 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RACA: Relation-Aware Credit Assignment for Ad-Hoc Cooperation in Multi-Agent Deep Reinforcement Learning
Jun 02, 2022
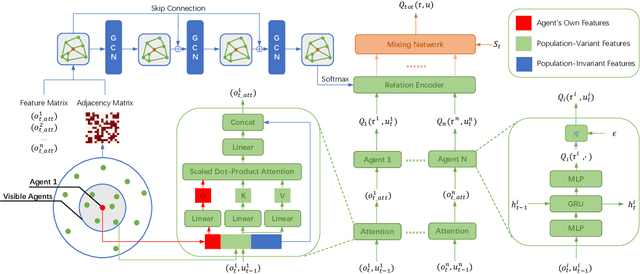
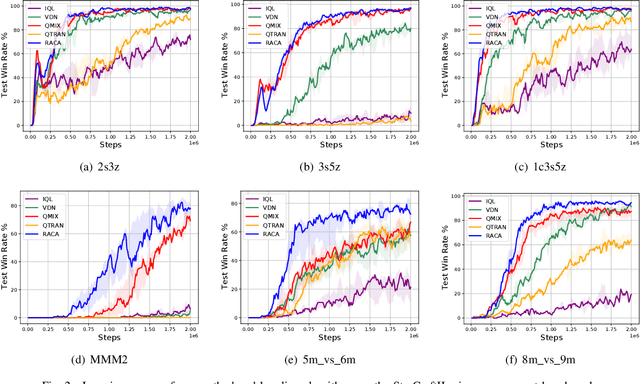
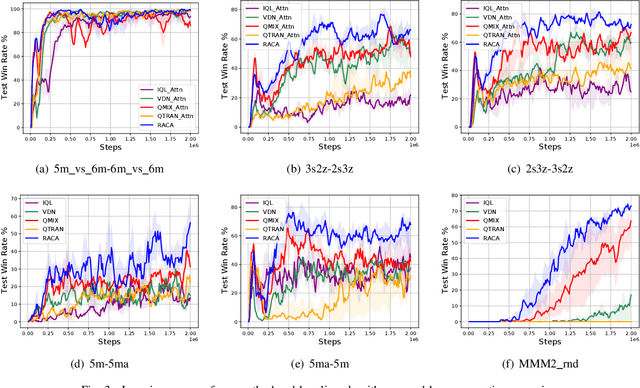
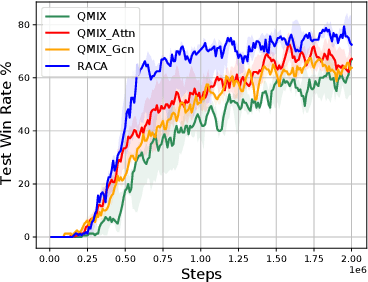
In recent years, reinforcement learning has faced several challenges in the multi-agent domain, such as the credit assignment issue. Value function factorization emerges as a promising way to handle the credit assignment issue under the centralized training with decentralized execution (CTDE) paradigm. However, existing value function factorization methods cannot deal with ad-hoc cooperation, that is, adapting to new configurations of teammates at test time. Specifically, these methods do not explicitly utilize the relationship between agents and cannot adapt to different sizes of inputs. To address these limitations, we propose a novel method, called Relation-Aware Credit Assignment (RACA), which achieves zero-shot generalization in ad-hoc cooperation scenarios. RACA takes advantage of a graph-based relation encoder to encode the topological structure between agents. Furthermore, RACA utilizes an attention-based observation abstraction mechanism that can generalize to an arbitrary number of teammates with a fixed number of parameters. Experiments demonstrate that our method outperforms baseline methods on the StarCraftII micromanagement benchmark and ad-hoc cooperation scenarios.
FBSNet: A Fast Bilateral Symmetrical Network for Real-Time Semantic Segmentation
Sep 02, 2021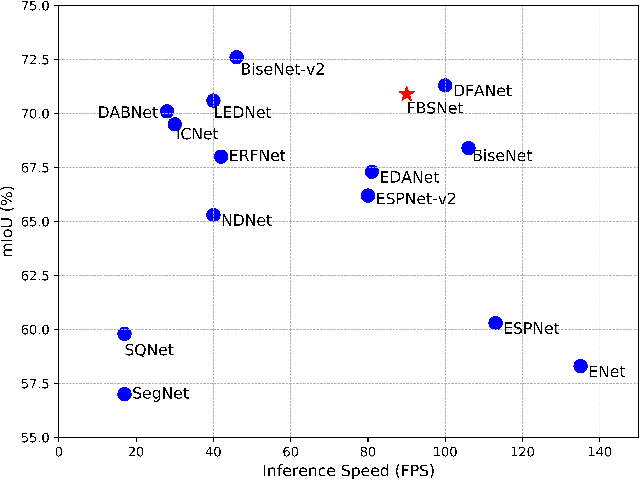
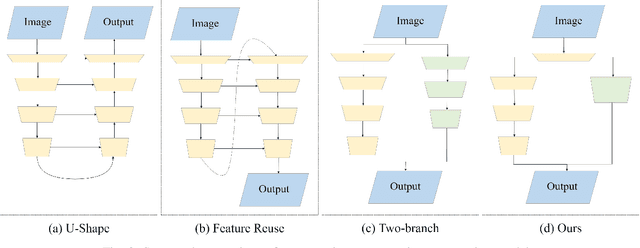
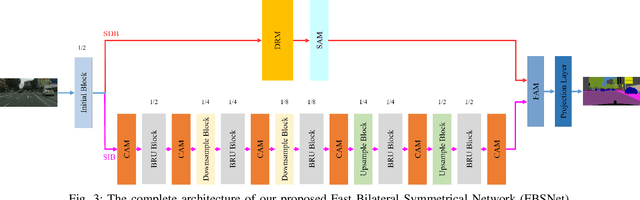
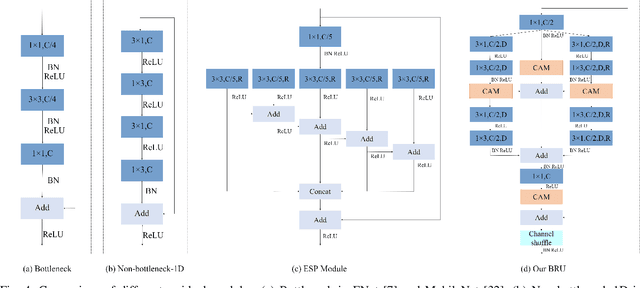
Real-time semantic segmentation, which can be visually understood as the pixel-level classification task on the input image, currently has broad application prospects, especially in the fast-developing fields of autonomous driving and drone navigation. However, the huge burden of calculation together with redundant parameters are still the obstacles to its technological development. In this paper, we propose a Fast Bilateral Symmetrical Network (FBSNet) to alleviate the above challenges. Specifically, FBSNet employs a symmetrical encoder-decoder structure with two branches, semantic information branch, and spatial detail branch. The semantic information branch is the main branch with deep network architecture to acquire the contextual information of the input image and meanwhile acquire sufficient receptive field. While spatial detail branch is a shallow and simple network used to establish local dependencies of each pixel for preserving details, which is essential for restoring the original resolution during the decoding phase. Meanwhile, a feature aggregation module (FAM) is designed to effectively combine the output features of the two branches. The experimental results of Cityscapes and CamVid show that the proposed FBSNet can strike a good balance between accuracy and efficiency. Specifically, it obtains 70.9\% and 68.9\% mIoU along with the inference speed of 90 fps and 120 fps on these two test datasets, respectively, with only 0.62 million parameters on a single RTX 2080Ti GPU.
An Optimization Method-Assisted Ensemble Deep Reinforcement Learning Algorithm to Solve Unit Commitment Problems
Jun 09, 2022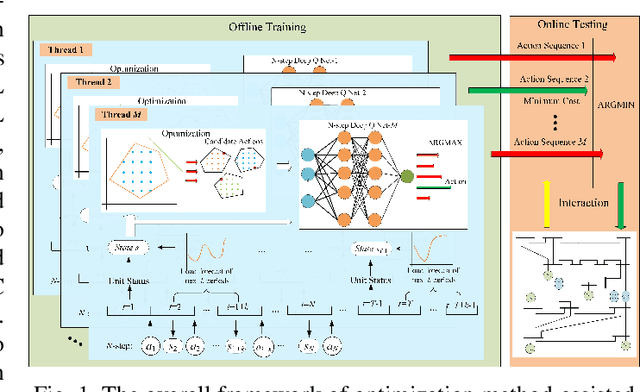
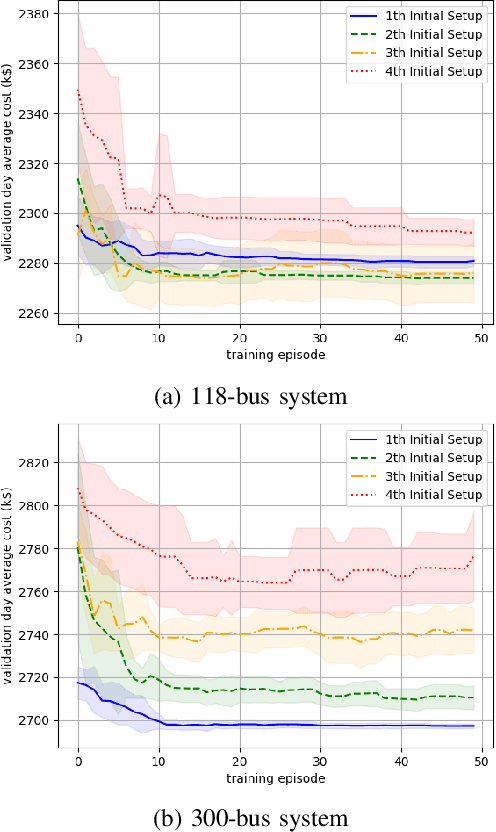
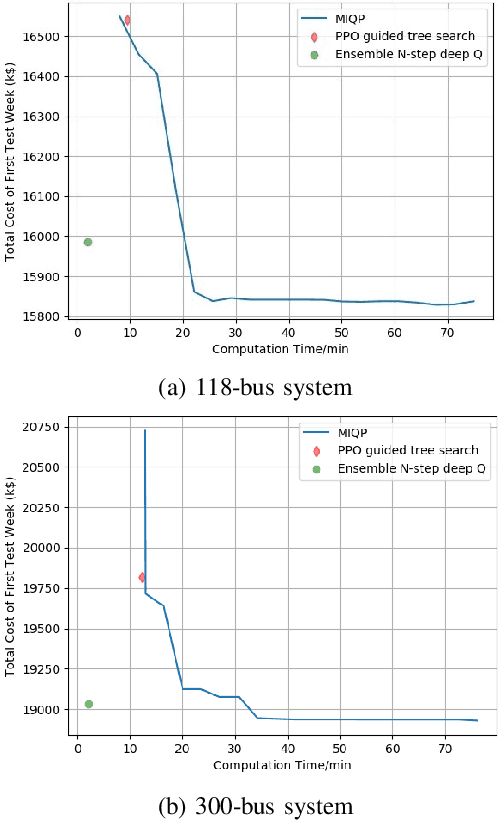
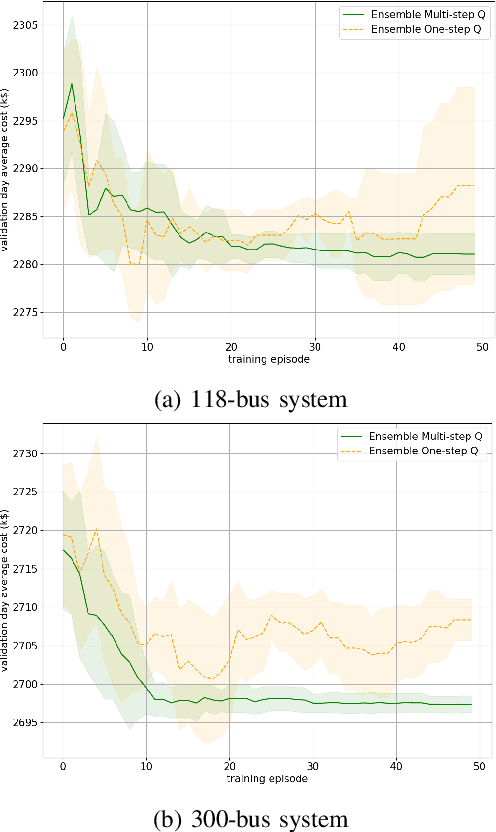
Unit commitment (UC) is a fundamental problem in the day-ahead electricity market, and it is critical to solve UC problems efficiently. Mathematical optimization techniques like dynamic programming, Lagrangian relaxation, and mixed-integer quadratic programming (MIQP) are commonly adopted for UC problems. However, the calculation time of these methods increases at an exponential rate with the amount of generators and energy resources, which is still the main bottleneck in industry. Recent advances in artificial intelligence have demonstrated the capability of reinforcement learning (RL) to solve UC problems. Unfortunately, the existing research on solving UC problems with RL suffers from the curse of dimensionality when the size of UC problems grows. To deal with these problems, we propose an optimization method-assisted ensemble deep reinforcement learning algorithm, where UC problems are formulated as a Markov Decision Process (MDP) and solved by multi-step deep Q-learning in an ensemble framework. The proposed algorithm establishes a candidate action set by solving tailored optimization problems to ensure a relatively high performance and the satisfaction of operational constraints. Numerical studies on IEEE 118 and 300-bus systems show that our algorithm outperforms the baseline RL algorithm and MIQP. Furthermore, the proposed algorithm shows strong generalization capacity under unforeseen operational conditions.
ReS2tAC -- UAV-Borne Real-Time SGM Stereo Optimized for Embedded ARM and CUDA Devices
Jun 15, 2021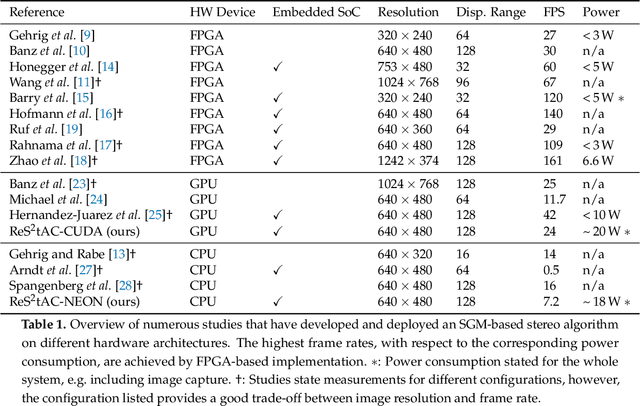

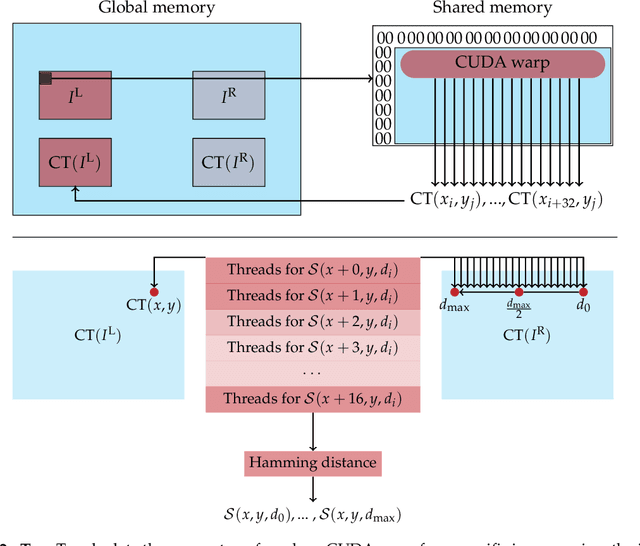
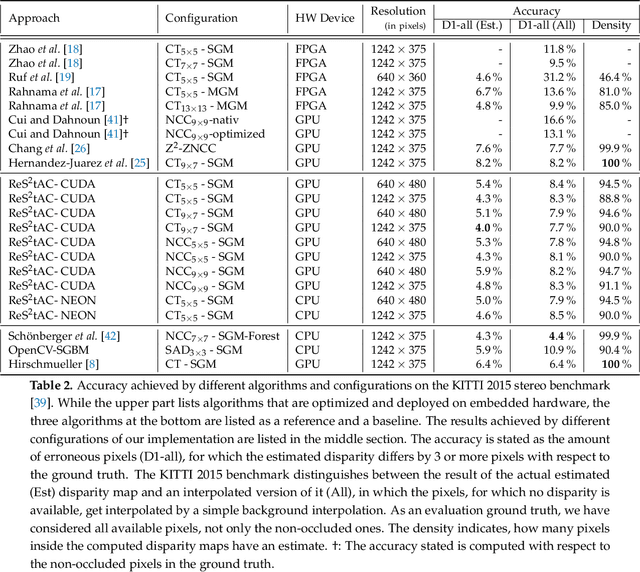
With the emergence of low-cost robotic systems, such as unmanned aerial vehicle, the importance of embedded high-performance image processing has increased. For a long time, FPGAs were the only processing hardware that were capable of high-performance computing, while at the same time preserving a low power consumption, essential for embedded systems. However, the recently increasing availability of embedded GPU-based systems, such as the NVIDIA Jetson series, comprised of an ARM CPU and a NVIDIA Tegra GPU, allows for massively parallel embedded computing on graphics hardware. With this in mind, we propose an approach for real-time embedded stereo processing on ARM and CUDA-enabled devices, which is based on the popular and widely used Semi-Global Matching algorithm. In this, we propose an optimization of the algorithm for embedded CUDA GPUs, by using massively parallel computing, as well as using the NEON intrinsics to optimize the algorithm for vectorized SIMD processing on embedded ARM CPUs. We have evaluated our approach with different configurations on two public stereo benchmark datasets to demonstrate that they can reach an error rate as low as 3.3%. Furthermore, our experiments show that the fastest configuration of our approach reaches up to 46 FPS on VGA image resolution. Finally, in a use-case specific qualitative evaluation, we have evaluated the power consumption of our approach and deployed it on the DJI Manifold 2-G attached to a DJI Matrix 210v2 RTK unmanned aerial vehicle (UAV), demonstrating its suitability for real-time stereo processing onboard a UAV.
Molecular dynamics without molecules: searching the conformational space of proteins with generative neural networks
Jun 09, 2022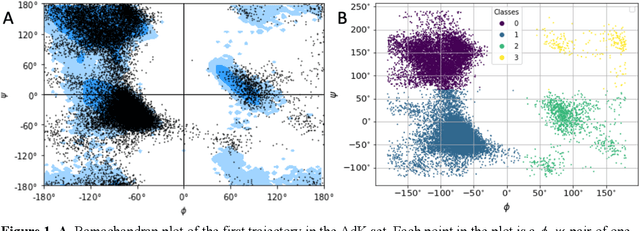
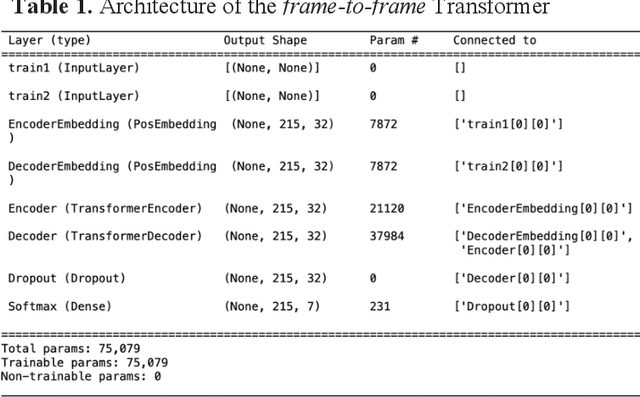
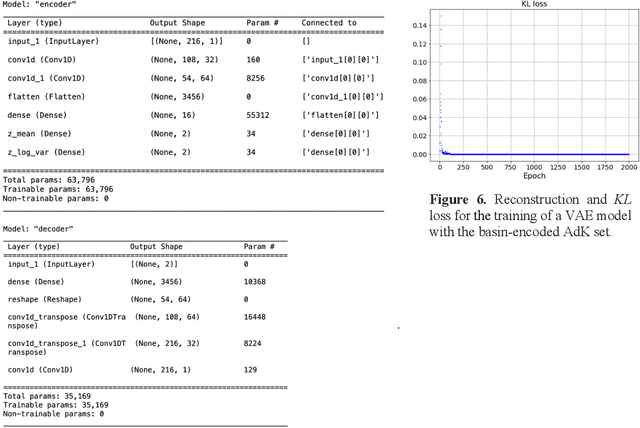
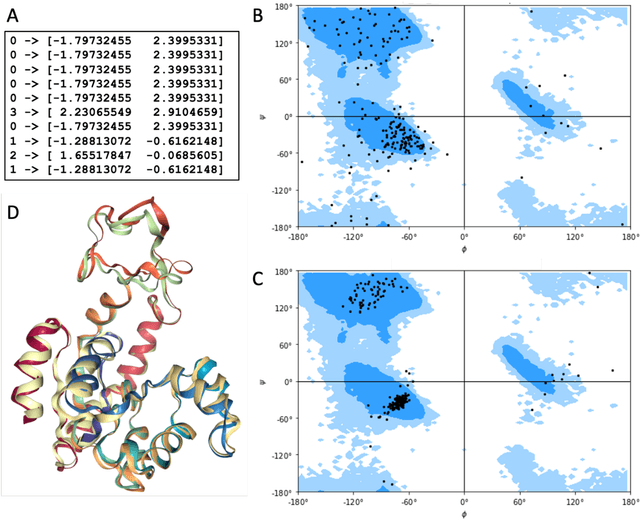
All-atom and coarse-grained molecular dynamics are two widely used computational tools to study the conformational states of proteins. Yet, these two simulation methods suffer from the fact that without access to supercomputing resources, the time and length scales at which these states become detectable are difficult to achieve. One alternative to such methods is based on encoding the atomistic trajectory of molecular dynamics as a shorthand version devoid of physical particles, and then learning to propagate the encoded trajectory through the use of artificial intelligence. Here we show that a simple textual representation of the frames of molecular dynamics trajectories as vectors of Ramachandran basin classes retains most of the structural information of the full atomistic representation of a protein in each frame, and can be used to generate equivalent atom-less trajectories suitable to train different types of generative neural networks. In turn, the trained generative models can be used to extend indefinitely the atom-less dynamics or to sample the conformational space of proteins from their representation in the models latent space. We define intuitively this methodology as molecular dynamics without molecules, and show that it enables to cover physically relevant states of proteins that are difficult to access with traditional molecular dynamics.
Brownian Noise Reduction: Maximizing Privacy Subject to Accuracy Constraints
Jun 15, 2022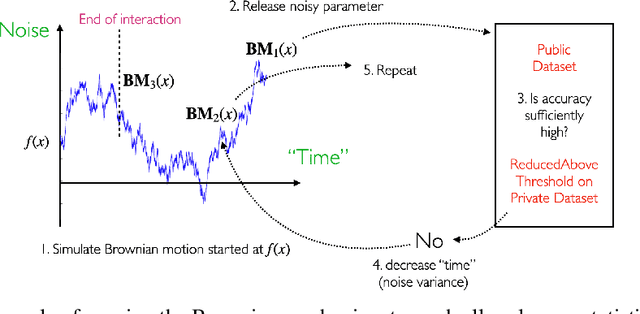
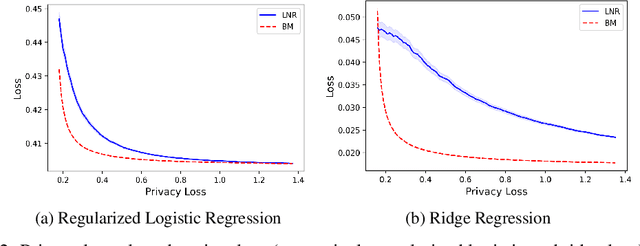
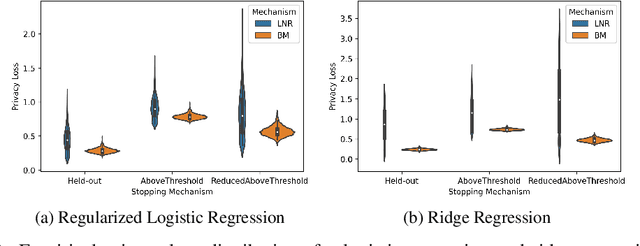
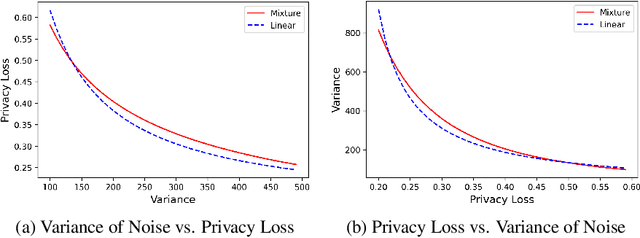
There is a disconnect between how researchers and practitioners handle privacy-utility tradeoffs. Researchers primarily operate from a privacy first perspective, setting strict privacy requirements and minimizing risk subject to these constraints. Practitioners often desire an accuracy first perspective, possibly satisfied with the greatest privacy they can get subject to obtaining sufficiently small error. Ligett et al. have introduced a "noise reduction" algorithm to address the latter perspective. The authors show that by adding correlated Laplace noise and progressively reducing it on demand, it is possible to produce a sequence of increasingly accurate estimates of a private parameter while only paying a privacy cost for the least noisy iterate released. In this work, we generalize noise reduction to the setting of Gaussian noise, introducing the Brownian mechanism. The Brownian mechanism works by first adding Gaussian noise of high variance corresponding to the final point of a simulated Brownian motion. Then, at the practitioner's discretion, noise is gradually decreased by tracing back along the Brownian path to an earlier time. Our mechanism is more naturally applicable to the common setting of bounded $\ell_2$-sensitivity, empirically outperforms existing work on common statistical tasks, and provides customizable control of privacy loss over the entire interaction with the practitioner. We complement our Brownian mechanism with ReducedAboveThreshold, a generalization of the classical AboveThreshold algorithm that provides adaptive privacy guarantees. Overall, our results demonstrate that one can meet utility constraints while still maintaining strong levels of privacy.
Computational Impact Time Guidance: A Learning-Based Prediction-Correction Approach
Mar 09, 2021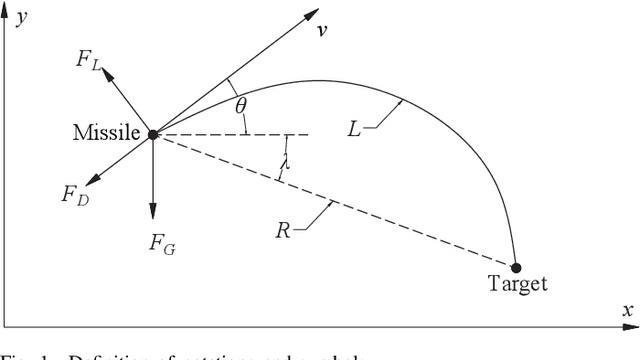
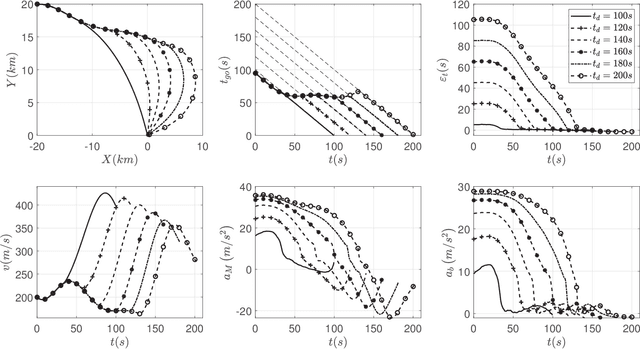
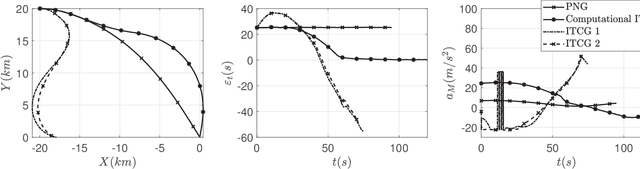
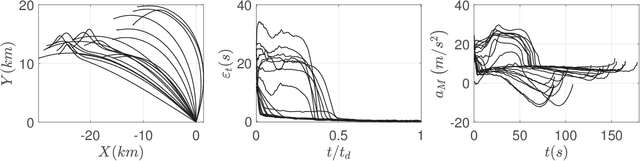
This paper investigates the problem of impact-time-control and proposes a learning-based computational guidance algorithm to solve this problem. The proposed guidance algorithm is developed based on a general prediction-correction concept: the exact time-to-go under proportional navigation guidance with realistic aerodynamic characteristics is estimated by a deep neural network and a biased command to nullify the impact time error is developed by utilizing the emerging reinforcement learning techniques. The deep neural network is augmented into the reinforcement learning block to resolve the issue of sparse reward that has been observed in typical reinforcement learning formulation. Extensive numerical simulations are conducted to support the proposed algorithm.
Learning code summarization from a small and local dataset
Jun 02, 2022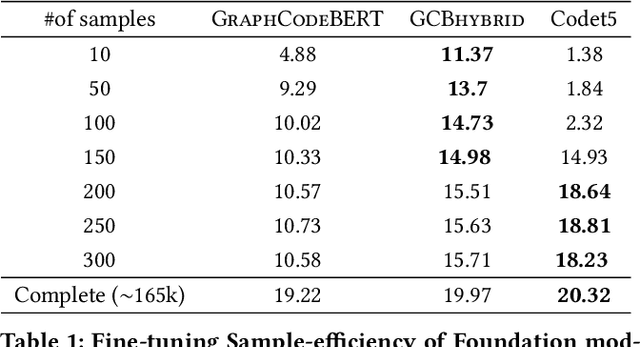

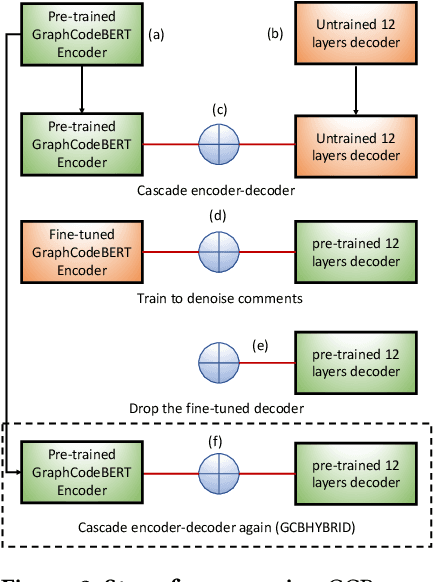
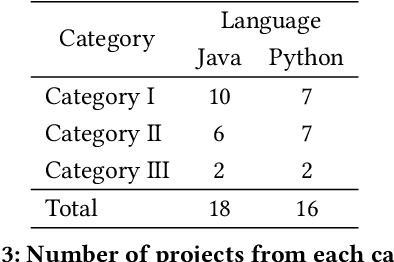
Foundation models (e.g., CodeBERT, GraphCodeBERT, CodeT5) work well for many software engineering tasks. These models are pre-trained (using self-supervision) with billions of code tokens, and then fine-tuned with hundreds of thousands of labeled examples, typically drawn from many projects. However, software phenomena can be very project-specific. Vocabulary, and other phenomena vary substantially with each project. Thus, training on project-specific data, and testing on the same project, is a promising idea. This hypothesis has to be evaluated carefully, e.g., in a time-series setting, to prevent training-test leakage. We compare several models and training approaches, including same-project training, cross-project training, training a model especially designed to be sample efficient (and thus prima facie well-suited for learning in a limited-sample same-project setting) and a maximalist hybrid approach, fine-tuning first on many projects in many languages and then training on the same-project. We find that the maximalist hybrid setting provides consistent, substantial gains over the state-of-the-art, on many different projects in both Java and Python.
Data-Driven Copy-Paste Imputation for Energy Time Series
Jan 05, 2021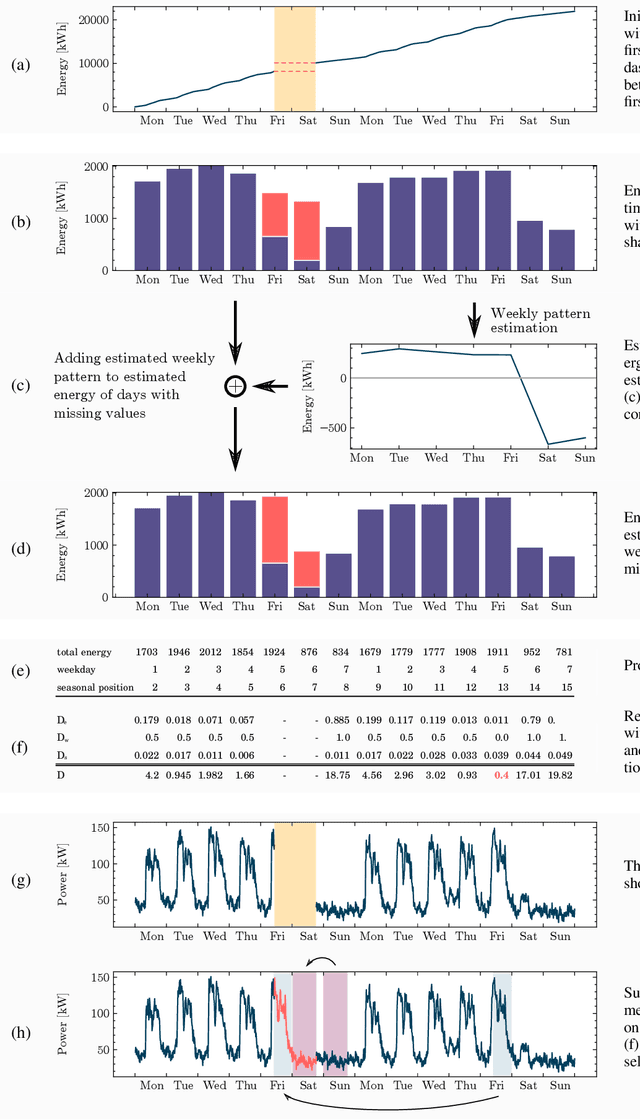
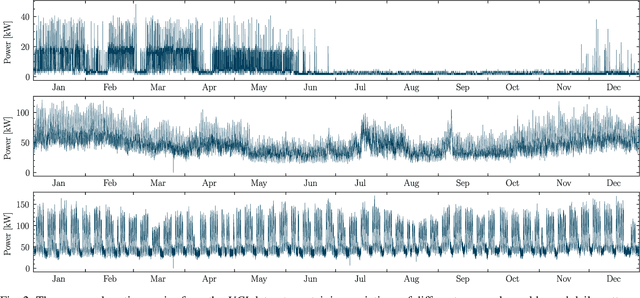
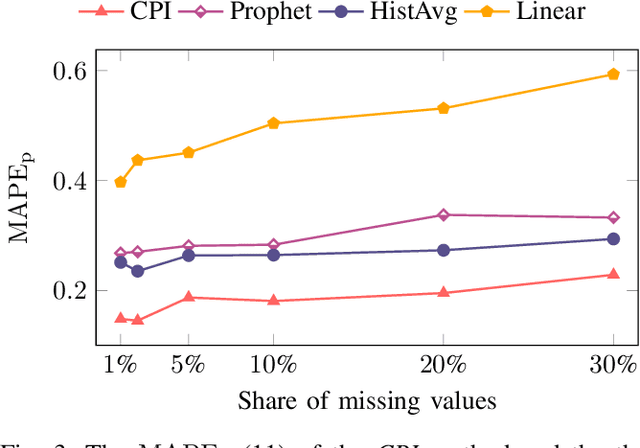
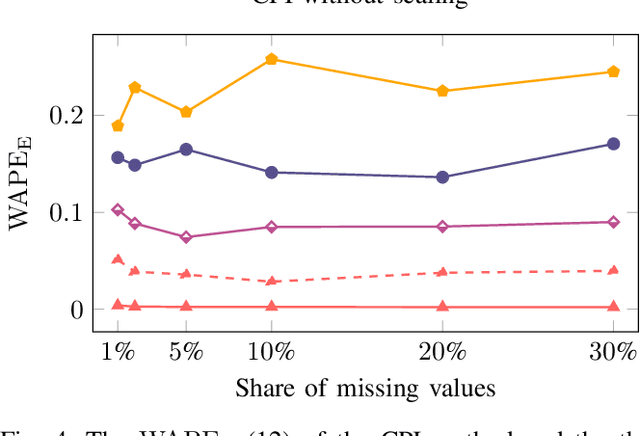
A cornerstone of the worldwide transition to smart grids are smart meters. Smart meters typically collect and provide energy time series that are vital for various applications, such as grid simulations, fault-detection, load forecasting, load analysis, and load management. Unfortunately, these time series are often characterized by missing values that must be handled before the data can be used. A common approach to handle missing values in time series is imputation. However, existing imputation methods are designed for power time series and do not take into account the total energy of gaps, resulting in jumps or constant shifts when imputing energy time series. In order to overcome these issues, the present paper introduces the new Copy-Paste Imputation (CPI) method for energy time series. The CPI method copies data blocks with similar properties and pastes them into gaps of the time series while preserving the total energy of each gap. The new method is evaluated on a real-world dataset that contains six shares of artificially inserted missing values between 1 and 30%. It outperforms by far the three benchmark imputation methods selected for comparison. The comparison furthermore shows that the CPI method uses matching patterns and preserves the total energy of each gap while requiring only a moderate run-time.
Characteristics of Interference in Licensed and Unlicensed Bands for Intelligent Spectrum Management
Jun 17, 2022
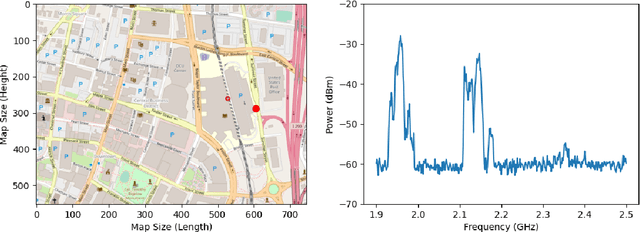
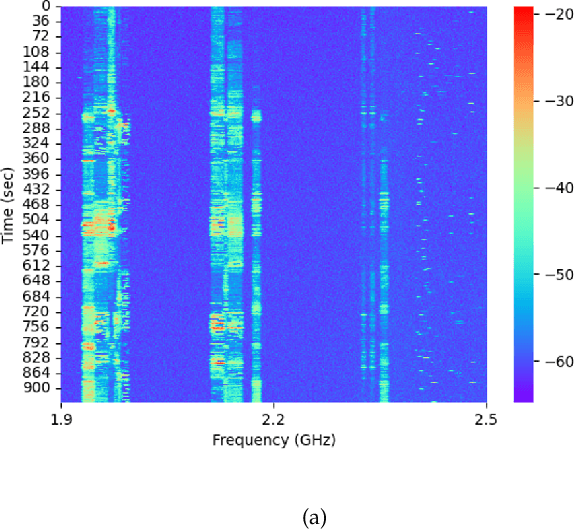
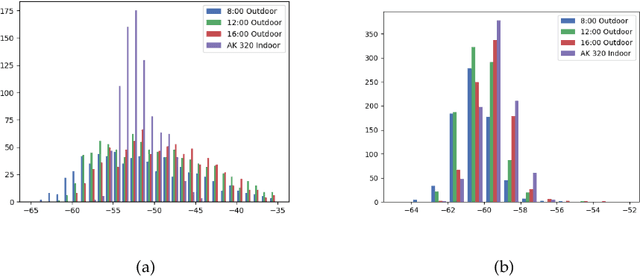
The exponential growth of IoT devices and the demand of smart devices for higher data rates has heightened the need for sharing and managing spectrum resources in cellular 5G/6G operating in licensed bands and Wi-Fi technologies operating in unlicensed bands. Intelligent spectrum management has emerged as a key concept in dynamic spectrum allocation. To understand the interference existing in the spectrum, researchers usually monitor the interference in a fixed location and either focus on the cellular band or Wi-Fi band. In this study, we conduct experiments for collecting real-time spectrum data in indoor and outdoor environments with a mobile receiver, the spectrum analyzer. For outdoor, we mount the spectrum analyzer on a car seat and drive on the selected route in an urban area. We put the analyzer on a cart and moved it around in the laboratory for indoor. The frequency of interest in this study is 1.9 - 2.5 GHz, including both licensed and unlicensed bands. Temporal and frequency domain behavior is compared between licensed and unlicensed bands. We first normalize and binarize the data with a threshold. Then we calculate the spectrum occupancy by counting how many consecutive ones. Based on our observation, the spectrum occupancy of the outdoor environment is more remarkable than the indoor environment. The interference in the licensed band shows more variations in the frequency domain than that in the unlicensed band. This study provides a better understanding of the interference behavior for different environments and frequency bands.