 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
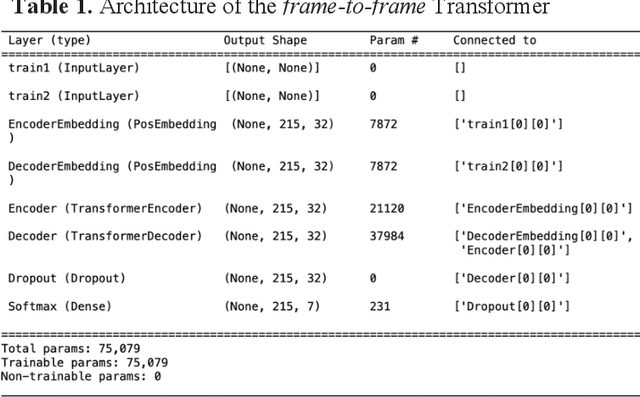
An Early Fault Detection Method of Rotating Machines Based on Multiple Feature Fusion with Stacking Architecture
May 01, 2022
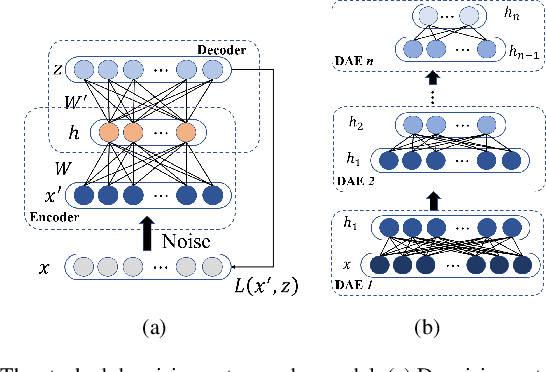
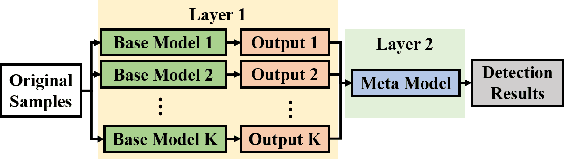
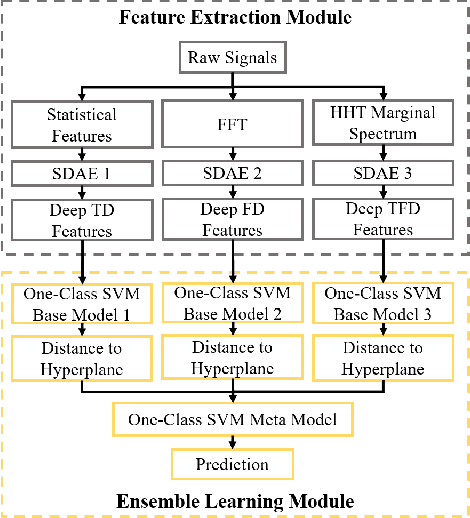
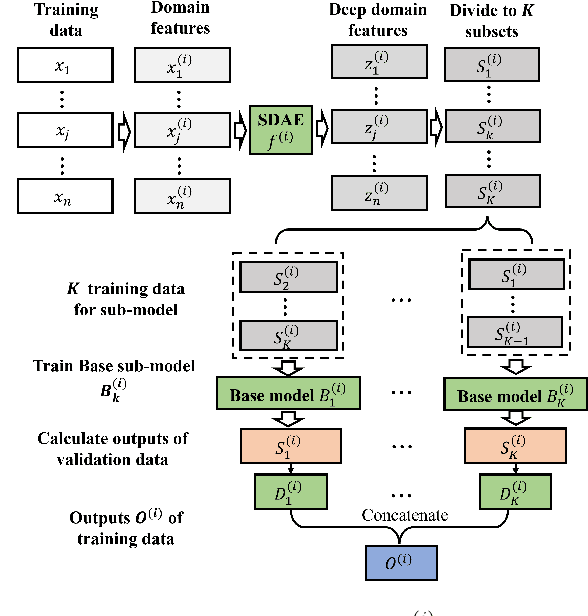
Early fault detection (EFD) of rotating machines is important to decrease the maintenance cost and improve the mechanical system stability. One of the key points of EFD is developing a generic model to extract robust and discriminative features from different equipment for early fault detection. Most existing EFD methods focus on learning fault representation by one type of feature. However, a combination of multiple features can capture a more comprehensive representation of system state. In this paper, we propose an EFD method based on multiple feature fusion with stacking architecture (M2FSA). The proposed method can extract generic and discriminiative features to detect early faults by combining time domain (TD), frequency domain (FD), and time-frequency domain (TFD) features. In order to unify the dimensions of the different domain features, Stacked Denoising Autoencoder (SDAE) is utilized to learn deep features in three domains. The architecture of the proposed M2FSA consists of two layers. The first layer contains three base models, whose corresponding inputs are different deep features. The outputs of the first layer are concatenated to generate the input to the second layer, which consists of a meta model. The proposed method is tested on three bearing datasets. The results demonstrate that the proposed method is better than existing methods both in sensibility and reliability.
RACA: Relation-Aware Credit Assignment for Ad-Hoc Cooperation in Multi-Agent Deep Reinforcement Learning
Jun 02, 2022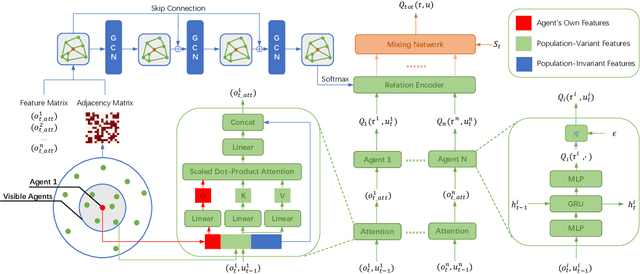
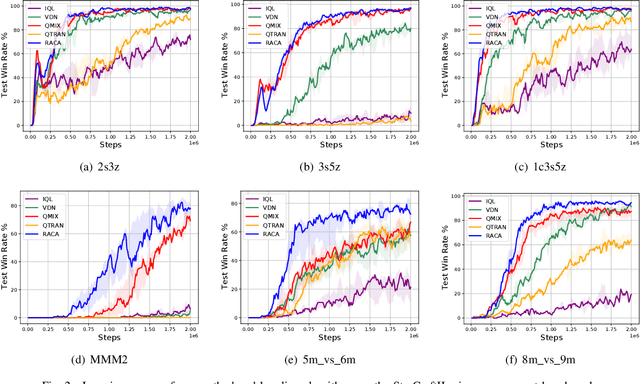
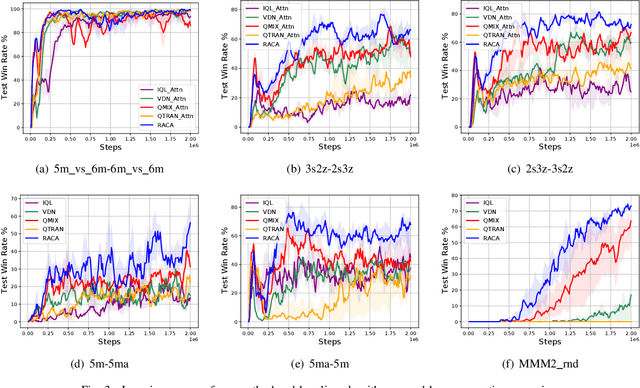
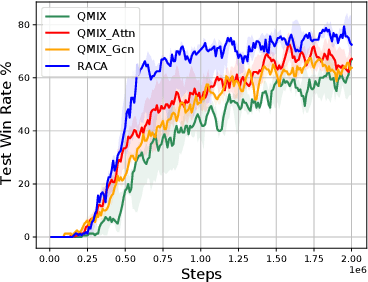
In recent years, reinforcement learning has faced several challenges in the multi-agent domain, such as the credit assignment issue. Value function factorization emerges as a promising way to handle the credit assignment issue under the centralized training with decentralized execution (CTDE) paradigm. However, existing value function factorization methods cannot deal with ad-hoc cooperation, that is, adapting to new configurations of teammates at test time. Specifically, these methods do not explicitly utilize the relationship between agents and cannot adapt to different sizes of inputs. To address these limitations, we propose a novel method, called Relation-Aware Credit Assignment (RACA), which achieves zero-shot generalization in ad-hoc cooperation scenarios. RACA takes advantage of a graph-based relation encoder to encode the topological structure between agents. Furthermore, RACA utilizes an attention-based observation abstraction mechanism that can generalize to an arbitrary number of teammates with a fixed number of parameters. Experiments demonstrate that our method outperforms baseline methods on the StarCraftII micromanagement benchmark and ad-hoc cooperation scenarios.
PIE: a Parameter and Inference Efficient Solution for Large Scale Knowledge Graph Embedding Reasoning
May 05, 2022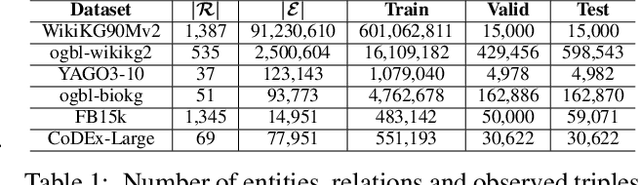
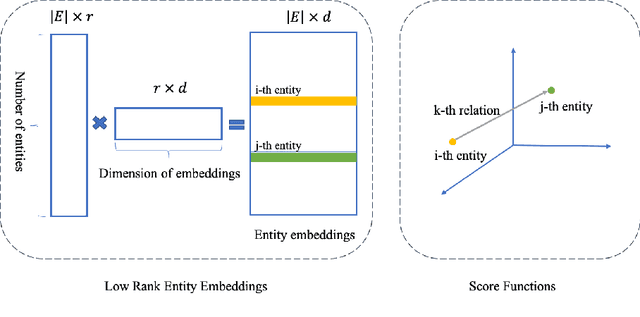

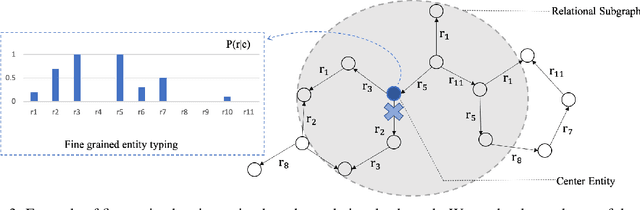
Knowledge graph (KG) embedding methods which map entities and relations to unique embeddings in the KG have shown promising results on many reasoning tasks. However, the same embedding dimension for both dense entities and sparse entities will cause either over parameterization (sparse entities) or under fitting (dense entities). Normally, a large dimension is set to get better performance. Meanwhile, the inference time grows log-linearly with the number of entities for all entities are traversed and compared. Both the parameter and inference become challenges when working with huge amounts of entities. Thus, we propose PIE, a \textbf{p}arameter and \textbf{i}nference \textbf{e}fficient solution. Inspired from tensor decomposition methods, we find that decompose entity embedding matrix into low rank matrices can reduce more than half of the parameters while maintaining comparable performance. To accelerate model inference, we propose a self-supervised auxiliary task, which can be seen as fine-grained entity typing. By randomly masking and recovering entities' connected relations, the task learns the co-occurrence of entity and relations. Utilizing the fine grained typing, we can filter unrelated entities during inference and get targets with possibly sub-linear time requirement. Experiments on link prediction benchmarks demonstrate the proposed key capabilities. Moreover, we prove effectiveness of the proposed solution on the Open Graph Benchmark large scale challenge dataset WikiKG90Mv2 and achieve the state of the art performance.
RL-EA: A Reinforcement Learning-Based Evolutionary Algorithm Framework for Electromagnetic Detection Satellite Scheduling Problem
Jun 12, 2022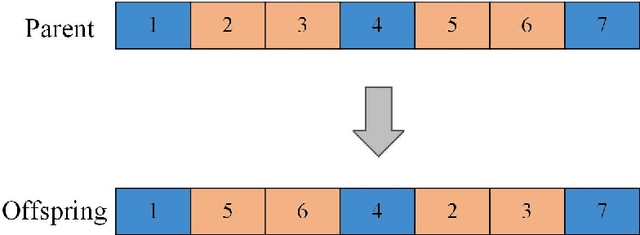

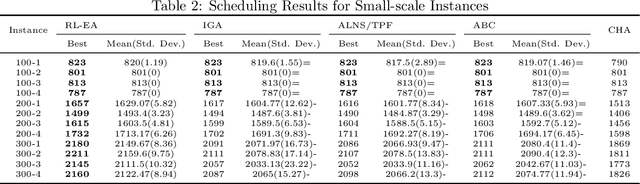
The study of electromagnetic detection satellite scheduling problem (EDSSP) has attracted attention due to the detection requirements for a large number of targets. This paper proposes a mixed-integer programming model for the EDSSP problem and an evolutionary algorithm framework based on reinforcement learning (RL-EA). Numerous factors that affect electromagnetic detection are considered in the model, such as detection mode, bandwidth, and other factors. The evolutionary algorithm framework based on reinforcement learning uses the Q-learning framework, and each individual in the population is regarded as an agent. Based on the proposed framework, a Q-learning-based genetic algorithm(QGA) is designed. Q-learning is used to guide the population search process by choosing variation operators. In the algorithm, we design a reward function to update the Q value. According to the problem characteristics, a new combination of <state, action> is proposed. The QGA also uses an elite individual retention strategy to improve search performance. After that, a task time window selection algorithm is proposed To evaluate the performance of population evolution. Various scales experiments are used to examine the planning effect of the proposed algorithm. Through the experimental verification of multiple instances, it can be seen that the QGA can solve the EDSSP problem effectively. Compared with the state-of-the-art algorithms, the QGA algorithm performs better in several aspects.
Feature-weighted Stacking for Nonseasonal Time Series Forecasts: A Case Study of the COVID-19 Epidemic Curves
Aug 20, 2021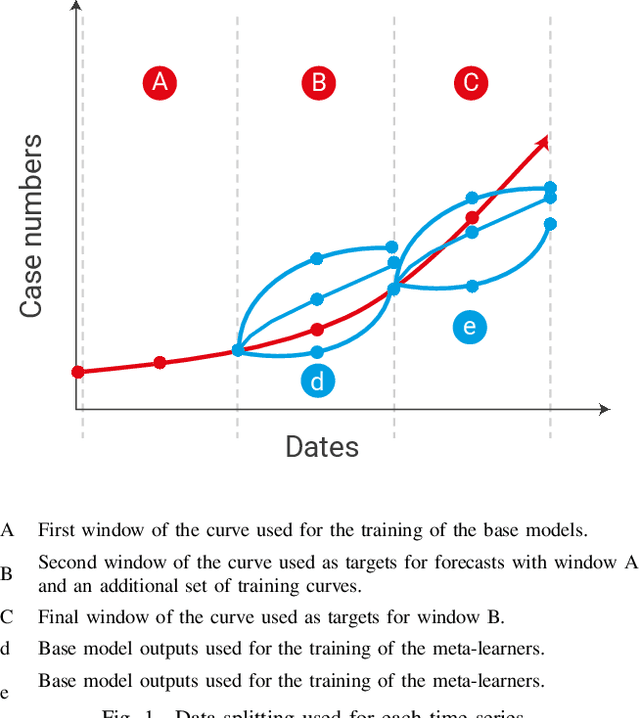
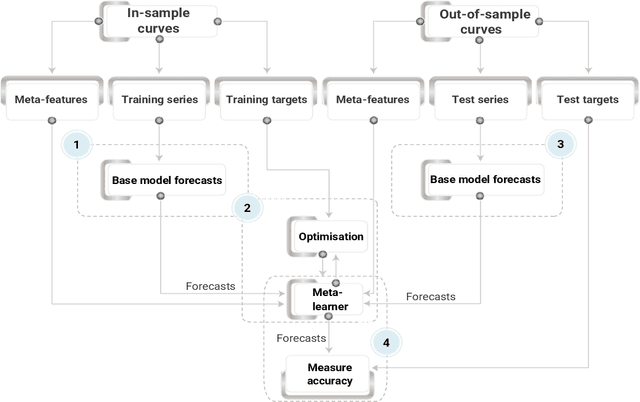
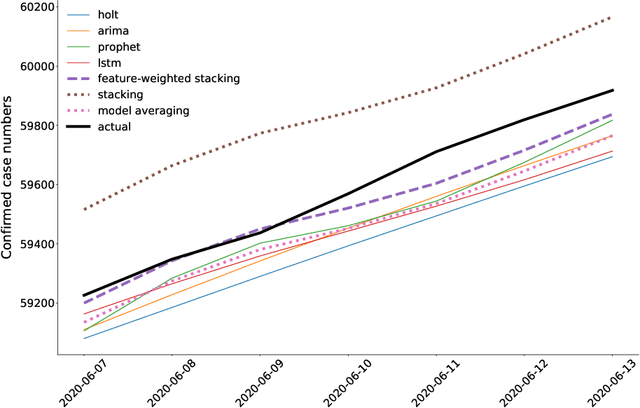
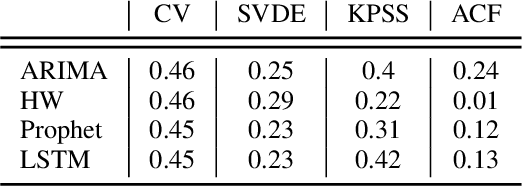
We investigate ensembling techniques in forecasting and examine their potential for use in nonseasonal time-series similar to those in the early days of the COVID-19 pandemic. Developing improved forecast methods is essential as they provide data-driven decisions to organisations and decision-makers during critical phases. We propose using late data fusion, using a stacked ensemble of two forecasting models and two meta-features that prove their predictive power during a preliminary forecasting stage. The final ensembles include a Prophet and long short term memory (LSTM) neural network as base models. The base models are combined by a multilayer perceptron (MLP), taking into account meta-features that indicate the highest correlation with each base model's forecast accuracy. We further show that the inclusion of meta-features generally improves the ensemble's forecast accuracy across two forecast horizons of seven and fourteen days. This research reinforces previous work and demonstrates the value of combining traditional statistical models with deep learning models to produce more accurate forecast models for time-series from different domains and seasonality.
An Optimization Method-Assisted Ensemble Deep Reinforcement Learning Algorithm to Solve Unit Commitment Problems
Jun 09, 2022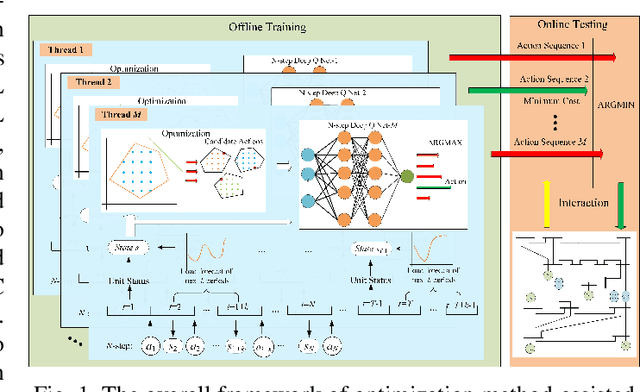
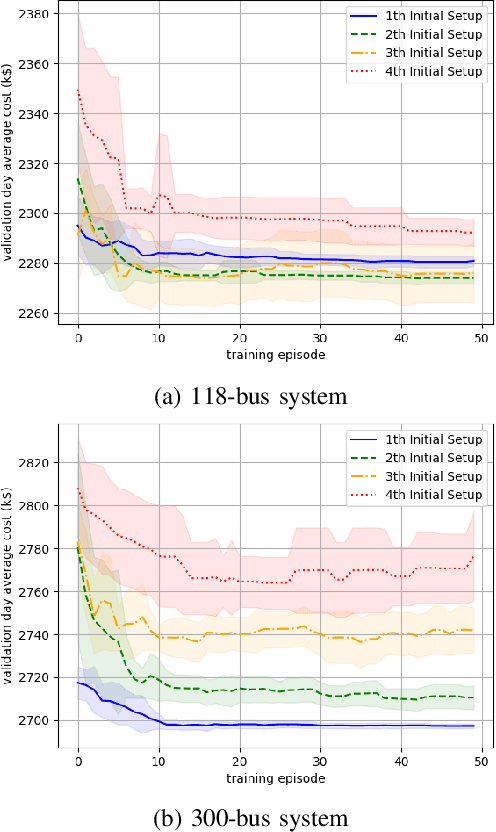
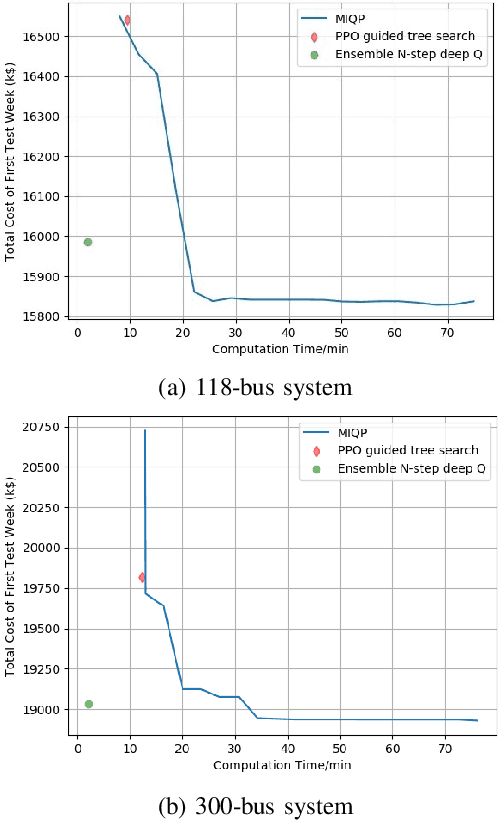
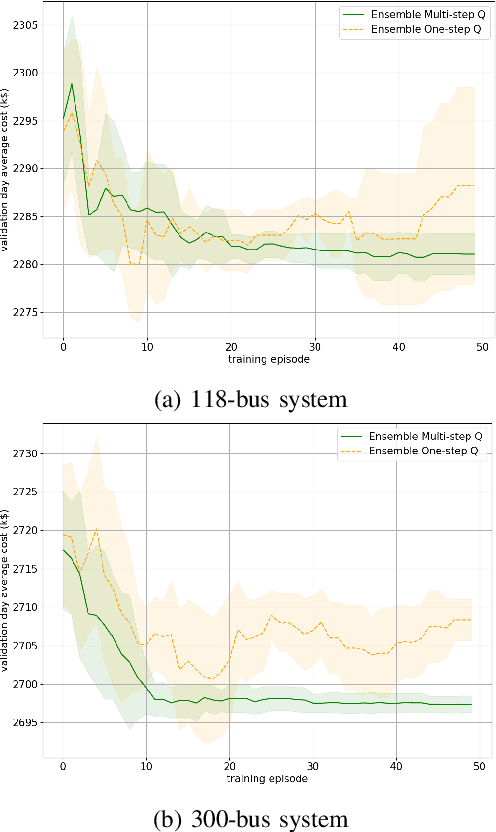
Unit commitment (UC) is a fundamental problem in the day-ahead electricity market, and it is critical to solve UC problems efficiently. Mathematical optimization techniques like dynamic programming, Lagrangian relaxation, and mixed-integer quadratic programming (MIQP) are commonly adopted for UC problems. However, the calculation time of these methods increases at an exponential rate with the amount of generators and energy resources, which is still the main bottleneck in industry. Recent advances in artificial intelligence have demonstrated the capability of reinforcement learning (RL) to solve UC problems. Unfortunately, the existing research on solving UC problems with RL suffers from the curse of dimensionality when the size of UC problems grows. To deal with these problems, we propose an optimization method-assisted ensemble deep reinforcement learning algorithm, where UC problems are formulated as a Markov Decision Process (MDP) and solved by multi-step deep Q-learning in an ensemble framework. The proposed algorithm establishes a candidate action set by solving tailored optimization problems to ensure a relatively high performance and the satisfaction of operational constraints. Numerical studies on IEEE 118 and 300-bus systems show that our algorithm outperforms the baseline RL algorithm and MIQP. Furthermore, the proposed algorithm shows strong generalization capacity under unforeseen operational conditions.
VectorAdam for Rotation Equivariant Geometry Optimization
May 26, 2022
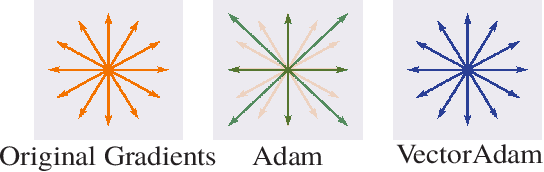

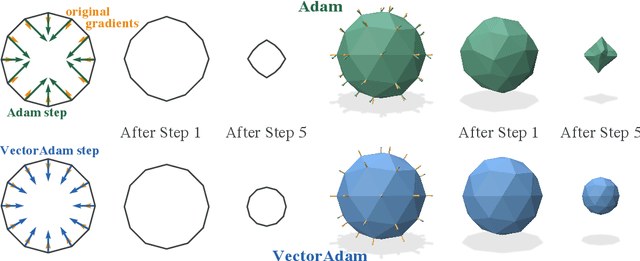
The rise of geometric problems in machine learning has necessitated the development of equivariant methods, which preserve their output under the action of rotation or some other transformation. At the same time, the Adam optimization algorithm has proven remarkably effective across machine learning and even traditional tasks in geometric optimization. In this work, we observe that naively applying Adam to optimize vector-valued data is not rotation equivariant, due to per-coordinate moment updates, and in fact this leads to significant artifacts and biases in practice. We propose to resolve this deficiency with VectorAdam, a simple modification which makes Adam rotation-equivariant by accounting for the vector structure of optimization variables. We demonstrate this approach on problems in machine learning and traditional geometric optimization, showing that equivariant VectorAdam resolves the artifacts and biases of traditional Adam when applied to vector-valued data, with equivalent or even improved rates of convergence.
Learning code summarization from a small and local dataset
Jun 02, 2022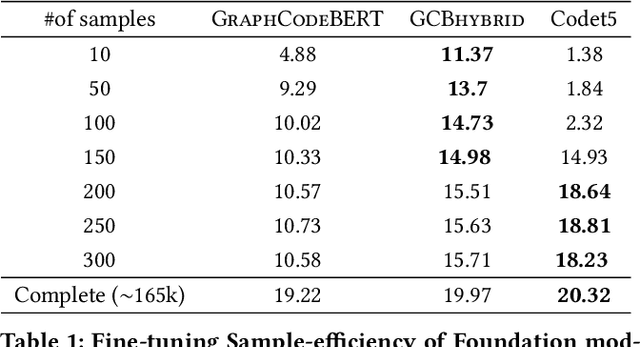

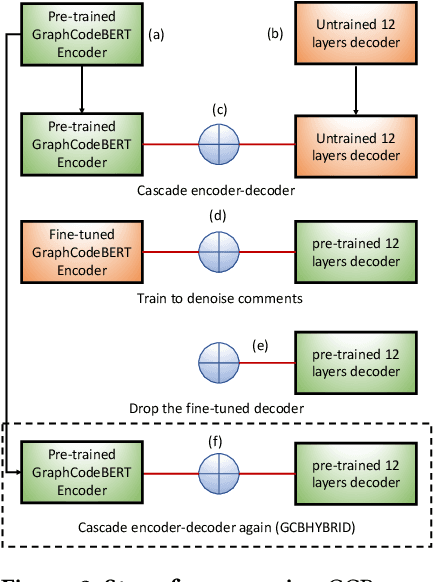
Foundation models (e.g., CodeBERT, GraphCodeBERT, CodeT5) work well for many software engineering tasks. These models are pre-trained (using self-supervision) with billions of code tokens, and then fine-tuned with hundreds of thousands of labeled examples, typically drawn from many projects. However, software phenomena can be very project-specific. Vocabulary, and other phenomena vary substantially with each project. Thus, training on project-specific data, and testing on the same project, is a promising idea. This hypothesis has to be evaluated carefully, e.g., in a time-series setting, to prevent training-test leakage. We compare several models and training approaches, including same-project training, cross-project training, training a model especially designed to be sample efficient (and thus prima facie well-suited for learning in a limited-sample same-project setting) and a maximalist hybrid approach, fine-tuning first on many projects in many languages and then training on the same-project. We find that the maximalist hybrid setting provides consistent, substantial gains over the state-of-the-art, on many different projects in both Java and Python.
Molecular dynamics without molecules: searching the conformational space of proteins with generative neural networks
Jun 09, 2022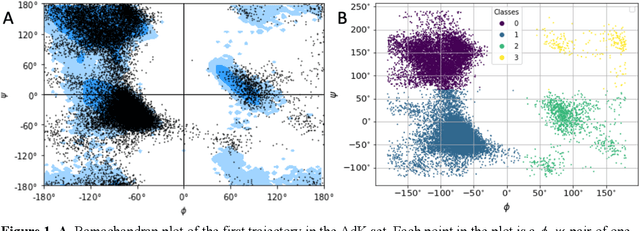
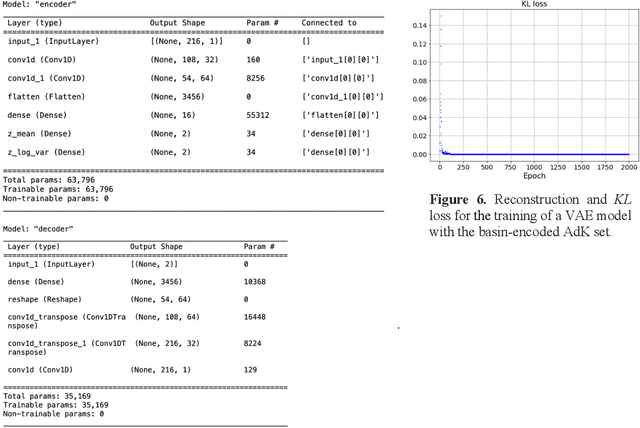
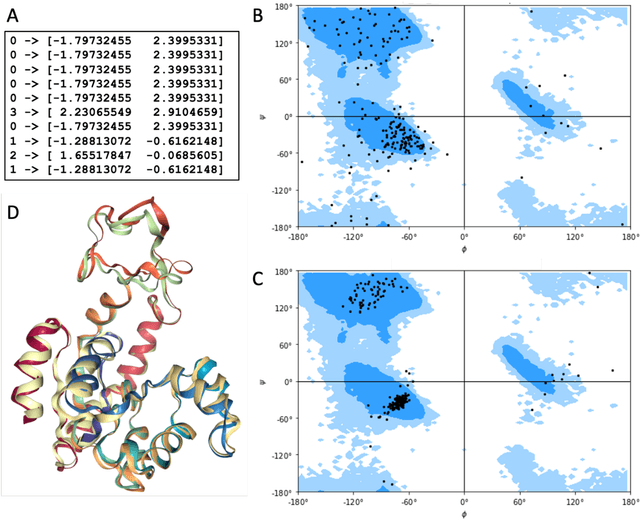
All-atom and coarse-grained molecular dynamics are two widely used computational tools to study the conformational states of proteins. Yet, these two simulation methods suffer from the fact that without access to supercomputing resources, the time and length scales at which these states become detectable are difficult to achieve. One alternative to such methods is based on encoding the atomistic trajectory of molecular dynamics as a shorthand version devoid of physical particles, and then learning to propagate the encoded trajectory through the use of artificial intelligence. Here we show that a simple textual representation of the frames of molecular dynamics trajectories as vectors of Ramachandran basin classes retains most of the structural information of the full atomistic representation of a protein in each frame, and can be used to generate equivalent atom-less trajectories suitable to train different types of generative neural networks. In turn, the trained generative models can be used to extend indefinitely the atom-less dynamics or to sample the conformational space of proteins from their representation in the models latent space. We define intuitively this methodology as molecular dynamics without molecules, and show that it enables to cover physically relevant states of proteins that are difficult to access with traditional molecular dynamics.
Robust Experimentation in the Continuous Time Bandit Problem
Mar 31, 2021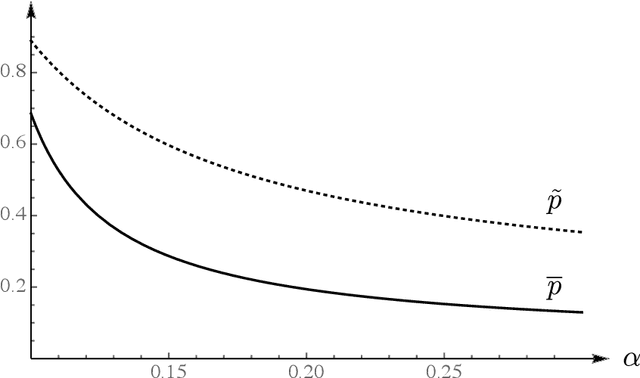
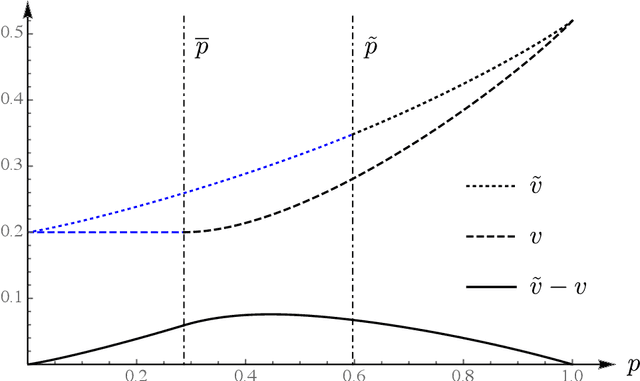
We study the experimentation dynamics of a decision maker (DM) in a two-armed bandit setup (Bolton and Harris (1999)), where the agent holds ambiguous beliefs regarding the distribution of the return process of one arm and is certain about the other one. The DM entertains Multiplier preferences a la Hansen and Sargent (2001), thus we frame the decision making environment as a two-player differential game against nature in continuous time. We characterize the DM value function and her optimal experimentation strategy that turns out to follow a cut-off rule with respect to her belief process. The belief threshold for exploring the ambiguous arm is found in closed form and is shown to be increasing with respect to the ambiguity aversion index. We then study the effect of provision of an unambiguous information source about the ambiguous arm. Interestingly, we show that the exploration threshold rises unambiguously as a result of this new information source, thereby leading to more conservatism. This analysis also sheds light on the efficient time to reach for an expert opinion.