 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepSITH: Efficient Learning via Decomposition of What and When Across Time Scales
Apr 09, 2021
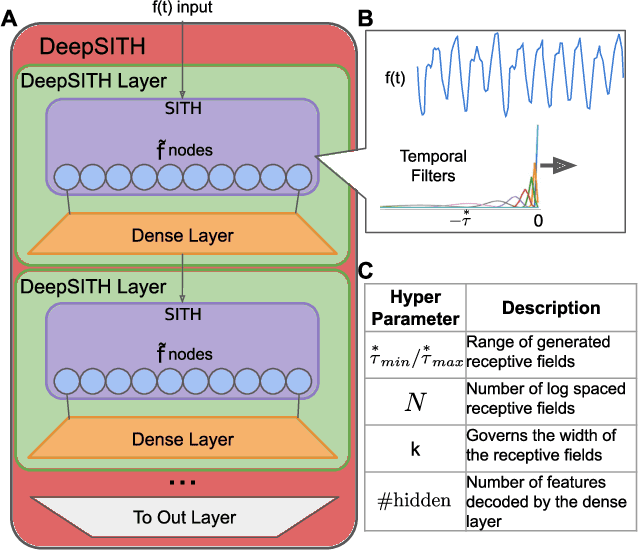

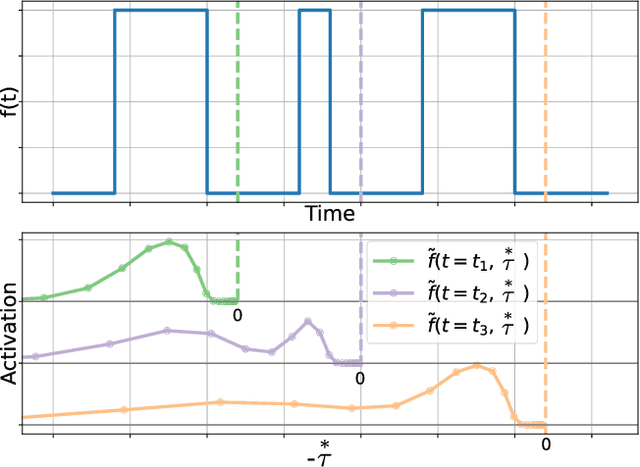

Extracting temporal relationships over a range of scales is a hallmark of human perception and cognition -- and thus it is a critical feature of machine learning applied to real-world problems. Neural networks are either plagued by the exploding/vanishing gradient problem in recurrent neural networks (RNNs) or must adjust their parameters to learn the relevant time scales (e.g., in LSTMs). This paper introduces DeepSITH, a network comprising biologically-inspired Scale-Invariant Temporal History (SITH) modules in series with dense connections between layers. SITH modules respond to their inputs with a geometrically-spaced set of time constants, enabling the DeepSITH network to learn problems along a continuum of time-scales. We compare DeepSITH to LSTMs and other recent RNNs on several time series prediction and decoding tasks. DeepSITH achieves state-of-the-art performance on these problems.
Bi-static Radar Cross Section Test Method by Using Historic Marconi Set-up and Time Gating
Jun 27, 2021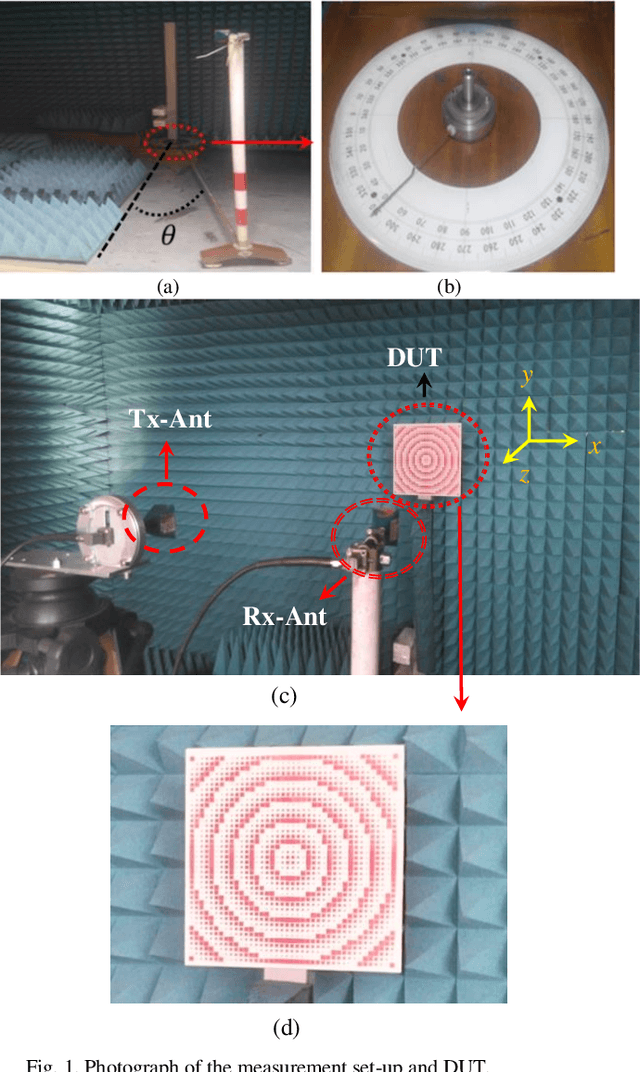
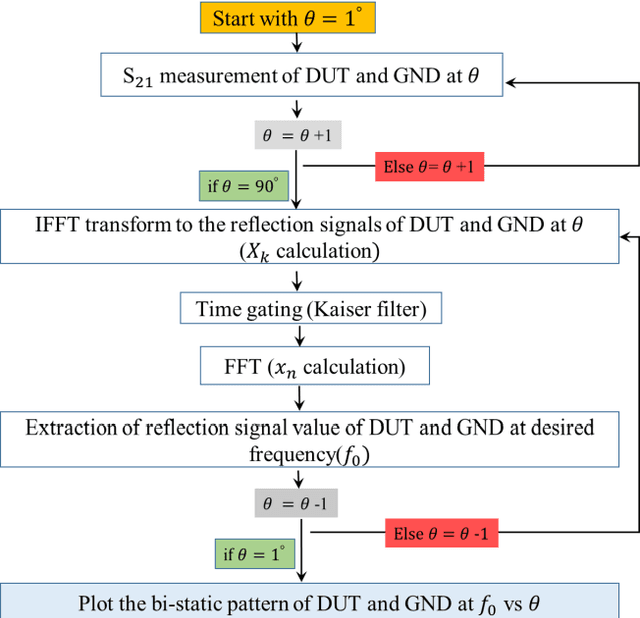
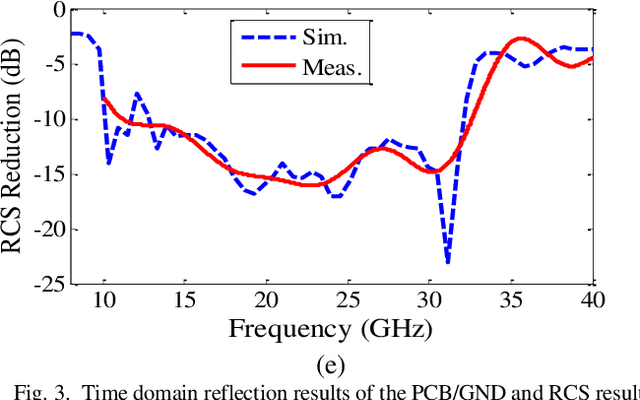
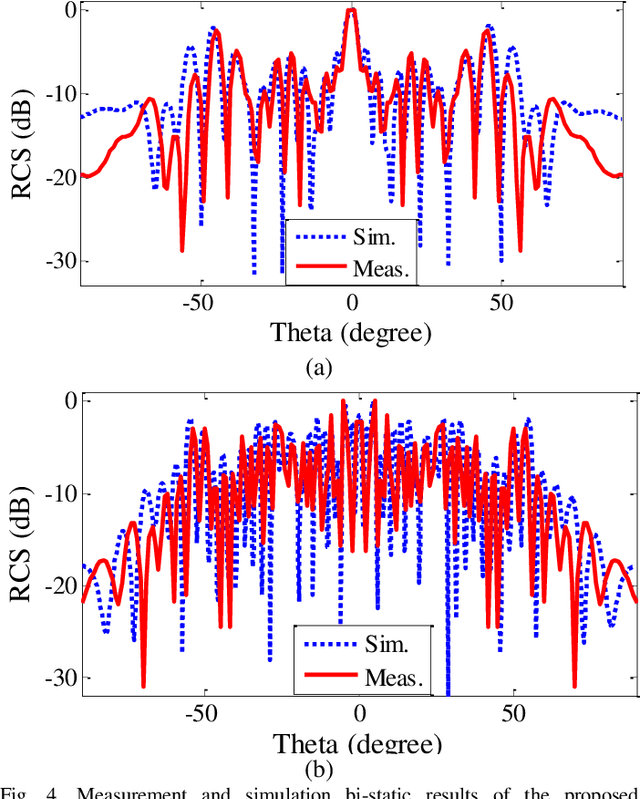
In this paper, a low-cost, simple and reliable bi-static Radar Cross Section (RCS) measurement method making use a historic Marconi set-up is presented. It uses a transmitting (Tx) antenna (located at a constant position, at a reference angle of {\theta} = 0o) and a receiver (Rx) antenna (mounted on a moveable arm calibrated in the azimuthal direction with an accuracy of 0.1o). A time gating method is used to extract the information from the reflection in the time domain; applying time filter allows removing the antenna side lobe effects and other ambient noise. In this method, the Rx antenna (on the movable arm) is used to measure the reflected field in the angular range from 1o to 90o of reflection from the structure (printed PCB) and from the reference configuration represented by a ground (GND) plane of the same dimension. The time gating method is then applied to each pair of PCB / GND measurements to extract the bi-static RCS pattern of the structure at a given frequency. Here comparison of measurement results carried out at 18 GHz and 32 GHz with simulation indicates the successful performance of the proposed method. It can be used as a low-cost, reliable and available option in future measurement and scientific research.
STMTrack: Template-free Visual Tracking with Space-time Memory Networks
Apr 01, 2021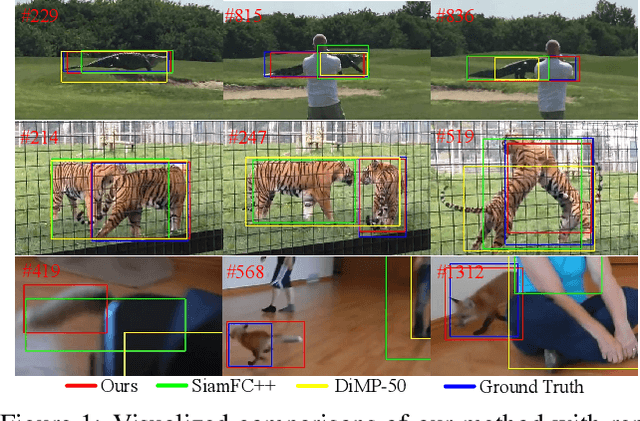
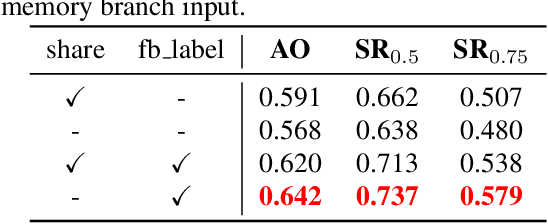
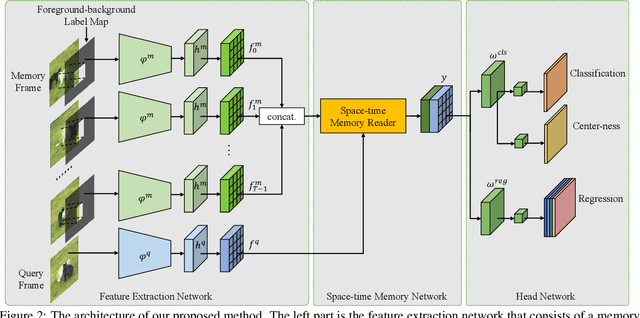

Boosting performance of the offline trained siamese trackers is getting harder nowadays since the fixed information of the template cropped from the first frame has been almost thoroughly mined, but they are poorly capable of resisting target appearance changes. Existing trackers with template updating mechanisms rely on time-consuming numerical optimization and complex hand-designed strategies to achieve competitive performance, hindering them from real-time tracking and practical applications. In this paper, we propose a novel tracking framework built on top of a space-time memory network that is competent to make full use of historical information related to the target for better adapting to appearance variations during tracking. Specifically, a novel memory mechanism is introduced, which stores the historical information of the target to guide the tracker to focus on the most informative regions in the current frame. Furthermore, the pixel-level similarity computation of the memory network enables our tracker to generate much more accurate bounding boxes of the target. Extensive experiments and comparisons with many competitive trackers on challenging large-scale benchmarks, OTB-2015, TrackingNet, GOT-10k, LaSOT, UAV123, and VOT2018, show that, without bells and whistles, our tracker outperforms all previous state-of-the-art real-time methods while running at 37 FPS. The code is available at https://github.com/fzh0917/STMTrack.
Brownian Noise Reduction: Maximizing Privacy Subject to Accuracy Constraints
Jun 15, 2022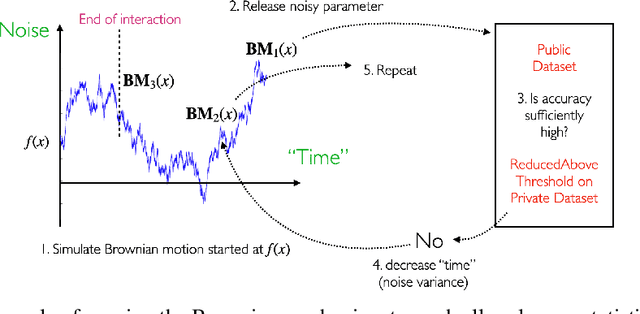
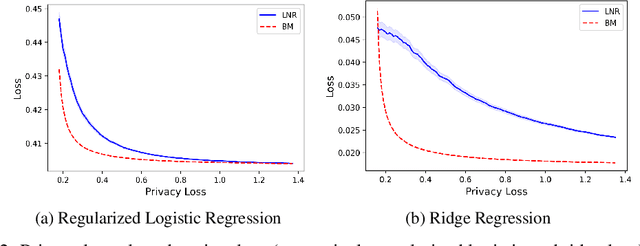
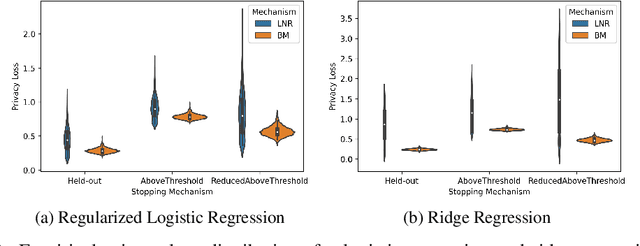
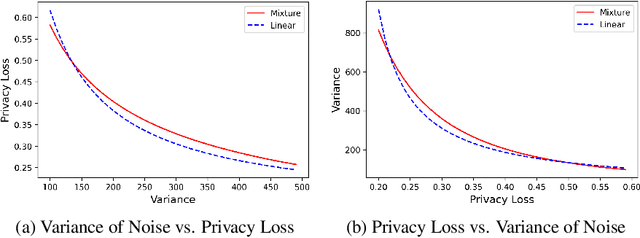
There is a disconnect between how researchers and practitioners handle privacy-utility tradeoffs. Researchers primarily operate from a privacy first perspective, setting strict privacy requirements and minimizing risk subject to these constraints. Practitioners often desire an accuracy first perspective, possibly satisfied with the greatest privacy they can get subject to obtaining sufficiently small error. Ligett et al. have introduced a "noise reduction" algorithm to address the latter perspective. The authors show that by adding correlated Laplace noise and progressively reducing it on demand, it is possible to produce a sequence of increasingly accurate estimates of a private parameter while only paying a privacy cost for the least noisy iterate released. In this work, we generalize noise reduction to the setting of Gaussian noise, introducing the Brownian mechanism. The Brownian mechanism works by first adding Gaussian noise of high variance corresponding to the final point of a simulated Brownian motion. Then, at the practitioner's discretion, noise is gradually decreased by tracing back along the Brownian path to an earlier time. Our mechanism is more naturally applicable to the common setting of bounded $\ell_2$-sensitivity, empirically outperforms existing work on common statistical tasks, and provides customizable control of privacy loss over the entire interaction with the practitioner. We complement our Brownian mechanism with ReducedAboveThreshold, a generalization of the classical AboveThreshold algorithm that provides adaptive privacy guarantees. Overall, our results demonstrate that one can meet utility constraints while still maintaining strong levels of privacy.
Molecular dynamics without molecules: searching the conformational space of proteins with generative neural networks
Jun 09, 2022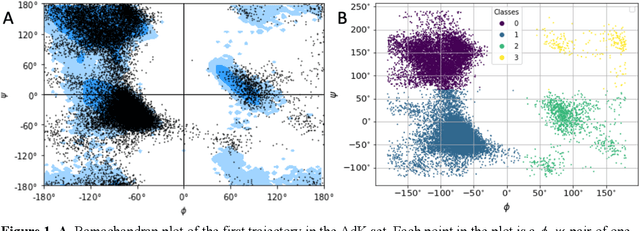
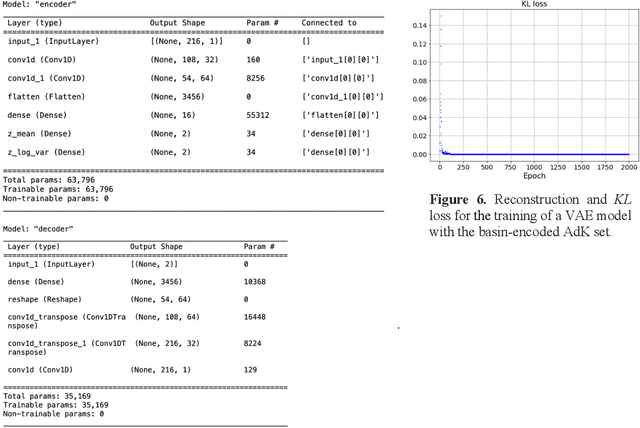
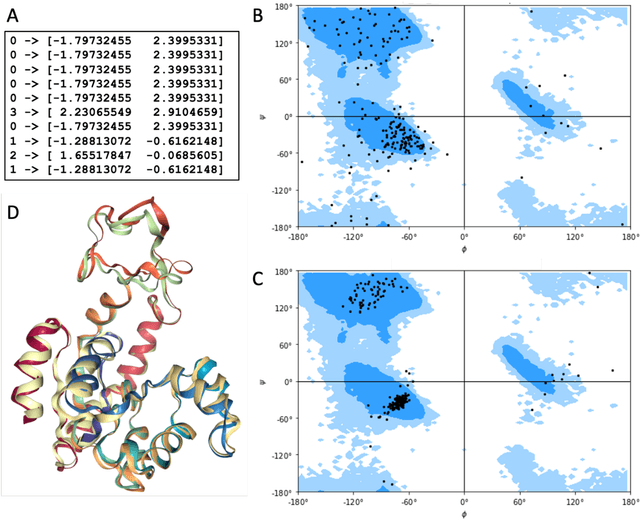
All-atom and coarse-grained molecular dynamics are two widely used computational tools to study the conformational states of proteins. Yet, these two simulation methods suffer from the fact that without access to supercomputing resources, the time and length scales at which these states become detectable are difficult to achieve. One alternative to such methods is based on encoding the atomistic trajectory of molecular dynamics as a shorthand version devoid of physical particles, and then learning to propagate the encoded trajectory through the use of artificial intelligence. Here we show that a simple textual representation of the frames of molecular dynamics trajectories as vectors of Ramachandran basin classes retains most of the structural information of the full atomistic representation of a protein in each frame, and can be used to generate equivalent atom-less trajectories suitable to train different types of generative neural networks. In turn, the trained generative models can be used to extend indefinitely the atom-less dynamics or to sample the conformational space of proteins from their representation in the models latent space. We define intuitively this methodology as molecular dynamics without molecules, and show that it enables to cover physically relevant states of proteins that are difficult to access with traditional molecular dynamics.
Curriculum Learning for Goal-Oriented Semantic Communications with a Common Language
Apr 21, 2022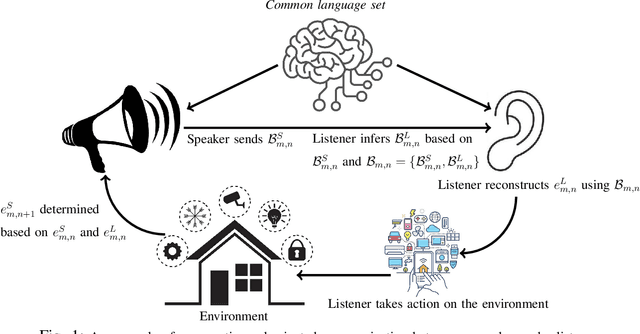
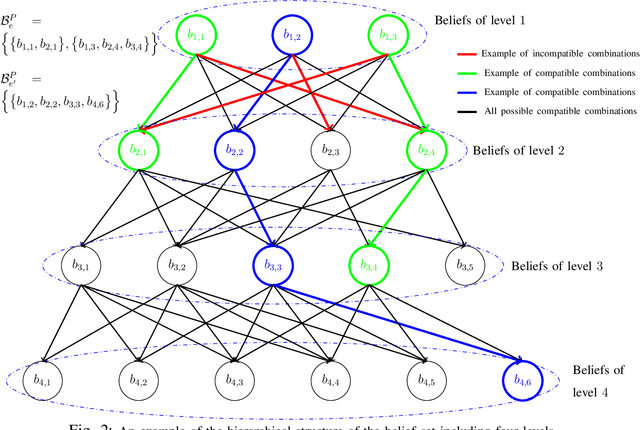
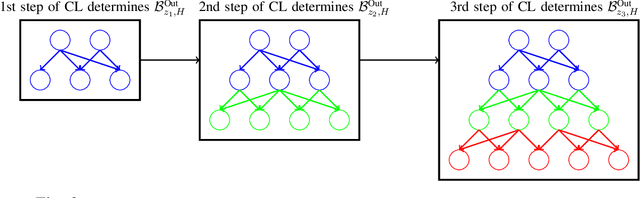
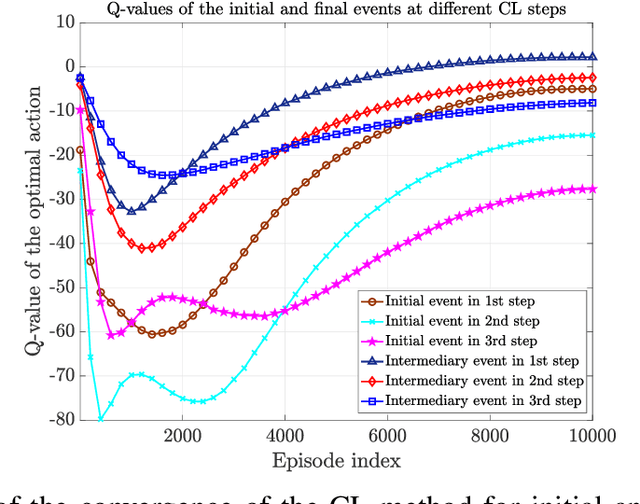
Goal-oriented semantic communication will be a pillar of next-generation wireless networks. Despite significant recent efforts in this area, most prior works are focused on specific data types (e.g., image or audio), and they ignore the goal and effectiveness aspects of semantic transmissions. In contrast, in this paper, a holistic goal-oriented semantic communication framework is proposed to enable a speaker and a listener to cooperatively execute a set of sequential tasks in a dynamic environment. A common language based on a hierarchical belief set is proposed to enable semantic communications between speaker and listener. The speaker, acting as an observer of the environment, utilizes the beliefs to transmit an initial description of its observation (called event) to the listener. The listener is then able to infer on the transmitted description and complete it by adding related beliefs to the transmitted beliefs of the speaker. As such, the listener reconstructs the observed event based on the completed description, and it then takes appropriate action in the environment based on the reconstructed event. An optimization problem is defined to determine the perfect and abstract description of the events while minimizing the transmission and inference costs with constraints on the task execution time and belief efficiency. Then, a novel bottom-up curriculum learning (CL) framework based on reinforcement learning is proposed to solve the optimization problem and enable the speaker and listener to gradually identify the structure of the belief set and the perfect and abstract description of the events. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution cost and time, reliability, and belief efficiency.
Characteristics of Interference in Licensed and Unlicensed Bands for Intelligent Spectrum Management
Jun 17, 2022
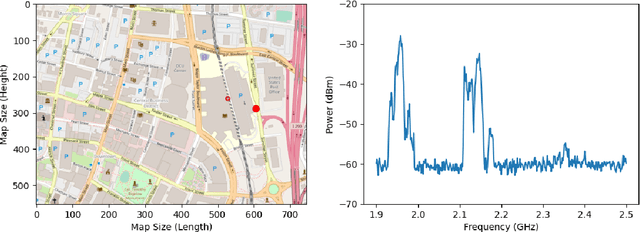
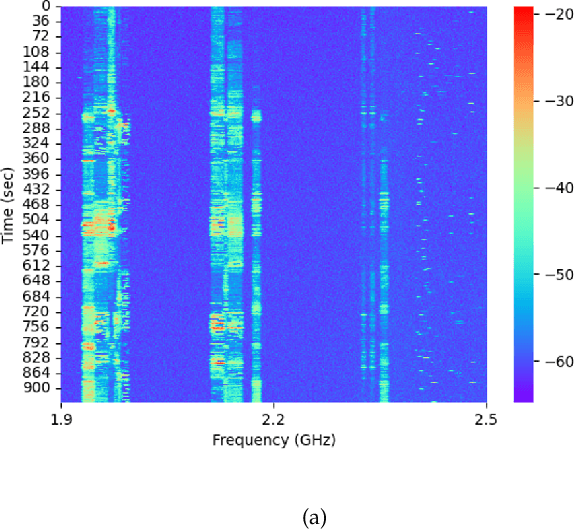
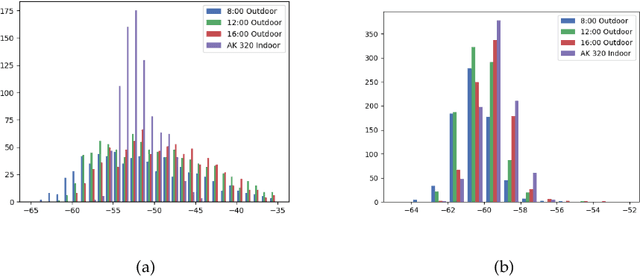
The exponential growth of IoT devices and the demand of smart devices for higher data rates has heightened the need for sharing and managing spectrum resources in cellular 5G/6G operating in licensed bands and Wi-Fi technologies operating in unlicensed bands. Intelligent spectrum management has emerged as a key concept in dynamic spectrum allocation. To understand the interference existing in the spectrum, researchers usually monitor the interference in a fixed location and either focus on the cellular band or Wi-Fi band. In this study, we conduct experiments for collecting real-time spectrum data in indoor and outdoor environments with a mobile receiver, the spectrum analyzer. For outdoor, we mount the spectrum analyzer on a car seat and drive on the selected route in an urban area. We put the analyzer on a cart and moved it around in the laboratory for indoor. The frequency of interest in this study is 1.9 - 2.5 GHz, including both licensed and unlicensed bands. Temporal and frequency domain behavior is compared between licensed and unlicensed bands. We first normalize and binarize the data with a threshold. Then we calculate the spectrum occupancy by counting how many consecutive ones. Based on our observation, the spectrum occupancy of the outdoor environment is more remarkable than the indoor environment. The interference in the licensed band shows more variations in the frequency domain than that in the unlicensed band. This study provides a better understanding of the interference behavior for different environments and frequency bands.
Approaching sales forecasting using recurrent neural networks and transformers
Apr 16, 2022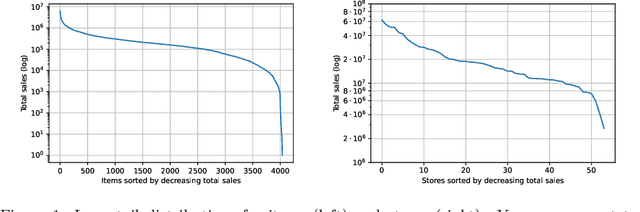
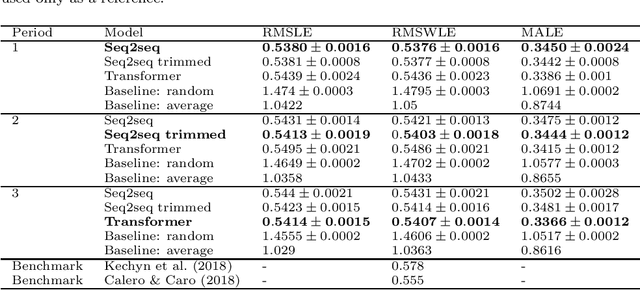
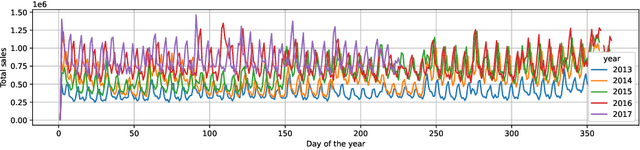
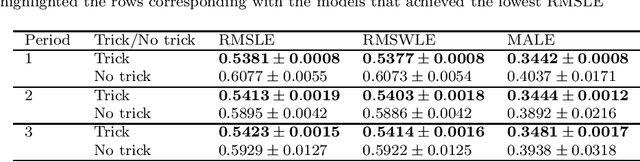
Accurate and fast demand forecast is one of the hot topics in supply chain for enabling the precise execution of the corresponding downstream processes (inbound and outbound planning, inventory placement, network planning, etc). We develop three alternatives to tackle the problem of forecasting the customer sales at day/store/item level using deep learning techniques and the Corporaci\'on Favorita data set, published as part of a Kaggle competition. Our empirical results show how good performance can be achieved by using a simple sequence to sequence architecture with minimal data preprocessing effort. Additionally, we describe a training trick for making the model more time independent and hence improving generalization over time. The proposed solution achieves a RMSLE of around 0.54, which is competitive with other more specific solutions to the problem proposed in the Kaggle competition.
Exploring the Relationship Between Algorithm Performance, Vocabulary, and Run-Time in Text Classification
Apr 08, 2021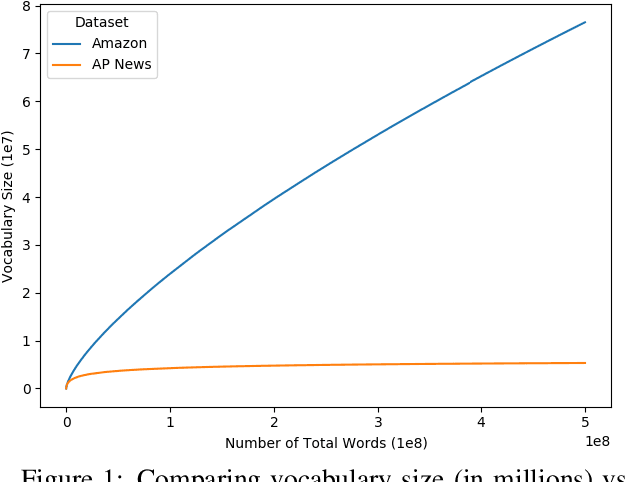
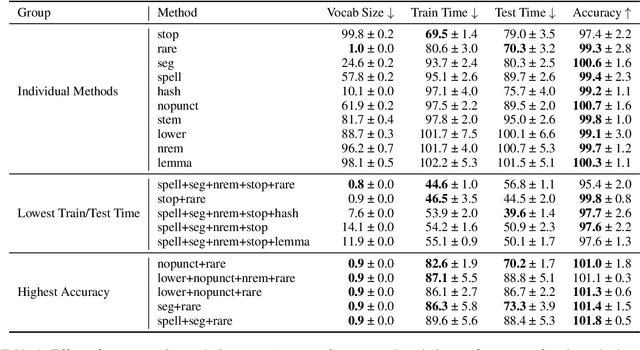
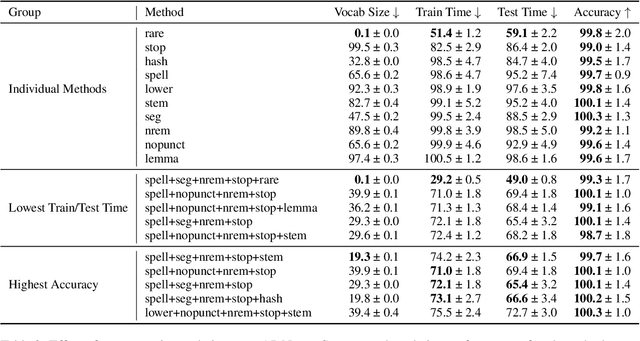
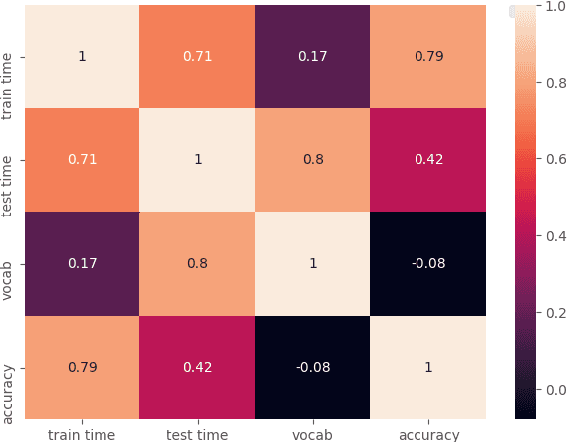
Text classification is a significant branch of natural language processing, and has many applications including document classification and sentiment analysis. Unsurprisingly, those who do text classification are concerned with the run-time of their algorithms, many of which depend on the size of the corpus' vocabulary due to their bag-of-words representation. Although many studies have examined the effect of preprocessing techniques on vocabulary size and accuracy, none have examined how these methods affect a model's run-time. To fill this gap, we provide a comprehensive study that examines how preprocessing techniques affect the vocabulary size, model performance, and model run-time, evaluating ten techniques over four models and two datasets. We show that some individual methods can reduce run-time with no loss of accuracy, while some combinations of methods can trade 2-5% of the accuracy for up to a 65% reduction of run-time. Furthermore, some combinations of preprocessing techniques can even provide a 15% reduction in run-time while simultaneously improving model accuracy.
Queried Unlabeled Data Improves and Robustifies Class-Incremental Learning
Jun 17, 2022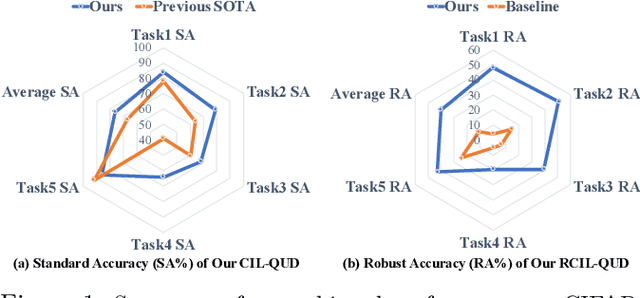
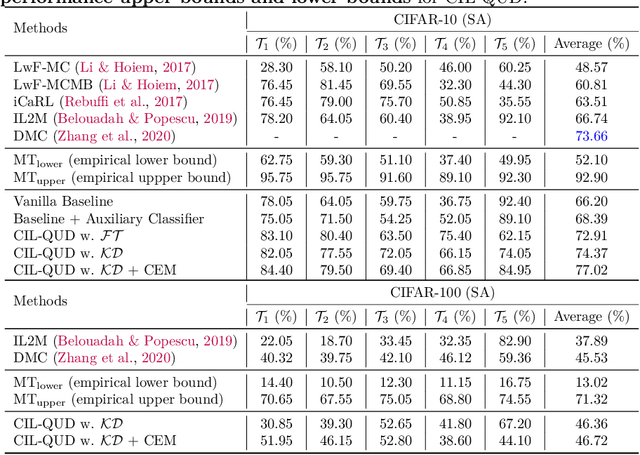
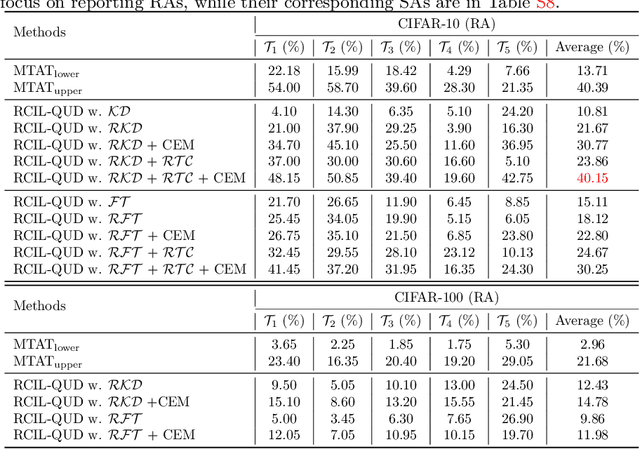
Class-incremental learning (CIL) suffers from the notorious dilemma between learning newly added classes and preserving previously learned class knowledge. That catastrophic forgetting issue could be mitigated by storing historical data for replay, which yet would cause memory overheads as well as imbalanced prediction updates. To address this dilemma, we propose to leverage "free" external unlabeled data querying in continual learning. We first present a CIL with Queried Unlabeled Data (CIL-QUD) scheme, where we only store a handful of past training samples as anchors and use them to query relevant unlabeled examples each time. Along with new and past stored data, the queried unlabeled are effectively utilized, through learning-without-forgetting (LwF) regularizers and class-balance training. Besides preserving model generalization over past and current tasks, we next study the problem of adversarial robustness for CIL-QUD. Inspired by the recent success of learning robust models with unlabeled data, we explore a new robustness-aware CIL setting, where the learned adversarial robustness has to resist forgetting and be transferred as new tasks come in continually. While existing options easily fail, we show queried unlabeled data can continue to benefit, and seamlessly extend CIL-QUD into its robustified versions, RCIL-QUD. Extensive experiments demonstrate that CIL-QUD achieves substantial accuracy gains on CIFAR-10 and CIFAR-100, compared to previous state-of-the-art CIL approaches. Moreover, RCIL-QUD establishes the first strong milestone for robustness-aware CIL. Codes are available in https://github.com/VITA-Group/CIL-QUD.