 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reconstruct from Top View: A 3D Lane Detection Approach based on Geometry Structure Prior
Jun 21, 2022
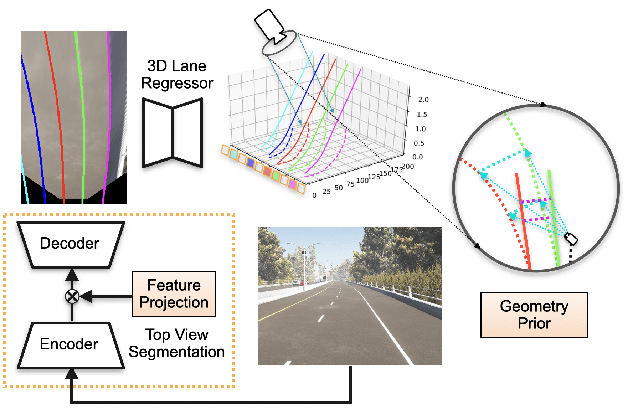
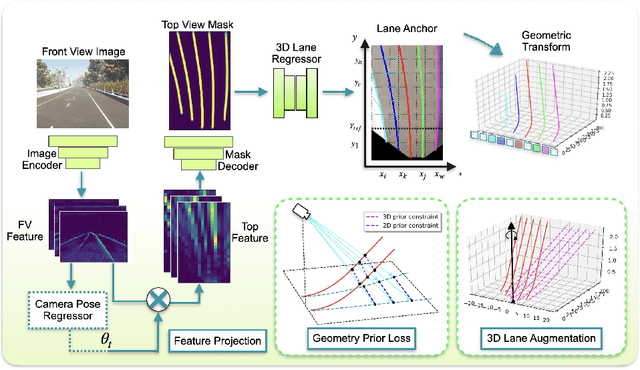
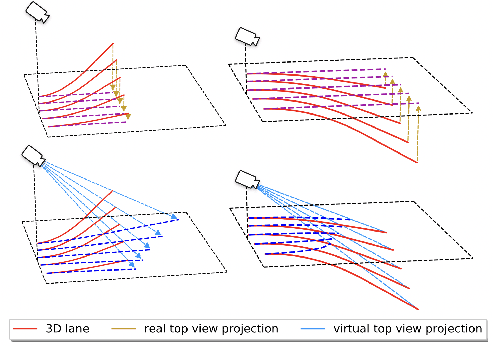
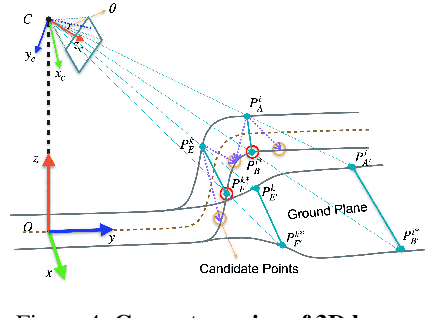
In this paper, we propose an advanced approach in targeting the problem of monocular 3D lane detection by leveraging geometry structure underneath the process of 2D to 3D lane reconstruction. Inspired by previous methods, we first analyze the geometry heuristic between the 3D lane and its 2D representation on the ground and propose to impose explicit supervision based on the structure prior, which makes it achievable to build inter-lane and intra-lane relationships to facilitate the reconstruction of 3D lanes from local to global. Second, to reduce the structure loss in 2D lane representation, we directly extract top view lane information from front view images, which tremendously eases the confusion of distant lane features in previous methods. Furthermore, we propose a novel task-specific data augmentation method by synthesizing new training data for both segmentation and reconstruction tasks in our pipeline, to counter the imbalanced data distribution of camera pose and ground slope to improve generalization on unseen data. Our work marks the first attempt to employ the geometry prior information into DNN-based 3D lane detection and makes it achievable for detecting lanes in an extra-long distance, doubling the original detection range. The proposed method can be smoothly adopted by other frameworks without extra costs. Experimental results show that our work outperforms state-of-the-art approaches by 3.8% F-Score on Apollo 3D synthetic dataset at real-time speed of 82 FPS without introducing extra parameters.
Energy time series forecasting-Analytical and empirical assessment of conventional and machine learning models
Aug 24, 2021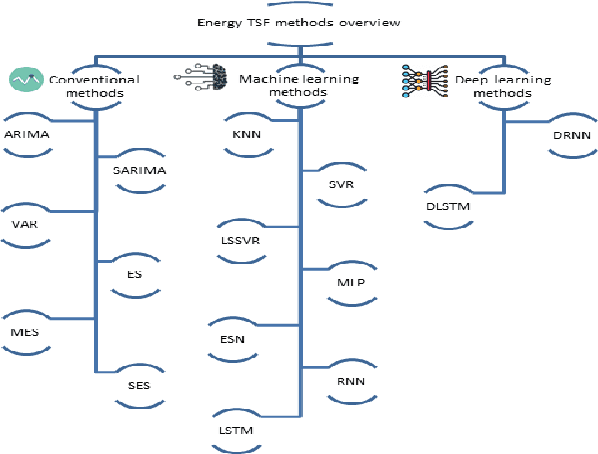
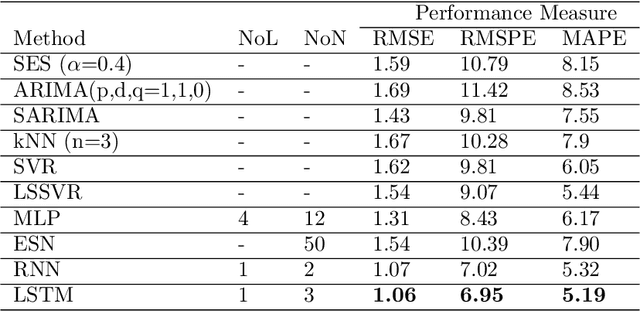
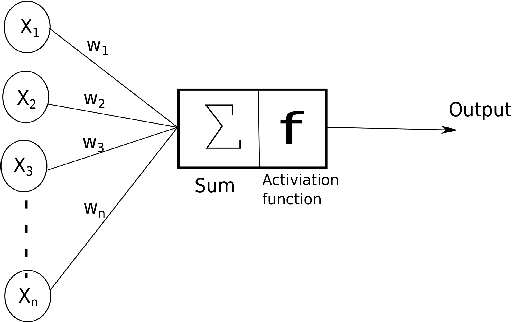
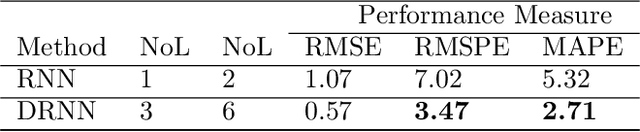
Machine learning methods have been adopted in the literature as contenders to conventional methods to solve the energy time series forecasting (TSF) problems. Recently, deep learning methods have been emerged in the artificial intelligence field attaining astonishing performance in a wide range of applications. Yet, the evidence about their performance in to solve the energy TSF problems, in terms of accuracy and computational requirements, is scanty. Most of the review articles that handle the energy TSF problem are systematic reviews, however, a qualitative and quantitative study for the energy TSF problem is not yet available in the literature. The purpose of this paper is twofold, first it provides a comprehensive analytical assessment for conventional,machine learning, and deep learning methods that can be utilized to solve various energy TSF problems. Second, the paper carries out an empirical assessment for many selected methods through three real-world datasets. These datasets related to electrical energy consumption problem, natural gas problem, and electric power consumption of an individual household problem.The first two problems are univariate TSF and the third problem is a multivariate TSF. Com-pared to both conventional and machine learning contenders, the deep learning methods attain a significant improvement in terms of accuracy and forecasting horizons examined. In the mean-time, their computational requirements are notably greater than other contenders. Eventually,the paper identifies a number of challenges, potential research directions, and recommendations to the research community may serve as a basis for further research in the energy forecasting domain.
Low-cost Relevance Generation and Evaluation Metrics for Entity Resolution in AI
May 20, 2022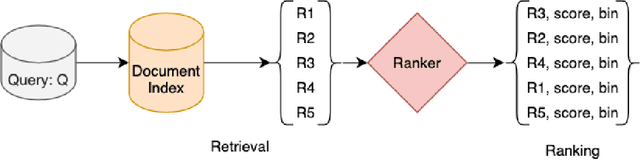


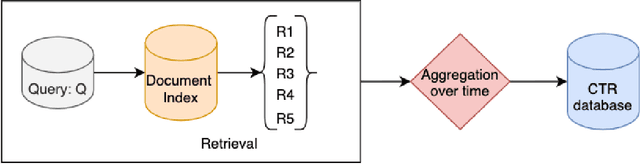
Entity Resolution (ER) in voice assistants is a prime component during run time that resolves entities in users request to real world entities. ER involves two major functionalities 1. Relevance generation and 2. Ranking. In this paper we propose a low cost relevance generation framework by generating features using customer implicit and explicit feedback signals. The generated relevance datasets can serve as test sets to measure ER performance. We also introduce a set of metrics that accurately measures the performance of ER systems in various dimensions. They provide great interpretability to deep dive and identifying root cause of ER issues, whether the problem is in relevance generation or ranking.
What You See is What You Get: Distributional Generalization for Algorithm Design in Deep Learning
Apr 07, 2022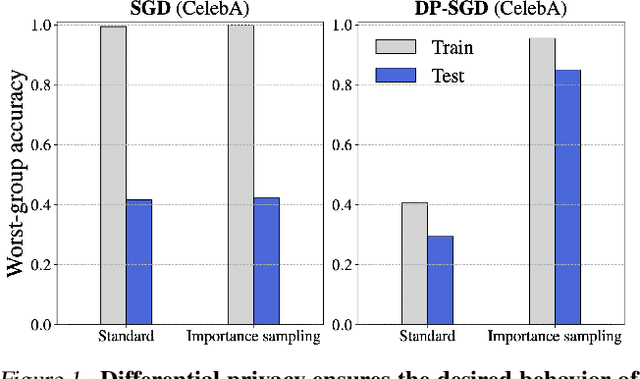
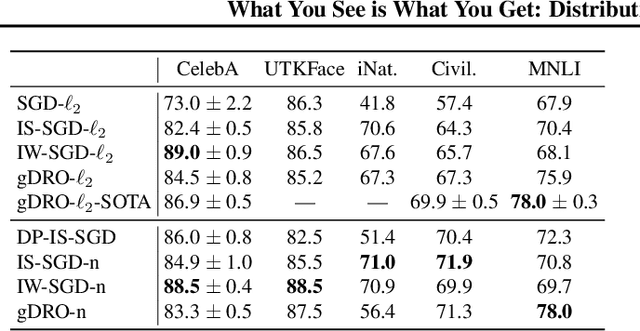
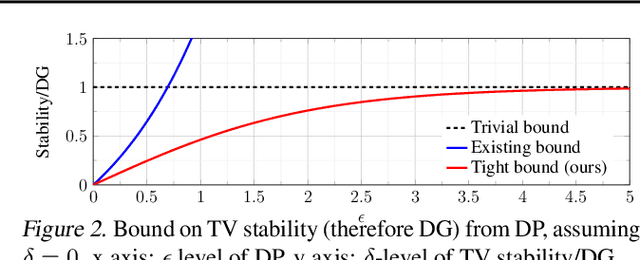
We investigate and leverage a connection between Differential Privacy (DP) and the recently proposed notion of Distributional Generalization (DG). Applying this connection, we introduce new conceptual tools for designing deep-learning methods that bypass "pathologies" of standard stochastic gradient descent (SGD). First, we prove that differentially private methods satisfy a "What You See Is What You Get (WYSIWYG)" generalization guarantee: whatever a model does on its train data is almost exactly what it will do at test time. This guarantee is formally captured by distributional generalization. WYSIWYG enables principled algorithm design in deep learning by reducing $\textit{generalization}$ concerns to $\textit{optimization}$ ones: in order to mitigate unwanted behavior at test time, it is provably sufficient to mitigate this behavior on the train data. This is notably false for standard (non-DP) methods, hence this observation has applications even when privacy is not required. For example, importance sampling is known to fail for standard SGD, but we show that it has exactly the intended effect for DP-trained models. Thus, with DP-SGD, unlike with SGD, we can influence test-time behavior by making principled train-time interventions. We use these insights to construct simple algorithms which match or outperform SOTA in several distributional robustness applications, and to significantly improve the privacy vs. disparate impact trade-off of DP-SGD. Finally, we also improve on known theoretical bounds relating differential privacy, stability, and distributional generalization.
Dynamic covariate balancing: estimating treatment effects over time
Mar 01, 2021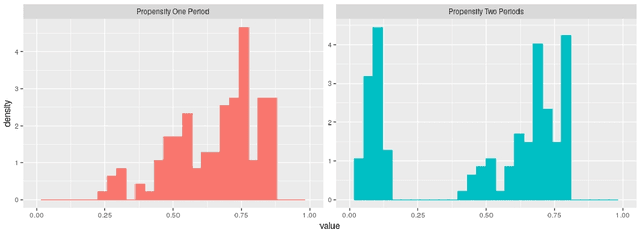
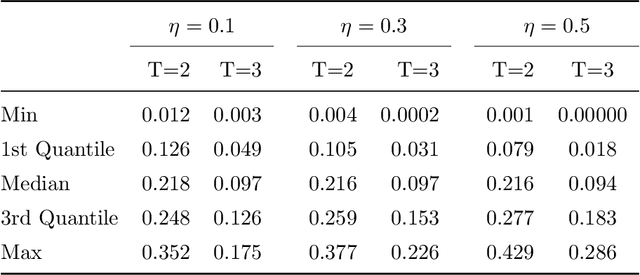
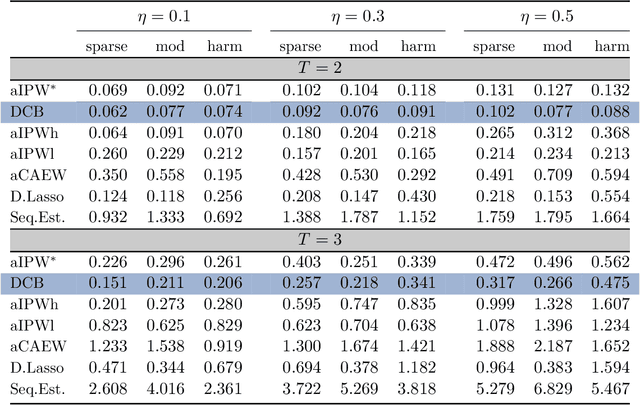
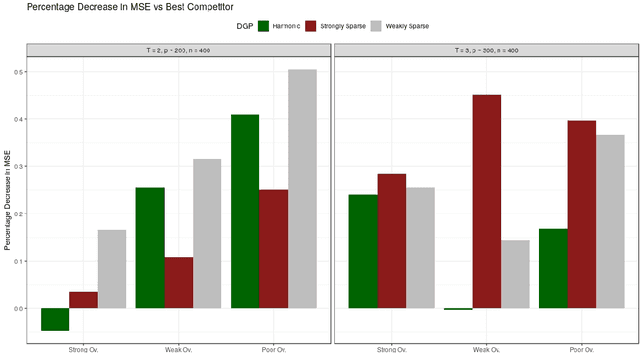
This paper discusses the problem of estimation and inference on time-varying treatments. We propose a method for inference on treatment histories, by introducing a \textit{dynamic} covariate balancing method. Our approach allows for (i) treatments to propagate arbitrarily over time; (ii) non-stationarity and heterogeneity of treatment effects; (iii) high-dimensional covariates, and (iv) unknown propensity score functions. We study the asymptotic properties of the estimator, and we showcase the parametric convergence rate of the proposed procedure. We illustrate in simulations and an empirical application the advantage of the method over state-of-the-art competitors.
Analysis Social Sparsity Audio Declipper
May 20, 2022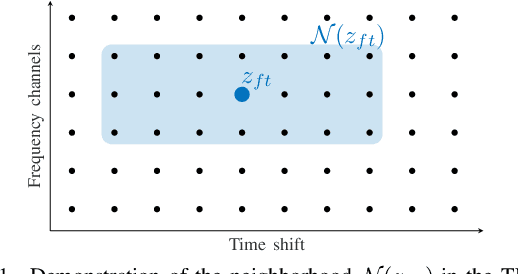
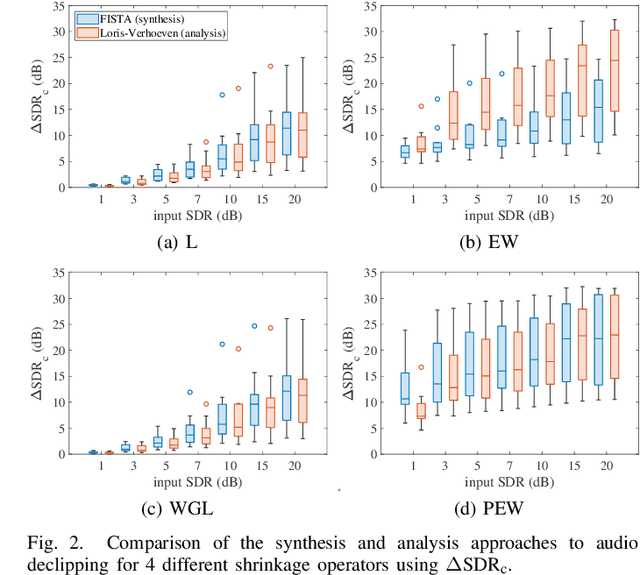
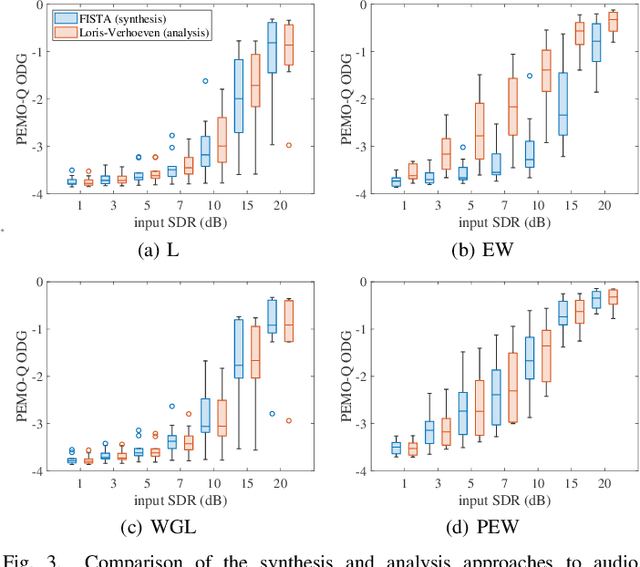
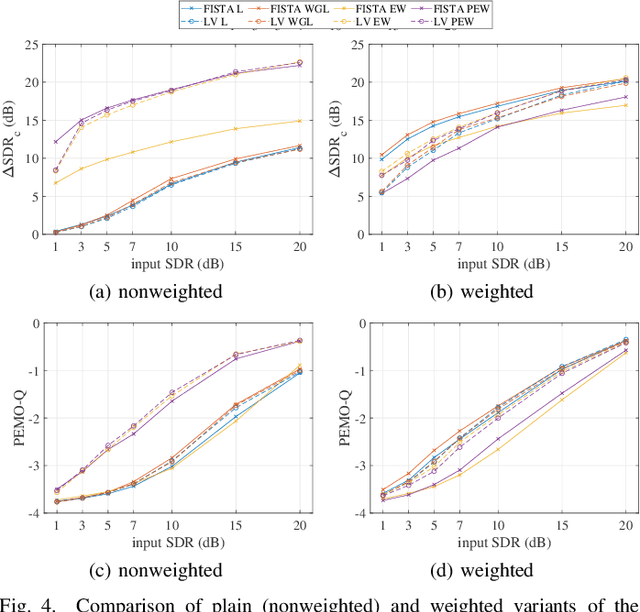
We develop the analysis (cosparse) variant of the popular audio declipping algorithm of Siedenburg et al. Furthermore, we extend it by the possibility of weighting the time-frequency coefficients. We examine the audio reconstruction performance of several combinations of weights and shrinkage operators. We show that weights improve the reconstruction quality in some cases; however, the overall scores achieved by the non-weighted are not surpassed. Yet, the analysis Empirical Wiener (EW) shrinkage was able to reach the quality of a computationally more expensive competitor, the Persistent Empirical Wiener (PEW). Moreover, the proposed analysis variant using PEW slightly outperforms the synthesis counterpart in terms of an auditory-motivated metric.
Adaptive Sequential Design for a Single Time-Series
Jan 29, 2021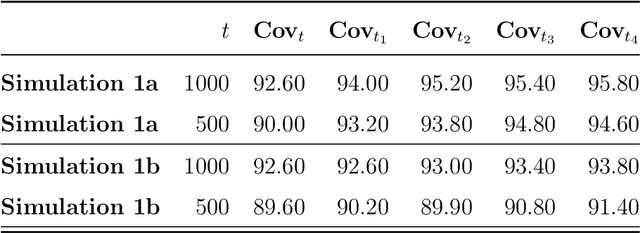
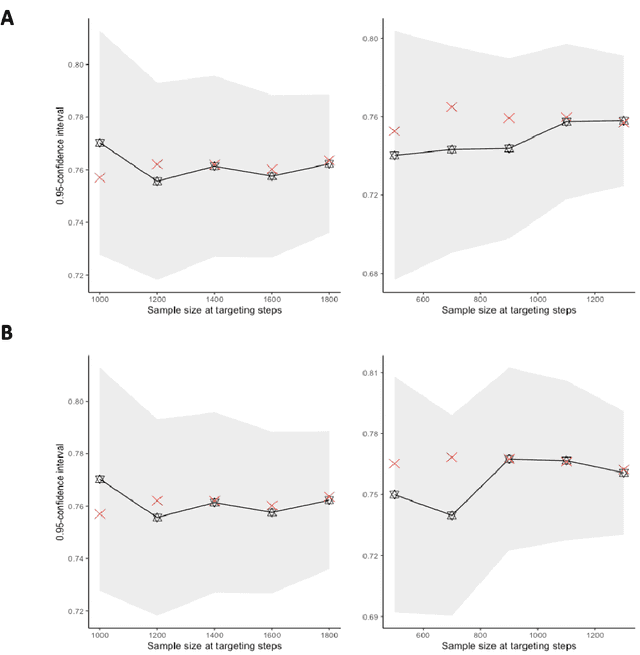
The current work is motivated by the need for robust statistical methods for precision medicine; as such, we address the need for statistical methods that provide actionable inference for a single unit at any point in time. We aim to learn an optimal, unknown choice of the controlled components of the design in order to optimize the expected outcome; with that, we adapt the randomization mechanism for future time-point experiments based on the data collected on the individual over time. Our results demonstrate that one can learn the optimal rule based on a single sample, and thereby adjust the design at any point t with valid inference for the mean target parameter. This work provides several contributions to the field of statistical precision medicine. First, we define a general class of averages of conditional causal parameters defined by the current context for the single unit time-series data. We define a nonparametric model for the probability distribution of the time-series under few assumptions, and aim to fully utilize the sequential randomization in the estimation procedure via the double robust structure of the efficient influence curve of the proposed target parameter. We present multiple exploration-exploitation strategies for assigning treatment, and methods for estimating the optimal rule. Lastly, we present the study of the data-adaptive inference on the mean under the optimal treatment rule, where the target parameter adapts over time in response to the observed context of the individual. Our target parameter is pathwise differentiable with an efficient influence function that is doubly robust - which makes it easier to estimate than previously proposed variations. We characterize the limit distribution of our estimator under a Donsker condition expressed in terms of a notion of bracketing entropy adapted to martingale settings.
An Efficient Real-Time NMPC for Quadrotor Position Control under Communication Time-Delay
Oct 21, 2020
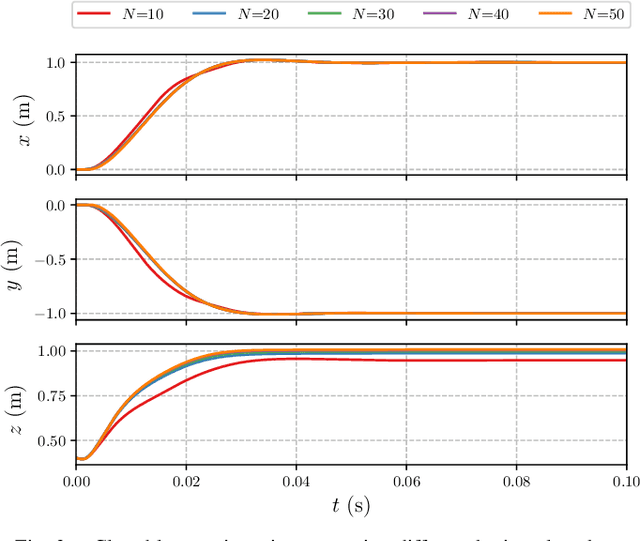
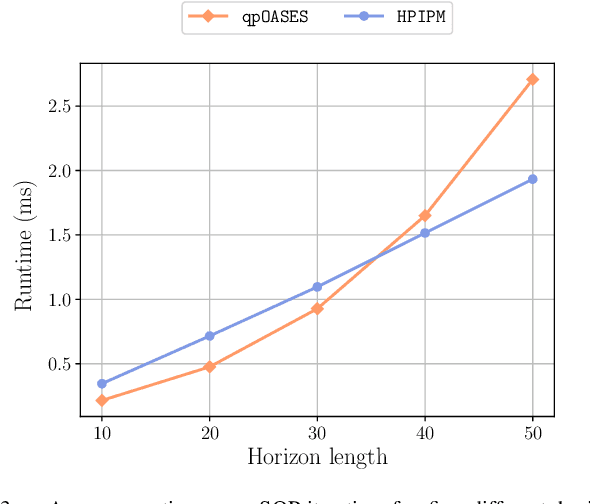
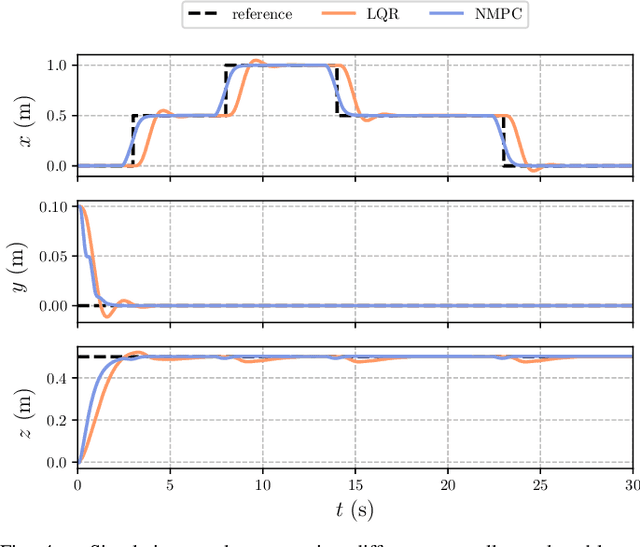
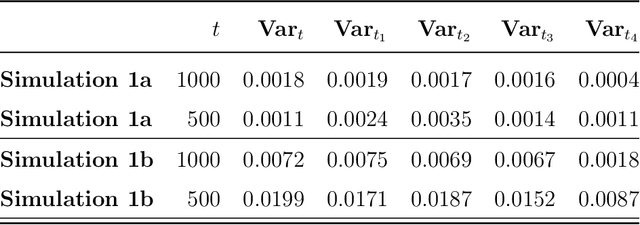
The advances in computer processor technology have enabled the application of nonlinear model predictive control (NMPC) to agile systems, such as quadrotors. These systems are characterized by their underactuation, nonlinearities, bounded inputs, and time-delays. Classical control solutions fall short in overcoming these difficulties and fully exploiting the capabilities offered by such platforms. This paper presents the design and implementation of an efficient position controller for quadrotors based on real-time NMPC with time-delay compensation and bounds enforcement on the actuators. To deal with the limited computational resources onboard, an offboard control architecture is proposed. It is implemented using the high-performance software package acados, which solves optimal control problems and implements a real-time iteration (RTI) variant of a sequential quadratic programming (SQP) scheme with Gauss-Newton Hessian approximation. The quadratic subproblems (QP) in the SQP scheme are solved with HPIPM, an interior-point method solver, built on top of the linear algebra library BLASFEO, finely tuned for multiple CPU architectures. Solution times are further reduced by reformulating the QPs using the efficient partial condensing algorithm implemented in HPIPM. We demonstrate the capabilities of our architecture using the Crazyflie 2.1 nanoquadrotor.
Feature-weighted Stacking for Nonseasonal Time Series Forecasts: A Case Study of the COVID-19 Epidemic Curves
Aug 28, 2021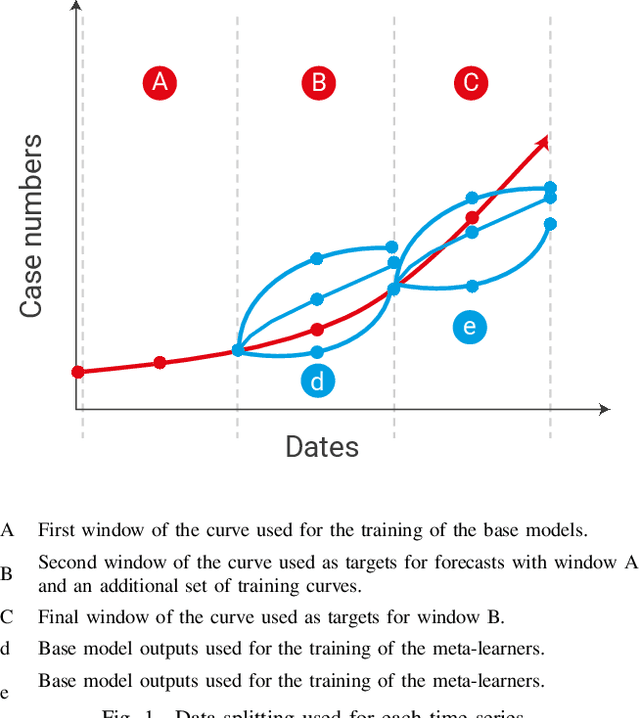
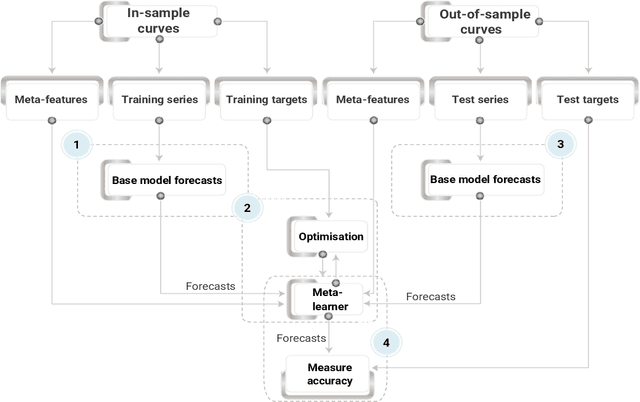
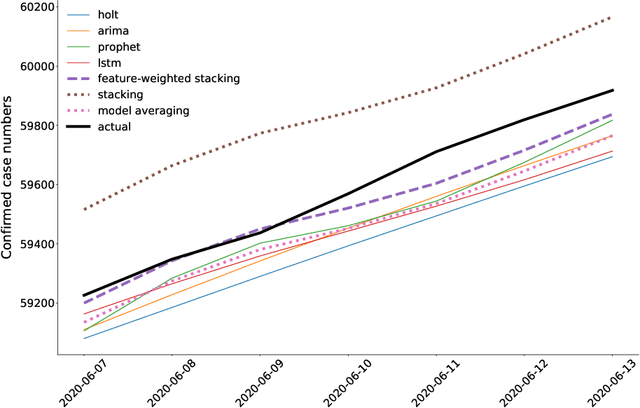
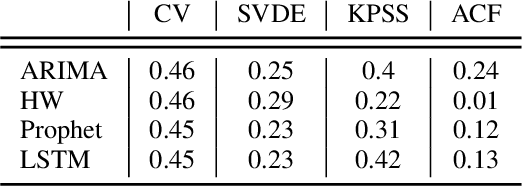
We investigate ensembling techniques in forecasting and examine their potential for use in nonseasonal time-series similar to those in the early days of the COVID-19 pandemic. Developing improved forecast methods is essential as they provide data-driven decisions to organisations and decision-makers during critical phases. We propose using late data fusion, using a stacked ensemble of two forecasting models and two meta-features that prove their predictive power during a preliminary forecasting stage. The final ensembles include a Prophet and long short term memory (LSTM) neural network as base models. The base models are combined by a multilayer perceptron (MLP), taking into account meta-features that indicate the highest correlation with each base model's forecast accuracy. We further show that the inclusion of meta-features generally improves the ensemble's forecast accuracy across two forecast horizons of seven and fourteen days. This research reinforces previous work and demonstrates the value of combining traditional statistical models with deep learning models to produce more accurate forecast models for time-series from different domains and seasonality.
Flatten the Curve: Efficiently Training Low-Curvature Neural Networks
Jun 14, 2022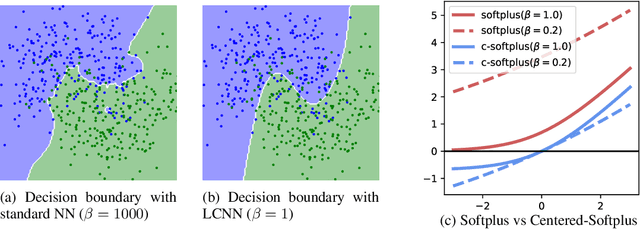

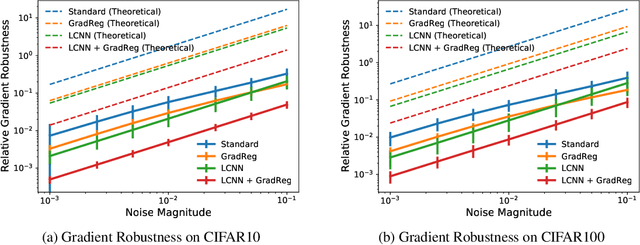
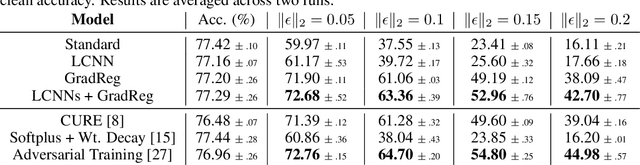
The highly non-linear nature of deep neural networks causes them to be susceptible to adversarial examples and have unstable gradients which hinders interpretability. However, existing methods to solve these issues, such as adversarial training, are expensive and often sacrifice predictive accuracy. In this work, we consider curvature, which is a mathematical quantity which encodes the degree of non-linearity. Using this, we demonstrate low-curvature neural networks (LCNNs) that obtain drastically lower curvature than standard models while exhibiting similar predictive performance, which leads to improved robustness and stable gradients, with only a marginally increased training time. To achieve this, we minimize a data-independent upper bound on the curvature of a neural network, which decomposes overall curvature in terms of curvatures and slopes of its constituent layers. To efficiently minimize this bound, we introduce two novel architectural components: first, a non-linearity called centered-softplus that is a stable variant of the softplus non-linearity, and second, a Lipschitz-constrained batch normalization layer. Our experiments show that LCNNs have lower curvature, more stable gradients and increased off-the-shelf adversarial robustness when compared to their standard high-curvature counterparts, all without affecting predictive performance. Our approach is easy to use and can be readily incorporated into existing neural network models.