 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prediction of Landfall Intensity, Location, and Time of a Tropical Cyclone
Mar 30, 2021
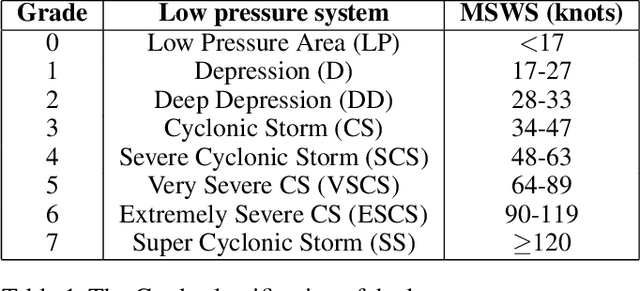
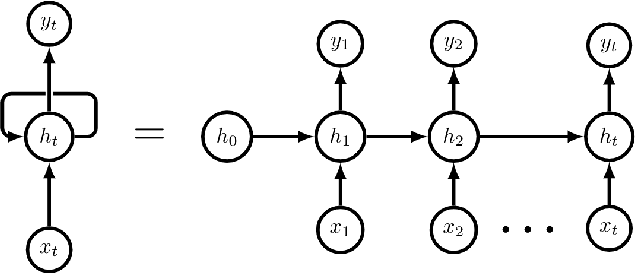
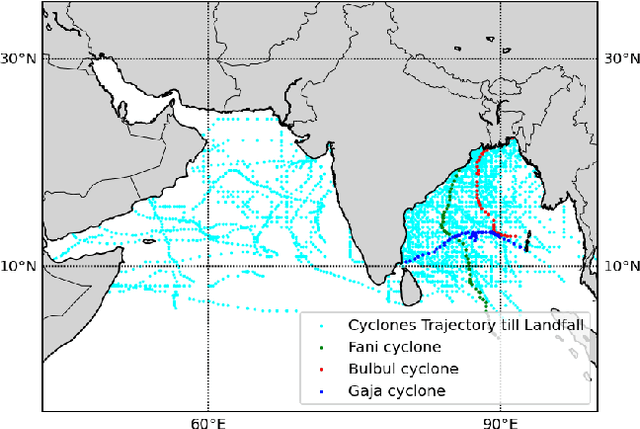
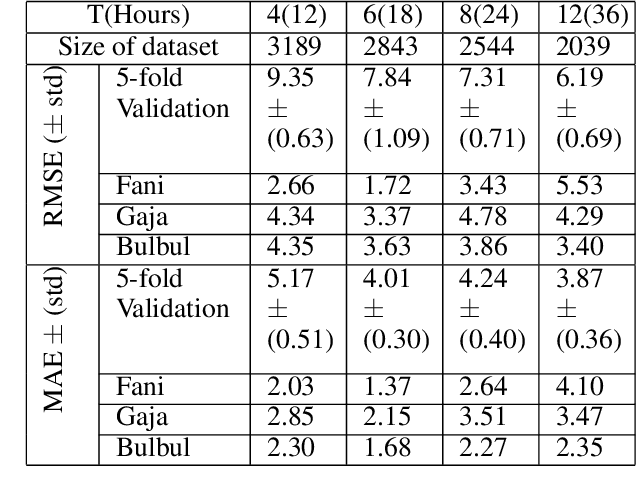
The prediction of the intensity, location and time of the landfall of a tropical cyclone well advance in time and with high accuracy can reduce human and material loss immensely. In this article, we develop a Long Short-Term memory based Recurrent Neural network model to predict intensity (in terms of maximum sustained surface wind speed), location (latitude and longitude), and time (in hours after the observation period) of the landfall of a tropical cyclone which originates in the North Indian ocean. The model takes as input the best track data of cyclone consisting of its location, pressure, sea surface temperature, and intensity for certain hours (from 12 to 36 hours) anytime during the course of the cyclone as a time series and then provide predictions with high accuracy. For example, using 24 hours data of a cyclone anytime during its course, the model provides state-of-the-art results by predicting landfall intensity, time, latitude, and longitude with a mean absolute error of 4.24 knots, 4.5 hours, 0.24 degree, and 0.37 degree respectively, which resulted in a distance error of 51.7 kilometers from the landfall location. We further check the efficacy of the model on three recent devastating cyclones Bulbul, Fani, and Gaja, and achieved better results than the test dataset.
Omnivision forecasting: combining satellite observations with sky images for improved intra-hour solar energy predictions
Jun 07, 2022



Integration of intermittent renewable energy sources into electric grids in large proportions is challenging. A well-established approach aimed at addressing this difficulty involves the anticipation of the upcoming energy supply variability to adapt the response of the grid. In solar energy, short-term changes in electricity production caused by occluding clouds can be predicted at different time scales from all-sky cameras (up to 30-min ahead) and satellite observations (up to 6h ahead). In this study, we integrate these two complementary points of view on the cloud cover in a single machine learning framework to improve intra-hour (up to 60-min ahead) irradiance forecasting. Both deterministic and probabilistic predictions are evaluated in different weather conditions (clear-sky, cloudy, overcast) and with different input configurations (sky images, satellite observations and/or past irradiance values). Our results show that the hybrid model benefits predictions in clear-sky conditions and improves longer-term forecasting. This study lays the groundwork for future novel approaches of combining sky images and satellite observations in a single learning framework to advance solar nowcasting.
A Survey on Surrogate-assisted Efficient Neural Architecture Search
Jun 03, 2022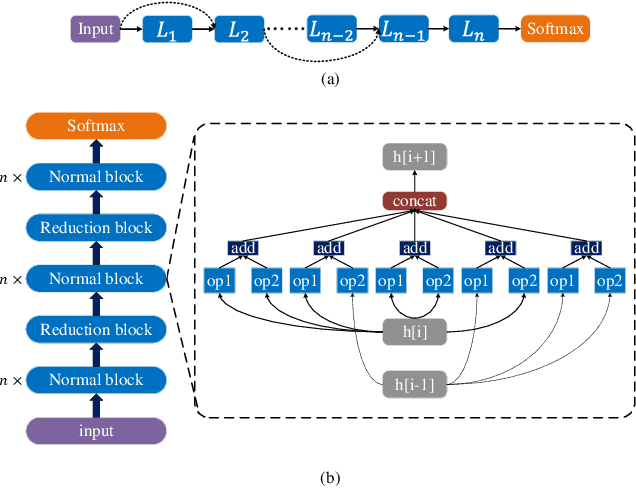
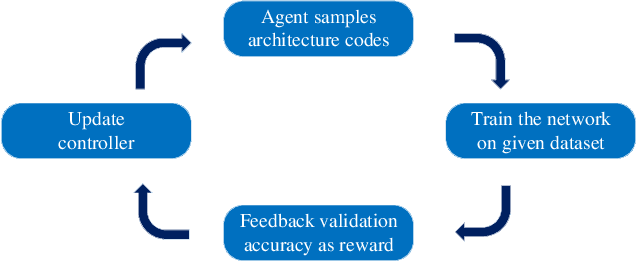
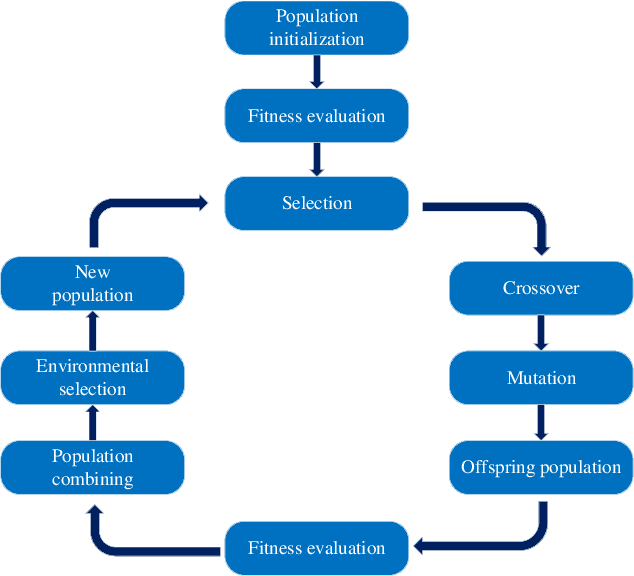
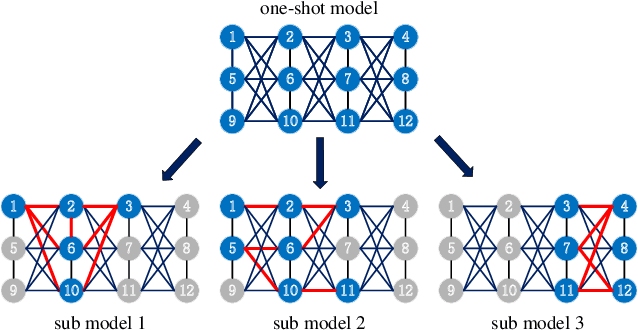
Neural architecture search (NAS) has become increasingly popular in the deep learning community recently, mainly because it can provide an opportunity to allow interested users without rich expertise to benefit from the success of deep neural networks (DNNs). However, NAS is still laborious and time-consuming because a large number of performance estimations are required during the search process of NAS, and training DNNs is computationally intensive. To solve the major limitation of NAS, improving the efficiency of NAS is essential in the design of NAS. This paper begins with a brief introduction to the general framework of NAS. Then, the methods for evaluating network candidates under the proxy metrics are systematically discussed. This is followed by a description of surrogate-assisted NAS, which is divided into three different categories, namely Bayesian optimization for NAS, surrogate-assisted evolutionary algorithms for NAS, and MOP for NAS. Finally, remaining challenges and open research questions are discussed, and promising research topics are suggested in this emerging field.
Can Hybrid Geometric Scattering Networks Help Solve the Maximal Clique Problem?
Jun 03, 2022
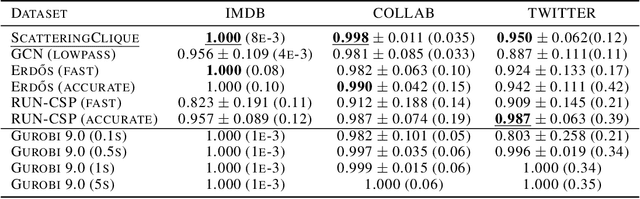

We propose a geometric scattering-based graph neural network (GNN) for approximating solutions of the NP-hard maximal clique (MC) problem. We construct a loss function with two terms, one which encourages the network to find a large set of nodes and the other which acts as a surrogate for the constraint that the nodes form a clique. We then use this loss to train a novel GNN architecture that outputs a vector representing the probability for each node to be part of the MC and apply a rule-based decoder to make our final prediction. The incorporation of the scattering transform alleviates the so-called oversmoothing problem that is often encountered in GNNs and would degrade the performance of our proposed setup. Our empirical results demonstrate that our method outperforms representative GNN baselines in terms of solution accuracy and inference speed as well as conventional solvers like GUROBI with limited time budgets.
CTooth: A Fully Annotated 3D Dataset and Benchmark for Tooth Volume Segmentation on Cone Beam Computed Tomography Images
Jun 17, 2022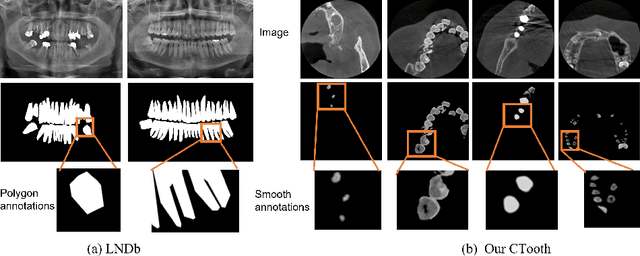
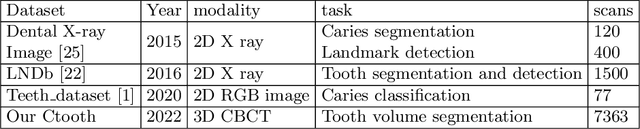
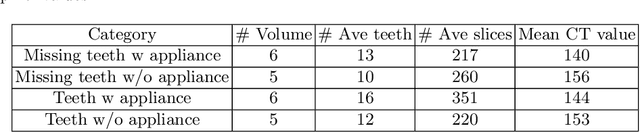
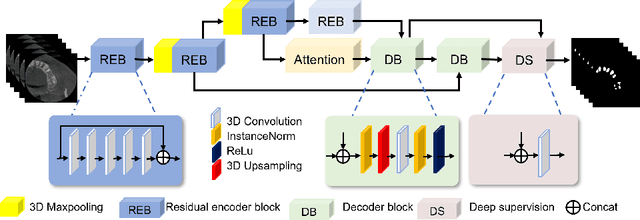
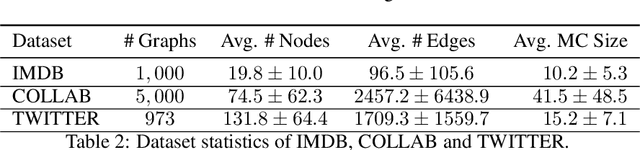
3D tooth segmentation is a prerequisite for computer-aided dental diagnosis and treatment. However, segmenting all tooth regions manually is subjective and time-consuming. Recently, deep learning-based segmentation methods produce convincing results and reduce manual annotation efforts, but it requires a large quantity of ground truth for training. To our knowledge, there are few tooth data available for the 3D segmentation study. In this paper, we establish a fully annotated cone beam computed tomography dataset CTooth with tooth gold standard. This dataset contains 22 volumes (7363 slices) with fine tooth labels annotated by experienced radiographic interpreters. To ensure a relative even data sampling distribution, data variance is included in the CTooth including missing teeth and dental restoration. Several state-of-the-art segmentation methods are evaluated on this dataset. Afterwards, we further summarise and apply a series of 3D attention-based Unet variants for segmenting tooth volumes. This work provides a new benchmark for the tooth volume segmentation task. Experimental evidence proves that attention modules of the 3D UNet structure boost responses in tooth areas and inhibit the influence of background and noise. The best performance is achieved by 3D Unet with SKNet attention module, of 88.04 \% Dice and 78.71 \% IOU, respectively. The attention-based Unet framework outperforms other state-of-the-art methods on the CTooth dataset. The codebase and dataset are released.
Procedural Content Generation using Neuroevolution and Novelty Search for Diverse Video Game Levels
Apr 14, 2022
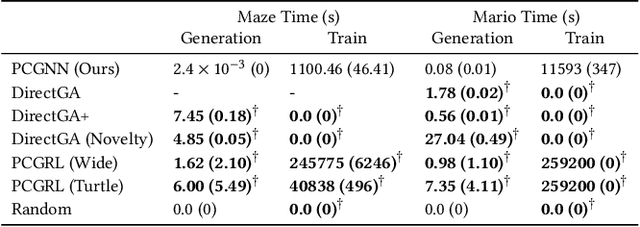
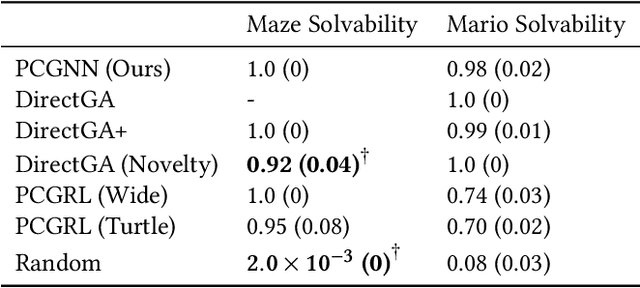
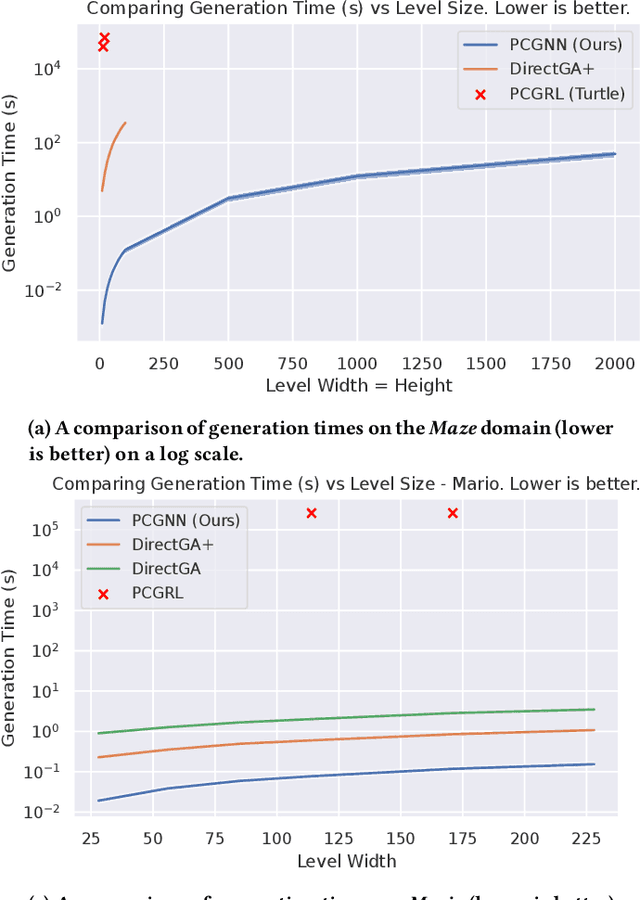
Procedurally generated video game content has the potential to drastically reduce the content creation budget of game developers and large studios. However, adoption is hindered by limitations such as slow generation, as well as low quality and diversity of content. We introduce an evolutionary search-based approach for evolving level generators using novelty search to procedurally generate diverse levels in real time, without requiring training data or detailed domain-specific knowledge. We test our method on two domains, and our results show an order of magnitude speedup in generation time compared to existing methods while obtaining comparable metric scores. We further demonstrate the ability to generalise to arbitrary-sized levels without retraining.
Transformer-based Self-Supervised Fish Segmentation in Underwater Videos
Jun 11, 2022
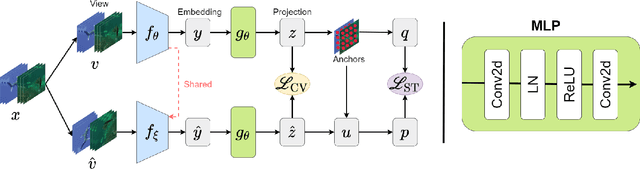
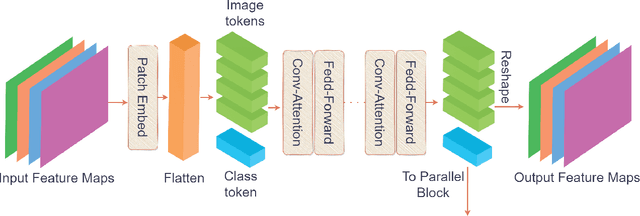
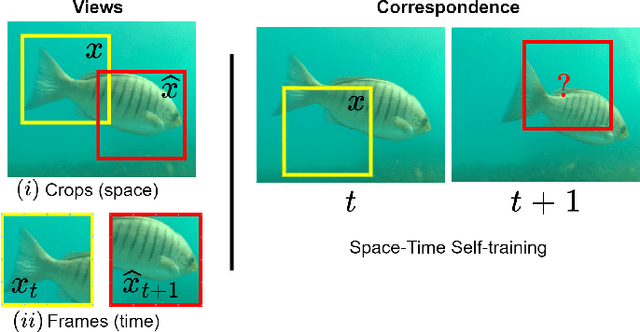
Underwater fish segmentation to estimate fish body measurements is still largely unsolved due to the complex underwater environment. Relying on fully-supervised segmentation models requires collecting per-pixel labels, which is time-consuming and prone to overfitting. Self-supervised learning methods can help avoid the requirement of large annotated training datasets, however, to be useful in real-world applications, they should achieve good segmentation quality. In this paper, we introduce a Transformer-based method that uses self-supervision for high-quality fish segmentation. Our proposed model is trained on videos -- without any annotations -- to perform fish segmentation in underwater videos taken in situ in the wild. We show that when trained on a set of underwater videos from one dataset, the proposed model surpasses previous CNN-based and Transformer-based self-supervised methods and achieves performance relatively close to supervised methods on two new unseen underwater video datasets. This demonstrates the great generalisability of our model and the fact that it does not need a pre-trained model. In addition, we show that, due to its dense representation learning, our model is compute-efficient. We provide quantitative and qualitative results that demonstrate our model's significant capabilities.
Spatial-Temporal Adaptive Graph Convolution with Attention Network for Traffic Forecasting
Jun 07, 2022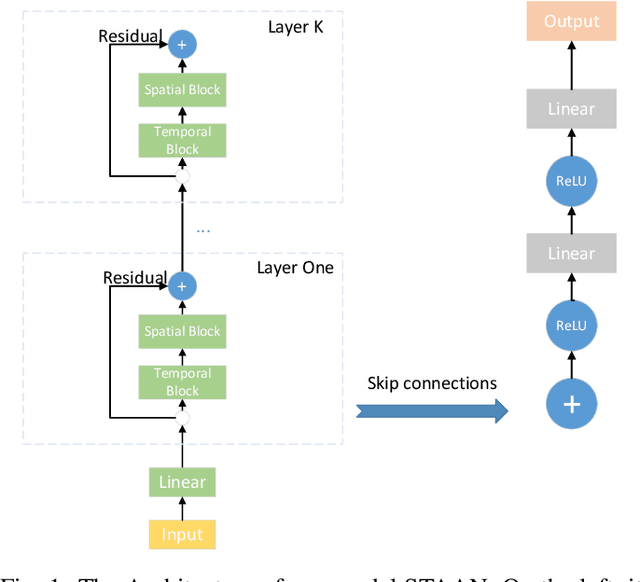
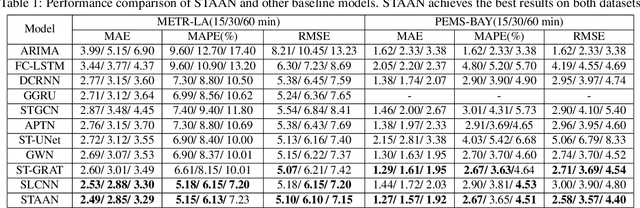
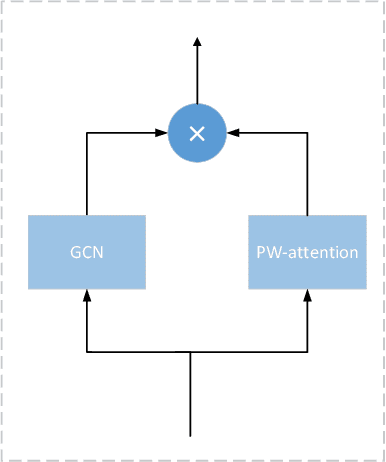
Traffic forecasting is one canonical example of spatial-temporal learning task in Intelligent Traffic System. Existing approaches capture spatial dependency with a pre-determined matrix in graph convolution neural operators. However, the explicit graph structure losses some hidden representations of relationships among nodes. Furthermore, traditional graph convolution neural operators cannot aggregate long-range nodes on the graph. To overcome these limits, we propose a novel network, Spatial-Temporal Adaptive graph convolution with Attention Network (STAAN) for traffic forecasting. Firstly, we adopt an adaptive dependency matrix instead of using a pre-defined matrix during GCN processing to infer the inter-dependencies among nodes. Secondly, we integrate PW-attention based on graph attention network which is designed for global dependency, and GCN as spatial block. What's more, a stacked dilated 1D convolution, with efficiency in long-term prediction, is adopted in our temporal block for capturing the different time series. We evaluate our STAAN on two real-world datasets, and experiments validate that our model outperforms state-of-the-art baselines.
Stein Variational Goal Generation For Reinforcement Learning in Hard Exploration Problems
Jun 14, 2022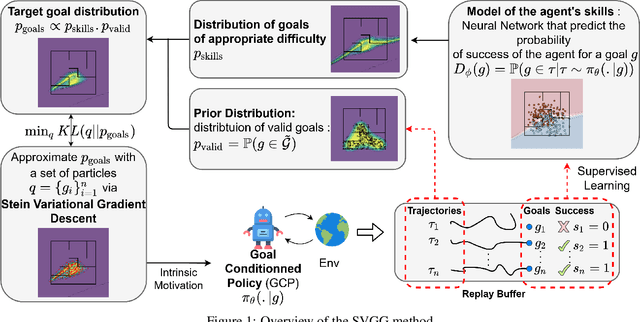
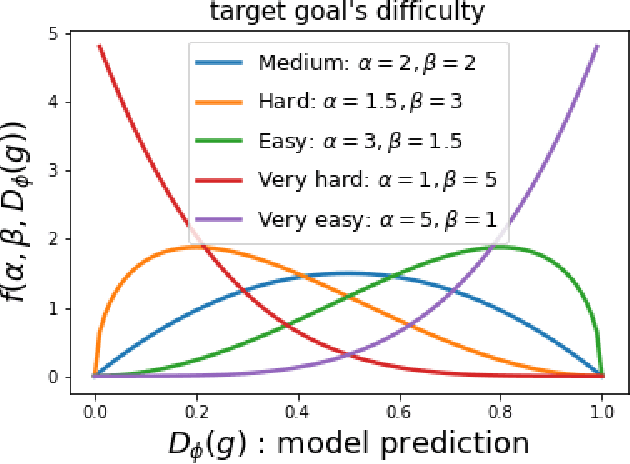
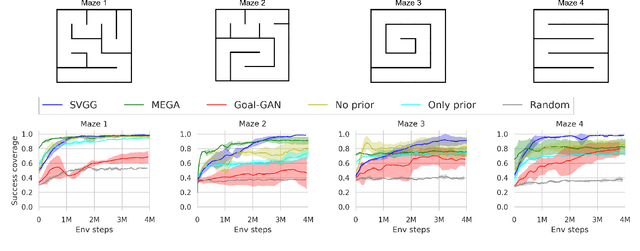
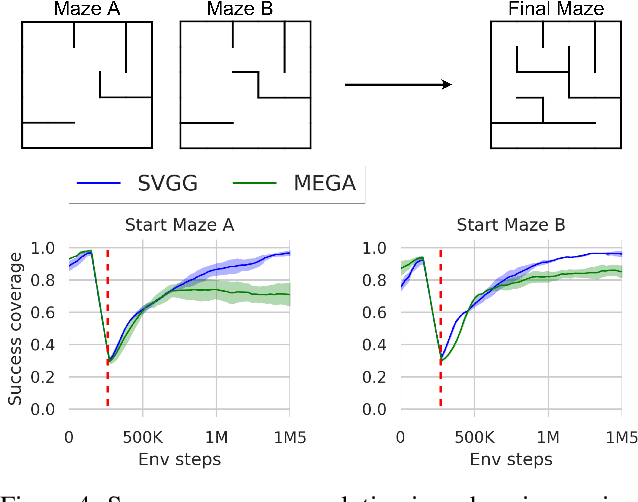
Multi-goal Reinforcement Learning has recently attracted a large amount of research interest. By allowing experience to be shared between related training tasks, this setting favors generalization for new tasks at test time, whenever some smoothness exists in the considered representation space of goals. However, in settings with discontinuities in state or goal spaces (e.g. walls in a maze), a majority of goals are difficult to reach, due to the sparsity of rewards in the absence of expert knowledge. This implies hard exploration, for which some curriculum of goals must be discovered, to help agents learn by adapting training tasks to their current capabilities. Building on recent automatic curriculum learning techniques for goal-conditioned policies, we propose a novel approach: Stein Variational Goal Generation (SVGG), which seeks at preferably sampling new goals in the zone of proximal development of the agent, by leveraging a learned model of its abilities, and a goal distribution modeled as particles in the exploration space. Our approach relies on Stein Variational Gradient Descent to dynamically attract the goal sampling distribution in areas of appropriate difficulty. We demonstrate the performances of the approach, in terms of success coverage in the goal space, compared to recent state-of-the-art RL methods for hard exploration problems.
Sardino: Ultra-Fast Dynamic Ensemble for Secure Visual Sensing at Mobile Edge
Apr 18, 2022
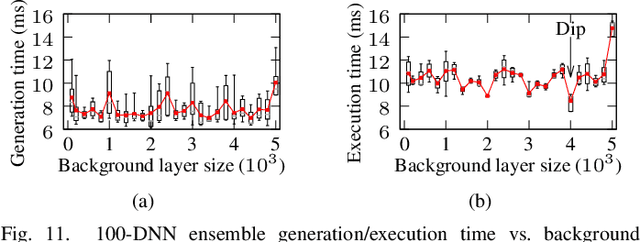
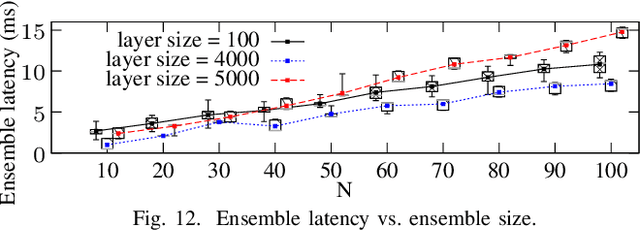
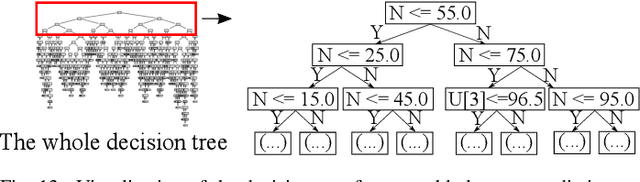
Adversarial example attack endangers the mobile edge systems such as vehicles and drones that adopt deep neural networks for visual sensing. This paper presents {\em Sardino}, an active and dynamic defense approach that renews the inference ensemble at run time to develop security against the adaptive adversary who tries to exfiltrate the ensemble and construct the corresponding effective adversarial examples. By applying consistency check and data fusion on the ensemble's predictions, Sardino can detect and thwart adversarial inputs. Compared with the training-based ensemble renewal, we use HyperNet to achieve {\em one million times} acceleration and per-frame ensemble renewal that presents the highest level of difficulty to the prerequisite exfiltration attacks. Moreover, the robustness of the renewed ensembles against adversarial examples is enhanced with adversarial learning for the HyperNet. We design a run-time planner that maximizes the ensemble size in favor of security while maintaining the processing frame rate. Beyond adversarial examples, Sardino can also address the issue of out-of-distribution inputs effectively. This paper presents extensive evaluation of Sardino's performance in counteracting adversarial examples and applies it to build a real-time car-borne traffic sign recognition system. Live on-road tests show the built system's effectiveness in maintaining frame rate and detecting out-of-distribution inputs due to the false positives of a preceding YOLO-based traffic sign detector.