 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LIDER: An Efficient High-dimensional Learned Index for Large-scale Dense Passage Retrieval
May 02, 2022
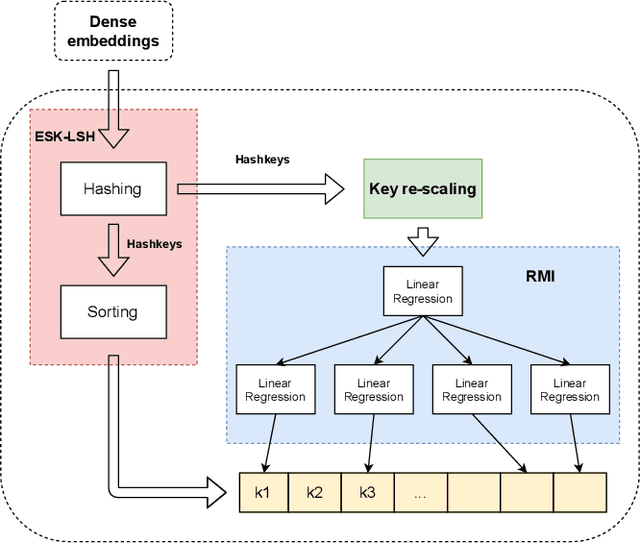
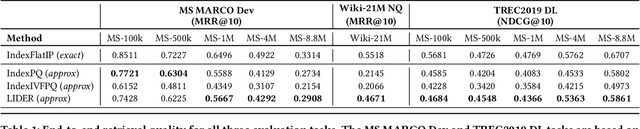
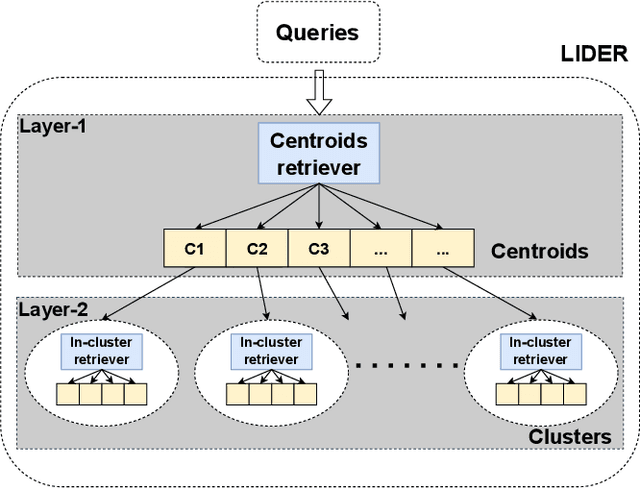
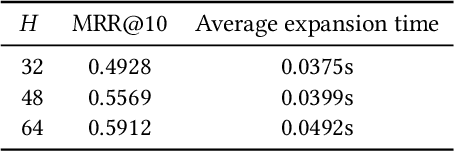
Text retrieval using dense embeddings generated from deep neural models is called "dense passage retrieval". Dense passage retrieval systems normally deploy a deep neural model followed by an approximate nearest neighbor (ANN) search module. The model generates text embeddings, which are then indexed by the ANN module. With the increasing data scale, the ANN module unavoidably becomes the bottleneck on efficiency, because of its linear or sublinear time complexity with data scale. An alternative is the learned index which has a theoretically constant time complexity. But most of the existing learned indexes are designed for low dimensional data. Thus they are not suitable for dense passage retrieval tasks with high-dimensional dense embeddings. We propose LIDER, an efficient high-dimensional Learned Index for large-scale DEnse passage Retrieval. LIDER has a clustering-based hierarchical architecture formed by two layers of core models. As the basic unit of LIDER to index and search data, each core model includes an adapted recursive model index (RMI) and a dimension reduction component which consists of an extended SortingKeys-LSH (SK-LSH) and a key re-scaling module. The dimension reduction component reduces the high-dimensional dense embeddings into one-dimensional keys and sorts them in a specific order, which are then used by the RMI. And the RMI consists of multiple simple linear regression models that make fast prediction in only O(1) time. We successfully optimize and combine SK-LSH and RMI together into the core model, and organize multiple core models into a two-layer structure based on a clustering-based partitioning of the whole data space. Experiments show that LIDER has a higher search speed with high retrieval quality comparing to the state-of-the-art ANN indexes commonly used in dense passage retrieval. Furthermore, LIDER has a better capability of speed-quality trade-off.
pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models
Jun 23, 2022



Knowledge tracing (KT) is the task of using students' historical learning interaction data to model their knowledge mastery over time so as to make predictions on their future interaction performance. Recently, remarkable progress has been made of using various deep learning techniques to solve the KT problem. However, the success behind deep learning based knowledge tracing (DLKT) approaches is still left somewhat mysterious and proper measurement and analysis of these DLKT approaches remain a challenge. First, data preprocessing procedures in existing works are often private and/or custom, which limits experimental standardization. Furthermore, existing DLKT studies often differ in terms of the evaluation protocol and are far away real-world educational contexts. To address these problems, we introduce a comprehensive python based benchmark platform, \textsc{pyKT}, to guarantee valid comparisons across DLKT methods via thorough evaluations. The \textsc{pyKT} library consists of a standardized set of integrated data preprocessing procedures on 7 popular datasets across different domains, and 10 frequently compared DLKT model implementations for transparent experiments. Results from our fine-grained and rigorous empirical KT studies yield a set of observations and suggestions for effective DLKT, e.g., wrong evaluation setting may cause label leakage that generally leads to performance inflation; and the improvement of many DLKT approaches is minimal compared to the very first DLKT model proposed by Piech et al. \cite{piech2015deep}. We have open sourced \textsc{pyKT} and our experimental results at \url{https://pykt.org/}. We welcome contributions from other research groups and practitioners.
Robust-RRT: Probabilistically-Complete Motion Planning for Uncertain Nonlinear Systems
May 16, 2022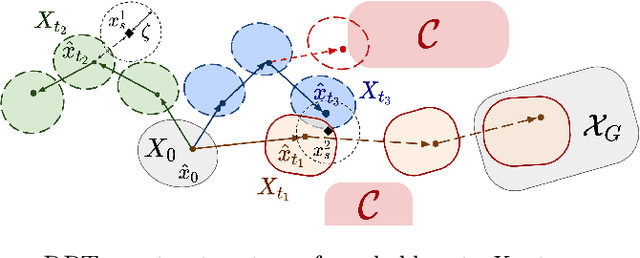
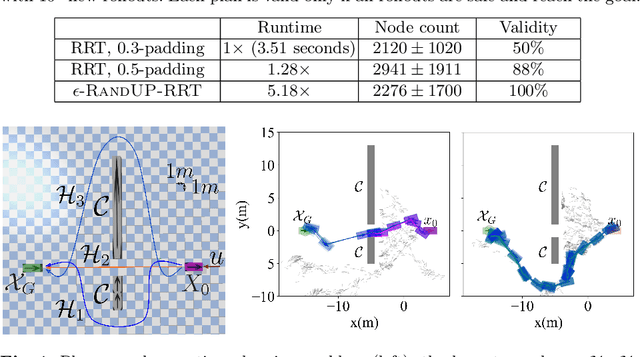
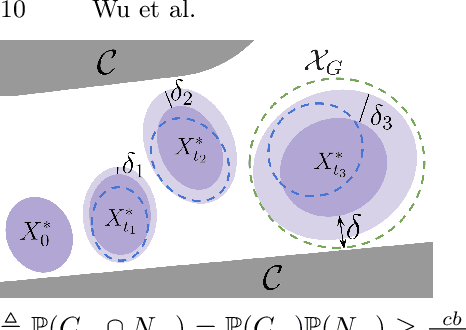

Robust motion planning entails computing a global motion plan that is safe under all possible uncertainty realizations, be it in the system dynamics, the robot's initial position, or with respect to external disturbances. Current approaches for robust motion planning either lack theoretical guarantees, or make restrictive assumptions on the system dynamics and uncertainty distributions. In this paper, we address these limitations by proposing the robust rapidly-exploring random-tree (Robust-RRT) algorithm, which integrates forward reachability analysis directly into sampling-based control trajectory synthesis. We prove that Robust-RRT is probabilistically complete (PC) for nonlinear Lipschitz continuous dynamical systems with bounded uncertainty. In other words, Robust-RRT eventually finds a robust motion plan that is feasible under all possible uncertainty realizations assuming such a plan exists. Our analysis applies even to unstable systems that admit only short-horizon feasible plans; this is because we explicitly consider the time evolution of reachable sets along control trajectories. Thanks to the explicit consideration of time dependency in our analysis, PC applies to unstabilizable systems. To the best of our knowledge, this is the most general PC proof for robust sampling-based motion planning, in terms of the types of uncertainties and dynamical systems it can handle. Considering that an exact computation of reachable sets can be computationally expensive for some dynamical systems, we incorporate sampling-based reachability analysis into Robust-RRT and demonstrate our robust planner on nonlinear, underactuated, and hybrid systems.
Asking the Right Questions in Low Resource Template Extraction
May 25, 2022
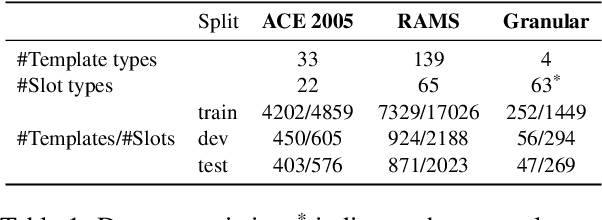
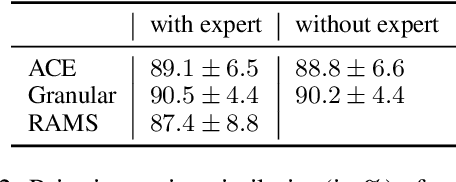
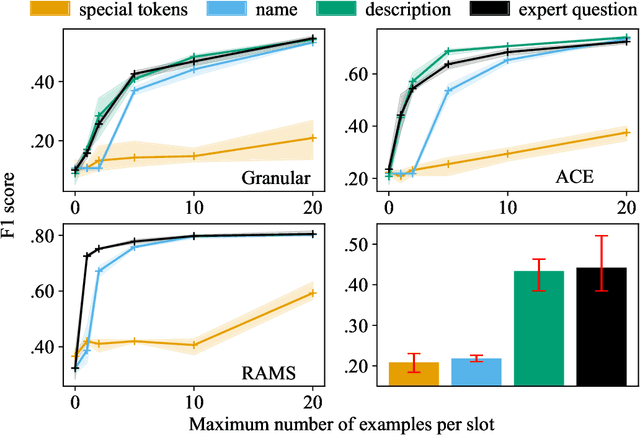
Information Extraction (IE) researchers are mapping tasks to Question Answering (QA) in order to leverage existing large QA resources, and thereby improve data efficiency. Especially in template extraction (TE), mapping an ontology to a set of questions can be more time-efficient than collecting labeled examples. We ask whether end users of TE systems can design these questions, and whether it is beneficial to involve an NLP practitioner in the process. We compare questions to other ways of phrasing natural language prompts for TE. We propose a novel model to perform TE with prompts, and find it benefits from questions over other styles of prompts, and that they do not require an NLP background to author.
Langevin Diffusion: An Almost Universal Algorithm for Private Euclidean (Convex) Optimization
Apr 06, 2022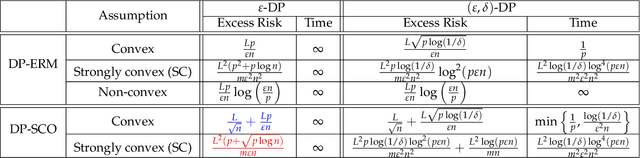
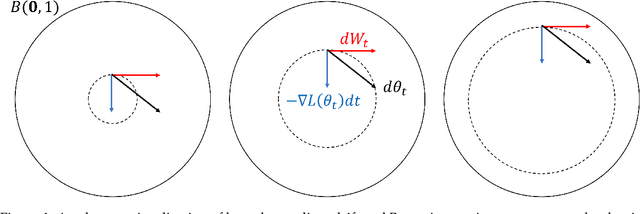
In this paper we revisit the problem of differentially private empirical risk minimization (DP-ERM) and stochastic convex optimization (DP-SCO). We show that a well-studied continuous time algorithm from statistical physics called Langevin diffusion (LD) simultaneously provides optimal privacy/utility tradeoffs for both DP-ERM and DP-SCO under $\epsilon$-DP and $(\epsilon,\delta)$-DP. Using the uniform stability properties of LD, we provide the optimal excess population risk guarantee for $\ell_2$-Lipschitz convex losses under $\epsilon$-DP (even up to $\log n$ factors), thus improving on Asi et al. Along the way we provide various technical tools which can be of independent interest: i) A new R\'enyi divergence bound for LD when run on loss functions over two neighboring data sets, ii) Excess empirical risk bounds for last-iterate LD analogous to that of Shamir and Zhang for noisy stochastic gradient descent (SGD), and iii) A two phase excess risk analysis of LD, where the first phase is when the diffusion has not converged in any reasonable sense to a stationary distribution, and in the second phase when the diffusion has converged to a variant of Gibbs distribution. Our universality results crucially rely on the dynamics of LD. When it has converged to a stationary distribution, we obtain the optimal bounds under $\epsilon$-DP. When it is run only for a very short time $\propto 1/p$, we obtain the optimal bounds under $(\epsilon,\delta)$-DP. Here, $p$ is the dimensionality of the model space. Our work initiates a systematic study of DP continuous time optimization. We believe this may have ramifications in the design of discrete time DP optimization algorithms analogous to that in the non-private setting, where continuous time dynamical viewpoints have helped in designing new algorithms, including the celebrated mirror-descent and Polyak's momentum method.
Parallel bandit architecture based on laser chaos for reinforcement learning
May 19, 2022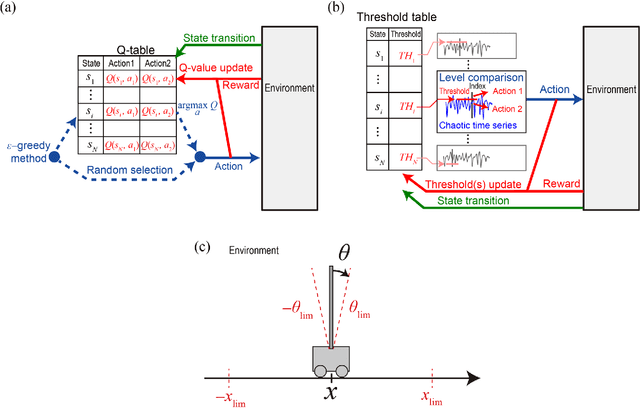

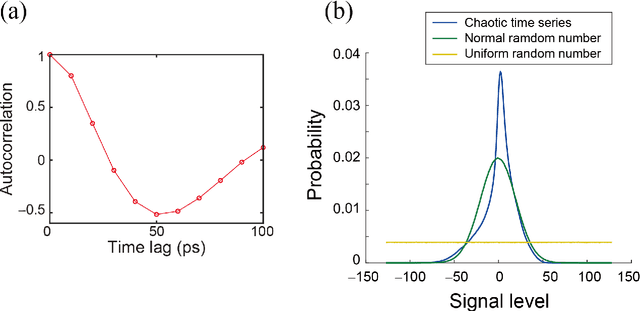
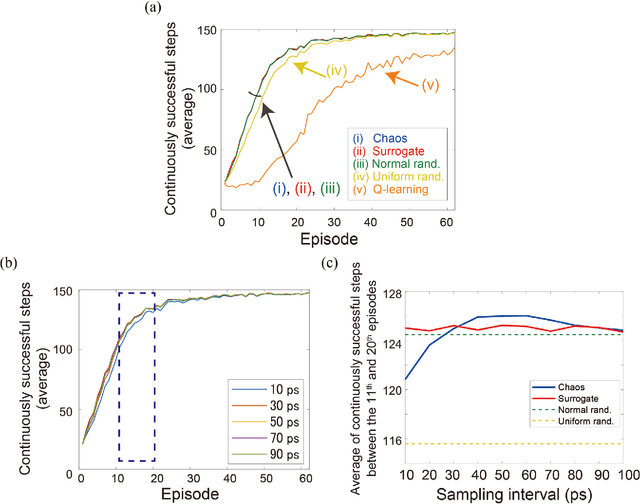
Accelerating artificial intelligence by photonics is an active field of study aiming to exploit the unique properties of photons. Reinforcement learning is an important branch of machine learning, and photonic decision-making principles have been demonstrated with respect to the multi-armed bandit problems. However, reinforcement learning could involve a massive number of states, unlike previously demonstrated bandit problems where the number of states is only one. Q-learning is a well-known approach in reinforcement learning that can deal with many states. The architecture of Q-learning, however, does not fit well photonic implementations due to its separation of update rule and the action selection. In this study, we organize a new architecture for multi-state reinforcement learning as a parallel array of bandit problems in order to benefit from photonic decision-makers, which we call parallel bandit architecture for reinforcement learning or PBRL in short. Taking a cart-pole balancing problem as an instance, we demonstrate that PBRL adapts to the environment in fewer time steps than Q-learning. Furthermore, PBRL yields faster adaptation when operated with a chaotic laser time series than the case with uniformly distributed pseudorandom numbers where the autocorrelation inherent in the laser chaos provides a positive effect. We also find that the variety of states that the system undergoes during the learning phase exhibits completely different properties between PBRL and Q-learning. The insights obtained through the present study are also beneficial for existing computing platforms, not just photonic realizations, in accelerating performances by the PBRL algorithms and correlated random sequences.
Transformer Lesion Tracker
Jun 13, 2022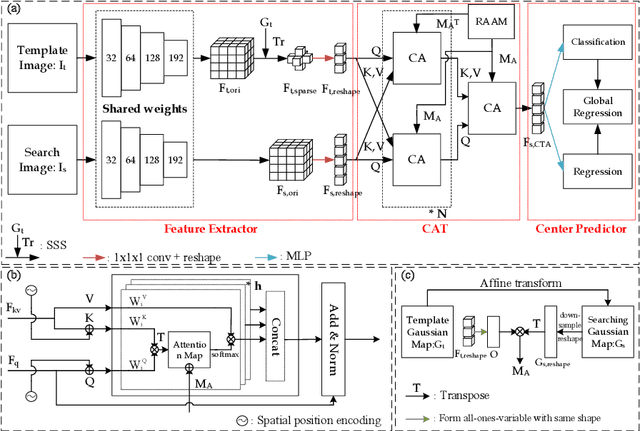
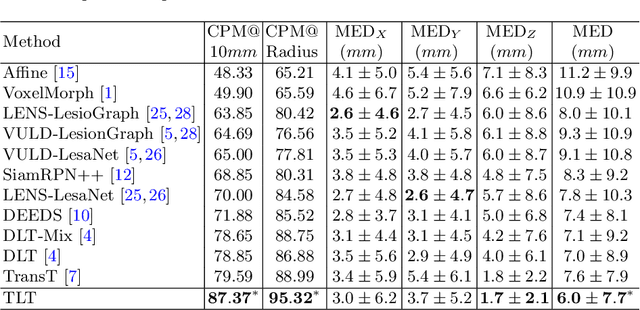
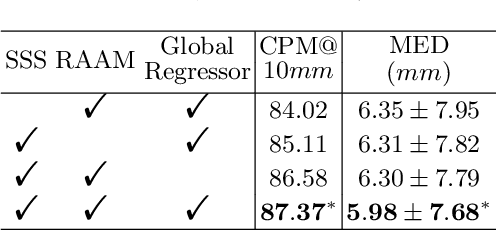

Evaluating lesion progression and treatment response via longitudinal lesion tracking plays a critical role in clinical practice. Automated approaches for this task are motivated by prohibitive labor costs and time consumption when lesion matching is done manually. Previous methods typically lack the integration of local and global information. In this work, we propose a transformer-based approach, termed Transformer Lesion Tracker (TLT). Specifically, we design a Cross Attention-based Transformer (CAT) to capture and combine both global and local information to enhance feature extraction. We also develop a Registration-based Anatomical Attention Module (RAAM) to introduce anatomical information to CAT so that it can focus on useful feature knowledge. A Sparse Selection Strategy (SSS) is presented for selecting features and reducing memory footprint in Transformer training. In addition, we use a global regression to further improve model performance. We conduct experiments on a public dataset to show the superiority of our method and find that our model performance has improved the average Euclidean center error by at least 14.3% (6mm vs. 7mm) compared with the state-of-the-art (SOTA). Code is available at https://github.com/TangWen920812/TLT.
Cooperative Retriever and Ranker in Deep Recommenders
Jun 28, 2022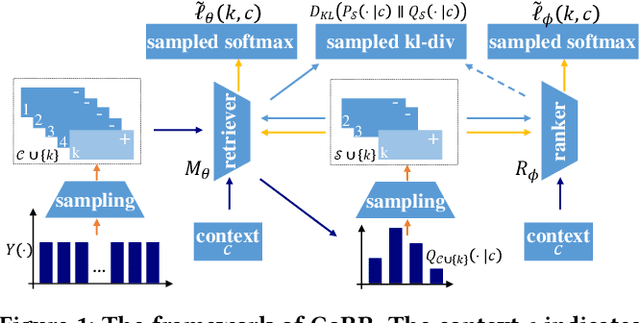

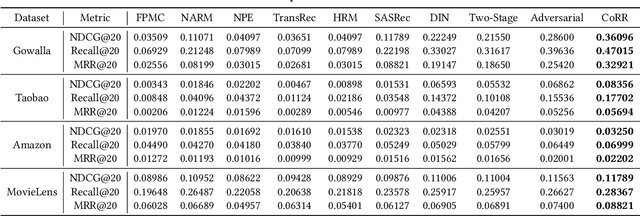
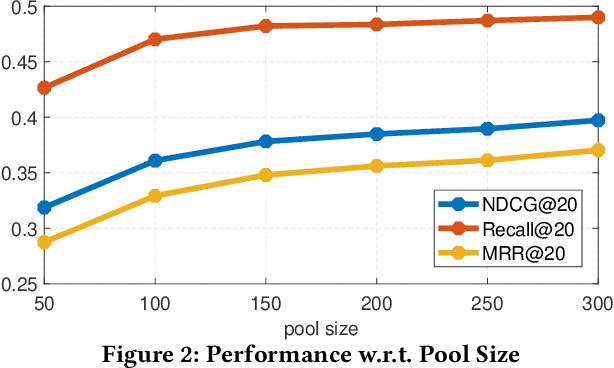
Deep recommender systems jointly leverage the retrieval and ranking operations to generate the recommendation result. The retriever targets selecting a small set of relevant candidates from the entire items with high efficiency; while the ranker, usually more precise but time-consuming, is supposed to identify the best items out of the retrieved candidates with high precision. However, the retriever and ranker are usually trained in poorly-cooperative ways, leading to limited recommendation performances when working as an entirety. In this work, we propose a novel DRS training framework CoRR(short for Cooperative Retriever and Ranker), where the retriever and ranker can be mutually reinforced. On one hand, the retriever is learned from recommendation data and the ranker via knowledge distillation; knowing that the ranker is more precise, the knowledge distillation may provide extra weak-supervision signals for the improvement of retrieval quality. On the other hand, the ranker is trained by learning to discriminate the truth positive items from hard negative candidates sampled from the retriever. With the iteration going on, the ranker may become more precise, which in return gives rise to informative training signals for the retriever; meanwhile, with the improvement of retriever, harder negative candidates can be sampled, which contributes to a higher discriminative capability of the ranker. To facilitate the effective conduct of CoRR, an asymptotic-unbiased approximation of KL divergence is introduced for the knowledge distillation over sampled items; besides, a scalable and adaptive strategy is developed to efficiently sample from the retriever. Comprehensive experimental studies are performed over four large-scale benchmark datasets, where CoRR improves the overall recommendation quality resulting from the cooperation between retriever and ranker.
Predicting extreme events from data using deep machine learning: when and where
Mar 31, 2022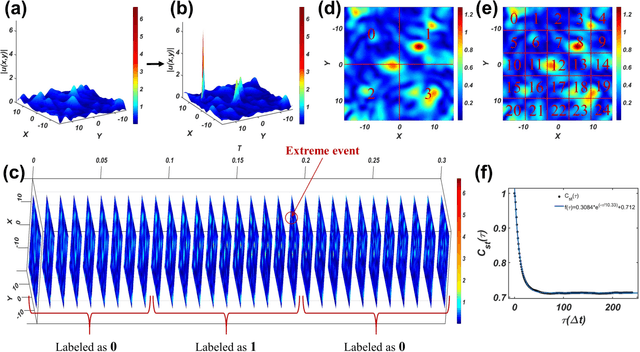
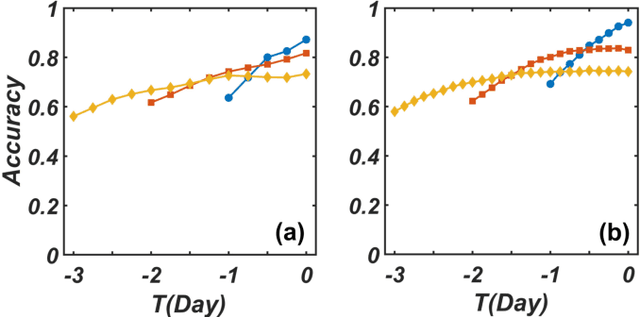
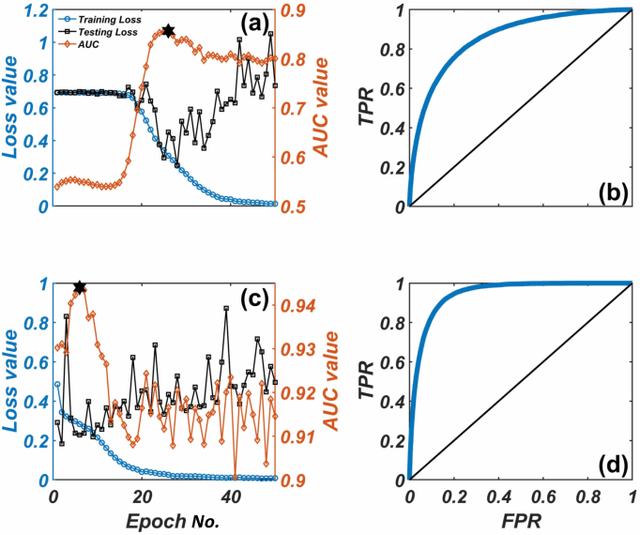
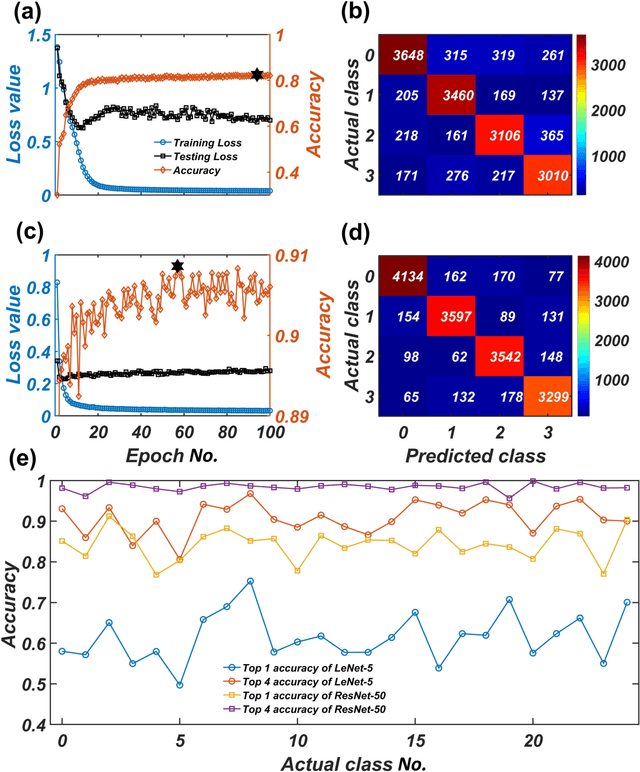
We develop a deep convolutional neural network (DCNN) based framework for model-free prediction of the occurrence of extreme events both in time ("when") and in space ("where") in nonlinear physical systems of spatial dimension two. The measurements or data are a set of two-dimensional snapshots or images. For a desired time horizon of prediction, a proper labeling scheme can be designated to enable successful training of the DCNN and subsequent prediction of extreme events in time. Given that an extreme event has been predicted to occur within the time horizon, a space-based labeling scheme can be applied to predict, within certain resolution, the location at which the event will occur. We use synthetic data from the 2D complex Ginzburg-Landau equation and empirical wind speed data of the North Atlantic ocean to demonstrate and validate our machine-learning based prediction framework. The trade-offs among the prediction horizon, spatial resolution, and accuracy are illustrated, and the detrimental effect of spatially biased occurrence of extreme event on prediction accuracy is discussed. The deep learning framework is viable for predicting extreme events in the real world.
CLAP: Learning Audio Concepts From Natural Language Supervision
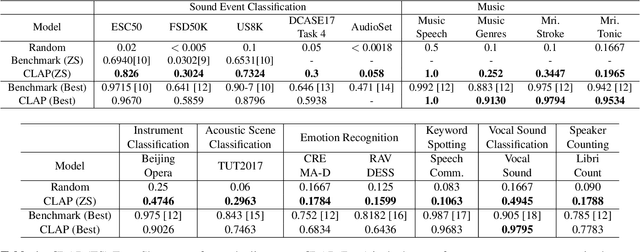
Jun 09, 2022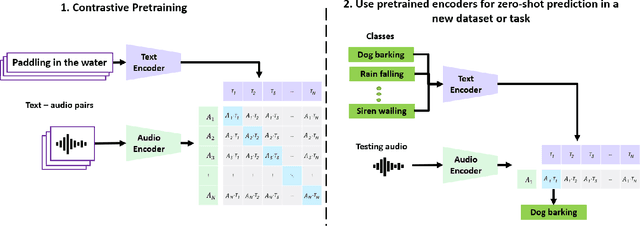
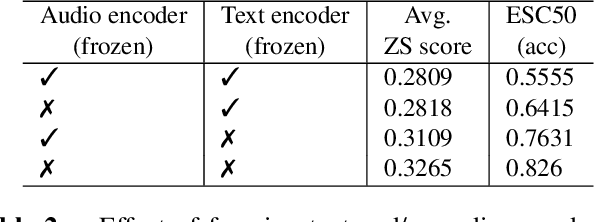
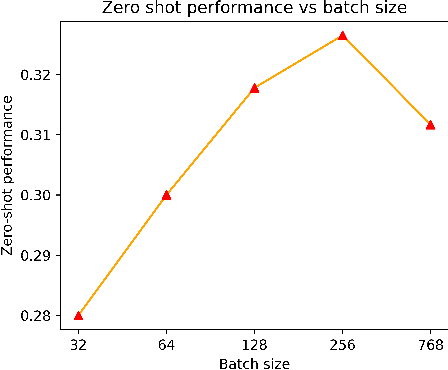
Mainstream Audio Analytics models are trained to learn under the paradigm of one class label to many recordings focusing on one task. Learning under such restricted supervision limits the flexibility of models because they require labeled audio for training and can only predict the predefined categories. Instead, we propose to learn audio concepts from natural language supervision. We call our approach Contrastive Language-Audio Pretraining (CLAP), which learns to connect language and audio by using two encoders and a contrastive learning to bring audio and text descriptions into a joint multimodal space. We trained CLAP with 128k audio and text pairs and evaluated it on 16 downstream tasks across 8 domains, such as Sound Event Classification, Music tasks, and Speech-related tasks. Although CLAP was trained with significantly less pairs than similar computer vision models, it establishes SoTA for Zero-Shot performance. Additionally, we evaluated CLAP in a supervised learning setup and achieve SoTA in 5 tasks. Hence, CLAP's Zero-Shot capability removes the need of training with class labels, enables flexible class prediction at inference time, and generalizes to multiple downstream tasks.