 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Analysis of Linear Time Series Forecasting Models
Mar 25, 2024
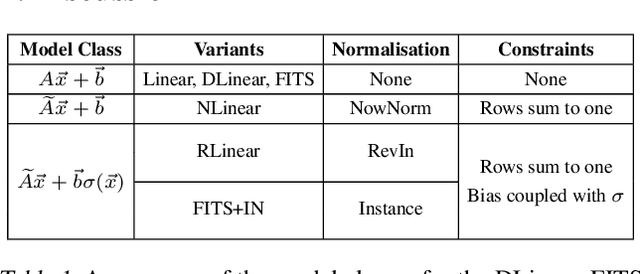

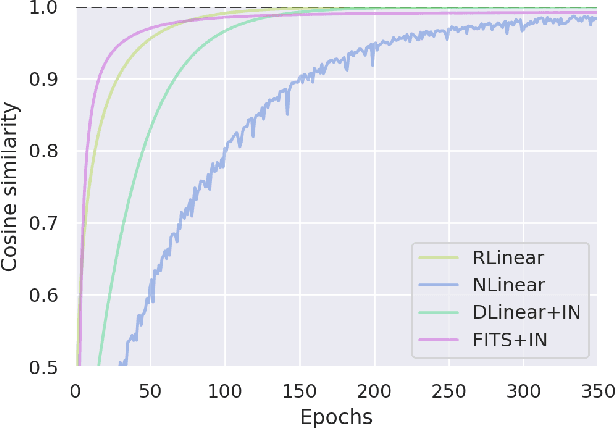
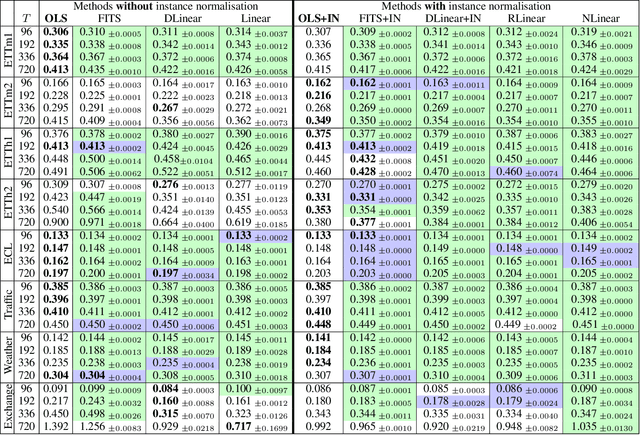
Despite their simplicity, linear models perform well at time series forecasting, even when pitted against deeper and more expensive models. A number of variations to the linear model have been proposed, often including some form of feature normalisation that improves model generalisation. In this paper we analyse the sets of functions expressible using these linear model architectures. In so doing we show that several popular variants of linear models for time series forecasting are equivalent and functionally indistinguishable from standard, unconstrained linear regression. We characterise the model classes for each linear variant. We demonstrate that each model can be reinterpreted as unconstrained linear regression over a suitably augmented feature set, and therefore admit closed-form solutions when using a mean-squared loss function. We provide experimental evidence that the models under inspection learn nearly identical solutions, and finally demonstrate that the simpler closed form solutions are superior forecasters across 72% of test settings.
A Tight $O(4^k/p_c)$ Runtime Bound for a ($μ$+1) GA on Jump$_k$ for Realistic Crossover Probabilities
Apr 10, 2024The Jump$_k$ benchmark was the first problem for which crossover was proven to give a speedup over mutation-only evolutionary algorithms. Jansen and Wegener (2002) proved an upper bound of $O({\rm poly}(n) + 4^k/p_c)$ for the ($\mu$+1)~Genetic Algorithm ($(\mu+1)$ GA), but only for unrealistically small crossover probabilities $p_c$. To this date, it remains an open problem to prove similar upper bounds for realistic~$p_c$; the best known runtime bound for $p_c = \Omega(1)$ is $O((n/\chi)^{k-1})$, $\chi$ a positive constant. Using recently developed techniques, we analyse the evolution of the population diversity, measured as sum of pairwise Hamming distances, for a variant of the \muga on Jump$_k$. We show that population diversity converges to an equilibrium of near-perfect diversity. This yields an improved and tight time bound of $O(\mu n \log(k) + 4^k/p_c)$ for a range of~$k$ under the mild assumptions $p_c = O(1/k)$ and $\mu \in \Omega(kn)$. For all constant~$k$ the restriction is satisfied for some $p_c = \Omega(1)$. Our work partially solves a problem that has been open for more than 20 years.
UAV-Assisted Enhanced Coverage and Capacity in Dynamic MU-mMIMO IoT Systems: A Deep Reinforcement Learning Approach
Apr 10, 2024This study focuses on a multi-user massive multiple-input multiple-output (MU-mMIMO) system by incorporating an unmanned aerial vehicle (UAV) as a decode-and-forward (DF) relay between the base station (BS) and multiple Internet-of-Things (IoT) devices. Our primary objective is to maximize the overall achievable rate (AR) by introducing a novel framework that integrates joint hybrid beamforming (HBF) and UAV localization in dynamic MU-mMIMO IoT systems. Particularly, HBF stages for BS and UAV are designed by leveraging slow time-varying angular information, whereas a deep reinforcement learning (RL) algorithm, namely deep deterministic policy gradient (DDPG) with continuous action space, is developed to train the UAV for its deployment. By using a customized reward function, the RL agent learns an optimal UAV deployment policy capable of adapting to both static and dynamic environments. The illustrative results show that the proposed DDPG-based UAV deployment (DDPG-UD) can achieve approximately 99.5% of the sum-rate capacity achieved by particle swarm optimization (PSO)-based UAV deployment (PSO-UD), while requiring a significantly reduced runtime at approximately 68.50% of that needed by PSO-UD, offering an efficient solution in dynamic MU-mMIMO environments.
A Survey on the Integration of Generative AI for Critical Thinking in Mobile Networks
Apr 10, 2024In the near future, mobile networks are expected to broaden their services and coverage to accommodate a larger user base and diverse user needs. Thus, they will increasingly rely on artificial intelligence (AI) to manage network operation and control costs, undertaking complex decision-making roles. This shift will necessitate the application of techniques that incorporate critical thinking abilities, including reasoning and planning. Symbolic AI techniques already facilitate critical thinking based on existing knowledge. Yet, their use in telecommunications is hindered by the high cost of mostly manual curation of this knowledge and high computational complexity of reasoning tasks. At the same time, there is a spurt of innovations in industries such as telecommunications due to Generative AI (GenAI) technologies, operating independently of human-curated knowledge. However, their capacity for critical thinking remains uncertain. This paper aims to address this gap by examining the current status of GenAI algorithms with critical thinking capabilities and investigating their potential applications in telecom networks. Specifically, the aim of this study is to offer an introduction to the potential utilization of GenAI for critical thinking techniques in mobile networks, while also establishing a foundation for future research.
Generative Pre-Trained Transformer for Symbolic Regression Base In-Context Reinforcement Learning
Apr 09, 2024The mathematical formula is the human language to describe nature and is the essence of scientific research. Finding mathematical formulas from observational data is a major demand of scientific research and a major challenge of artificial intelligence. This area is called symbolic regression. Originally symbolic regression was often formulated as a combinatorial optimization problem and solved using GP or reinforcement learning algorithms. These two kinds of algorithms have strong noise robustness ability and good Versatility. However, inference time usually takes a long time, so the search efficiency is relatively low. Later, based on large-scale pre-training data proposed, such methods use a large number of synthetic data points and expression pairs to train a Generative Pre-Trained Transformer(GPT). Then this GPT can only need to perform one forward propagation to obtain the results, the advantage is that the inference speed is very fast. However, its performance is very dependent on the training data and performs poorly on data outside the training set, which leads to poor noise robustness and Versatility of such methods. So, can we combine the advantages of the above two categories of SR algorithms? In this paper, we propose \textbf{FormulaGPT}, which trains a GPT using massive sparse reward learning histories of reinforcement learning-based SR algorithms as training data. After training, the SR algorithm based on reinforcement learning is distilled into a Transformer. When new test data comes, FormulaGPT can directly generate a "reinforcement learning process" and automatically update the learning policy in context. Tested on more than ten datasets including SRBench, formulaGPT achieves the state-of-the-art performance in fitting ability compared with four baselines. In addition, it achieves satisfactory results in noise robustness, versatility, and inference efficiency.
CLIP-Embed-KD: Computationally Efficient Knowledge Distillation Using Embeddings as Teachers
Apr 09, 2024Contrastive Language-Image Pre-training (CLIP) has been shown to improve zero-shot generalization capabilities of language and vision models. In this paper, we extend CLIP for efficient knowledge distillation, by utilizing embeddings as teachers. Typical knowledge distillation frameworks require running forward passes through a teacher model, which is often prohibitive in the case of billion or trillion parameter teachers. In these cases, using only the embeddings of the teacher models to guide the distillation can yield significant computational savings. Our preliminary findings show that CLIP-based knowledge distillation with embeddings can outperform full scale knowledge distillation using $9\times$ less memory and $8\times$ less training time. Code available at: https://github.com/lnairGT/CLIP-Distillation/
Interpretable Neural Temporal Point Processes for Modelling Electronic Health Records
Apr 09, 2024Electronic Health Records (EHR) can be represented as temporal sequences that record the events (medical visits) from patients. Neural temporal point process (NTPP) has achieved great success in modeling event sequences that occur in continuous time space. However, due to the black-box nature of neural networks, existing NTPP models fall short in explaining the dependencies between different event types. In this paper, inspired by word2vec and Hawkes process, we propose an interpretable framework inf2vec for event sequence modelling, where the event influences are directly parameterized and can be learned end-to-end. In the experiment, we demonstrate the superiority of our model on event prediction as well as type-type influences learning.
RiEMann: Near Real-Time SE(3)-Equivariant Robot Manipulation without Point Cloud Segmentation
Mar 28, 2024
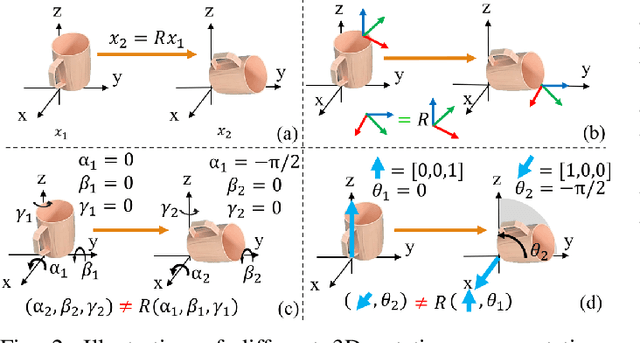
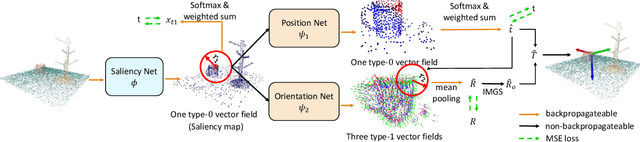

We present RiEMann, an end-to-end near Real-time SE(3)-Equivariant Robot Manipulation imitation learning framework from scene point cloud input. Compared to previous methods that rely on descriptor field matching, RiEMann directly predicts the target poses of objects for manipulation without any object segmentation. RiEMann learns a manipulation task from scratch with 5 to 10 demonstrations, generalizes to unseen SE(3) transformations and instances of target objects, resists visual interference of distracting objects, and follows the near real-time pose change of the target object. The scalable action space of RiEMann facilitates the addition of custom equivariant actions such as the direction of turning the faucet, which makes articulated object manipulation possible for RiEMann. In simulation and real-world 6-DOF robot manipulation experiments, we test RiEMann on 5 categories of manipulation tasks with a total of 25 variants and show that RiEMann outperforms baselines in both task success rates and SE(3) geodesic distance errors on predicted poses (reduced by 68.6%), and achieves a 5.4 frames per second (FPS) network inference speed. Code and video results are available at https://riemann-web.github.io/.
Multi-Modal Contrastive Learning for Online Clinical Time-Series Applications
Mar 27, 2024Electronic Health Record (EHR) datasets from Intensive Care Units (ICU) contain a diverse set of data modalities. While prior works have successfully leveraged multiple modalities in supervised settings, we apply advanced self-supervised multi-modal contrastive learning techniques to ICU data, specifically focusing on clinical notes and time-series for clinically relevant online prediction tasks. We introduce a loss function Multi-Modal Neighborhood Contrastive Loss (MM-NCL), a soft neighborhood function, and showcase the excellent linear probe and zero-shot performance of our approach.
Exploiting Preference Elicitation in Interactive and User-centered Algorithmic Recourse: An Initial Exploration
Apr 08, 2024Algorithmic Recourse aims to provide actionable explanations, or recourse plans, to overturn potentially unfavourable decisions taken by automated machine learning models. In this paper, we propose an interaction paradigm based on a guided interaction pattern aimed at both eliciting the users' preferences and heading them toward effective recourse interventions. In a fictional task of money lending, we compare this approach with an exploratory interaction pattern based on a combination of alternative plans and the possibility of freely changing the configurations by the users themselves. Our results suggest that users may recognize that the guided interaction paradigm improves efficiency. However, they also feel less freedom to experiment with "what-if" scenarios. Nevertheless, the time spent on the purely exploratory interface tends to be perceived as a lack of efficiency, which reduces attractiveness, perspicuity, and dependability. Conversely, for the guided interface, more time on the interface seems to increase its attractiveness, perspicuity, and dependability while not impacting the perceived efficiency. That might suggest that this type of interfaces should combine these two approaches by trying to support exploratory behavior while gently pushing toward a guided effective solution.