 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Energy-Efficient Model Compression and Splitting for Collaborative Inference Over Time-Varying Channels
Jun 02, 2021
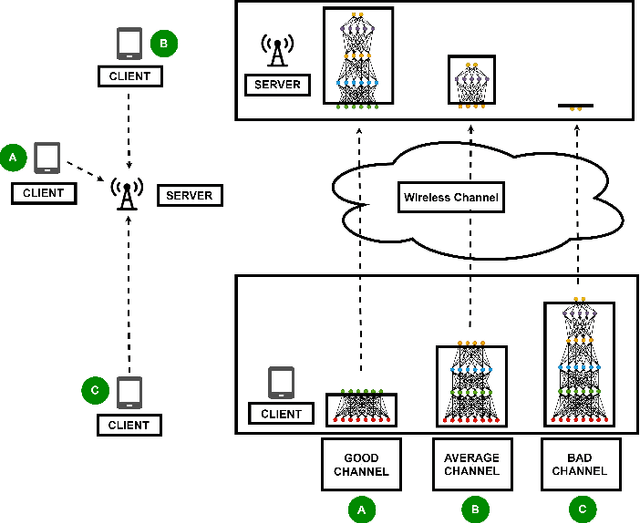
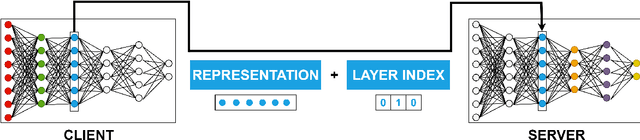
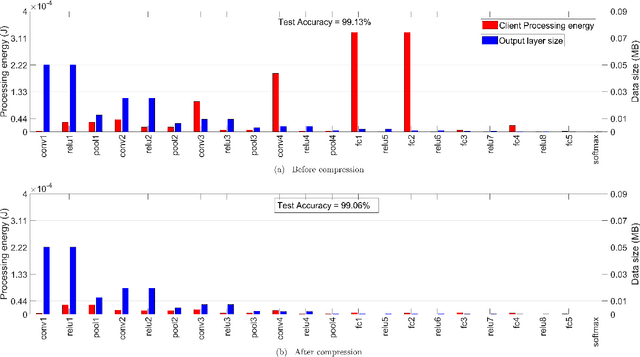
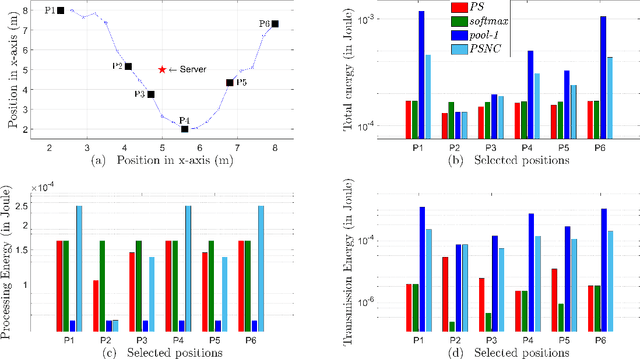
Today's intelligent applications can achieve high performance accuracy using machine learning (ML) techniques, such as deep neural networks (DNNs). Traditionally, in a remote DNN inference problem, an edge device transmits raw data to a remote node that performs the inference task. However, this may incur high transmission energy costs and puts data privacy at risk. In this paper, we propose a technique to reduce the total energy bill at the edge device by utilizing model compression and time-varying model split between the edge and remote nodes. The time-varying representation accounts for time-varying channels and can significantly reduce the total energy at the edge device while maintaining high accuracy (low loss). We implement our approach in an image classification task using the MNIST dataset, and the system environment is simulated as a trajectory navigation scenario to emulate different channel conditions. Numerical simulations show that our proposed solution results in minimal energy consumption and $CO_2$ emission compared to the considered baselines while exhibiting robust performance across different channel conditions and bandwidth regime choices.
Interpretable Deep Learning Classifier by Detection of Prototypical Parts on Kidney Stones Images
Jun 02, 2022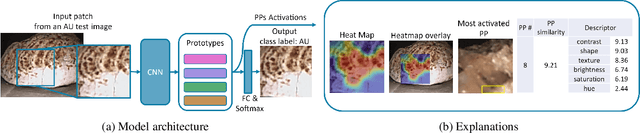


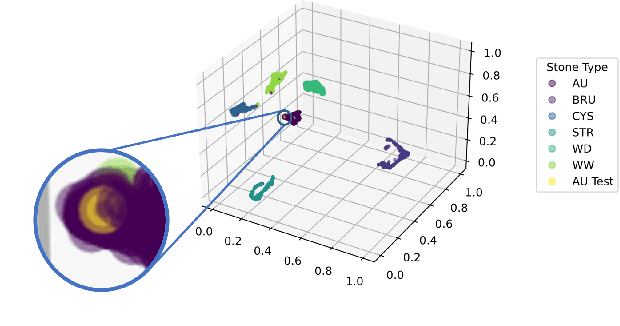
Identifying the type of kidney stones can allow urologists to determine their formation cause, improving the early prescription of appropriate treatments to diminish future relapses. However, currently, the associated ex-vivo diagnosis (known as morpho-constitutional analysis, MCA) is time-consuming, expensive, and requires a great deal of experience, as it requires a visual analysis component that is highly operator dependant. Recently, machine learning methods have been developed for in-vivo endoscopic stone recognition. Shallow methods have been demonstrated to be reliable and interpretable but exhibit low accuracy, while deep learning-based methods yield high accuracy but are not explainable. However, high stake decisions require understandable computer-aided diagnosis (CAD) to suggest a course of action based on reasonable evidence, rather than merely prescribe one. Herein, we investigate means for learning part-prototypes (PPs) that enable interpretable models. Our proposal suggests a classification for a kidney stone patch image and provides explanations in a similar way as those used on the MCA method.
Simple Cues Lead to a Strong Multi-Object Tracker
Jun 09, 2022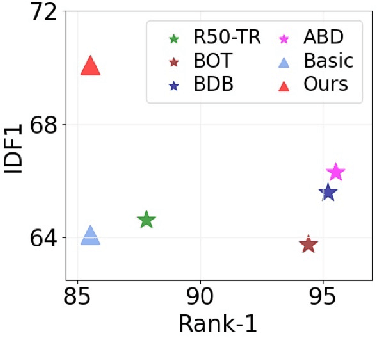

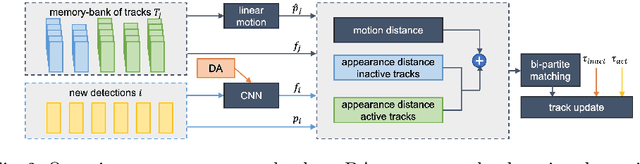
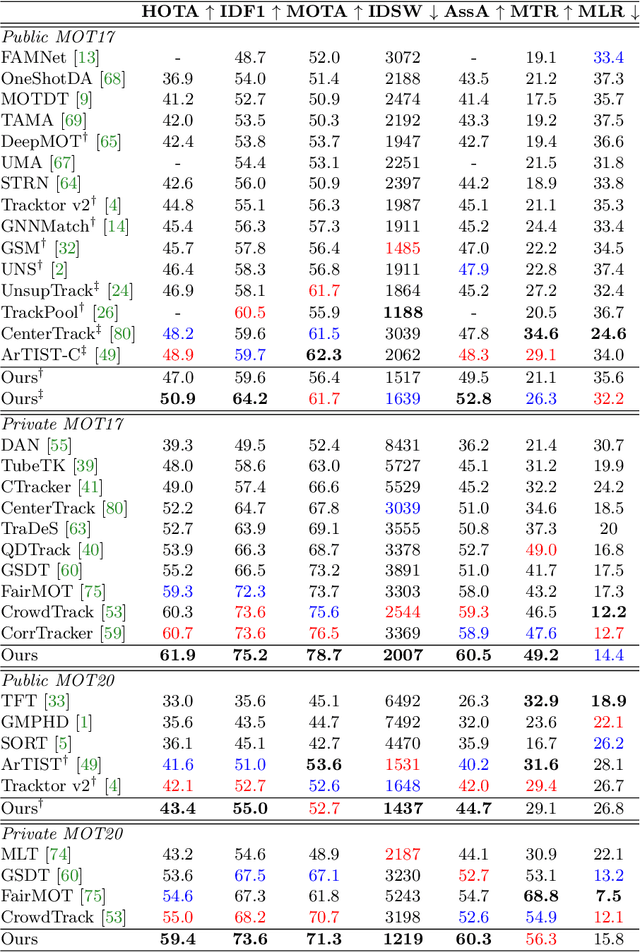
For a long time, the most common paradigm in Multi-Object Tracking was tracking-by-detection (TbD), where objects are first detected and then associated over video frames. For association, most models resource to motion and appearance cues. While still relying on these cues, recent approaches based on, e.g., attention have shown an ever-increasing need for training data and overall complex frameworks. We claim that 1) strong cues can be obtained from little amounts of training data if some key design choices are applied, 2) given these strong cues, standard Hungarian matching-based association is enough to obtain impressive results. Our main insight is to identify key components that allow a standard reidentification network to excel at appearance-based tracking. We extensively analyze its failure cases and show that a combination of our appearance features with a simple motion model leads to strong tracking results. Our model achieves state-of-the-art performance on MOT17 and MOT20 datasets outperforming previous state-of-the-art trackers by up to 5.4pp in IDF1 and 4.4pp in HOTA. We will release the code and models after the paper's acceptance.
Vision Transformer for Contrastive Clustering
Jun 26, 2022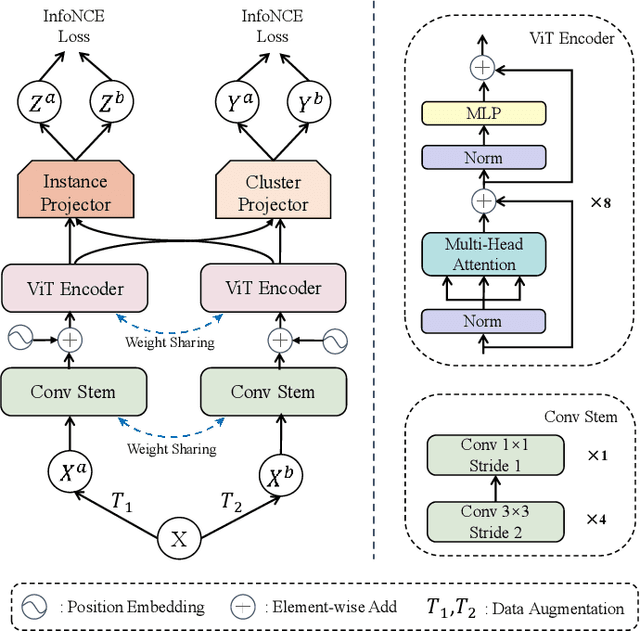

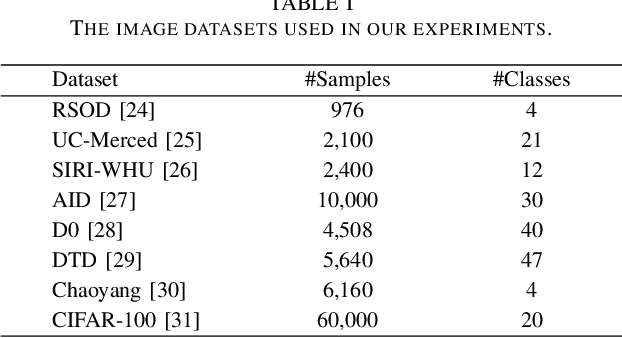
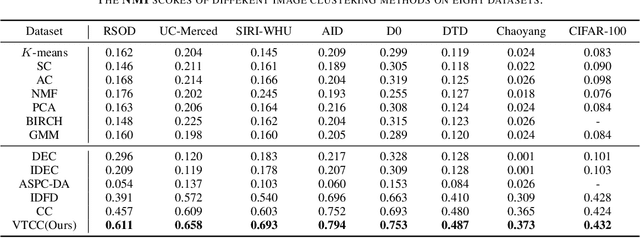
Vision Transformer (ViT) has shown its advantages over the convolutional neural network (CNN) with its ability to capture global long-range dependencies for visual representation learning. Besides ViT, contrastive learning is another popular research topic recently. While previous contrastive learning works are mostly based on CNNs, some latest studies have attempted to jointly model the ViT and the contrastive learning for enhanced self-supervised learning. Despite the considerable progress, these combinations of ViT and contrastive learning mostly focus on the instance-level contrastiveness, which often overlook the contrastiveness of the global clustering structures and also lack the ability to directly learn the clustering result (e.g., for images). In view of this, this paper presents an end-to-end deep image clustering approach termed Vision Transformer for Contrastive Clustering (VTCC), which for the first time, to the best of our knowledge, unifies the Transformer and the contrastive learning for the image clustering task. Specifically, with two random augmentations performed on each image in a mini-batch, we utilize a ViT encoder with two weight-sharing views as the backbone to learn the representations for the augmented samples. To remedy the potential instability of the ViT, we incorporate a convolutional stem, which uses multiple stacked small convolutions instead of a big convolution in the patch projection layer, to split each augmented sample into a sequence of patches. With representations learned via the backbone, an instance projector and a cluster projector are further utilized for the instance-level contrastive learning and the global clustering structure learning, respectively. Extensive experiments on eight image datasets demonstrate the stability (during the training-from-scratch) and the superiority (in clustering performance) of VTCC over the state-of-the-art.
Mapping Research Trajectories
Apr 25, 2022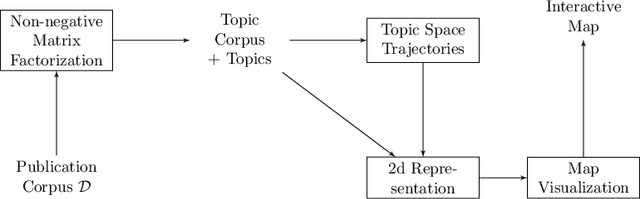
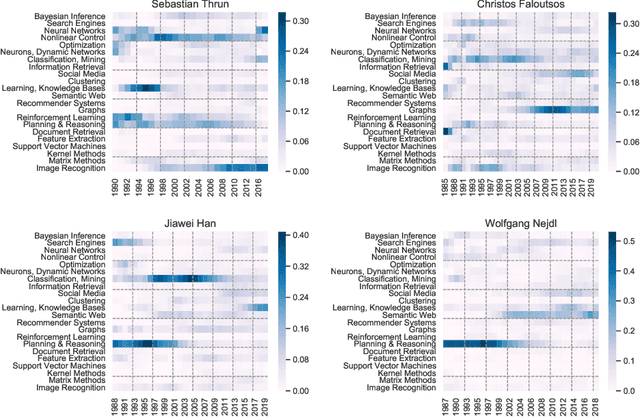
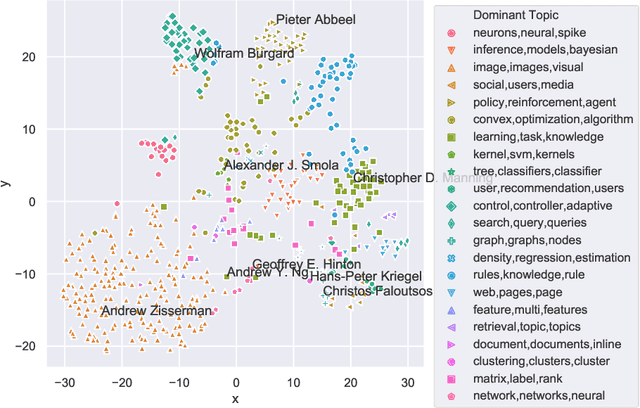
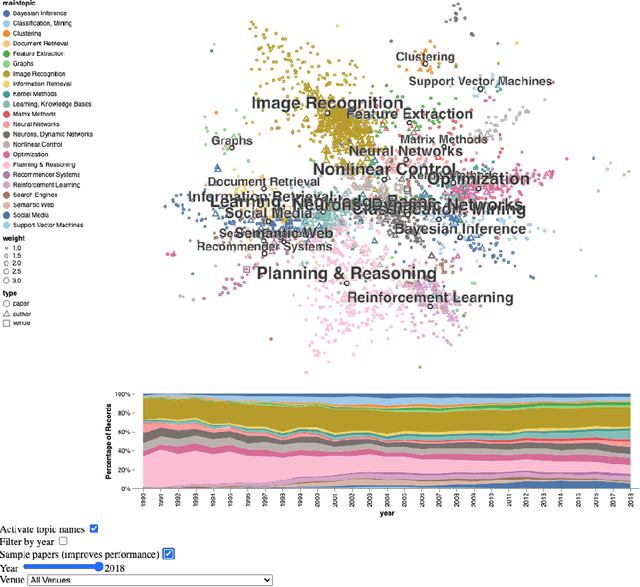
Steadily growing amounts of information, such as annually published scientific papers, have become so large that they elude an extensive manual analysis. Hence, to maintain an overview, automated methods for the mapping and visualization of knowledge domains are necessary and important, e.g., for scientific decision makers. Of particular interest in this field is the development of research topics of different entities (e.g., scientific authors and venues) over time. However, existing approaches for their analysis are only suitable for single entity types, such as venues, and they often do not capture the research topics or the time dimension in an easily interpretable manner. Hence, we propose a principled approach for \emph{mapping research trajectories}, which is applicable to all kinds of scientific entities that can be represented by sets of published papers. For this, we transfer ideas and principles from the geographic visualization domain, specifically trajectory maps and interactive geographic maps. Our visualizations depict the research topics of entities over time in a straightforward interpr. manner. They can be navigated by the user intuitively and restricted to specific elements of interest. The maps are derived from a corpus of research publications (i.e., titles and abstracts) through a combination of unsupervised machine learning methods. In a practical demonstrator application, we exemplify the proposed approach on a publication corpus from machine learning. We observe that our trajectory visualizations of 30 top machine learning venues and 1000 major authors in this field are well interpretable and are consistent with background knowledge drawn from the entities' publications. Next to producing interactive, interpr. visualizations supporting different kinds of analyses, our computed trajectories are suitable for trajectory mining applications in the future.
DeepSITH: Efficient Learning via Decomposition of What and When Across Time Scales
Apr 09, 2021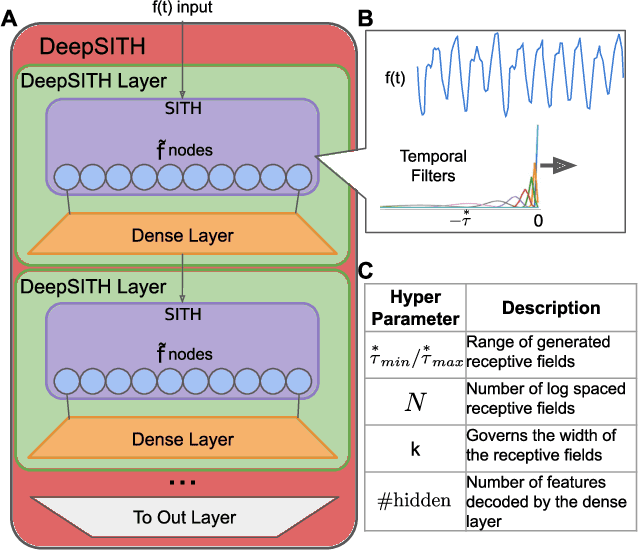

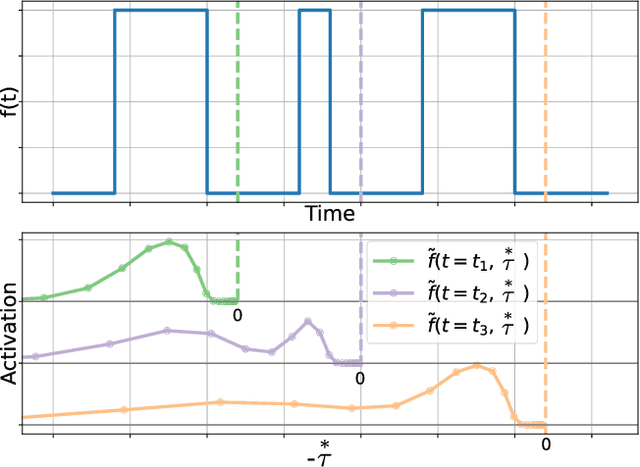

Extracting temporal relationships over a range of scales is a hallmark of human perception and cognition -- and thus it is a critical feature of machine learning applied to real-world problems. Neural networks are either plagued by the exploding/vanishing gradient problem in recurrent neural networks (RNNs) or must adjust their parameters to learn the relevant time scales (e.g., in LSTMs). This paper introduces DeepSITH, a network comprising biologically-inspired Scale-Invariant Temporal History (SITH) modules in series with dense connections between layers. SITH modules respond to their inputs with a geometrically-spaced set of time constants, enabling the DeepSITH network to learn problems along a continuum of time-scales. We compare DeepSITH to LSTMs and other recent RNNs on several time series prediction and decoding tasks. DeepSITH achieves state-of-the-art performance on these problems.
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
Apr 01, 2021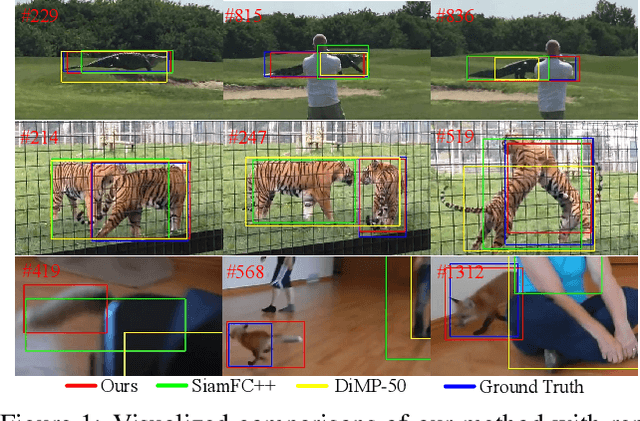
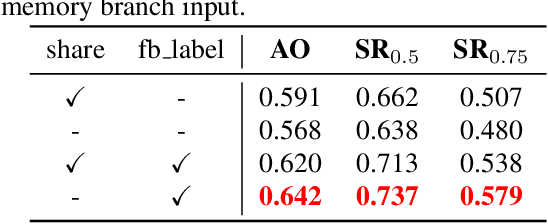
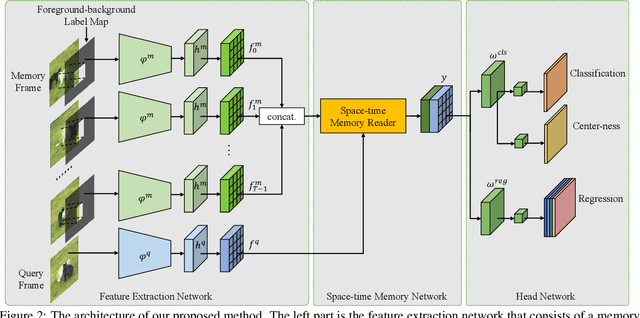

Boosting performance of the offline trained siamese trackers is getting harder nowadays since the fixed information of the template cropped from the first frame has been almost thoroughly mined, but they are poorly capable of resisting target appearance changes. Existing trackers with template updating mechanisms rely on time-consuming numerical optimization and complex hand-designed strategies to achieve competitive performance, hindering them from real-time tracking and practical applications. In this paper, we propose a novel tracking framework built on top of a space-time memory network that is competent to make full use of historical information related to the target for better adapting to appearance variations during tracking. Specifically, a novel memory mechanism is introduced, which stores the historical information of the target to guide the tracker to focus on the most informative regions in the current frame. Furthermore, the pixel-level similarity computation of the memory network enables our tracker to generate much more accurate bounding boxes of the target. Extensive experiments and comparisons with many competitive trackers on challenging large-scale benchmarks, OTB-2015, TrackingNet, GOT-10k, LaSOT, UAV123, and VOT2018, show that, without bells and whistles, our tracker outperforms all previous state-of-the-art real-time methods while running at 37 FPS. The code is available at https://github.com/fzh0917/STMTrack.
GAN for time series prediction, data assimilation and uncertainty quantification
May 28, 2021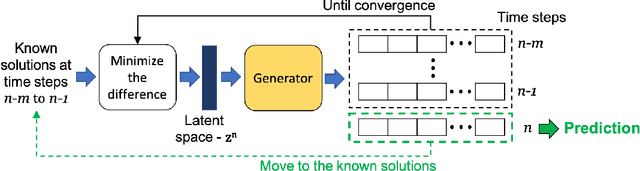

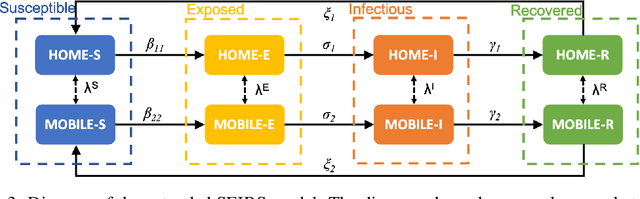
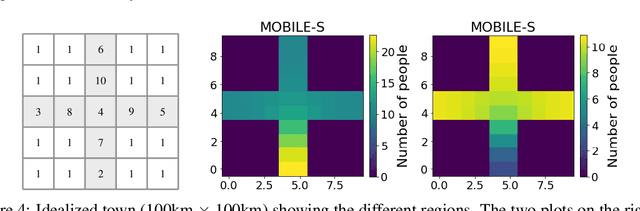
We propose a new method in which a generative adversarial network (GAN) is used to quantify the uncertainty of forward simulations in the presence of observed data. Previously, a method has been developed which enables GANs to make time series predictions and data assimilation by training a GAN with unconditional simulations of a high-fidelity numerical model. After training, the GAN can be used to predict the evolution of the spatial distribution of the simulation states and observed data is assimilated. In this paper, we describe the process required in order to quantify uncertainty, during which no additional simulations of the high-fidelity numerical model are required. These methods take advantage of the adjoint-like capabilities of generative models and the ability to simulate forwards and backwards in time. Set within a reduced-order model framework for efficiency, we apply these methods to a compartmental model in epidemiology to predict the spread of COVID-19 in an idealised town. The results show that the proposed method can efficiently quantify uncertainty in the presence of measurements using only unconditional simulations of the high-fidelity numerical model.
Xavier-Enabled Extreme Reservoir Machine for Millimeter-Wave Beamspace Channel Tracking
Jun 01, 2022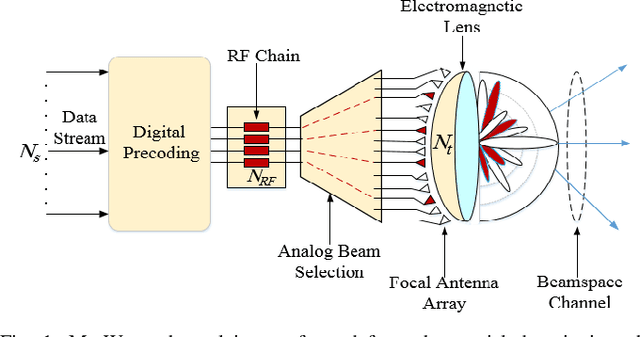
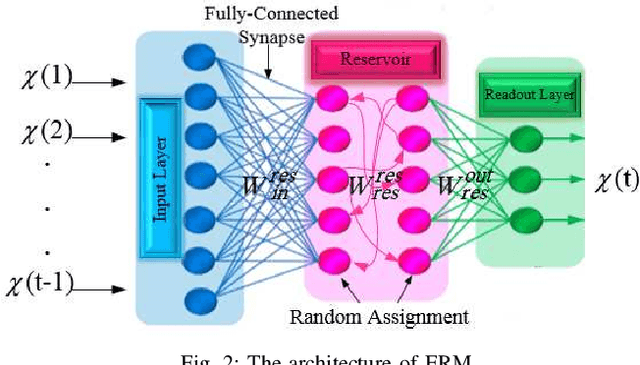
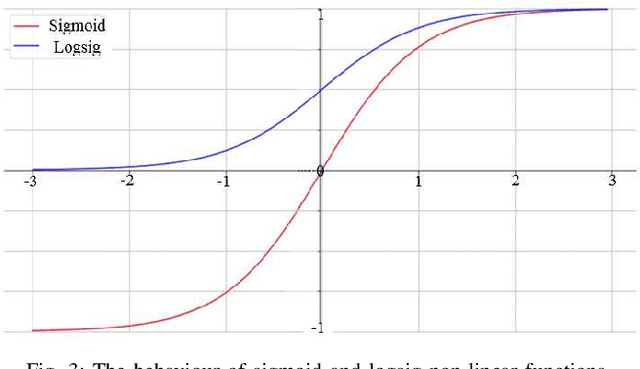
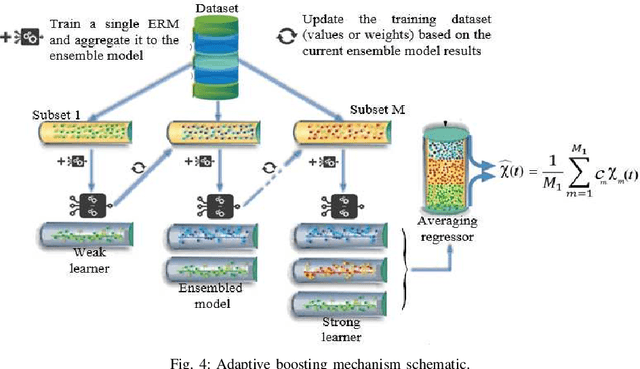
In this paper, we propose an accurate two-phase millimeter-Wave (mmWave) beamspace channel tracking mechanism. Particularly in the first phase, we train an extreme reservoir machine (ERM) for tracking the historical features of the mmWave beamspace channel and predicting them in upcoming time steps. Towards a more accurate prediction, we further fine-tune the ERM by means of Xavier initializer technique, whereby the input weights in ERM are initially derived from a zero mean and finite variance Gaussian distribution, leading to 49% degradation in prediction variance of the conventional ERM. The proposed method numerically improves the achievable spectral efficiency (SE) of the existing counterparts, by 13%, when signal-to-noise-ratio (SNR) is 15dB. We further investigate an ensemble learning technique in the second phase by sequentially incorporating multiple ERMs to form an ensembled model, namely adaptive boosting (AdaBoost), which further reduces the prediction variance in conventional ERM by 56%, and concludes in 21% enhancement of achievable SE upon the existing schemes at SNR=15dB.
An Automatic and Efficient BERT Pruning for Edge AI Systems
Jun 21, 2022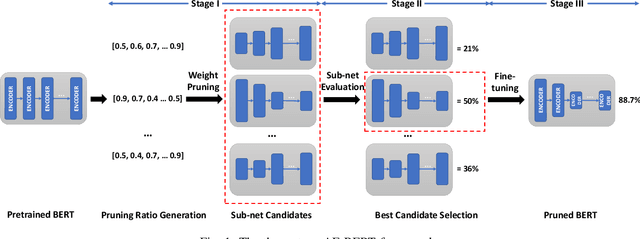
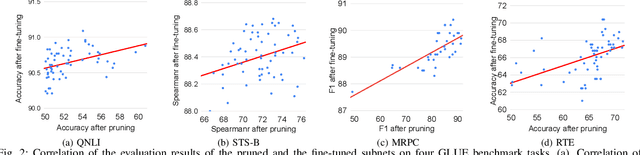
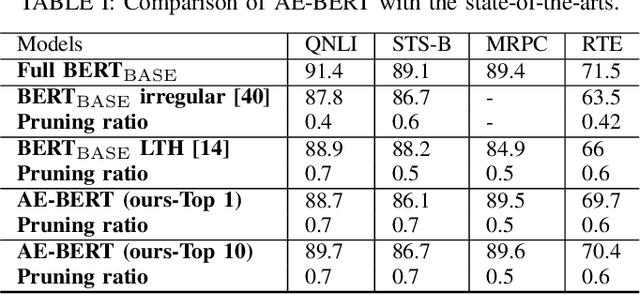
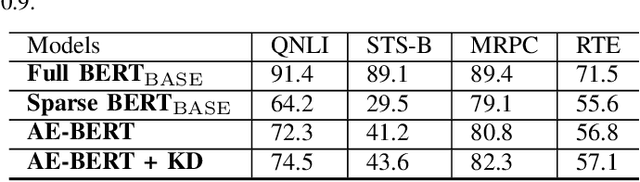
With the yearning for deep learning democratization, there are increasing demands to implement Transformer-based natural language processing (NLP) models on resource-constrained devices for low-latency and high accuracy. Existing BERT pruning methods require domain experts to heuristically handcraft hyperparameters to strike a balance among model size, latency, and accuracy. In this work, we propose AE-BERT, an automatic and efficient BERT pruning framework with efficient evaluation to select a "good" sub-network candidate (with high accuracy) given the overall pruning ratio constraints. Our proposed method requires no human experts experience and achieves a better accuracy performance on many NLP tasks. Our experimental results on General Language Understanding Evaluation (GLUE) benchmark show that AE-BERT outperforms the state-of-the-art (SOTA) hand-crafted pruning methods on BERT$_{\mathrm{BASE}}$. On QNLI and RTE, we obtain 75\% and 42.8\% more overall pruning ratio while achieving higher accuracy. On MRPC, we obtain a 4.6 higher score than the SOTA at the same overall pruning ratio of 0.5. On STS-B, we can achieve a 40\% higher pruning ratio with a very small loss in Spearman correlation compared to SOTA hand-crafted pruning methods. Experimental results also show that after model compression, the inference time of a single BERT$_{\mathrm{BASE}}$ encoder on Xilinx Alveo U200 FPGA board has a 1.83$\times$ speedup compared to Intel(R) Xeon(R) Gold 5218 (2.30GHz) CPU, which shows the reasonableness of deploying the proposed method generated subnets of BERT$_{\mathrm{BASE}}$ model on computation restricted devices.