 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient fine-grained road segmentation using superpixel-based CNN and CRF models
Jun 22, 2022
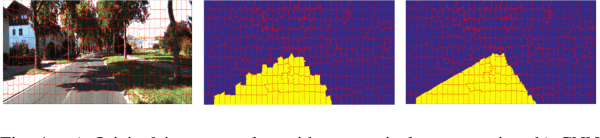
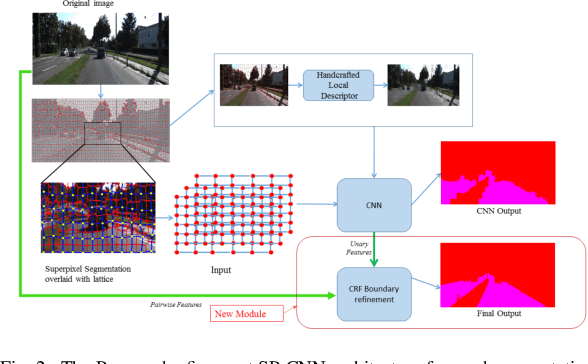

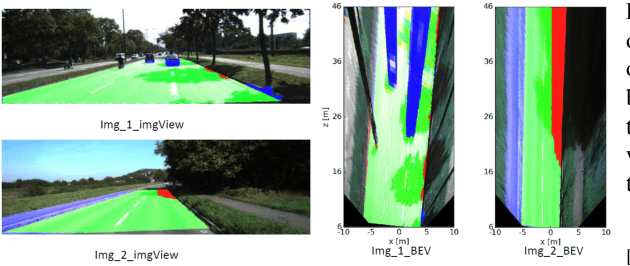
Towards a safe and comfortable driving, road scene segmentation is a rudimentary problem in camera-based advance driver assistance systems (ADAS). Despite of the great achievement of Convolutional Neural Networks (CNN) for semantic segmentation task, the high computational efforts of CNN based methods is still a challenging area. In recent work, we proposed a novel approach to utilise the advantages of CNNs for the task of road segmentation at reasonable computational effort. The runtime benefits from using irregular super pixels as basis for the input for the CNN rather than the image grid, which tremendously reduces the input size. Although, this method achieved remarkable low computational time in both training and testing phases, the lower resolution of the super pixel domain yields naturally lower accuracy compared to high cost state of the art methods. In this work, we focus on a refinement of the road segmentation utilising a Conditional Random Field (CRF).The refinement procedure is limited to the super pixels touching the predicted road boundary to keep the additional computational effort low. Reducing the input to the super pixel domain allows the CNNs structure to stay small and efficient to compute while keeping the advantage of convolutional layers and makes them eligible for ADAS. Applying CRF compensate the trade off between accuracy and computational efficiency. The proposed system obtained comparable performance among the top performing algorithms on the KITTI road benchmark and its fast inference makes it particularly suitable for realtime applications.
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Aug 23, 2021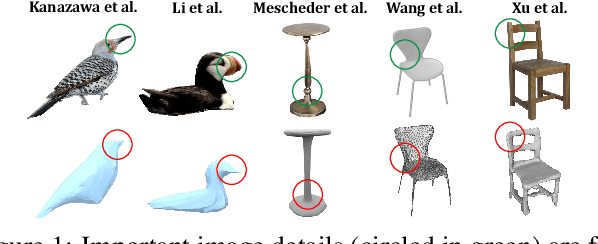
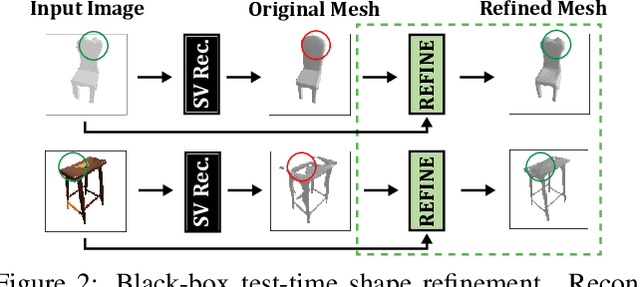
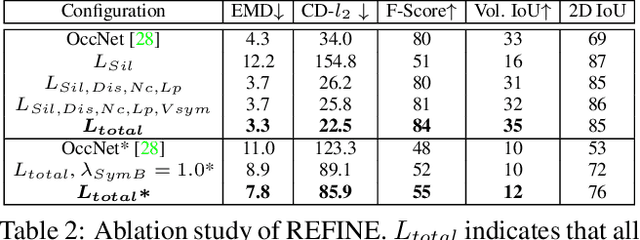
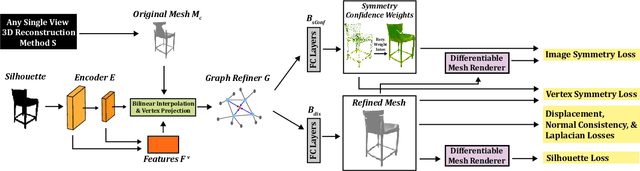
Much recent progress has been made in reconstructing the 3D shape of an object from an image of it, i.e. single view 3D reconstruction. However, it has been suggested that current methods simply adopt a "nearest-neighbor" strategy, instead of genuinely understanding the shape behind the input image. In this paper, we rigorously show that for many state of the art methods, this issue manifests as (1) inconsistencies between coarse reconstructions and input images, and (2) inability to generalize across domains. We thus propose REFINE, a postprocessing mesh refinement step that can be easily integrated into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, along with a novel combination of regularizing losses, reduces the domain gap and achieves state of the art performance. We believe that this novel paradigm is an important step towards robust, accurate reconstructions, remaining relevant as new reconstruction networks are introduced.
Accelerating Federated Learning via Sampling Anchor Clients with Large Batches
Jun 13, 2022
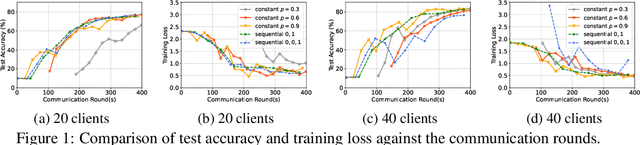
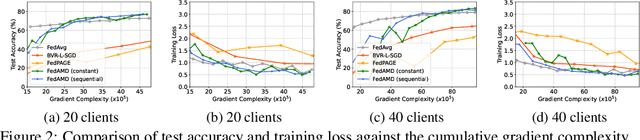
Using large batches in recent federated learning studies has improved convergence rates, but it requires additional computation overhead compared to using small batches. To overcome this limitation, we propose a unified framework FedAMD, which disjoints the participants into anchor and miner groups based on time-varying probabilities. Each client in the anchor group computes the gradient using a large batch, which is regarded as its bullseye. Clients in the miner group perform multiple local updates using serial mini-batches, and each local update is also indirectly regulated by the global target derived from the average of clients' bullseyes. As a result, the miner group follows a near-optimal update towards the global minimizer, adapted to update the global model. Measured by $\epsilon$-approximation, FedAMD achieves a convergence rate of $O(1/\epsilon)$ under non-convex objectives by sampling an anchor with a constant probability. The theoretical result considerably surpasses the state-of-the-art algorithm BVR-L-SGD at $O(1/\epsilon^{3/2})$, while FedAMD reduces at least $O(1/\epsilon)$ communication overhead. Empirical studies on real-world datasets validate the effectiveness of FedAMD and demonstrate the superiority of our proposed algorithm.
On the well-spread property and its relation to linear regression
Jun 16, 2022We consider the robust linear regression model $\boldsymbol{y} = X\beta^* + \boldsymbol{\eta}$, where an adversary oblivious to the design $X \in \mathbb{R}^{n \times d}$ may choose $\boldsymbol{\eta}$ to corrupt all but a (possibly vanishing) fraction of the observations $\boldsymbol{y}$ in an arbitrary way. Recent work [dLN+21, dNS21] has introduced efficient algorithms for consistent recovery of the parameter vector. These algorithms crucially rely on the design matrix being well-spread (a matrix is well-spread if its column span is far from any sparse vector). In this paper, we show that there exists a family of design matrices lacking well-spreadness such that consistent recovery of the parameter vector in the above robust linear regression model is information-theoretically impossible. We further investigate the average-case time complexity of certifying well-spreadness of random matrices. We show that it is possible to efficiently certify whether a given $n$-by-$d$ Gaussian matrix is well-spread if the number of observations is quadratic in the ambient dimension. We complement this result by showing rigorous evidence -- in the form of a lower bound against low-degree polynomials -- of the computational hardness of this same certification problem when the number of observations is $o(d^2)$.
Learning Vehicle Trajectory Uncertainty
Jun 09, 2022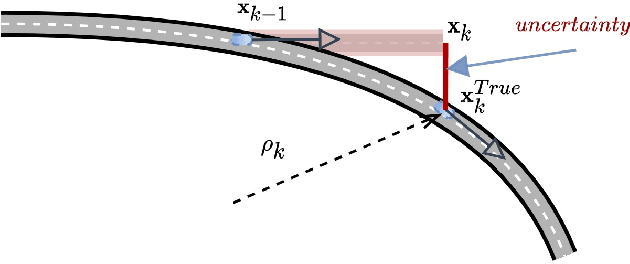
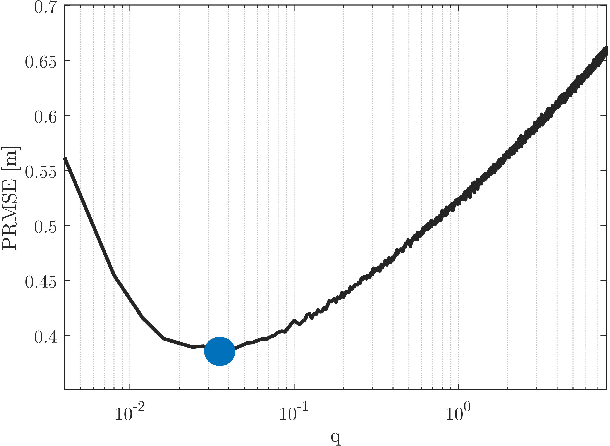
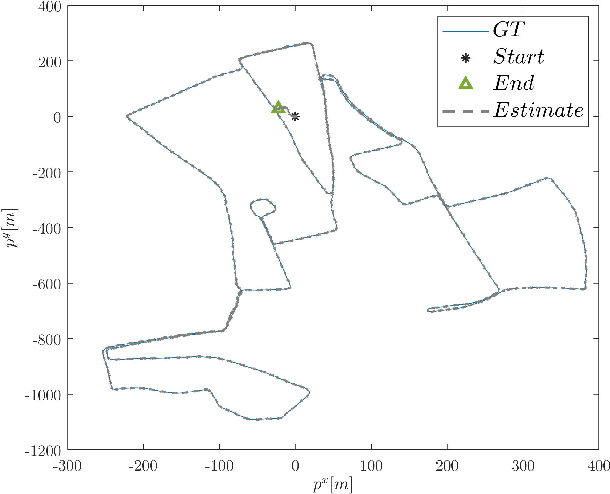
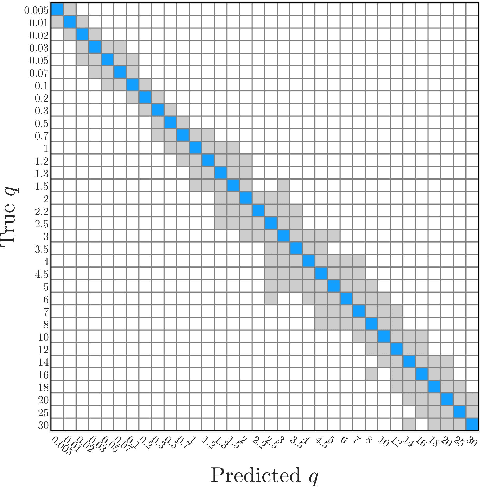
The linear Kalman filter is commonly used for vehicle tracking. This filter requires knowledge of the vehicle trajectory and the statistics of the system and measurement models. In real-life scenarios, prior assumptions made while determining those models do not hold. As a consequence, the overall filter performance degrades and in some situations the estimated states diverge. To overcome the uncertainty in the {vehicle kinematic} trajectory modeling, additional artificial process noise may be added to the model or different types of adaptive filters may be employed. This paper proposes {a hybrid} adaptive Kalman filter based on {model and} machine learning algorithms. First, recurrent neural networks are employed to learn the vehicle's geometrical and kinematic features. In turn, those features are plugged into a supervised learning model, thereby providing the actual process noise covariance to be used in the Kalman framework. The proposed approach is evaluated and compared to six other adaptive filters using the Oxford RobotCar dataset. The proposed framework can be implemented in other estimation problems to accurately determine the process noise covariance in real-time scenarios.
A Database for Perceived Quality Assessment of User-Generated VR Videos
Jun 13, 2022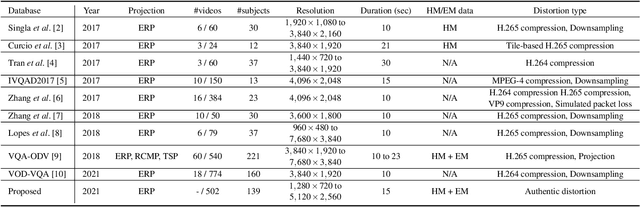

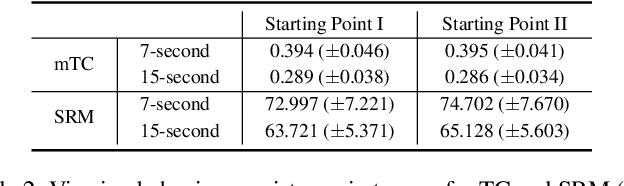
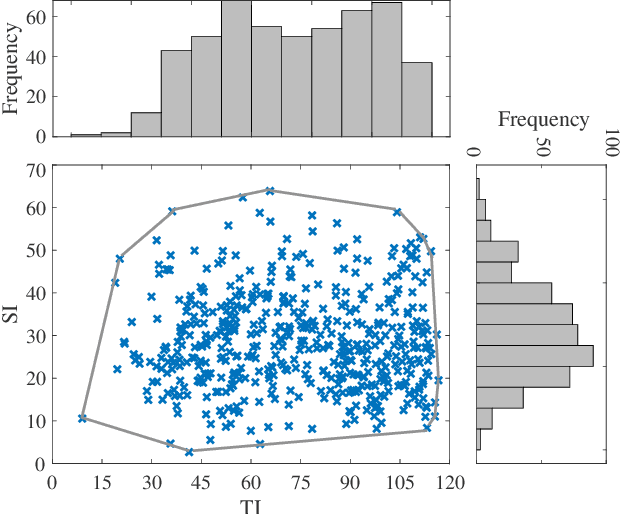
Virtual reality (VR) videos (typically in the form of 360$^\circ$ videos) have gained increasing attention due to the fast development of VR technologies and the remarkable popularization of consumer-grade 360$^\circ$ cameras and displays. Thus it is pivotal to understand how people perceive user-generated VR videos, which may suffer from commingled authentic distortions, often localized in space and time. In this paper, we establish one of the largest 360$^\circ$ video databases, containing 502 user-generated videos with rich content and distortion diversities. We capture viewing behaviors (i.e., scanpaths) of 139 users, and collect their opinion scores of perceived quality under four different viewing conditions (two starting points $\times$ two exploration times). We provide a thorough statistical analysis of recorded data, resulting in several interesting observations, such as the significant impact of viewing conditions on viewing behaviors and perceived quality. Besides, we explore other usage of our data and analysis, including evaluation of computational models for quality assessment and saliency detection of 360$^\circ$ videos. We have made the dataset and code available at https://github.com/Yao-Yiru/VR-Video-Database.
Reconstructing Speech from Real-Time Articulatory MRI Using Neural Vocoders
Apr 23, 2021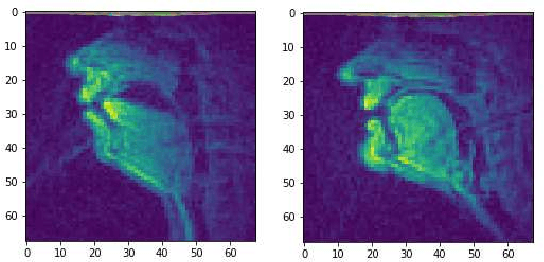
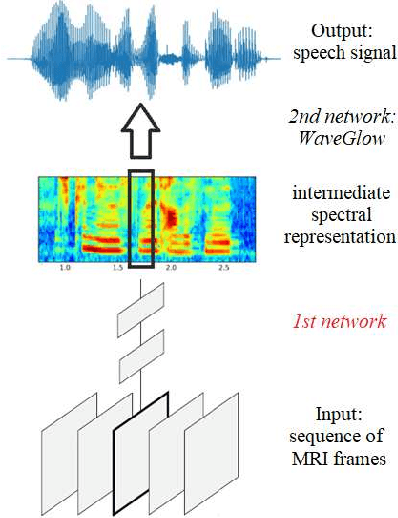
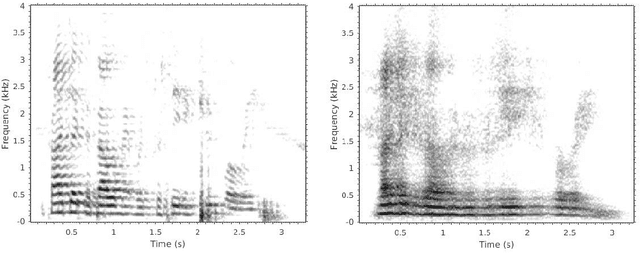

Several approaches exist for the recording of articulatory movements, such as eletromagnetic and permanent magnetic articulagraphy, ultrasound tongue imaging and surface electromyography. Although magnetic resonance imaging (MRI) is more costly than the above approaches, the recent developments in this area now allow the recording of real-time MRI videos of the articulators with an acceptable resolution. Here, we experiment with the reconstruction of the speech signal from a real-time MRI recording using deep neural networks. Instead of estimating speech directly, our networks are trained to output a spectral vector, from which we reconstruct the speech signal using the WaveGlow neural vocoder. We compare the performance of three deep neural architectures for the estimation task, combining convolutional (CNN) and recurrence-based (LSTM) neural layers. Besides the mean absolute error (MAE) of our networks, we also evaluate our models by comparing the speech signals obtained using several objective speech quality metrics like the mean cepstral distortion (MCD), Short-Time Objective Intelligibility (STOI), Perceptual Evaluation of Speech Quality (PESQ) and Signal-to-Distortion Ratio (SDR). The results indicate that our approach can successfully reconstruct the gross spectral shape, but more improvements are needed to reproduce the fine spectral details.
Causal Inference-Based Root Cause Analysis for Online Service Systems with Intervention Recognition
Jun 13, 2022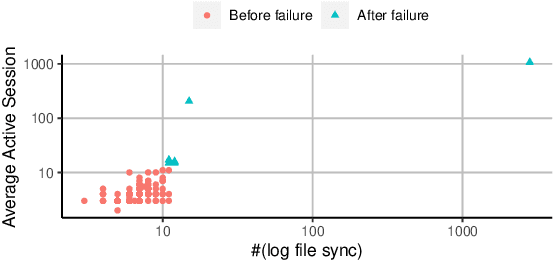
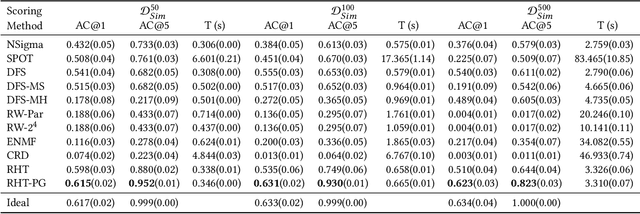
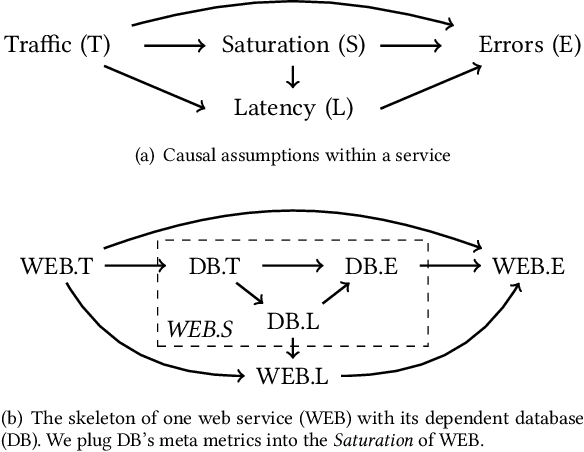
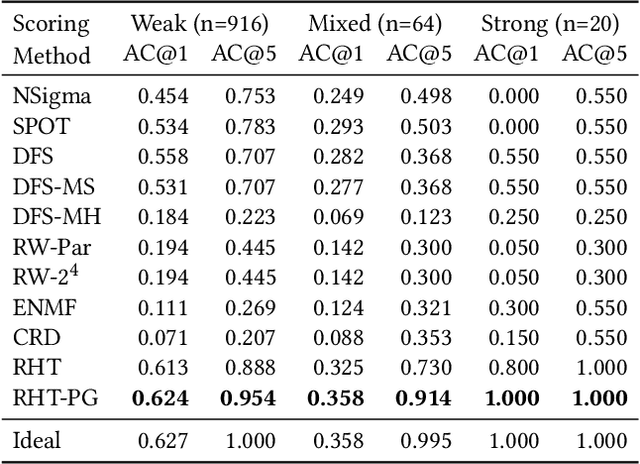
Fault diagnosis is critical in many domains, as faults may lead to safety threats or economic losses. In the field of online service systems, operators rely on enormous monitoring data to detect and mitigate failures. Quickly recognizing a small set of root cause indicators for the underlying fault can save much time for failure mitigation. In this paper, we formulate the root cause analysis problem as a new causal inference task named intervention recognition. We proposed a novel unsupervised causal inference-based method named Causal Inference-based Root Cause Analysis (CIRCA). The core idea is a sufficient condition for a monitoring variable to be a root cause indicator, i.e., the change of probability distribution conditioned on the parents in the Causal Bayesian Network (CBN). Towards the application in online service systems, CIRCA constructs a graph among monitoring metrics based on the knowledge of system architecture and a set of causal assumptions. The simulation study illustrates the theoretical reliability of CIRCA. The performance on a real-world dataset further shows that CIRCA can improve the recall of the top-1 recommendation by 25% over the best baseline method.
Automated WBRT Treatment Planning via Deep Learning Auto-Contouring and Customizable Landmark-Based Field Aperture Design
May 24, 2022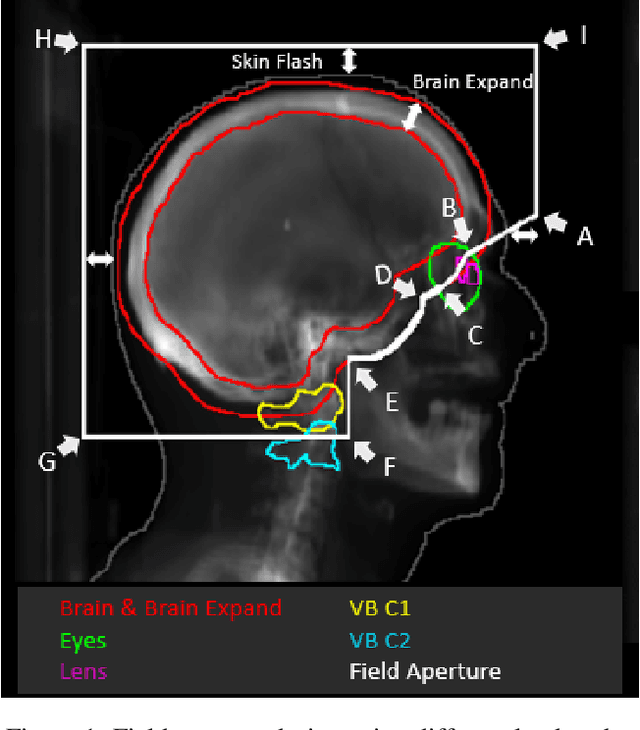

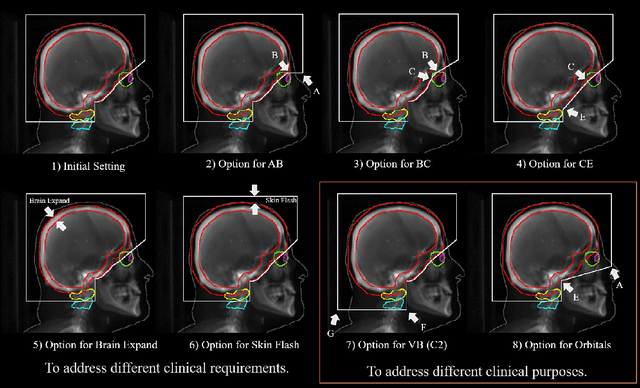
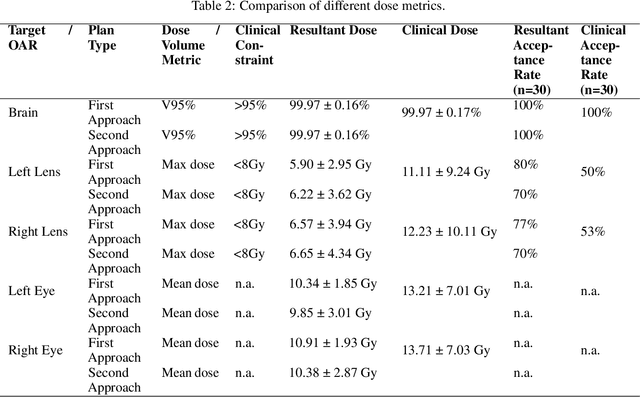
In this work, we developed and evaluated a novel pipeline consisting of two landmark-based field aperture generation approaches for WBRT treatment planning; they are fully automated and customizable. The automation pipeline is beneficial for both clinicians and patients, where we can reduce clinician workload and reduce treatment planning time. The customizability of the field aperture design addresses different clinical requirements and allows the personalized design to become feasible. The performance results regarding quantitative and qualitative evaluations demonstrated that our plans were comparable with the original clinical plans. This technique has been deployed as part of a fully automated treatment planning tool for whole-brain cancer and could be translated to other treatment sites in the future.
NNTrainer: Light-Weight On-Device Training Framework
Jun 09, 2022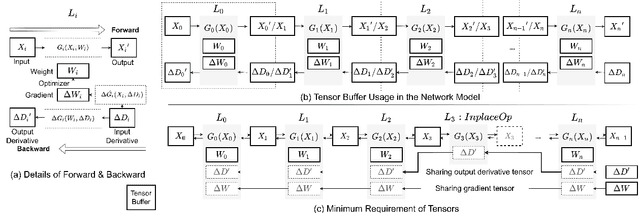

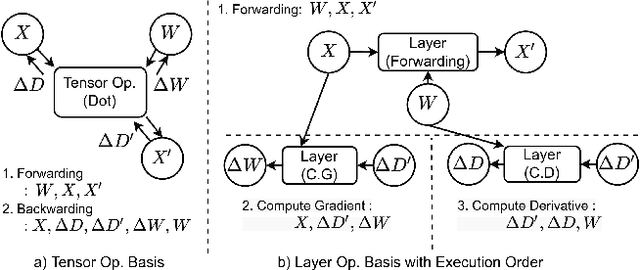

Modern consumer electronic devices have adopted deep learning-based intelligence services for their key features. Vendors have recently started to execute intelligence services on devices to preserve personal data in devices, reduce network and cloud costs. We find such a trend as the opportunity to personalize intelligence services by updating neural networks with user data without exposing the data out of devices: on-device training. For example, we may add a new class, my dog, Alpha, for robotic vacuums, adapt speech recognition for the users accent, let text-to-speech speak as if the user speaks. However, the resource limitations of target devices incur significant difficulties. We propose NNTrainer, a light-weight on-device training framework. We describe optimization techniques for neural networks implemented by NNTrainer, which are evaluated along with the conventional. The evaluations show that NNTrainer can reduce memory consumption down to 1/28 without deteriorating accuracy or training time and effectively personalizes applications on devices. NNTrainer is cross-platform and practical open source software, which is being deployed to millions of devices in the authors affiliation.