 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dataset Distillation using Neural Feature Regression
Jun 01, 2022

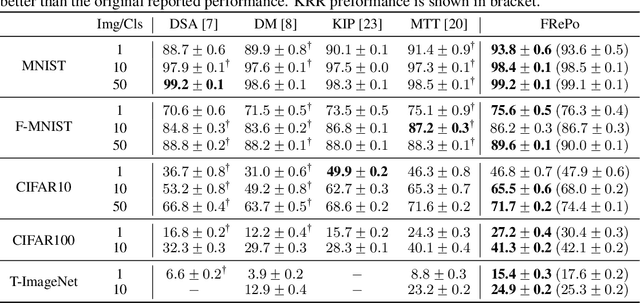
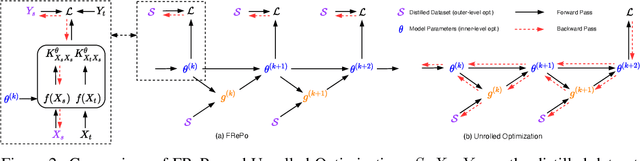

Dataset distillation aims to learn a small synthetic dataset that preserves most of the information from the original dataset. Dataset distillation can be formulated as a bi-level meta-learning problem where the outer loop optimizes the meta-dataset and the inner loop trains a model on the distilled data. Meta-gradient computation is one of the key challenges in this formulation, as differentiating through the inner loop learning procedure introduces significant computation and memory costs. In this paper, we address these challenges using neural Feature Regression with Pooling (FRePo), achieving the state-of-the-art performance with an order of magnitude less memory requirement and two orders of magnitude faster training than previous methods. The proposed algorithm is analogous to truncated backpropagation through time with a pool of models to alleviate various types of overfitting in dataset distillation. FRePo significantly outperforms the previous methods on CIFAR100, Tiny ImageNet, and ImageNet-1K. Furthermore, we show that high-quality distilled data can greatly improve various downstream applications, such as continual learning and membership inference defense.
Receding Moving Object Segmentation in 3D LiDAR Data Using Sparse 4D Convolutions
Jun 08, 2022
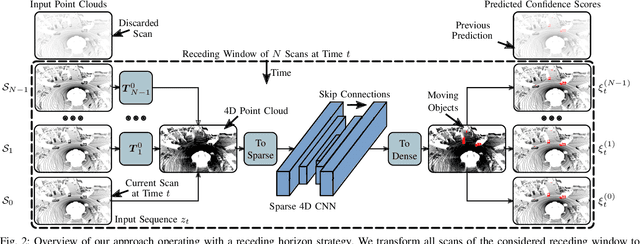
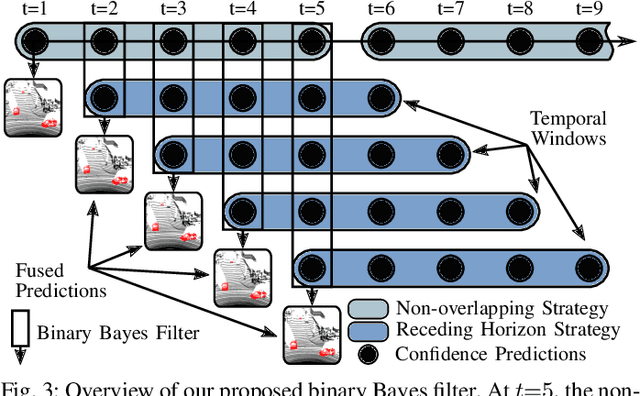
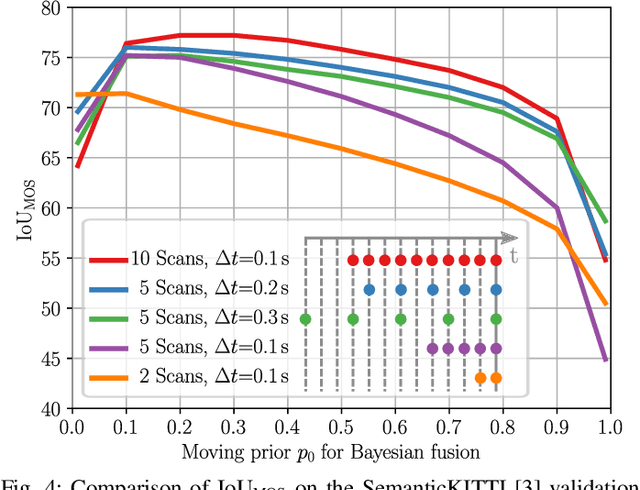
A key challenge for autonomous vehicles is to navigate in unseen dynamic environments. Separating moving objects from static ones is essential for navigation, pose estimation, and understanding how other traffic participants are likely to move in the near future. In this work, we tackle the problem of distinguishing 3D LiDAR points that belong to currently moving objects, like walking pedestrians or driving cars, from points that are obtained from non-moving objects, like walls but also parked cars. Our approach takes a sequence of observed LiDAR scans and turns them into a voxelized sparse 4D point cloud. We apply computationally efficient sparse 4D convolutions to jointly extract spatial and temporal features and predict moving object confidence scores for all points in the sequence. We develop a receding horizon strategy that allows us to predict moving objects online and to refine predictions on the go based on new observations. We use a binary Bayes filter to recursively integrate new predictions of a scan resulting in more robust estimation. We evaluate our approach on the SemanticKITTI moving object segmentation challenge and show more accurate predictions than existing methods. Since our approach only operates on the geometric information of point clouds over time, it generalizes well to new, unseen environments, which we evaluate on the Apollo dataset.
Optimal Decision Diagrams for Classification
May 28, 2022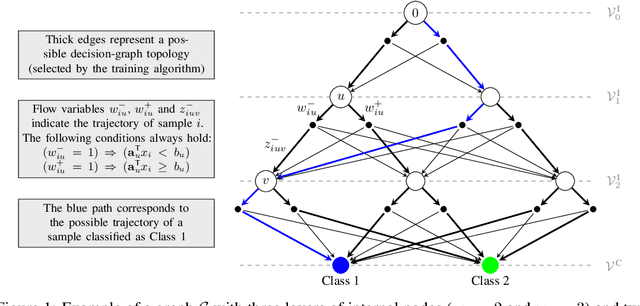
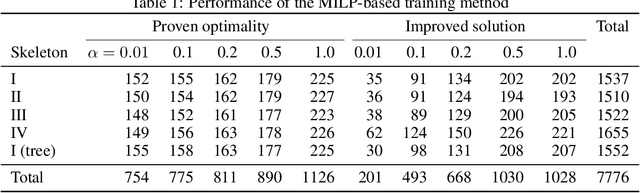
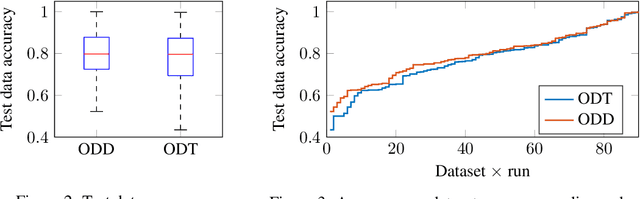
Decision diagrams for classification have some notable advantages over decision trees, as their internal connections can be determined at training time and their width is not bound to grow exponentially with their depth. Accordingly, decision diagrams are usually less prone to data fragmentation in internal nodes. However, the inherent complexity of training these classifiers acted as a long-standing barrier to their widespread adoption. In this context, we study the training of optimal decision diagrams (ODDs) from a mathematical programming perspective. We introduce a novel mixed-integer linear programming model for training and demonstrate its applicability for many datasets of practical importance. Further, we show how this model can be easily extended for fairness, parsimony, and stability notions. We present numerical analyses showing that our model allows training ODDs in short computational times, and that ODDs achieve better accuracy than optimal decision trees, while allowing for improved stability without significant accuracy losses.
Speech Artifact Removal from EEG Recordings of Spoken Word Production with Tensor Decomposition
Jun 01, 2022
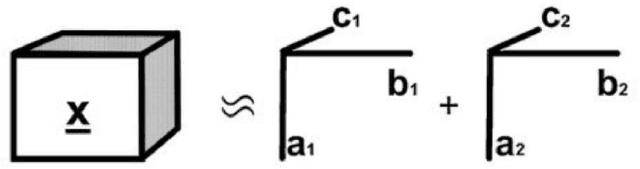
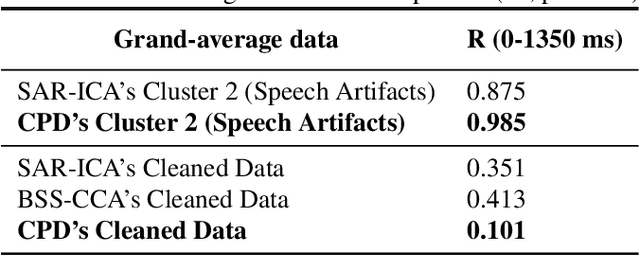
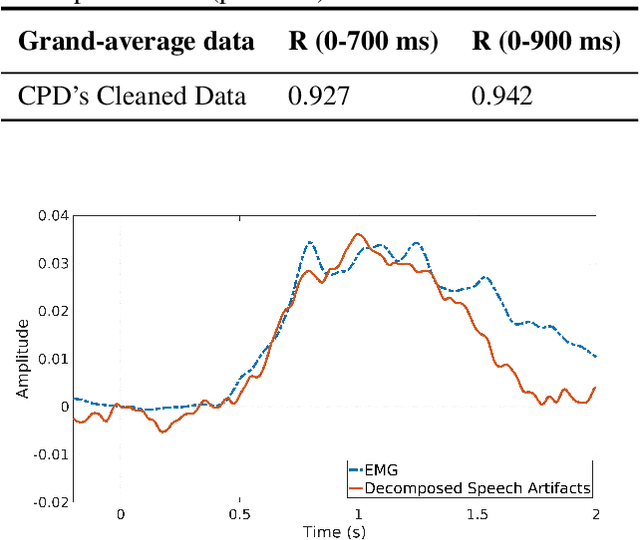
Research about brain activities involving spoken word production is considerably underdeveloped because of the undiscovered characteristics of speech artifacts, which contaminate electroencephalogram (EEG) signals and prevent the inspection of the underlying cognitive processes. To fuel further EEG research with speech production, a method using three-mode tensor decomposition (time x space x frequency) is proposed to perform speech artifact removal. Tensor decomposition enables simultaneous inspection of multiple modes, which suits the multi-way nature of EEG data. In a picture-naming task, we collected raw data with speech artifacts by placing two electrodes near the mouth to record lip EMG. Based on our evaluation, which calculated the correlation values between grand-averaged speech artifacts and the lip EMG, tensor decomposition outperformed the former methods that were based on independent component analysis (ICA) and blind source separation (BSS), both in detecting speech artifact (0.985) and producing clean data (0.101). Our proposed method correctly preserved the components unrelated to speech, which was validated by computing the correlation value between the grand-averaged raw data without EOG and cleaned data before the speech onset (0.92-0.94).
ShapePU: A New PU Learning Framework Regularized by Global Consistency for Scribble Supervised Cardiac Segmentation
Jun 05, 2022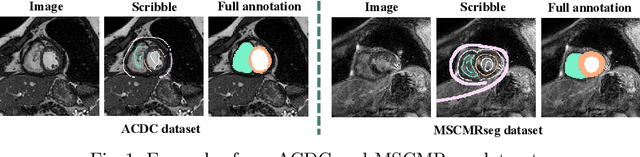

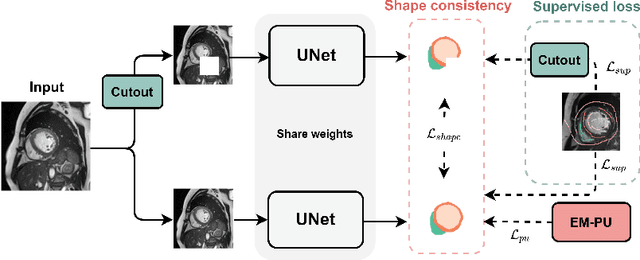
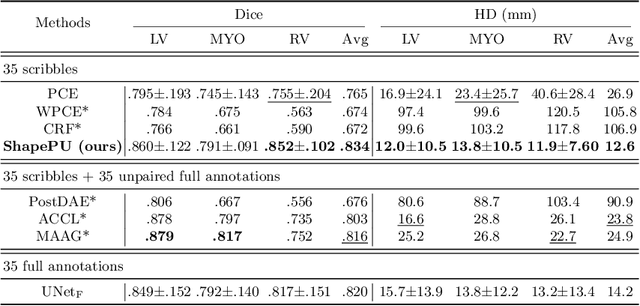
Cardiac segmentation is an essential step for the diagnosis of cardiovascular diseases. However, pixel-wise dense labeling is both costly and time-consuming. Scribble, as a form of sparse annotation, is more accessible than full annotations. However, it's particularly challenging to train a segmentation network with weak supervision from scribbles. To tackle this problem, we propose a new scribble-guided method for cardiac segmentation, based on the Positive-Unlabeled (PU) learning framework and global consistency regularization, and termed as ShapePU. To leverage unlabeled pixels via PU learning, we first present an Expectation-Maximization (EM) algorithm to estimate the proportion of each class in the unlabeled pixels. Given the estimated ratios, we then introduce the marginal probability maximization to identify the classes of unlabeled pixels. To exploit shape knowledge, we apply cutout operations to training images, and penalize the inconsistent segmentation results. Evaluated on two open datasets, i.e, ACDC and MSCMRseg, our scribble-supervised ShapePU surpassed the fully supervised approach respectively by 1.4% and 9.8% in average Dice, and outperformed the state-of-the-art weakly supervised and PU learning methods by large margins. Our code is available at https://github.com/BWGZK/ShapePU.
Learning Binarized Graph Representations with Multi-faceted Quantization Reinforcement for Top-K Recommendation
Jun 05, 2022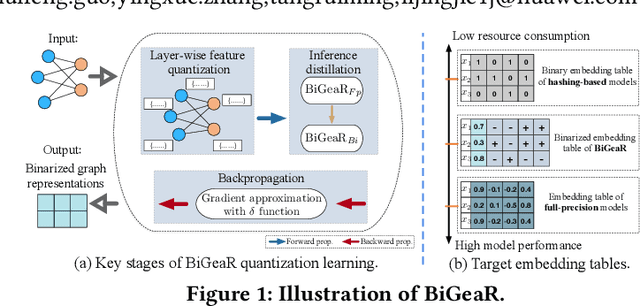
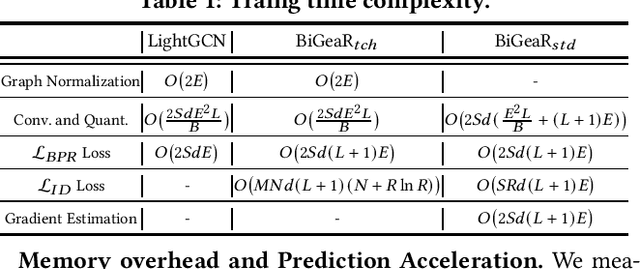
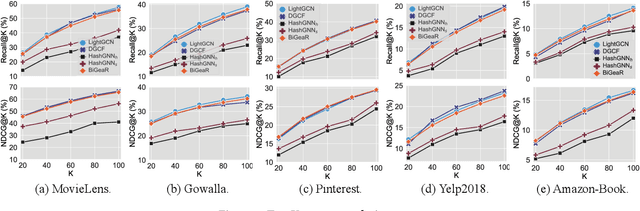
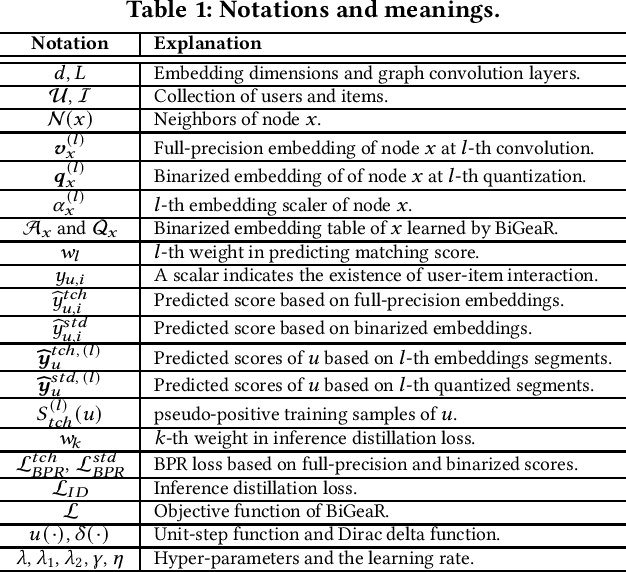
Learning vectorized embeddings is at the core of various recommender systems for user-item matching. To perform efficient online inference, representation quantization, aiming to embed the latent features by a compact sequence of discrete numbers, recently shows the promising potentiality in optimizing both memory and computation overheads. However, existing work merely focuses on numerical quantization whilst ignoring the concomitant information loss issue, which, consequently, leads to conspicuous performance degradation. In this paper, we propose a novel quantization framework to learn Binarized Graph Representations for Top-K Recommendation (BiGeaR). BiGeaR introduces multi-faceted quantization reinforcement at the pre-, mid-, and post-stage of binarized representation learning, which substantially retains the representation informativeness against embedding binarization. In addition to saving the memory footprint, BiGeaR further develops solid online inference acceleration with bitwise operations, providing alternative flexibility for the realistic deployment. The empirical results over five large real-world benchmarks show that BiGeaR achieves about 22%~40% performance improvement over the state-of-the-art quantization-based recommender system, and recovers about 95%~102% of the performance capability of the best full-precision counterpart with over 8x time and space reduction.
Deep Learning Techniques for Visual Counting
Jun 08, 2022
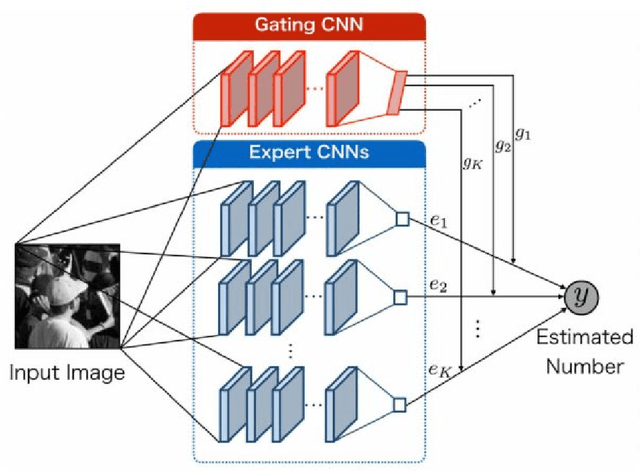
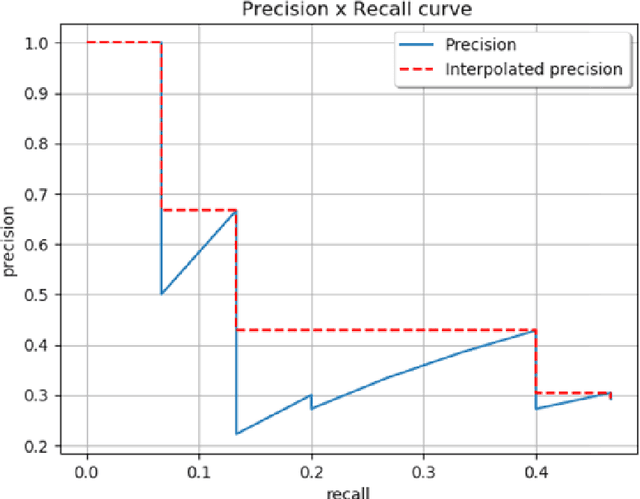
In this dissertation, we investigated and enhanced Deep Learning (DL) techniques for counting objects, like pedestrians, cells or vehicles, in still images or video frames. In particular, we tackled the challenge related to the lack of data needed for training current DL-based solutions. Given that the budget for labeling is limited, data scarcity still represents an open problem that prevents the scalability of existing solutions based on the supervised learning of neural networks and that is responsible for a significant drop in performance at inference time when new scenarios are presented to these algorithms. We introduced solutions addressing this issue from several complementary sides, collecting datasets gathered from virtual environments automatically labeled, proposing Domain Adaptation strategies aiming at mitigating the domain gap existing between the training and test data distributions, and presenting a counting strategy in a weakly labeled data scenario, i.e., in the presence of non-negligible disagreement between multiple annotators. Moreover, we tackled the non-trivial engineering challenges coming out of the adoption of Convolutional Neural Network-based techniques in environments with limited power resources, introducing solutions for counting vehicles and pedestrians directly onboard embedded vision systems, i.e., devices equipped with constrained computational capabilities that can capture images and elaborate them.
Design and Mathematical Modelling of Inter Spike Interval of Temporal Neuromorphic Encoder for Image Recognition
May 19, 2022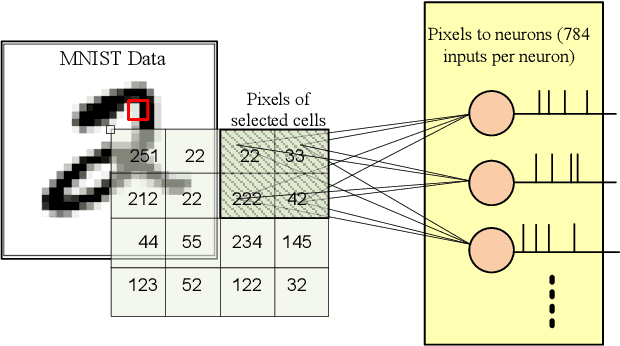
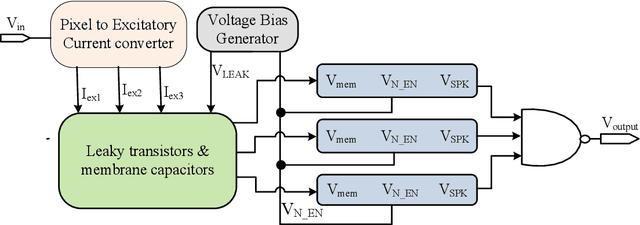
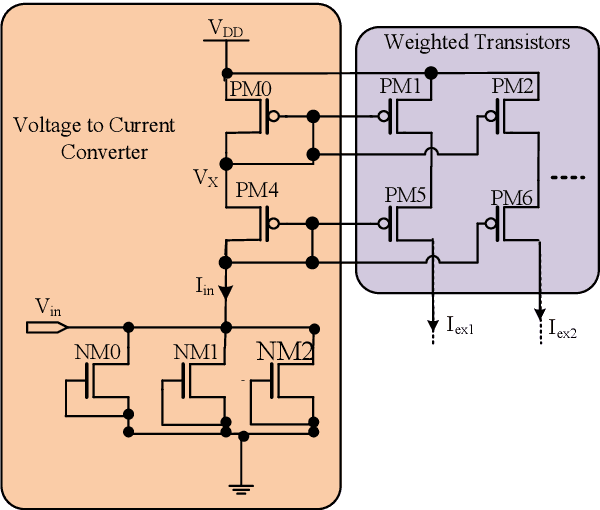
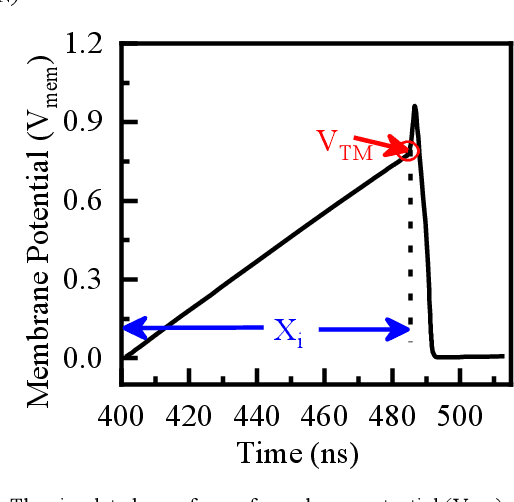
Neuromorphic computing systems emulate the electrophysiological behavior of the biological nervous system using mixed-mode analog or digital VLSI circuits. These systems show superior accuracy and power efficiency in carrying out cognitive tasks. The neural network architecture used in neuromorphic computing systems is spiking neural networks (SNNs) analogous to the biological nervous system. SNN operates on spike trains as a function of time. A neuromorphic encoder converts sensory data into spike trains. In this paper, a low-power neuromorphic encoder for image processing is implemented. A mathematical model between pixels of an image and the inter-spike intervals is also formulated. Wherein an exponential relationship between pixels and inter-spike intervals is obtained. Finally, the mathematical equation is validated with circuit simulation.
Variance Reduction is an Antidote to Byzantines: Better Rates, Weaker Assumptions and Communication Compression as a Cherry on the Top
Jun 01, 2022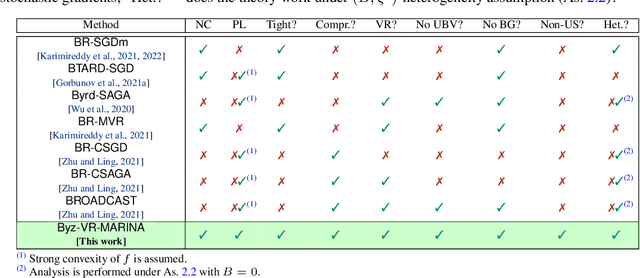
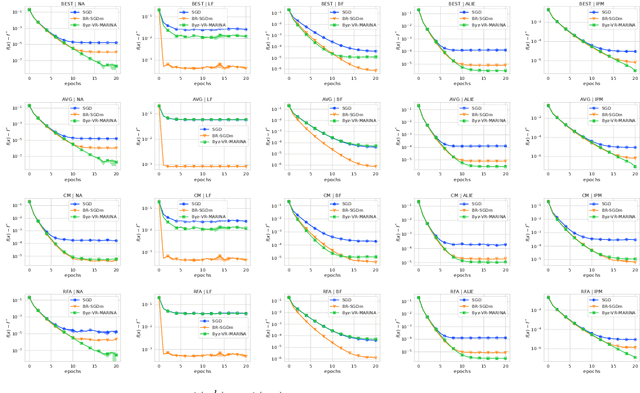
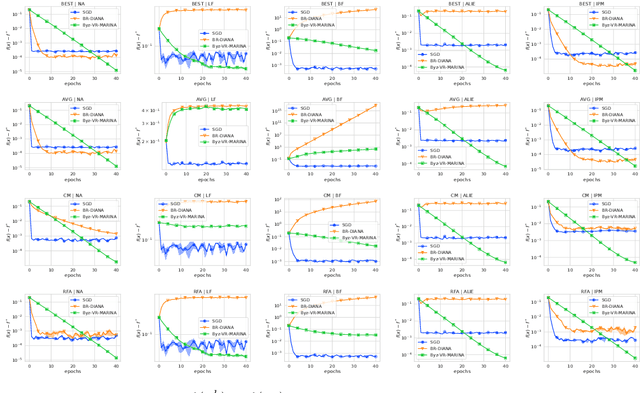
Byzantine-robustness has been gaining a lot of attention due to the growth of the interest in collaborative and federated learning. However, many fruitful directions, such as the usage of variance reduction for achieving robustness and communication compression for reducing communication costs, remain weakly explored in the field. This work addresses this gap and proposes Byz-VR-MARINA - a new Byzantine-tolerant method with variance reduction and compression. A key message of our paper is that variance reduction is key to fighting Byzantine workers more effectively. At the same time, communication compression is a bonus that makes the process more communication efficient. We derive theoretical convergence guarantees for Byz-VR-MARINA outperforming previous state-of-the-art for general non-convex and Polyak-Lojasiewicz loss functions. Unlike the concurrent Byzantine-robust methods with variance reduction and/or compression, our complexity results are tight and do not rely on restrictive assumptions such as boundedness of the gradients or limited compression. Moreover, we provide the first analysis of a Byzantine-tolerant method supporting non-uniform sampling of stochastic gradients. Numerical experiments corroborate our theoretical findings.
Unsupervised Representation Learning for 3D MRI Super Resolution with Degradation Adaptation
May 13, 2022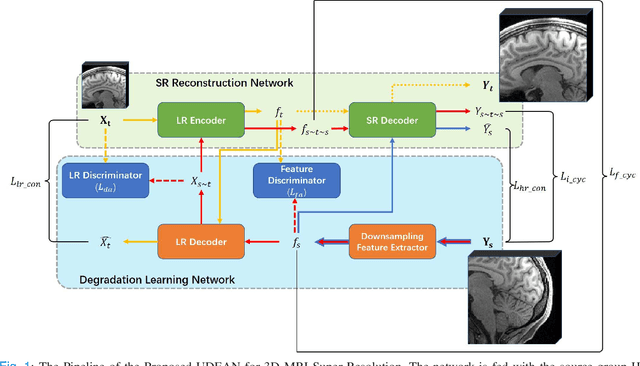
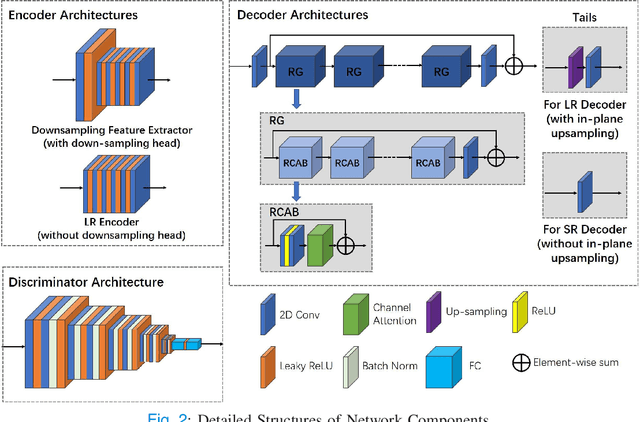
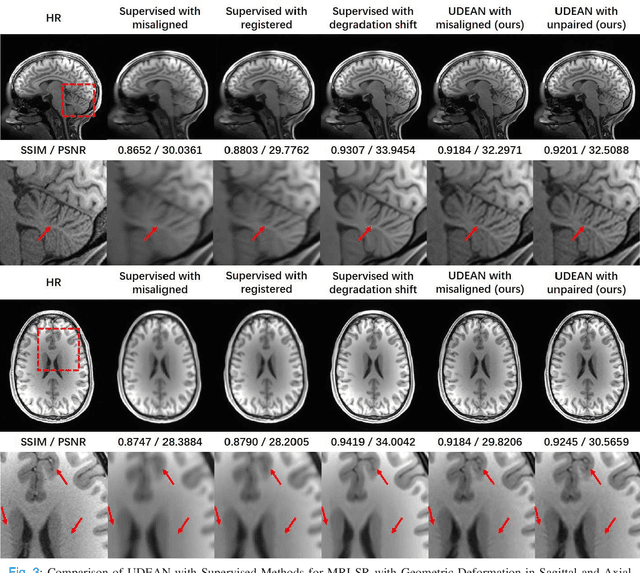
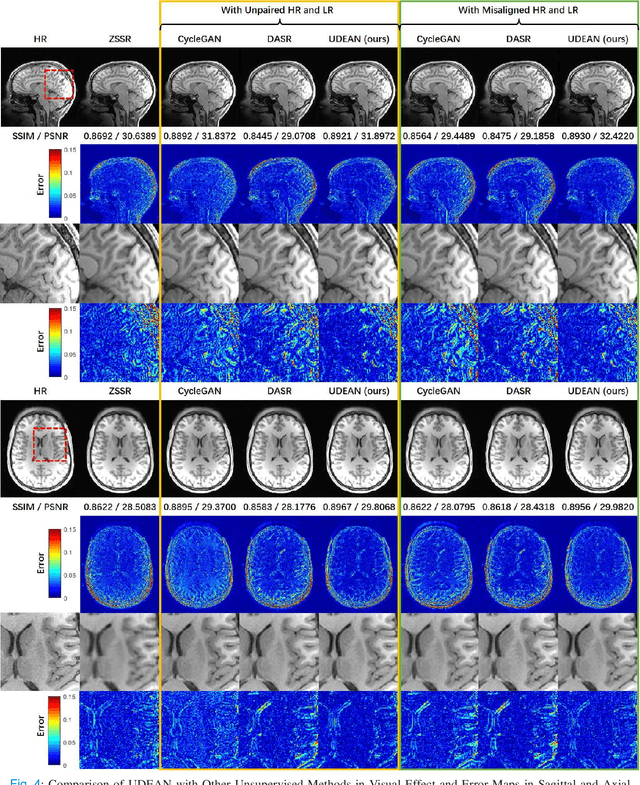
High-resolution (HR) MRI is critical in assisting the doctor's diagnosis and image-guided treatment, but is hard to obtain in a clinical setting due to long acquisition time. Therefore, the research community investigated deep learning-based super-resolution (SR) technology to reconstruct HR MRI images with shortened acquisition time. However, training such neural networks usually requires paired HR and low-resolution (LR) in-vivo images, which are difficult to acquire due to patient movement during and between the image acquisition. Rigid movements of hard tissues can be corrected with image-registration, whereas the alignment of deformed soft tissues is challenging, making it impractical to train the neural network with such authentic HR and LR image pairs. Therefore, most of the previous studies proposed SR reconstruction by employing authentic HR images and synthetic LR images downsampled from the HR images, yet the difference in degradation representations between synthetic and authentic LR images suppresses the performance of SR reconstruction from authentic LR images. To mitigate the aforementioned problems, we propose a novel Unsupervised DEgradation Adaptation Network (UDEAN). Our model consists of two components: the degradation learning network and the SR reconstruction network. The degradation learning network downsamples the HR images by addressing the degradation representation of the misaligned or unpaired LR images, and the SR reconstruction network learns the mapping from the downsampled HR images to their original HR images. As a result, the SR reconstruction network can generate SR images from the LR images and achieve comparable quality to the HR images. Experimental results show that our method outperforms the state-of-the-art models and can potentially be applied in real-world clinical settings.