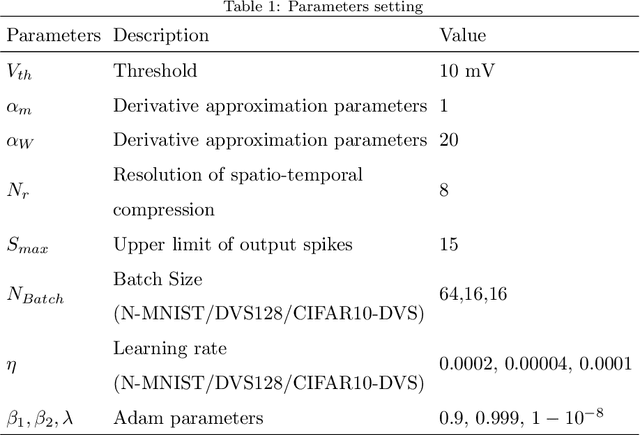
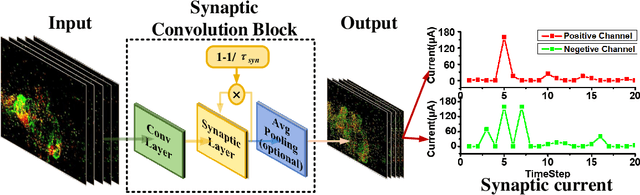
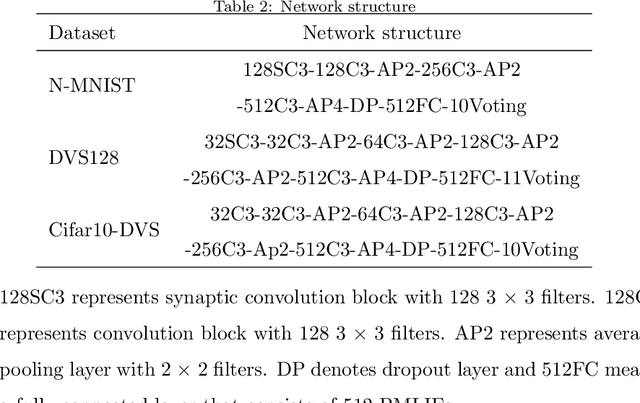
Spiking neural networks (SNNs), as one of the brain-inspired models, has spatio-temporal information processing capability, low power feature, and high biological plausibility. The effective spatio-temporal feature makes it suitable for event streams classification. However, neuromorphic datasets, such as N-MNIST, CIFAR10-DVS, DVS128-gesture, need to aggregate individual events into frames with a new higher temporal resolution for event stream classification, which causes high training and inference latency. In this work, we proposed a spatio-temporal compression method to aggregate individual events into a few time steps of synaptic current to reduce the training and inference latency. To keep the accuracy of SNNs under high compression ratios, we also proposed a synaptic convolutional block to balance the dramatic change between adjacent time steps. And multi-threshold Leaky Integrate-and-Fire (LIF) with learnable membrane time constant is introduced to increase its information processing capability. We evaluate the proposed method for event streams classification tasks on neuromorphic N-MNIST, CIFAR10-DVS, DVS128 gesture datasets. The experiment results show that our proposed method outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps.
Reliability Assessment of Neural Networks in GPUs: A Framework For Permanent Faults Injections
May 24, 2022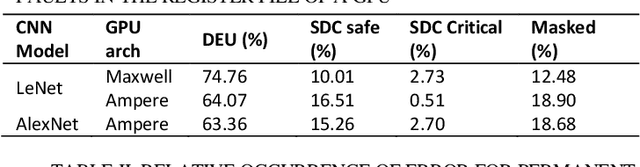
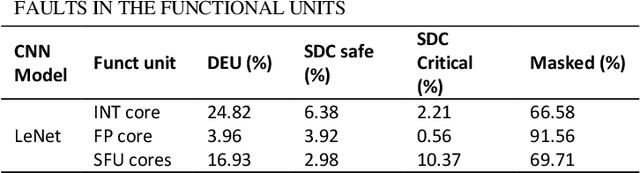
Currently, Deep learning and especially Convolutional Neural Networks (CNNs) have become a fundamental computational approach applied in a wide range of domains, including some safety-critical applications (e.g., automotive, robotics, and healthcare equipment). Therefore, the reliability evaluation of those computational systems is mandatory. The reliability evaluation of CNNs is performed by fault injection campaigns at different levels of abstraction, from the application level down to the hardware level. Many works have focused on evaluating the reliability of neural networks in the presence of transient faults. However, the effects of permanent faults have been investigated at the application level, only, e.g., targeting the parameters of the network. This paper intends to propose a framework, resorting to a binary instrumentation tool to perform fault injection campaigns, targeting different components inside the GPU, such as the register files and the functional units. This environment allows for the first time assessing the reliability of CNNs deployed on a GPU considering the presence of permanent faults.