 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Regularization-wise double descent: Why it occurs and how to eliminate it
Jun 03, 2022
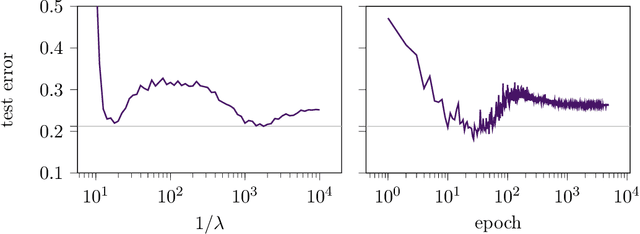
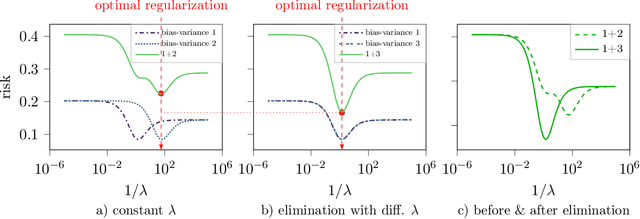
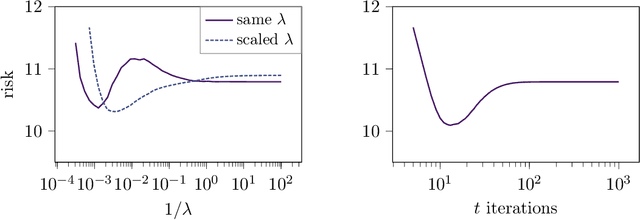
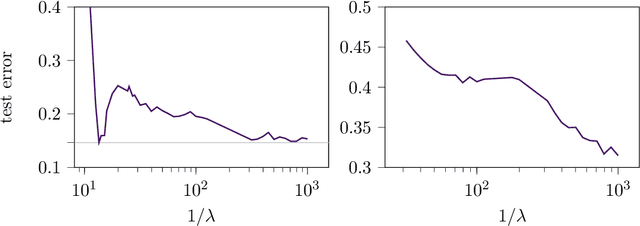
The risk of overparameterized models, in particular deep neural networks, is often double-descent shaped as a function of the model size. Recently, it was shown that the risk as a function of the early-stopping time can also be double-descent shaped, and this behavior can be explained as a super-position of bias-variance tradeoffs. In this paper, we show that the risk of explicit L2-regularized models can exhibit double descent behavior as a function of the regularization strength, both in theory and practice. We find that for linear regression, a double descent shaped risk is caused by a superposition of bias-variance tradeoffs corresponding to different parts of the model and can be mitigated by scaling the regularization strength of each part appropriately. Motivated by this result, we study a two-layer neural network and show that double descent can be eliminated by adjusting the regularization strengths for the first and second layer. Lastly, we study a 5-layer CNN and ResNet-18 trained on CIFAR-10 with label noise, and CIFAR-100 without label noise, and demonstrate that all exhibit double descent behavior as a function of the regularization strength.
Linear Algorithms for Nonparametric Multiclass Probability Estimation
Jun 03, 2022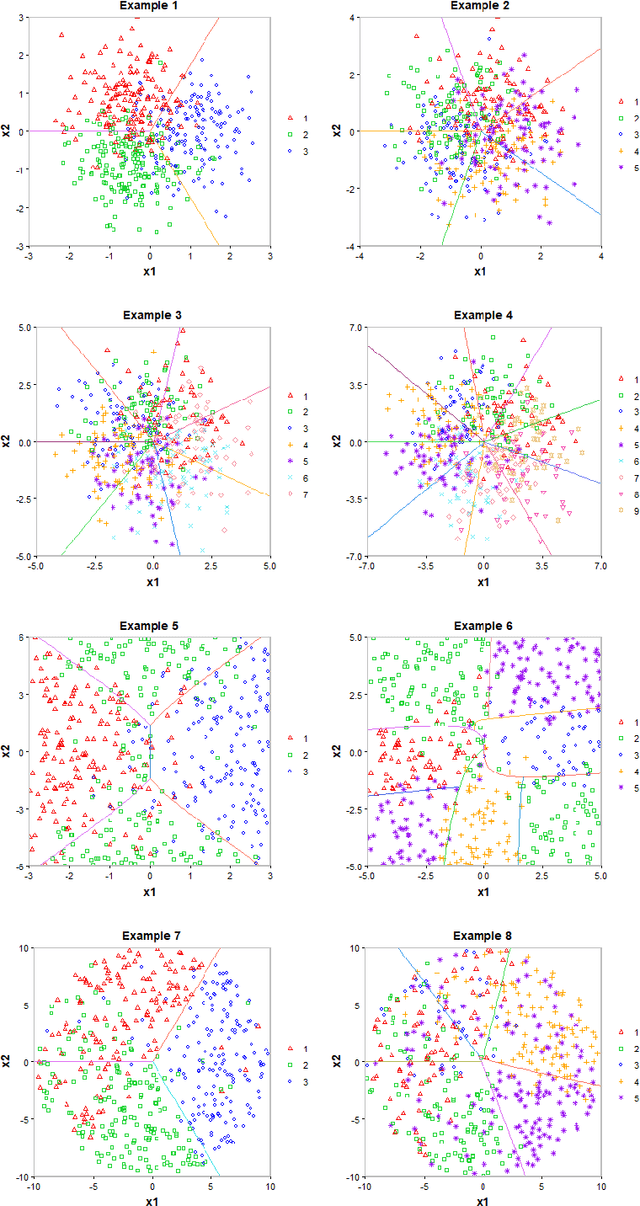
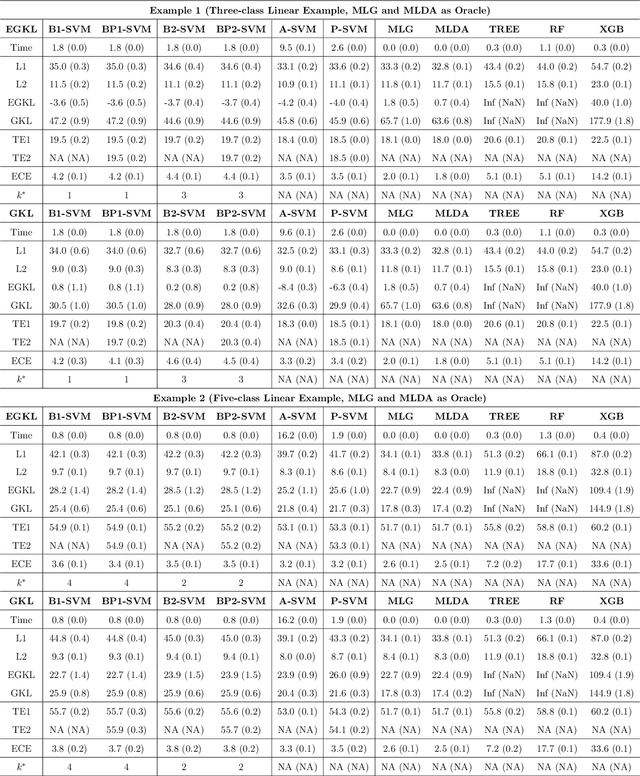
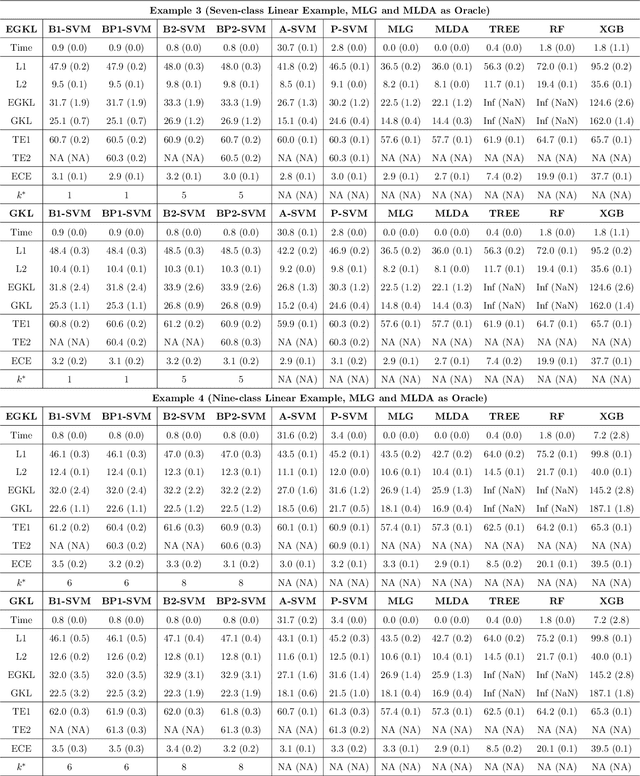
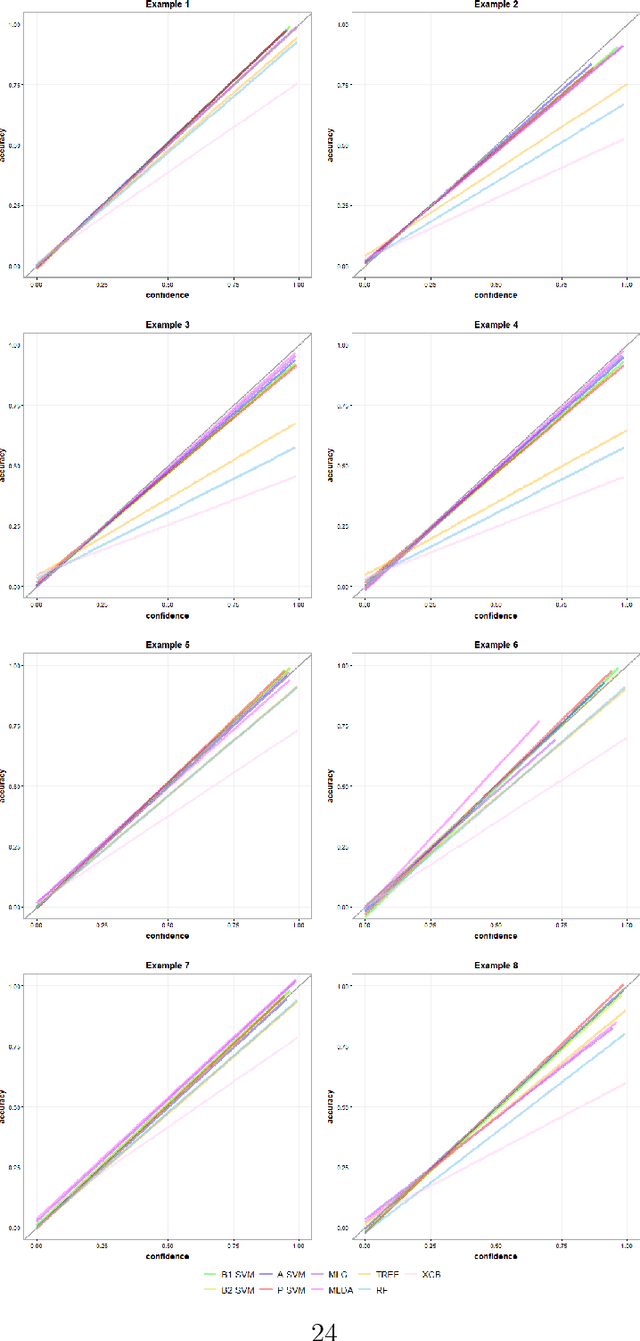
Multiclass probability estimation is the problem of estimating conditional probabilities of a data point belonging to a class given its covariate information. It has broad applications in statistical analysis and data science. Recently a class of weighted Support Vector Machines (wSVMs) has been developed to estimate class probabilities through ensemble learning for $K$-class problems (Wu, Zhang and Liu, 2010; Wang, Zhang and Wu, 2019), where $K$ is the number of classes. The estimators are robust and achieve high accuracy for probability estimation, but their learning is implemented through pairwise coupling, which demands polynomial time in $K$. In this paper, we propose two new learning schemes, the baseline learning and the One-vs-All (OVA) learning, to further improve wSVMs in terms of computational efficiency and estimation accuracy. In particular, the baseline learning has optimal computational complexity in the sense that it is linear in $K$. Though not being most efficient in computation, the OVA offers the best estimation accuracy among all the procedures under comparison. The resulting estimators are distribution-free and shown to be consistent. We further conduct extensive numerical experiments to demonstrate finite sample performance.
Identifying Cause-and-Effect Relationships of Manufacturing Errors using Sequence-to-Sequence Learning
May 05, 2022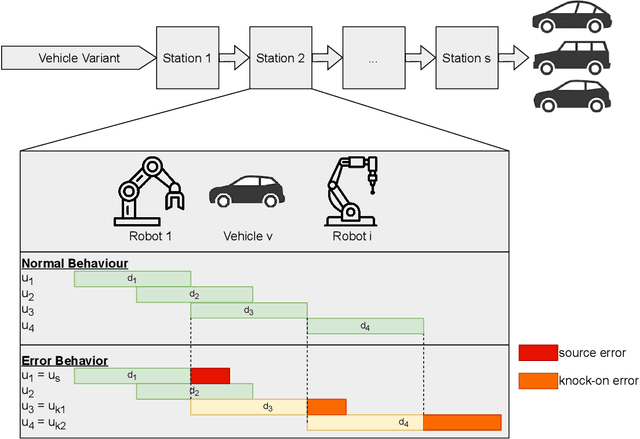
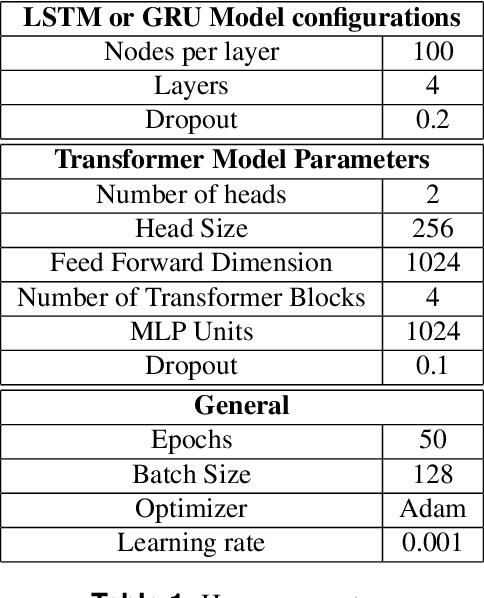
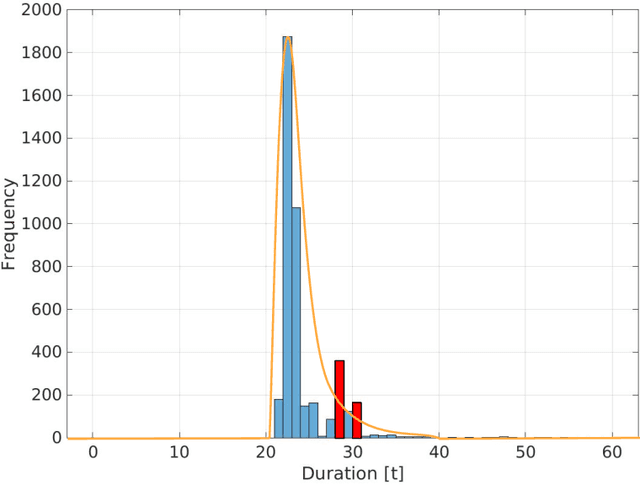
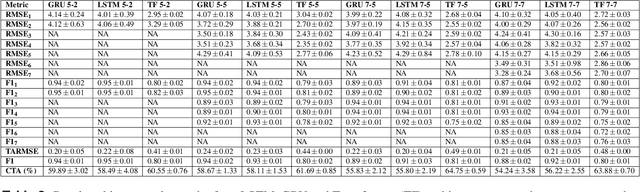
In car-body production the pre-formed sheet metal parts of the body are assembled on fully-automated production lines. The body passes through multiple stations in succession, and is processed according to the order requirements. The timely completion of orders depends on the individual station-based operations concluding within their scheduled cycle times. If an error occurs in one station, it can have a knock-on effect, resulting in delays on the downstream stations. To the best of our knowledge, there exist no methods for automatically distinguishing between source and knock-on errors in this setting, as well as establishing a causal relation between them. Utilizing real-time information about conditions collected by a production data acquisition system, we propose a novel vehicle manufacturing analysis system, which uses deep learning to establish a link between source and knock-on errors. We benchmark three sequence-to-sequence models, and introduce a novel composite time-weighted action metric for evaluating models in this context. We evaluate our framework on a real-world car production dataset recorded by Volkswagen Commercial Vehicles. Surprisingly we find that 71.68% of sequences contain either a source or knock-on error. With respect to seq2seq model training, we find that the Transformer demonstrates a better performance compared to LSTM and GRU in this domain, in particular when the prediction range with respect to the durations of future actions is increased.
Unsupervised Difference Learning for Noisy Rigid Image Alignment
May 24, 2022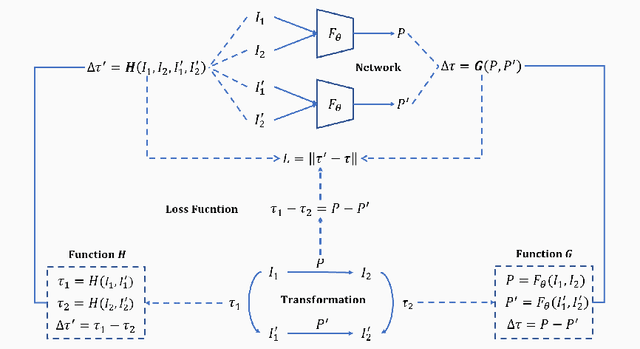
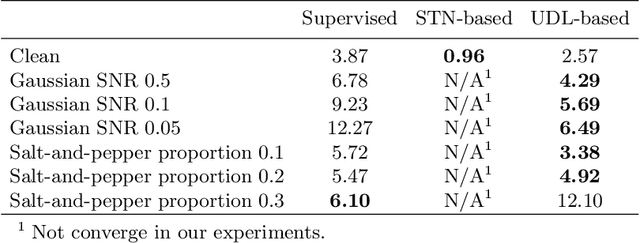
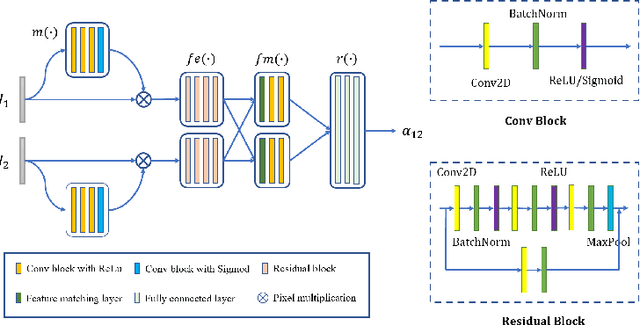

Rigid image alignment is a fundamental task in computer vision, while the traditional algorithms are either too sensitive to noise or time-consuming. Recent unsupervised image alignment methods developed based on spatial transformer networks show an improved performance on clean images but will not achieve satisfactory performance on noisy images due to its heavy reliance on pixel value comparations. To handle such challenging applications, we report a new unsupervised difference learning (UDL) strategy and apply it to rigid image alignment. UDL exploits the quantitative properties of regression tasks and converts the original unsupervised problem to pseudo supervised problem. Under the new UDL-based image alignment pipeline, rotation can be accurately estimated on both clean and noisy images and translations can then be easily solved. Experimental results on both nature and cryo-EM images demonstrate the efficacy of our UDL-based unsupervised rigid image alignment method.
An advanced spatio-temporal convolutional recurrent neural network for storm surge predictions
Apr 18, 2022
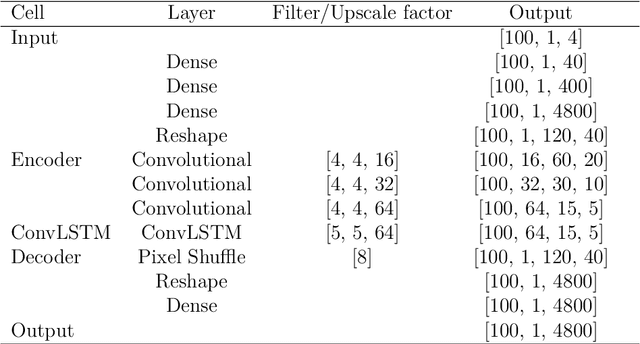
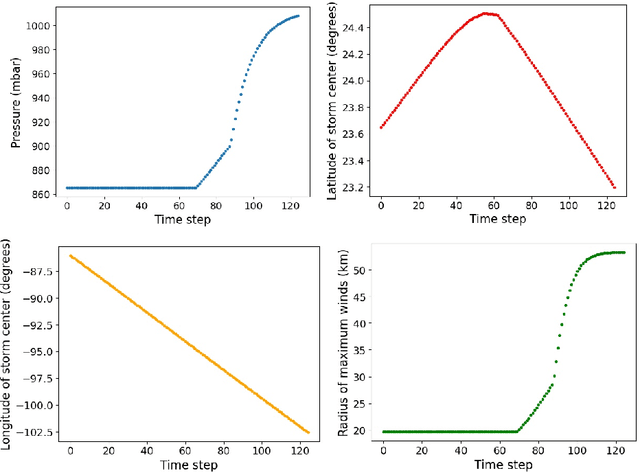

In this research paper, we study the capability of artificial neural network models to emulate storm surge based on the storm track/size/intensity history, leveraging a database of synthetic storm simulations. Traditionally, Computational Fluid Dynamics solvers are employed to numerically solve the storm surge governing equations that are Partial Differential Equations and are generally very costly to simulate. This study presents a neural network model that can predict storm surge, informed by a database of synthetic storm simulations. This model can serve as a fast and affordable emulator for the very expensive CFD solvers. The neural network model is trained with the storm track parameters used to drive the CFD solvers, and the output of the model is the time-series evolution of the predicted storm surge across multiple nodes within the spatial domain of interest. Once the model is trained, it can be deployed for further predictions based on new storm track inputs. The developed neural network model is a time-series model, a Long short-term memory, a variation of Recurrent Neural Network, which is enriched with Convolutional Neural Networks. The convolutional neural network is employed to capture the correlation of data spatially. Therefore, the temporal and spatial correlations of data are captured by the combination of the mentioned models, the ConvLSTM model. As the problem is a sequence to sequence time-series problem, an encoder-decoder ConvLSTM model is designed. Some other techniques in the process of model training are also employed to enrich the model performance. The results show the proposed convolutional recurrent neural network outperforms the Gaussian Process implementation for the examined synthetic storm database.
Investigation of Optimization Techniques on the Elevator Dispatching Problem
Feb 26, 2022
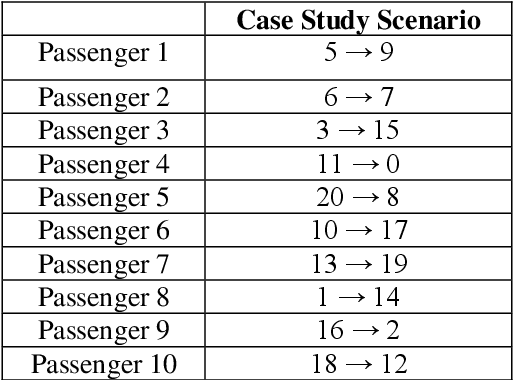
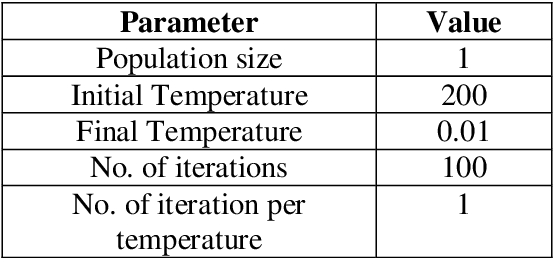

In the elevator industry, reducing passenger journey time in an elevator system is a major aim. The key obstacle to optimising elevator dispatching is the unpredictable traffic flow of passengers. To address this difficulty, two main features must be optimised: waiting time and journey time. To address the problem in real time, several strategies are employed, including Simulated Annealing (SA), Genetic Algorithm (GA), Particle Swarm Optimization Algorithm (PSO), and Whale Optimization Algorithm (WOA). This research article compares the algorithms discussed above. To investigate the functioning of the algorithms for visualisation and insight, a case study was created. In order to discover the optimum algorithm for the elevator dispatching problem, performance indices such as average and ideal fitness value are generated in 5 runs to compare the outcomes of the methods. The goal of this study is to compute a dispatching scheme, which is the result of the algorithms, in order to lower the average trip time for all passengers. This study builds on previous studies that recommended ways to reduce waiting time. The proposed technique reduces average wait time, improves lift efficiency, and improves customer experience.
Automated Crossword Solving
May 19, 2022
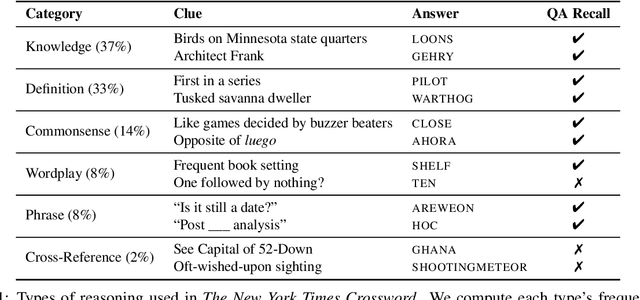
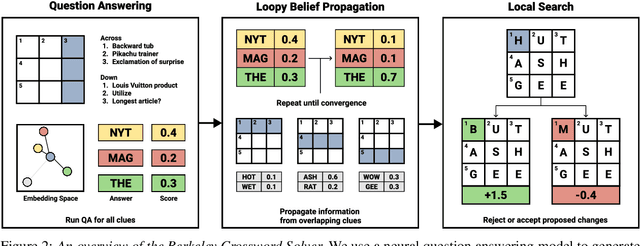
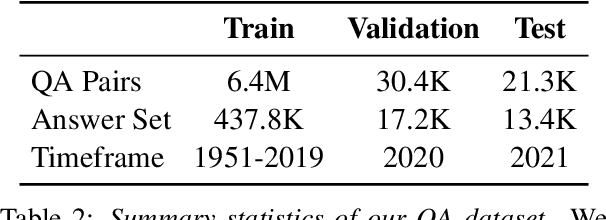
We present the Berkeley Crossword Solver, a state-of-the-art approach for automatically solving crossword puzzles. Our system works by generating answer candidates for each crossword clue using neural question answering models and then combines loopy belief propagation with local search to find full puzzle solutions. Compared to existing approaches, our system improves exact puzzle accuracy from 57% to 82% on crosswords from The New York Times and obtains 99.9% letter accuracy on themeless puzzles. Our system also won first place at the top human crossword tournament, which marks the first time that a computer program has surpassed human performance at this event. To facilitate research on question answering and crossword solving, we analyze our system's remaining errors and release a dataset of over six million question-answer pairs.
Image-Based Conditioning for Action Policy Smoothness in Autonomous Miniature Car Racing with Reinforcement Learning
May 19, 2022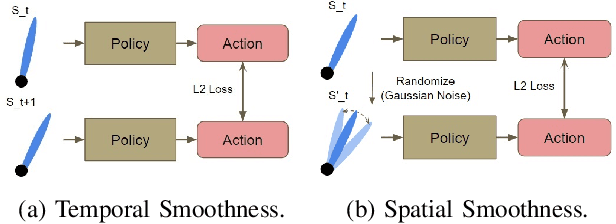


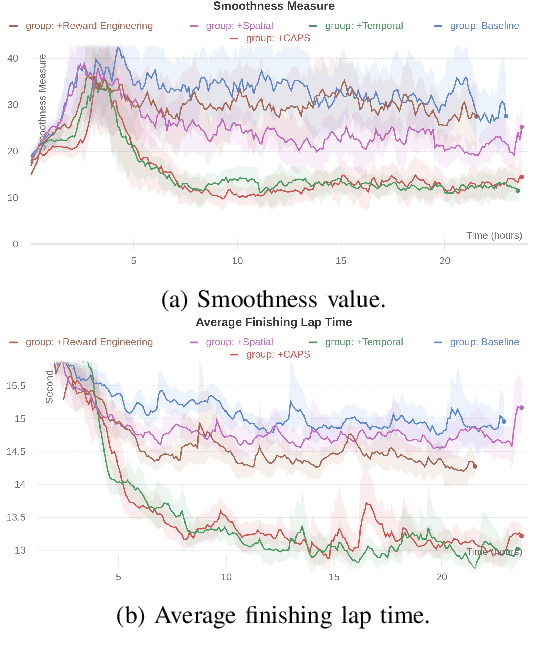
In recent years, deep reinforcement learning has achieved significant results in low-level controlling tasks. However, the problem of control smoothness has less attention. In autonomous driving, unstable control is inevitable since the vehicle might suddenly change its actions. This problem will lower the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. In this paper, we apply the Conditioning for Action Policy Smoothness (CAPS) with image-based input to smooth the control of an autonomous miniature car racing. Applying CAPS and sim-to-real transfer methods helps to stabilize the control at a higher speed. Especially, the agent with CAPS and CycleGAN reduces 21.80% of the average finishing lap time. Moreover, we also conduct extensive experiments to analyze the impact of CAPS components.
Efficient Scheduling of Data Augmentation for Deep Reinforcement Learning
Jun 03, 2022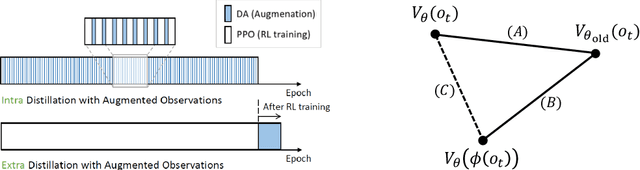
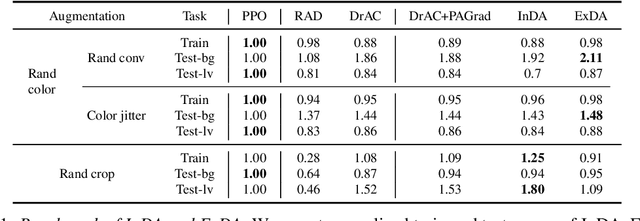
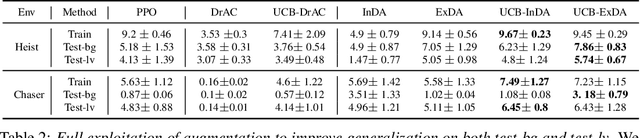
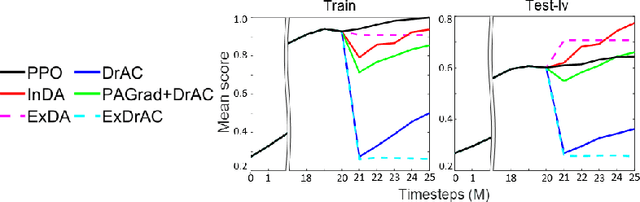
In deep reinforcement learning (RL), data augmentation is widely considered as a tool to induce a set of useful priors about semantic consistency and improve sample efficiency and generalization performance. However, even when the prior is useful for generalization, distilling it to RL agent often interferes with RL training and degenerates sample efficiency. Meanwhile, the agent is forgetful of the prior due to the non-stationary nature of RL. These observations suggest two extreme schedules of distillation: (i) over the entire training; or (ii) only at the end. Hence, we devise a stand-alone network distillation method to inject the consistency prior at any time (even after RL), and a simple yet efficient framework to automatically schedule the distillation. Specifically, the proposed framework first focuses on mastering train environments regardless of generalization by adaptively deciding which {\it or no} augmentation to be used for the training. After this, we add the distillation to extract the remaining benefits for generalization from all the augmentations, which requires no additional new samples. In our experiments, we demonstrate the utility of the proposed framework, in particular, that considers postponing the augmentation to the end of RL training.
Optimal Sublinear Sampling of Spanning Trees and Determinantal Point Processes via Average-Case Entropic Independence
Apr 06, 2022We design fast algorithms for repeatedly sampling from strongly Rayleigh distributions, which include random spanning tree distributions and determinantal point processes. For a graph $G=(V, E)$, we show how to approximately sample uniformly random spanning trees from $G$ in $\widetilde{O}(\lvert V\rvert)$ time per sample after an initial $\widetilde{O}(\lvert E\rvert)$ time preprocessing. For a determinantal point process on subsets of size $k$ of a ground set of $n$ elements, we show how to approximately sample in $\widetilde{O}(k^\omega)$ time after an initial $\widetilde{O}(nk^{\omega-1})$ time preprocessing, where $\omega<2.372864$ is the matrix multiplication exponent. We even improve the state of the art for obtaining a single sample from determinantal point processes, from the prior runtime of $\widetilde{O}(\min\{nk^2, n^\omega\})$ to $\widetilde{O}(nk^{\omega-1})$. In our main technical result, we achieve the optimal limit on domain sparsification for strongly Rayleigh distributions. In domain sparsification, sampling from a distribution $\mu$ on $\binom{[n]}{k}$ is reduced to sampling from related distributions on $\binom{[t]}{k}$ for $t\ll n$. We show that for strongly Rayleigh distributions, we can can achieve the optimal $t=\widetilde{O}(k)$. Our reduction involves sampling from $\widetilde{O}(1)$ domain-sparsified distributions, all of which can be produced efficiently assuming convenient access to approximate overestimates for marginals of $\mu$. Having access to marginals is analogous to having access to the mean and covariance of a continuous distribution, or knowing "isotropy" for the distribution, the key assumption behind the Kannan-Lov\'asz-Simonovits (KLS) conjecture and optimal samplers based on it. We view our result as a moral analog of the KLS conjecture and its consequences for sampling, for discrete strongly Rayleigh measures.