 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Landfall's Location and Time of a Tropical Cyclone Using Reanalysis Data
Mar 30, 2021
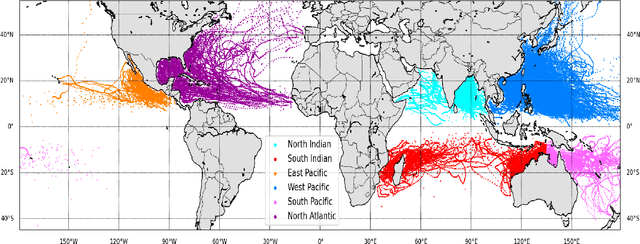
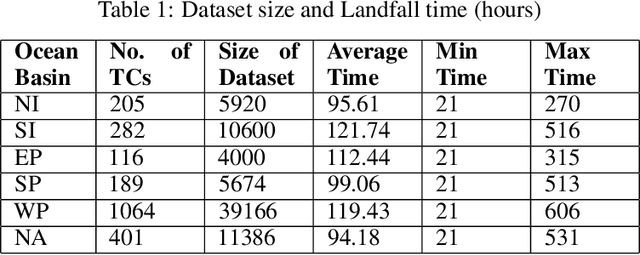
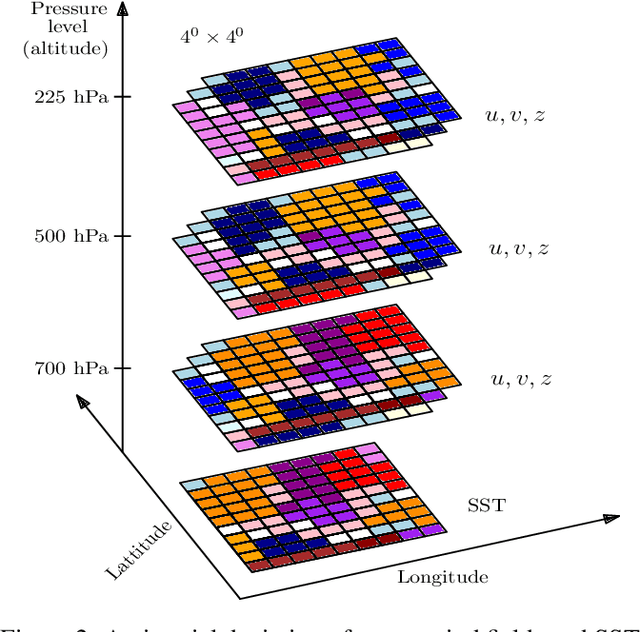
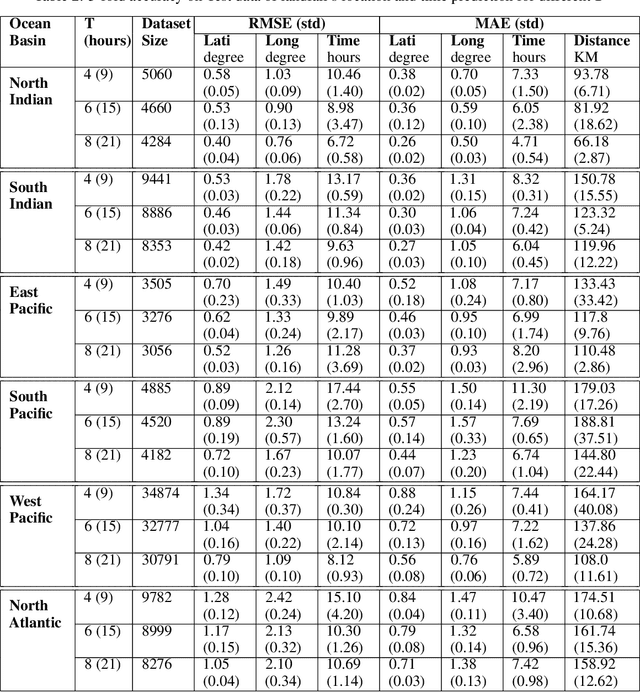
Landfall of a tropical cyclone is the event when it moves over the land after crossing the coast of the ocean. It is important to know the characteristics of the landfall in terms of location and time, well advance in time to take preventive measures timely. In this article, we develop a deep learning model based on the combination of a Convolutional Neural network and a Long Short-Term memory network to predict the landfall's location and time of a tropical cyclone in six ocean basins of the world with high accuracy. We have used high-resolution spacial reanalysis data, ERA5, maintained by European Center for Medium-Range Weather Forecasting (ECMWF). The model takes any 9 hours, 15 hours, or 21 hours of data, during the progress of a tropical cyclone and predicts its landfall's location in terms of latitude and longitude and time in hours. For 21 hours of data, we achieve mean absolute error for landfall's location prediction in the range of 66.18 - 158.92 kilometers and for landfall's time prediction in the range of 4.71 - 8.20 hours across all six ocean basins. The model can be trained in just 30 to 45 minutes (based on ocean basin) and can predict the landfall's location and time in a few seconds, which makes it suitable for real time prediction.
Enhancing Event-Level Sentiment Analysis with Structured Arguments
May 31, 2022

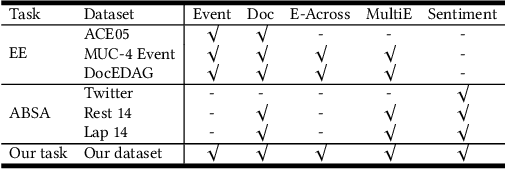
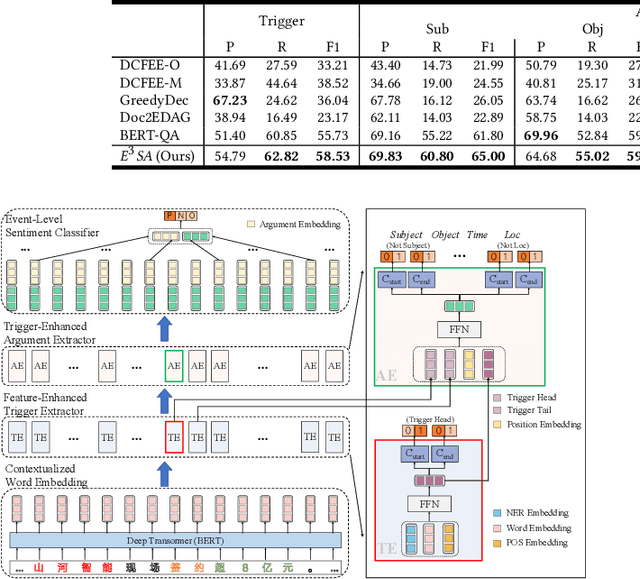
Previous studies about event-level sentiment analysis (SA) usually model the event as a topic, a category or target terms, while the structured arguments (e.g., subject, object, time and location) that have potential effects on the sentiment are not well studied. In this paper, we redefine the task as structured event-level SA and propose an End-to-End Event-level Sentiment Analysis ($\textit{E}^{3}\textit{SA}$) approach to solve this issue. Specifically, we explicitly extract and model the event structure information for enhancing event-level SA. Extensive experiments demonstrate the great advantages of our proposed approach over the state-of-the-art methods. Noting the lack of the dataset, we also release a large-scale real-world dataset with event arguments and sentiment labelling for promoting more researches\footnote{The dataset is available at https://github.com/zhangqi-here/E3SA}.
A Multi-stage Framework with Mean Subspace Computation and Recursive Feedback for Online Unsupervised Domain Adaptation
Jun 24, 2022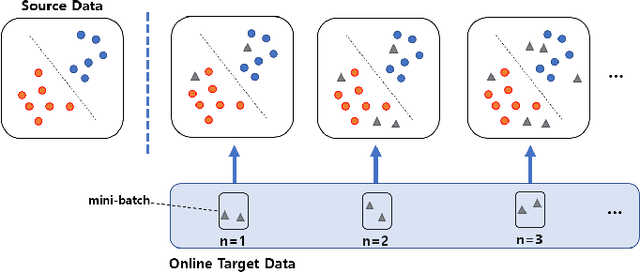
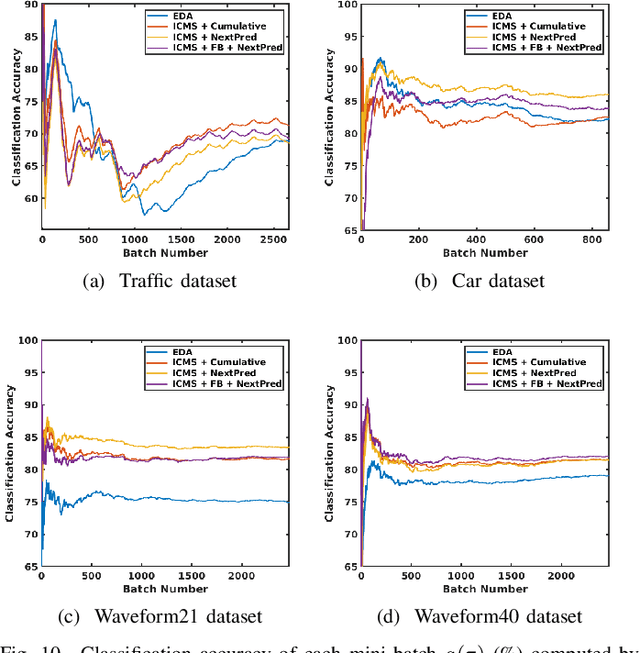
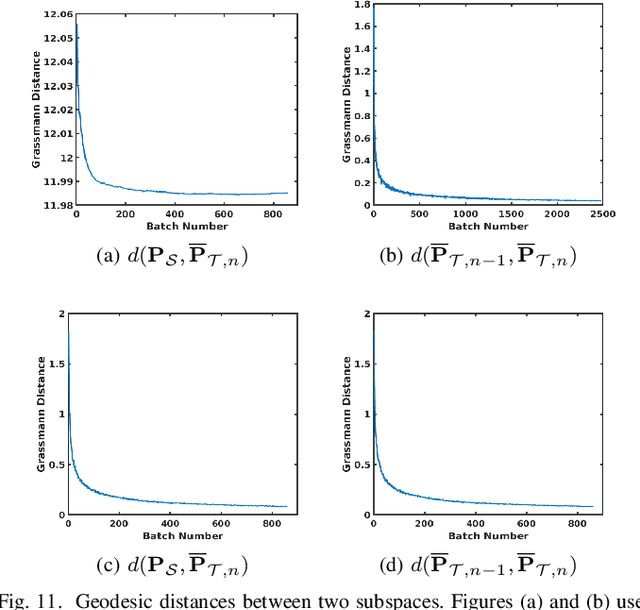
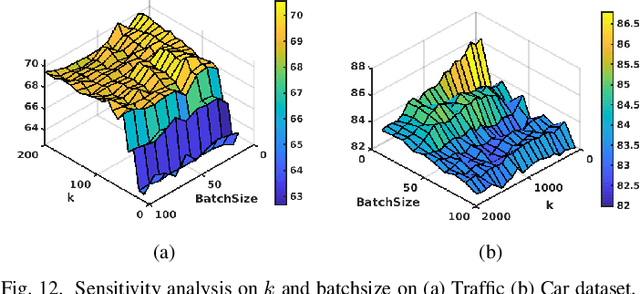
In this paper, we address the Online Unsupervised Domain Adaptation (OUDA) problem and propose a novel multi-stage framework to solve real-world situations when the target data are unlabeled and arriving online sequentially in batches. To project the data from the source and the target domains to a common subspace and manipulate the projected data in real-time, our proposed framework institutes a novel method, called an Incremental Computation of Mean-Subspace (ICMS) technique, which computes an approximation of mean-target subspace on a Grassmann manifold and is proven to be a close approximate to the Karcher mean. Furthermore, the transformation matrix computed from the mean-target subspace is applied to the next target data in the recursive-feedback stage, aligning the target data closer to the source domain. The computation of transformation matrix and the prediction of next-target subspace leverage the performance of the recursive-feedback stage by considering the cumulative temporal dependency among the flow of the target subspace on the Grassmann manifold. The labels of the transformed target data are predicted by the pre-trained source classifier, then the classifier is updated by the transformed data and predicted labels. Extensive experiments on six datasets were conducted to investigate in depth the effect and contribution of each stage in our proposed framework and its performance over previous approaches in terms of classification accuracy and computational speed. In addition, the experiments on traditional manifold-based learning models and neural-network-based learning models demonstrated the applicability of our proposed framework for various types of learning models.
Formal Specifications from Natural Language
Jun 04, 2022


We study the ability of language models to translate natural language into formal specifications with complex semantics. In particular, we fine-tune off-the-shelf language models on three datasets consisting of structured English sentences and their corresponding formal representation: 1) First-order logic (FOL), commonly used in software verification and theorem proving; 2) linear-time temporal logic (LTL), which forms the basis for industrial hardware specification languages; and 3) regular expressions (regex), frequently used in programming and search. Our experiments show that, in these diverse domains, the language models achieve competitive performance to the respective state-of-the-art with the benefits of being easy to access, cheap to fine-tune, and without a particular need for domain-specific reasoning. Additionally, we show that the language models have a unique selling point: they benefit from their generalization capabilities from pre-trained knowledge on natural language, e.g., to generalize to unseen variable names.
EST: Evaluating Scientific Thinking in Artificial Agents
Jun 18, 2022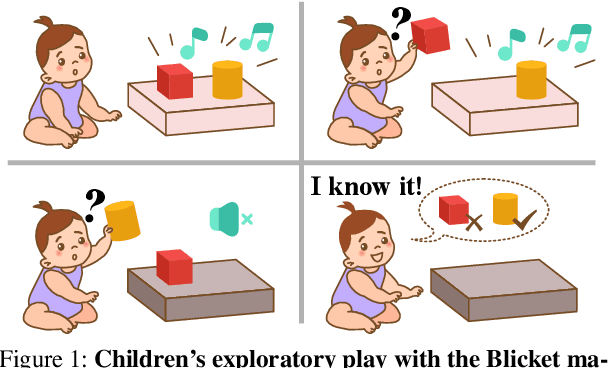

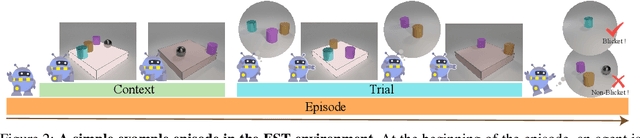
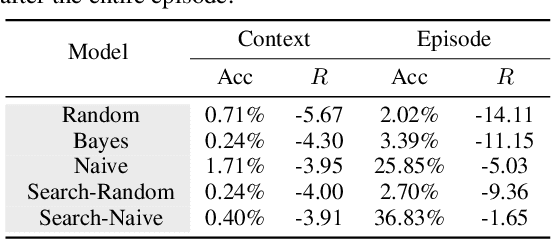
Theoretical ideas and empirical research have shown us a seemingly surprising result: children, even very young toddlers, demonstrate learning and thinking in a strikingly similar manner to scientific reasoning in formal research. Encountering a novel phenomenon, children make hypotheses against data, conduct causal inference from observation, test their theory via experimentation, and correct the proposition if inconsistency arises. Rounds of such processes continue until the underlying mechanism is found. Towards building machines that can learn and think like people, one natural question for us to ask is: whether the intelligence we achieve today manages to perform such a scientific thinking process, and if any, at what level. In this work, we devise the EST environment for evaluating the scientific thinking ability in artificial agents. Motivated by the stream of research on causal discovery, we build our interactive EST environment based on Blicket detection. Specifically, in each episode of EST, an agent is presented with novel observations and asked to figure out all objects' Blicketness. At each time step, the agent proposes new experiments to validate its hypothesis and updates its current belief. By evaluating Reinforcement Learning (RL) agents on both a symbolic and visual version of this task, we notice clear failure of today's learning methods in reaching a level of intelligence comparable to humans. Such inefficacy of learning in scientific thinking calls for future research in building humanlike intelligence.
Real-time Pose and Shape Reconstruction of Two Interacting Hands With a Single Depth Camera
Jun 15, 2021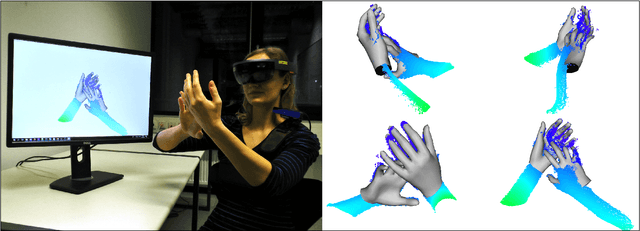

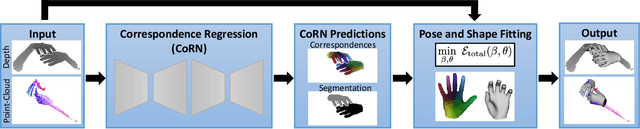

We present a novel method for real-time pose and shape reconstruction of two strongly interacting hands. Our approach is the first two-hand tracking solution that combines an extensive list of favorable properties, namely it is marker-less, uses a single consumer-level depth camera, runs in real time, handles inter- and intra-hand collisions, and automatically adjusts to the user's hand shape. In order to achieve this, we embed a recent parametric hand pose and shape model and a dense correspondence predictor based on a deep neural network into a suitable energy minimization framework. For training the correspondence prediction network, we synthesize a two-hand dataset based on physical simulations that includes both hand pose and shape annotations while at the same time avoiding inter-hand penetrations. To achieve real-time rates, we phrase the model fitting in terms of a nonlinear least-squares problem so that the energy can be optimized based on a highly efficient GPU-based Gauss-Newton optimizer. We show state-of-the-art results in scenes that exceed the complexity level demonstrated by previous work, including tight two-hand grasps, significant inter-hand occlusions, and gesture interaction.
An Empirical Study of Challenges in Converting Deep Learning Models
Jun 28, 2022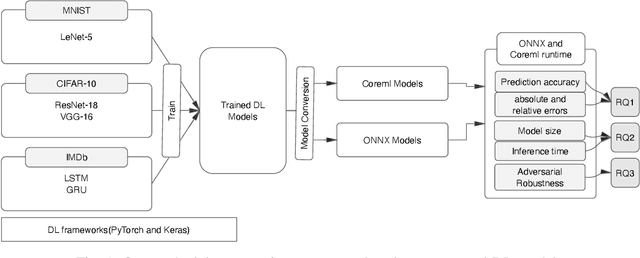
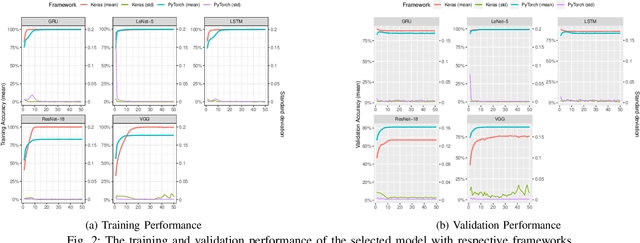
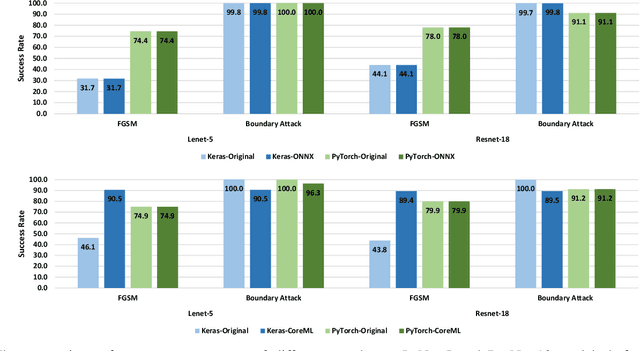
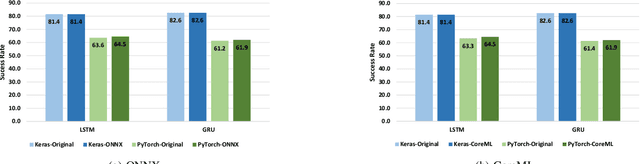
There is an increase in deploying Deep Learning (DL)-based software systems in real-world applications. Usually DL models are developed and trained using DL frameworks that have their own internal mechanisms/formats to represent and train DL models, and usually those formats cannot be recognized by other frameworks. Moreover, trained models are usually deployed in environments different from where they were developed. To solve the interoperability issue and make DL models compatible with different frameworks/environments, some exchange formats are introduced for DL models, like ONNX and CoreML. However, ONNX and CoreML were never empirically evaluated by the community to reveal their prediction accuracy, performance, and robustness after conversion. Poor accuracy or non-robust behavior of converted models may lead to poor quality of deployed DL-based software systems. We conduct, in this paper, the first empirical study to assess ONNX and CoreML for converting trained DL models. In our systematic approach, two popular DL frameworks, Keras and PyTorch, are used to train five widely used DL models on three popular datasets. The trained models are then converted to ONNX and CoreML and transferred to two runtime environments designated for such formats, to be evaluated. We investigate the prediction accuracy before and after conversion. Our results unveil that the prediction accuracy of converted models are at the same level of originals. The performance (time cost and memory consumption) of converted models are studied as well. The size of models are reduced after conversion, which can result in optimized DL-based software deployment. Converted models are generally assessed as robust at the same level of originals. However, obtained results show that CoreML models are more vulnerable to adversarial attacks compared to ONNX.
Multi-Task Time Series Forecasting With Shared Attention
Jan 24, 2021
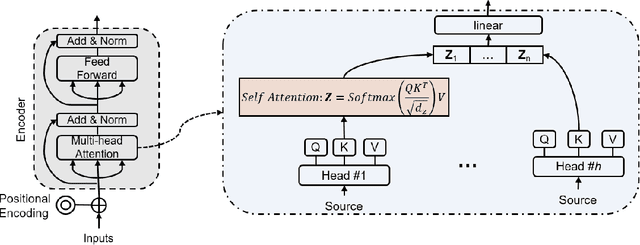
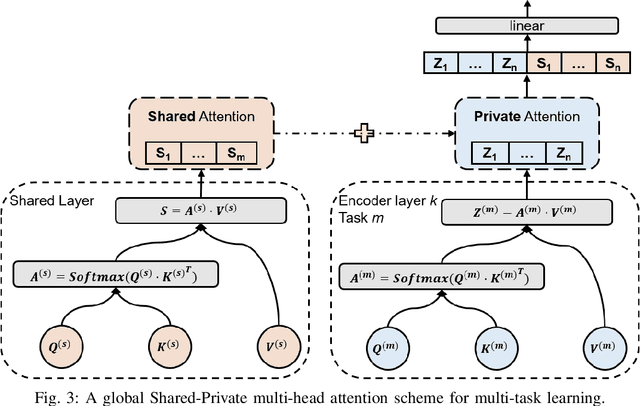
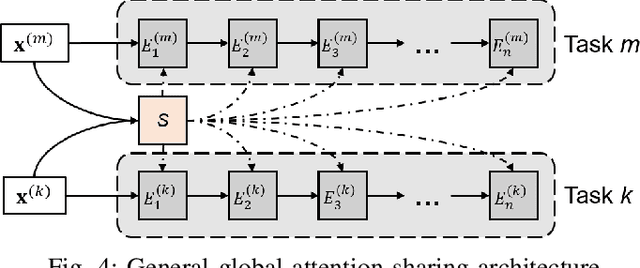
Time series forecasting is a key component in many industrial and business decision processes and recurrent neural network (RNN) based models have achieved impressive progress on various time series forecasting tasks. However, most of the existing methods focus on single-task forecasting problems by learning separately based on limited supervised objectives, which often suffer from insufficient training instances. As the Transformer architecture and other attention-based models have demonstrated its great capability of capturing long term dependency, we propose two self-attention based sharing schemes for multi-task time series forecasting which can train jointly across multiple tasks. We augment a sequence of paralleled Transformer encoders with an external public multi-head attention function, which is updated by all data of all tasks. Experiments on a number of real-world multi-task time series forecasting tasks show that our proposed architectures can not only outperform the state-of-the-art single-task forecasting baselines but also outperform the RNN-based multi-task forecasting method.
Multistep Automated Data Labelling Procedure (MADLaP) for Thyroid Nodules on Ultrasound: An Artificial Intelligence Approach for Automating Image Annotation
Jun 28, 2022
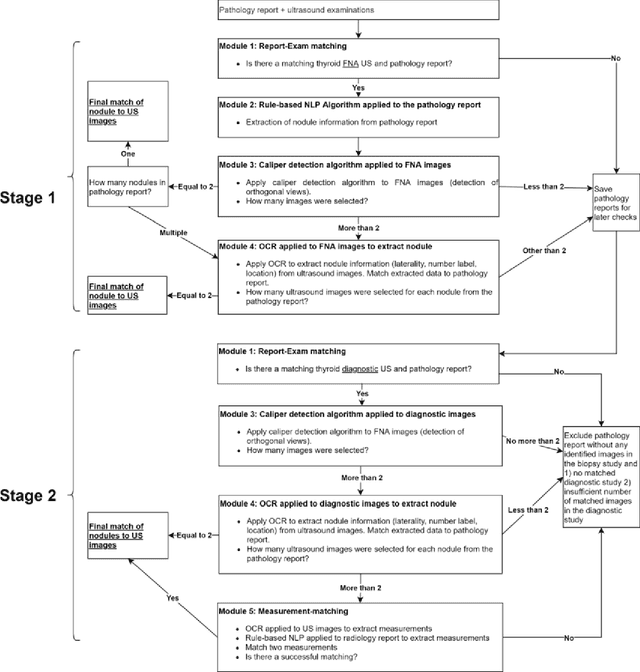


Machine learning (ML) for diagnosis of thyroid nodules on ultrasound is an active area of research. However, ML tools require large, well-labelled datasets, the curation of which is time-consuming and labor-intensive. The purpose of our study was to develop and test a deep-learning-based tool to facilitate and automate the data annotation process for thyroid nodules; we named our tool Multistep Automated Data Labelling Procedure (MADLaP). MADLaP was designed to take multiple inputs included pathology reports, ultrasound images, and radiology reports. Using multiple step-wise modules including rule-based natural language processing, deep-learning-based imaging segmentation, and optical character recognition, MADLaP automatically identified images of a specific thyroid nodule and correctly assigned a pathology label. The model was developed using a training set of 378 patients across our health system and tested on a separate set of 93 patients. Ground truths for both sets were selected by an experienced radiologist. Performance metrics including yield (how many labeled images the model produced) and accuracy (percentage correct) were measured using the test set. MADLaP achieved a yield of 63% and an accuracy of 83%. The yield progressively increased as the input data moved through each module, while accuracy peaked part way through. Error analysis showed that inputs from certain examination sites had lower accuracy (40%) than the other sites (90%, 100%). MADLaP successfully created curated datasets of labeled ultrasound images of thyroid nodules. While accurate, the relatively suboptimal yield of MADLaP exposed some challenges when trying to automatically label radiology images from heterogeneous sources. The complex task of image curation and annotation could be automated, allowing for enrichment of larger datasets for use in machine learning development.
Estimating Link Flows in Road Networks with Synthetic Trajectory Data Generation: Reinforcement Learning-based Approaches
Jun 26, 2022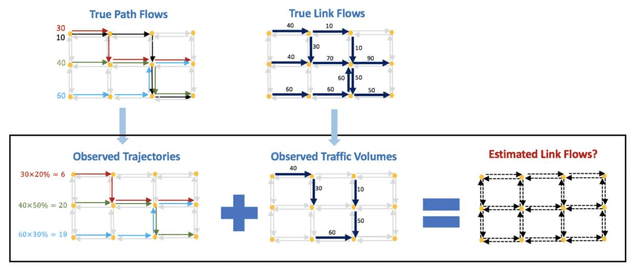
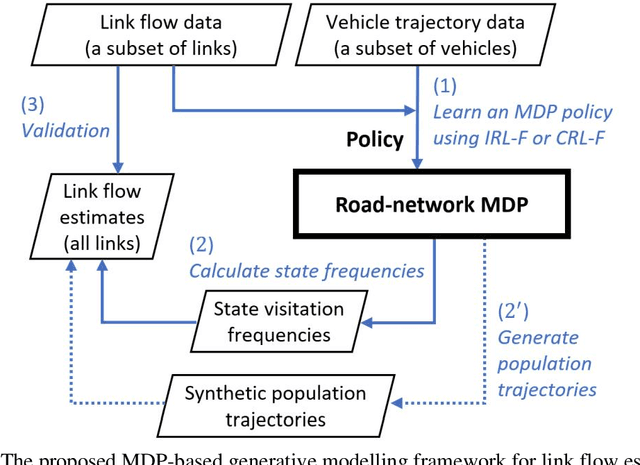

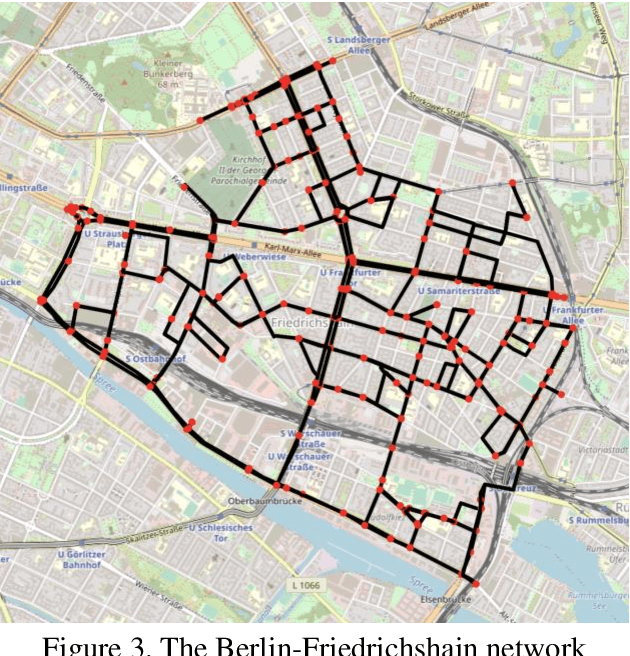
This paper addresses the problem of estimating link flows in a road network by combining limited traffic volume and vehicle trajectory data. While traffic volume data from loop detectors have been the common data source for link flow estimation, the detectors only cover a subset of links. Vehicle trajectory data collected from vehicle tracking sensors are also incorporated these days. However, trajectory data are often sparse in that the observed trajectories only represent a small subset of the whole population, where the exact sampling rate is unknown and may vary over space and time. This study proposes a novel generative modelling framework, where we formulate the link-to-link movements of a vehicle as a sequential decision-making problem using the Markov Decision Process framework and train an agent to make sequential decisions to generate realistic synthetic vehicle trajectories. We use Reinforcement Learning (RL)-based methods to find the best behaviour of the agent, based on which synthetic population vehicle trajectories can be generated to estimate link flows across the whole network. To ensure the generated population vehicle trajectories are consistent with the observed traffic volume and trajectory data, two methods based on Inverse Reinforcement Learning and Constrained Reinforcement Learning are proposed. The proposed generative modelling framework solved by either of these RL-based methods is validated by solving the link flow estimation problem in a real road network. Additionally, we perform comprehensive experiments to compare the performance with two existing methods. The results show that the proposed framework has higher estimation accuracy and robustness under realistic scenarios where certain behavioural assumptions about drivers are not met or the network coverage and penetration rate of trajectory data are low.