 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
STNDT: Modeling Neural Population Activity with a Spatiotemporal Transformer
Jun 09, 2022
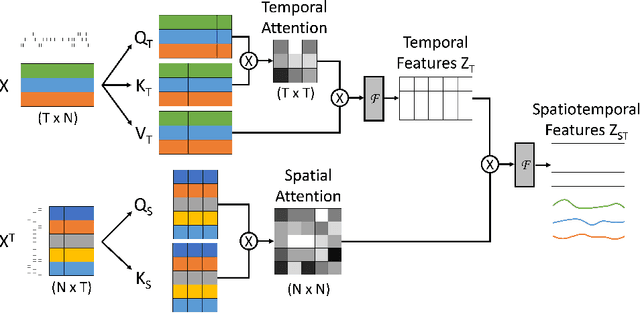
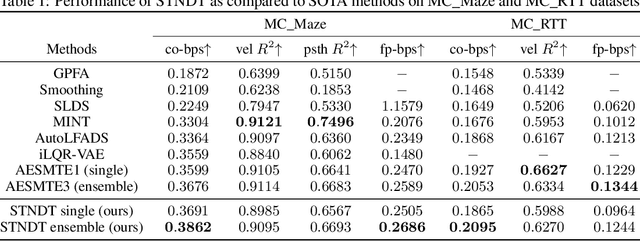
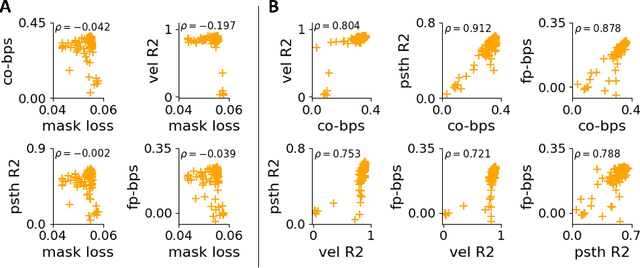
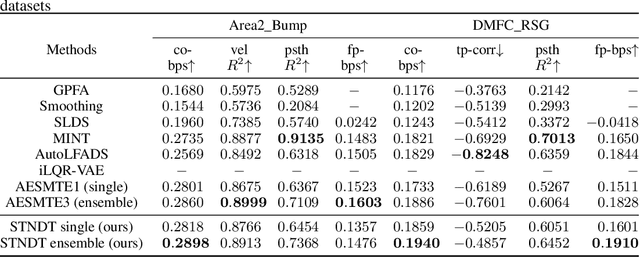
Modeling neural population dynamics underlying noisy single-trial spiking activities is essential for relating neural observation and behavior. A recent non-recurrent method - Neural Data Transformers (NDT) - has shown great success in capturing neural dynamics with low inference latency without an explicit dynamical model. However, NDT focuses on modeling the temporal evolution of the population activity while neglecting the rich covariation between individual neurons. In this paper we introduce SpatioTemporal Neural Data Transformer (STNDT), an NDT-based architecture that explicitly models responses of individual neurons in the population across time and space to uncover their underlying firing rates. In addition, we propose a contrastive learning loss that works in accordance with mask modeling objective to further improve the predictive performance. We show that our model achieves state-of-the-art performance on ensemble level in estimating neural activities across four neural datasets, demonstrating its capability to capture autonomous and non-autonomous dynamics spanning different cortical regions while being completely agnostic to the specific behaviors at hand. Furthermore, STNDT spatial attention mechanism reveals consistently important subsets of neurons that play a vital role in driving the response of the entire population, providing interpretability and key insights into how the population of neurons performs computation.
Towards Target High-Utility Itemsets
Jun 09, 2022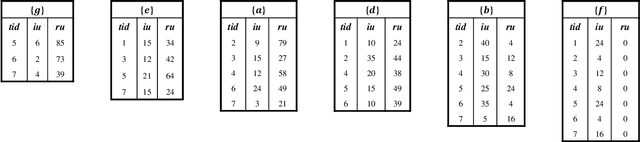

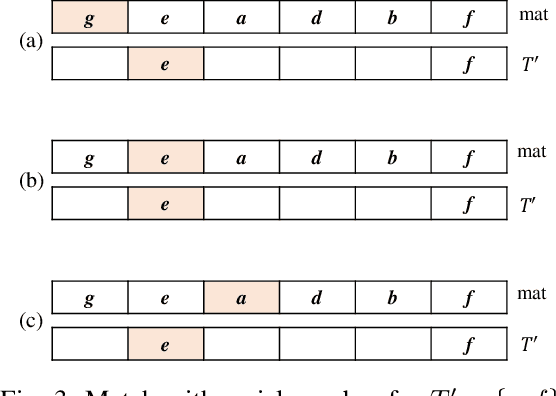
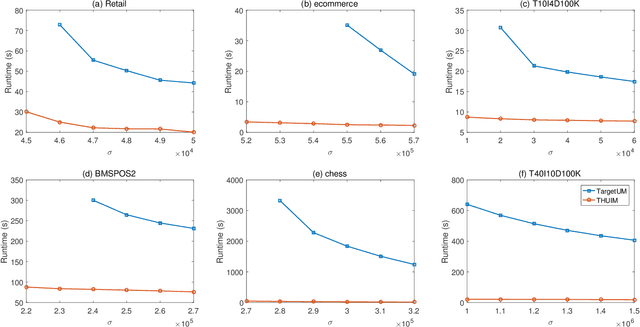
For applied intelligence, utility-driven pattern discovery algorithms can identify insightful and useful patterns in databases. However, in these techniques for pattern discovery, the number of patterns can be huge, and the user is often only interested in a few of those patterns. Hence, targeted high-utility itemset mining has emerged as a key research topic, where the aim is to find a subset of patterns that meet a targeted pattern constraint instead of all patterns. This is a challenging task because efficiently finding tailored patterns in a very large search space requires a targeted mining algorithm. A first algorithm called TargetUM has been proposed, which adopts an approach similar to post-processing using a tree structure, but the running time and memory consumption are unsatisfactory in many situations. In this paper, we address this issue by proposing a novel list-based algorithm with pattern matching mechanism, named THUIM (Targeted High-Utility Itemset Mining), which can quickly match high-utility itemsets during the mining process to select the targeted patterns. Extensive experiments were conducted on different datasets to compare the performance of the proposed algorithm with state-of-the-art algorithms. Results show that THUIM performs very well in terms of runtime and memory consumption, and has good scalability compared to TargetUM.
Condensing Graphs via One-Step Gradient Matching
Jun 15, 2022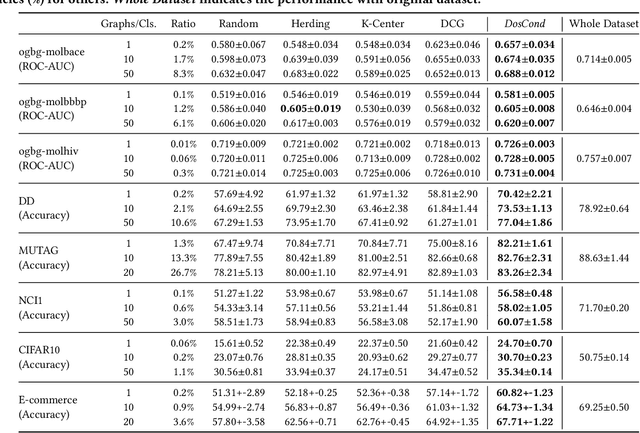
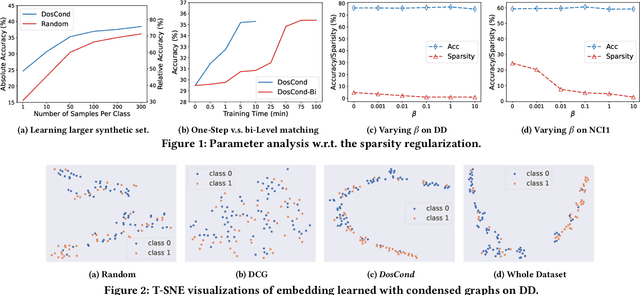
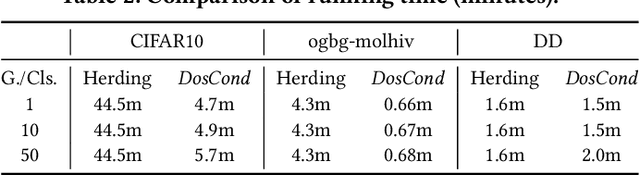
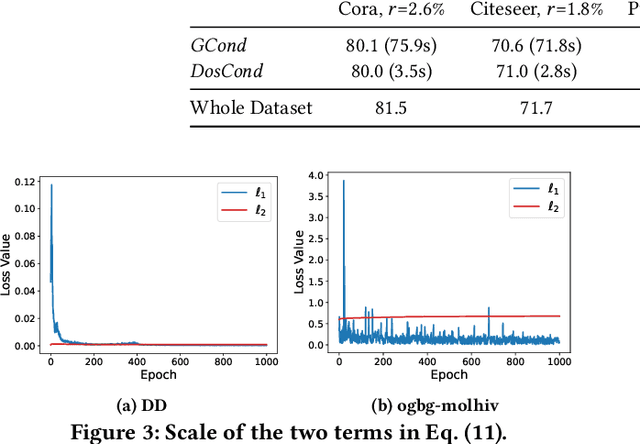
As training deep learning models on large dataset takes a lot of time and resources, it is desired to construct a small synthetic dataset with which we can train deep learning models sufficiently. There are recent works that have explored solutions on condensing image datasets through complex bi-level optimization. For instance, dataset condensation (DC) matches network gradients w.r.t. large-real data and small-synthetic data, where the network weights are optimized for multiple steps at each outer iteration. However, existing approaches have their inherent limitations: (1) they are not directly applicable to graphs where the data is discrete; and (2) the condensation process is computationally expensive due to the involved nested optimization. To bridge the gap, we investigate efficient dataset condensation tailored for graph datasets where we model the discrete graph structure as a probabilistic model. We further propose a one-step gradient matching scheme, which performs gradient matching for only one single step without training the network weights. Our theoretical analysis shows this strategy can generate synthetic graphs that lead to lower classification loss on real graphs. Extensive experiments on various graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, we are able to reduce the dataset size by 90% while approximating up to 98% of the original performance and our method is significantly faster than multi-step gradient matching (e.g. 15x in CIFAR10 for synthesizing 500 graphs).
ED2LM: Encoder-Decoder to Language Model for Faster Document Re-ranking Inference
Apr 25, 2022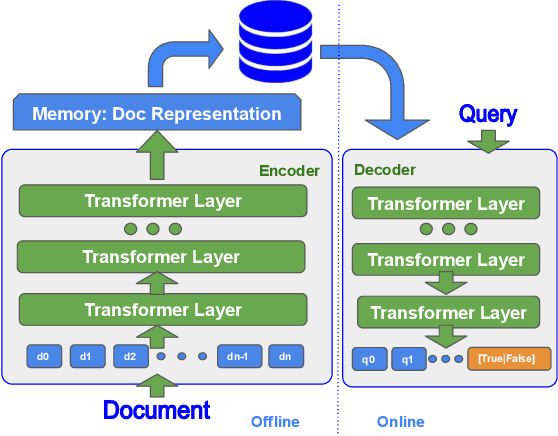
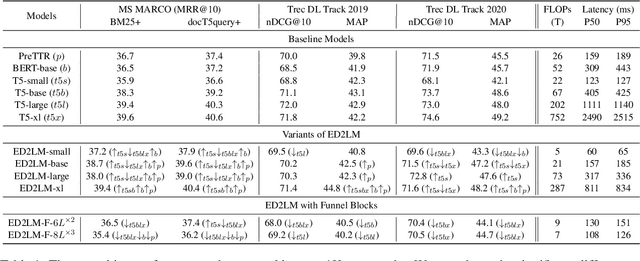
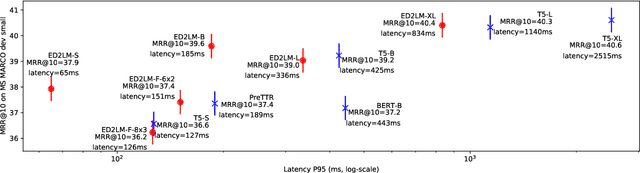
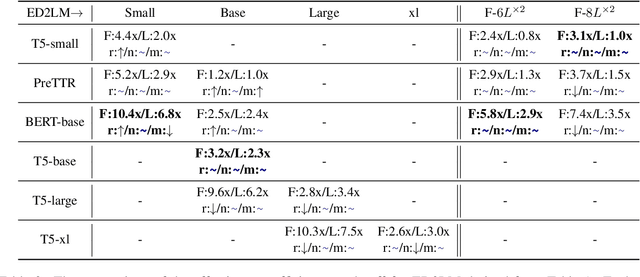
State-of-the-art neural models typically encode document-query pairs using cross-attention for re-ranking. To this end, models generally utilize an encoder-only (like BERT) paradigm or an encoder-decoder (like T5) approach. These paradigms, however, are not without flaws, i.e., running the model on all query-document pairs at inference-time incurs a significant computational cost. This paper proposes a new training and inference paradigm for re-ranking. We propose to finetune a pretrained encoder-decoder model using in the form of document to query generation. Subsequently, we show that this encoder-decoder architecture can be decomposed into a decoder-only language model during inference. This results in significant inference time speedups since the decoder-only architecture only needs to learn to interpret static encoder embeddings during inference. Our experiments show that this new paradigm achieves results that are comparable to the more expensive cross-attention ranking approaches while being up to 6.8X faster. We believe this work paves the way for more efficient neural rankers that leverage large pretrained models.
Masked Frequency Modeling for Self-Supervised Visual Pre-Training
Jun 15, 2022



We present Masked Frequency Modeling (MFM), a unified frequency-domain-based approach for self-supervised pre-training of visual models. Instead of randomly inserting mask tokens to the input embeddings in the spatial domain, in this paper, we shift the perspective to the frequency domain. Specifically, MFM first masks out a portion of frequency components of the input image and then predicts the missing frequencies on the frequency spectrum. Our key insight is that predicting masked components in the frequency domain is more ideal to reveal underlying image patterns rather than predicting masked patches in the spatial domain, due to the heavy spatial redundancy. Our findings suggest that with the right configuration of mask-and-predict strategy, both the structural information within high-frequency components and the low-level statistics among low-frequency counterparts are useful in learning good representations. For the first time, MFM demonstrates that, for both ViT and CNN, a simple non-Siamese framework can learn meaningful representations even using none of the following: (i) extra data, (ii) extra model, (iii) mask token. Experimental results on ImageNet and several robustness benchmarks show the competitive performance and advanced robustness of MFM compared with recent masked image modeling approaches. Furthermore, we also comprehensively investigate the effectiveness of classical image restoration tasks for representation learning from a unified frequency perspective and reveal their intriguing relations with our MFM approach. Project page: https://www.mmlab-ntu.com/project/mfm/index.html.
Pervasive wireless channel modeling theory and applications to 6G GBSMs for all frequency bands and all scenarios
Jun 06, 2022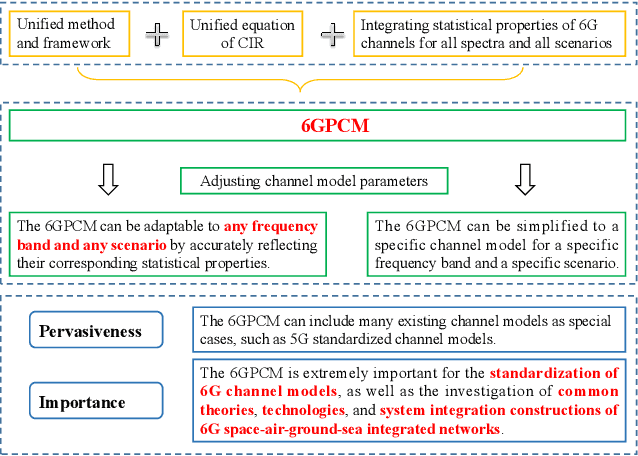
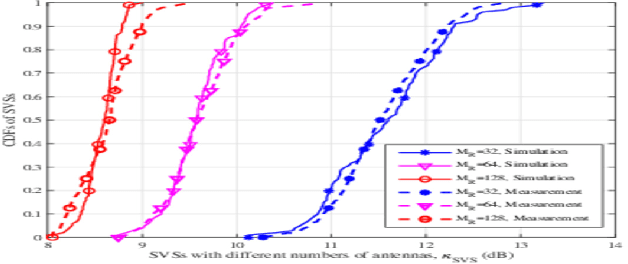
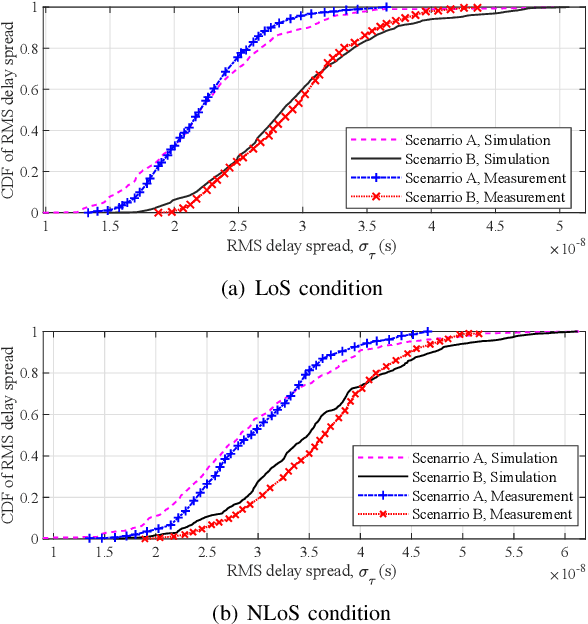
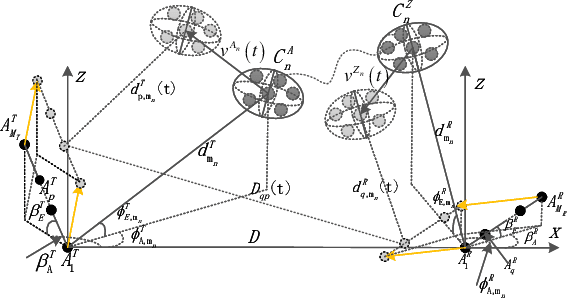
In this paper, a pervasive wireless channel modeling theory is first proposed, which uses a unified channel modeling method and a unified equation of channel impulse response (CIR), and can integrate important channel characteristics at different frequency bands and scenarios. Then, we apply the proposed theory to a three dimensional (3D) space-time-frequency (STF) non-stationary geometry-based stochastic model (GBSM) for the sixth generation (6G) wireless communication systems. The proposed 6G pervasive channel model (6GPCM) can characterize statistical properties of channels at all frequency bands from sub-6 GHz to visible light communication (VLC) bands and all scenarios such as unmanned aerial vehicle (UAV), maritime, (ultra-)massive multiple-input multiple-output (MIMO), reconfigurable intelligent surface (RIS), and industry Internet of things (IIoT) scenarios. By adjusting channel model parameters, the 6GPCM can be reduced to various simplified channel models for specific frequency bands and scenarios. Also, it includes standard fifth generation (5G) channel models as special cases. In addition, key statistical properties of the proposed 6GPCM are derived, simulated, and verified by various channel measurement results, which clearly demonstrates its accuracy, pervasiveness, and applicability.
Neural Deformable Voxel Grid for Fast Optimization of Dynamic View Synthesis
Jun 15, 2022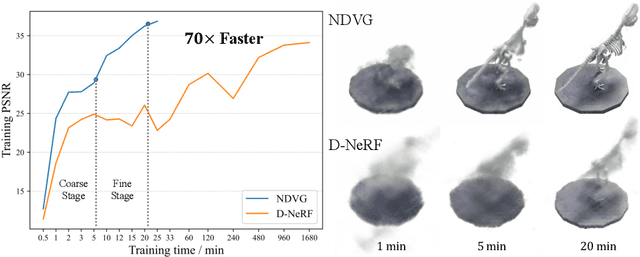
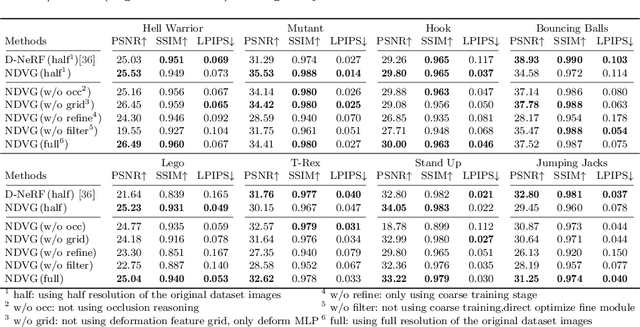
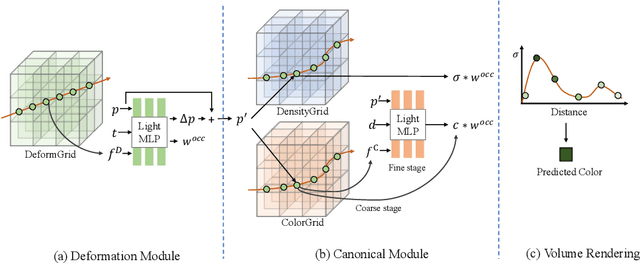

Recently, Neural Radiance Fields (NeRF) is revolutionizing the task of novel view synthesis (NVS) for its superior performance. However, NeRF and its variants generally require a lengthy per-scene training procedure, where a multi-layer perceptron (MLP) is fitted to the captured images. To remedy the challenge, the voxel-grid representation has been proposed to significantly speed up the training. However, these existing methods can only deal with static scenes. How to develop an efficient and accurate dynamic view synthesis method remains an open problem. Extending the methods for static scenes to dynamic scenes is not straightforward as both the scene geometry and appearance change over time. In this paper, built on top of the recent advances in voxel-grid optimization, we propose a fast deformable radiance field method to handle dynamic scenes. Our method consists of two modules. The first module adopts a deformation grid to store 3D dynamic features, and a light-weight MLP for decoding the deformation that maps a 3D point in observation space to the canonical space using the interpolated features. The second module contains a density and a color grid to model the geometry and density of the scene. The occlusion is explicitly modeled to further improve the rendering quality. Experimental results show that our method achieves comparable performance to D-NeRF using only 20 minutes for training, which is more than 70x faster than D-NeRF, clearly demonstrating the efficiency of our proposed method.
MemSeg: A semi-supervised method for image surface defect detection using differences and commonalities
May 02, 2022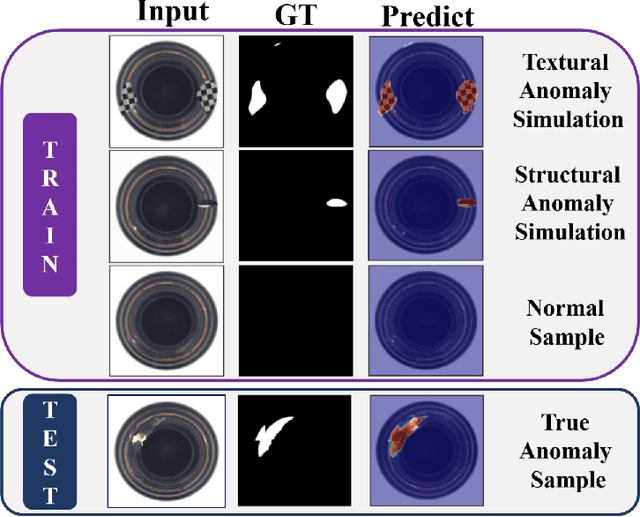
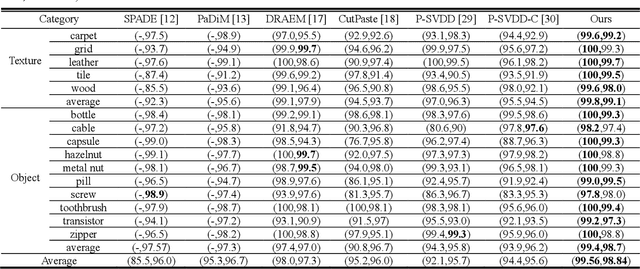


Under the semi-supervised framework, we propose an end-to-end memory-based segmentation network (MemSeg) to detect surface defects on industrial products. Considering the small intra-class variance of products in the same production line, from the perspective of differences and commonalities, MemSeg introduces artificially simulated abnormal samples and memory samples to assist the learning of the network. In the training phase, MemSeg explicitly learns the potential differences between normal and simulated abnormal images to obtain a robust classification hyperplane. At the same time, inspired by the mechanism of human memory, MemSeg uses a memory pool to store the general patterns of normal samples. By comparing the similarities and differences between input samples and memory samples in the memory pool to give effective guesses about abnormal regions; In the inference phase, MemSeg directly determines the abnormal regions of the input image in an end-to-end manner. Through experimental validation, MemSeg achieves the state-of-the-art (SOTA) performance on MVTec AD datasets with AUC scores of 99.56% and 98.84% at the image-level and pixel-level, respectively. In addition, MemSeg also has a significant advantage in inference speed benefiting from the end-to-end and straightforward network structure, which better meets the real-time requirement in industrial scenarios.
Statistical and Computational Phase Transitions in Group Testing
Jun 15, 2022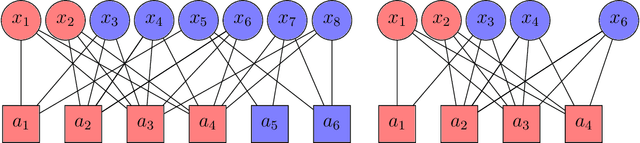
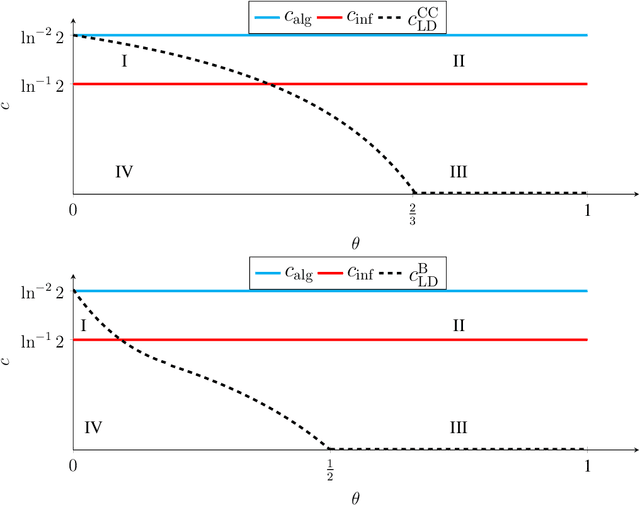
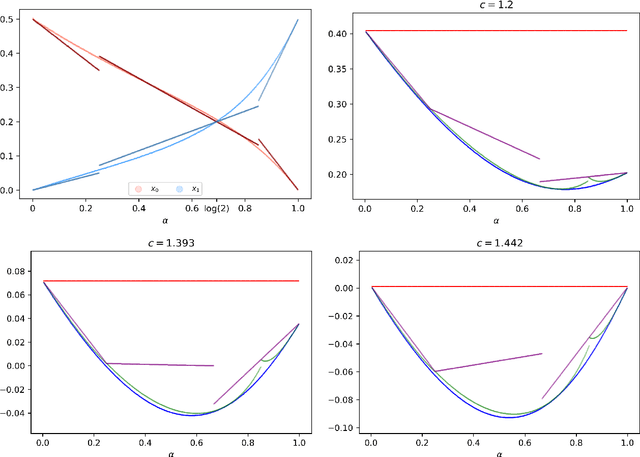
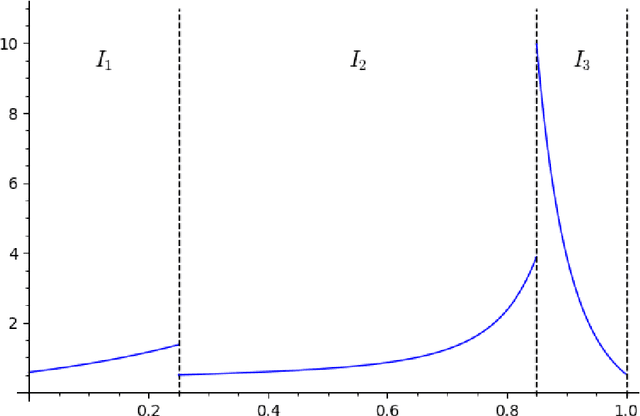
We study the group testing problem where the goal is to identify a set of k infected individuals carrying a rare disease within a population of size n, based on the outcomes of pooled tests which return positive whenever there is at least one infected individual in the tested group. We consider two different simple random procedures for assigning individuals to tests: the constant-column design and Bernoulli design. Our first set of results concerns the fundamental statistical limits. For the constant-column design, we give a new information-theoretic lower bound which implies that the proportion of correctly identifiable infected individuals undergoes a sharp "all-or-nothing" phase transition when the number of tests crosses a particular threshold. For the Bernoulli design, we determine the precise number of tests required to solve the associated detection problem (where the goal is to distinguish between a group testing instance and pure noise), improving both the upper and lower bounds of Truong, Aldridge, and Scarlett (2020). For both group testing models, we also study the power of computationally efficient (polynomial-time) inference procedures. We determine the precise number of tests required for the class of low-degree polynomial algorithms to solve the detection problem. This provides evidence for an inherent computational-statistical gap in both the detection and recovery problems at small sparsity levels. Notably, our evidence is contrary to that of Iliopoulos and Zadik (2021), who predicted the absence of a computational-statistical gap in the Bernoulli design.
To catch a chorus, verse, intro, or anything else: Analyzing a song with structural functions
May 29, 2022
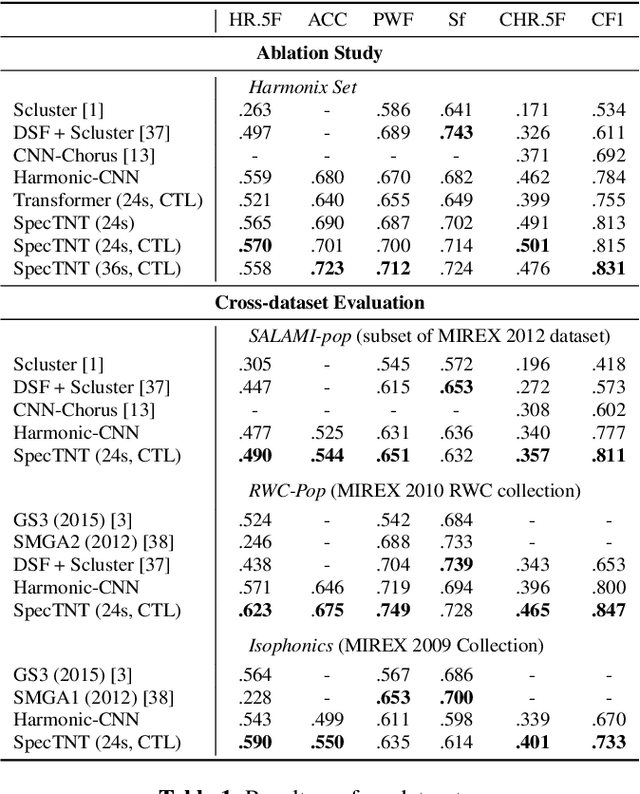
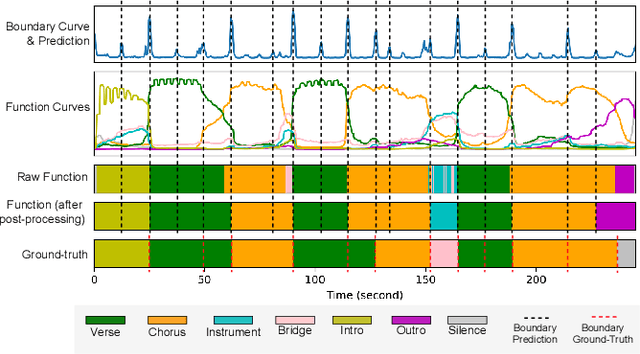
Conventional music structure analysis algorithms aim to divide a song into segments and to group them with abstract labels (e.g., 'A', 'B', and 'C'). However, explicitly identifying the function of each segment (e.g., 'verse' or 'chorus') is rarely attempted, but has many applications. We introduce a multi-task deep learning framework to model these structural semantic labels directly from audio by estimating "verseness," "chorusness," and so forth, as a function of time. We propose a 7-class taxonomy (i.e., intro, verse, chorus, bridge, outro, instrumental, and silence) and provide rules to consolidate annotations from four disparate datasets. We also propose to use a spectral-temporal Transformer-based model, called SpecTNT, which can be trained with an additional connectionist temporal localization (CTL) loss. In cross-dataset evaluations using four public datasets, we demonstrate the effectiveness of the SpecTNT model and CTL loss, and obtain strong results overall: the proposed system outperforms state-of-the-art chorus-detection and boundary-detection methods at detecting choruses and boundaries, respectively.