 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SoK: Cross-border Criminal Investigations and Digital Evidence
May 25, 2022

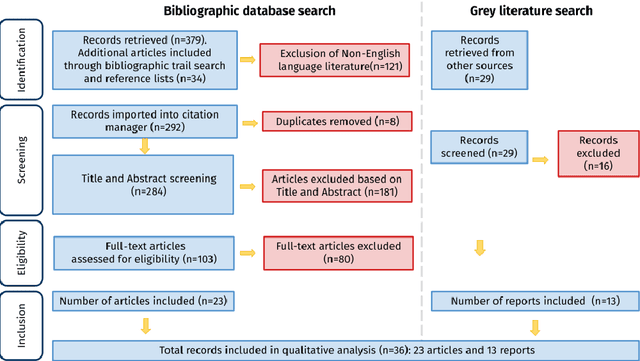

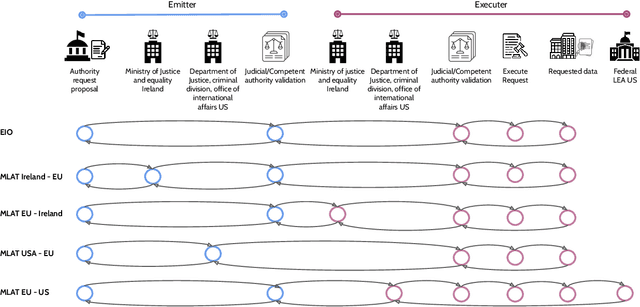
Digital evidence underpin the majority of crimes as their analysis is an integral part of almost every criminal investigation. Even if we temporarily disregard the numerous challenges in the collection and analysis of digital evidence, the exchange of the evidence among the different stakeholders has many thorny issues. Of specific interest are cross-border criminal investigations as the complexity is significantly high due to the heterogeneity of legal frameworks which beyond time bottlenecks can also become prohibiting. The aim of this article is to analyse the current state of practice of cross-border investigations considering the efficacy of current collaboration protocols along with the challenges and drawbacks to be overcome. Further to performing a legally-oriented research treatise, we recall all the challenges raised in the literature and discuss them from a more practical yet global perspective. Thus, this article paves the way to enabling practitioners and stakeholders to leverage horizontal strategies to fill in the identified gaps timely and accurately.
Compositional Visual Generation with Composable Diffusion Models
Jun 08, 2022
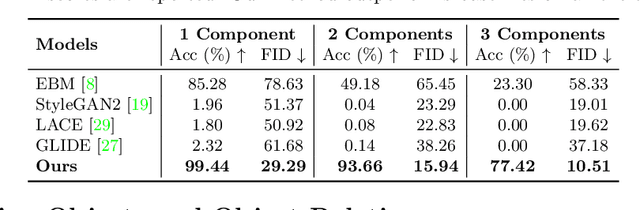

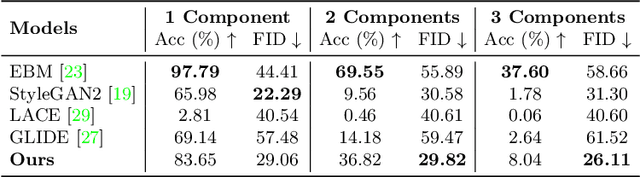
Large text-guided diffusion models, such as DALLE-2, are able to generate stunning photorealistic images given natural language descriptions. While such models are highly flexible, they struggle to understand the composition of certain concepts, such as confusing the attributes of different objects or relations between objects. In this paper, we propose an alternative structured approach for compositional generation using diffusion models. An image is generated by composing a set of diffusion models, with each of them modeling a certain component of the image. To do this, we interpret diffusion models as energy-based models in which the data distributions defined by the energy functions may be explicitly combined. The proposed method can generate scenes at test time that are substantially more complex than those seen in training, composing sentence descriptions, object relations, human facial attributes, and even generalizing to new combinations that are rarely seen in the real world. We further illustrate how our approach may be used to compose pre-trained text-guided diffusion models and generate photorealistic images containing all the details described in the input descriptions, including the binding of certain object attributes that have been shown difficult for DALLE-2. These results point to the effectiveness of the proposed method in promoting structured generalization for visual generation. Project page: https://energy-based-model.github.io/Compositional-Visual-Generation-with-Composable-Diffusion-Models/
AlphaZero-Inspired General Board Game Learning and Playing
Apr 28, 2022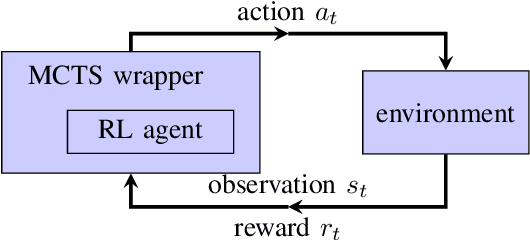
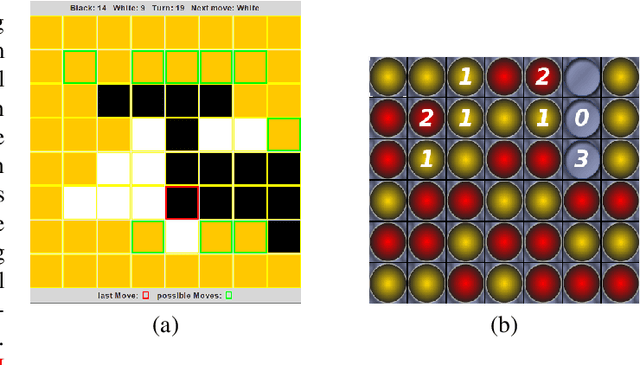
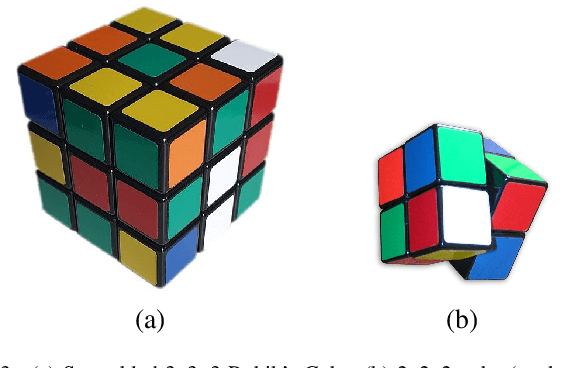
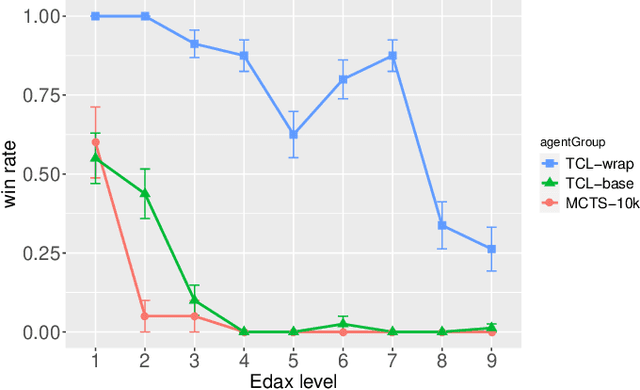
Recently, the seminal algorithms AlphaGo and AlphaZero have started a new era in game learning and deep reinforcement learning. While the achievements of AlphaGo and AlphaZero - playing Go and other complex games at super human level - are truly impressive, these architectures have the drawback that they are very complex and require high computational resources. Many researchers are looking for methods that are similar to AlphaZero, but have lower computational demands and are thus more easily reproducible. In this paper, we pick an important element of AlphaZero - the Monte Carlo Tree Search (MCTS) planning stage - and combine it with reinforcement learning (RL) agents. We wrap MCTS for the first time around RL n-tuple networks to create versatile agents that keep at the same time the computational demands low. We apply this new architecture to several complex games (Othello, ConnectFour, Rubik's Cube) and show the advantages achieved with this AlphaZero-inspired MCTS wrapper. In particular, we present results that this AlphaZero-inspired agent is the first one trained on standard hardware (no GPU or TPU) to beat the very strong Othello program Edax up to and including level 7 (where most other algorithms could only defeat Edax up to level 2).
A Broadband and Compact Millimeter-Wave Imaging System based on Synthetic Aperture Radar
May 29, 2022

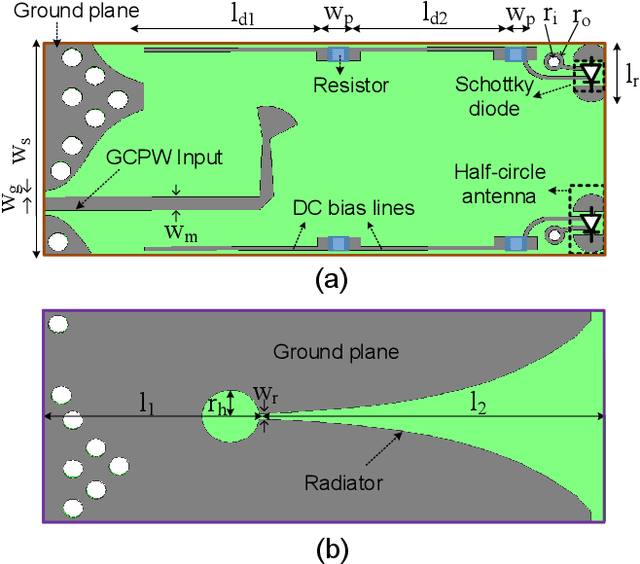
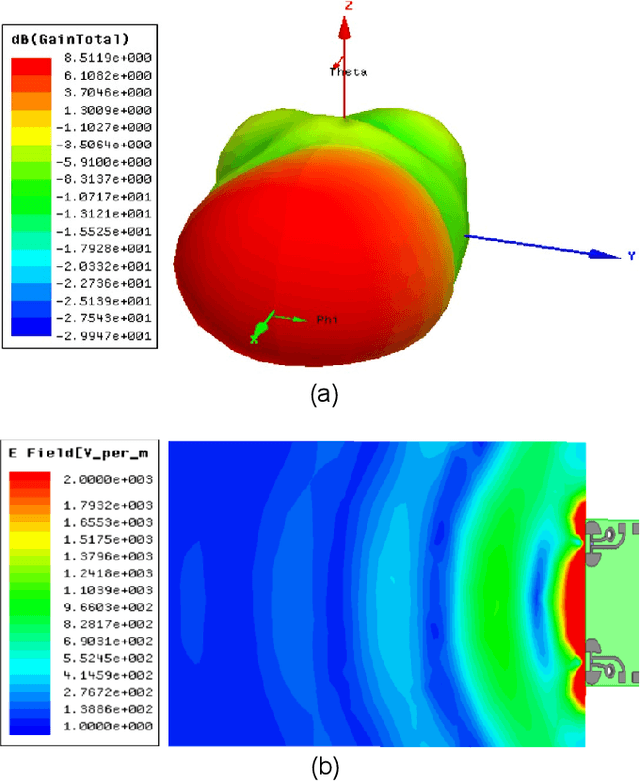
In this paper, the design, realization, and demonstration of a broadband millimeter-wave imaging system based on the synthetic aperture radar technique (SAR) are discussed. The proposed system, operating within the frequency range of 25.3-30.8 GHz, consists of a tapered slot antenna as the transmitter and two half-circle antennas as the receivers. The size of the antenna is 19.5 * 8 mm with a maximum gain of 8.5 dB. The transmitter and the receiver antennas are printed on the same board. This feature leads to a highly compact and flexible configuration, enabling the applicability of the proposed imaging system in the handheld devices. Furthermore, it significantly reduces the fabrication cost of the system. The proposed broadband imaging system, being capable of performing 3D real-time imaging with high resolutions, can be easily calibrated for each frequency within the desired range. By performing 3D imaging from metallic objects with different shapes, we experimentally demonstrate the high performance of the proposed system, which offers great potentialities for a broad range of applications such as security, medical diagnostic, concealed object detection, to name a few.
Visualizing CoAtNet Predictions for Aiding Melanoma Detection
May 21, 2022
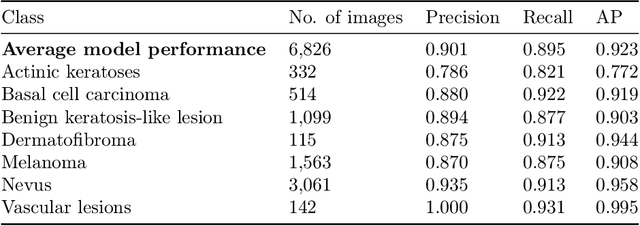
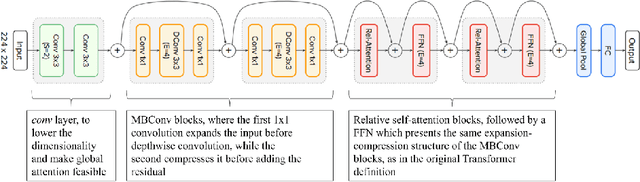
Melanoma is considered to be the most aggressive form of skin cancer. Due to the similar shape of malignant and benign cancerous lesions, doctors spend considerably more time when diagnosing these findings. At present, the evaluation of malignancy is performed primarily by invasive histological examination of the suspicious lesion. Developing an accurate classifier for early and efficient detection can minimize and monitor the harmful effects of skin cancer and increase patient survival rates. This paper proposes a multi-class classification task using the CoAtNet architecture, a hybrid model that combines the depthwise convolution matrix operation of traditional convolutional neural networks with the strengths of Transformer models and self-attention mechanics to achieve better generalization and capacity. The proposed multi-class classifier achieves an overall precision of 0.901, recall 0.895, and AP 0.923, indicating high performance compared to other state-of-the-art networks.
Smart Meter Data Anomaly Detection using Variational Recurrent Autoencoders with Attention
Jun 08, 2022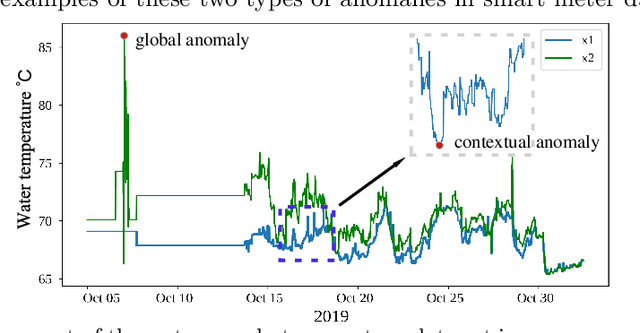
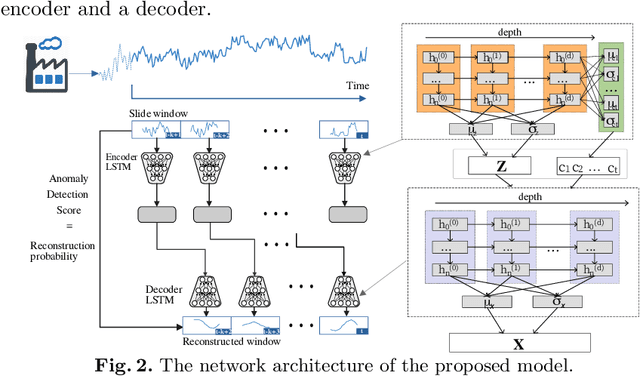
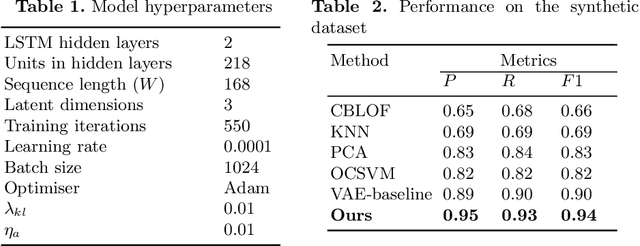
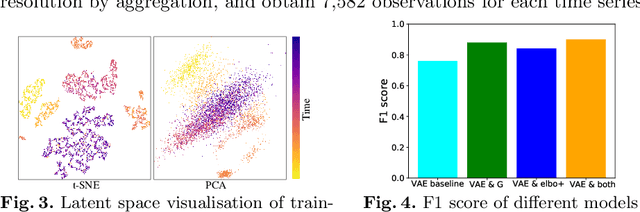
In the digitization of energy systems, sensors and smart meters are increasingly being used to monitor production, operation and demand. Detection of anomalies based on smart meter data is crucial to identify potential risks and unusual events at an early stage, which can serve as a reference for timely initiation of appropriate actions and improving management. However, smart meter data from energy systems often lack labels and contain noise and various patterns without distinctively cyclical. Meanwhile, the vague definition of anomalies in different energy scenarios and highly complex temporal correlations pose a great challenge for anomaly detection. Many traditional unsupervised anomaly detection algorithms such as cluster-based or distance-based models are not robust to noise and not fully exploit the temporal dependency in a time series as well as other dependencies amongst multiple variables (sensors). This paper proposes an unsupervised anomaly detection method based on a Variational Recurrent Autoencoder with attention mechanism. with "dirty" data from smart meters, our method pre-detects missing values and global anomalies to shrink their contribution while training. This paper makes a quantitative comparison with the VAE-based baseline approach and four other unsupervised learning methods, demonstrating its effectiveness and superiority. This paper further validates the proposed method by a real case study of detecting the anomalies of water supply temperature from an industrial heating plant.
Machine learning method for return direction forecasting of Exchange Traded Funds using classification and regression models
May 25, 2022
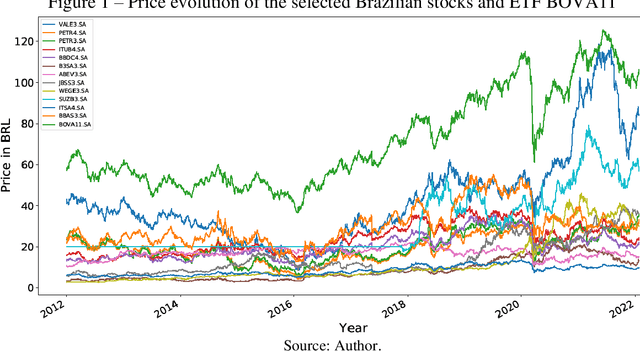

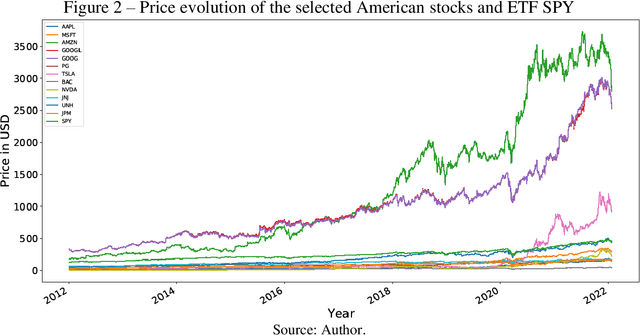
This article aims to propose and apply a machine learning method to analyze the direction of returns from Exchange Traded Funds (ETFs) using the historical return data of its components, helping to make investment strategy decisions through a trading algorithm. In methodological terms, regression and classification models were applied, using standard datasets from Brazilian and American markets, in addition to algorithmic error metrics. In terms of research results, they were analyzed and compared to those of the Na\"ive forecast and the returns obtained by the buy & hold technique in the same period of time. In terms of risk and return, the models mostly performed better than the control metrics, with emphasis on the linear regression model and the classification models by logistic regression, support vector machine (using the LinearSVC model), Gaussian Naive Bayes and K-Nearest Neighbors, where in certain datasets the returns exceeded by two times and the Sharpe ratio by up to four times those of the buy & hold control model.
The ACM Multimedia 2022 Computational Paralinguistics Challenge: Vocalisations, Stuttering, Activity, & Mosquitoes
May 13, 2022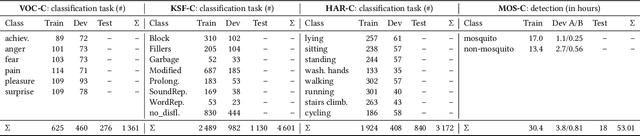
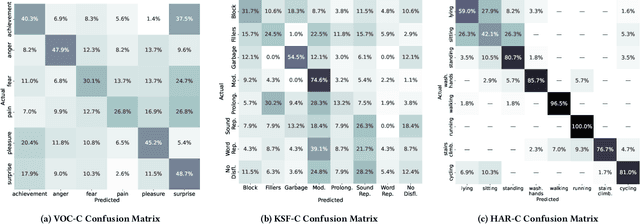

The ACM Multimedia 2022 Computational Paralinguistics Challenge addresses four different problems for the first time in a research competition under well-defined conditions: In the Vocalisations and Stuttering Sub-Challenges, a classification on human non-verbal vocalisations and speech has to be made; the Activity Sub-Challenge aims at beyond-audio human activity recognition from smartwatch sensor data; and in the Mosquitoes Sub-Challenge, mosquitoes need to be detected. We describe the Sub-Challenges, baseline feature extraction, and classifiers based on the usual ComPaRE and BoAW features, the auDeep toolkit, and deep feature extraction from pre-trained CNNs using the DeepSpectRum toolkit; in addition, we add end-to-end sequential modelling, and a log-mel-128-BNN.
Deep learning for time series classification
Oct 01, 2020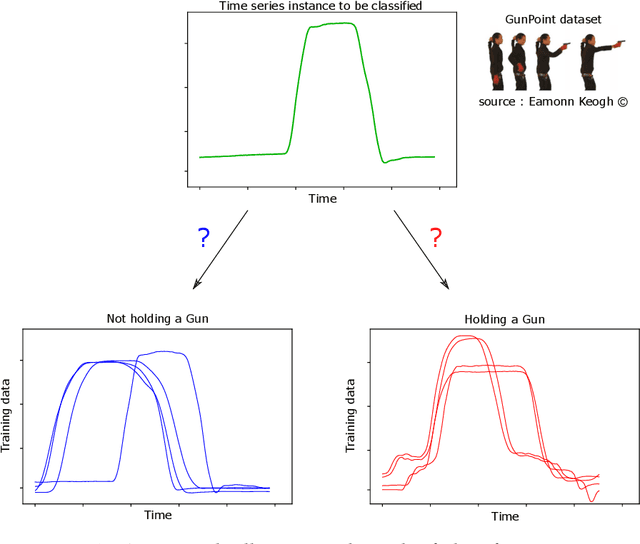
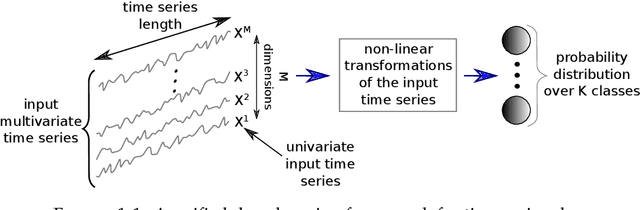
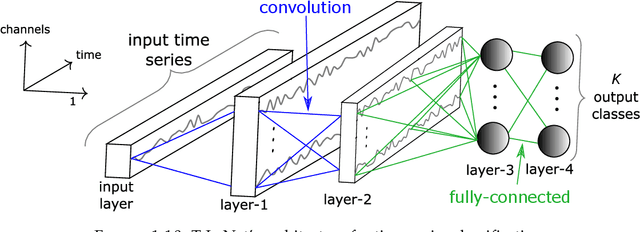
Time series analysis is a field of data science which is interested in analyzing sequences of numerical values ordered in time. Time series are particularly interesting because they allow us to visualize and understand the evolution of a process over time. Their analysis can reveal trends, relationships and similarities across the data. There exists numerous fields containing data in the form of time series: health care (electrocardiogram, blood sugar, etc.), activity recognition, remote sensing, finance (stock market price), industry (sensors), etc. Time series classification consists of constructing algorithms dedicated to automatically label time series data. The sequential aspect of time series data requires the development of algorithms that are able to harness this temporal property, thus making the existing off-the-shelf machine learning models for traditional tabular data suboptimal for solving the underlying task. In this context, deep learning has emerged in recent years as one of the most effective methods for tackling the supervised classification task, particularly in the field of computer vision. The main objective of this thesis was to study and develop deep neural networks specifically constructed for the classification of time series data. We thus carried out the first large scale experimental study allowing us to compare the existing deep methods and to position them compared other non-deep learning based state-of-the-art methods. Subsequently, we made numerous contributions in this area, notably in the context of transfer learning, data augmentation, ensembling and adversarial attacks. Finally, we have also proposed a novel architecture, based on the famous Inception network (Google), which ranks among the most efficient to date.
Provably Auditing Ordinary Least Squares in Low Dimensions
Jun 05, 2022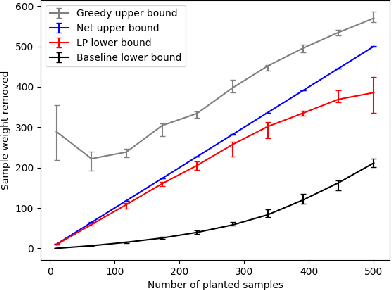
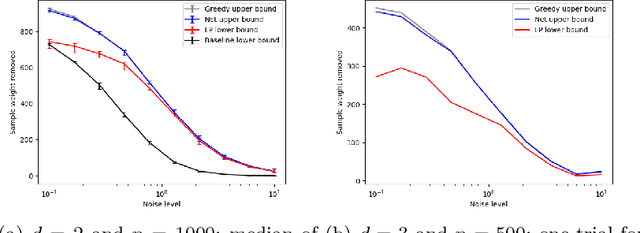
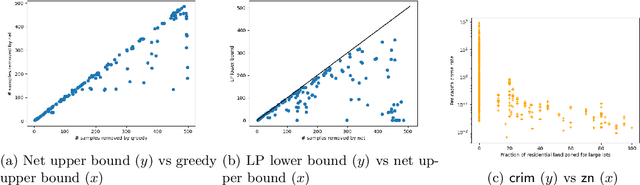
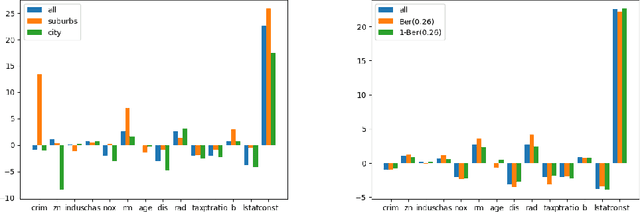
Measuring the stability of conclusions derived from Ordinary Least Squares linear regression is critically important, but most metrics either only measure local stability (i.e. against infinitesimal changes in the data), or are only interpretable under statistical assumptions. Recent work proposes a simple, global, finite-sample stability metric: the minimum number of samples that need to be removed so that rerunning the analysis overturns the conclusion, specifically meaning that the sign of a particular coefficient of the estimated regressor changes. However, besides the trivial exponential-time algorithm, the only approach for computing this metric is a greedy heuristic that lacks provable guarantees under reasonable, verifiable assumptions; the heuristic provides a loose upper bound on the stability and also cannot certify lower bounds on it. We show that in the low-dimensional regime where the number of covariates is a constant but the number of samples is large, there are efficient algorithms for provably estimating (a fractional version of) this metric. Applying our algorithms to the Boston Housing dataset, we exhibit regression analyses where we can estimate the stability up to a factor of $3$ better than the greedy heuristic, and analyses where we can certify stability to dropping even a majority of the samples.